
Configure and Manage Cluster Links on Confluent Cloud
A cluster link is a connection between two Apache Kafka® clusters that enables data replication, consumer offset sync, and ACL synchronization across clusters.
You can create, view, manage, and delete cluster links using the Confluent CLI and the Confluent Cloud Cluster Linking (v3) REST API.
Configure cluster link behavior
Configure the following properties to control the behavior of a cluster link that goes to a Confluent Cloud destination cluster. These properties control features such as ACL synchronization, consumer offset migration, automatic mirror topic creation, and the starting position for topic mirroring.
If you disable a feature that has filters after having it enabled initially, then any existing filters will be cleared or deleted from the cluster link.
acl.filtersJSON string that lists the ACLs to migrate. Define the ACLs in a file,
acl.filters.json, and pass the file name as an argument to--acl-filters-json-file. Populateacl.filtersby passing a JSON file on the command line that specifies the ACLs. Do not include in the filter ACLs that are managed independently on the destination cluster. This is to prevent cluster link migration from deleting ACLs that were added specifically on the destination and should not be deleted. For more information, see ACL syncing.Type: string
Default: “”
acl.sync.enableWhether to migrate ACLs. See also, Syncing ACLs from source to destination cluster and ACL syncing.
Type: boolean
Default: false
acl.sync.msThe ACL refresh interval in milliseconds when ACL migration is enabled. The default is 5000 milliseconds (5 seconds).
Type: int
Default: 5000
auto.create.mirror.topics.enableWhether to auto-create mirror topics based on topics on the source cluster. When set to “true”, mirror topics will be auto-created. Setting this option to “false” disables mirror topic creation and clears any existing filters. For details on this option, see Auto-Create mirror topics.
auto.create.mirror.topics.filtersA JSON object with one property,
topicFilters, that contains an array of filters to apply to indicate which topics should be mirrored. For details on this option, see Auto-Create mirror topics.
cluster.link.prefixA prefix that is applied to the names of the mirror topics. The same prefix is applied to consumer groups when consumer.group.prefix is set to
true. The prefix cannot be changed after the cluster link is created. To learn more, see “Prefixing Mirror Topics and Consumer Group Names” in Mirror Topics.Type: string
Default: null
Note
The prefix cannot be changed after the cluster link is created.
The reverse commands do not support prefixed links for disaster recovery. If your architecture requires reversing mirroring relationships during a failover, do not configure a prefix on the link.
consumer.group.prefix.enableWhen set to
true, the prefix specified for the cluster link prefix is also applied to the names of consumer groups. The cluster link prefix must be specified in order for the consumer group prefix to be applied. To learn more, see “Prefixing Mirror Topics and Consumer Group Names” in Mirror Topics.Type: boolean
Default: false
consumer.offset.group.filtersJSON array that specifies the consumer groups to migrate. To migrate consumer groups, you must configure both the
consumer.offset.group.filtersandconsumer.offset.sync.enableproperties. Specify the list of consumer groups in theconsumer.offset.group.filtersproperty, and setconsumer.offset.sync.enabletotrueto enable it. To learn more, see Migrate consumer groups from source to destination cluster and Sync consumer group offsets.Type: string
Default: “”
consumer.offset.sync.enableWhether to migrate consumer offsets from the source cluster. To migrate consumer groups, you must configure both
consumer.offset.group.filtersandconsumer.offset.sync.enable. Specify the list of consumer groups inconsumer.offset.group.filters, and setconsumer.offset.sync.enabletotrueto enable it. To learn more, see Migrate consumer groups from source to destination cluster and Sync consumer group offsets.Type: boolean
Default: false
consumer.offset.sync.msThe consumer offset synchronization interval in milliseconds when consumer offset sync is enabled.
Type: int
Default: 30000
link.modeIndicates the direction of the cluster link, which can start from
DESTINATION(default),SOURCEfor a source-initiated link, orBIDIRECTIONAL. This setting cannot be changed once the link is created. This configuration is not available to set or create from the Confluent Cloud Console. The value forlink.modeis not case-sensitive. For example, you can also set this asdestination,source, orbidirectional.Type: string
Default: destination
If overriding the default, the link must be used exactly as specified in Bidirectional Mode Cluster Linking, Private to public Cluster Linking, or Hybrid Cloud Cluster Linking.
mirror.start.offset.specWhether to get the full history of a mirrored topic (
earliest), only thelatestmessages, or the history starting at a given timestamp.Type: string
Default: earliest
If set to a value of
earliest(the default), new mirror topics will get the full history of their associated topics.If set to a value of
latest, new mirror topics will exclude the history and only replicate messages sent after the mirror topic is created.If set to a timestamp in ISO 8601 format:
YYYY-MM-DDTHH:mm:SS.sss, new mirror topics get the history of the topics starting from the timestamp.
When a mirror topic is created, it reads the value of this configuration and begins replication accordingly. If the setting is changed, it does not affect existing mirror topics; new mirror topics use the new value when they’re created.
If some mirror topics need to start from earliest and some need to start from latest, there are two options:
Change the value of the cluster link’s
mirror.start.offset.specto the desired starting position before creating the mirror topic, orUse two distinct cluster links, each with their own value for
mirror.start.offset.spec, and create mirror topics on the appropriate cluster link as desired.
topic.config.sync.msThe topic configuration refresh interval in milliseconds.
Type: int
Default: 5000
What you need to create a cluster link
To create a cluster link, you need:
Access to the Destination cluster. Cluster links are created on the destination cluster. For the specific security authorization needed, see Manage Security for Cluster Linking on Confluent Cloud.
The name you wish to give the cluster link.
The Source cluster’s bootstrap server and cluster ID.
If the Source cluster is a Confluent Cloud cluster, you can get those using these commands:
confluent kafka cluster listto get the Source cluster’s ID. For example,lkc-12345confluent kafka cluster describe <source-cluster-id>to get the bootstrap server. It will be the value of the row calledEndpoint. For example,SASL_SSL://pkc-12345.us-west-2.aws.confluent.cloud:9092
If the Source cluster is a Confluent Platform or Apache Kafka® cluster, your system administrator can give you your bootstrap server. You can get your cluster ID by doing
confluent cluster describeorzookeeper-shell <bootstrap-server> get /cluster/id 2> /dev/null. For example,0gXf5xg8Sp2G4FlxNriNaA.Authentication credentials for the cluster link to use with the Source cluster. These can be updated, allowing you to rotate credentials used by your cluster link. See the section on configuring security credentials for more details.
(Optional) Any additional configuration parameters you wish to add to the cluster link. See the list of possible configurations below.
You will then pass this information into the CLI or API command to create a cluster link. You cannot update the cluster link’s name, Source cluster ID, or Destination cluster ID. These values are only set at creation.
Bidirectional mode
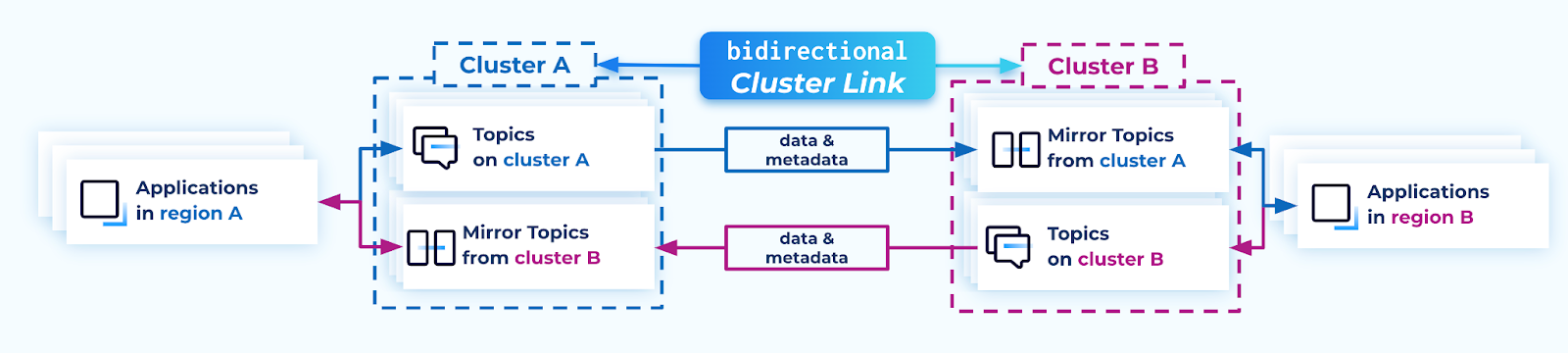
Cluster Linking bidirectional mode (a bidirectional cluster link) enables better Disaster Recovery and active/active architectures, with data and metadata flowing bidirectionally between two or more clusters.
Mental model
A useful analogy is to consider a cluster link as a bridge between two clusters.
By default, a cluster link is a one-way bridge: topics go from a source cluster to a destination cluster, with data and metadata always flowing from source to destination.
In contrast, a bidirectional cluster link is a two-way bridge: topics on either side can go to the other cluster, with data and metadata flowing in both directions.
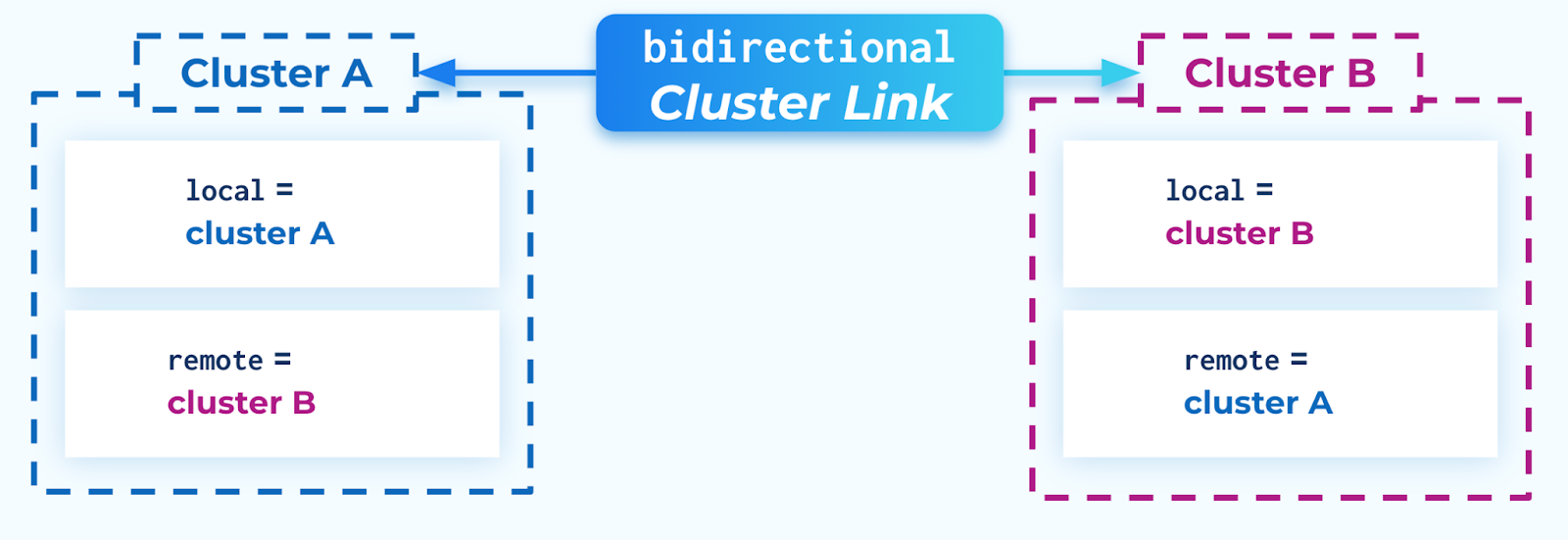
In the case of a “bidirectional” cluster link, there is no “source” or “destination” cluster. Both clusters are equal, and can function as a source or destination for the other cluster. Each cluster sees itself as the “local” cluster and the other cluster as the “remote” cluster.
Benefits
Bidirectional cluster links are advantageous in disaster recovery (DR) architectures, and certain types of migrations, as described below.
Disaster recovery
Bidirectional cluster links are useful for Disaster Recovery, both active/passive and active/active.
In a disaster recovery setup, two clusters in different regions are deployed so that at least one cluster is available at all times, even if a region experiences an outage. A bidirectional cluster link ensures both regions have the latest data and metadata from the other region, should one of them fail, or should applications need to be rotated from region to region for DR testing.
It is easier to test and practice DR by moving producers and consumers to the DR cluster and reversing the direction of data and metadata, with fewer commands and moving pieces.
For active/passive setups, a bidirectional link:
Gives access to the reverse and truncate-and-restore commands, which make for easier DR workflows with fast and efficient failover and failback. To learn more about these commands, see Convert a mirror topic to a normal topic.
If you have any consumers on the DR site consuming from the mirror topics, their consumer offsets can be synced to the Primary site should you need to move them from DR to Primary.
For active/active setups, a bidirectional link syncs all consumer offsets–from both regular topics and mirror topics–to both sides. Since consumers use a mix of regular and mirror topics, it is crucial to use a bidirectional link so that the consumer’s offsets are synced to the opposite side for failover.
Consumer-last migrations
Bidirectional cluster links are useful for certain types of migrations, where consumers are migrated after producers.
In most migrations from an old cluster to a new cluster, a default cluster link suffices because consumers are migrated before or at the same time as producers.
If there are straggling consumers on the old cluster, a bidirectional cluster link can help by ensuring their consumer offsets flow to the new cluster and are available when these consumers need to migrate. A default cluster link does not do this.
Tip
Bidirectional cluster links can only be used for this use case if the clusters fit the supported combinations described below.
Restrictions and limitations
To use bidirectional mode for Cluster Linking, both clusters must be one of these types:
Bidirectional mode is not supported if either of the clusters is a Basic or Standard Confluent Cloud cluster, a version of Confluent Platform 7.4 or earlier, or open source Apache Kafka®.
Consumer group prefixing cannot be enabled for bidirectional links. Setting consumer.group.prefix.enable to true on a bidirectional cluster link will result in an “invalid configuration” error stating that the cluster link cannot be validated due to this limitation.
Security
The cluster link will need one or more principal to represent it on each cluster, and those principals will be given cluster permissions via ACLs or RBAC, consistent with how authentication and authorization works for Cluster Linking. To learn more about authentication and authorization for Cluster Linking, see Manage Security for Cluster Linking on Confluent Cloud and Manage Security for Cluster Linking on Confluent Platform
On Confluent Cloud, the same service account or identity pool can be used for both clusters, or two separate service accounts and identity pools can be used.
Default security config for bidirectional connectivity
By default, a cluster link in bidirectional mode is configured similar to the default configuration for two cluster links.
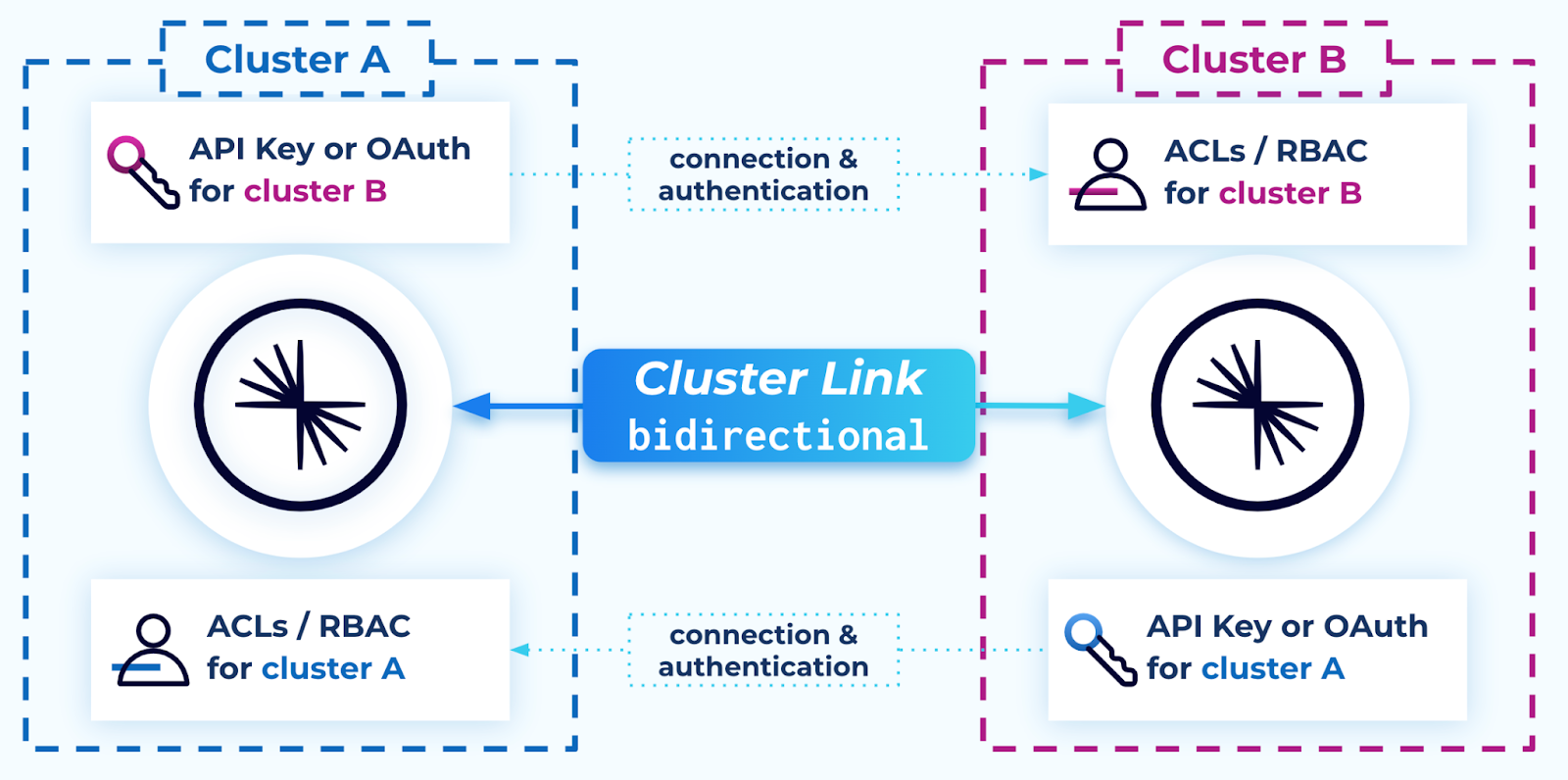
Each cluster requires:
The ability to connect outbound to the other cluster. If this is not possible, see Advanced options for bidirectional Cluster Linking.
A user to create a cluster link object on it with:
An authentication configuration, such as API key or OAuth, for a principal on its remote cluster with ACLs or RBAC role bindings giving permission to read topic data and metadata.
The Describe:Cluster ACL
The
DescribeConfigs:ClusterACL if consumer offset sync is enabled, which is recommendedThe required ACLs or RBAC role bindings for a cluster link, as described in Manage Security for Cluster Linking on Confluent Cloud in the rows for a cluster link on a source cluster.
link.mode=BIDIRECTIONAL
In some cases, only one cluster can reach the other. For example, if one of the clusters is in a private network or private datacenter, and the other is not. For details on how to configure a bidirectional link in this scenario, see Advanced options for bidirectional Cluster Linking.
The value for link.mode is not case-sensitive. For example, you can also set this to bidirectional.
Create a cluster link in bidirectional mode
The following sections explain how to create a cluster link in bidirectional mode using the Confluent CLI. The REST API can also be used with the supplied configurations.
If both clusters can reach each other, follow these steps. If only one cluster can reach the other, see Advanced options for bidirectional Cluster Linking.
Log in as a user with the necessary permissions to create a cluster link and service accounts.
Typically, this requires an OrganizationAdmin, EnvironmentAdmin, or CloudClusterAdmin.
Decide which security and connection model to use.
To learn about security and connection models for bidirectional Cluster Linking, see Security.
Locate the cluster IDs, optionally saving them for easy use. For example:
confluent kafka cluster list
Save cluster A ID in an environment variable. If you are using the unidirectional model, save that one as cluster A, corresponding with the descriptions in Security. Otherwise, either cluster can be cluster A.
aID=<cluster A ID>
Save cluster B ID in an environment variable.
bID=<cluster B ID>

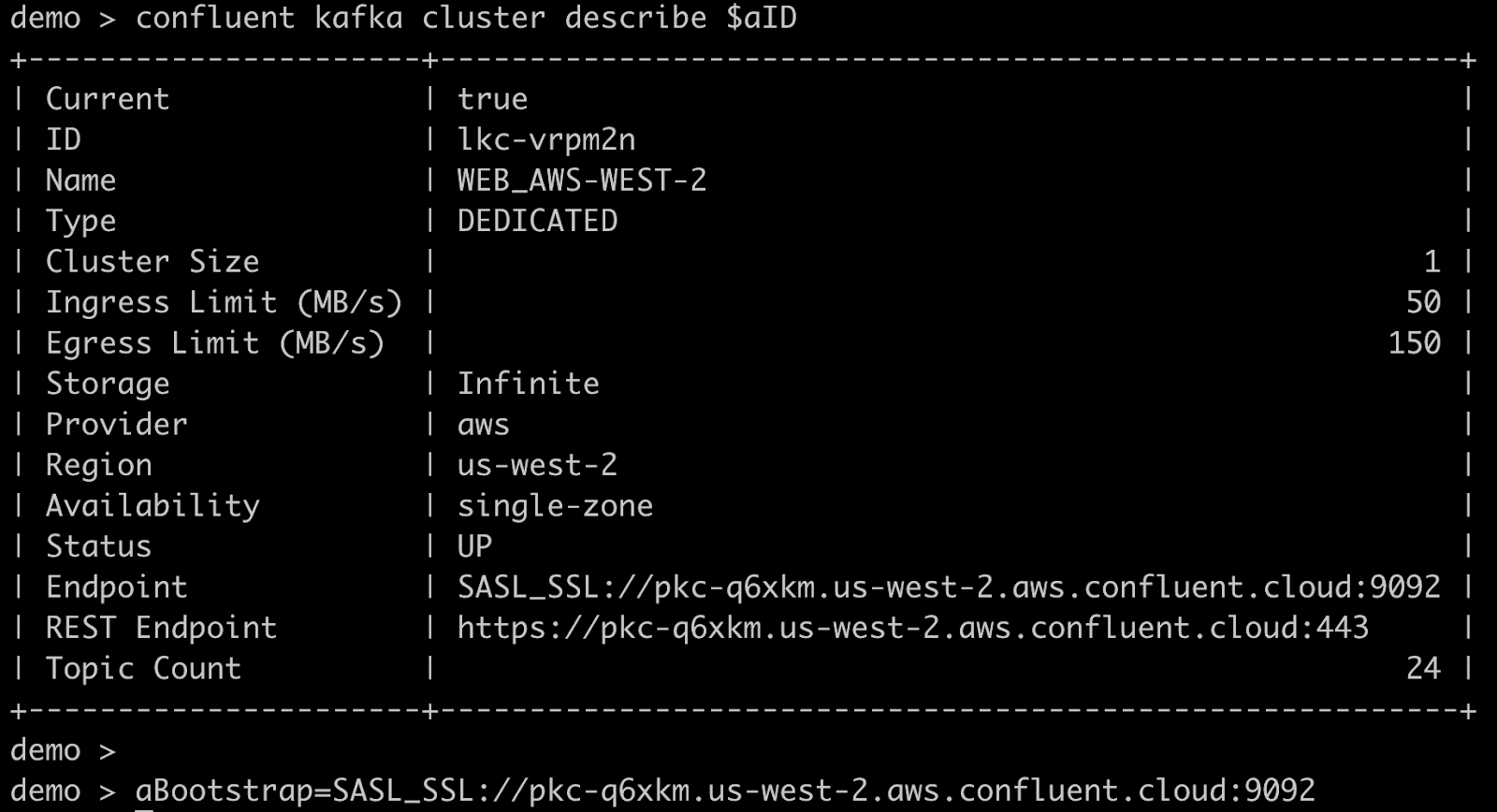
Locate your clusters’ bootstrap servers, optionally saving them for easy reuse:
confluent kafka cluster describe $aID
aBootstrap=<Endpoint-of-a>
confluent kafka cluster describe $bID
bBootstrap=<Endpoint-of-b>
Create principals for the cluster link. If both clusters are Confluent Cloud clusters, create a Service Account as the principal for the cluster link.
confluent iam service-account create <name> --description "<a short description>"
Take note of the Service Account ID. Optionally, save this ID for later:
saID=<service-account-ID>

You can choose any name and description for the service account.
If the clusters belong to different Confluent Cloud Organizations, two Service Accounts will be needed. A Service Account cannot belong to or have permissions for more than one organization. When creating API keys and ACLs, use the Service Account from that organization.
Create an API Key for the Service Account on both clusters.
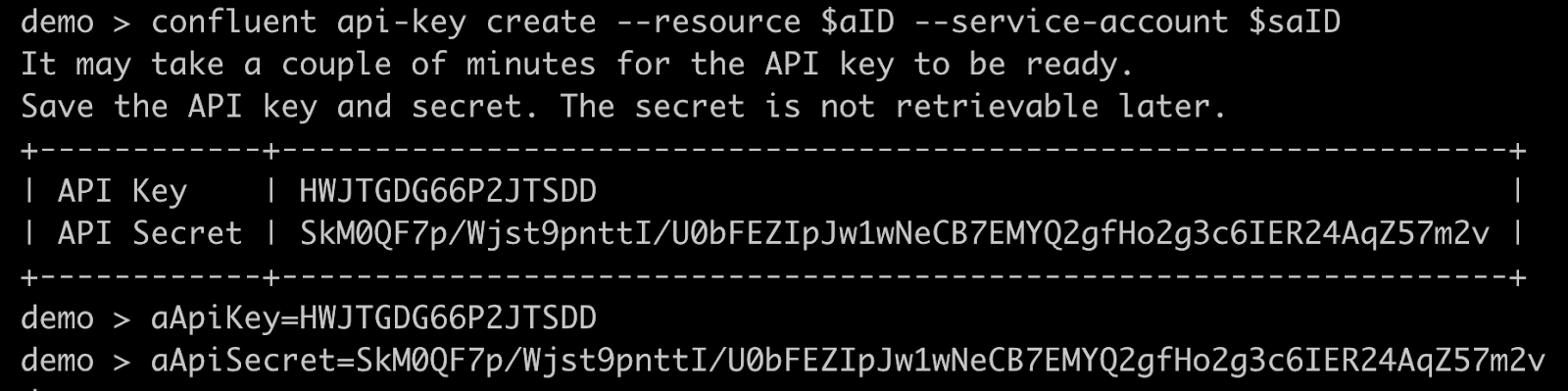
confluent api-key create --resource $aID --service-account $saID
confluent api-key create --resource $bID --service-account $saID
Take note of the API keys and secrets, optionally saving them for easy use:
aApiKey=<key>
aApiSecret=<secret>
bApiKey=<key>
bApiSecret=<secret>
Alternatively, use OAuth for authentication.
Assign permissions to the Service Account on both clusters.
In this example, create ACLs to allow the cluster link to read from topics beginning with the prefix “public.” on either cluster. To allow other topics, consumer offset sync, or ACL sync, add the ACLs listed in Manage Security for Cluster Linking on Confluent Cloud. Or, use RBAC role bindings.
confluent kafka acl create --allow --service-account $saID --operations read,describe-configs --topic "public." --prefix --cluster $aID
confluent kafka acl create --allow --service-account $saID --operations describe --cluster-scope --cluster $aID
confluent kafka acl create --allow --service-account $saID --operations read,describe-configs --topic "public." --prefix --cluster $bID
confluent kafka acl create --allow --service-account $saID --operations describe --cluster-scope --cluster $bID


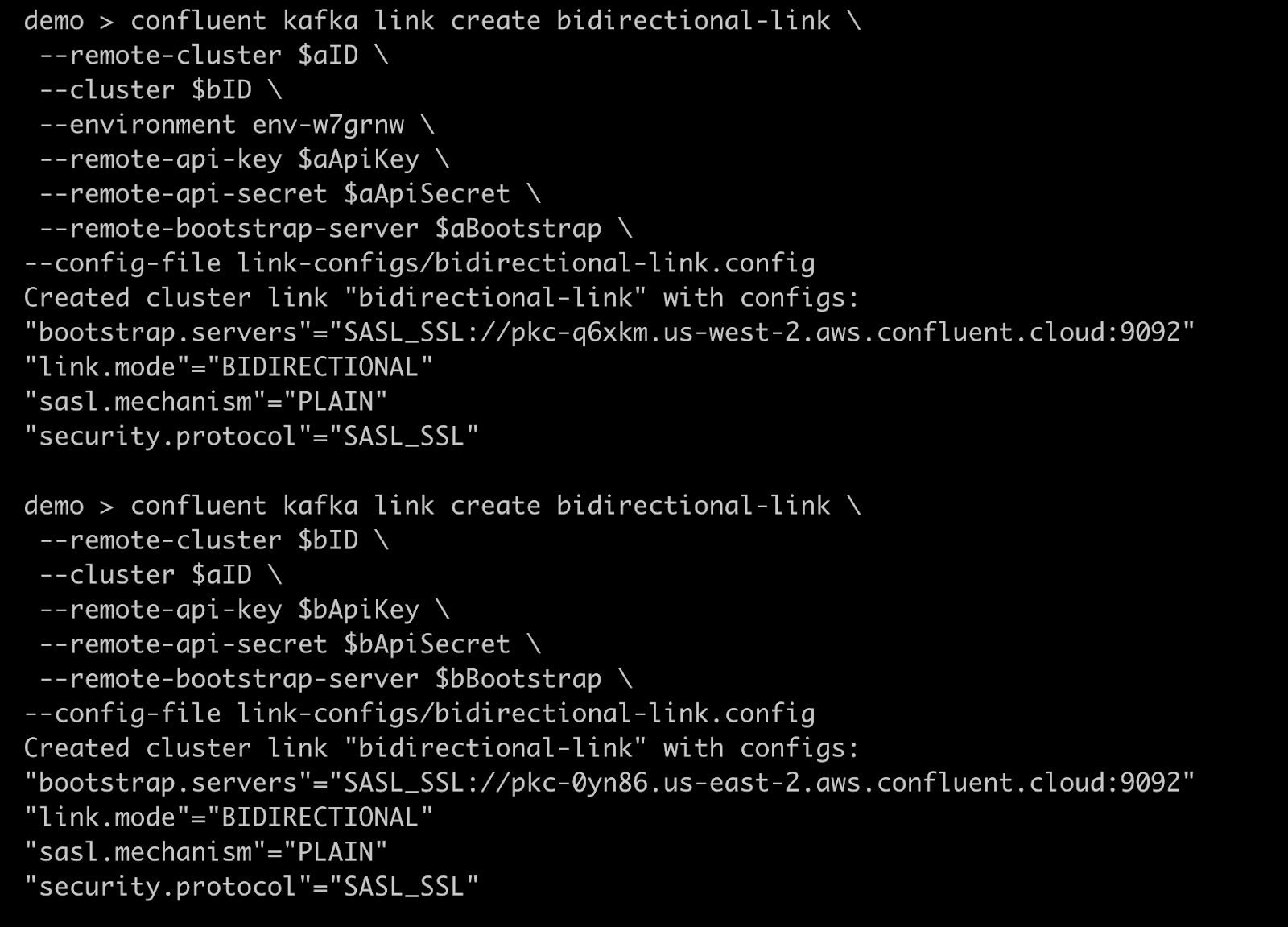
Create the cluster link object on cluster B, using the command confluent kafka link create.
Create a configuration file that includes the line
link.mode=BIDIRECTIONAL.echo "link.mode=BIDIRECTIONAL">link-configs/bidirectional-link.config
Note that more cluster link configurations can be added to this file if desired. These will be applied to data and metadata coming to cluster B only, and will not affect cluster A.
Issue the following CLI command to create a link named “bidirectional-link”. Name the link anything you want, but use identical link names on both clusters.
confluent kafka link create bidirectional-link \ --remote-cluster $aID \ --cluster $bID \ --remote-api-key $aApiKey \ --remote-api-secret $aApiSecret \ --remote-bootstrap-server $aBootstrap \ --config link-configs/bidirectional-link.config
Create the cluster link object on cluster A.
Use the same configuration file from cluster B, or create a new one with
link.mode=BIDIRECTIONAL.Note that more cluster link configurations can be added to this file if desired. These will be applied to data and metadata coming to cluster A only, and will not affect cluster B.
Issue the following CLI command to create a link named “bidirectional-link”. Name the link anything you want, but use identical link names on both clusters.
confluent kafka link create bidirectional-link \ --remote-cluster $bID \ --cluster $aID \ --remote-api-key $bApiKey \ --remote-api-secret $bApiSecret \ --remote-bootstrap-server $bBootstrap \ --config link-configs/bidirectional-link.config
Create mirror topics on either cluster, using the same link name and standard create mirror topic process.
confluent kafka topic create public.topic-on-a --cluster $aID
confluent kafka mirror create public.topic-on-a --link bidirectional-link --cluster $bID
confluent kafka topic create public.b-was-here --cluster $bID
confluent kafka mirror create public.b-was-here --link bidirectional-link --cluster $aID
Manage a cluster link in bidirectional mode
Configurations for a cluster link in bidirectional mode can be changed using the Confluent CLI, the REST API, or the Confluent Cloud Console.
Configurations are applied independently for clusters A and B. For example:
If consumer offset sync is only enabled on the cluster A cluster link object, then consumer offsets will only sync to A from B. No consumer offsets will be synced to B.
Conversely, to have consumer offsets sync to both clusters, it must be enabled on the cluster link objects on both clusters.
The same is true for other configuration options, including prefixing, auto-create mirror topics, and ACL sync.
Regardless of method used; CLI, REST API, or Confluent Cloud Console, editing configurations for one of the cluster link objects is done one at a time, with commands issued against that cluster.
In the Confluent Cloud Console:
A bidirectional cluster link appears as two rows, one for each cluster.
To add mirror topics for a given cluster or to edit the configurations for that side of the cluster link, click the row that has destination cluster set as that cluster.
Limitations on bidirectional cluster link management
The Confluent Cloud Console displays “Unknown” for the “Source Cluster” field in bidirectional cluster links, even when the remote cluster exists in Confluent Cloud.
Mirror topic names must be entered manually because the in-browser autocomplete does not work for bidirectional cluster links.
Delete a cluster link in bidirectional mode
To delete a cluster link that is in bidirectional mode:
Both cluster link objects on both clusters must be deleted. Delete them using the CLI, REST API, or Confluent Cloud Console.
Deleting the cluster link object on only one cluster will stop data from flowing either direction over the cluster link, but will not stop all billing charges, as some hourly charges may still occur on the remaining cluster link object.
Advanced options for bidirectional Cluster Linking
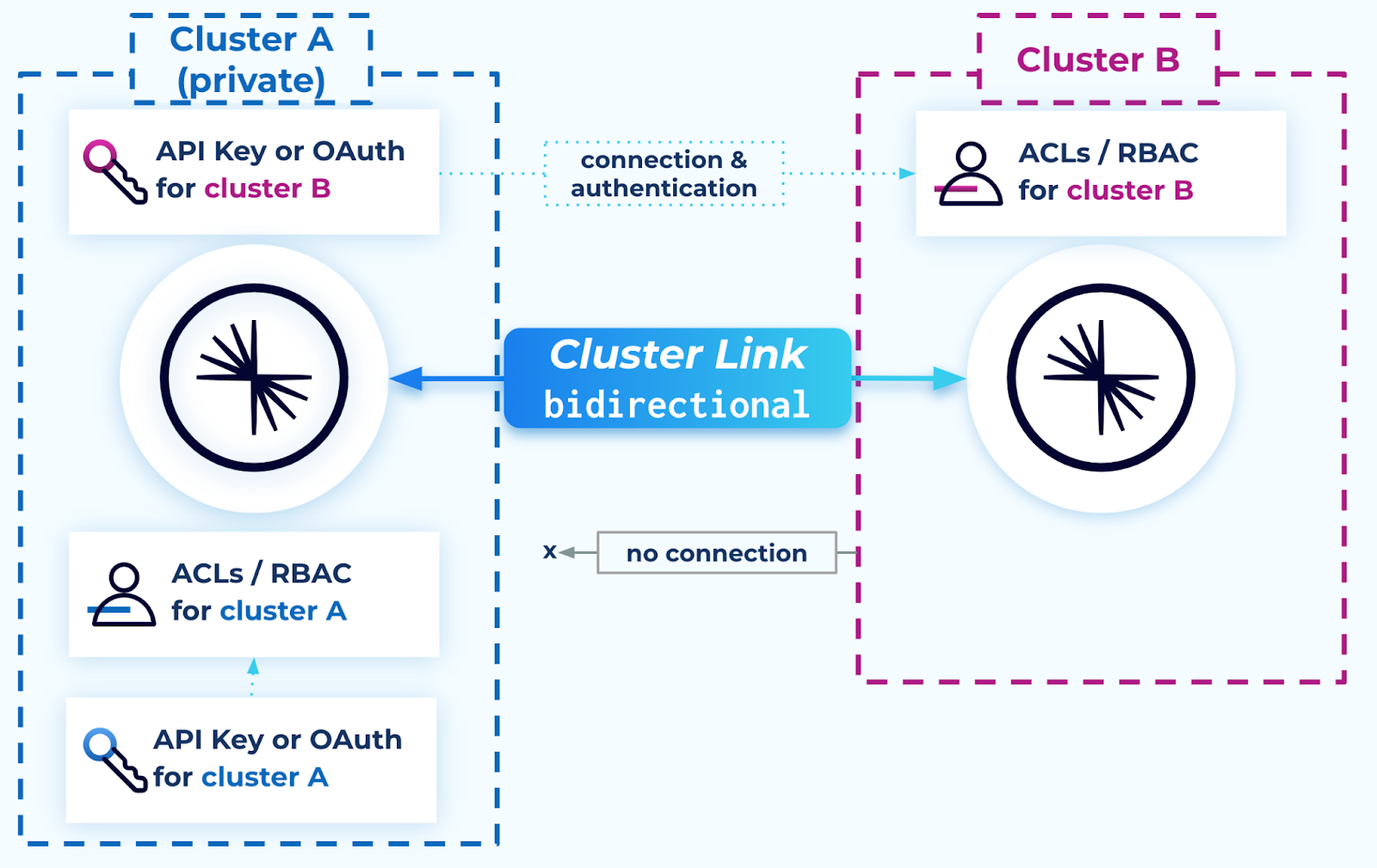
An advanced option for bidirectional Cluster Linking is a “unidirectional” security configuration for private-to-public or Confluent Platform to Confluent Cloud with a source-initiated link.
In advanced situations, security requirements may require that only one cluster can reach the other and/or that security credentials be stored on only one cluster. This would be the case, for example, if one of the clusters has private networking or is located in a datacenter, and the other cluster is configured with Internet networking.
In this scenario, configure the bidirectional cluster link so that only the more privileged private cluster connects to the remote cluster, and not the other way around. This is similar to a source-initiated cluster link. The following steps describe how to create a unidirectional, source-initiated cluster link.
To learn more about the advantages of creating this type of link in bidirectional mode, see What is the difference between unidirectional (source-initiated) and bidirectional (source-initiated) links? in the FAQ.
Step 1. Configure the link on the public cluster
The less privileged cluster, cluster B in the diagram above requires:
Create the inbound link on this less privileged cluster before its remote cluster, with
connection.mode=INBOUNDandlink.mode=BIDIRECTIONAL. Otherwise, the links on both sides may end up with different IDs even though they may have the same names, and it is the link IDs that establish the connection between the two sides
For example, create a .config file for cluster B as shown:
cat link-configs/bidirectional-inbound.config
link.mode=BIDIRECTIONAL
connection.mode=INBOUND
Then, run the command to create an INBOUND only link on cluster B, including a call to your cluster B config file:
confluent kafka link create bidirectional-link --remote-cluster $aID --environment $bEnvId --cluster $bId --remote-bootstrap-server $aBootstrap --config link-configs/bidirectional-inbound.config
Step 2. Configure the link on the private cluster
The more privileged / private cluster, cluster A in the diagram, requires:
Connectivity to its remote cluster. One-way connectivity is acceptable; such as AWS PrivateLink.
A user to create a cluster link object on it second, after the remote cluster, with the following configuration:
link.mode=BIDIRECTIONAL connection.mode=OUTBOUND security.protocol=SASL_SSL sasl.mechanism=PLAIN sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username='<bApiKey>' password='<bApiSecret>'; local.security.protocol=SASL_SSL local.sasl.mechanism=PLAIN local.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username='<aApiKey>' password='<aApiSecret>'; local.listener.name=<LISTENER_NAME>
The
local.listener.nameis optional in single-listener setups, but recommended in multi-listener environments. Rather than allowing the cluster link to infer a default listener, specify the exact network listener name on the private cluster to handle the incoming connection. In multi-listener scenarios, specifyinglocal.listener.nameensures predictable network routing and prevents traffic drift if cluster configurations are updated.An authentication configuration, such as API key or OAuth, for a principal on its remote cluster with ACLs or RBAC role bindings giving permission to read topic data and metadata.
Alter:Cluster ACL – this is used in the advanced mode and for the
reverseandtruncate-and-restorecommandsDescribe:Cluster ACL
The required ACLs or RBAC role bindings for a cluster link, as described in Manage Security for Cluster Linking on Confluent Cloud in the rows for a cluster link on a source cluster and for a source-initiated link on the destination cluster.
The required ACLs or RBAC role bindings as described in Manage Security for Cluster Linking on Confluent Cloud (the rows for a cluster link on a source cluster. This authentication configuration never leaves this cluster).
For example, run the following command to create a bidirectional INBOUND/OUTBOUND link on the private cluster, cluster A in the diagram, including the call to your cluster A configuration file:
confluent kafka link create bidirectional-link --remote-cluster $bId --environment $aEnvId --cluster $aID --remote-api-key $bApiKey --remote-api-secret $bApiSecret --remote-bootstrap-server $bBootstrap --config link-configs/bidirectional-outbound.config
Managing cluster links with the CLI
To create or configure a cluster link with the Confluent Cloud CLI, create a configuration file with the configurations you wish to set. Each configuration should be on one line in the file, with the format key=value, where key is the name of the configuration, and value is the value you wish to set on that cluster link. In the following commands, the location of this file is referred to as <config-file>.
Create a cluster link
To create a cluster link with the confluent CLI, use this command on the Destination cluster:
confluent kafka link create <link-name> \
--source-cluster <source-cluster-id> \
--source-bootstrap-server <source-bootstrap-server> \
--config <config-file> \
--cluster <destination-cluster-id>
--source-cluster-id was replaced with --source-cluster in version 3 of the Confluent CLI, as described in the command reference for confluent kafka link create.
Create a source-initiated cluster link
By default, cluster links are destination-initiated, meaning the destination cluster reaches out to the source cluster to establish the connection and pull data.
You can also create a source-initiated cluster link, where the source cluster initiates the network connection to the destination cluster. This pattern is particularly useful when security configurations, firewall rules, or private networking constraints prevent the destination cluster from reaching into the source environment.
Create the inbound link on the destination cluster.
confluent kafka link create <link-name> \ --cluster <destination-cluster-id> \ --mode INBOUND \ --source-cluster <source-cluster-id>
When a link is in INBOUND mode, it sits in a disconnected state, waiting for the source cluster to reach out and match the configuration.
Prepare the configuration file for the source cluster.
The source cluster needs to know how to connect and authenticate to the destination cluster. Create a local configuration file named
source-link-config.propertiescontaining the destination cluster’s details and API credentials:# Destination cluster bootstrap server link.destination.bootstrap.servers=<destination-cluster-bootstrap-url>:9092 # Security configuration to authenticate against the destination cluster link.destination.security.protocol=SASL_SSL link.destination.sasl.mechanism=PLAIN link.destination.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<destination-api-key>" password="<destination-api-secret>";
Create the outbound link on the source cluster.
Next, establish the actual connection by creating the matching link on the source cluster using OUTBOUND mode and passing the configuration file you created in Step 2. Run this command against your source cluster:
confluent kafka link create <link-name> \ --cluster <source-cluster-id> \ --mode OUTBOUND \ --config-file source-link-config.properties
The
<link-name>must be exactly identical on both the source and destination clusters for the handshake to succeed.Verify the link status.
After both sides are created, the source cluster actively initiates the handshake. Verify that the link status has transitioned to ACTIVE by running:
confluent kafka link status <link-name>
Find your link name in the output and confirm that the status reads ACTIVE. You are now ready to mirror topics across the source-initiated link.
Update a cluster link
To update the configuration for an existing cluster link with the cloud CLI, use this command on the Destination cluster:
confluent kafka link configuration update <link-name> --config my-update-configs.txt --cluster <destination-cluster-id>
Follow these guidelines:
When updating the configuration for an existing cluster link, include only the configurations that change. Be mindful when you use
--configto specify a configuration file that it contains only the configurations you want to update. For example,my-update-configs.txtmight include:consumer.offset.sync.ms=25384 topic.config.sync.ms=38254
You can change several aspects of a cluster link configuration, but you cannot change its source cluster, ID, prefix, or link name.
Examples of creating and configuring cluster links with the CLI are shown in the Cluster Linking Quick Start on Confluent Cloud, and the tutorials for Share Data Across Clusters, Regions, and Clouds using Confluent Cloud and Cluster Linking Disaster Recovery and Failover on Confluent Cloud.
List all cluster links going to the destination cluster
To see a list of all cluster links going to a Destination cluster, use the command:
confluent kafka link list --cluster <destination-cluster-id>
The output for this command will include the names of existing links; for example:
Name | Source Cluster | Destination Cluster | State | Error | Error Message
----------+----------------+---------------------+--------+-------+----------------
my-link | lkc-1225nz | | ACTIVE | |
View the configuration for a given cluster link
To view the configuration of a specific cluster link, use the command:
confluent kafka --cluster <destination-cluster-id> link configuration list <link-name>
View a cluster link task status
You can view the status of the following configurable tasks:
To view the status of any given task, use the following command:
confluent kafka link task list <link-name>
For example, to list tasks:
confluent kafka link task list link-1
Task Name | State | Errors
---------------------+----------------+---------------------------------
AclSync | NOT_CONFIGURED |
AutoCreateMirror | NOT_CONFIGURED |
ConsumerOffsetSync | IN_ERROR | REMOTE_LINK_NOT_FOUND_ERROR:
| | "Failed to get remote link
| | config due to link not being
| | found on the remote cluster."
TopicConfigsSync | ACTIVE |
Tasks can be in any one of the following states:
Task Status | Description |
|---|---|
| Task is configured, running and healthy. |
| Task is configured, but is encountering errors. Use the error code and error message to understand why the task is in error. |
| Task is not configured to run. |
| Link is in a failed state, so the task is not running. |
| Link is in an unavailable state, so the task is not running. |
| Link is in a paused state, so the task is not running. |
| Link state is unknown. A task is not expected to be in this state for prolonged periods of time. If it is, reach out to Confluent support. |
Delete a cluster link
To delete a cluster link, use the command:
confluent kafka link delete <link-name> --cluster <destination-cluster-id>
Using the command confluent kafka cluster use <destination-cluster-id> sets the Destination cluster to the active cluster, so you won’t need to specify --cluster <destination-cluster-id> in any commands.
Important
Before deleting a cluster link, verify that all mirror topics are in the
STOPPEDstate. If any are in thePENDING_STOPPEDstate, deleting a cluster link can cause irrecoverable errors on those mirror topics due to a temporary limitation.When a cluster link is deleted, the history of any
STOPPEDtopics is also deleted. If you need theLast Source Fetch Offsetor theStatus Timeof your promoted or failed-over mirror topics, save those before you delete the cluster link.You cannot delete a cluster link that still has mirror topics on it. The delete operation fails.
If you are using Confluent for Kubernetes (CFK), and you delete your cluster link resource, any mirror topics still attached to that cluster link will be forcibly converted to regular topics by use of the
failoverAPI. To learn more, see Modify a mirror topic in Cluster Linking using Confluent for Kubernetes.Cluster links are automatically deleted if the destination cluster is deleted.
Managing cluster links with the REST API
REST API calls and examples are provided in the reference documentation for the Confluent Cloud Cluster Linking (v3) REST API.
To learn how to authenticate with the REST API, see the REST API documentation.
To configure cluster links with the Confluent Cloud REST API, pass in configs in JSON format. Each config will take this shape:
{
"name": "<config-name>",
"value": "<config-value>"
}
Since this is JSON, if your config value is a string, surround it in double quotes. Then, pass in the name/value pairs as an array to the configs argument of the JSON payload.
For example, this JSON enables consumer offset sync for all consumer groups and ACL sync for all ACLs.
{
"configs": [
{
"name": "consumer.offset.sync.enable",
"value": "true"
},
{
"name": "consumer.offset.group.filters",
"value": "{\"groupFilters\": [{\"name\": \"*\",\"patternType\": \"LITERAL\",\"filterType\": \"INCLUDE\"}]}"
},
{
"name": "acl.sync.enable",
"value": "true"
},
{
"name": "acl.filters",
"value": "{ \"aclFilters\": [ { \"resourceFilter\": { \"resourceType\": \"any\", \"patternType\": \"any\" }, \"accessFilter\": { \"operation\": \"any\", \"permissionType\": \"any\" } } ] }"
}
]
}
Creating a cluster link through the REST API
See Create a cluster link in the Confluent Cloud REST API documentation.
To create a cluster link using the REST API, the JSON payload needs:
An entry called
source_cluster_idset to your Source cluster’s IDA config in the
configsarray calledbootstrap.serversset to your Source cluster’s bootstrap serverYour cluster link’s security configuration listed as configs in the
configsarrayThe security configuration must include the API key and secret resource-scoped for the cluster against which you are running the REST API commands. For more information on creating an API key, see Add an API key.
(Optional) Additional configurations in the
configsarray
Example JSON payload for a request to create a cluster link that syncs consumers offsets for all consumer groups, and syncs all ACLs:
{
"source_cluster_id": "<source-cluster-id>",
"configs": [
{
"name": "security.protocol",
"value": "SASL_SSL"
},
{
"name": "bootstrap.servers",
"value": "<source-bootstrap-server>"
},
{
"name": "sasl.mechanism",
"value": "PLAIN"
},
{
"name": "sasl.jaas.config",
"value": "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"<source-api-key>\" password=\"<source-api-secret>\";"
}
]
}
Include this JSON payload in a POST request to:
<REST-Endpoint>/kafka/v3/clusters/<cluster-ID>/links/?link_name=<link-name>
Where you replace the following:
<REST-Endpoint>is your cluster’s REST url. You can find this withconfluent kafka cluster describe <cluster-ID>. It will look like:https://pkc-XXXXX.us-west1.gcp.confluent.cloud:443<cluster-ID>is your destination cluster’s ID. You can find this withconfluent kafka cluster list. It will look likelkc-XXXXX.<link-name>is the name of your cluster link. You can name it whatever you choose.
Updating and viewing cluster link configs with the REST API
Update an existing cluster link
See Alter the config under a cluster link in the Confluent Cloud REST API documentation.
To update an existing link, you will send the JSON payload described above as a PUT request to <REST-Endpoint>/clusters/<cluster-ID>/links/<link-name>/configs:alter.
Get the value of a cluster link configuration
See Describe a cluster link in the Confluent Cloud REST API documentation.
To get the value of your cluster link’s configurations using the REST API, use one of these options:
GET
<REST-Endpoint>/clusters/<cluster-ID>/links/<link-name>/configsto get the full list of configs.GET
<REST-Endpoint>/clusters/<cluster-ID>/links/<link-name>/<config-name>to get the value of a specific config.
List all cluster links going to the destination cluster
See List all cluster links in the destination cluster in the Confluent Cloud REST API documentation.
To view a list of all cluster links going to a Destination cluster, send a GET request to <REST-Endpoint>/clusters/<cluster-ID>/links.
View a cluster link task status
See Describe a cluster link in the Confluent Cloud REST API documentation.
To view a cluster link task status, send a GET request to <REST-Endpoint>/clusters/<cluster-ID>/links/<link-name>?include_tasks=true.
For example, to list tasks:
curl -H "Authorization: Basic XXX" --request GET \
--url 'https://pkc-j581r8.us-west2.gcp.confluent.cloud:443/kafka/v3/clusters/lkc-ok51xj/links/link-1?include_tasks=true' | jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 839 0 839 0 0 1727 0 --:--:-- --:--:-- --:--:-- 1729
{
"kind": "KafkaLinkData",
"metadata": {
"self": "https://pkc-j581r8.us-west2.gcp.confluent.cloud/kafka/v3/clusters/lkc-ok51xj/links/link-1"
},
"source_cluster_id": null,
"destination_cluster": null,
"remote_cluster_id": "lkc-038qdq",
"link_name": "link-1",
"link_id": "d27ab324-82e8-4806-8487-1c6dcb3377dc",
"cluster_link_id": "0nqzJILoSAaEhxxtyzN33A",
"topic_names": [],
"link_error": "NO_ERROR",
"link_error_message": "",
"link_state": "ACTIVE",
"tasks": [
{
"task_name": "ConsumerOffsetSync",
"state": "IN_ERROR",
"errors": [
{
"error_code": "REMOTE_LINK_NOT_FOUND_ERROR",
"error_message": "Failed to get remote link config due to link not being found on the remote cluster."
}
]
},
{
"task_name": "AclSync",
"state": "NOT_CONFIGURED",
"errors": []
},
{
"task_name": "TopicConfigsSync",
"state": "ACTIVE",
"errors": []
},
{
"task_name": "AutoCreateMirror",
"state": "NOT_CONFIGURED",
"errors": []
}
]
}
To learn more about viewing task statuses, see View a cluster link task status in the CLI section.
Delete a cluster link
See Delete the cluster link in the Confluent Cloud REST API documentation.
To delete a cluster link, send a DELETE request to <REST-Endpoint>/clusters/<cluster-ID>/links/<link-name>.
Important
Before deleting a cluster link, verify that all mirror topics are in the
STOPPEDstate. If any are in thePENDING_STOPPEDstate, deleting a cluster link can cause irrecoverable errors on those mirror topics due to a temporary limitation.When a cluster link is deleted, the history of any
STOPPEDtopics is also deleted. If you need theLast Source Fetch Offsetor theStatus Timeof your promoted or failed-over mirror topics, save those before you delete the cluster link.You cannot directly call the “delete cluster link” command on a cluster link that still has mirror topics on it. The command will fail.
If you are using Confluent for Kubernetes (CFK), and you delete your cluster link resource, any mirror topics still attached to that cluster link will be forcibly converted to regular topics by use of the
failoverAPI. To learn more, see Modify a mirror topic in Cluster Linking using Confluent for Kubernetes.Cluster links are automatically deleted if the destination cluster is deleted.
Migrate consumer groups from source to destination cluster
To migrate a consumer group across the link, set consumer.offset.sync.enable=true in your link configuration, specify a group filter in a JSON file, and pass the configuration when creating the link with confluent kafka link create or use confluent kafka link configuration update to update an existing link. You can set this at the time you create the link, or as an update to an existing configuration.
Note
Consumer group filters should only include groups that are not being used on the destination. This will help ensure that the system does not override offsets committed by other consumers on the destination. The system attempts to work around filters containing groups that are also used on the destination, but in these cases there are no guarantees; offsets may be overwritten. For mirror topic “promotion” to work, the system must be able to roll back offsets, which cannot be done if the group is being used by destination consumers.
This example assumes you are migrating group “someGroup” from a source cluster to a destination cluster and the state before the migration is executed is that you are currently migrating all offsets with the following filter set.
{"groupFilters": [
{
"name": "*",
"patternType": "LITERAL",
"filterType": "INCLUDE"
}
]}
To migrate a consumer group from a source cluster to a destination cluster, follow these steps.
Stop the consumer on the source cluster.
Wait for a period of 2x
consumer.offset.sync.ms.Verify that Cluster Linking replication is beyond the latest committed offset. Confirm this with the following commands.
Check the CURRENT-OFFSET on the source cluster.
confluent kafka consumer group describe someGroup --cluster <source-cluster-id>
Your output should resemble the following:
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID someGroup west-offsets 0 100 100 0 - - -
Check the LOG-END-OFFSET on the destination cluster and ensure it is equal or larger than the CURRENT-OFFSET recorded above.
confluent kafka consumer group describe someGroup --cluster <destination-cluster-id>
Your output should resemble the following:
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID someGroup west-offsets 0 100 100 0
Verify the current offset is consistent in source and destination using the following commands.
Check the CURRENT-OFFSET on the source cluster.
confluent kafka consumer group describe someGroup --cluster <source-cluster-id>
Your output should resemble the following:
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID someGroup west-offsets 0 100 100 0 - - -
Check the CURRENT-OFFSET on the destination cluster.
confluent kafka consumer group describe someGroup --cluster <destination-cluster-id>
Your output should resemble the following:
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID someGroup west-offsets 0 100 100 0
Update the offset migration filters to remove the group from the migration process.
Create a configuration file with the updated filters:
echo 'consumer.offset.group.filters={"groupFilters": [ { "name": "*", "patternType": "LITERAL", "filterType": "INCLUDE" }, { "name": "someGroup", "patternType": "LITERAL", "filterType": "EXCLUDE" } ]}' > newFilters.txt
Update the cluster link configuration:
confluent kafka link configuration update <link-name> --config newFilters.txt --cluster <destination-cluster-id>
Start the consumer on the destination cluster.
Define the direction of offset syncing
When configuring consumer offset syncing for Cluster Linking, specify whether to sync offsets for local mirror topics (LOCAL_MIRROR), remote mirror topics (REMOTE_MIRROR), or both. Understanding when to use each option is critical for achieving reliable failover and avoiding offset sync conflicts.
Use the topicTypes field in the group filter JSON to specify which topics to sync.
By default, offsets are synced for both local and remote mirrors (
["LOCAL_MIRROR", "REMOTE_MIRROR"]).REMOTE_MIRRORonly takes effect in bidirectional mode.
For example, the following filter syncs offsets for all consumer groups on both local and remote mirror topics in bidirectional mode:
{"groupFilters": [
{
"name": "*",
"patternType": "LITERAL",
"filterType": "INCLUDE",
"topicTypes": ["LOCAL_MIRROR", "REMOTE_MIRROR"]
}
]}
For more examples of filter configurations, see Guidance for active-passive deployments and Guidance for active-active deployments.
What is LOCAL_MIRROR?
LOCAL_MIRROR syncs consumer group offsets for topics that are mirrored on the local cluster; that is, the cluster where the cluster link object is configured. When LOCAL_MIRROR is specified:
The cluster link fetches consumer offsets from the remote cluster, which is the source of the mirror topic.
These offsets are applied to the local cluster, where the mirror topic resides.
This enables consumers to resume from the correct position when they failover from the source cluster to the destination cluster where the mirror topics are located.
LOCAL_MIRROR determines the exact offset a consumer should resume from when failing over from a remote source topic to a local mirror topic.
What is REMOTE_MIRROR?
REMOTE_MIRROR syncs consumer group offsets for topics that are mirrored on the remote cluster. When REMOTE_MIRROR is specified:
The cluster link pulls consumer offsets from the mirror topic on the remote cluster and writes them to the source topic on the local cluster.
This is used in bidirectional configurations where the remote cluster also has mirror topics that need offset sync.
This enables consumers to resume from the correct position when they fail back from the destination cluster to the original source cluster.
REMOTE_MIRROR determines the exact offset a consumer should resume from when failing back from a remote mirror topic to a local source topic.
Offset syncing behavior summary
Mode | Offsets Fetched From | Offsets Written To | Use Case |
|---|---|---|---|
| Remote cluster (source) | Local cluster (mirror) | Failover from source to DR cluster |
| Remote cluster (mirror) | Local cluster (source) | Failback from DR to original cluster |
Guidance for active-passive deployments
In an active-passive deployment:
All producers and consumers interact with the active (primary) cluster only.
The passive (DR) cluster receives mirrored data but does not have active consumers until a failover occurs.
On failover, producers and consumers stop interacting with the failed cluster and start using the DR cluster.
Recommended configuration
Specify LOCAL_MIRROR only in the offset sync configuration on the DR cluster’s cluster link. This ensures offsets sync in one direction only: from the active cluster to the DR cluster.
Example configuration for active-passive
Create a configuration file, dr-link.config, for the cluster link on the DR cluster:
link.mode=BIDIRECTIONAL
consumer.offset.sync.enable=true
consumer.offset.group.filters={"groupFilters": [{"name": "*", "patternType": "LITERAL", "filterType": "INCLUDE", "topicTypes": ["LOCAL_MIRROR"]}]}
consumer.offset.sync.ms=5000
With this configuration:
Consumer offsets from the active cluster are synced to the DR cluster for all consumer groups.
When failover occurs, consumers can resume from their last committed offset on the DR cluster.
No offsets are synced back to the active cluster, which is appropriate since the active cluster is the source of truth until failover.
Failback after recovery
After the original cluster recovers and you want to fail back:
Use the
truncate-and-restorecommand on the original cluster’s topics to make them mirror the DR cluster’s topics.Update the cluster link configuration on the original cluster to enable
LOCAL_MIRRORoffset sync.Use
reverse-and-startto restore the original mirroring direction.
Guidance for active-active deployments
In an active-active deployment:
Producers may write to either, or both, clusters.
Consumers are active on both clusters simultaneously.
Each cluster has writable topics and mirror topics, typically with prefixes to avoid name clashes.
Key requirements
Unique consumer group names: Each consumer group must exist on only one cluster at a time. If you need consumers in both regions, use different consumer group names for each region.
Explicit group filtering: Do not use wildcard filters (
*) for bothLOCAL_MIRRORandREMOTE_MIRROR. Instead, to prevent cycles, explicitly specify which consumer groups should sync and in which direction.Prefixed topics: Use
cluster.link.prefixto distinguish mirror topics from source topics.
Example configuration for active-active
Consider two clusters, cluster A (us-east) and cluster B (us-west), with the following setup:
Cluster A has topic
orders(source) andwest.orders(mirror from cluster B)Cluster B has topic
orders(source) andeast.orders(mirror from cluster A)Consumer group
cg-eastconsumes on cluster AConsumer group
cg-westconsumes on cluster B
Cluster A’s cluster link configuration:
link.mode=BIDIRECTIONAL
cluster.link.prefix=west.
consumer.offset.sync.enable=true
consumer.offset.group.filters={"groupFilters": [{"name": "cg-east", "patternType": "LITERAL", "filterType": "INCLUDE", "topicTypes": ["REMOTE_MIRROR"]}, {"name": "cg-west", "patternType": "LITERAL", "filterType": "INCLUDE", "topicTypes": ["LOCAL_MIRROR"]}]}
Cluster B’s cluster link configuration:
link.mode=BIDIRECTIONAL
cluster.link.prefix=east.
consumer.offset.sync.enable=true
consumer.offset.group.filters={"groupFilters": [{"name": "cg-west", "patternType": "LITERAL", "filterType": "INCLUDE", "topicTypes": ["REMOTE_MIRROR"]}, {"name": "cg-east", "patternType": "LITERAL", "filterType": "INCLUDE", "topicTypes": ["LOCAL_MIRROR"]}]}
With this configuration:
cg-eastoffsets sync from cluster A to cluster B for theeast.ordersmirror topic.cg-westoffsets sync from cluster B to cluster A for thewest.ordersmirror topic.Each consumer group’s offsets flow in one direction only, preventing cycles.
Failover in active-active
When a region fails in an active-active setup:
Move affected consumers to the surviving region.
Update the offset sync filters on the surviving cluster to exclude the moved consumer groups from sync to prevent the surviving cluster from overwriting their offsets.
After recovery, update filters again before moving consumers back.
Best practices for offset sync configuration
Start with LOCAL_MIRROR for DR scenarios: For standard disaster recovery,
LOCAL_MIRRORon the DR cluster is sufficient. Only addREMOTE_MIRRORif you need failback capabilities with offset preservation.Use explicit filters in active-active: Never use
"name": "*"with bothLOCAL_MIRRORandREMOTE_MIRRORtopicTypes, as this can create offset sync cycles.Match consumer group lifecycles: Ensure that consumer groups are explicitly stopped on one cluster before being started on another to avoid offset conflicts.
Configure appropriate sync intervals: Adjust
consumer.offset.sync.msbased on your recovery point objectives (RPO) requirements. Lower values, for example: 1000 ms, provide more frequent syncs but increase overhead.Monitor offset sync state: Use the
confluent kafka link task listcommand to verify that consumer offset sync is working correctly. Look for theConsumerOffsetSynctask inACTIVEstate.
Limitations on bidirectional consumer offset sync
Consumer group offsets that are deleted on the destination cluster, especially those that are auto-deleted, persist instead of being removed as expected. Internally, the offsets are re-replicated to the destination before retention settings delete the offsets from source. This results in extended retention of inactive consumer group offsets.
To prevent this, extend retention on the destination to ensure data is deleted on the source before it is deleted on the destination. To do this, increase offsets.retention.minutes on destination cluster by at least double offsets.retention.check.interval.ms.
Important
If you use bidirectional linking to sync the same consumer group between both sides, the above argument infinitely extends retention due to the cyclical nature of the argument. To avoid this, ensure that each consumer group exists on only one cluster at a time, as recommended in Guidance for active-active deployments.
To learn more
Considerations for failover scenarios in the Mirror Topics documentation
Syncing ACLs from source to destination cluster
Cluster Linking can sync some or all of the ACLs on the source cluster to the destination cluster. This is critical for Disaster Recovery (DR) architectures, so that when your client applications failover to the DR cluster, they have the same access that they had on their original cluster. When you create the cluster link, specify which ACLs to sync, filtering down by the name of the resource, principal for a service account, operation, and/or permission. You can update this setting on the cluster link at any time. The cluster link will copy the initial set of matching ACLs, and then continuously sync any changes, additions, or deletions of matching ACLs from the source cluster to the destination cluster.
By default, ACLs on the source that were themselves created by Cluster Linking are not synced. Override this behavior with another filter. To learn more, see Sync ACLs created by a cluster link in the Examples section.
In Confluent Cloud, ACL sync is only supported between two Confluent Cloud clusters that belong to the same Confluent Cloud organization. ACL sync is not supported between two Confluent Cloud clusters in different organizations, or between a Confluent Platform and a Confluent Cloud cluster. Do not include in the sync filter ACLs that are managed independently on the destination cluster. Before configuring and deploying with ACL sync, see ACL syncing limitations in the overview for full details.
To learn more, see Migrate consumer groups from source to destination cluster.
How does it work?
ACL sync creates an exact replica of the ACLs from the source. ACL sync is capable of syncing ACLs for multiple resource types. When enabled, it typically syncs topics, consumer groups, and transactional IDs.
Prerequisites
Authorizations: You must have the appropriate authorizations:
DESCRIBE Cluster ACLs (
DescribeAclsAPI) on the source clusterALTER Cluster ACLs (
CreateAcls/DeleteAclsAPIs) on the destination cluster
Cluster link prefixing cannot be used with ACL sync: ACL syncing cannot be used in cluster links that are configured with a prefix, defined as
cluster.link.prefix. For more details, see Limitations on prefixing.
Configurations for ACL Sync
To enable ACL sync on a cluster link, specify these properties:
acl.sync.enable=trueThis turns on ACL sync. Updating this config to
falsewill turn off ACL sync.If you set this up and run Cluster Linking, then later disable it, the filters will be cleared (deleted) from the cluster link.
acl.filtersA JSON object with one property,
aclFilters, that contains an array of filters to include specific ACLs to sync. Examples are below.acl.sync.ms (optional)How frequently to sync ACLs. The default is 5000 (5 seconds). Minimum is 1000.
Configure ACLs at the time you create the cluster link, or as an update to an existing configuration.
Here is an example of setting up a cluster link with ACL migration when you create the cluster link. Note that the link configurations, including ACL migration properties, are defined in a file, link-configs.properties, rather than specified directly on the command line.
confluent kafka link create from-aws-basic \
--source-cluster lkc-12345 \
--source-bootstrap-server SASL_SSL://pkc-abcde.us-west1.gcp.confluent.cloud:9092 \
--source-api-key 1L1NK2RUL3TH3M4LL \
--source-api-secret ******* \
--config link-configs.properties
Here is an example of what you might have in link-configs.properties:
acl.sync.enable=true
acl.sync.ms=1000
acl.filters={ "aclFilters": [ { "resourceFilter": { "resourceType": "any", "patternType": "any" }, "accessFilter": { "operation": "any", "permissionType": "any" } } ] }
The following sections provide examples of how you might define the actual ACLs in acl.filters.
Examples
The following examples show how to configure the JSON for various types of ACL migration, with granularity on a topic, a resource, or a mixed set.
Migrate all ACLs from source to destination cluster
To migrate all ACLs from the source to the destination cluster, provide the following for acl.filters.
acl.filters={ \
"aclFilters": [ \
{ \
"resourceFilter": { \
"resourceType": "any", \
"patternType": "any" \
}, \
"accessFilter": { \
"operation": "any", \
"permissionType": "any" \
} \
} \
] \
}
Each field in the JSON has the following options:
resourceType: Can beANY(meaning any kind of resource),topic,cluster,group, ortransactionalID, which are the resources specified in ACL Overview.patternType: Can beANY,LITERAL, orMATCH. Note that whilePREFIXEDis a valid pattern type option, it is not supported in the context of ACL syncing in Cluster Linking. For more details, see Limitations on filtering ACLs.name: Name of resource.If left empty, will default to the
*wildcard, which will match all names of the specifiedresourceType.If
patternTypeis"LITERAL"then any resources with this exact name will be included.If
patternTypeis"MATCH", then any resources that match a given literal or wildcard (*) pattern of the same name and type will be included.
principal: (optional) Name of principal specified on the ACL. If left empty will default to the*wildcard, which will match all principals with the specifiedoperationandpermissionType.For example, a service account with ID 12345 has this principal:
User:sa-12345.
operation: Can either be any or one of those specified in Operations under the “Operation” column.permissionType: Can beany,allow, ordeny.
Limitations on filtering ACLs
In Cluster Linking, ACL sync does not support prefix-pattern resource filtering. For example, using "patternType": "PREFIXED" to sync all ACLs for topics starting with orders- is unsupported.
Instead, use the following alternatives to search for prefixed resources using ACL filters:
Configure ACL filters using the
LITERALpattern type, and define the exact name of each of the desired prefixed resources in each filter.Configure ACL filters that each define a specific
principalwith access to the desired prefixed resources.This alternative is best when ACLs for the desired prefixed resources are all assigned to the same principals.
For example, if you want to sync read ACLs for topics
orders-us,orders-eu,orders-apac, andorders-latamthat are all assigned to the same principal, you would define a separate filter entry for each topic:acl.filters={ "aclFilters": [ { "resourceFilter": { "resourceType": "topic", "patternType": "LITERAL", "name": "orders-us" }, "accessFilter": { "principal": "User:sa-12345", "operation": "read", "permissionType": "allow" } }, { "resourceFilter": { "resourceType": "topic", "patternType": "LITERAL", "name": "orders-eu" }, "accessFilter": { "principal": "User:sa-12345", "operation": "read", "permissionType": "allow" } }, { "resourceFilter": { "resourceType": "topic", "patternType": "LITERAL", "name": "orders-apac" }, "accessFilter": { "principal": "User:sa-12345", "operation": "read", "permissionType": "allow" } }, { "resourceFilter": { "resourceType": "topic", "patternType": "LITERAL", "name": "orders-latam" }, "accessFilter": { "principal": "User:sa-12345", "operation": "read", "permissionType": "allow" } } ] }
Sync all ACLs specific to a topic
To sync all ACLs for topic pineapple, provide the following configurations in acl.filters:
acl.filters={ \
"aclFilters": [ \
{ \
"resourceFilter": { \
"resourceType": "topic", \
"patternType": "literal", \
"name": "pineapple” \
}, \
"accessFilter": { \
"operation": "any", \
"permissionType": "any" \
} \
} \
] \
}
Sync ACLs specific to a principal or permission
To sync all ACLs specific to a service account with ID 12345 and also all ACLs that deny access to the cluster, provide the following configurations in acl.filters:
acl.filters={ \
"aclFilters": [ \
{ \
"resourceFilter": { \
"resourceType": "any", \
"patternType": "any" \
}, \
"accessFilter": { \
“principal”: “User:sa-12345”, \
"operation": "any", \
"permissionType": "any" \
} \
}, \
{ \
"resourceFilter": { \
"resourceType": "any", \
"patternType": "any" \
}, \
"accessFilter": { \
"operation": "any", \
"permissionType": "deny" \
} \
} \
] \
}
Sync ACLs created by a cluster link
By default, ACLs on the source that were themselves created by Cluster Linking are not synced. For example, suppose you have three clusters: cluster-1, cluster-2, and cluster-3. Link-1 syncs ACLs from cluster-1 to cluster-2, and link-2 syncs ACLs from cluster-2 to cluster-3. If link-1 creates ACLs on cluster-2, by default link-2 does not migrate those ACLs to cluster-3 even if the filter is any. cluster-3 by link-2 even if the filter is any.
You can override this by using two filters: one that supports standard ACL syncing, and another that syncs ACLs created by a cluster link, such as “link-1” in the following example.
The first is the regular type of filter that syncs all, except those created by any cluster link.
The second makes sure that the ACLs created by link-1 get synced.
[
{
"resourceFilter": {
"resourceType": "any",
"patternType": "any"
},
"accessFilter": {
"operation": "any",
"permissionType": "any"
}
},
{
"resourceFilter": {
"resourceType": "any",
"patternType": "any"
},
"accessFilter": {
"operation": "any",
"permissionType": "any",
"clusterLinkIds ": [
"link-1-ID"
]
}
}
]
Configure Security Credentials
When you create a cluster link, give the cluster link credentials to authenticate to the source cluster. Read the Cluster Linking security overview for more information about Cluster Linking security requirements, including the required ACLs.
Configure security credentials for Confluent Cloud source clusters
If your Source cluster is a Confluent Cloud cluster, your cluster link will need these properties configured:
security.protocolset toSASL_SSLsasl.mechanismset toPLAINsasl.jaas.configset toorg.apache.kafka.common.security.plain.PlainLoginModule required username="<source-api-key>" password="<source-api-secret>";Replace
<source-api-key>and<source-api-secret>with the API key to use on your Source cluster.Be careful not to forget the
"characters and the ending;
Configure security credentials for Confluent Platform and Kafka source clusters
Since cluster links consume from the source cluster using the same mechanism as a regular Kafka consumer, the cluster link’s authentication configuration is identical to the one needed by Kafka consumers.
For Confluent Cloud cluster links, if your source cluster uses SSL, also known as TLS, pass the keystore and truststore in-line, rather than with a keystore and truststore location. To learn more, see the security section on mutual TLS (mTLS) authentication.
The following properties are supported by cluster links going to Confluent Destination clusters:
sasl.client.callback.handler.classsasl.jaas.configsasl.kerberos.kinit.cmdsasl.kerberos.min.time.before.reloginsasl.kerberos.service.namesasl.kerberos.ticket.renew.jittersasl.kerberos.ticket.renew.window.factorsasl.login.callback.handler.classsasl.login.classsasl.login.refresh.buffer.secondssasl.login.refresh.min.period.secondssasl.login.refresh.window.factorsasl.login.refresh.window.jittersasl.mechanismsecurity.protocolssl.cipher.suitesssl.enabled.protocolsssl.endpoint.identification.algorithmssl.engine.factory.classssl.key.passwordssl.keymanager.algorithmssl.keystore.locationssl.keystore.passwordssl.keystore.typessl.keystore.certificate.chainssl.protocolssl.providerssl.truststore.certificates