
Read and Write Custom Changelog Formats in Confluent Cloud for Apache Flink
A changelog is a stream of row-level changes, where each record says whether a row was created, updated, or deleted. Change data capture (CDC) tools such as Debezium produce changelogs in a standard format that Confluent Cloud for Apache Flink® understands. Many systems use their own custom format, where the change operation is carried in a field you define, for example an op field set to c, u, or d. Flink doesn’t recognize that field on its own.
This guide shows how to bridge that gap with two built-in process table functions (PTFs), FROM_CHANGELOG and TO_CHANGELOG. FROM_CHANGELOG reads a custom changelog into a Flink table you can query. TO_CHANGELOG does the reverse: it turns a Flink table back into a custom changelog that another system can consume. A process table function takes a table as input and returns a table as output. These two are built-in, so you call them directly in Flink SQL with no code to write or deploy. If you want to build your own PTF, which is an Open Preview feature, see Process Table Functions and Create a Process Table Function.
Note
In these function names, changelog refers to a stream where each record states its own change operation in a field, for example op = c for a create or op = d for a delete. This is the kind of stream a CDC tool produces. It is different from Flink’s internal changelog, the +I, -U, +U, and -D markers that Flink manages for you behind the scenes. FROM_CHANGELOG and TO_CHANGELOG translate between the two. For the underlying concept, see The internal changelog versus a changelog you own.
When would you use these functions?
Reading change data that arrives in a custom format. A CDC connector other than Debezium, or a custom event envelope, puts the operation in its own field instead of using Flink’s row kinds.
FROM_CHANGELOGreads that stream and turns it into a table you can query, join, and aggregate. Typical cases are ingesting a non-Debezium CDC source or fanning a custom lifecycle-event topic into per-entity tables.Producing change events for a non-|af| consumer. A microservice, a Connect sink, or a compacted topic expects an explicit operation on each record, or a tombstone on delete, not Flink’s internal
-Uand+Urecords.TO_CHANGELOGturns your updating table into an append-only stream the consumer can act on.
The round trip at a glance
The following diagram follows a small batch of order events all the way through Flink: in from a custom changelog, through a query, and back out as a custom changelog.

The round trip: FROM_CHANGELOG reads a custom changelog in, a query processes it, and TO_CHANGELOG writes a custom changelog back out.
A few terms appear in every step. They are described as follows:
Operation code (or op code): a field in each record that states what happened to the row, for example
cfor create,ufor update, anddfor delete. You choose these values. They are whatever your source system uses.Row kind: the marker Flink puts on each change internally, one of four:
+I(insert),-Uand+U(the before and after images of an update), and-D(delete).Append-only stream: a stream where every record is a brand-new insert. Nothing that already arrived is changed or removed.
Updating table: a table whose rows can change or be deleted after they first appear, such as the result of an aggregation.
Step through the diagram:
The
raw_orderstopic holds your custom changelog. To Flink every record looks like an insert; the real intent is in theopfield.FROM_CHANGELOGreadsopand converts each record into the matching row kind, producing theorderstable. Order103is created and then deleted, so it appears as+Iand later-D.A query aggregates the orders into a count per region. Because the count changes over time, the result is an updating table.
TO_CHANGELOGconverts the updating result back into explicit op codes.The
orders_outtopic holds the resulting custom changelog, ready for a downstream consumer.
The next sections walk through each function with its own example.
Read a custom changelog with FROM_CHANGELOG
FROM_CHANGELOG reads an append-only stream that carries an operation code and turns it into an updating table, mapping each code to a Flink row kind.
Suppose a single order is created, has its amount updated from 100 to 150, and is then deleted. Your source records this in a custom format where c is a create, ub and ua are the before and after of an update, and d is a delete. FROM_CHANGELOG maps each op code to a Flink row kind.
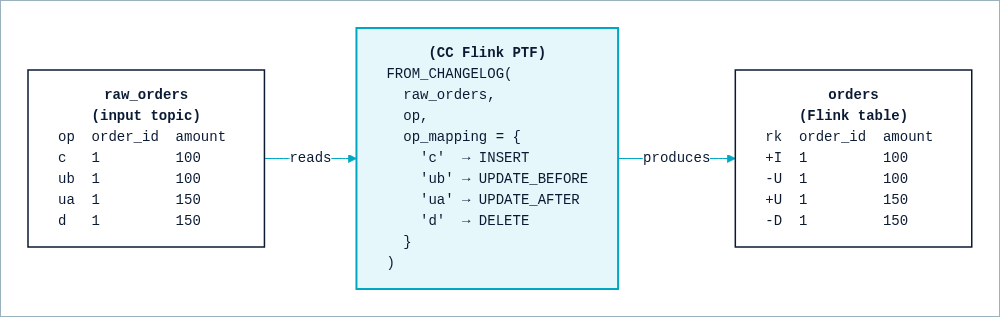
FROM_CHANGELOG interprets your op codes as Flink row kinds.
You declare that mapping with the op_mapping parameter:
SELECT * FROM FROM_CHANGELOG(
input => TABLE raw_orders,
op => DESCRIPTOR(op),
op_mapping => MAP[
'c', 'INSERT',
'ub', 'UPDATE_BEFORE',
'ua', 'UPDATE_AFTER',
'd', 'DELETE'
]
);
The op parameter names the field that holds the operation code, and op_mapping says how each of your codes maps to a row kind. The result is the orders table: the create becomes +I, the update becomes the -U / +U pair, and the delete becomes -D. Flink now treats orders as a real updating table. If you query it, the row for order 1 collapses to nothing, because it was created, updated, and then deleted.
When you reconstruct updates or handle deletes, route every event for the same key to the same task with PARTITION BY, so that the changes are applied in order.
Because this example maps both UPDATE_BEFORE and UPDATE_AFTER, the result is a retract stream, where every update is a pair of records. If your source only ever sends the new value of a row, map it to UPDATE_AFTER alone. The result is then an upsert stream, which is more compact but requires a primary key so that Flink knows which row each update replaces.
The function doesn’t change raw_orders or create anything by itself. It produces a table as the result of the query, which you can read, join, or write to a sink. To persist the result as a new table and its backing Apache Kafka® topic, wrap the query in a CREATE TABLE ... AS SELECT:
CREATE TABLE orders AS
SELECT * FROM FROM_CHANGELOG(
input => TABLE raw_orders,
op => DESCRIPTOR(op),
op_mapping => MAP[
'c', 'INSERT',
'ub', 'UPDATE_BEFORE',
'ua', 'UPDATE_AFTER',
'd', 'DELETE'
]
);
Any Flink statement that reads the new orders table sees the same row kinds.
Query the result and why it keeps updating
After you have a table, you query it like any other. A query that only filters or transforms an append-only stream stays append-only, because each input row maps to at most one output row that never changes afterward. An aggregation or a join is different: it has to revise an answer it already gave.
Take the count of orders per region from the round-trip diagram:
SELECT region, COUNT(*) AS cnt
FROM orders
GROUP BY region;
When the first EU order arrives, Flink emits +I (EU, 1). When a second EU order arrives, the count for EU is no longer 1, so Flink revises the earlier answer: it emits +U (EU, 2) (in a retract stream, preceded by -U (EU,1)). When the EU order is later deleted, the count drops back and Flink emits +U (EU, 1). The result is an updating table, even though the input was append-only. This is why a downstream system that expects plain inserts can’t read the result directly, and why you need TO_CHANGELOG to hand it off.
Write a custom changelog with TO_CHANGELOG
TO_CHANGELOG turns an updating table into a plain append stream where each change carries an explicit op code the consumer can act on. Consider the reverse direction: you have orders_per_region, the updating result of the aggregation, and you want to publish it to a topic for a consumer that doesn’t understand Flink’s internal -U and +U records and would read them as duplicates.
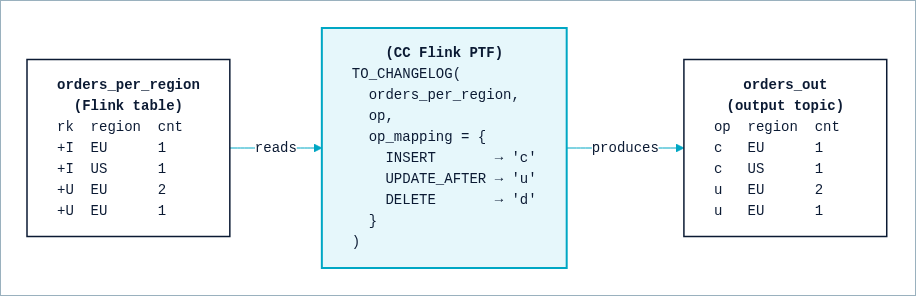
TO_CHANGELOG stamps each change with the op code your sink expects.
The mapping runs the other way: each row kind maps to an output op code.
SELECT * FROM TO_CHANGELOG(
input => TABLE orders_per_region,
op => DESCRIPTOR(op),
op_mapping => MAP[
'INSERT', 'c',
'UPDATE_AFTER', 'u',
'DELETE', 'd'
]
);
Each change in orders_per_region becomes one append record on the output topic, carrying the op code in the op column. The consumer reads a clean sequence of creates and updates instead of Flink’s internal row kinds.
Example: custom CDC to a compacted topic with tombstones
A common end-to-end pattern brings both directions together. You receive lifecycle events for an entity in a custom envelope, where the operation is a type field such as Customer.Invitation.Created, and you want to write each entity to its own compacted topic, with a tombstone on delete. A tombstone is a record with a key and a null value, which tells a compacted topic that the key is deleted.

Map the type values to row kinds, and the tombstone falls out naturally on delete.
Map each type value to a row kind, and write the result to the compacted topic:
INSERT INTO customer_invitations
SELECT id, email
FROM FROM_CHANGELOG(
input => TABLE raw_events PARTITION BY id,
op => DESCRIPTOR(event_type),
op_mapping => MAP[
'Customer.Invitation.Created', 'INSERT',
'Customer.Invitation.Updated', 'UPDATE_AFTER',
'Customer.Invitation.Deleted', 'DELETE'
]
)
WHERE event_type LIKE 'Customer.Invitation.%';
When the input carries a Customer.Invitation.Deleted event, Flink emits a -D for that key, and the compacted sink writes a tombstone. You don’t write the null value yourself; it follows from mapping the delete to the DELETE row kind.
Important
FROM_CHANGELOG is an advanced feature. When you use it, you tell Flink that your stream is a valid changelog, and Flink doesn’t validate that claim. An incorrect changelog can produce silently wrong results downstream and, in the worst case, leave a statement in an unrecoverable state. When the data handed to FROM_CHANGELOG isn’t the shape the function expects, it becomes hard to diagnose what actually went wrong, so Confluent is only able to provide limited support for statements that contain FROM_CHANGELOG.
To stay correct, make sure that every update and delete refers to a key you have already inserted, you map all of your operation codes so no changes are dropped, events for the same key stay in order, and your key is unique per row.
Limitations
These functions work on flat records with a direct one-to-one operation mapping, where each input record maps to a single row kind. A single message that carries both the before and after image of a row isn’t supported.