
Formats, Serializers, and Deserializers for Schema Registry on Confluent Platform
Schema formats, serializers, and deserializers discussed here are applicable to both Confluent Cloud and Confluent Platform; however, Confluent Platform is required to develop applications using these resources. Therefore, this page refers to both Confluent Cloud and Confluent Platform as appropriate to describe the available tools and applicable use cases.
Ready to get started?
Sign up for Confluent Cloud, the fully managed cloud-native service for Apache Kafka® and get started for free using the Cloud quick start.
Download Confluent Platform, the self managed, enterprise-grade distribution of Apache Kafka and get started using the Confluent Platform quick start.
Schema Registry supports Protocol Buffers and JSON Schema along with Avro, the original default format. Support for these new serialization formats is not limited to Schema Registry, but provided throughout Confluent products. Additionally, Schema Registry is extensible to support adding custom schema formats as schema plugins.
New Kafka serializers and deserializers are available for Protobuf and JSON Schema, along with Avro. The serializers can automatically register schemas when serializing a Protobuf message or a JSON-serializable object. The Protobuf serializer can recursively register all imported schemas, .
The serializers and deserializers are available in multiple languages, including Java, .NET and Python.
Schema Registry supports multiple formats at the same time. For example, you can have Avro schemas in one subject and Protobuf schemas in another. Furthermore, both Protobuf and JSON Schema have their own compatibility rules, so you can have your Protobuf schemas evolve in a backward or forward compatible manner, just as with Avro.
Schema Registry also supports for schema references in Protobuf by modeling the import statement.
Supported formats
The following schema formats are supported out-of-the box, with serializers, deserializers, and command line tools available for each format.
Format | Producer | Consumer |
|---|---|---|
Avro | io.confluent.kafka.serializers.KafkaAvroSerializer | io.confluent.kafka.serializers.KafkaAvroDeserializer |
ProtoBuf | io.confluent.kafka.serializers.protobuf.KafkaProtobufSerializer | io.confluent.kafka.serializers.protobuf.KafkaProtobufDeserializer |
JSON Schema | io.confluent.kafka.serializers.json.KafkaJsonSchemaSerializer | io.confluent.kafka.serializers.json.KafkaJsonSchemaDeserializer |
Note
JSON and PROTOBUF_NOSR are not supported. For more details, see What’s supported in the Schema Registry overview.
Use the serializer and deserializer for your schema format. Specify the serializer in the code for the Kafka producer to send messages, and specify the deserializer in the code for the Kafka consumer to read messages.
Subject name strategies
The Protobuf and JSON Schema serializers and deserializers support many of the same configuration properties as the Avro equivalents, including subject name strategies for the key and value. In the case of the RecordNameStrategy (and TopicRecordNameStrategy), the subject name will be:
For Avro, the record fullname (namespace + record name).
For Protobuf, the message name.
For JSON Schema, the title.
When using RecordNameStrategy with Protobuf and JSON Schema, there is additional configuration that is required. This, along with examples and command line testing utilities, is covered in the deep dive sections:
Produce and consume examples
In addition to the detailed sections above, produce and consume examples are available in confluentinc/confluent-kafka-go/examples for each of the different Schema Registry SerDes.
Schema registration
The serializers and Kafka Connect converters for all supported schema formats automatically register schemas by default. The Protobuf serializer recursively registers all referenced schemas separately.
Add a format using a schema plugin
With Protobuf and JSON Schema support, the Schema Registry adds the ability to add new schema formats using schema plugins (the existing Avro support has been wrapped with an Avro schema plugin).
Client support notes
Versioning of clients to Schema Registry (whether on Confluent Cloud or Confluent Platform) tracks with Confluent Platform versions.
Schema Registry clients 7.7.4 and later include support for auto retries for 429 exceptions. A 429 exception is related to rate limiting by the Schema Registry server. When a client exceeds the set rate limit, the server responds with an HTTP 429 status code. This signals to the client that it needs to slow down its requests. Schema Registry clients built with Confluent Platform versions prior to 7.7.4 do not include support for auto retries for 429 exceptions.
Schema references
Confluent Platform (versions 5.5.0 and later) and Confluent Cloud provide full support for the notion of schema references, the ability of a schema to refer to other schemas. Support for schema references is provided for out-of-the-box schema formats: Avro, JSON Schema, and Protobuf. Schema references use the import statement of Protobuf and the $ref field of JSON Schema. Avro is also updated to support schema references.
A schema reference consists of the following:
A name for the reference. (For Avro, the reference name is the fully qualified schema name, for JSON Schema it is a URL, and for Protobuf, it is the name of another Protobuf file.)
A subject, representing the subject under which the referenced schema is registered.
A version, representing the exact version of the schema under the registered subject.
When registering a schema, you must provide the associated references, if any. Typically the referenced schemas would be registered first, then their subjects and versions can be used when registering the schema that references them.
When a schema that has references is retrieved from Schema Registry, the referenced schemas are also retrieved if needed.
See these sections for examples of schema references in each of the formats:
Multiple event types in the same topic
In addition to providing a way for one schema to call other schemas, Schema references can be used to efficiently combine multiple event types in the same topic and still maintain subject-topic constraints. Using schema references to achieve this is a new approach to putting multiple event types in the same topic.
See these sections for examples in each of the formats:
APIs
Two additional endpoints are available, as further described in the Schema Registry API.
This endpoint shows the IDs of schemas that reference the schema with the given subject and version.
GET /subjects/{subject}/versions/{version}/referencedby
This endpoint shows all subject-version pairs where the ID is used.
GET /schemas/ids/{id}/versions
Schema format extensibility
Note
Schema format extensibility is limited to Confluent Platform. This is not an option for Schema Registry on Confluent Cloud.
For a self-managed Schema Registry, such as when using Confluent Platform, you can create schema plugins to define and integrate custom schema formats.
By default, Schema Registry loads schema plugins for Avro, Protobuf, and JSON Schema. When using the REST API, specify the schema type as AVRO, PROTOBUF, or JSON, respectively.
You can create custom schema plugins by implementing the SchemaProvider and ParsedSchema interfaces. To load the custom schema plugin into Schema Registry, place the JARs for the plugins on the CLASSPATH and then use the following Schema Registry configuration property to identify the comma separated list of additional plugin provider classes to be used:
schema.providers=com.acme.MySchemaProvider
Do not include the schema plugins for AVRO, PROTOBUF, or JSON, since Schema Registry always loads them.
Subject name strategy
A serializer registers a schema in Schema Registry under a subject name, which defines a namespace in the registry:
Compatibility checks are per subject
Versions are tied to subjects
When schemas evolve, they are still associated to the same subject but get a new schema ID and version
Overview
The subject name depends on the subject name strategy. Three supported strategies include:
Strategy | Description |
|---|---|
TopicNameStrategy | Derives subject name from topic name. (This is the default.) |
RecordNameStrategy | Derives subject name from record name, and provides a way to group logically related events that may have different data structures under a topic. |
TopicRecordNameStrategy | Derives the subject name from topic and record name, as a way to group logically related events that may have different data structures under a topic. |
Note
The full class names for the above strategies consist of the strategy name prefixed by
io.confluent.kafka.serializers.subject.The subject name strategy configured on a topic in the broker for schema ID validation does not propagate to clients. The subject name strategy must be configured separately in the clients.
Group by topic or other relationships
The default naming strategy (TopicNameStrategy) names the schema based on the topic name and implicitly requires that all messages in the same topic conform to the same schema, otherwise a new record type could break compatibility checks on the topic. This is a good strategy for scenarios where grouping messages by topic name makes sense, such as aggregating logged activities or stream processing website comment threads.
The non-default naming strategies (RecordNameStrategy and TopicRecordNameStrategy) support schema management for use cases where grouping by topic isn’t optimal, for example a single topic can have records that use multiple schemas. This is useful when your data represents a time-ordered sequence of events, and the messages have different data structures. In this case, it is more useful to keep an ordered sequence of related messages together that play a part in a chain of events, regardless of topic names. For example, a financial service that tracks a customer account might include initiating checking and savings, making a deposit, then a withdrawal, applying for a loan, getting approval, and so forth.
How the naming strategies work
The following table compares the strategies.
Behavior | TopicNameStrategy | RecordNameStrategy | TopicRecordNameStrategy |
|---|---|---|---|
Subject format | <topic name> plus “-key” or “-value” depending on configuration | <fully-qualified record name> | <topic name>-<fully-qualified record name> |
Unique subject per topic | Yes | No | Yes |
Schema Registry checks compatibility across all schemas in a topic | Yes | No, checks compatibility of any occurrences of the same record name across all topics. | Yes, moreover, different topics may contain mutually incompatible versions of the same record name, since the compatibility check is scoped to a particular record name within a particular topic. |
Multiple topics can have records with the same schema | Yes | Yes | Yes |
Multiple subjects can have schemas with the same schema ID, if schema is identical | Yes | Yes | Yes |
A single topic can have multiple schemas for the same record type, i.e. schema evolution | Yes | Yes | Yes |
A single topic can have multiple record types | Not generally because a new record type could break Schema Registry compatibility checks done on the topic | Yes | Yes |
Requires client application to change setting | No, because it is already the default for all clients | Yes | Yes |
The same subject can be reused for replicated topics that have been renamed, i.e., Replicator configured with topic.rename.format | No, requires manual subject registration with new topic name | Yes | No, requires manual subject registration with new topic name |
Limitations
ksqlDB uses only the default
TopicNameStrategy, and does not currently support multiple schemas in a single topic.The Confluent Cloud Console and Confluent Platform Control Center options to view and edit schemas through the user interfaces are available only for schemas that use the default
TopicNameStrategy. The Cloud Console and the Control Center use onlyTopicNamingStrategyto associate schemas and topics. Therefore, from the topic tabs, these UIs show only schemas linked with subjects derived fromTopicNamingStrategy. Similarly, for schema side lookups, only schemas that use the default naming strategy (TopicNameStrategy) are returned and displayed. Only subject names defined as<topic name>+ “<-key>” or “<-value>” are found in lookups. For example, if a schema subject is namedmy-first-topic-value, the lookup checks for a topic namedmy-first-topic. If found, this prints in the “used by topic” section. Schema subjects using other naming strategies will not be found in lookups on the UIs.“
/” in the name of a subject is allowed, but is very cumbersome to use with the Schema Registry Maven Plugin for Confluent Platform. It requires that the XML tags be renamed using_x2Fescape sequences to replace the “/”, and even so will cause integration issues with things like topics names and some schema URIs. For best practice, use “.”, “-”, and “_” as a separator characters instead.You must escape any “natural”
_xoccurrences in subject names (for example,my_xyz_subject) because_xis interpreted by the XML parser as the start of an escape sequence (_xyz). This must be escaped with_x5F(my_x5Fxyz_subject) to be properly interpreted by the Maven plugin.
Configuration details
The Kafka serializers default to using TopicNameStrategy to determine the subject name while registering the schema.
This behavior can be modified by using the following configs:
key.subject.name.strategyDetermines how to construct the subject name under which the key schema is registered with the Schema Registry.
Any implementation of
io.confluent.kafka.serializers.subject.strategy.SubjectNameStrategycan be specified. By default, <topic>-key is used as subject. Specifying an implementation ofio.confluent.kafka.serializers.subject.SubjectNameStrategyis deprecated as of4.1.3and if used may have some performance degradation.Type: class
Default: class io.confluent.kafka.serializers.subject.TopicNameStrategy
Importance: medium
value.subject.name.strategyDetermines how to construct the subject name under which the value schema is registered with Schema Registry.
Any implementation of
io.confluent.kafka.serializers.subject.strategy.SubjectNameStrategycan be specified. By default, <topic>-value is used as subject. Specifying an implementation ofio.confluent.kafka.serializers.subject.SubjectNameStrategyis deprecated as of4.1.3and if used may have some performance degradation.Type: class
Default: class io.confluent.kafka.serializers.subject.TopicNameStrategy
Importance: medium
The other available options that can be configured out of the box include:
io.confluent.kafka.serializers.subject.RecordNameStrategyFor any record type that is published to Kafka, registers the schema in the registry under the fully-qualified record name (regardless of the topic). This strategy allows a topic to contain a mixture of different record types, since no intra-topic compatibility checking is performed. Instead, checks compatibility of any occurrences of the same record name across all topics.
io.confluent.kafka.serializers.subject.TopicRecordNameStrategyFor any record type that is published to Kafka topic
<topicName>, registers the schema in the registry under the subject name<topicName>-<recordName>, where<recordName>is the fully-qualified record name. This strategy allows a topic to contain a mixture of different record types, since no intra-topic compatibility checking is performed. Moreover, different topics may contain mutually incompatible versions of the same record name, since the compatibility check is scoped to a particular record name within a particular topic.
Protobuf is the only format that auto-registers schema references, therefore an additional configuration is provided specifically for Protobuf to supply a naming strategy for auto-registered schema references. For Avro and JSON Schema, the references are typically registered manually, so you can always choose the subject name. The behavior for Protobuf can be modified by using the following configuration.
reference.subject.name.strategyAny implementation of
io.confluent.kafka.serializers.subject.strategy.ReferenceSubjectNameStrategycan be specified. The default isDefaultReferenceSubjectNameStrategy, where the reference name is used as the subject.
Type: class
Default: class io.confluent.kafka.serializers.subject.strategy.DefaultReferenceSubjectNameStrategy
Importance: medium
Handling differences between preregistered and client-derived schemas
The following properties can be configured in any client using a Schema Registry serializer (producers, streams, Connect). These are described specifically for connectors in Kafka Connect converters, including full reference documentation in the section, Configuration Options.
auto.register.schemas- Specify if the serializer should attempt to register the schema with Schema Registry.use.latest.version- Only applies whenauto.register.schemasis set tofalse. Ifauto.register.schemasis set tofalseanduse.latest.versionis set totrue, then instead of deriving a schema for the object passed to the client for serialization, Schema Registry will use the latest version of the schema in the subject for serialization. For deserialization whenuse.latest.versionis set totrue, the deserializer will use the latest version of the schema from Schema Registry to decode future messages. However, this setting does not override the embedded schema ID in existing messages. The deserializer will still try to fetch the schema corresponding to the message’s schema ID, as shown in Wire format. If that schema ID is missing (for example, due to deletion), deserialization will fail with a schema not found.latest.compatibility.strict- The default istrue, but this only applies whenuse.latest.version=true. If both properties aretrue, a check is performed during serialization to verify that the latest subject version is backward compatible with the schema of the object being serialized. If the check fails, an error is thrown. Iflatest.compatibility.strictisfalse, then the latest subject version is used for serialization, without any compatibility check. Relaxing the compatibility requirement (by settinglatest.compatibility.stricttofalse) may be useful, for example, when using schema references.
The following table summarizes serializer behaviors based on the configurations of these three properties.
auto.register.schemas | use.latest.version | latest.compatibility.strict | Behavior |
|---|---|---|---|
true | (true or false) | (true or false) | The serializer will attempt to register the schema with Schema Registry by deriving a schema for the object passed to the client for serialization. When |
false | true | false | Schema Registry will use the latest version of the schema in the subject for serialization. |
false | true | true | The serializer performs a check to verify that the latest subject version is backward compatible with the schema of the object being serialized. If the check fails, the serializer throws an error. |
Here are two scenarios where you may want to disable schema auto-registration, and enable use.latest.version:
Using schema references to combine multiple events in the same topic - You can use Schema references as a way to combine multiple events in the same topic. Disabling schema auto-registration is integral to this configuration for Avro and JSON Schema serializers. Examples of configuring serializers to use the latest schema version instead of auto-registering schemas are provided in the sections on combining multiple event types in the same topic (Avro) and combining multiple event types in the same topic (JSON).
Ramping up production efficiency by disabling schema auto-registration and avoiding “Schema not found” exceptions - Sometimes subtle (but not semantically significant) differences can exist between a pre-registered schema and the schema used by the client when using code-generated classes from the pre-registered schema with a Schema Registry aware serializer. An example of this is with Protobuf, where a fully-qualified type name such as
google.protobuf.Timestampmay code-generate a descriptor with the type name.google.protobuf.Timestamp. Schema Registry considers these two variations of the same type name to be different. With auto-registration enabled, this would result in auto-registering two essentially identical schemas. With auto-registration disabled, this can cause a “Schema not found”. To configure the serializer to not register new schemas and ignore minor differences between client and registered schemas which could cause unexpected “Schema not found” exceptions, set these properties in your serializer configuration:auto.register.schemas=false use.latest.version=true latest.compatibility.strict=false
The
use.latest.versionsets the serializer to retrieve the latest schema version for the subject, and use that for validation and serialization, ignoring the client’s schema. The assumption is that if there are any differences between client and latest registered schema, they are minor and backward compatible.
Specifying schema ID and compatibility checks
The following properties are also configurable on Schema Registry clients.
use.schema.id- Specify the schema ID to use for serialization. By default, a numeric schema ID is auto-assigned.id.compatibility.strict- When set totrue, which is the default, Schema Registry checks for backward compatibility between the schema with the given ID and the schema of the object to be serialized.
You can configure these to transform a message value into a schema that is used to validate compatibility in the case of id.compatibility.strict=true.
Compatibility checks
For Schema Evolution and Compatibility for Schema Registry on Confluent Platform, the following compatibility levels can be defined for all schema formats:
BACKWARD
FORWARD
FULL
BACKWARD_TRANSITIVE
FORWARD_TRANSITIVE
FULL_TRANSITIVE
NONE
One of the methods in ParsedSchema is isBackwardCompatible`(ParsedSchema previousSchema). As long as a schema type uses this method to define backward compatibility for a schema type, the other types of compatibility can be derived from it.
The rules for Avro are detailed in the Avro specification under Schema Resolution.
The rules for Protobuf backward compatibility are derived from the Protobuf language specification. These are as follows:
Fields can be added. All fields in Protobuf are optional, by default. If you specify defaults, these will be used for backward compatibility.
Fields can be removed. A field number can be reused by a new field of the same type. A field number cannot be reused by a new field of a different type.
Types
int32,uint32,int64,uint64andbooltypes are compatible (can be swapped in the same field).Types
sint32andsint64are compatible (can be swapped in the same field).Types
stringandbytesare compatible (can be swapped in the same field).Types
fixed32andsfixed32are compatible (can be swapped in the same field).Types
fixed64andsfixed64are compatible (can be swapped in the same field).Type
enumis compatible withint32,uint32,int64, anduint64(can be swapped in the same field).Changing a single value into a member of a new
oneofis compatible.For string, bytes, and message fields, singular fields are compatible with repeated fields. Given serialized data of a repeated field as input, clients that expect this field to be singular will take the last input value if it is a primitive type field or merge all input elements if it is a message type field. Note that this is not generally safe for numeric types, including
boolandenum. Repeated fields of numeric types can be serialized in the packed format, which will not be parsed correctly when a singular field is expected. To learn more, see Updating a Message Type in the official ProtoBuf documentation.
The rules for JSON Schema backward compatibility are a bit more involved and so appear in the last section in the JSON Schema deep dive, under JSON Schema compatibility rules.
Schema normalization
Schema normalization is disabled by default. It is highly recommended that you enable schema normalization. This section describes how schema normalization works, and how to enable it per subject or globally.
When registering a schema or looking up an ID for a schema, Schema Registry will use the string representation of the schema for registration/lookup. Minor formatting of the string representation is performed, but otherwise the schema is left mostly the same. However, this means that two schemas that are semantically equivalent may be considered different from the perspective of Schema Registry.
If semantic (rather than syntactic) equivalence is desired, the client can ask Schema Registry to normalize the schema during registration or lookup. This can be achieved by passing a configuration parameter of normalize.schemas=true to the serializer, or a query parameter of normalize=true to the REST APIs for registration and lookup. To learn more, see POST /subjects/(string: subject)/versions and POST /subjects/(string: subject) in the Confluent Platform API reference, or Register a schema under a subject and Lookup schema under subject in the Confluent Cloud API reference.
Some of the syntactic differences that are handled by normalization include the following:
The ordering of properties in JSON Schema
The ordering of imports and options in Protobuf
The ordering of schema references
Non-qualified names vs. fully-qualified names
You can also enable schema normalization globally with the /config endpoint for Schema Registry, as described in the Confluent Platform API Reference and the Confluent Cloud API Reference.
Avro Normalization
When considering normalization with Avro, the following transformations are used to produce to an input schema’s Parsing Canonical Form. This set of transformations is similar to the Apache Avro® Canonical Form outlined in the specification under Transforming into Parsing Canonical Form, with the exception of the “STRIP” transformation. This transformation is excluded from Schema Registry Serdes because it results in data being lost (docs, default, alias fields).
Convert primitive schemas to their simple form (for example,
intinstead of{"type":"int"}).Replace short names with full names, using applicable namespaces to do so. Then eliminate namespace attributes, which are now redundant.
Order the appearance of fields of JSON objects as follows:
name,type,fields,symbols,items,values,size. For example, if an object hastype,name, andsizefields, then the namefieldshould appear first, followed by thetypeand then thesizefields.For all JSON string literals in the schema text, replace any escaped characters (such as
\uXXXXescapes) with their UTF-8 equivalents.Eliminate quotes around and any leading zeros in front of JSON integer literals (which appear in the size attributes of fixed schemas).
Eliminate extra whitespace in JSON outside of string literals.
Kafka producers and consumers for development and testing
The Confluent and open source Apache Kafka® scripts for basic actions on Kafka clusters and topics live in $CONFLUENT_HOME/etc/bin. A full reference for Confluent premium command line tools and utilities is provided in CLI Tools for Confluent Platform. These include Confluent provided producers and consumers that you can run locally against either self-managed locally installed Confluent Platform instance, against the Confluent Platform demo, or Confluent Cloud clusters. In $CONFLUENT_HOME/etc/bin, you will find:
kafka-avro-console-consumerkafka-avro-console-producerkafka-protobuf-console-consumerkafka-protobuf-console-producerkafka-json-schema-console-consumerkafka-json-schema-console-producer
These are provided in the same location along with the original, generic kafka-console-consumer and kafka-console-producer, which expect an Avro schema by default. A reference for the open source utilities is provided in Kafka Command-Line Interface (CLI) Tools.
Command-line producer, consumer utilities and JSON encoding of messages
Both Avro and Protobuf provide options to use human-readable JSON or storage-efficient binary format to encode the messages of either schema format, as described in the respective specifications:
The command line utilities (as well as REST Proxy and Confluent Control Center) make use of these JSON encodings.
These utilities live in $CONFLUENT_HOME/etc/bin.
To start the Protobuf command line producer:
kafka-protobuf-console-producer --bootstrap-server localhost:9092 --topic t1 --property value.schema='message Foo { required string f1 = 1; }'
To start the Protobuf command line consumer (at a separate terminal):
kafka-protobuf-console-consumer --topic t1 --bootstrap-server localhost:9092
You can now send JSON messages in the form: { “f1”: “some-value” }.
Likewise, to start the JSON Schema command line producer:
kafka-json-schema-console-producer --bootstrap-server localhost:9092 --topic t2 --property value.schema='{"type":"object","properties":{"f1":{"type":"string"}}}'
To start JSON Schema command line consumer:
kafka-json-schema-console-consumer --topic t2 --bootstrap-server localhost:9092
You can send JSON messages of the form { “f1”: “some-value” }.
The producers can also be passed references as either <key.refs> or <value.refs>, for example:
--property value.refs=’[ { “name”: “myName”, “subject”: “mySubject”, “version”: 1 } ]’.
More examples of using these command line utilities are provided in the “Test Drive ..” sections for each of the formats:
Print schema IDs with command line consumer utilities
You can use the kafka-avro-console-consumer, kafka-protobuf-console-consumer, and kafka-json-schema-console-consumer utilities to get the schema IDs for all messages on a topic, or for a specified subset of messages. This can be useful for exploring or troubleshooting schemas.
To print schema IDs, run the consumer with --property print.schema.ids=true and --property print.key=true. The basic command syntax for Avro is as follows:
kafka-avro-console-consumer --bootstrap-server $BOOTSTRAP_SERVER \
--property basic.auth.credentials.source="USER_INFO" \
--property print.key=true --property print.schema.ids=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property schema.registry.url=$SCHEMA_REGISTRY_URL \
--consumer.config /Users/vicky/creds.config \
--topic <topic-name> --from-beginning \
--property schema.registry.basic.auth.user.info=$SR_APIKEY:$SR_APISECRET
Note that to run this command against Confluent Cloud, you must have an API key and secret for the Kafka cluster and for the Schema Registry cluster associated with the environment. To specify the value for $BOOTSTRAP_SERVER, you must use the Endpoint URL on Confluent Cloud or the host and port as specified in your properties files for Confluent Platform.
To find the Endpoint URL on Confluent Cloud to use as the value for $BOOTSTRAP_SERVER, on the Cloud Console navigate to Cluster settings and find the URL for Bootstrap server under Endpoints. Alternatively, use the Confluent CLI command confluent kafka cluster describe to find the value given for Endpoint, minus the security protocol prefix. For Confluent Cloud, this will always be in the form of
URL:port, such aspkc-12576z.us-west2.gcp.confluent.cloud:9092.The examples use shell environment variables to indicate values for
--bootstrap-server,schema.registry.url, API key and secret, and so forth. You may want to store the values for these properties in local shell environment variables to make testing at the command line easier. (For example:export API_KEY=xyz.) You can check the contents of a variable withecho $<VAR>(for example,echo $APIKEY), then use it as such in subsequent commands and config files.The users’ credentials are in a local file called
creds.config, which contains the following information:# Required connection configs for Kafka producer, consumer, and admin bootstrap.servers=<BOOTSTRAP_SERVER> security.protocol=SASL_SSL sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<CLUSTER_API_KEY>" password="<CLUSTER_API_SECRET>"; sasl.mechanism=PLAIN # Required for correctness in Apache Kafka clients prior to 2.6 client.dns.lookup=use_all_dns_ips # Best practice for higher availability in Apache Kafka clients prior to 3.0 # This value is ignored when group.protocol=consumer is set. session.timeout.ms=45000 # Best practice for Kafka producer to prevent data loss acks=all
The subsequent examples use basic authentication and API keys. To learn more about authentication on Confluent Cloud, see security/authenticate/workload-identities/service-accounts/api-keys/manage-api-keys.html#add-an-api-key. To learn more about authentication on Confluent Platform, see Use HTTP Basic Authentication in Confluent Platform.
Avro consumer
For example, to consume messages from the beginning (--from-beginning) from the stocks topic on a Confluent Cloud cluster:
./bin/kafka-avro-console-consumer --bootstrap-server $BOOTSTRAP_SERVER \
--property basic.auth.credentials.source="USER_INFO" \
--property print.key=true --property print.schema.ids=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property schema.registry.url=$SCHEMA_REGISTRY_URL \
--consumer.config /Users/vicky/creds.config \
--topic stocks --from-beginning \
--property schema.registry.basic.auth.user.info=$SR_APIKEY:$SR_APISECRET
This results in output similar to the following, with the schema ID showing at the end of each message line:
...
ZVZZT {"side":"SELL","quantity":1546,"symbol":"ZVZZT","price":629,"account":"ABC123","userid":"User_4"} 100008
ZJZZT {"side":"SELL","quantity":765,"symbol":"ZJZZT","price":140,"account":"ABC123","userid":"User_2"} 100008
ZJZZT {"side":"BUY","quantity":2977,"symbol":"ZJZZT","price":264,"account":"ABC123","userid":"User_9"} 100008
...
To drill down on a particular subset of messages, determine the offset and partition you want to focus on. You can use the Confluent Cloud Console to navigate to a particular offset and partition.
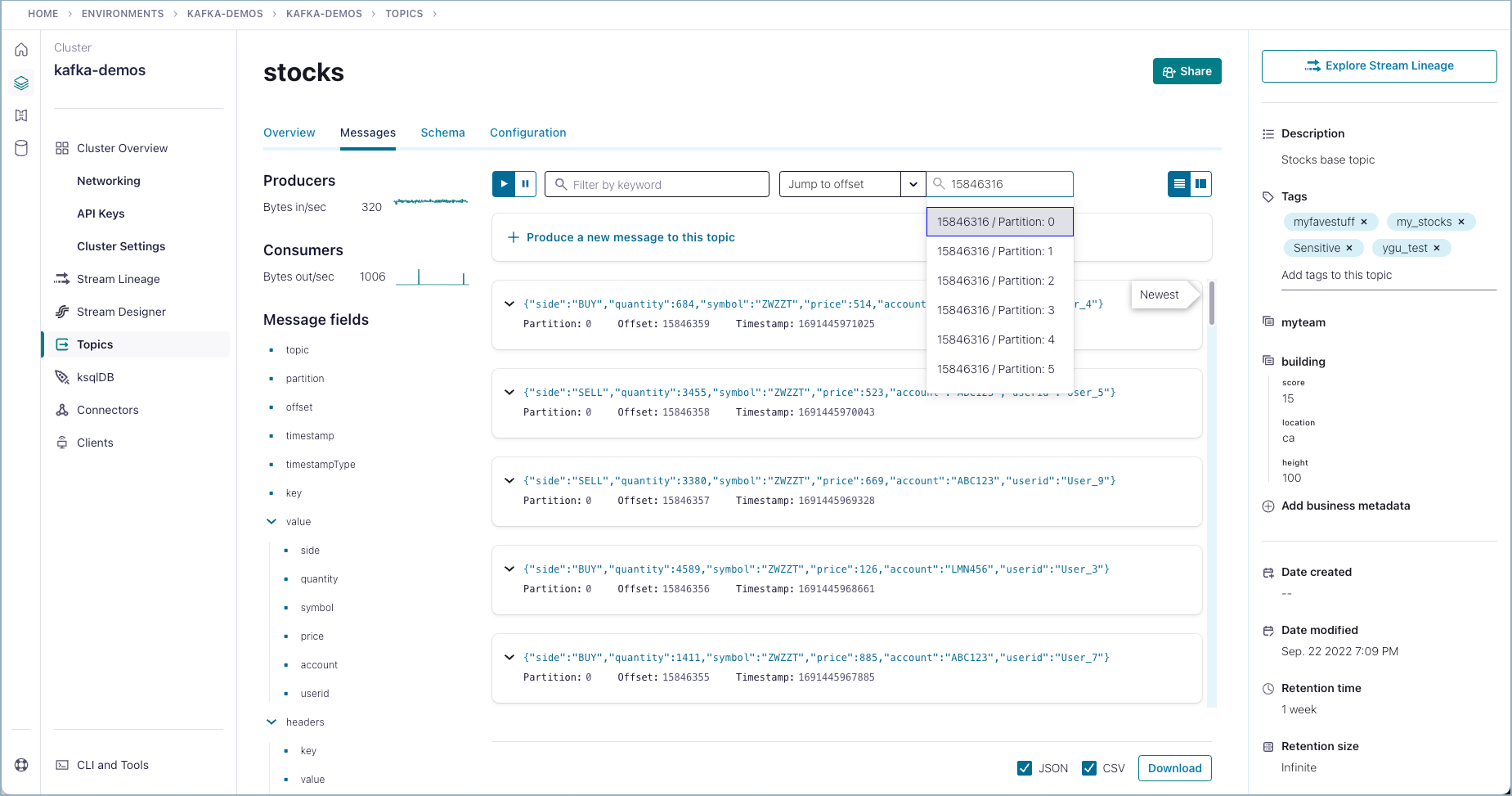
For example, to show messages to the stocks topic, starting at offset 15846316 on partition 0, replace from --from-beginning in the command with the --offset and --partition numbers you want to explore. To limit the number of messages, you can add a value for --max-messages such as 5 in the example:
./bin/kafka-avro-console-consumer --bootstrap-server $BOOTSTRAP_SERVER \
--property basic.auth.credentials.source="USER_INFO" \
--property print.key=true --property print.schema.ids=true \
--offset 15846316 --partition 0 --max-messages 5 \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property schema.registry.basic.auth.user.info=$SR_APIKEY:$SR_APISECRET \
--consumer.config /Users/vicky/creds.config --topic stocks \
--property schema.registry.basic.auth.user.info=$SR_APIKEY:$SR_APISECRET
The output for this example is:
....
ZWZZT {"side":"SELL","quantity":1905,"symbol":"ZWZZT","price":33,"account":"LMN456","userid":"User_9"} 100008
ZVV {"side":"BUY","quantity":4288,"symbol":"ZVV","price":795,"account":"XYZ789","userid":"User_9"} 100008
ZVV {"side":"BUY","quantity":235,"symbol":"ZVV","price":918,"account":"ABC123","userid":"User_7"} 100008
ZWZZT {"side":"BUY","quantity":3041,"symbol":"ZWZZT","price":759,"account":"LMN456","userid":"User_3"} 100008
ZVV {"side":"BUY","quantity":3080,"symbol":"ZVV","price":79,"account":"XYZ789","userid":"User_7"} 100008
Processed a total of 5 messages
Protobuf consumer
The command for a Protobuf consumer to print schema IDs for all messages from the beginning to a specified topic is:
kafka-protobuf-console-consumer --bootstrap-server $BOOTSTRAP_SERVER \
--property basic.auth.credentials.source="USER_INFO" \
--property print.key=true --property print.schema.ids=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property schema.registry.url=$SCHEMA_REGISTRY_URL --consumer.config <path-to-config-file> \
--topic <topic-name> --from-beginning \
--property schema.registry.basic.auth.user.info=$SR_APIKEY:$SR_APISECRET
JSON Schema consumer
The analogous command for a JSON Schema consumer to print schema IDs for all messages from the beginning to a specified topic is:
kafka-json-schema-console-consumer --bootstrap-server $BOOTSTRAP_SERVER \
--property basic.auth.credentials.source="USER_INFO" \
--property print.key=true --property print.schema.ids=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property schema.registry.url=$SCHEMA_REGISTRY_URL --consumer.config <path-to-config-file> \
--topic <topic_name> --from-beginning \
--property schema.registry.basic.auth.user.info=$SR_APIKEY:$SR_APISECRET
Use API calls to print schema IDs
It’s worth noting that another way to get schema IDs is to use an API call (instead of the local consumer).
Given a similar setup as described above, where you are running commands against a Confluent Cloud cluster and Schema Registry, the following API call returns the schema ID and latest version of the associated schema for the subject stocks-value.
curl -u $SR_APIKEY:$SR_APISECRET --request GET --url $SCHEMA_REGISTRY_URL/subjects/stocks-value/versions/latest
To see more API usage examples, refer to:
Troubleshoot Avro records producers on Confluent Platform 7.5.2 and 7.4.3
This applies to the named versions of Confluent Platform only, not Confluent Cloud.
With Confluent Platform versions 7.5.2 and 7.4.3 of io.confluent.kafka-avro-serialize a failure to serialize a schema with some logicalTypes can occur such as timestamp-millis. One or more of the following exceptions might occur when producing Avro records using io.confluent.kafka-avro-serialize using Avro schema with logicalType (with both Kafka REST Proxy and with kafka-avro-console-producer).
Example producer code
{
"name": "createdDate",
"type": {
"logicalType": "timestamp-millis",
"type": "long"
}
}
Example errors returned
error serializing Avro message
Or,
java.lang.ClassCastException: class java.time.Instant cannot be cast to class java.lang.Number
Caused by: org.apache.avro.AvroRuntimeException: Unknown datum type java.time.Instant
Or, the following error might be observed when using Kafka RestProxy to produce records:
{"error_code":40801,"message":"Error serializing Avro message"}
Solution
This misbehavior is fixed with the release of Confluent Platform 7.5.3 and 7.4.4, but you must add the kafka-avro-console-producer property:
--property avro.use.logical.type.converters=true
The REST Proxy does not support setting the above property as of now.
This is resolved in REST Proxy 7.7.0. Until this fix is backported, use the REST Proxy 7.4.2-(2 or lower) or 7.5.1-(1 or lower) as an interim workaround to avoid this issue altogether.
Basic authentication security for producers and consumers
Schema Registry supports the ability to authenticate requests using Basic authentication headers. You can send the Basic authentication headers by setting the following configuration in your producer or consumer example.
An example of using a credentials file to authenticate a consumer to Schema Registry is shown above in Print schema IDs with command line consumer utilities.
For more examples and details on credentials files on both Confluent Cloud and Confluent Platform, see the “Prerequisites” sections in each of the “Test Drives” for the different schema formats:
For details on all Schema Registry client configuration options, see Configuration Reference for Schema Registry Clients on Confluent Cloud and Configuration Reference for Schema Registry Clients on Confluent Platform.
Wire format
Wire format can take the form of a schema ID in the header or in the payload prefix.
Wire format: schema ID in the payload prefix
In most cases, you can use the serializers and formatter directly and not worry about the details of how messages are mapped to bytes. However, if you’re working with a language that Confluent has not developed serializers for, or simply want a deeper understanding of how the Confluent Platform works, here is more detail on how data is mapped to low-level bytes.
The wire format currently has only a couple of components:
Bytes | Area | Description |
|---|---|---|
0 | Version Byte | Confluent serialization format version number, which is 0 when using the schema ID (the default). |
1-4 | Schema ID | 4-byte schema ID as returned by Schema Registry. |
5-x | Messaging index | For Protobuf, an array of indexes that correspond to the message type. Otherwise, this is empty. |
x+1… | Data | The data for the specified schema format (for example, binary encoding for Avro or Protocol Buffers). The only exception is raw bytes, which will be written directly without any special encoding. |
Important
The schema ID is encoded with big-endian ordering; that is, standard network byte order.
The wire format applies to both Kafka message keys and message values.
The Protobuf serialization format appends a list of message indexes after the version-byte and schema-id. The message indexes are an array of indexes that corresponds to the message type (which may be nested). A single Schema Registry Protobuf entry may contain multiple Protobuf messages, some of which may have nested messages. The role of message-indexes is to identify which Protobuf message in the Schema Registry entry to use. For example, given a Schema Registry entry with the following definition:
package test.package;
message MessageA {
message Message B {
message Message C {
...
}
}
message Message D {
...
}
message Message E {
message Message F {
...
}
message Message G {
...
}
...
}
...
}
message MessageH {
message MessageI {
...
}
}
The array [1, 0] is (reading the array backwards) the first nested message type of the second top-level message type, corresponding to test.package.MessageH.MessageI. Similarly [0, 2, 1] is the second message type of the third message type of the first top-level message type corresponding to test.package.MessageA.MessageE.MessageG.
The message indexes are encoded as int using variable-length zigzag encoding, prefixed by the length of the array, which is also a variable length, zigzag encoded. The message index encoding is the same as Avro,as described in Binary encoding in the Avro specification.
Given this, the above example array [1, 0] is encoded as the variable length integers 2,1,0 where the first 2 is the length.
Also, since most of the time the actual message type is the first message type (the array [0]), which would normally be encoded as 1,0 (1 for length), this special case is optimized to simply 0. In the most common case of the first message type being used, a single 0 is encoded as the message-indexes.
Messages with null keys or values will pass broker-side schema ID validation, as described in the sections on Confluent Cloud and Confluent Platform:
Wire format: schema GUID in header
As of Confluent Platform 8.1.1, you can change the wire format to not emit the schema ID in the payload prefix. This helps with migration scenarios, when a client that is not currently using Schema Registry wants to start using it. Such clients have only the serialized data in the message key or value, and adapting a format that has the schema ID and other schema metadata in the payload prefix would be a breaking change.
Instead, one can ask that the metadata for the schema be placed in the message header. In this case, the metadata in the header will contain a 16-byte schema GUID instead of the 4-byte schema ID.
Bytes | Area | Description |
|---|---|---|
0 | Version Byte | Confluent serialization format version number, which is 1 when using the schema GUID. |
1-16 | Schema ID | 16-byte schema GUID as returned by Schema Registry. |
5-x | Message indexes | For Protobuf, an array of indexes that correspond to the message type. |
The 16-byte GUID is based on a fingerprint of the schema (including schema references, rules, and metadata) that is generated by Schema Registry. Two schemas that are exactly the same (including schema references, rules, and metadata) will have the same fingerprint regardless of which Schema Registry the schema was registered with. When using the Schema Registry APIs, the GUID will appear in the 8-4-4-4-12 hexadecimal format, such as “xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx”, where every x represents 4 bits. In addition, there is a Schema Registry API endpoint, /schemas/guids/{guid}, which can be used to retrieve a schema based on its fingerprint GUID.
To enable the use of the schema GUID in the header, use one or both of the following properties.
key.schema.id.serializer=io.confluent.kafka.serializers.schema.id.HeaderSchemaIdSerializer
value.schema.id.serializer=io.confluent.kafka.serializers.schema.id.HeaderSchemaIdSerializer
Important
Starting with Confluent Platform 8.1.1, the default behavior of Schema Registry deserializers has changed. Before, the deserializer would look for the schema ID in the payload prefix. Now, the deserializer looks for the schema GUID in the header, and if not found, then looks for the schema ID in the payload prefix.
Migrating to use of schema GUID in header
Follow the correct upgrade order (producers first vs. consumers first) to maintain compatibility during rollout.
Starting with custom serialized Avro, Protobuf, or JSON data and no Schema Registry
Upgrade order: producers → consumers.
Producers: Adopt Schema Registry serializers for your chosen format and add the header schema serializer setting. Older consumers that ignore headers will continue to work while you roll out producers.
// Producer (JSON Schema example) props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "io.confluent.kafka.serializers.JSONSchemaSerializer"); props.put("value.schema.id.serializer", "io.confluent.kafka.serializers.schema.id.HeaderSchemaIdSerializer");
Consumers: Adopt Schema Registry Avro, Protobuf or JSON deserializer; deserializers check header first, then payload (for backward compatibility). With producers already writing the header, consumers will find the schema in headers after upgrade.
Starting with Schema Registry and schema ID in payload prefix
Upgrade order: consumers → producers.
Consumers: upgrade first so they can read either header or payload; existing producers will keep writing the ID in the payload prefix until you finish consumer upgrades.
Producers: switch to header mode by adding the header schema serializer; keep using your existing Avro/Protobuf/JSON serializer class, schema compatibility, and subject naming as before.
// Producer (Avro example) props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "io.confluent.kafka.serializers.KafkaAvroSerializer"); props.put("value.schema.id.serializer", "io.confluent.kafka.serializers.schema.id.HeaderSchemaIdSerializer");
Rollout guidance
Use canary producers/consumers to validate header reads while keeping legacy readers working via header ignorance (without Schema Registry) or consumer fallback (with Schema Registry).
For Protobuf subjects with multiple message types, confirm message‑indexes behavior in integration tests across nested messages to ensure correct deserialization post‑migration.
- Plan a staggered deployment per application or team to limit blast radius and simplify rollbacks.
Reverting producers to payload ID or reverting consumers to legacy behavior is non‑breaking with the recommended upgrade order.
Known behaviors and notes
Default consumer behavior change in Confluent Platform 8.1.1+: deserializers prefer header GUID, then fall back to payload ID if header is absent. This is intentional to support rolling upgrades.
Kafka Streams support: in Confluent Platform 8.3 (Kafka Streams 4.3), headers-aware state stores preserve record headers. In Confluent Platform 8.2 and earlier, Kafka Streams state stores drop headers. For configuration and limitations, see Limitations of schema GUID in header.
ksqlDB support: if your ksqlDB applications rely on legacy payload ID parsing semantics, verify compatibility before rollout. ksqlDB support might be limited with header-only identification.
End‑to‑end examples
Producer (Avro) with header GUID
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "<brokers>");
props.put("schema.registry.url", "<sr-url>");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"io.confluent.kafka.serializers.KafkaAvroSerializer");
// Put schema identifier in Kafka header (value side)
props.put("value.schema.id.serializer",
"io.confluent.kafka.serializers.schema.id.HeaderSchemaIdSerializer");
Consumer (header‑first fallback to payload)
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "<brokers>");
props.put("schema.registry.url", "<sr-url>");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
"io.confluent.kafka.serializers.KafkaAvroDeserializer");
// No special config needed for header-first; CP 8.1.1+ deserializers check header, then fall back to the legacy payload prefix automatically.
Limitations of schema GUID in header
Kafka Streams state stores: In Confluent Platform 8.2 and earlier, state stores drop record headers, which causes deserialization by downstream applications to fail when using header-based schema identification.
Starting in Confluent Platform 8.3 (Kafka Streams 4.3), headers-aware state stores preserve record headers through state store operations. To use schema GUIDs in headers with Kafka Streams, set
dsl.store.format=HEADERSin your Kafka Streams application configuration. This enables Kafka Streams applications to adopt Schema Registry without modifying existing data, because schema identifiers are stored in record headers (metadata) rather than in the payload prefix.The following Kafka Streams DSL operations do not support headers-aware state stores in Confluent Platform 8.3:
suppress()Left and outer stream-stream joins
Versioned state stores
When using ksqlDB, headers might be dropped by state stores, which causes deserialization by downstream applications to fail.
When using Kafka Connect, verify that the Connect configurations are properly preserving the header, and not performing transformations on it.
Changing from the use of the ID in the payload prefix to the GUID in the header for a record key might cause partitioning to be different for the same raw key, which might cause downstream queries to fail.
When using Schema Linking, do not use any configurations that might change the body of the schema (such as
kekRenameFormat), as this causes the GUID to differ between the source and destination Schema Registry clusters, leading to deserialization errors.
Compatibility guarantees across Confluent Platform versions
The serialization format used by Confluent Platform serializers is guaranteed to be stable over major releases. No changes are made without advanced warning. This is critical because the serialization format affects how keys are mapped across partitions. Since many applications depend on keys with the same logical format being routed to the same physical partition, it is usually important that the physical byte format of serialized data does not change unexpectedly for an application. Even the smallest modification can result in records with the same logical key being routed to different partitions because messages are routed to partitions based on the hash of the key.
To prevent variation even as the serializers are updated with new formats, the serializers are very conservative when updating output formats. To guarantee stability for clients, Confluent Platform and its serializers ensure the following:
The format (including magic byte) will not change without significant warning over multiple Confluent Platform major releases. Although the default may change infrequently to allow adoption of new features by default, this will be done very conservatively and with at least one major release between changes, during which the relevant changes will result in user-facing warnings to make sure users are not caught off guard by the need for transition. Significant, compatibility-affecting changes will guarantee at least 1 major release of warning and 2 major releases before an incompatible change is made.
Within the version specified by the magic byte, the format will never change in any backwards-incompatible way. Any changes made will be fully backward compatible with documentation in release notes and at least one version of warning provided if it introduces a new serialization feature that requires additional downstream support.
Deserialization will be supported over multiple major releases. This does not guarantee indefinite support, but support for deserializing any earlier formats will be supported indefinitely as long as there is no notified reason for incompatibility.
For more information about compatibility or support, reach out to the community mailing list.