Important
You are viewing documentation for an older version of Confluent Platform. For the latest, click here.
Confluent Platform Quick Start (Local)¶
Download Confluent Platform and use this quick start to get up and running with Confluent Platform and its main components in a development environment. This quick start demonstrates both the basic and most powerful capabilities of Confluent Platform, including using Control Center for topic management and event stream processing using KSQL. In this quick start you create Apache Kafka® topics, use Kafka Connect to generate mock data to those topics, and create KSQL streaming queries on those topics. You then go to Control Center to monitor and analyze the streaming queries.
See also
You can also run an automated version of this quick start designed for Confluent Platform local installs.
Important
Java 8 and Java 11 are supported in this version of Confluent Platform (Java 9 and 10 are not supported). For more information, see Java supported versions. You need to separately install the correct version of Java before you start the Confluent Platform installation process.
- Prerequisites:
- Internet connectivity.
- Ensure you are on an Operating System currently supported by Confluent Platform.
Step 1: Download and Start Confluent Platform¶
Go to the downloads page and choose Confluent Platform.
Tip
Download a previous version from Previous Versions.
Provide your name and email and select Download, and then choose the desired format
.tar.gzor.zip.Decompress the file. You should have the directories, such as
binandetc.Set the environment variable for the Confluent Platform directory.
export CONFLUENT_HOME=<path-to-confluent>
Add the Confluent Platform
bindirectory to your PATH.export PATH=$PATH:$CONFLUENT_HOME/bin
Install the Kafka Connect Datagen source connector using the Confluent Hub client. This connector generates mock data for demonstration purposes and is not suitable for production. Confluent Hub is an online library of pre-packaged and ready-to-install extensions or add-ons for Confluent Platform and Kafka.
$CONFLUENT_HOME/bin/confluent-hub install \ --no-prompt confluentinc/kafka-connect-datagen:latest
Your output should resemble:
Running in a "--no-prompt" mode ... Completed
Start Confluent Platform using the Confluent CLI confluent local start command. This command starts all of the Confluent Platform components; including Kafka, ZooKeeper, Schema Registry, HTTP REST Proxy for Kafka, Kafka Connect, KSQL, and Control Center.
Important
The confluent local commands are intended for a single-node development environment and are not suitable for a production environment. The data that are produced are transient and are intended to be temporary. For production-ready workflows, see Install and Upgrade.
confluent local start
Your output should resemble:
Starting zookeeper zookeeper is [UP] Starting kafka kafka is [UP] Starting schema-registry schema-registry is [UP] Starting kafka-rest kafka-rest is [UP] Starting connect connect is [UP] Starting ksql-server ksql-server is [UP] Starting control-center control-center is [UP]
Step 2: Create Kafka Topics¶
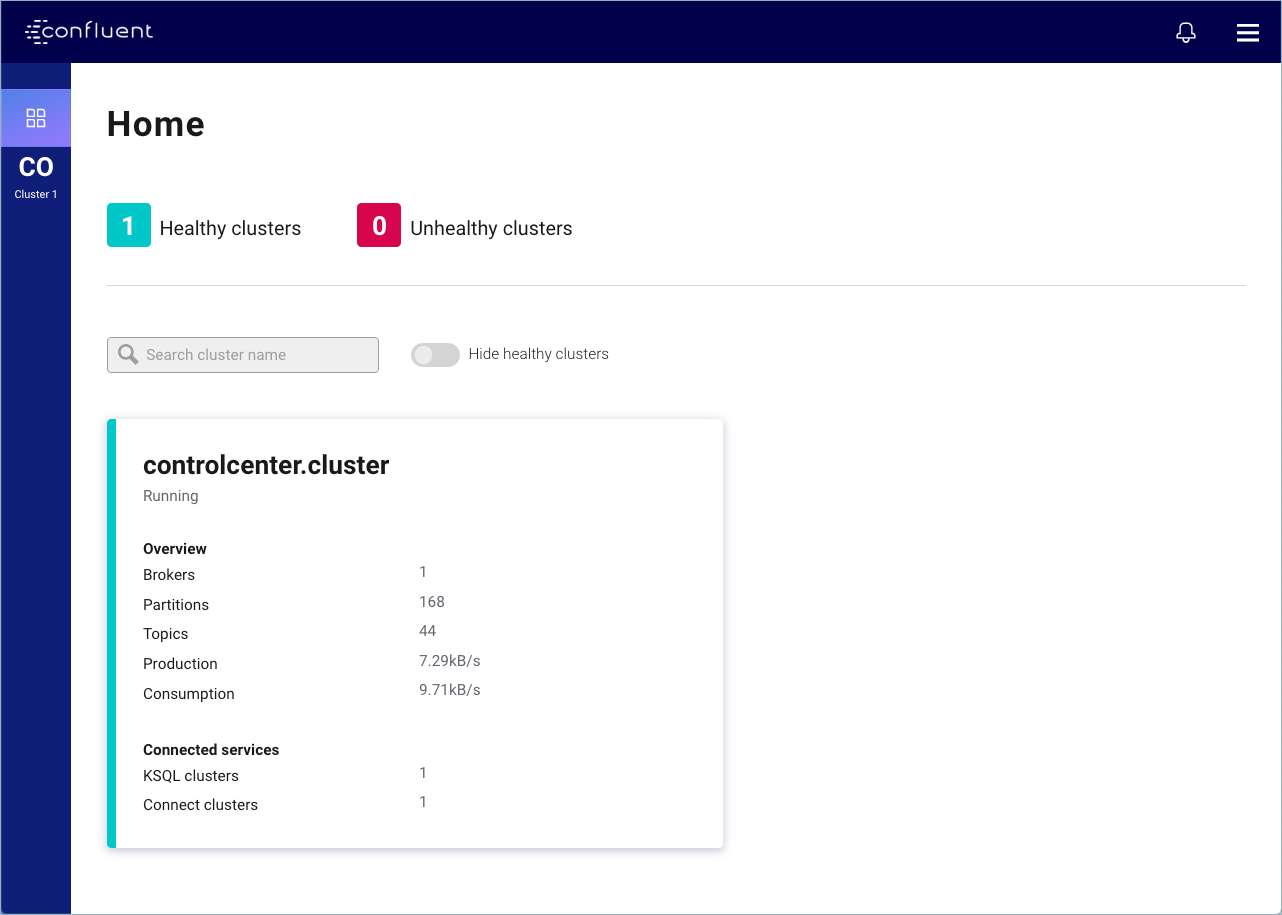
In this step, you create Kafka topics by using the Confluent Control Center. Confluent Control Center provides the functionality for building and monitoring production data pipelines and event streaming applications.
Navigate to the Control Center web interface at http://localhost:9021/ and select your cluster.
Important
It may take a minute or two for Control Center to come online.
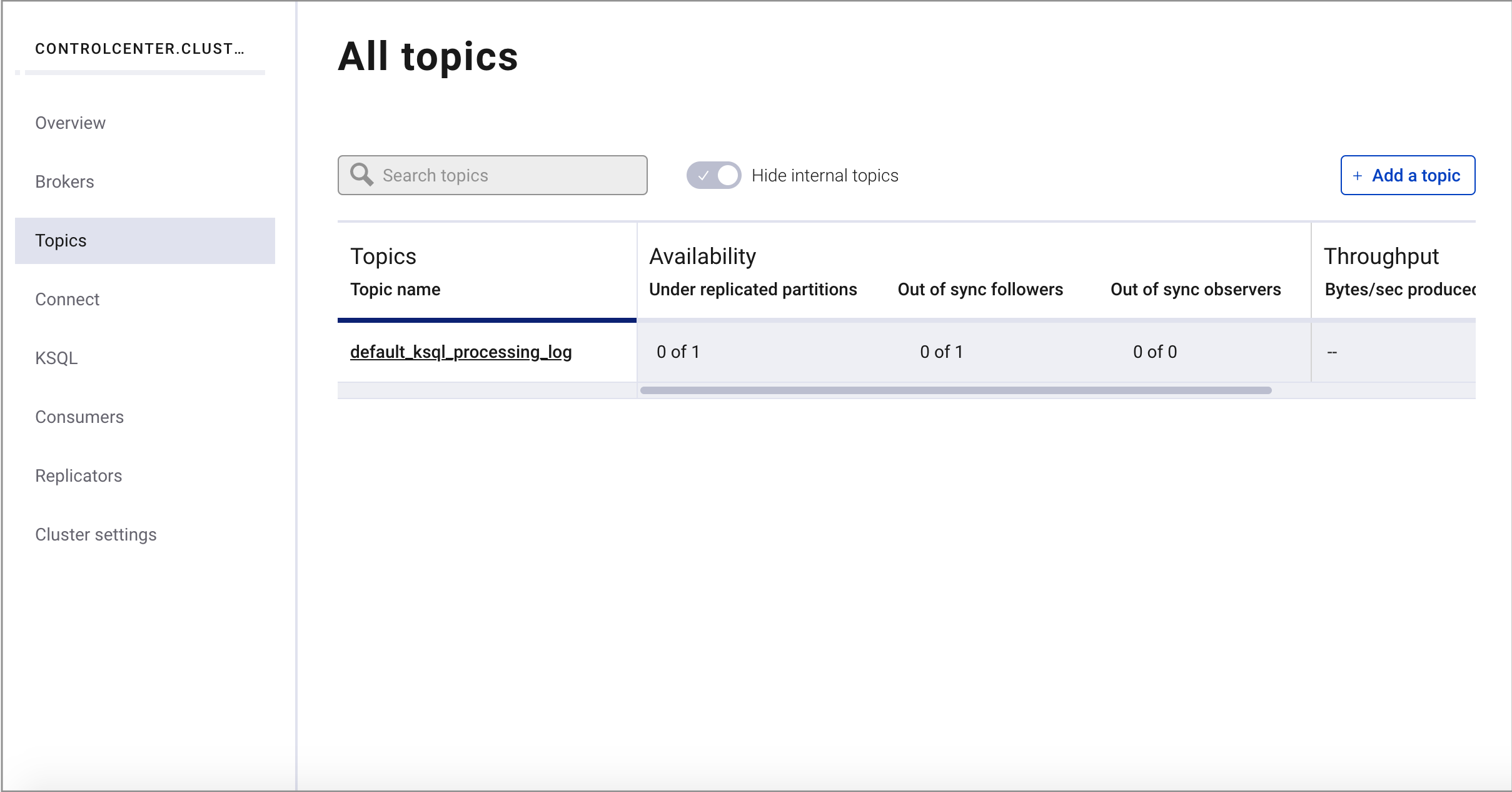
Select Topics from the cluster submenu and click Add a topic.
Create a topic named
pageviewsand click Create with defaults.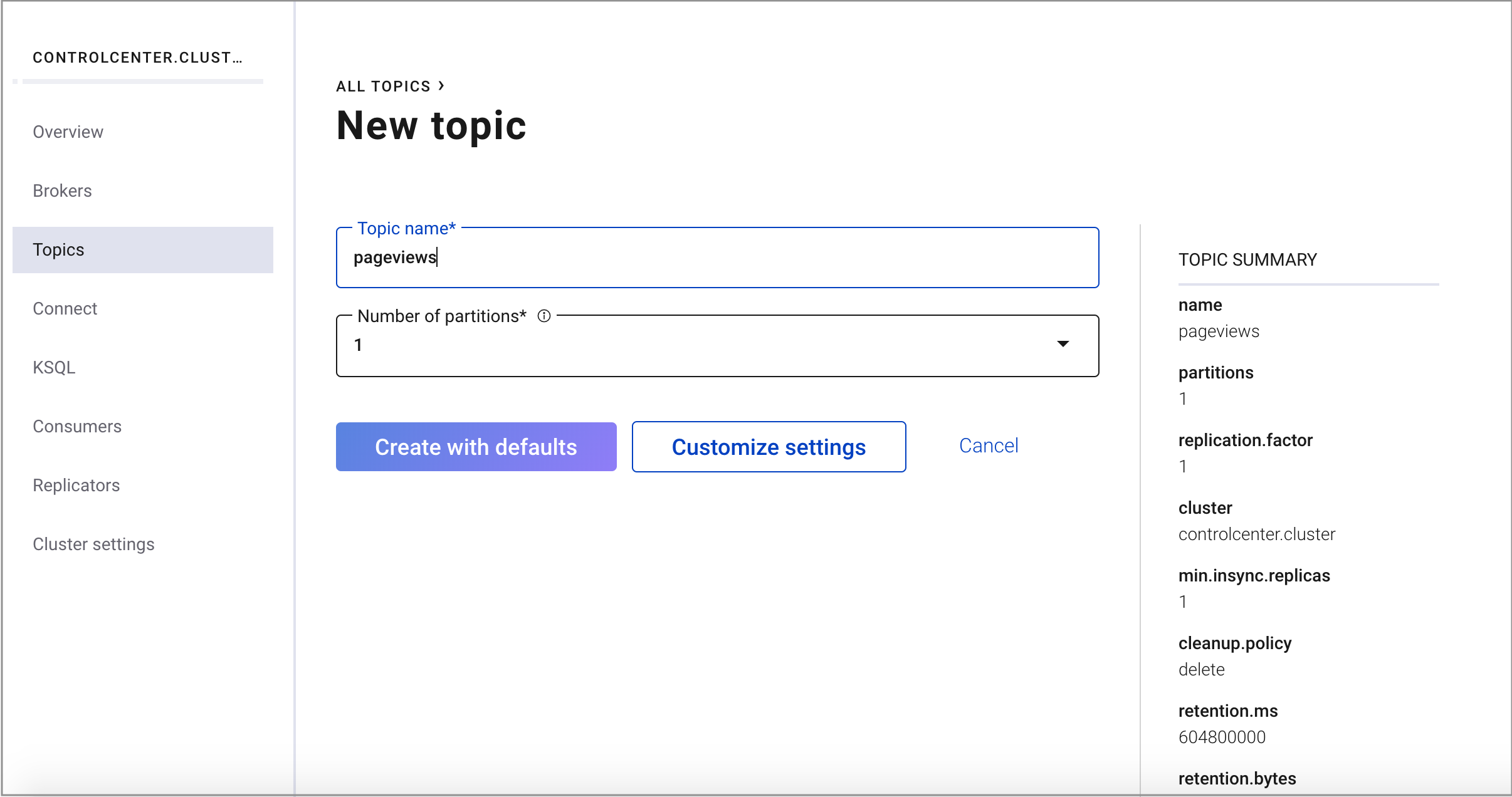
Repeat the previous steps and create a topic named
usersand click Create with defaults.
Step 3: Install a Kafka Connector and Generate Sample Data¶
In this step, you use Kafka Connect to run a demo source connector called kafka-connect-datagen that creates sample data for the Kafka topics pageviews and users.
Tip
The Kafka Connect Datagen connector was installed manually in Step 1: Download and Start Confluent Platform. If you encounter issues locating the Datagen Connector, refer to the Issue: Cannot locate the Datagen Connector in the Troubleshooting section.
Run one instance of the Kafka Connect Datagen connector to produce Kafka data to the
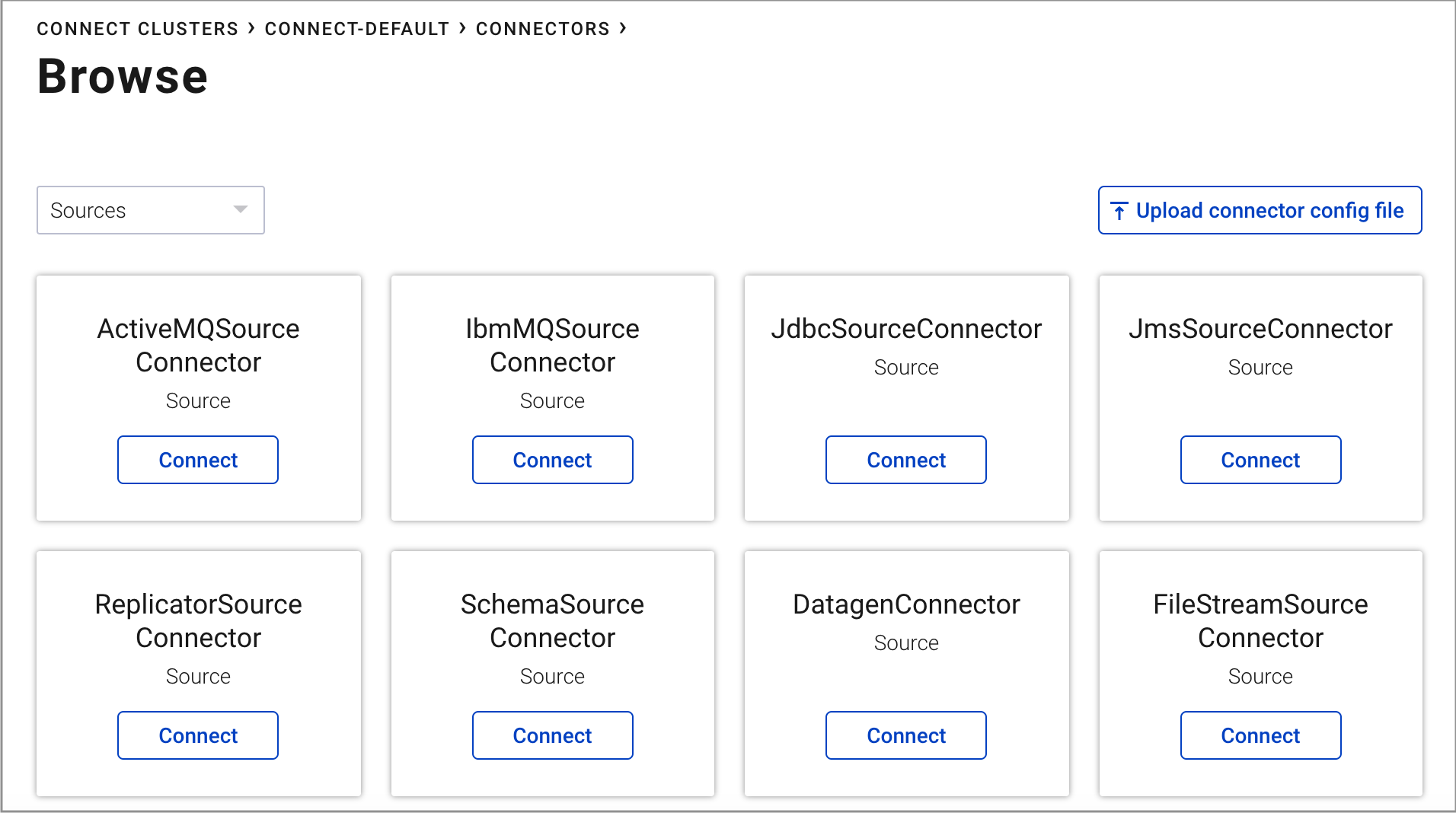
pageviewstopic in AVRO format.From your cluster, click Connect.
Select the
connect-defaultcluster and click Add connector.Find the DatagenConnector tile and click Connect.
Tip
To narrow displayed connectors, click Filter by type -> Sources.
Name the connector
datagen-pageviews. After naming the connector, new fields appear. Scroll down and specify the following configuration values:- In the Key converter class field, type
org.apache.kafka.connect.storage.StringConverter. - In the kafka.topic field, type
pageviews. - In the max.interval field, type
100. - In the iterations field, type
1000000000. - In the quickstart field, type
pageviews.
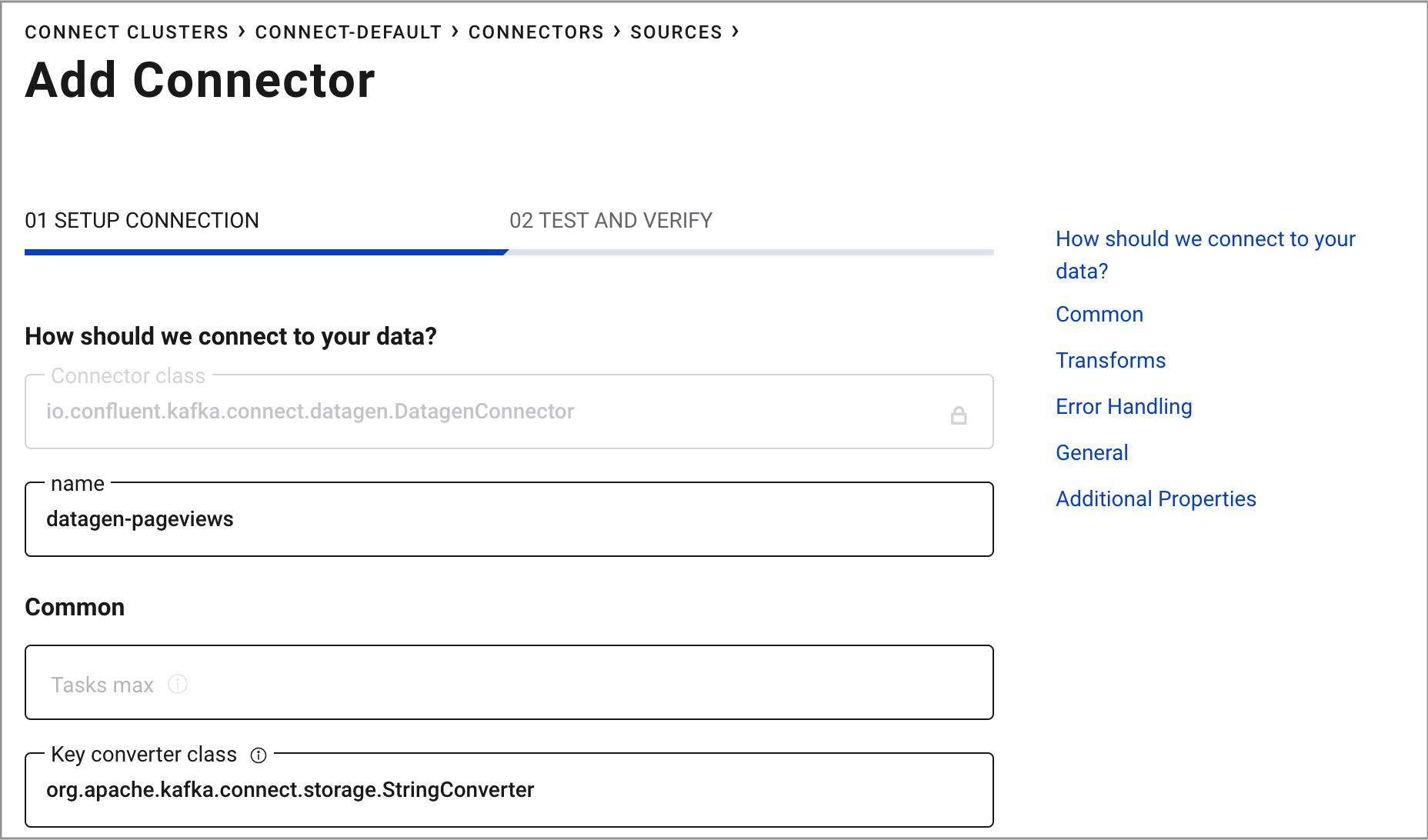
- In the Key converter class field, type
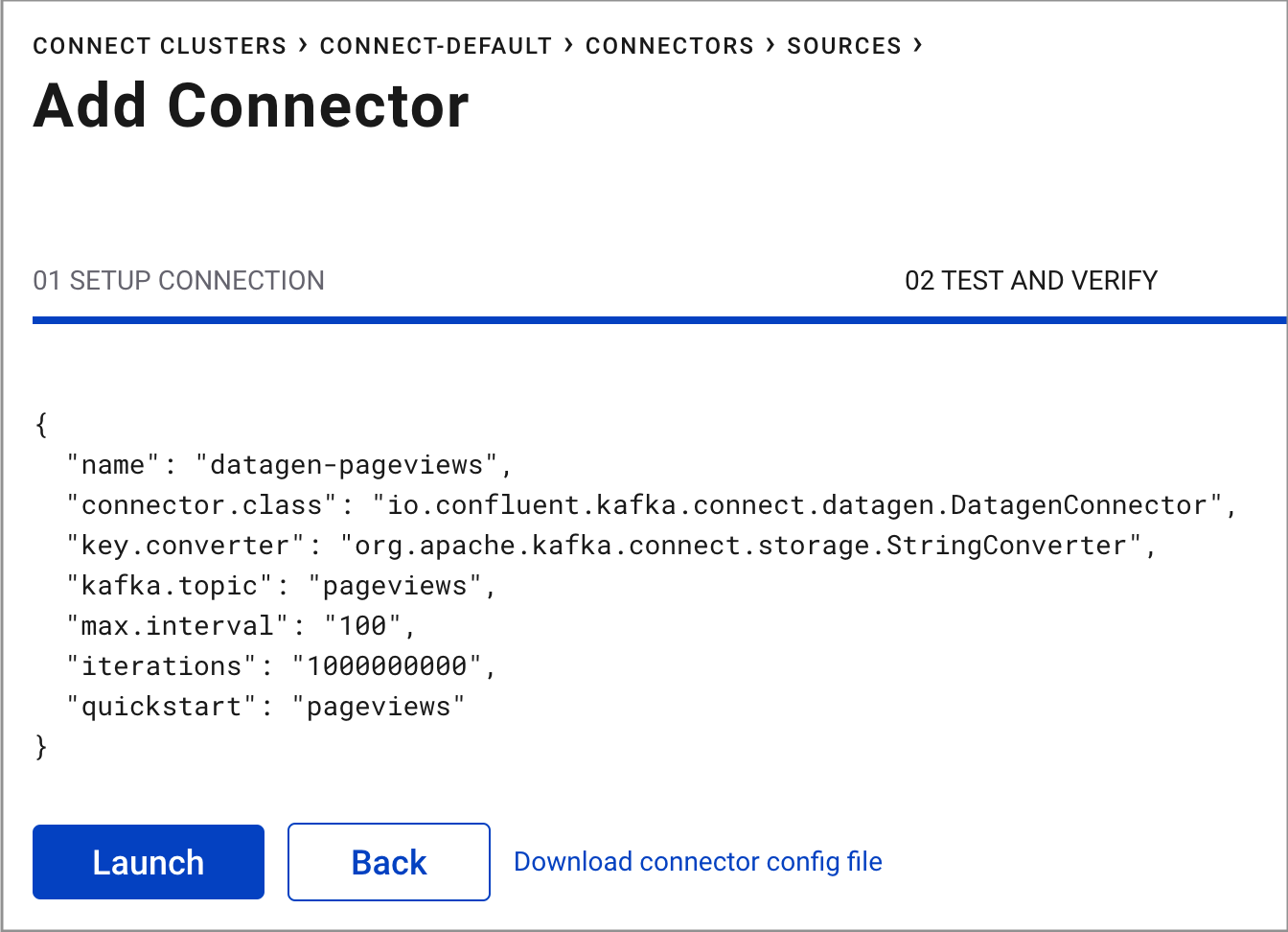
Click Continue.
Review the connector configuration and click Launch.
Run another instance of the Kafka Connect Datagen connector to produce Kafka data to the
userstopic in AVRO format.Select the
connect_defaultcluster and click Add connector.Find the DatagenConnector tile and click Connect.
Name the connector
datagen-users. After naming the connector, new fields appear. Scroll down and specify the following configuration values:- In the Key converter class field, type
org.apache.kafka.connect.storage.StringConverter. - In the kafka.topic field, type
users. - In the max.interval field, type
1000. - In the iterations field, type
1000000000. - In the quickstart field, type
users.
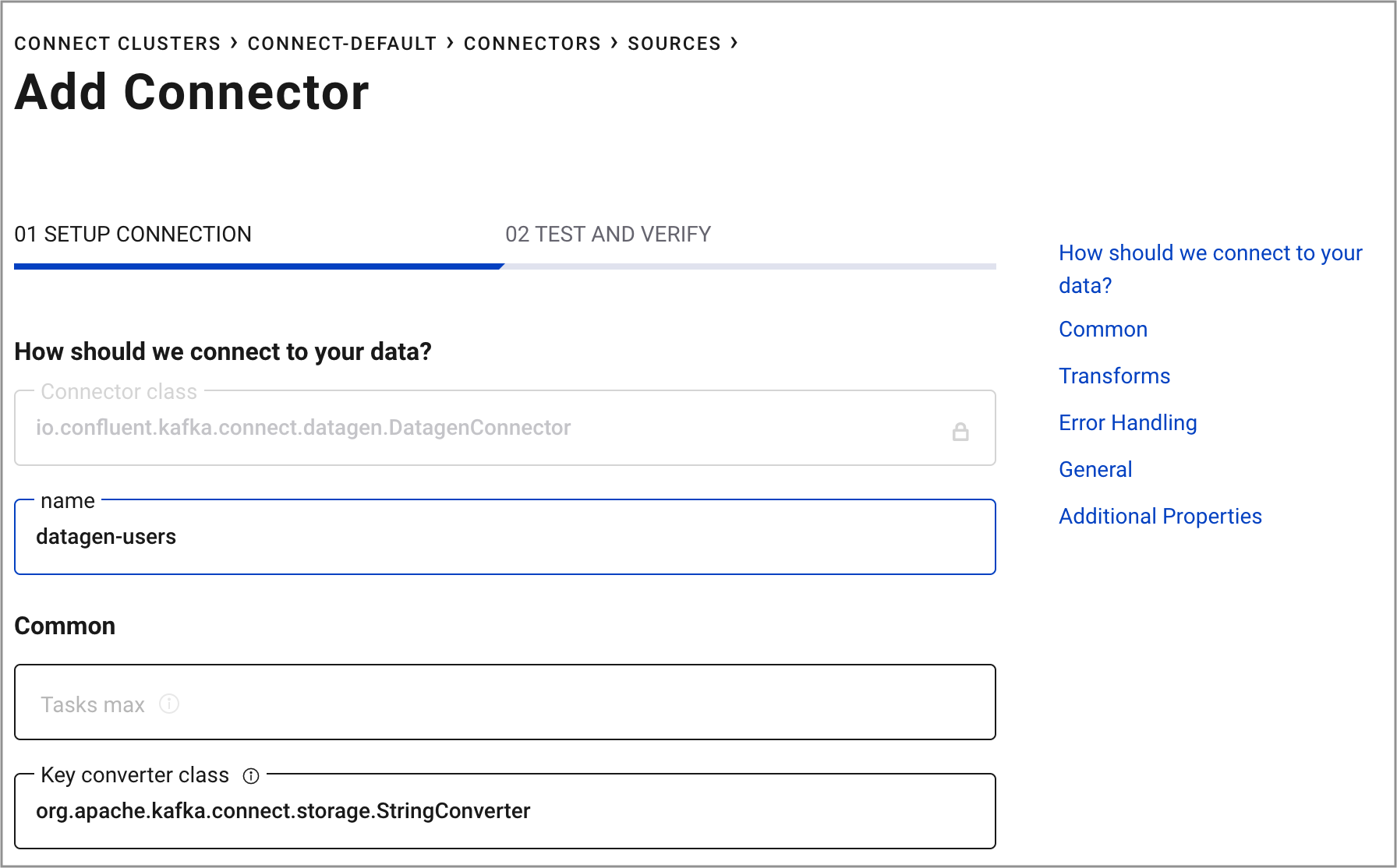
- In the Key converter class field, type
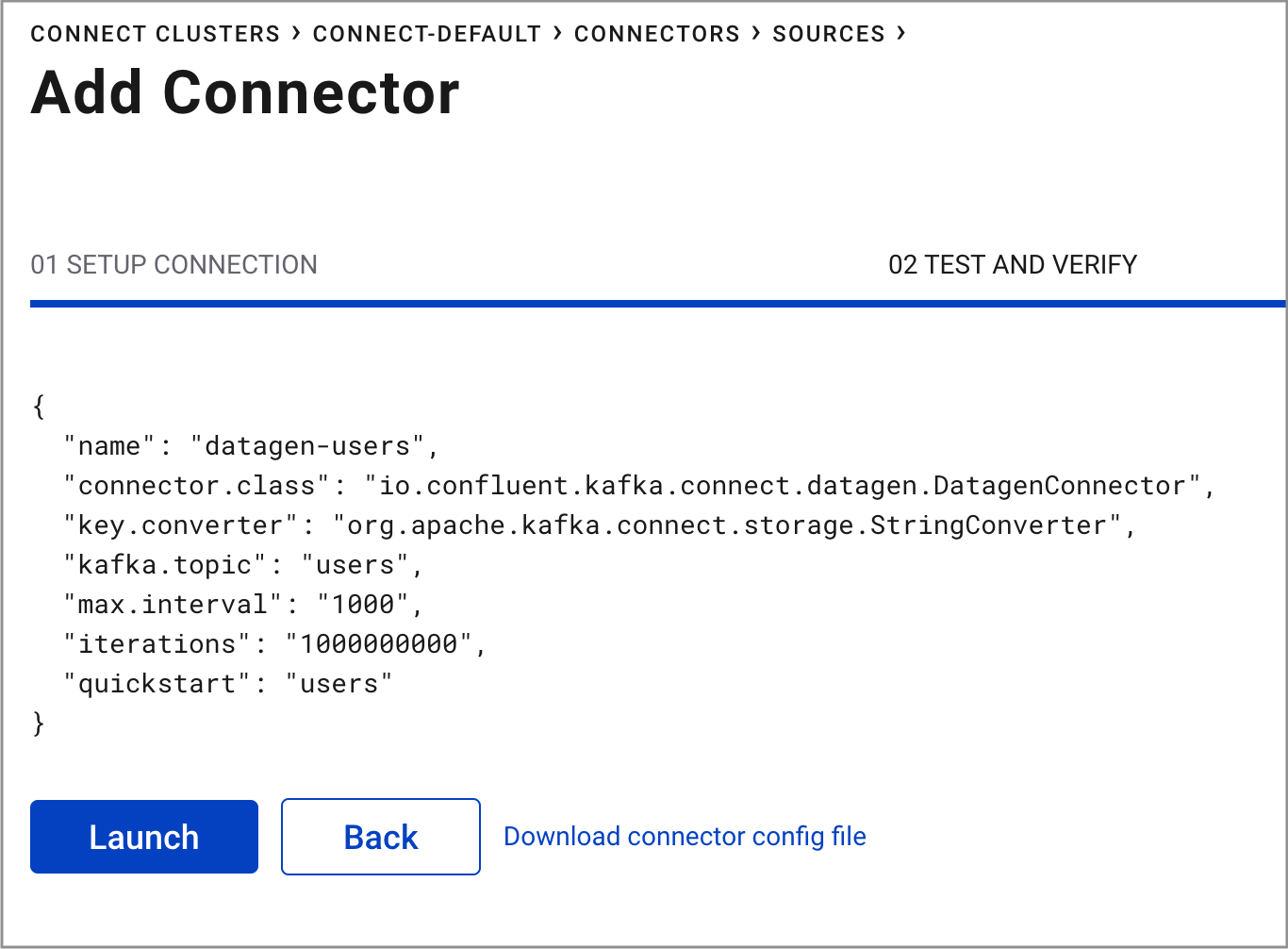
Click Continue.
Review the connector configuration and click Launch.
Step 4: Create and Write to a Stream and Table using KSQL¶
In this step, KSQL queries are run on the pageviews and users topics that were created in the previous step. The
KSQL commands are run using the KSQL tab in Control Center.
Tip
You can also run these commands using the KSQL CLI from your terminal
with this command: <path-to-confluent>/bin/ksql http://localhost:8088.
Create Streams and Tables¶
In this step, KSQL is used to create a stream for the pageviews topic, and a table for the users topic.
From your cluster, click KSQL and choose the KSQL application.
From the KSQL EDITOR page, click the Streams tab and Add Stream.
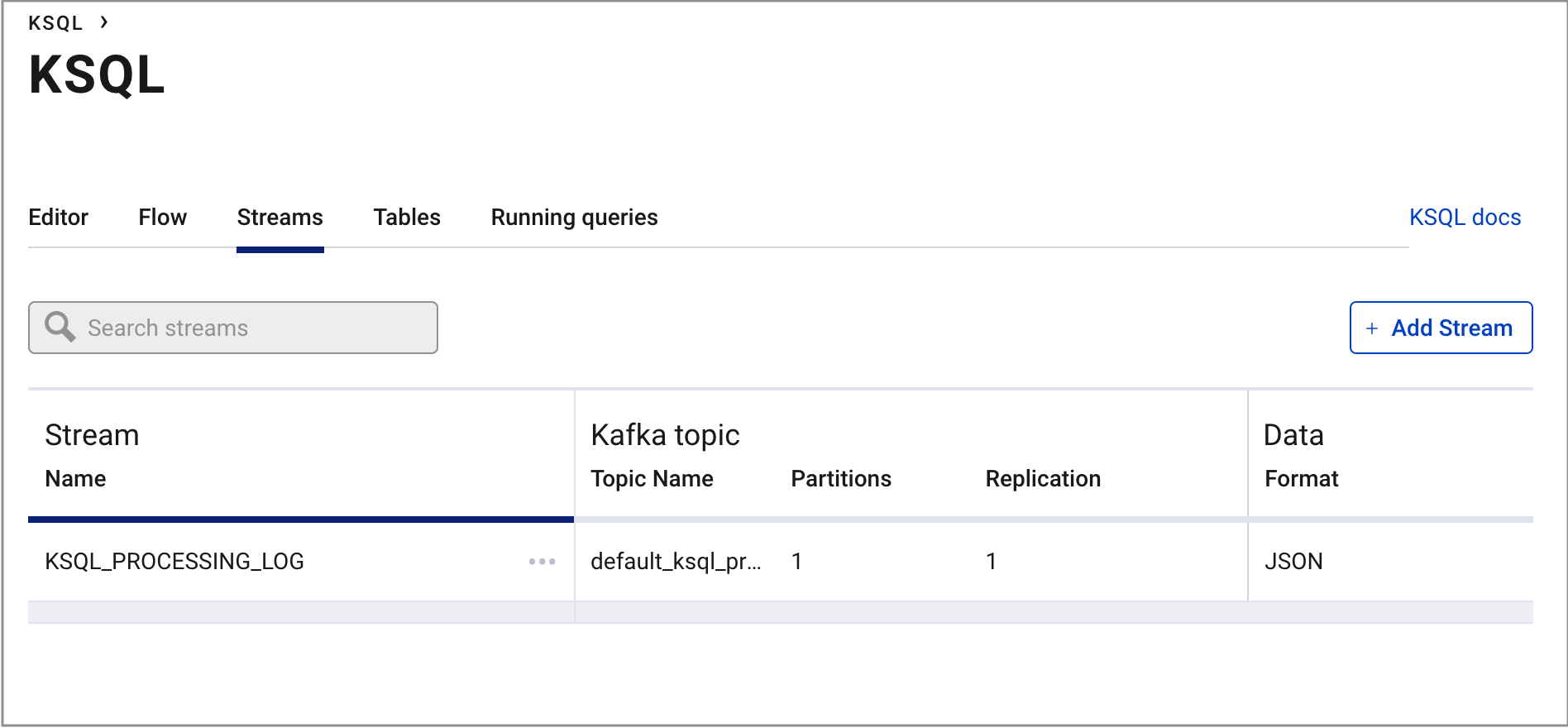
Select the
pageviewstopic.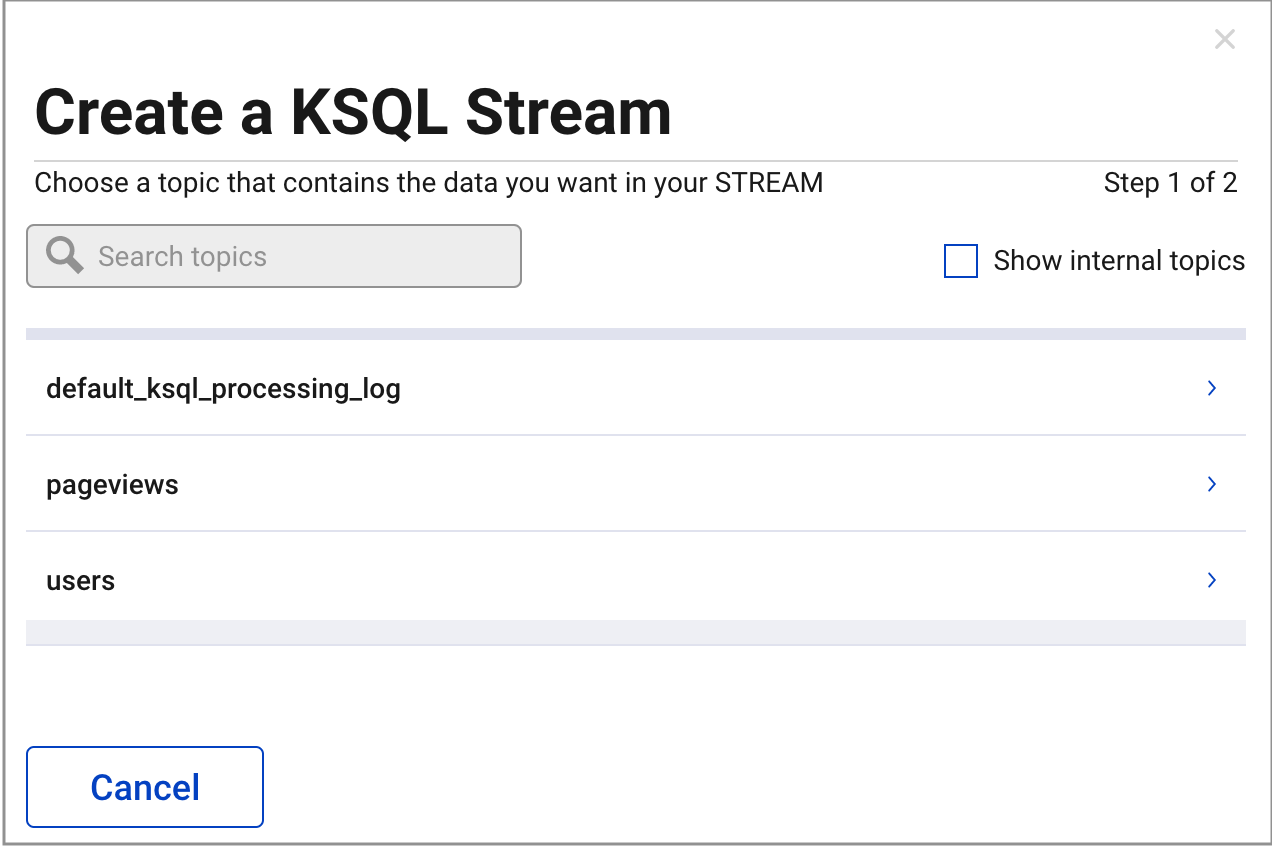
Choose your stream options:
- In the Encoding field, select
AVRO. - In the Field(s) you’d like to include in your STREAM field, ensure fields are set as follows:
viewtimewith typeBIGINTuseridwith typeVARCHARpageidwith typeVARCHAR
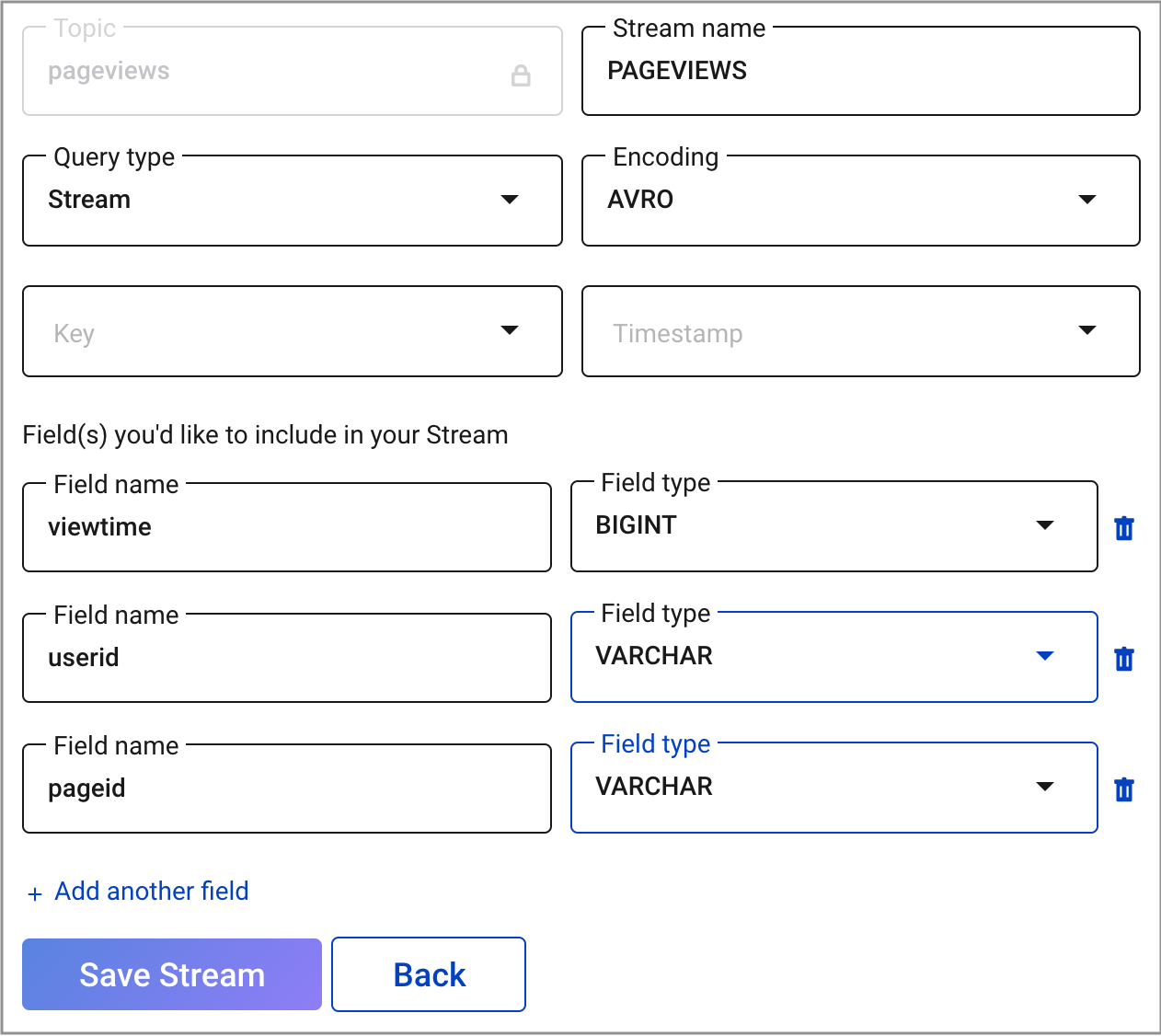
- In the Encoding field, select
Click Save Stream.
Click the Tables tab -> Add a Table and select the
userstopic.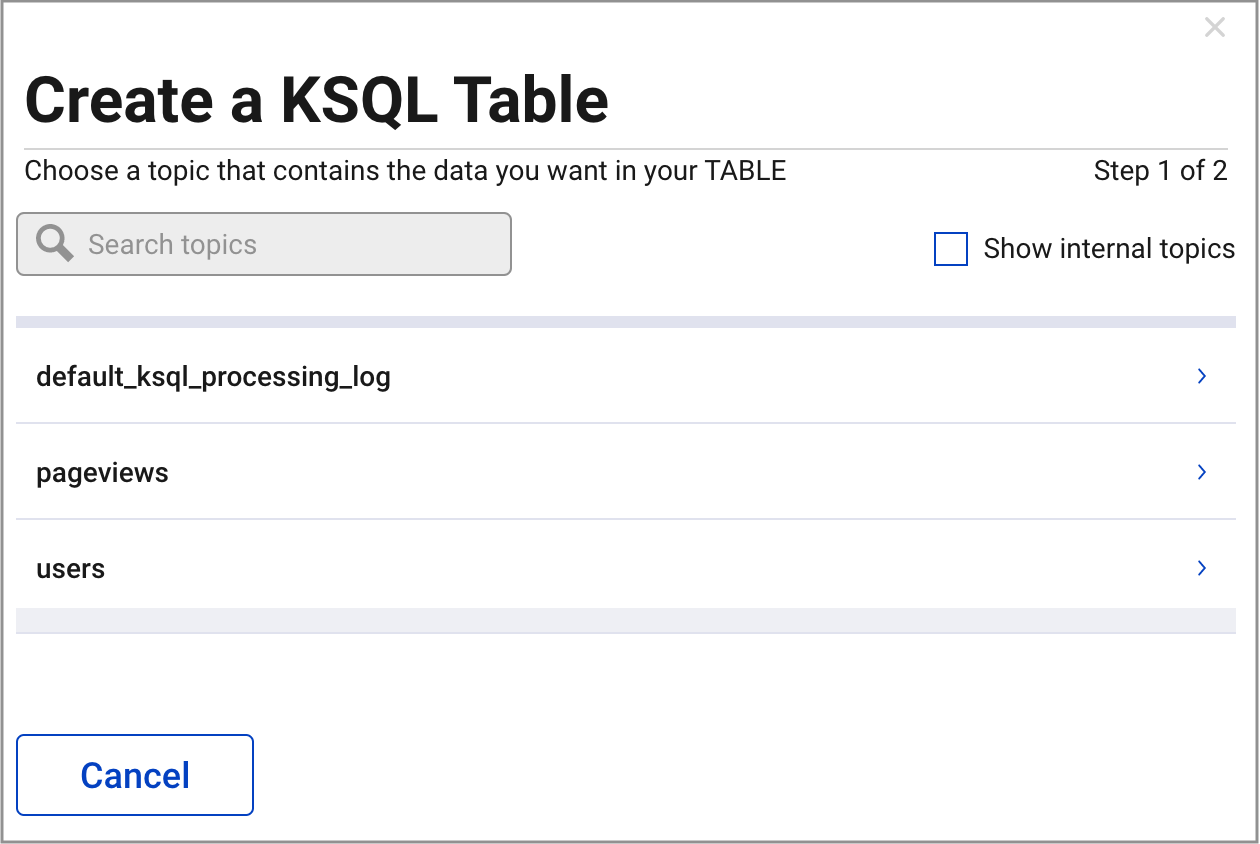
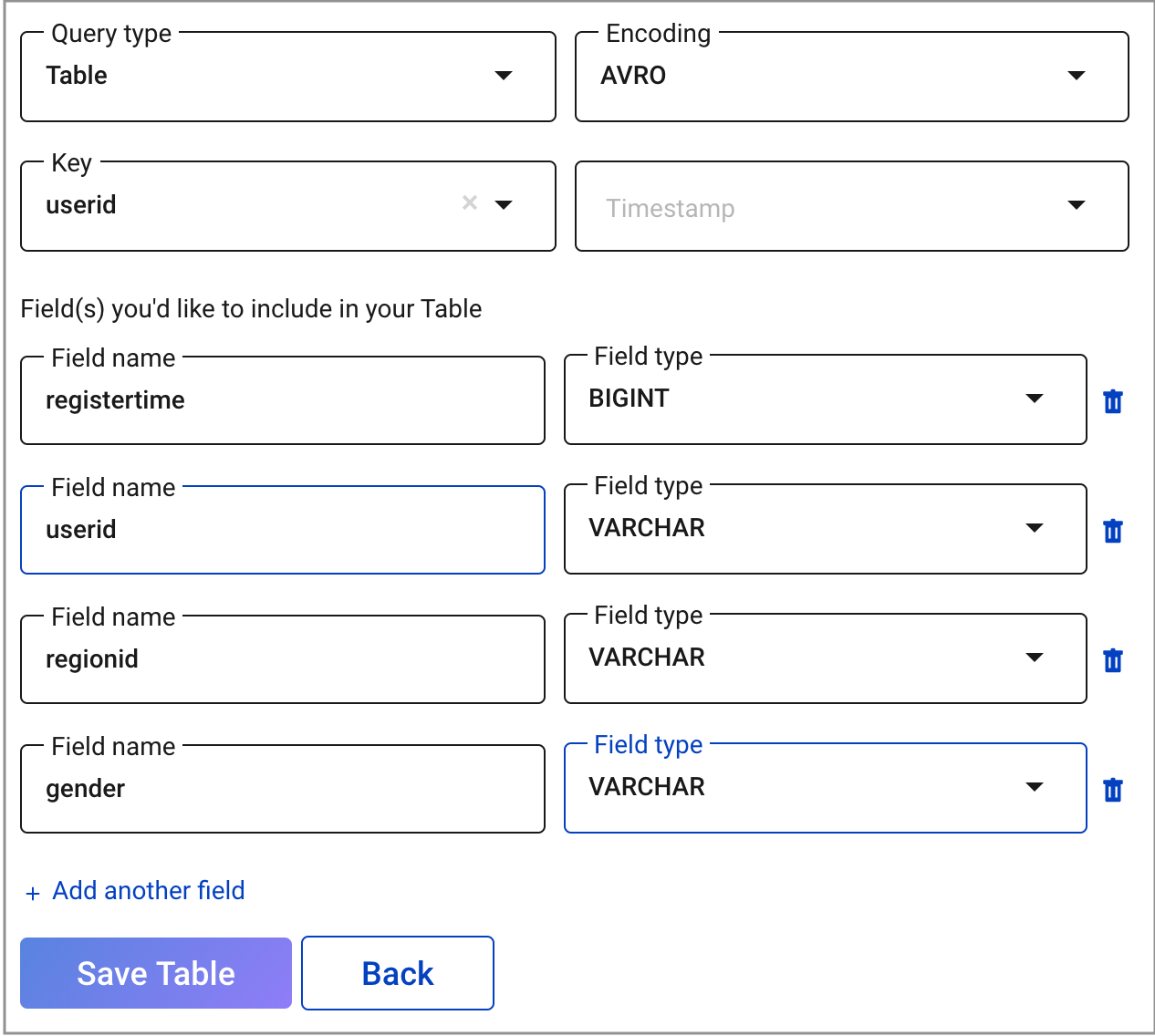
Choose your table options:
- In the Encoding field, select
AVRO. - In the Key field, select
userid. - In the Field(s) you’d like to include in your TABLE field, ensure fields are set as follows:
registertimewith typeBIGINTuseridwith typeVARCHARregionidwith typeVARCHARgenderwith typeVARCHAR
- In the Encoding field, select
Click Save Table.
Write Queries¶
These examples write queries using the KSQL tab in Control Center.
From your cluster, click KSQL and choose the Editor page.
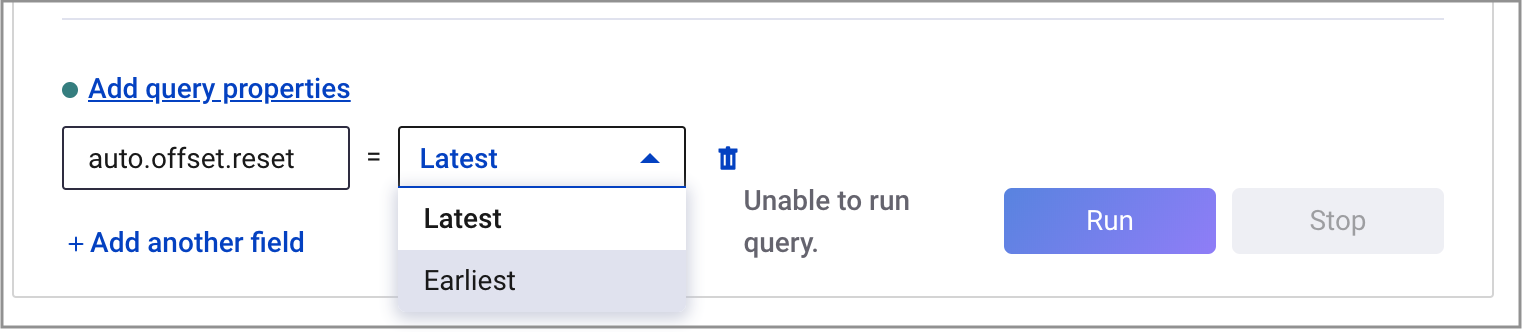
From the KSQL EDITOR page, click Add query properties to add a custom query property. Set the
auto.offset.resetparameter toearliest.This instructs KSQL queries to read all available topic data from the beginning. This configuration is used for each subsequent query. For more information, see the KSQL Configuration Parameter Reference.
Run the following queries.
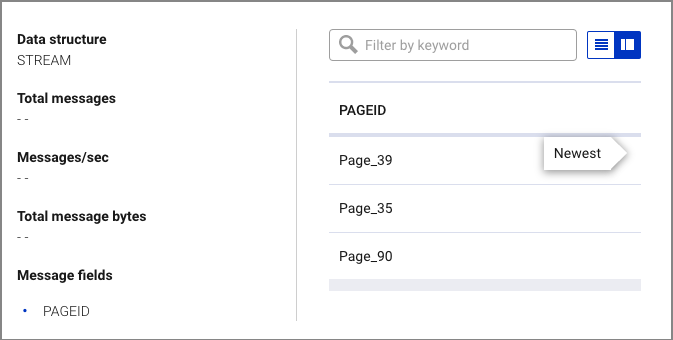
Create a non-persistent query that returns data from a stream with the results limited to a maximum of three rows.
SELECT pageid FROM pageviews EMIT CHANGES LIMIT 3;
Your output should resemble:
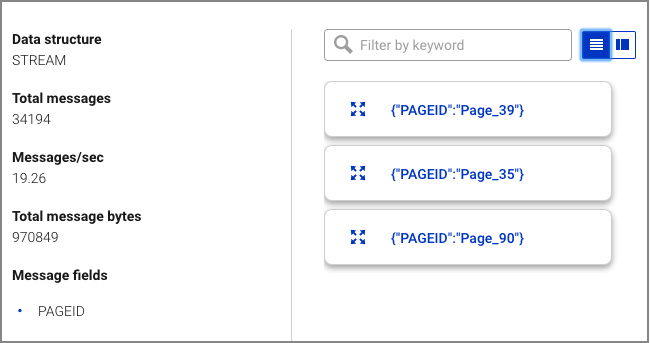
Tip
Click the Card view or Tabular view icon to change the layout. Click the expand icon to expand a message.
Create a persistent query that filters for female users. The results from this query are written to the Kafka
PAGEVIEWS_FEMALEtopic. This query enriches thepageviewsSTREAM by doing aLEFT JOINwith theusersTABLE on the user ID, where a condition (gender = 'FEMALE') is met.CREATE STREAM pageviews_female AS SELECT users.userid AS userid, pageid, regionid, gender FROM pageviews LEFT JOIN users ON pageviews.userid = users.userid WHERE gender = 'FEMALE';
Your output should resemble:

Create a persistent query where a condition (
regionid) is met, usingLIKE. Results from this query are written to a Kafka topic namedpageviews_enriched_r8_r9.CREATE STREAM pageviews_female_like_89 WITH (kafka_topic='pageviews_enriched_r8_r9', value_format='AVRO') AS SELECT * FROM pageviews_female WHERE regionid LIKE '%_8' OR regionid LIKE '%_9';
Your output should resemble:

Create a persistent query that counts the pageviews for each region and gender combination in a tumbling window of 30 seconds when the count is greater than 1. Because the procedure is grouping and counting, the result is now a table, rather than a stream. Results from this query are written to a Kafka topic called
PAGEVIEWS_REGIONS.CREATE TABLE pageviews_regions AS SELECT gender, regionid , COUNT(*) AS numusers FROM pageviews_female WINDOW TUMBLING (size 30 second) GROUP BY gender, regionid HAVING COUNT(*) > 1;
Your output should resemble:

Click Running queries. You should see the following persisted queries:
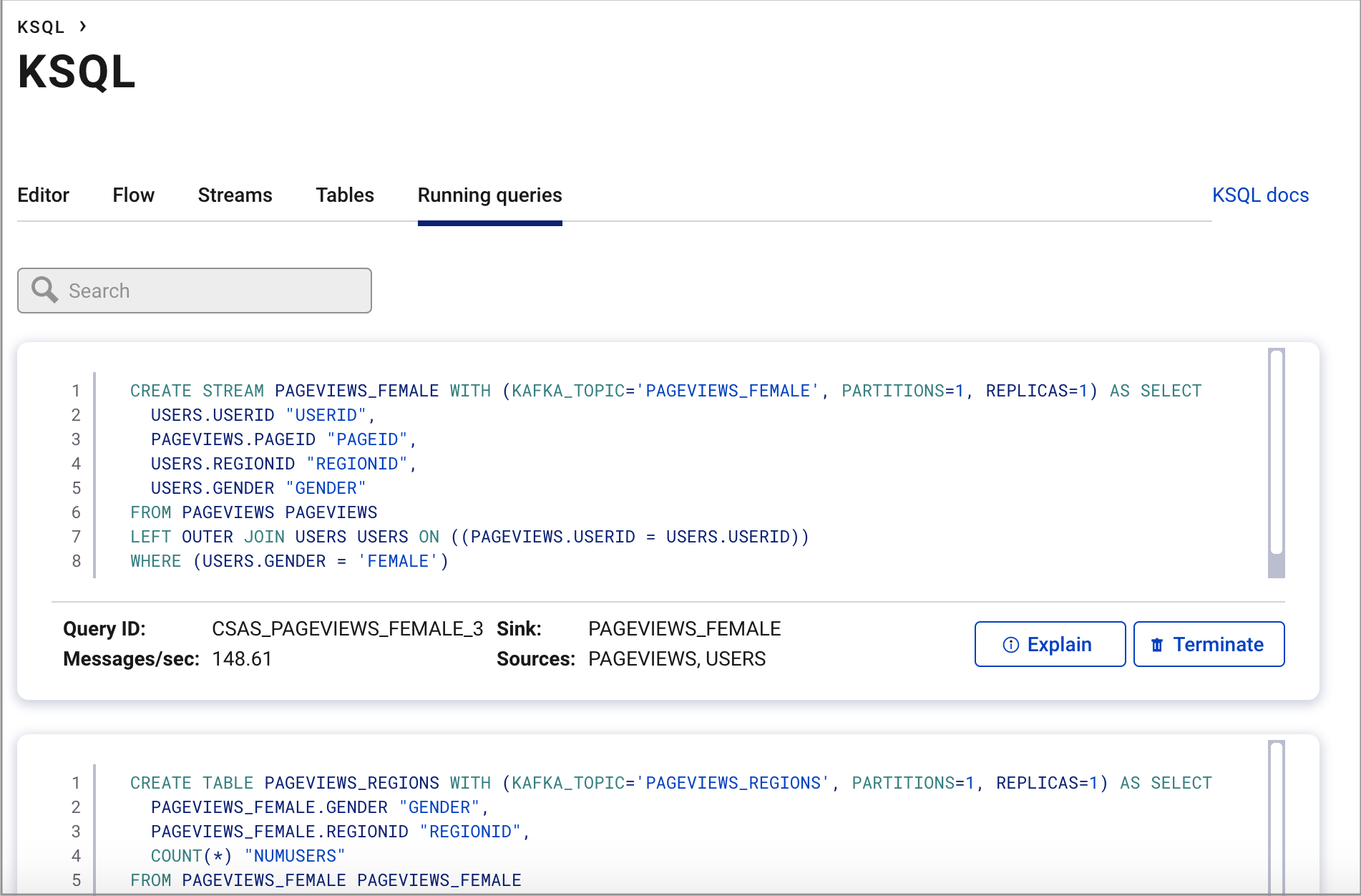
Click Editor. On the right side of the page, find the All available streams and tables pane, which shows all of the streams and tables that you can access.
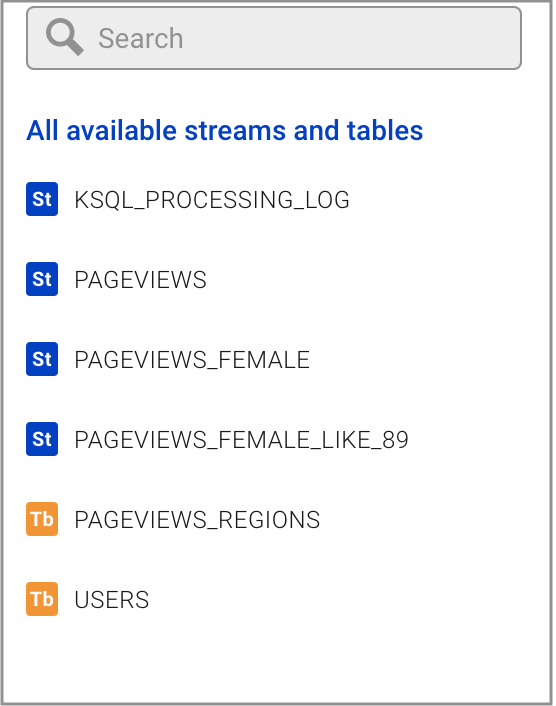
In the All available streams and tables section, click KSQL_PROCESSING_LOG to view the stream’s schema, including nested data structures.

Step 5: Monitor Consumer Lag¶
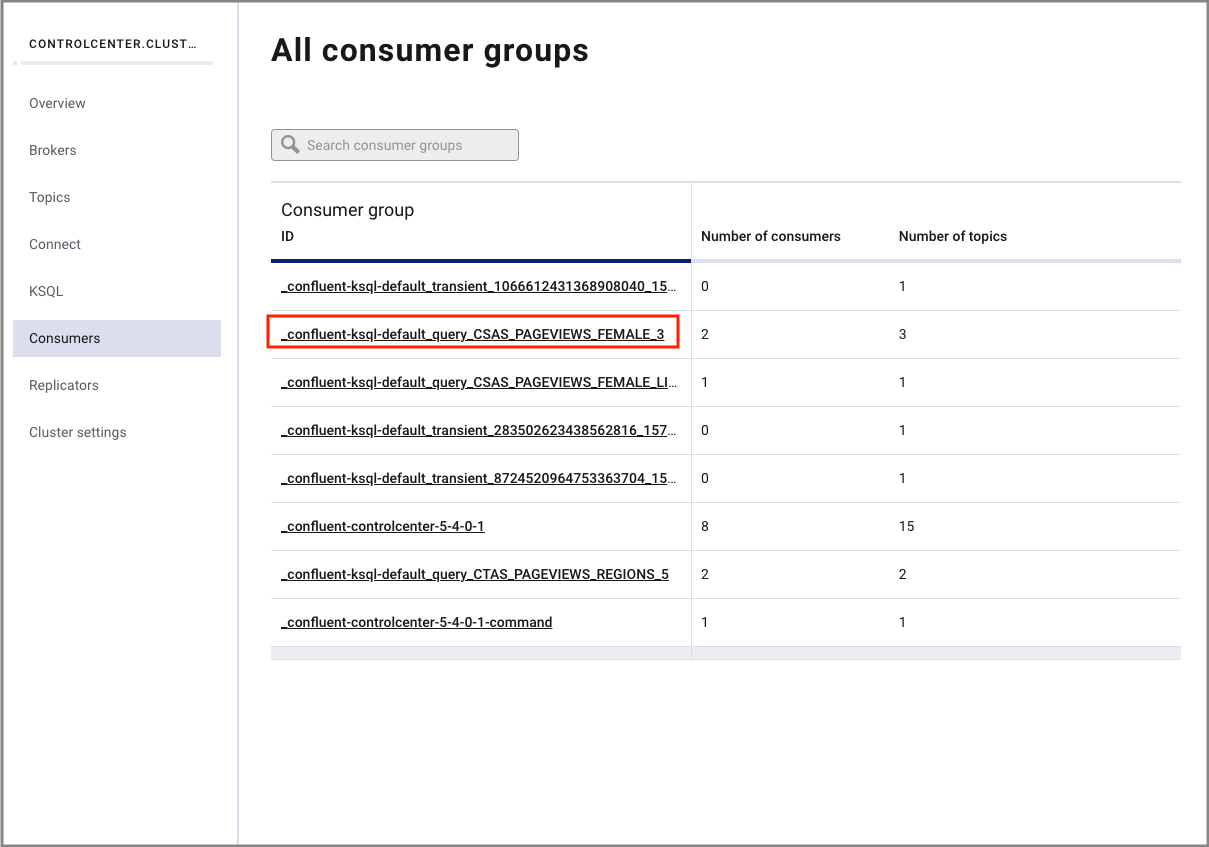
Navigate to the Consumers tab to view the consumers created by KSQL.
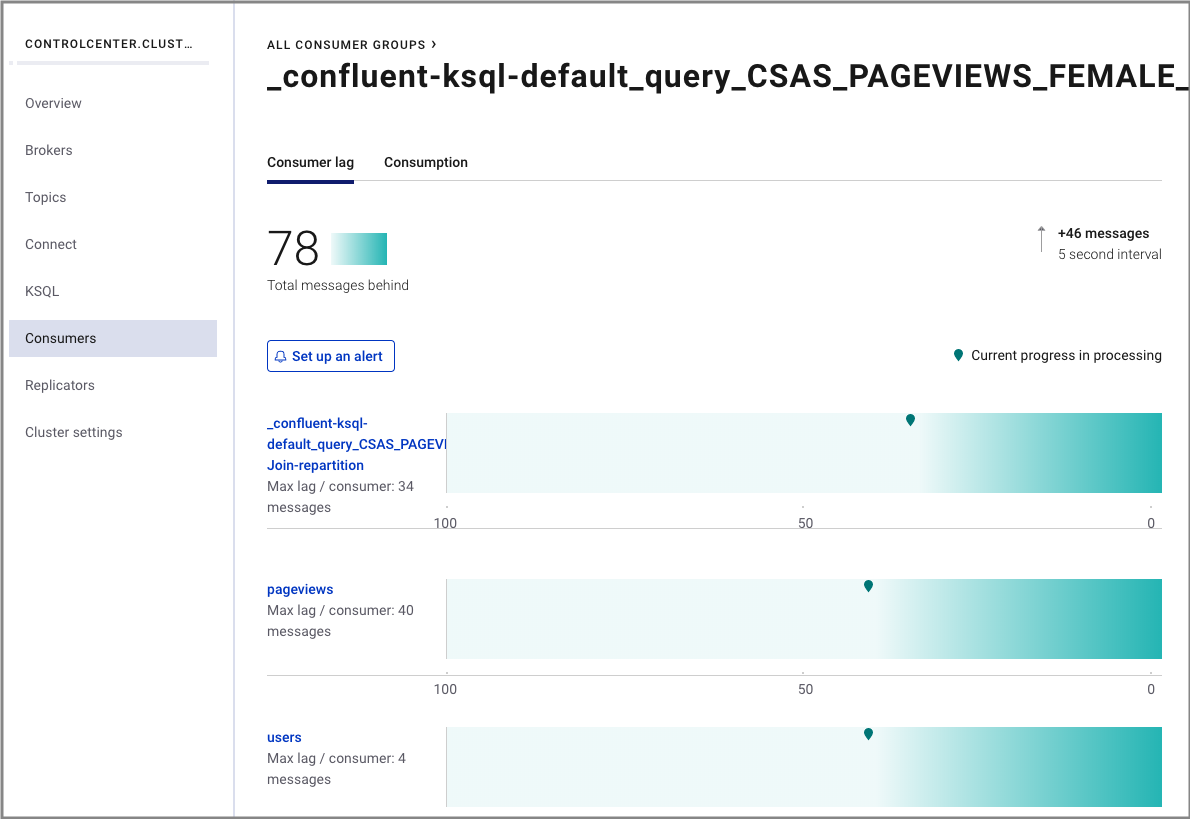
Click the consumer group ID to view details for the _confluent-ksql-default_query_CSAS_PAGEVIEWS_FEMALE_3 consumer group.
From this page you can see the consumer lag and consumption values for your streaming query.
For more information, see the Control Center Consumers documentation.
Step 6: Stop Confluent Platform¶
When you are done working with the local install, you can stop Confluent Platform.
Stop Confluent Platform using the Confluent CLI confluent local stop command.
<path-to-confluent>/bin/confluent local stop
Destroy the data in the Confluent Platform instance with the confluent local destroy command.
<path-to-confluent>/bin/confluent local destroy
You can start the local install of Confluent Platform again with the confluent local start command.
Troubleshooting¶
If you encountered any issues, review the following resolutions before trying the steps again.
Issue: Demo times out, some or all components do not start¶
You must allocate a minimum of 8 GB of Docker memory resource. The default memory allocation on Docker Desktop for Mac is 2 GB and must be changed. Confluent Platform demos and examples running on Docker may fail to work properly if Docker memory allocation does not meet this minimum requirement.
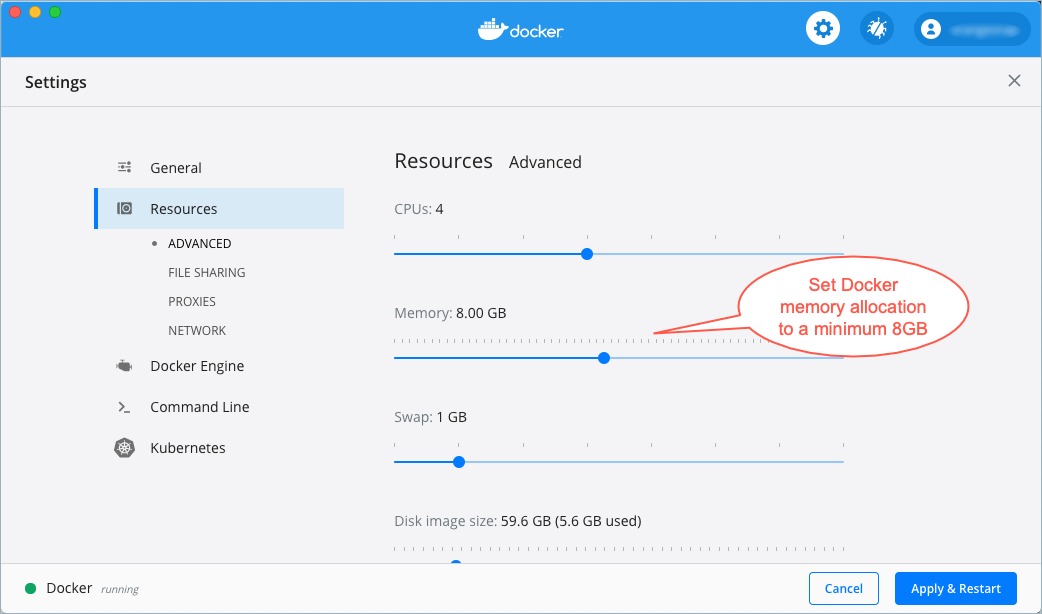
Memory settings on Docker preferences for resources
Issue: Cannot locate the Datagen Connector¶
Resolution: Verify that you have added the location of the Confluent Platform bin directory to your PATH
as described in Step 1: Download and Start Confluent Platform:
export PATH=<path-to-confluent>/bin:$PATH
Resolution: Verify the DataGen Connector is installed and running.
Ensure that the kafka-connect-datagen is installed and running as described in Step 1: Download and Start Confluent Platform.
<path-to-confluent>/bin/confluent-hub install --no-prompt confluentinc/kafka-connect-datagen:latest
Your output should resemble:
Running in a "--no-prompt" mode
...
Completed
Resolution: Check the connect logs for Datagen using the Confluent CLI confluent local log command.
<path-to-confluent>/bin/confluent local log connect | grep -i Datagen
Your output should resemble:
[2019-04-18 14:21:08,840] INFO Loading plugin from: /Users/user.name/Confluent/confluent-version/share/confluent-hub-components/confluentinc-kafka-connect-datagen (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader:215)
[2019-04-18 14:21:08,894] INFO Registered loader: PluginClassLoader{pluginLocation=file:/Users/user.name/Confluent/confluent-version/share/confluent-hub-components/confluentinc-kafka-connect-datagen/} (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader:238)
[2019-04-18 14:21:08,894] INFO Added plugin 'io.confluent.kafka.connect.datagen.DatagenConnector' (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader:167)
[2019-04-18 14:21:09,882] INFO Added aliases 'DatagenConnector' and 'Datagen' to plugin 'io.confluent.kafka.connect.datagen.DatagenConnector' (org.apache.kafka.connect.runtime.isolation.DelegatingClassLoader:386)
Resolution: Verify the .jar file for kafka-connect-datagen has been added and is present in the lib subfolder.
ls <path-to-confluent>/share/confluent-hub-components/confluentinc-kafka-connect-datagen/lib/
Your output should resemble:
...
kafka-connect-datagen-0.1.0.jar
...
Resolution: Verify the plugin exists in the connector path.
When you installed the kafka-connect-datagen file from Confluent hub, the installation directory
is added to the plugin path of several properties files:
Adding installation directory to plugin path in the following files:
/Users/user.name/Confluent/confluent-version/etc/kafka/connect-distributed.properties
/Users/user.name/Confluent/confluent-version/etc/kafka/connect-standalone.properties
/Users/user.name/Confluent/confluent-version/etc/schema-registry/connect-avro-distributed.properties
/Users/user.name/Confluent/confluent-version/etc/schema-registry/connect-avro-standalone.properties
...
You can use any of them to check the
connector path. This example uses the connect-avro-distributed.properties file.
grep plugin.path <path-to-confluent>/etc/schema-registry/connect-avro-distributed.properties
Your output should resemble:
plugin.path=share/java,/Users/user.name/Confluent/confluent-version/share/confluent-hub-components
Confirm its contents are present:
ls <path-to-confluent>/share/confluent-hub-components/confluentinc-kafka-connect-datagen
Your output should resemble:
assets doc lib manifest.json
Resolution: In Kafka Connect > Setup Connection, scroll down through the list of connectors to locate DatagenConnector; there are multiple connectors in the menu.
Issue: Stream-Stream joins error¶
An error states Stream-Stream joins must have a WITHIN clause specified. This error can occur if you created streams
for both pageviews and users by mistake.
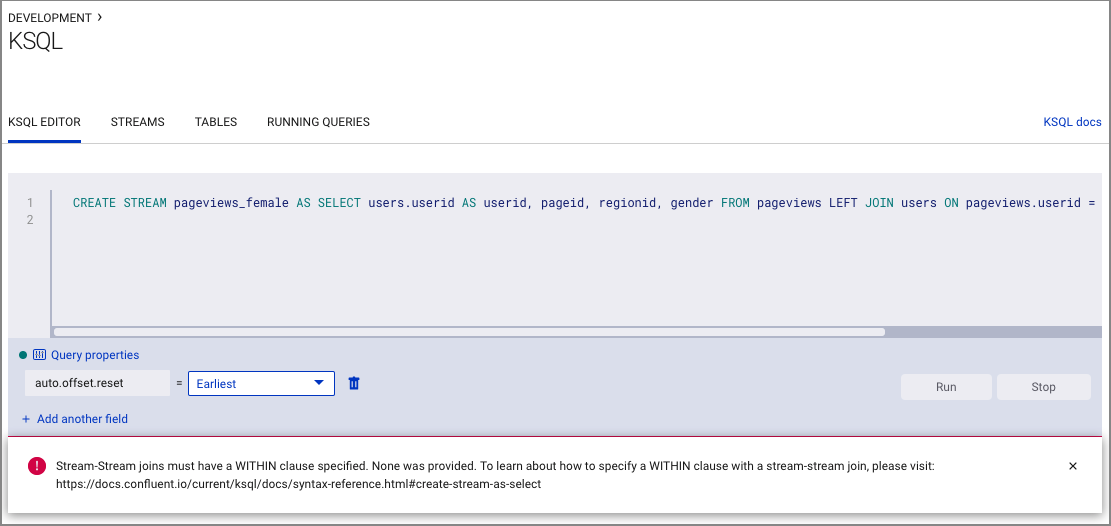
Resolution: Ensure that you created a stream for pageviews, and a table for users in Step 4: Create and Write to a Stream and Table using KSQL.
Issue: Unable to successfully complete KSQL query steps¶
Java errors or other severe errors were encountered.
Resolution: Ensure you are on an Operating System currently supported by Confluent Platform.
Next Steps¶
Learn more about the components shown in this quick start:
- KSQL documentation Learn about processing your data with KSQL for use cases such as streaming ETL, real-time monitoring, and anomaly detection. You can also learn how to use KSQL with this collection of scripted demos.
- Stream Processing Cookbook Try out in-depth KSQL tutorials and recommended deployment scenarios.
- Kafka Streams documentation Learn how to build stream processing applications in Java or Scala.
- Kafka Connect documentation Learn how to integrate Kafka with other systems and download ready-to-use connectors to easily ingest data in and out of Kafka in real-time.
- Kafka Clients documentation Learn how to read and write data to and from Kafka using programming languages such as Go, Python, .NET, C/C++.
- Videos, Demos, and Reading Material Try out the Confluent Platform tutorials and examples, watch demos and screencasts, and learn with white papers and blogs.