Query Tableflow Tables with DuckDB in Confluent Cloud
DuckDB is an in-process SQL database engine that can query Tableflow tables directly. Connect the local DuckDB CLI to Tableflow tables in Confluent Cloud to run SQL queries against event data stored as Apache Iceberg™ tables.
Prerequisites
A Confluent Cloud account. Sign up here: https://confluent.cloud/signup.
A Kafka topic with Tableflow enabled. For more information, see the Tableflow Quick Start.
Confluent Managed Storage: This guide assumes Tableflow is configured with Confluent Managed Storage.
Step 1: Install the DuckDB CLI
Run the following command to install the DuckDB command-line tool.
curl https://install.duckdb.org | sh
If you’re using Python, install by using pip:
pip install duckdb-cli
For other operating systems, refer to the DuckDB installation guide.
Once installed, run duckdb in your terminal to open the shell. A D> prompt indicates it is ready.
$ duckdb
v0.10.0 1f91b40b7d
Enter ".help" for usage hints.
D>
Step 2: Create your credentials
DuckDB requires three pieces of information for authentication:
CLIENT_ID: a Confluent Cloud API Key
CLIENT_SECRET: a Confluent Cloud API Secret
ENDPOINT URL: a Tableflow REST Catalog Endpoint
Confluent Cloud API key for Tableflow
Create a Tableflow API Key for your DuckDB credentials.
Log in to Confluent Cloud Console.
Open the Administration menu (
 ) and select API Keys.
) and select API Keys.Create a new Tableflow API Key for the cluster where Tableflow is enabled. For more information, see Manage API Keys.
Copy the key and secret to a secure location immediately, because the secret is not recoverable after you close the dialog. The key is your DuckDB CLIENT_ID, and the secret is your DuckDB CLIENT_SECRET, which you use in the next step.
Tableflow REST catalog endpoint
Get the Tableflow endpoint URL for your organization’s Tableflow catalog.
In Cloud Console, navigate to the Tableflow page in your Kafka cluster.
In the API access section, copy the REST Catalog Endpoint, which resembles the following example:
https://tableflow.{CLOUD_REGION}.aws.confluent.cloud/iceberg/catalog/organizations/{ORG_ID}/environments/{ENV_ID}
Cluster ID and topic name
Get the cluster ID and topic name, which are required for SELECT queries.
Cluster ID: Get the Kafka cluster ID, which resembles lkc-abc123, from your cluster’s Cluster Settings tab.
Topic name: Get the name of the Kafka topic that you want to query, for example,
test-topic-1.
Step 3: Connect DuckDB to Tableflow
The following steps are for the DuckDB shell.
Install and load the Iceberg extension
At the D> prompt, run the following commands to install and load the Iceberg extension, which is required to read the Iceberg table format.
INSTALL httpfs;
LOAD httpfs;
INSTALL iceberg;
LOAD iceberg;
INSTALLdownloads the extension. This is a one-time operation.LOADactivates it for the current session. This is required for each new session.
Create your secret
Run the following command to store your credentials as a named secret in DuckDB. Replace placeholders with the values you collected in Step 2.
CREATE SECRET iceberg_secret (
TYPE ICEBERG,
CLIENT_ID '<your-client-id>',
CLIENT_SECRET '<your-client-secret>',
ENDPOINT '<your-endpoint-url>',
OAUTH2_SCOPE 'catalog'
);
Attach the Tableflow catalog
Run the following command to attach the Iceberg Rest Catalog to the local DuckDB session.
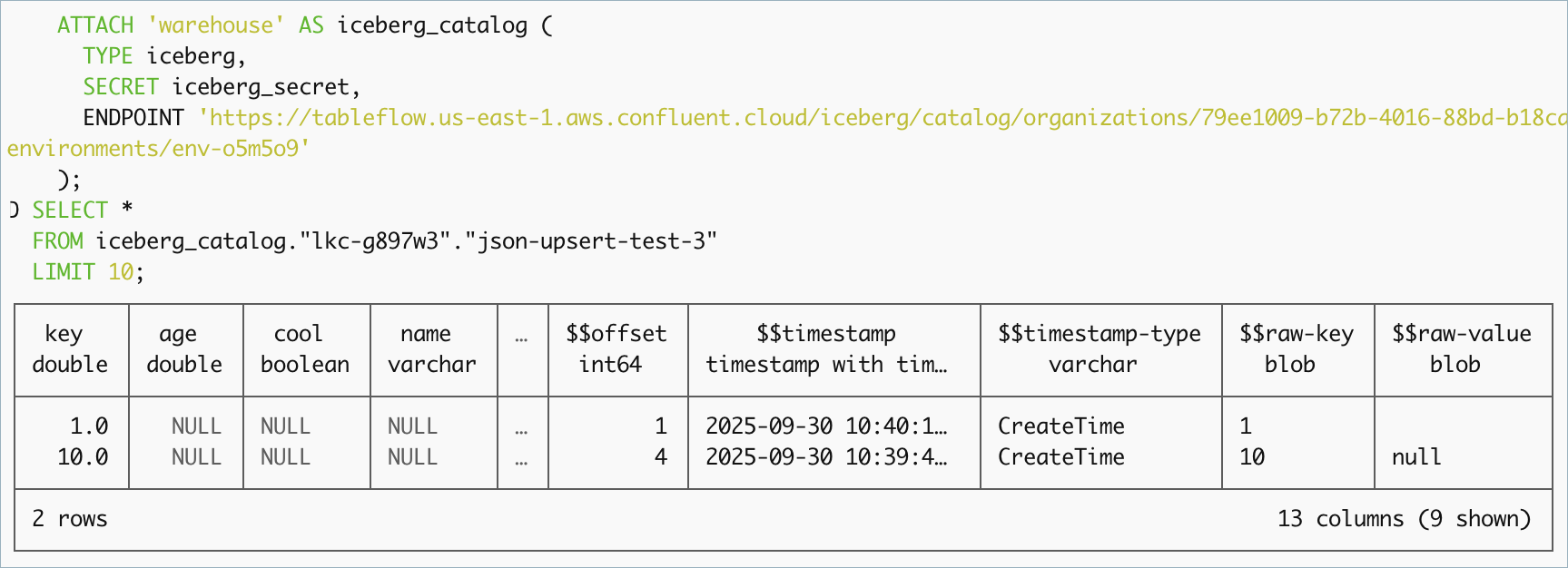
ATTACH 'warehouse' AS iceberg_catalog (
TYPE iceberg,
SECRET iceberg_secret,
ENDPOINT '<your-endpoint-url>'
);
iceberg_catalogis the local alias for referencing the catalog in queries.warehouseis a required logical name for the driver.
Note
You must provide the ENDPOINT URL in both the CREATE SECRET and ATTACH commands.
The DuckDB Iceberg Extension is experimental. After about a half-hour you may see an error when querying the warehouse: “HTTP Error: Unauthorized request to endpoint … returned an error response (HTTP 401). Reason: Unauthorized” . To work around this issue, restart the DuckDB session and recreate the secret, then re-attach the warehouse.
Step 4: Query your data
You can now run standard SQL queries against your Tableflow tables.
The query path is: "<warehouse_name>"."<cluster_id>"."<topic_name>" Replace <cluster_id> and <topic_name> with your specific values.
SELECT *
FROM iceberg_catalog."lkc-abc123"."test-topic-123"
LIMIT 10;
You can run SQL aggregations, joins, and filters directly on your Tableflow data from the DuckDB CLI.