
Data Portal on Confluent Cloud
Data Portal is a self-service interface for discovering, exploring, and accessing Apache Kafka® topics on Confluent Cloud.
Building new streaming applications and pipelines on top of Kafka can be slow and inefficient when there is a lack of visibility into what data exists, where it comes from, and who can grant access. Data Portal leverages Stream Catalog and Stream Lineage to empower data users to interact with their organization’s data streams efficiently and collaboratively.
With Data Portal, data practitioners can:
Search and discover existing topics with the help of topic metadata and get a drill-down view to understand data they hold (without access to the actual data).
Request access to topics through an approval workflow that connects the data user with the data owner, and admins that can approve the request.
View and use data in topics (once access is granted) to build new streaming applications and pipelines.
The following sections take you through each of the steps on this journey, from the perspectives of both data user and topic owner.
Demo: Data Portal and Flink
This video introduction to a real-world use case for Stream Governance highlights various aspects of Stream Catalog, stream lineage, data discovery, and data quality. Learn how the Data Portal and Apache Flink® in Confluent Cloud can help developers and data practitioners find the data they need to quickly create new data products.
Prerequisites and notes
Data Portal is available in Confluent Cloud for users with a Stream Governance package enabled in their environments.
User-generated metadata should be appended to topics to make them discoverable and present them effectively on the Data Portal. In particular, description, tags, business metadata and owner name and email should be added to topics.
The topic access request workflow is not available for topics on Basic clusters.
The collaboration workflow for topic access requests through email is dependent upon having owner names and emails appended to topics.
Users need search Stream Catalog permissions to use the Data Portal, at a minimum DataDiscovery role. On the “add new user” workflow, the DataDiscovery role is pre-selected by default to give the user permission to use the Data Portal.
To approve access requests to topics, users need topic read and write granting permissions, in particular ResourceOwner, CloudClusterAdmin, EnvironmentAdmin or OrganizationAdmin.
Users need query permissions on one or more compute pools to query data with Apache Flink®️, at a minimum FlinkDeveloper role.
Search and discover existing topics
To get started, sign in to Confluent Cloud, and click Data portal on the left menu.
Users with search Stream Catalog permissions can use the Data Portal. At the very least, a user must have the DataDiscovery RBAC role.
By default, the Discover tab on the Data Portal shows a curated view of all available Kafka topics by environment.
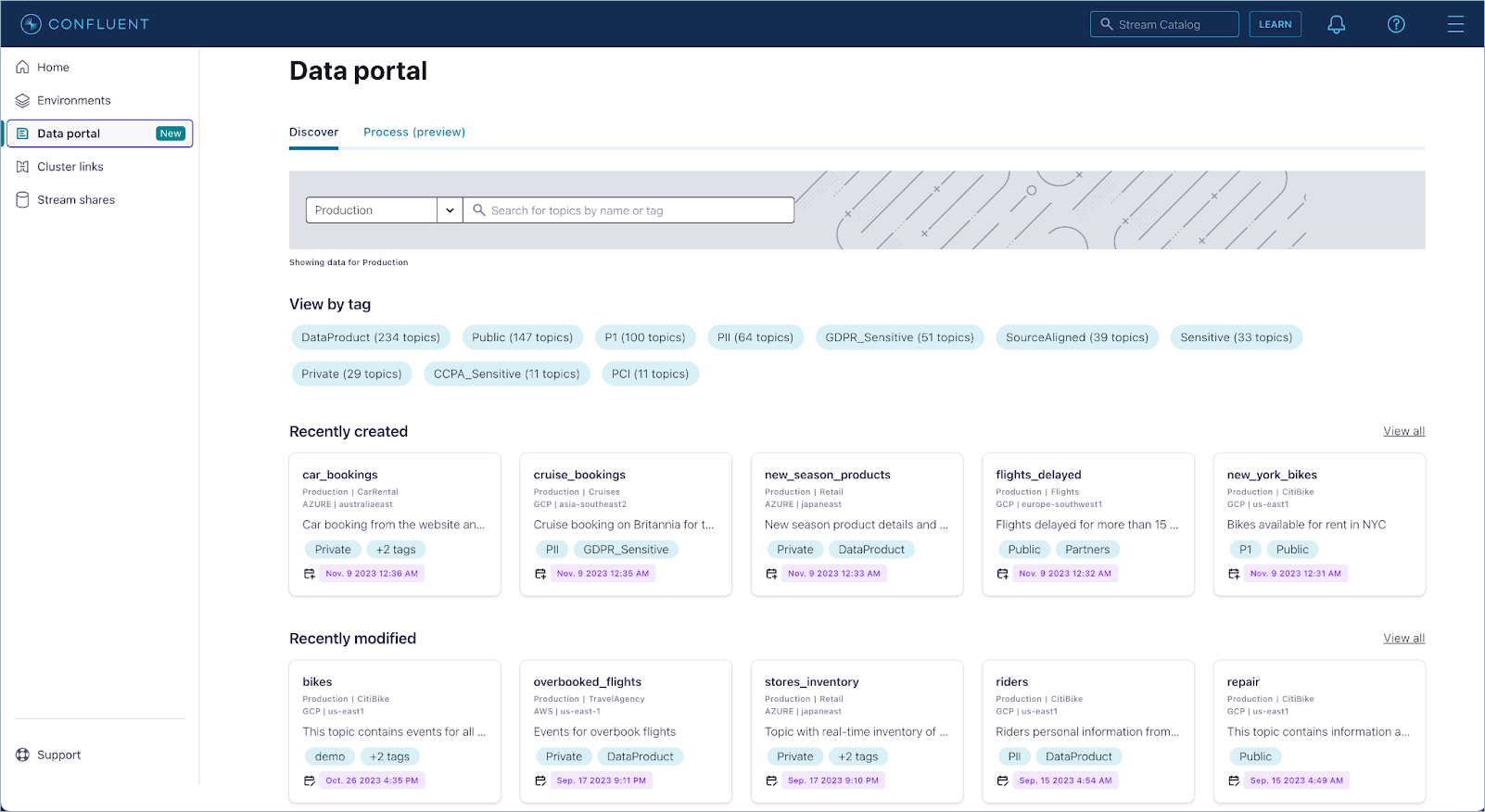
You can search for topics by name or tag, or alternatively browse topics by tag associated, creation date, and modified date. The search bar supports the following search modes:
Prefix search: Enter the beginning of a topic name to find all topics that start with that prefix. For example, searching for
samplereturns topics such assample_data_stock_trades_1,sample_data_orders, andsample_data_users_2.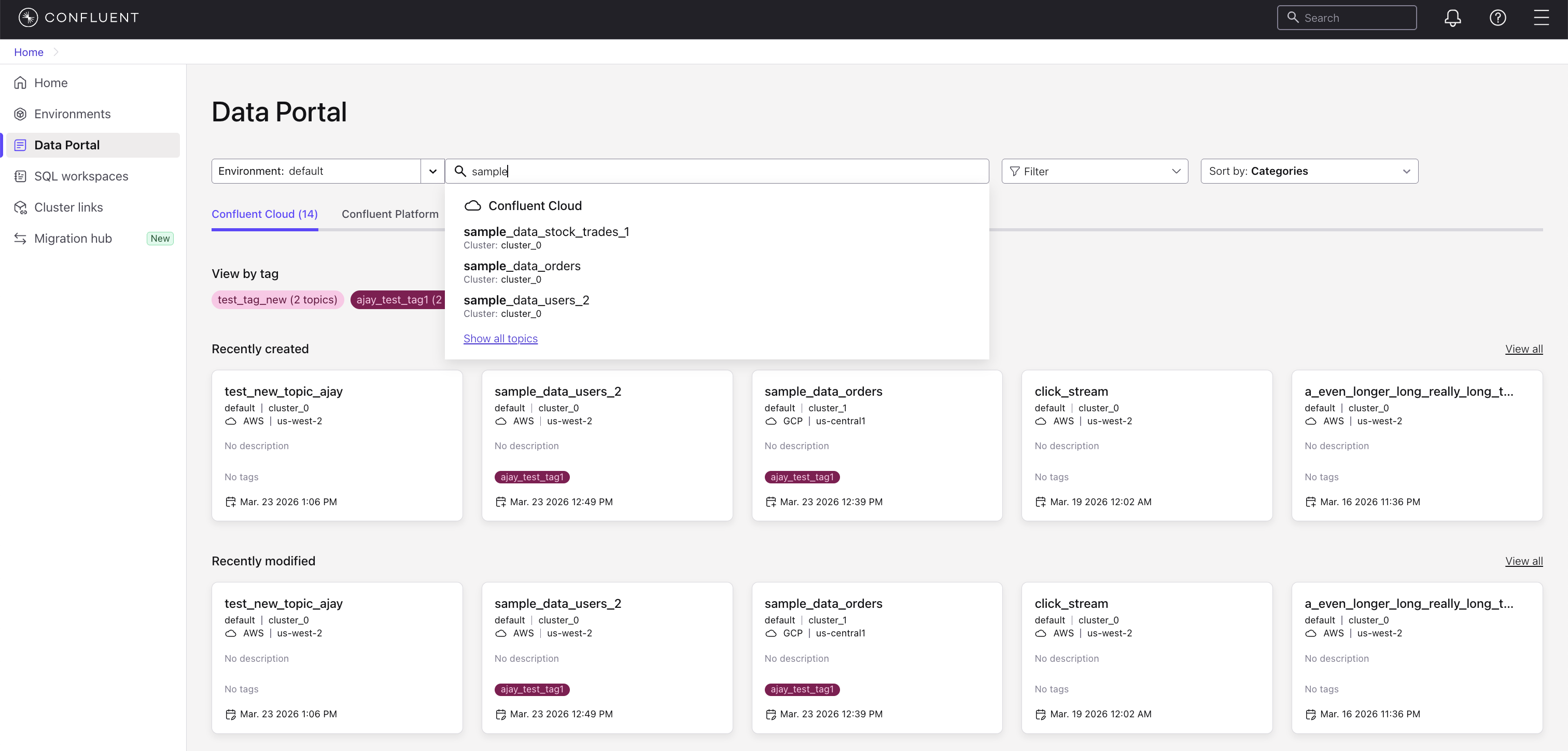
Substring search: Enter any part of a topic name to find all topics containing that string. For example, searching for
datareturns topics such assample_data_stock_trades_1,sample_data_orders, andsample_data_users_2.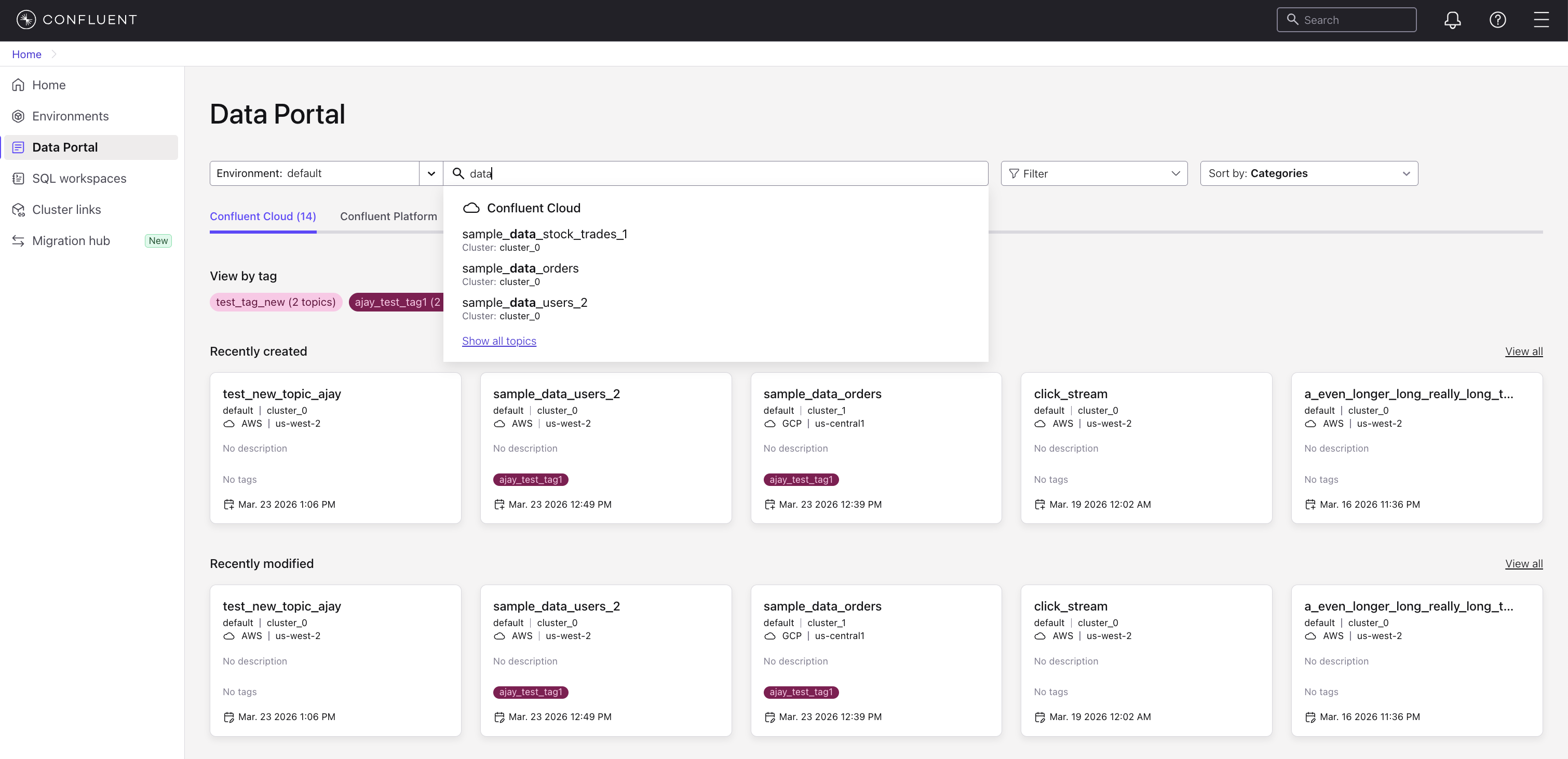
Fuzzy search: Enter a full topic name, and the search returns the nearest match even if the name does not match exactly. For example, searching for
clickstreamreturns the topicclick_stream.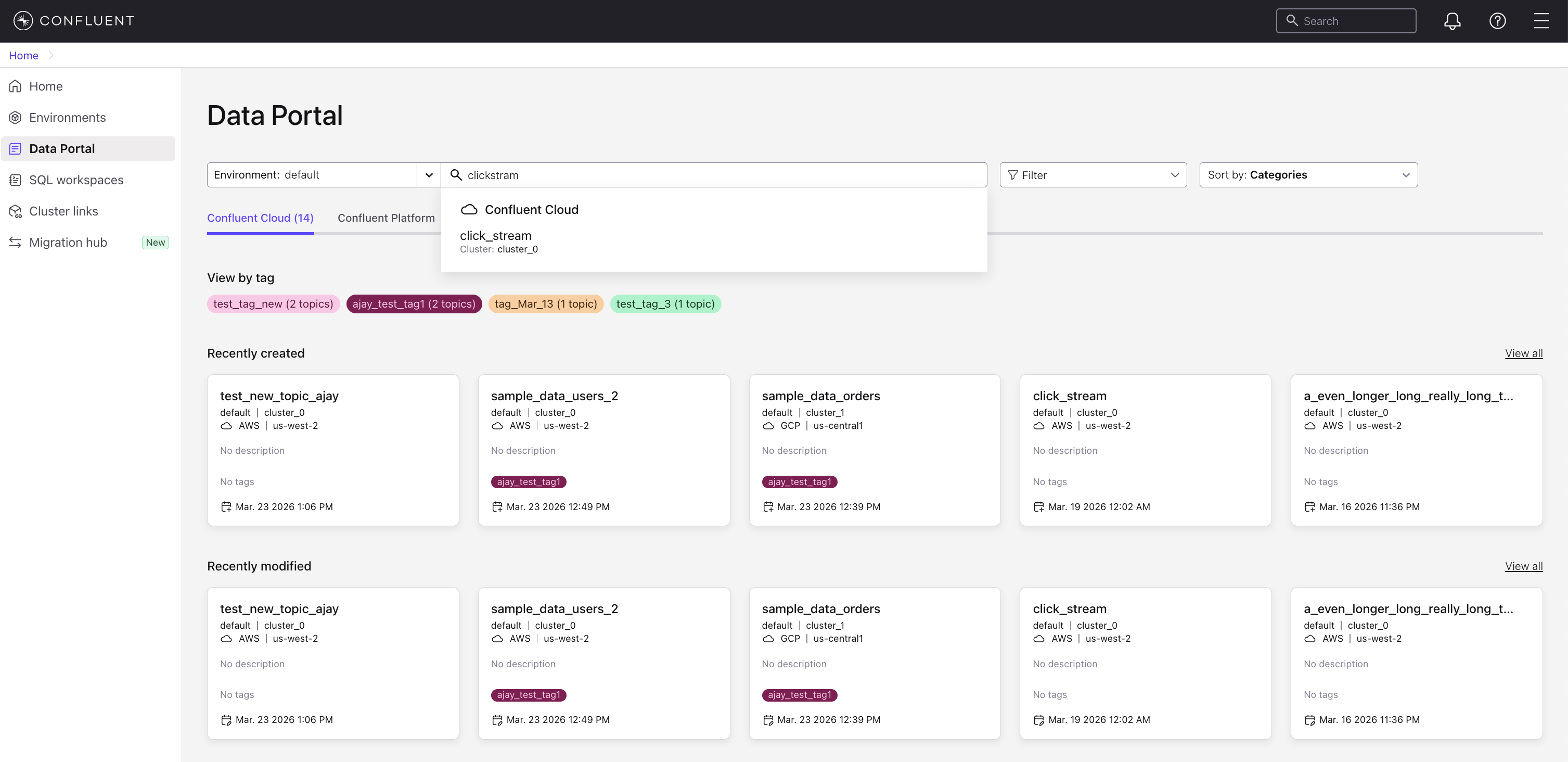
Wildcard search: Use the asterisk (
*) character as a wildcard to match any sequence of characters in a topic name. For example, searching forstock*tradereturns topics such assample_data_stock_trades_1andsample_data_stock_trades.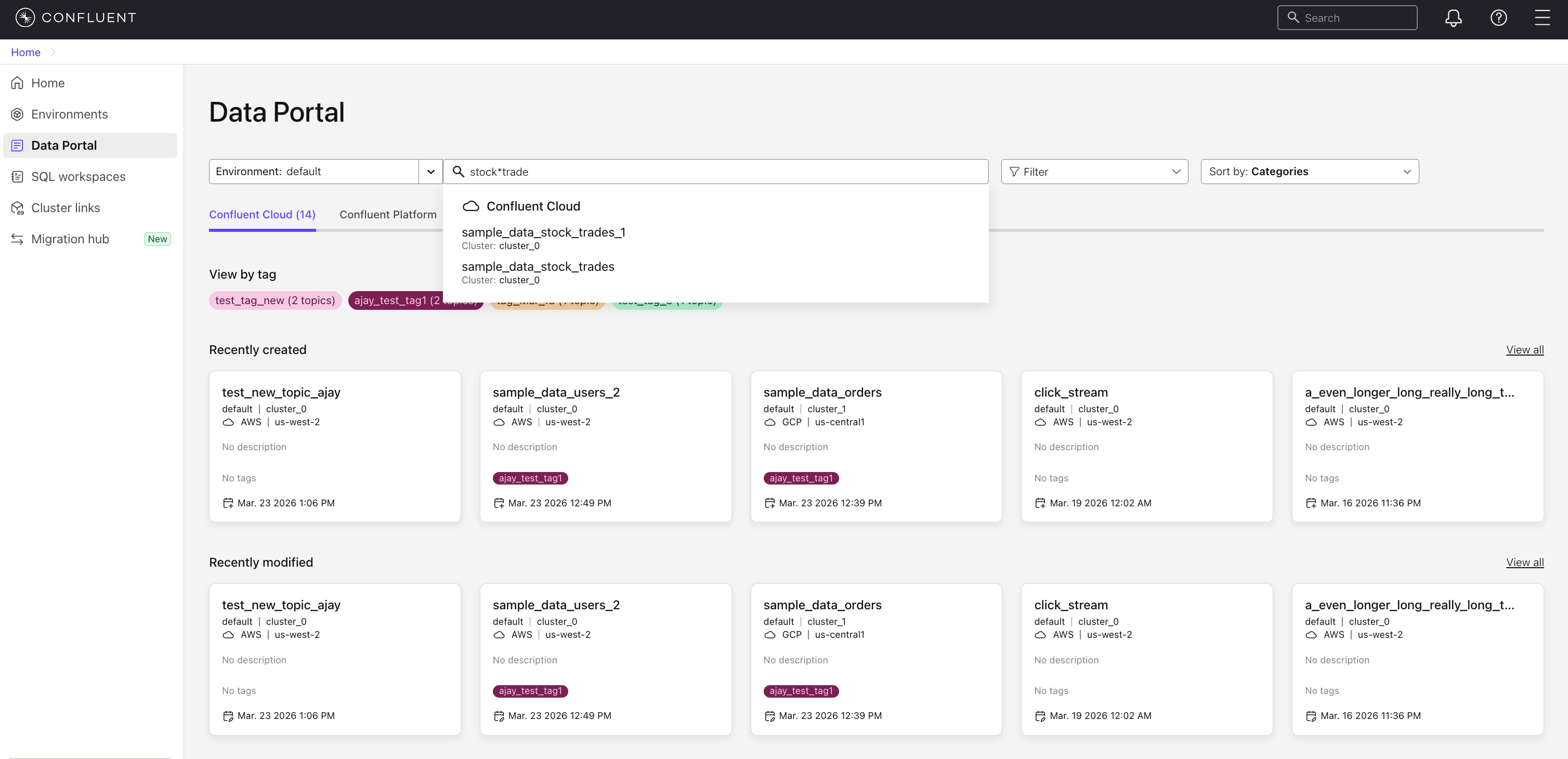
Important
Prefix, substring, fuzzy, and wildcard search are available in the Confluent Cloud Console. If you are using Stream Catalog REST APIs, only prefix search is available.
Substring, fuzzy, and wildcard search are currently not available if your Stream Catalog is in the following regions:
austriaeast(Azure)qatarcentral(Azure)jiodiawest(Azure)jiodiacentral(Azure)ap-southeast-5 (Malaysia)(AWS)ap-southeast-7 (Thailand)(AWS)
Each topic card on the page gives a summary of the topic with the name, data location (environment, cluster, cloud provider, and region), description, tags, and when it was created or modified.
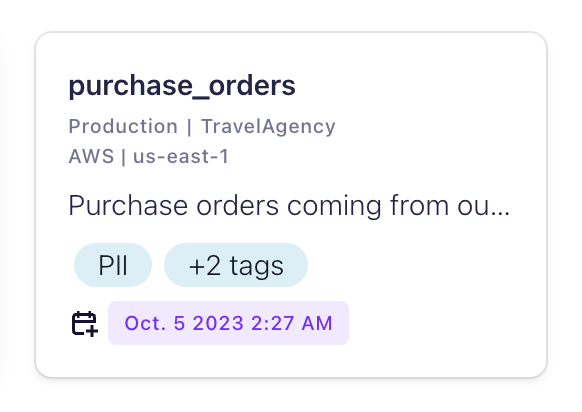
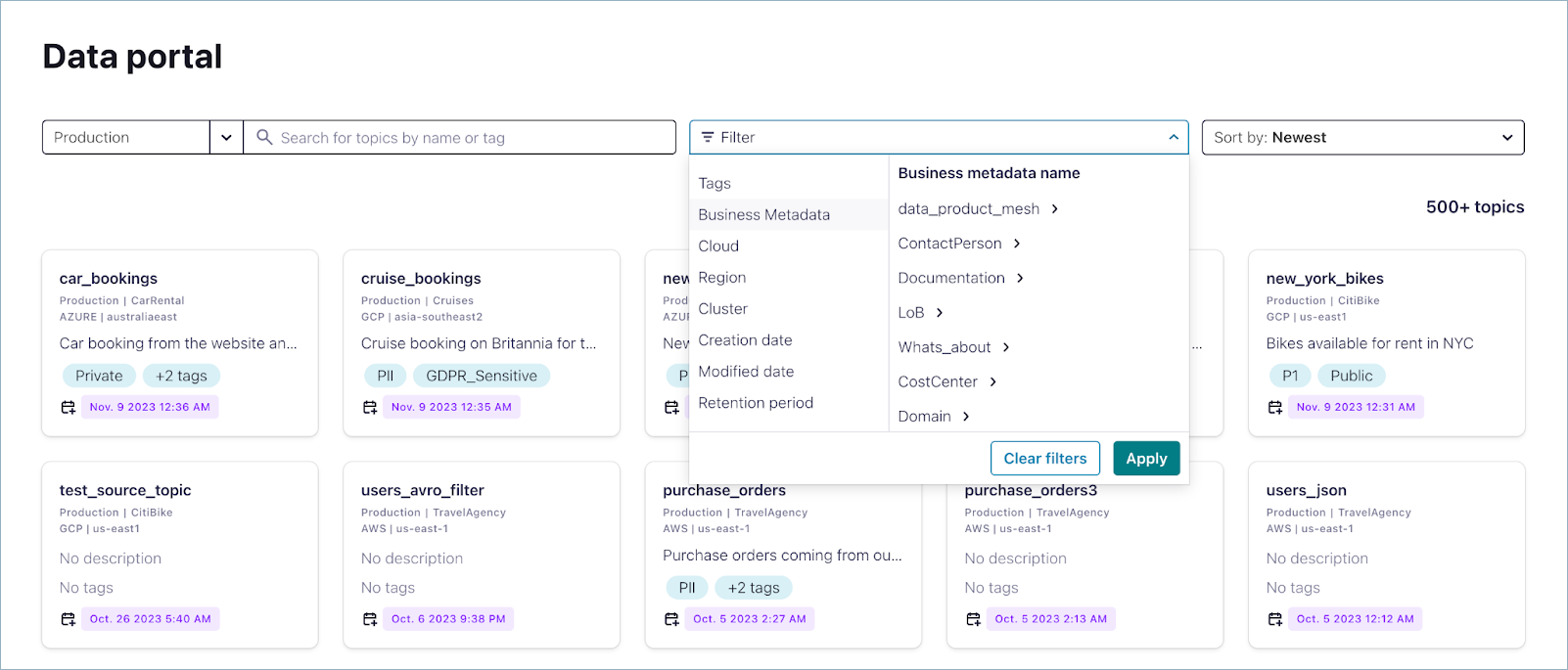
Click a tag pile, or View all to get to an advanced search page where you can apply additional filtering to narrow down the topic results. Available filters include tags, business metadata, cloud provider, region, and other topic technical metadata.
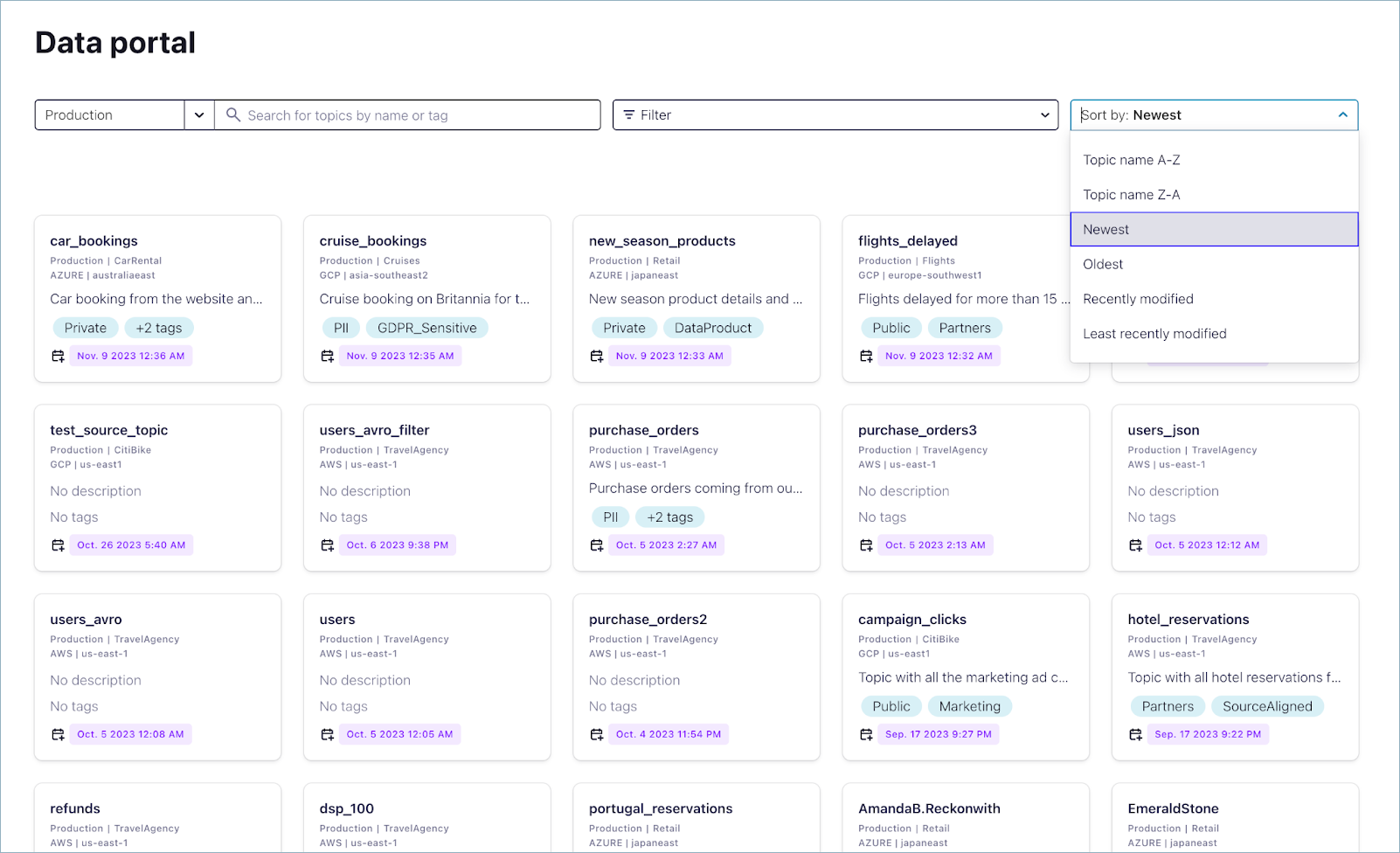
You can also sort topic results alphabetically, by creation date and by modified date.
To learn more about a topic, click its card. A summary of the topic is shown on the right panel, including the following information:
Name
Environment
Cluster
Cloud provider
Cloud region
Description
Schema (with link to see the schema in full screen)
Link to see topic Lineage
Owner name and email address
Business metadata
Technical metadata (created date, retention period, and so on)
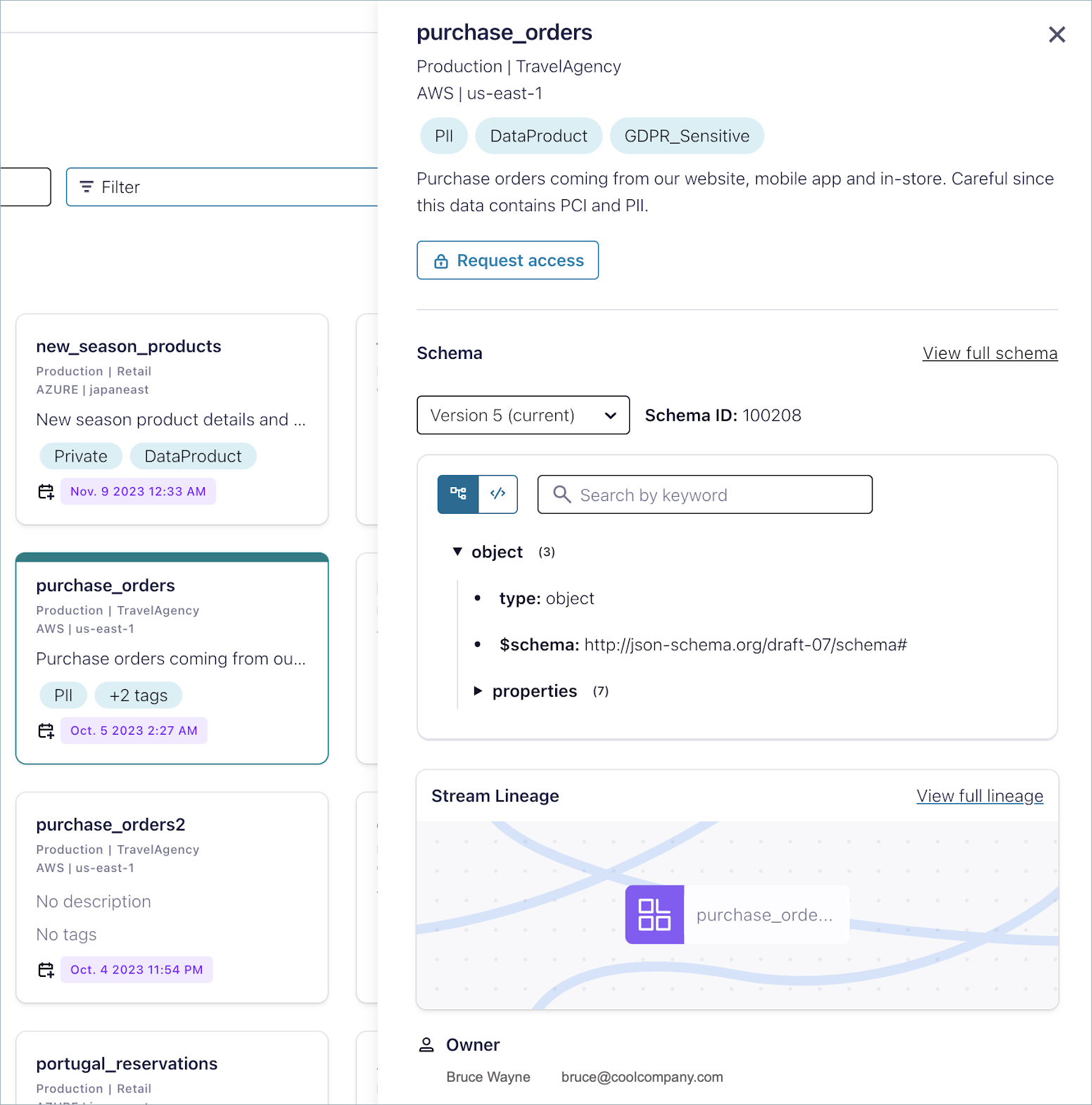
If you already have read access to the topic, you will see the last message produced and a link to the topic message browser. Also, you can set up a client and query the topic with Flink SQL from the actions section on the top.
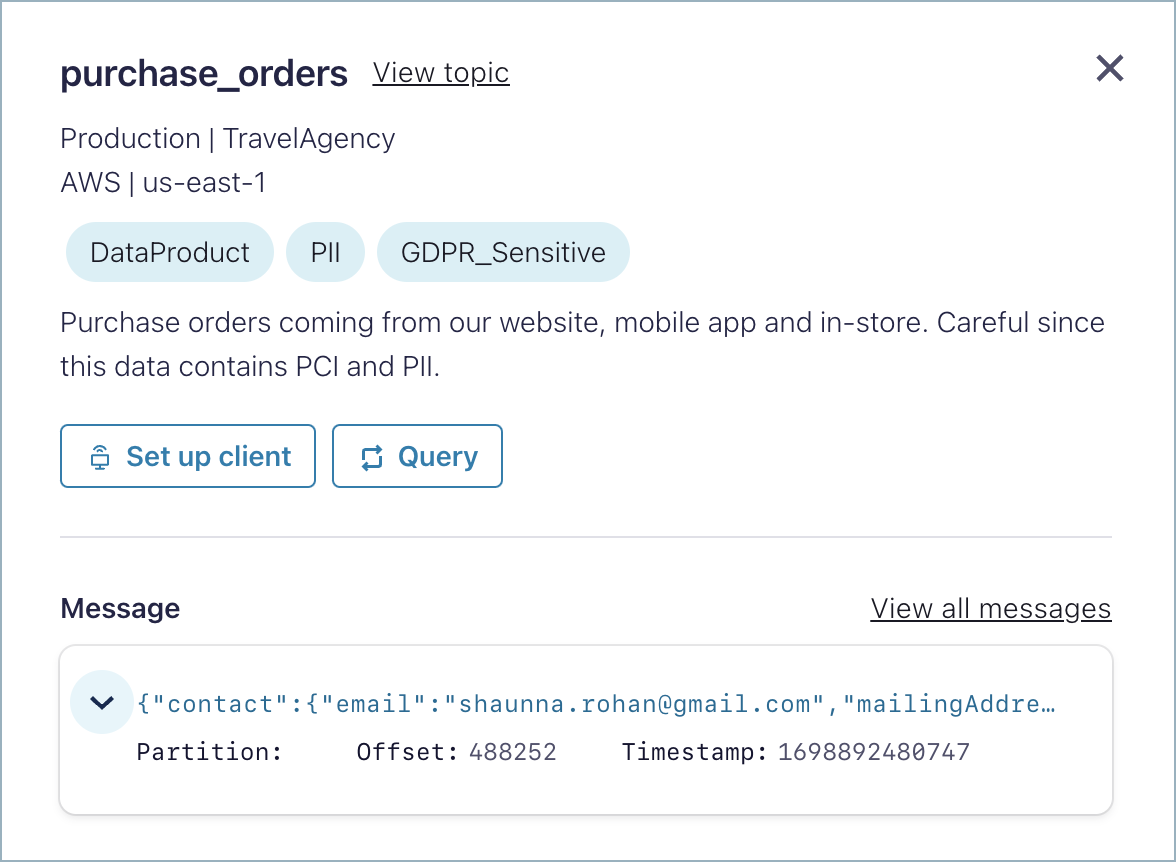
If you don’t have read access to the topic, you will see a Request access button on the actions section.
Search and discover Confluent Platform topics with USM
After you register a Confluent Platform cluster with Unified Stream Manager, all of its topics are available to view in the Data Portal. To get started, sign in to Confluent Cloud, and click Data portal on the left menu, then select the environment where your Confluent Platform cluster is located.
Each topic is displayed on a card that provides a summary, including its name, description, tags, and last modification date.
You can search for topics by name or tag. Alternatively, you can browse topics by their associated tags, creation date, or modification date.
Note
Confluent Platform topics support prefix search only. Substring, fuzzy, and wildcard search are available only for Confluent Cloud topics.
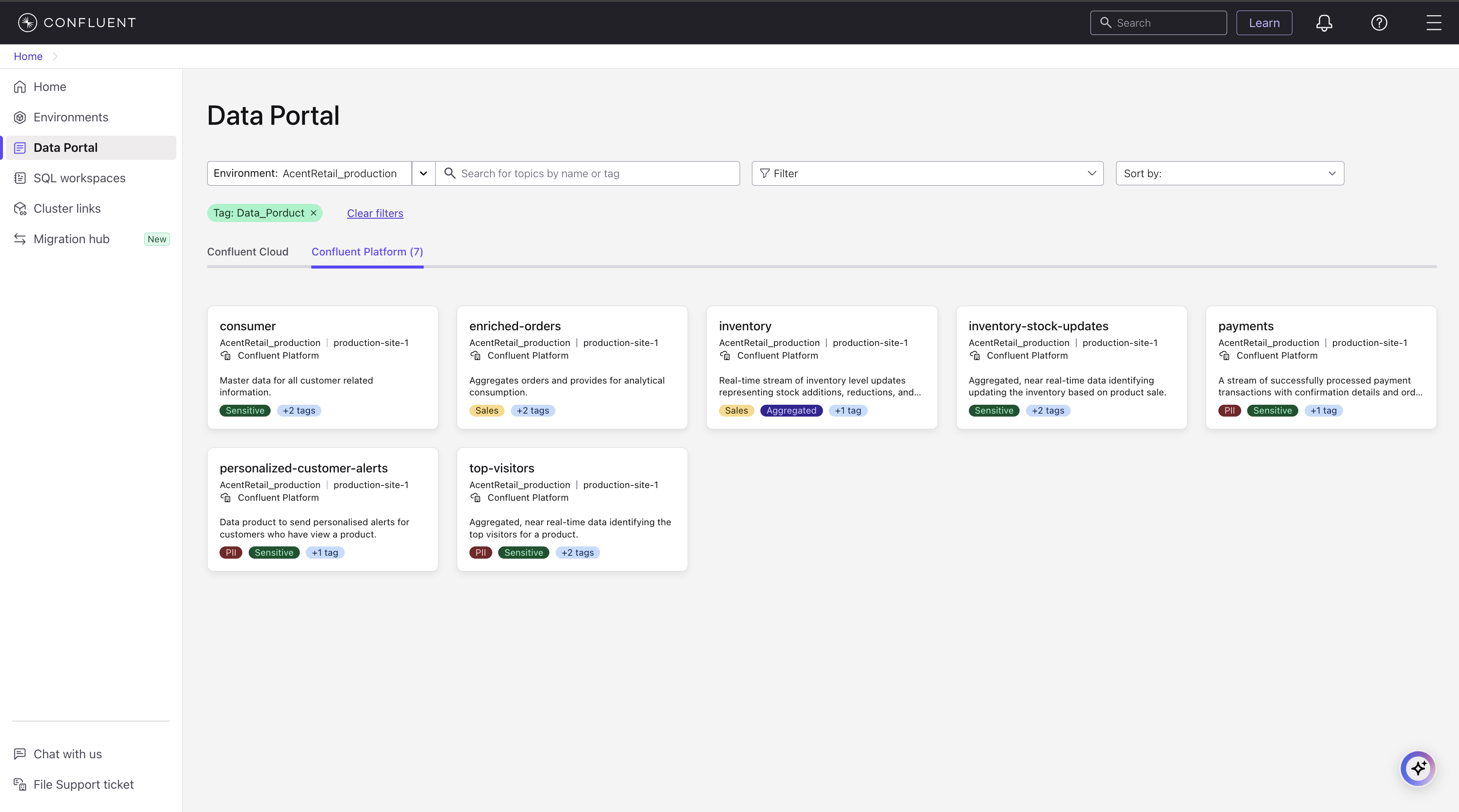
To refine your results, click any tag or the View all button to open the advanced search page. On this page, you can apply additional filters, such as tags, cluster type, connector type, and other technical metadata. You can also sort the results alphabetically, by creation date, or by modification date.
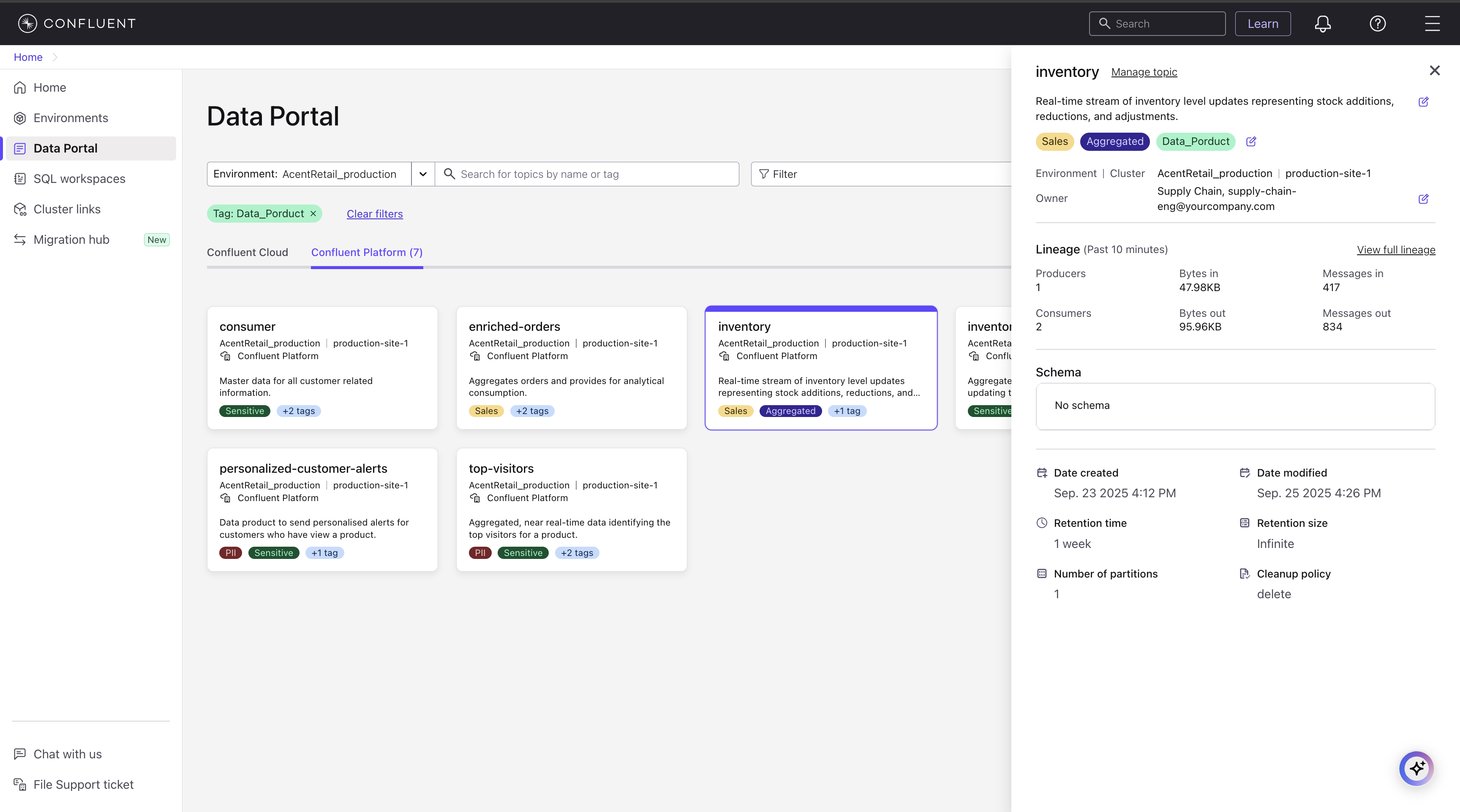
To view more details about a specific topic, click its card. A panel opens that shows a detailed summary, including the following:
Name, environment, and cluster
Description
Link to view topic Lineage
Schema, including a link to view it in full screen (if you have setup hybrid schema registry with Unified Stream Manager)
Owner’s name and email address
Technical metadata such as creation date, retention period, and more
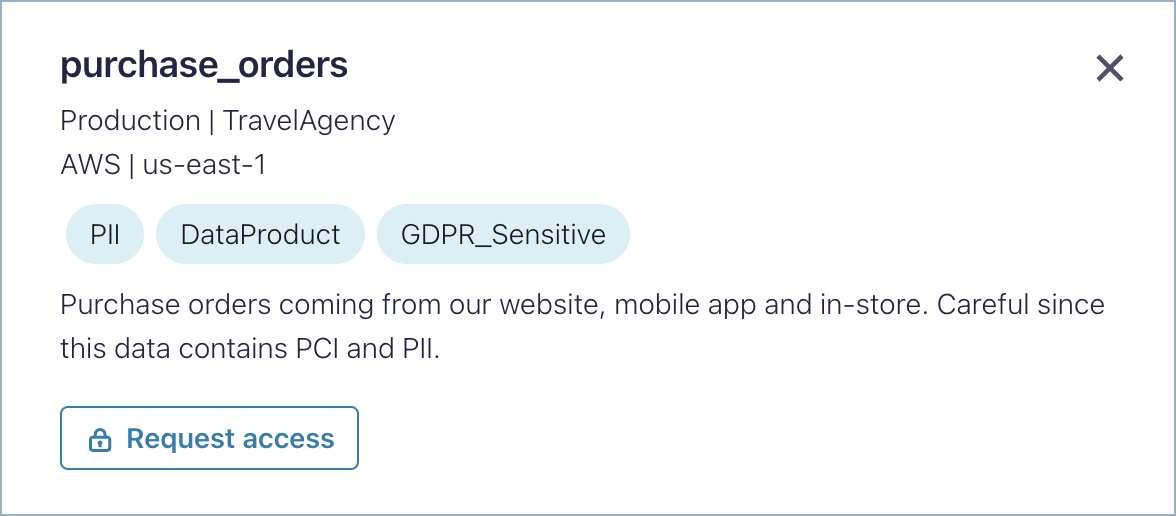
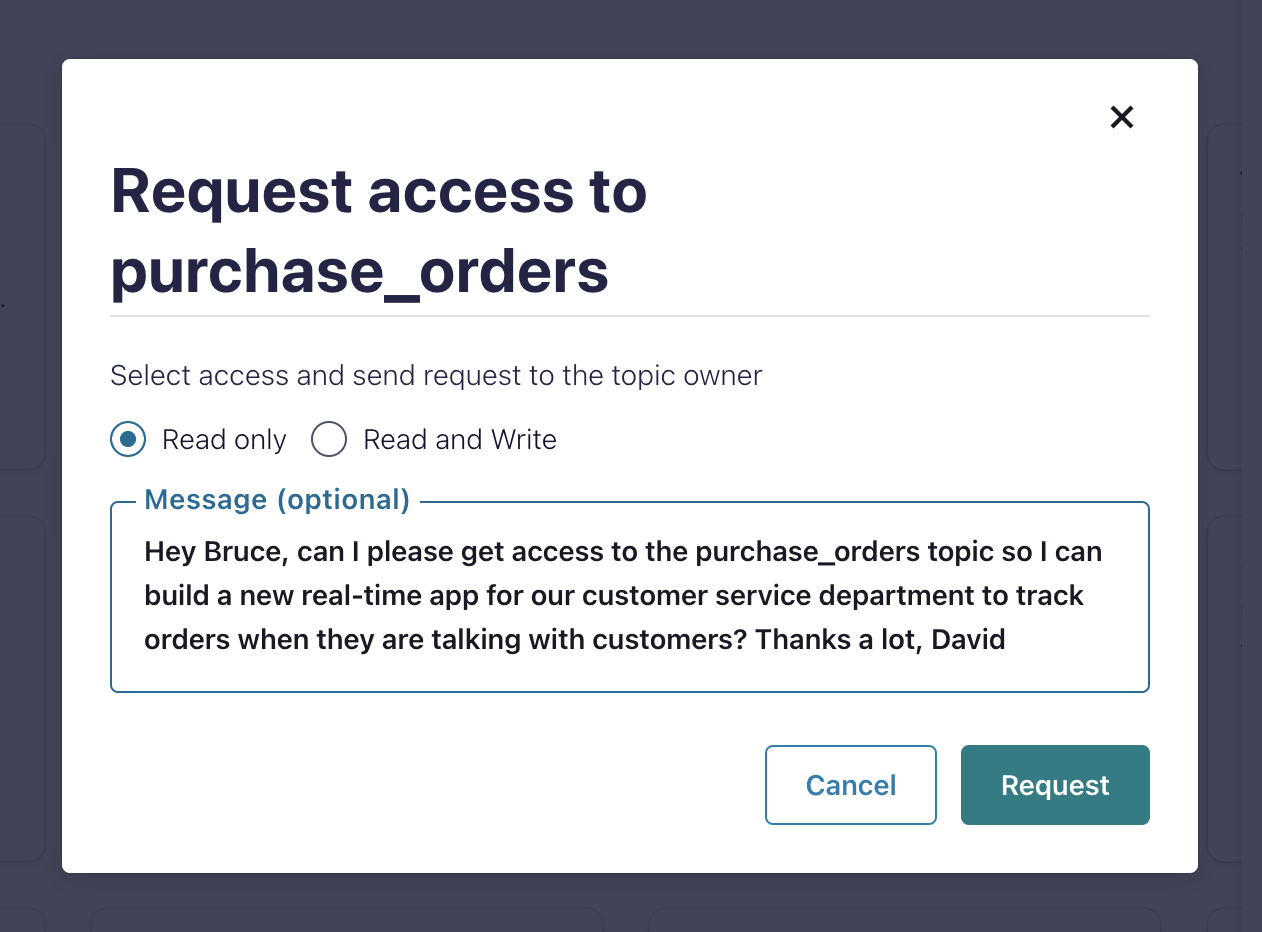
Request access to topics
When you click Request access, you are prompted to select the type of topic access you are looking for (Read only or Read and Write) and leave an optional message to the person that will review your request.
Note
This feature is not supported for Confluent Platform topics.
Read only maps to granting DeveloperRead role in RBAC, and Read and Write maps to granting DeveloperRead and DeveloperWrite roles in RBAC.
When you submit a request to access a topic, you get a confirmation message.

If the topic has an owner email, an email is sent to the topic owner with your request for access. Also, all requests show on Access requests under Accounts & access where any user with permissions to grant topic access can review.
When someone reviews your request, you will receive an email notifying you of the approval or rejection of your request.
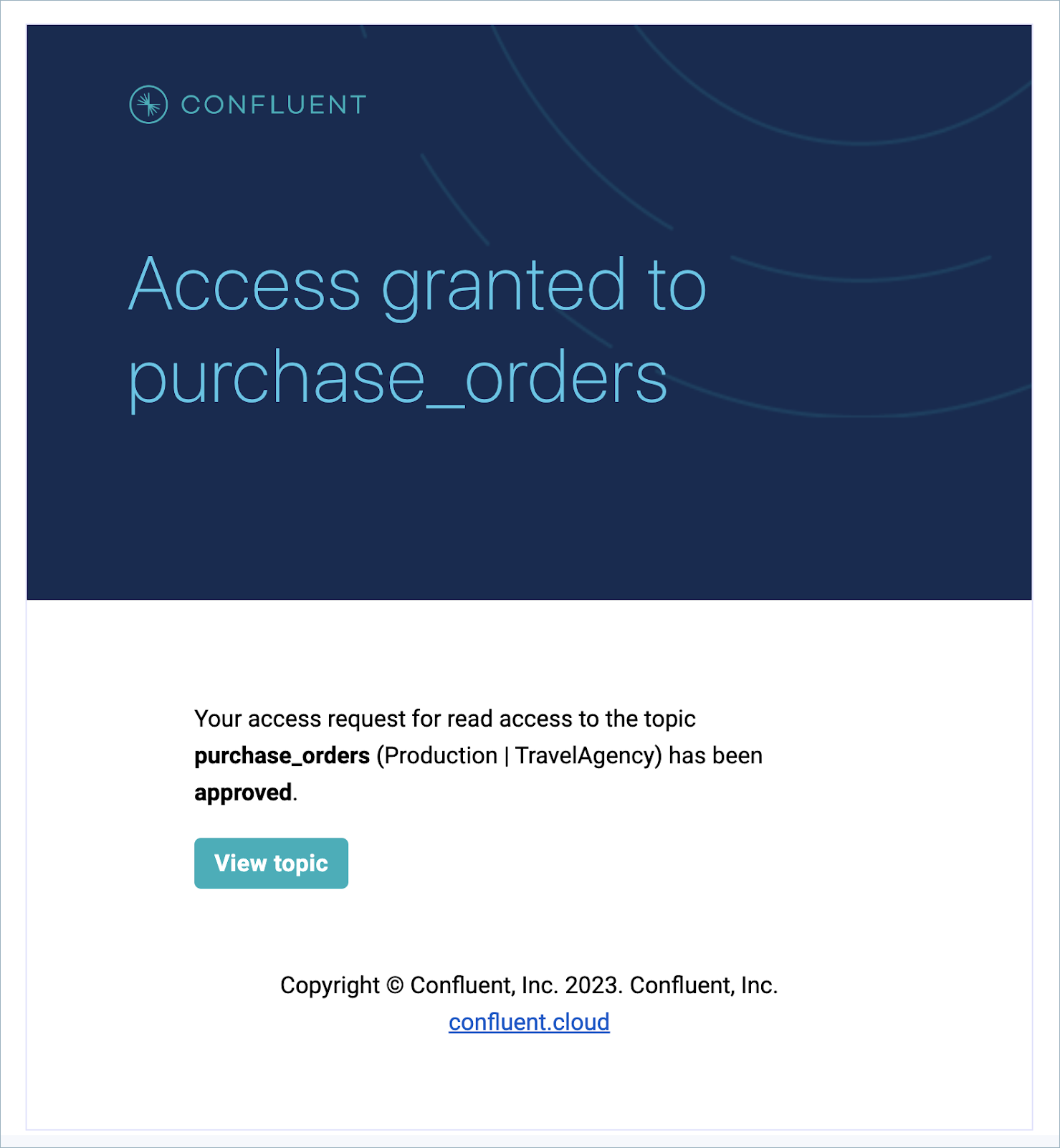
If your request is approved, your account is granted DeveloperRead and DeveloperWrite (if requested) to the topic.
Requests expire after 30 days. In this case, you will receive an email notifying you of request expiration.
You now have more visibility into the topic, and can start working with the data immediately. If you have both read and write privileges, you can develop clients to produce and consume from the topic, and query the topic with Flink SQL.
(Data Owners) Manage access to your topics
When a request for access to a topic is submitted, the topic owner receives an email to review the request (if an owner email is associated with the topic).
Note
This feature is not supported for Confluent Platform topics.
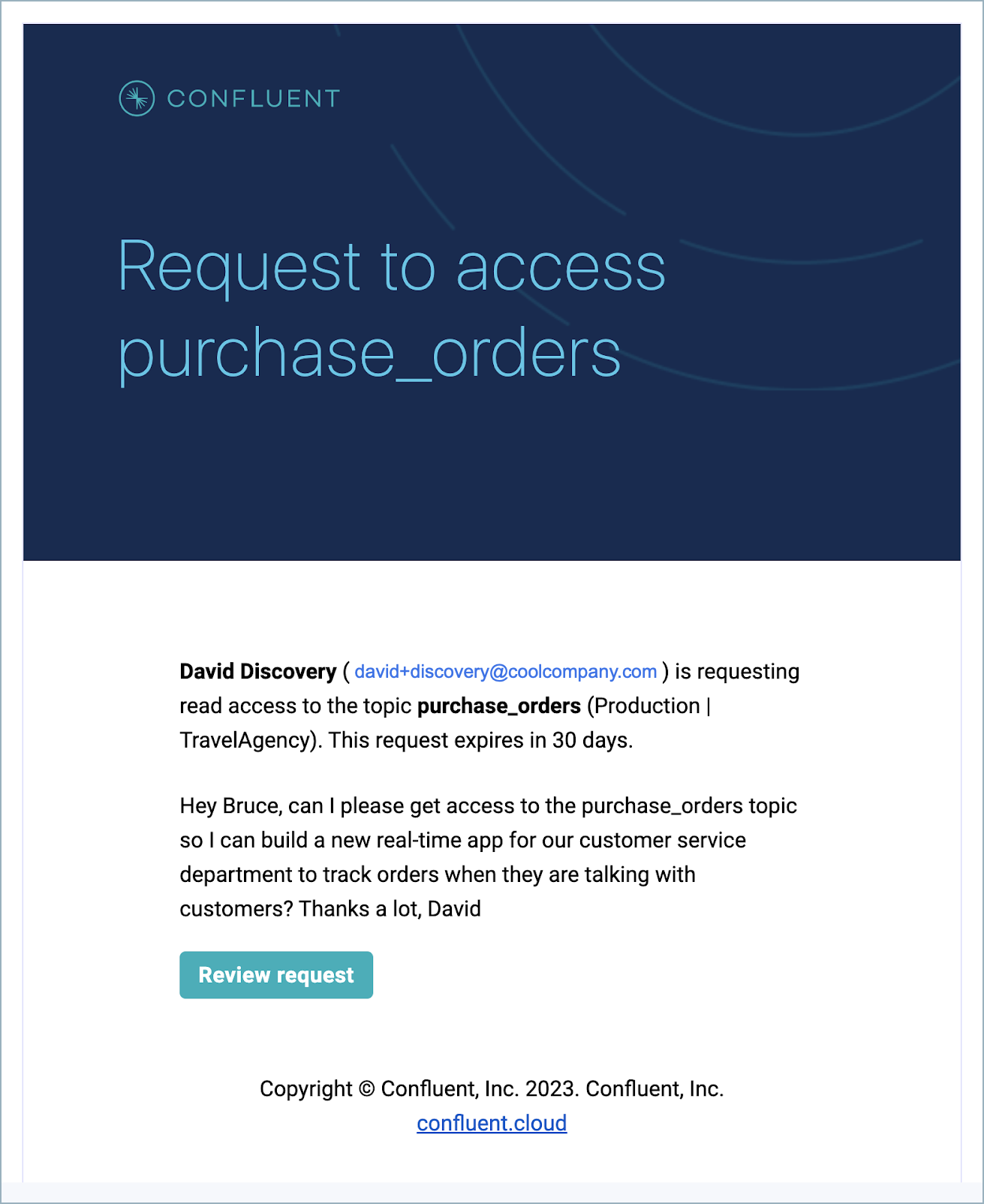
Additionally, all requests for access to topics show on the Access requests section under Accounts & access. From here, any user with permissions to grant access can approve or deny the request; for example, any admin.
The data owner of the topic or any admin can:
View the request in an approval queue, along with the message submitted by the requestor.
Approve or deny access to the topic.
Requests expire after 30 days. In this case, the requesting user receives an email notification of request expiration.
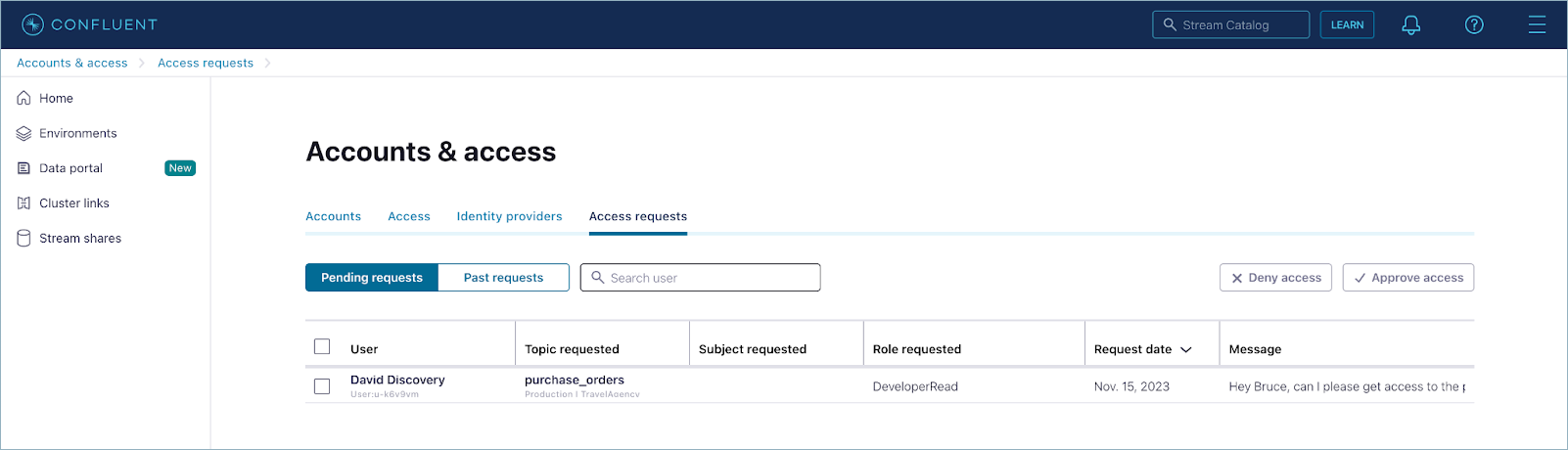
The Past requests tab under Access requests shows past requests (approved, rejected or expired) from the last 90 days.
Once the data owner or admin approves the request, the data user gets an email indicating access to the topic is granted.
View and use data in topics
With read access to the topic, you can view the last message produced and a link to the topic message browser.
Note
This feature is not supported for Confluent Platform topics.
Also, you can set up a client and query the topic with Flink SQL from the actions section on the top.
Click Set up a client to go to the clients page on the Cloud Console, where you can get the instructions to build an event-driven application in the programming language of your choice.

Click Query to work with Flink SQL. If a Flink SQL pool is pre-created in the same region of the topic, this takes you to a new workspace with a pre-selected query: SELECT * FROM <TOPIC_NAME> LIMIT 10;.
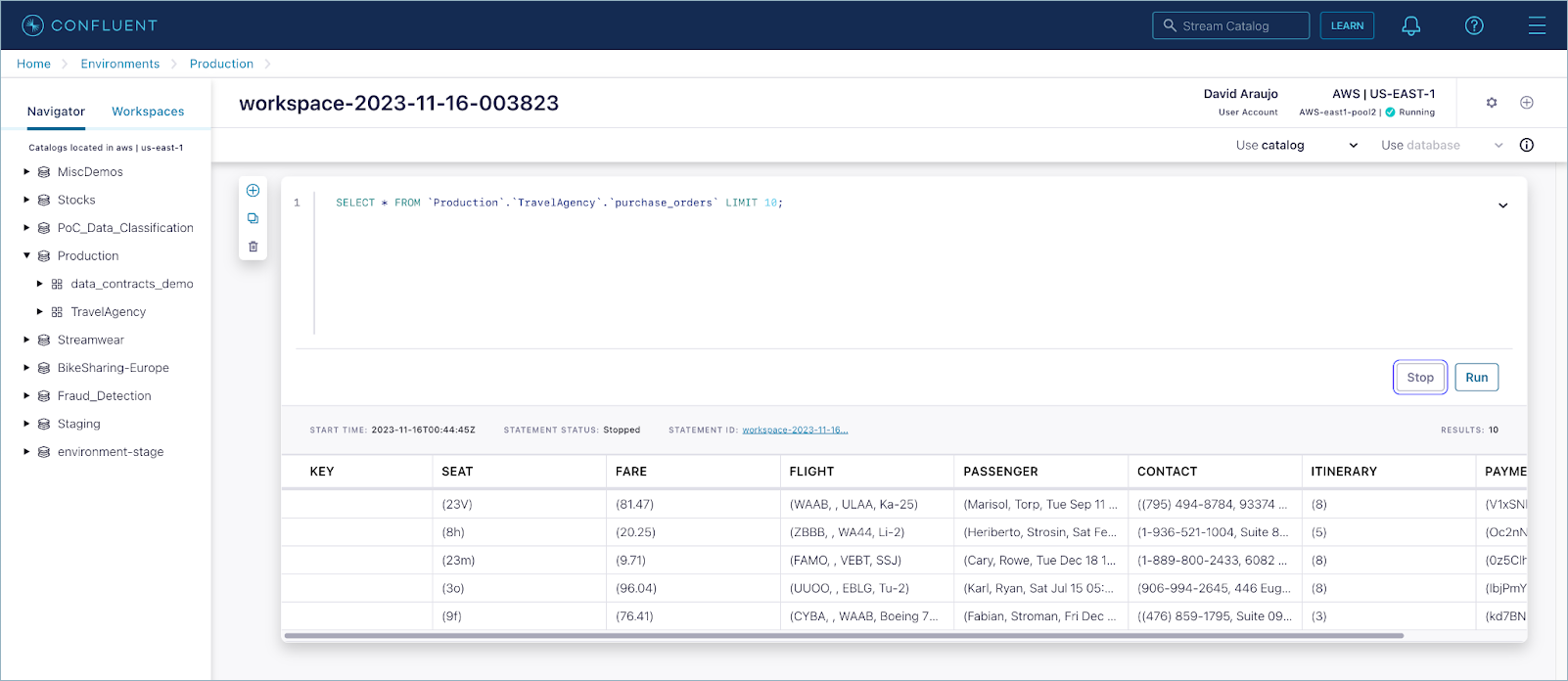
If more than one Flink SQL compute pool is created for the region of the topic, you are prompted to select one to run the query.
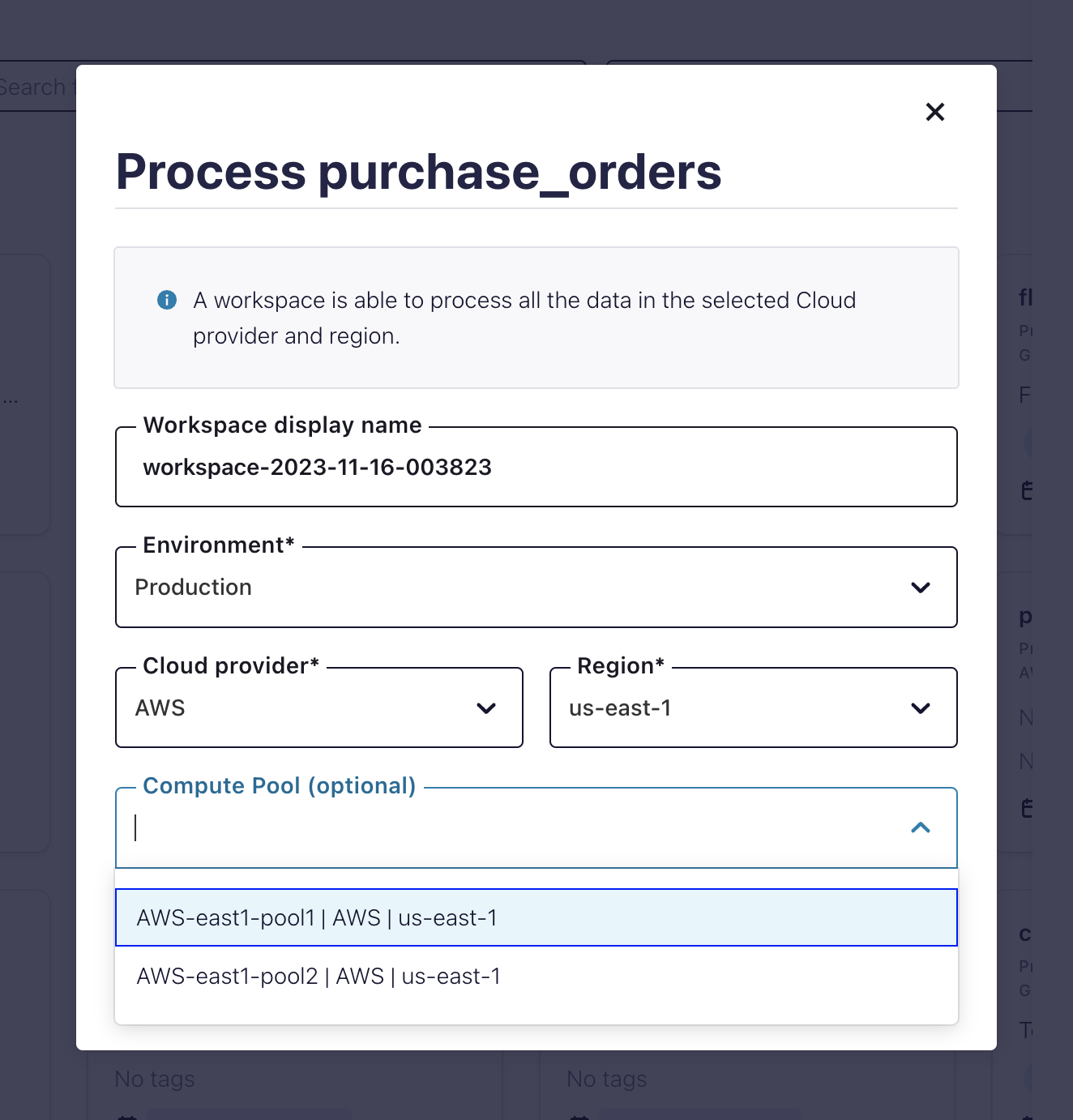
You can use Flink SQL to filter, join, and enrich your Kafka data streams. To learn more, see the blog post on Confluent Cloud for Apache Flink and the SQL documentation.