
Stream Processing with Confluent Cloud for Apache Flink
Confluent Cloud for Apache Flink provides fully managed, serverless stream processing on Confluent Cloud. Filter, join, enrich, and transform your Apache Kafka® data streams in real time without managing infrastructure. Built on Apache Flink, the industry standard for stateful stream processing, Confluent Cloud for Apache Flink handles provisioning, autoscaling, and fault tolerance so you can focus on your stream processing logic.
Get Started for Free
Sign up for a Confluent Cloud trial and get $400 of free credit.
Your Kafka topics appear automatically as queryable Flink tables, with schemas and metadata attached by Confluent Cloud. You can start processing data immediately by using Flink SQL, the Flink Table API (Java and Python), or custom user-defined functions. Confluent Cloud for Apache Flink integrates with Schema Registry, Connectors, and Tableflow to provide a complete data streaming platform.
Tip
Use Confluent MCP servers and agent skills to manage Confluent Cloud resources and build streaming applications from Claude Code and other AI assistants. For more information, see Use AI Tools with Confluent Cloud.
To run Flink on-premises with Confluent Platform, see Confluent Platform for Apache Flink.
What is Confluent Cloud for Apache Flink?
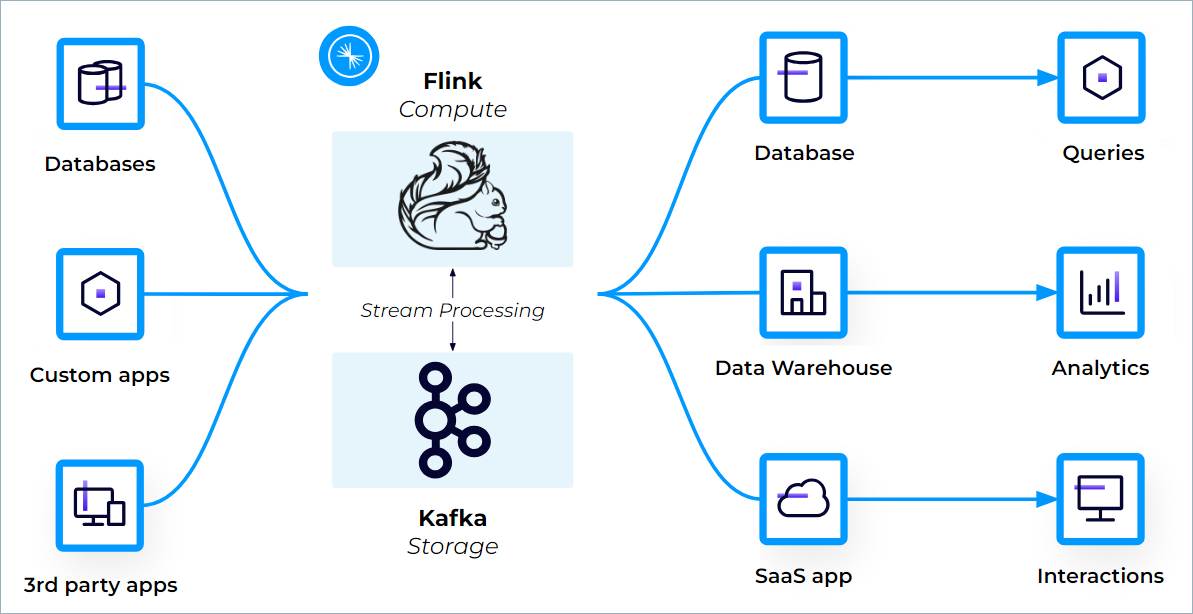
Confluent Cloud for Apache Flink integrates with the Kafka ecosystem
Confluent Cloud for Apache Flink is Flink re-imagined as a truly cloud-native service. Confluent’s fully managed Flink service enables you to:
Easily filter, join, and enrich your data streams with Flink
Enable high-performance and efficient stream processing at any scale, without the complexities of managing infrastructure
Experience Kafka and Flink as a unified platform, with fully integrated monitoring, security, and governance
When bringing Flink to Confluent Cloud, the goal was to provide a uniquely serverless experience superior to just “cloud-hosted” Flink. Kafka on Confluent Cloud goes beyond Kafka by using the Kora engine, which showcases Confluent’s engineering expertise in building cloud-native data systems. Confluent’s goal is to deliver the same simplicity, security, and scalability for Flink that you expect for Kafka.
Confluent Cloud for Apache Flink is engineered to be:
Cloud-native: Flink is fully managed on Confluent Cloud and autoscales up and down with your workloads.
Enterprise-ready: Flink is integrated deeply with Confluent Cloud to provide an enterprise-ready experience.
Everywhere: Flink is available in AWS, Azure, and Google Cloud.
Get started with Confluent Cloud for Apache Flink:
Confluent Cloud for Apache Flink is cloud-native
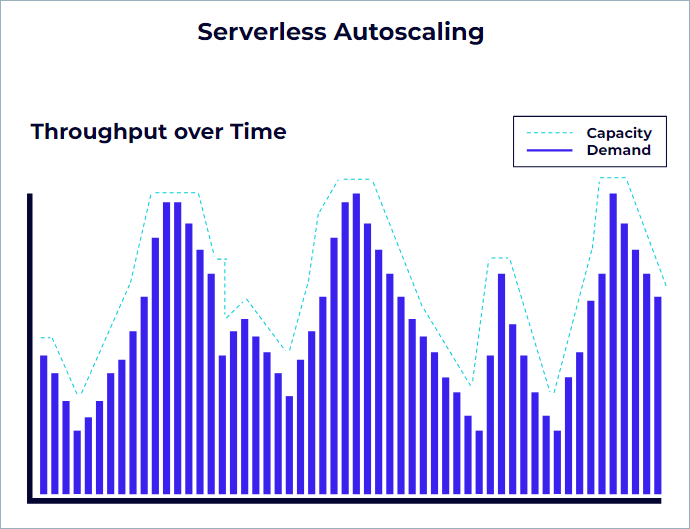
Confluent Cloud for Apache Flink autoscales with your workloads
Confluent Cloud for Apache Flink provides a cloud-native experience for Flink. This means you can focus fully on your business logic, encapsulated in Flink SQL statements, and Confluent Cloud takes care of what’s needed to run them in a secure, resource-efficient and fault-tolerant manner. You don’t need to know about or interact with Flink clusters, state backends, checkpointing, or any of the other aspects that are usually involved when operating a production-ready Flink deployment.
- Fully Managed
On Confluent Cloud, you don’t need to choose a runtime version of Flink. You’re always using the latest version and benefit from continuous improvements and innovations. All of your running statements automatically and transparently receive security patches and minor upgrades of the Flink runtime.
- Autoscaling
All of your Flink SQL statements on Confluent Cloud are monitored continuously and auto-scaled to keep up with the rate of their input topics. The resources required by a statement depend on its complexity and the throughput of topics it reads from.
- Usage-based billing
You pay only for what you use, not what you provision. Flink compute in Confluent Cloud is elastic: once you stop using the compute resources, they are deallocated, and you no longer pay for them. Coupled with the elasticity provided by scale-to-zero, you can benefit from unbounded scalability while maintaining cost efficiency. For more information, see Billing.
Confluent Cloud for Apache Flink is enterprise-ready

Confluent Cloud for Apache Flink is a unified platform
Confluent has integrated Flink deeply with Confluent Cloud to provide an enterprise-ready experience that enables data discovery and processing using familiar SQL semantics. Confluent Cloud for Apache Flink includes integrated monitoring, role-based access control, and private networking for production workloads.
Confluent Cloud for Apache Flink is a regional service
Confluent Cloud for Apache Flink is a regional service. When you run a Flink SQL statement, Confluent Cloud for Apache Flink automatically uses a default compute pool in your environment and region. Compute pools represent a set of resources that scale automatically between zero and their maximum size to provide all of the power required by your statements. A compute pool is bound to a region, and the resources provided by a compute pool are shared among all statements that use them.
For advanced use cases like workload isolation or cost control, you can create compute pools manually. See Compute Pools in Confluent Cloud for Apache Flink for more information.
You can query data in any topic in your Confluent Cloud organization, even if the data is in a different environment, as long as it’s in the same region. This enables Flink to do cross-cluster, cross-environment queries while providing low latency. Of course, access control with RBAC still determines the data that can be read or written.
Flink can read from and write to any Kafka cluster in the same region, but by design, Confluent Cloud doesn’t allow you to query across regions. This helps you to avoid expensive data transfer charges, and also protects data locality and sovereignty by keeping reads and writes in-region.
For a list of available regions, see Supported Cloud Regions.
Metadata mapping between Kafka cluster, topics, schemas, and Flink
Kafka topics and schemas are always in sync with Flink, simplifying how you can process your data. Any topic created in Kafka is visible directly as a table in Flink, and any table created in Flink is visible as a topic in Kafka. Effectively, Flink provides a SQL interface on top of Confluent Cloud.
Because Flink follows the SQL standard, the terminology is slightly different from Kafka. The following table shows the mapping between Kafka and Flink terminology.
Kafka | Flink | Notes |
|---|---|---|
Environment | Catalog | Flink can query and join data that are in any environments/catalogs |
Cluster | Database | Flink can query and join data that are in different clusters/databases |
Topic + Schema | Table | Kafka topics and Flink tables are always in sync. You never need to declare tables manually for existing topics. Creating a table in Flink creates a topic and the associated schema. |
As a result, when you start using Flink, you can directly access all of the environments, clusters, and topics that you already have in Confluent Cloud, without any additional metadata creation.
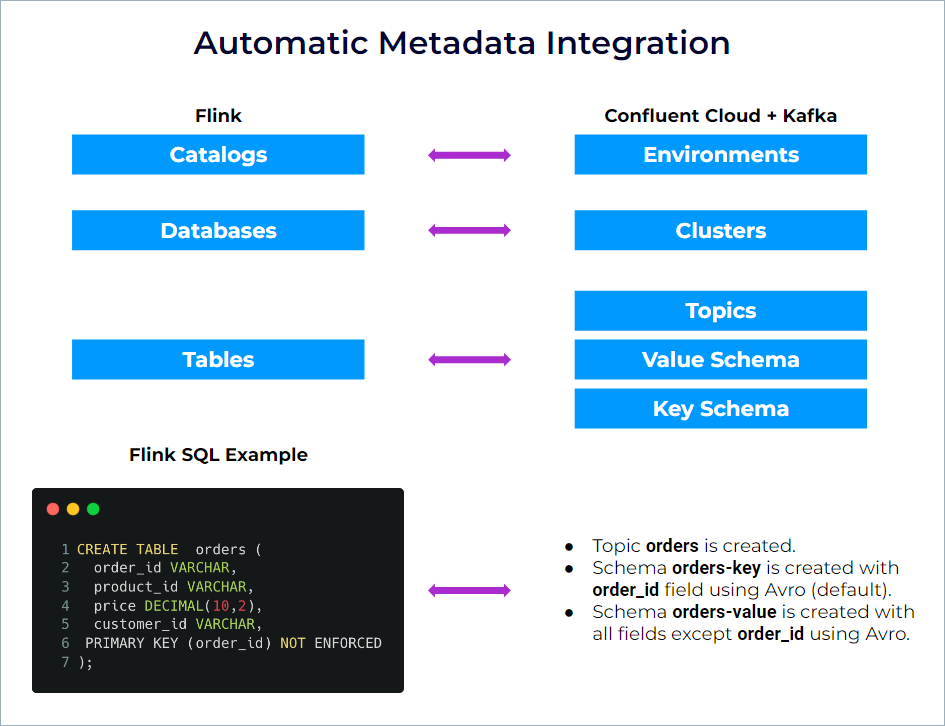
Automatic metadata integration in Confluent Cloud for Apache Flink
Compared with Apache Flink, the main difference is that the Data Definition Language (DDL) statements related to catalogs, databases, and tables act on physical objects and not only on metadata. For example, when you create a table in Flink, the corresponding topic and schema are created immediately in Confluent Cloud.
Confluent Cloud provides a unified approach to metadata management. There is one object definition, and Flink integrates directly with this definition, avoiding unnecessary duplication of metadata and making all topics immediately queryable with Flink SQL. Also, any existing schemas in Schema Registry are used to surface fully-defined entities in Confluent Cloud. If you’re already on Confluent Cloud, you see tables automatically that are ready to query using Flink, simplifying data discovery and exploration.
Observability
Confluent Cloud provides you with a curated set of metrics, exposing them through Confluent’s existing Metrics API. If you have established observability platforms in place, Confluent Cloud provides first-class integrations with New Relic, Datadog, Grafana Cloud, and Dynatrace.
You can also monitor workloads directly within the Confluent Cloud Console. Clicking into a compute pool gives you insight into the health and performance of your applications, in addition to the resource consumption of your compute pool.
Security
Confluent Cloud for Apache Flink has a deep integration with Role-Based Access Control (RBAC), ensuring that you can easily access and process the data that you have access to, and no other data.
Access from Flink to the data
For ad-hoc queries, you can use your user account, because the permissions of the current user are applied automatically without any additional setting needed.
For long-running statements that need to run 24/7, like INSERT INTO, you should use a service account, so the statements are not affected by a user leaving the company or changing teams.
Access to Flink
To manage Flink access, Confluent has introduced two roles. In both cases, RBAC of the user on the underlying data is still applied.
FlinkDeveloper: Granted by default to all users. Enables querying data and managing their own statements.
FlinkAdmin: Enables creating and managing explicit Flink compute pools for workload isolation or cost control.
Service accounts
Service accounts are available for running statements permanently. If you want to run a statement with service account permissions, an OrganizationAdmin must create an Assigner role binding for the user on the service account. For more information, see Production workloads (service accounts).
Private networking
Confluent Cloud for Apache Flink supports private networking on AWS, Azure, and Google Cloud, providing a simple, secure, and flexible solution that enables new scenarios while keeping your data securely in private networking.
All Kafka cluster types are supported, with any type of connectivity (public, Private Links, VPC Peering, and Transit Gateway).
For more information, see Private Networking with Flink.
Cross-environment queries
Flink can perform cross-environment queries when using both public and private networking. This can be useful if you want to enable a single networking route from your VPC or VNET.

In this case, you can use a single environment and a single PLATT where you run all your Flink workloads and use three-part name queries, to query data in other environments, for example:
SELECT * FROM `myEnvironment`.`myDatabase`.`myTable`;
As a result, a single routing rule is necessary on the VPC or VNet side, per region, to redirect all traffic to the Flink regional endpoint(s) using this PrivateLink Attachment Connection.
To isolate different workloads, you can create compute pools manually, which enables you to control budget and scale of these workloads independently. See Compute Pools in Confluent Cloud for Apache Flink for more information.
Data access is protected by RBAC at the Kafka cluster (Flink database) or Kafka topic (Flink table) level. If your user account or service account that runs the query doesn’t have access, Flink can’t access sources and destinations.
To access Flink statements and workspaces, you must access them from a public IP address, if authorized, or from a PLATT or Confluent Cloud Network from the same environment and region.
Flink statements themselves can then access all the environments in the same organization and region.
Program Flink with SQL, Java, and Python
Confluent Cloud for Apache Flink supports programming your streaming applications in these languages:
Also, you can create custom user-defined functions and call them in your SQL statements. For more information, see User-defined Functions.
Note
The Flink Table API is available for preview.
A Preview feature is a Confluent Cloud component that is being introduced to gain early feedback from developers. Preview features can be used for evaluation and non-production testing purposes or to provide feedback to Confluent. The warranty, SLA, and Support Services provisions of your agreement with Confluent do not apply to Preview features. Confluent may discontinue providing preview releases of the Preview features at any time in Confluent’s’ sole discretion.
Comments, questions, and suggestions related to the Table API are encouraged and can be submitted through the established channels.
Confluent for VS Code
Install Confluent for VS Code to access Smart Project Templates that accelerate project setup by providing ready-to-use templates tailored for common development patterns. These templates enable you to launch new projects quickly with minimal configuration, significantly reducing setup time.