
Monitor Production and Consumption in Control Center (Legacy)
Install Confluent Monitoring Interceptors with your Apache Kafka® applications to monitor production and consumption in Control Center (Legacy). Configure your applications to use the interceptors on the Kafka messages produced and consumed, and these messages are then sent to Control Center (Legacy). For example, to configure Consumer Group triggers for average and max latency, you must configure Monitoring Interceptors for the clients in the target consumer group.
You must be running Control Center (Legacy) in Normal mode to monitor this data.
The following image provides an example of a Kafka environment without Confluent Control Center (Legacy) and a similar environment that has Confluent Control Center (Legacy) running, and interceptors configured.
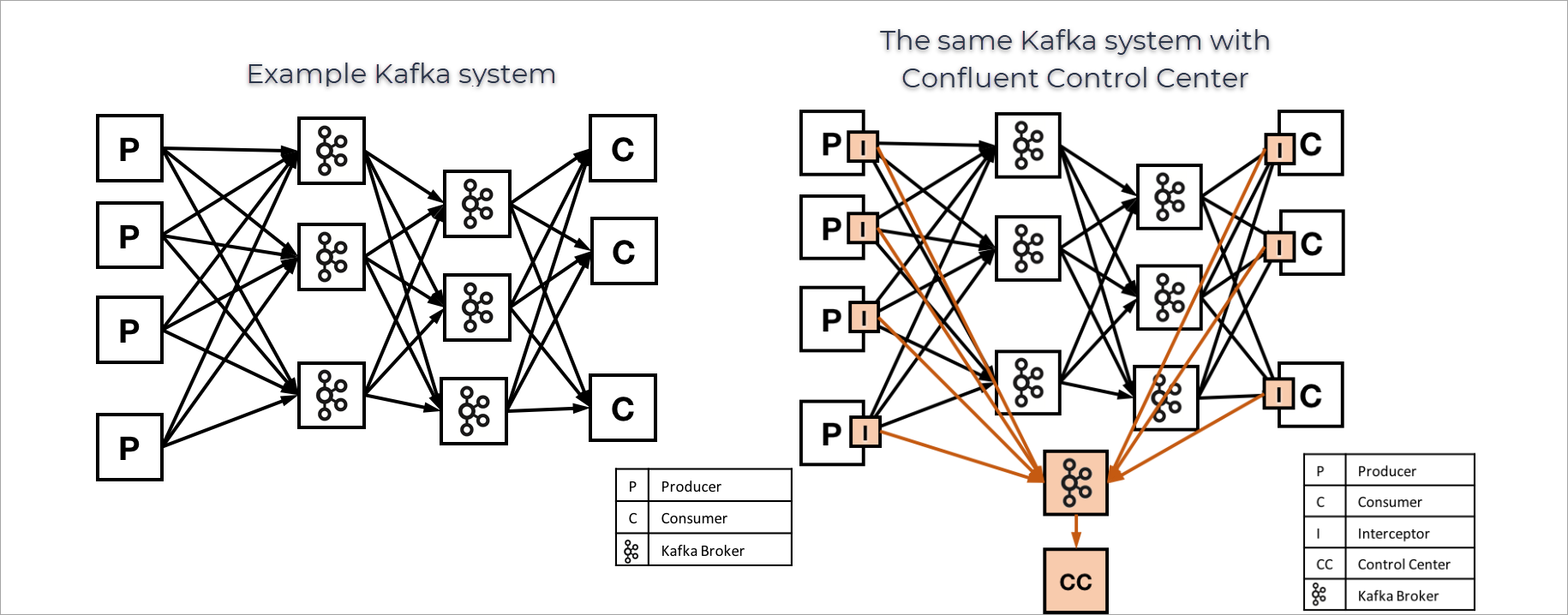
Interceptors, metrics and timestamps
The interceptors shown in the earlier image collect metrics on messages produced or consumed on each client, and send these to Control Center (Legacy) for analysis and reporting. Metrics are collected for each combination of producer, consumer group, consumer, topic, and partition. Currently, metrics include a message count and cumulative checksum for producers and consumer, and latency information from consumers.
Interceptors use Kafka message timestamps to group messages. Specifically, interceptors collect metrics during a one minute time window based on this timestamp. Calculate this with the following function: floor(messageTimestamp / 60) * 60.
Installing Interceptors
Since Kafka 0.10.0.0, Kafka Clients support pluggable interceptors to examine (and potentially modify) messages. Control Center (Legacy) requires clients to use Confluent Monitoring Interceptors to collect statistics on incoming and outgoing messages to provide production and consumption monitoring capabilities.
To use Control Center (Legacy)’s production and consumption monitoring features, first you must install the Confluent Monitoring Interceptor on clients.
Interceptor distribution
When you install Confluent Platform, you can choose between two different packages:
Confluent Platform Server Package, (-ce) which includes all community and commercial components, including monitoring interceptors.
Confluent Community Package (-ccs), which includes community components only. If you use this package, you will need to install a separate component package that contains the interceptors.
For more information, see Confluent Platform Packages.
Java Clients
Maven, Ivy, or Gradle when developing Java applications. Here is sample content for a POM file for Maven. First, specify the Confluent Maven repository:
<repositories>
...
<repository>
<id>confluent</id>
<url>http://packages.confluent.io/maven/</url>
</repository>
...
</repositories>
Next, add dependencies for the Kafka Java clients and the Confluent Monitoring Interceptors:
<dependencies>
...
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>7.5.15-ccs</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>monitoring-interceptors</artifactId>
<version>7.5.15</version>
</dependency>
...
</dependencies>
librdkafka-based Clients
For librdkafka-based clients such as confluent-kafka-python, confluent-kafka-go, or confluent-kafka-dotnet, a separate monitoring interceptor plugin is used. If you are using Confluent Community, this package is distributed differently depending on the client platform:
Linux (Debian and RedHat based distributions): If using Confluent Community, install the
confluent-librdkafka-pluginspackage from the Confluent repositories.macOS or Windows: If using Confluent Community, download the monitoring interceptor zip file, then:
For macOS: extract or copy the
monitoring-interceptor.dylibfile to the same directory as your application or a directory in the system library search path, such as/usr/local/lib.For Windows: extract or copy the appropriate
monitoring-interceptor.dllfor your architecture to the same location as where your application is installed or the directory where your application is run.
Note
The monitoring interceptor plugin for librdkafka-based clients requires librdkafka version 0.11.0 or later.
Note
The monitoring interceptor plugin is a runtime dependency and is not required to build the client or application; the plugin is directly referenced through configuration properties (plugin.library.paths) and must be installed on the deployment host rather than the build host.
Enabling Interceptors
After you have installed the Confluent Monitoring Interceptor package to your Kafka applications, configure your clients to actually use the interceptors. How you configure a client depends on what kind of client it is.
Warning
The producer and consumer interceptor classes are different; make sure you choose the correct class for each producer and consumer.
Note
If you are using interceptors, and you are installing Confluent Platform on RHEL, CentOS, Debian or Ubuntu, you must install the component package (for example, confluent-ksql) and Confluent Control Center (Legacy) (confluent-control-center) on the same machine.
Java Producers and Consumers
You can specify the Confluent Monitoring Interceptor to be used for Java producers and consumers.
For producers, set interceptor.classes to io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor.
producerProps.put(
ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
"io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor");
For consumers, set interceptor.classes to io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor.
consumerProps.put(
ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG,
"io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor");
Note
For librdkafka-based clients, see librdkafka.
Kafka Streams
Kafka Streams uses Kafka producers and consumers internally. You can specify the Confluent Monitoring Interceptor to be used for those internal producers and consumers.
For producers, set producer.interceptor.classes to io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor. For consumers, set consumer.interceptor.classes to io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor.
streamsConfig.put(
StreamsConfig.PRODUCER_PREFIX + ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
"io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor");
streamsConfig.put(
StreamsConfig.MAIN_CONSUMER_PREFIX + ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG,
"io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor");
ksqlDB
ksqlDB, like Kafka Streams, uses Kafka producers and consumers internally. You can specify the Confluent Monitoring Interceptor to be used for those internal producers and consumers.
For producers, set producer.interceptor.classes to io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor. For consumers, set consumer.interceptor.classes to io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor.
producer.interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor
consumer.interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor
librdkafka-based clients
For librdkafka-based clients, set the plugin.library.paths configuration property to the name of the interceptor library, monitoring-interceptor.
- C example:
rd_kafka_conf_t *conf = rd_kafka_conf_new(); rd_kafka_conf_res_t r; char errstr[512]; r = rd_kafka_conf_set(conf, "bootstrap.servers", "mybroker", errstr, sizeof(errstr)); if (r != RD_KAFKA_CONF_OK) fatal("%s", errstr); r = rd_kafka_conf_set(conf, "plugin.library.paths", "monitoring-interceptor", errstr, sizeof(errstr)); if (r != RD_KAFKA_CONF_OK) fatal("%s", errstr); rd_kafka_t *rk = rd_kafka_new(RD_KAFKA_PRODUCER, conf, errstr, sizeof(errstr)); if (!rk) fatal("%s", errstr); rd_kafka_destroy(rk);
- Python example:
p = confluent_kafka.Producer({'bootstrap.servers': 'mybroker', 'plugin.library.paths': 'monitoring-interceptor'})
Note
If the monitoring-interceptor library is installed to a non-standard location which is not covered by the systems dynamic linker path (see dlopen(3) or LoadLibrary documentation) a full or relative path needs to be configured.
Note
The platform-specific library filename extension (e.g., .so or .dll) may be omitted.
Kafka Connect
Kafka Connect connectors use Kafka producers and consumers internally. You can specify the Confluent Monitoring Interceptor to be used for these internal producers and consumers.
Source connector: In the worker, add the Confluent Monitoring Interceptors and use the
producerprefix.producer.interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptorSink connector: In the worker, add the Confluent Monitoring Interceptors and use the
consumerprefix.consumer.interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor
Tip
To override the monitoring interceptor bootstrap servers for metrics producers and consumers, specify the producer.<*> or consumer.<*> prefixes and any required security configuration properties, as shown in Encrypt and Authenticate with TLS and Encrypt with TLS. For example, for a metrics producer, you could override the bootstrap servers and provide the security protocol by entering the following properties: producer.confluent.monitoring.interceptor.bootstrap.servers and producer.confluent.monitoring.interceptor.security.protocol.
Confluent Replicator
Replicator uses a Kafka consumer internally. You can specify the Confluent Monitoring Interceptor to be used for that internal consumer. Modify the Replicator JSON configuration file. Here is an example subset of configuration to add.
{
"name":"replicator",
"config":{
....
"src.consumer.interceptor.classes": "io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor",
....
}
}
}
Tip
To override the monitoring interceptor bootstrap servers for Replicator, specify the prefix for Replicator as the consumer in the configuration. For example: "src.consumer.confluent.monitoring.interceptor.bootstrap.servers": "kafka1:9091"
To learn more, see Interceptors for Kafka Connect and Interceptors for Replicator in Confluent Monitoring Interceptors, Confluent Monitoring Interceptor in Encrypt with TLS, Monitor Replicator for Confluent Platform, and Use Control Center (Legacy) to monitor replicators in the Replicator quick start tutorial.
Confluent REST Proxy
REST Proxy uses Kafka consumers and producers internally. You can instrument these with the Confluent Monitoring Interceptors for these internal clients by modifying the startup configuration properties file (/etc/kafka-rest/kafka-rest.properties). You also need to include the interceptor JAR (located under share/java/monitoring-interceptors) on the CLASSPATH. Here is an example subset of the configuration to add.
producer.interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor
consumer.interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor
REST Proxy Interceptor class configurations
REST Proxy supports interceptor configurations as part of Java new producer and consumer settings.
producer.interceptor.classesProducer interceptor classes.
Type: string
Default: “”
Importance: low
consumer.interceptor.classesConsumer interceptor classes.
Type: string
Default: “”
Importance: low
Configuring Interceptors
Defaults
By default, Confluent Monitoring Interceptors will send and receive messages using the same Kafka cluster that you are monitoring, and will use a set of default topics to share information. The interceptors will also report data at a regular interval of 15 seconds by default.
General Options
Here are some recommended configuration parameters to use for the Confluent Monitoring Interceptors, although the defaults can be used for many applications.
confluent.monitoring.interceptor.bootstrap.serversList of Kafka brokers in a cluster to which monitoring data will be written. (Default is
localhost:9092.)
Note
You can change any Kafka producer configuration option for the interceptor by prefixing it with confluent.monitoring.interceptor. (including the . on the end). For example, you can change the value of timeout.ms for the interceptor using the property confluent.monitoring.interceptor.timeout.ms. For more information on Kafka producer options, see the Kafka Producer Configuration Reference for Confluent Platform.
There are also some configuration parameters that are only used by the Confluent Monitoring Interceptor:
confluent.monitoring.interceptor.topicTopic on which monitoring data will be written. (Default is
_confluent-monitoring.)confluent.monitoring.interceptor.publishMsPeriod the interceptor should use to publish messages to. (Default is 15 seconds.)
confluent.monitoring.interceptor.client.idA logical client name to be included in Confluent Control Center (Legacy) monitoring data. If not specified, client id of an intercepted client with
confluent.monitoring.interceptoris used.
Security
When configuring Monitoring Interceptor for a secure cluster, the embedded producer (that sends monitoring data to the broker) in Monitoring Interceptor must have the correct security configurations prefixed with confluent.monitoring.interceptor.
For librdkafka-based clients, while the confluent.monitoring.interceptor. prefix is the same, the actual client configuration properties may vary depending on the underlying client. They may differ between the Java client and librdkafka-based clients. For example:
For ksqlDB, prefix the entries with
confluent.monitoring.interceptor.For Connect producers, prefix the entries with
producer.confluent.monitoring.interceptor.For Connect consumers, prefix the entries with
consumer.confluent.monitoring.interceptor.
For more information on how to enable security for Confluent Monitoring Interceptors and example configuration settings, see:
For librdkafka-based clients, while the confluent.monitoring.interceptor. prefix is the same, the actual client configuration properties may vary depending on the underlying client. They may differ between the Java client and librdkafka-based clients.
Set up interceptors for RBAC
To use interceptors when RBAC is enabled, the producers and consumers require principal write access to the monitoring topic (default is _confluent-monitoring) on the cluster where the monitoring data is being sent. By default, the monitoring cluster is the same as the cluster being produced to and consumed from.
Follow these steps:
Create the
_confluent-monitoringtopic by either starting Control Center (Legacy) or manually create the topic.Grant the client principal the
DeveloperWriterole on the_confluent-monitoringtopic using the Confluent CLI.confluent iam rbac role-binding create \ --principal User:<client-principal> \ --role DeveloperWrite \ --resource Topic:_confluent-monitoring --kafka-cluster-id <kafka-id>
Start up the client.
For more infomration on RBAC in Confluent Platform, see Authorization using Role-Based Access Control and Configure RBAC for Control Center (Legacy).
Logging
Both the Kafka client and the Confluent interceptor use slf4j for logging errors and other information. To enable logging, you need to configure an slf4j binding, or you will see an error message like “Failed to load class org.slf4j.impl.StaticLoggerBinder.” The simplest way to resolve this issue is to add slf4j-simple.jar to your classpath. For more details, see http://www.slf4j.org/codes.html#StaticLoggerBinder.
The librdkafka-based monitoring interceptor will log critical errors to stderr. To enable interceptor-specific debugging (to stderr) set the confluent.monitoring.interceptor.icdebug configuration property to true.
Example Configuration
Below shows how to setup stream monitoring for the built-in performance testing tools that come with Kafka. The instructions assume you have a cluster setup similar to that of the quick start guide.
With Control Center (Legacy) already running, open a terminal and run the following commands to start the Producer Performance Test tool with the
MonitoringProducerInterceptor:export CLASSPATH=./share/java/monitoring-interceptors/monitoring-interceptors-7.5.15.jar ./bin/kafka-producer-perf-test --topic c3test --num-records 10000000 --record-size 1000 \ --throughput 10000 --producer-props bootstrap.servers=localhost:9092 \ interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor acks=all
Also, you can open a terminal and run the following commands to start the console producer with the
MonitoringProducerInterceptor:export CLASSPATH=./share/java/monitoring-interceptors/monitoring-interceptors-7.5.15.jar echo "interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor" > /tmp/producer.config echo "acks=all" >> /tmp/producer.config seq 10000 | bin/kafka-console-producer --topic c3test --bootstrap-server localhost:9092 --producer.config /tmp/producer.config
For librdkafka-based clients, like kafkacat:
(for i in $(seq 1 100000) ; echo $i ; sleep 0.01 ; done) | kafkacat -b localhost:9092 -P -t c3test -X acks=all \ -X plugin.library.paths=monitoring-interceptor
In a separate terminal, start up the console consumer with the
MonitoringConsumerInterceptor:export CLASSPATH=./share/java/monitoring-interceptors/monitoring-interceptors-7.5.15.jar echo "interceptor.classes=io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor" > /tmp/consumer.config echo "group.id=c3_example_consumer_group" >> /tmp/consumer.config bin/kafka-console-consumer --topic c3test --bootstrap-server localhost:9092 --consumer.config /tmp/consumer.config
For librdkafka-based clients, e.g. kafkacat:
kafkacat -b localhost:9092 -G c3_example_consumer_group -X auto.offset.reset=earliest \ -X plugin.library.paths=monitoring-interceptor \ c3test
Open the Control Center (Legacy) UI at http://localhost:9021/ and click on Consumers to view the
c3_example_consumer_group. Click the consumer group ID to view its details.
Synchronize clocks for accurate reporting
Latency is typically measured by calculating the difference between the system clock time for a consumer and the timestamp in a message received by that consumer. In a distributed environment, it can be difficult to keep clocks synchronized. For Control Center (Legacy) , if the clock on the consumer is running faster than the clock on the producer, then Control Center (Legacy) might show latency values that are higher than the true values. If the clock on the consumer is running slower than the clock on the producer, then Control Center (Legacy) might show latency values that are lower than the true values (and in the worst case, negative values).
If your clocks are out of sync, you might notice some unexpected results in Control Center (Legacy). Confluent recommends using a mechanism like NTP to synchronize time between production machines; this can help keep clocks synchronized to within 20ms over the public internet, and to within 1 ms for servers on the same local network.
Verification
To verify the interceptors are properly sending data to the _confluent-monitoring topic, start the console consumer:
bin/control-center-console-consumer <control-center.properties> --topic _confluent-monitoring --from-beginning
You should see monitoring messages with the relevant clientId being produced onto that topic.
Note
Make sure interceptor is working for both producers and consumers; Control Center (Legacy) currently will not display messages that have not been consumed.
Limitations
Confluent Monitoring Interceptors currently do not support consumers with
isolation.level=read_committedand producers withtransactional.idset.Confluent Monitoring Interceptors will skip messages with missing or invalid timestamps. Make sure all brokers and topics are all configured with
log.message.format.versionandmessage.format.version>=0.10.0Confluent Monitoring Interceptors cannot be configured in Confluent Control Center (Legacy) in conjunction with Exactly Once Semantics (EOS).