
What is Confluent Platform?
Confluent Platform is a full-scale data streaming platform that enables you to easily access, store, and manage data as continuous, real-time streams. Built by the original creators of Apache Kafka®, Confluent expands the benefits of Kafka with enterprise-grade features while removing the burden of Kafka management or monitoring. Today, over 80% of the Fortune 100 are powered by data streaming technology – and the majority of those leverage Confluent.
Looking for a fully managed cloud-native service for Apache Kafka®?
Sign up for Confluent Cloud and get started for free using the Cloud quick start.
Why Confluent?
By integrating historical and real-time data into a single, central source of truth, Confluent makes it easy to build an entirely new category of modern, event-driven applications, gain a universal data pipeline, and unlock powerful new use cases with full scalability, performance, and reliability.
What is Confluent Used For?
Confluent Platform lets you focus on how to derive business value from your data rather than worrying about the underlying mechanics, such as how data is being transported or integrated between disparate systems. Specifically, Confluent Platform simplifies connecting data sources to Kafka, building streaming applications, as well as securing, monitoring, and managing your Kafka infrastructure. Today, Confluent Platform is used for a wide array of use cases across numerous industries, from financial services, omnichannel retail, and autonomous cars, to fraud detection, microservices, and IoT.
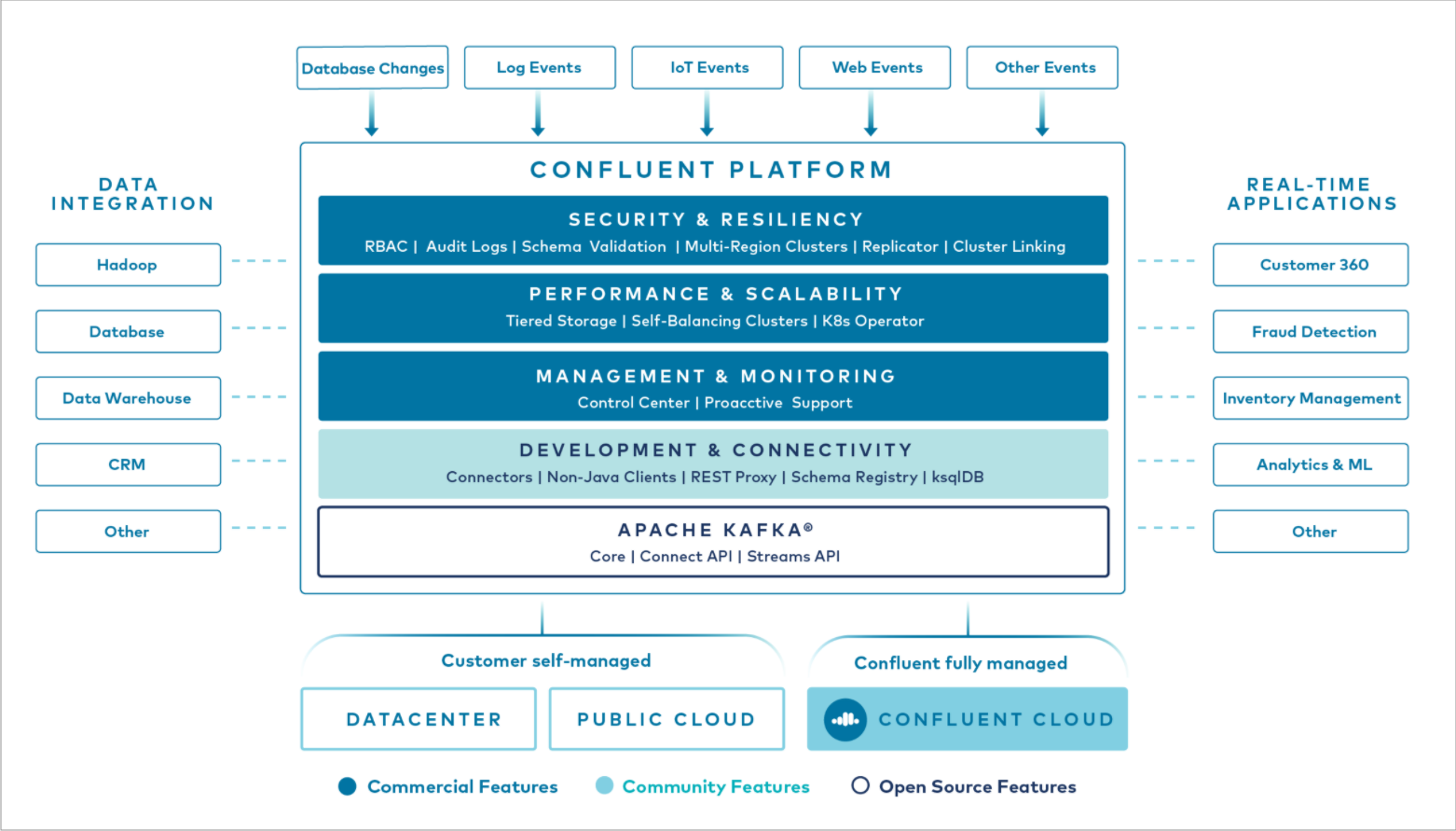
Confluent Platform Components
Overview of Confluent’s Event Streaming Technology
At the core of Confluent Platform is Apache Kafka, the most popular open source distributed streaming platform. The key capabilities of Kafka are:
Publish and subscribe to streams of records
Store streams of records in a fault tolerant way
Process streams of records
Out of the box, Confluent Platform also includes Schema Registry, REST Proxy, a total of 100+ pre-built Kafka connectors, and ksqlDB.
Why Kafka?
Kafka is used by 60% of Fortune 500 companies for a variety of use cases, including collecting user activity data, system logs, application metrics, stock ticker data, and device instrumentation signals.
The key components of the Kafka open source project are Kafka Brokers and Kafka Java Client APIs.
- Kafka Brokers
Kafka brokers that form the messaging, data persistency and storage tier of Kafka.
- Kafka Java Client APIs
Producer API is a Java Client that allows an application to publish a stream records to one or more Kafka topics.
Consumer API is a Java Client that allows an application to subscribe to one or more topics and process the stream of records produced to them.
Streams API allows applications to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams. It has a very low barrier to entry, easy operationalization, and a high-level DSL for writing stream processing applications. As such it is the most convenient yet scalable option to process and analyze data that is backed by Kafka.
Admin API provides the capability to create, inspect, delete, and manage topics, brokers, ACLs, and other Kafka objects.
- Kafka Connect API
Connect API is a component that you can use to stream data between Kafka and other data systems in a scalable and reliable way. It makes it simple to configure connectors to move data into and out of Kafka. Kafka Connect can ingest entire databases or collect metrics from all your application servers into Kafka topics, making the data available for stream processing. Connectors can also deliver data from Kafka topics into secondary indexes like Elasticsearch or into batch systems such as Hadoop for offline analysis.
Confluent Platform vs Kafka - Key Differences
Each release of Confluent Platform includes the latest release of Kafka and additional tools and services that make it easier to build and manage an Event Streaming Platform. Confluent Platform delivers both community and commercially licensed features that complement and enhance your Kafka deployment.
See also
For an example that shows how to set Docker environment variables for Confluent Platform running in ZooKeeper mode, see the Confluent Platform demo. Refer to the demo’s docker-compose.yml file for a configuration reference.
Overview of Confluent Platform’s Enterprise Features
Confluent Control Center (Legacy)
Confluent Control Center (Legacy) is a GUI-based system for managing and monitoring Kafka. It allows you to easily manage Kafka Connect, to create, edit, and manage connections to other systems. It also allows you to monitor data streams from producer to consumer, assuring that every message is delivered, and measuring how long it takes to deliver messages. Using Control Center (Legacy), you can build a production data pipeline based on Kafka without writing a line of code. Control Center (Legacy) also has the capability to define alerts on the latency and completeness statistics of data streams, which can be delivered by email or queried from a centralized alerting system.
Confluent for Kubernetes
Confluent for Kubernetes is a Kubernetes operator. Kubernetes operators extend the orchestration capabilities of Kubernetes by providing the unique features and requirements for a specific platform application. For Confluent Platform, this includes greatly simplifying the deployment process of Kafka on Kubernetes and automating typical infrastructure lifecycle tasks.
For more information, see Confluent for Kubernetes.
Confluent Connectors to Kafka
Connectors leverage the Kafka Connect API to connect Kafka to other systems such as databases, key-value stores, search indexes, and file systems.
Confluent Marketplace has downloadable connectors for the most popular data sources and sinks. These include fully tested and supported versions of these connectors with Confluent Platform. See the following documentation for more information:
Confluent provides both commercial and Community licensed connectors. For details, and to download connectors , see Confluent Hub.
Self-Balancing Clusters
Self-Balancing Clusters provides automated load balancing, failure detection and self-healing. It provides support for adding or decommissioning brokers as needed, with no manual tuning. Self-Balancing is the next iteration of Auto Data Balancer in that Self-Balancing auto-monitors clusters for imbalances, and automatically triggers rebalances based on your configurations. (You can choose to auto-balance Only when brokers are added or Anytime.)
Partition reassignment plans and execution are taken care of for you.
Confluent Cluster Linking
Cluster Linking for Confluent Platform directly connects clusters together and mirrors topics from one cluster to another over a link bridge. Cluster Linking simplifies setup of multi-datacenter, multi-cluster, and hybrid cloud deployments.
Confluent Auto Data Balancer
As clusters grow, topics and partitions grow at different rates, brokers are added and removed and over time this leads to unbalanced workload across datacenter resources. Some brokers are not doing much at all, while others are heavily taxed with large or many partitions, slowing down message delivery. When executed, Confluent Auto Data Balancer monitors your cluster for number of brokers, size of partitions, number of partitions and number of leaders within the cluster. It allows you to shift data to create an even workload across your cluster, while throttling rebalance traffic to minimize impact on production workloads while rebalancing.
For more information, see the automatic data balancing documentation.
Confluent Replicator
Replicator makes it easier than ever to maintain multiple Kafka clusters in multiple data centers. Managing replication of data and topic configuration between data centers enables use-cases such as:
Active-active geo-localized deployments: allows users to access a near-by data center to optimize their architecture for low latency and high performance
Centralized analytics: Aggregate data from multiple Kafka clusters into one location for organization-wide analytics
Cloud migration: Use Kafka to synchronize data between on-prem applications and cloud deployments
You can use Replicator to configure and manage replication for all these scenarios from either Confluent Control Center (Legacy) or command-line tools. To get started, see the Replicator documentation, including the quick start tutorial for Replicator.
Tiered Storage
Tiered Storage provides options for storing large volumes of Kafka data using your favorite cloud provider, thereby reducing operational burden and cost. With Tiered Storage, you can keep data on cost-effective object storage, and scale brokers only when you need more compute resources.
Confluent JMS Client
Confluent Platform includes a JMS-compatible client for Kafka. This Kafka client implements the JMS 1.1 standard API, using Kafka brokers as the backend. This is useful if you have legacy applications using JMS, and you would like to replace the existing JMS message broker with Kafka. By replacing the legacy JMS message broker with Kafka, existing applications can integrate with your modern streaming platform without a major rewrite of the application.
For more information, see JMS Client for Confluent Platform.
Confluent MQTT Proxy
Provides a way to publish data directly to Kafka from MQTT devices and gateways without the need for a MQTT Broker in the middle.
For more information, see MQTT Proxy.
Confluent Security Plugins
Confluent Security Plugins are used to add security capabilities to various Confluent Platform tools and products.
Currently, there is a plugin available for Confluent REST Proxy which helps in authenticating the incoming requests and propagating the authenticated principal to requests to Kafka. This enables Confluent REST Proxy clients to utilize the multi-tenant security features of the Kafka broker. For more information, see REST Proxy Security, the REST Proxy Security Plugin, and Schema Registry Security Plugin.
Community Features
ksqlDB
ksqlDB is the streaming SQL engine for Kafka. It provides an easy-to-use yet powerful interactive SQL interface for stream processing on Kafka, without the need to write code in a programming language such as Java or Python. ksqlDB is scalable, elastic, fault-tolerant, and real-time. It supports a wide range of streaming operations, including data filtering, transformations, aggregations, joins, windowing, and sessionization.
ksqlDB supports these use cases:
- Streaming ETL
Kafka is a popular choice for powering data pipelines. ksqlDB makes it simple to transform data within the pipeline, readying messages to cleanly land in another system.
- Materialized cache / views
A materialized view is a query result that is precomputed (before a user or app actually runs the query) and stored for faster read access. ksqlDB supports the building of materialized views in Kafka as event streams for distributed materializations. Complexity is reduced by using Kafka for storage and ksqlDB for computation.
- Event-driven Microservices
Provides support for modeling stateless, event-driven microservices in Kafka. Stateful stream processing is managed on a cluster of servers, while side-effects run inside your stateless microservice, which reads events from a Kafka topic and takes action as needed.
For more information, see the ksqlDB documentation, ksqlDB Developer site, and ksqlDB getting started guides on the website.
Confluent Connectors to Kafka
Connectors leverage the Kafka Connect API to connect Kafka to other systems such as databases, key-value stores, search indexes, and file systems. Confluent Marketplace has downloadable connectors for the most popular data sources and sinks.
Confluent provides both commercial and Community licensed connectors. See Confluent Hub for details, and to download connectors.
Confluent Clients
C/C++ Client Library
The library librdkafka is the C/C++ implementation of the Kafka protocol, containing both Producer and Consumer support. It was designed with message delivery, reliability and high performance in mind. Current benchmarking figures exceed 800,000 messages per second for the producer and 3 million messages per second for the consumer. This library includes support for many new features of Kafka 0.10, including message security. It also integrates easily with libserdes, our C/C++ library for Avro data serialization (supporting Schema Registry).
For more information, see the Overview of Confluent Platform Client Programming documentation.
Python Client Library
A high-performance client for Python.
For more information, see the Overview of Confluent Platform Client Programming documentation.
Go Client Library
Confluent Platform includes of a full-featured, high-performance client for Go.
For more information, see the Overview of Confluent Platform Client Programming documentation.
.NET Client Library
Confluent Platform bundles a full featured, high performance client for .NET.
For more information, see the Overview of Confluent Platform Client Programming documentation.
Confluent Schema Registry
One of the most difficult challenges with loosely coupled systems is ensuring compatibility of data and code as the system grows and evolves. With a messaging service like Kafka, services that interact with each other must agree on a common format, called a schema, for messages. In many systems, these formats are ad hoc, only implicitly defined by the code, and often are duplicated across each system that uses that message type.
As requirements change, it becomes necessary to evolve these formats. With only an ad-hoc definition, it is very difficult for developers to determine what the impact of their change might be.
Confluent Schema Registry enables safe, zero downtime evolution of schemas by centralizing the schema management. It provides a RESTful interface for storing and retrieving Avro®, JSON Schema, and Protobuf schemas. Schema Registry tracks all versions of schemas used for every topic in Kafka and only allows evolution of schemas according to user-defined compatibility settings. This gives developers confidence that they can safely modify schemas as necessary without worrying that doing so will break a different service they may not even be aware of. Support for schemas is a foundational component of a data governance solution.
Schema Registry also includes plugins for Kafka clients that handle schema storage and retrieval for Kafka messages that are sent in the Avro format. This integration is seamless – if you are already using Kafka with Avro data, using Schema Registry only requires including the serializers with your application and changing one setting.
For more information, see the Schema Registry documentation. For a hands-on introduction to working with schemas, see the On-Premises Schema Registry Tutorial. For a deep dive into supported serialization and deserialization formats, see Formats, Serializers, and Deserializers.
Confluent REST Proxy
Kafka and Confluent provide native clients for Java, C, C++, and Python that make it fast and easy to produce and consume messages through Kafka. These clients are usually the easiest, fastest, and most secure way to communicate directly with Kafka.
But sometimes, it isn’t practical to write and maintain an application that uses the native clients. For example, an organization might want to connect a legacy application written in PHP to Kafka. Or suppose that a company is running point-of-sale software that runs on cash registers, written in C# and running on Windows NT 4.0, maintained by contractors, and needs to post data across the public internet. To help with these cases, Confluent Platform includes a REST Proxy. The REST Proxy addresses these problems.
The Confluent REST Proxy makes it easy to work with Kafka from any language by providing a RESTful HTTP service for interacting with Kafka clusters. The REST Proxy supports all the core functionality: sending messages to Kafka, reading messages, both individually and as part of a consumer group, and inspecting cluster metadata, such as the list of topics and their settings. You can get the full benefits of the high quality, officially maintained Java clients from any language.
The REST Proxy also integrates with Schema Registry. It can read and write Avro data, registering and looking up schemas in Schema Registry. Because it automatically translates JSON data to and from Avro, you can get all the benefits of centralized schema management from any language using only HTTP and JSON.
For more information, see the Confluent REST Proxy documentation.
Docker images of Confluent Platform
Docker images of Confluent Platform are available on Docker Hub, and detailed in the Confluent documentation on the Docker Image Reference for Confluent Platform page. Some of these images contain proprietary components that require a Confluent commercial license as indicated in the image reference table.
For an example Docker compose file for Confluent Platform, refer to Confluent Platform all-in-one Docker Compose file. The file is for a quick start tutorial and should not be used in production environments.
Confluent CLI and other Command Line Tools
Confluent Platform ships a number of command line interface (CLI) tools, including the Confluent CLI. These are all listed under CLI Tools for Confluent Platform in the Confluent documentation, including both Confluent provided and Kafka utilities.
Get Started
Sign up for Confluent Cloud and use the Cloud quick start to get started.
Download Confluent Platform and use the Quick Start for Confluent Platform to get started.