
Monitoring Kafka with JMX
Java Management Extensions (JMX) and Managed Beans (MBeans) are technologies for monitoring and managing Java applications, and they are enabled by default for Kafka and provide metrics for its components; brokers, controllers, producers, and consumers. The next sections describe how to configure JMX and verify that you have configured it correctly.
You can search for a metric by name.
You can also browse metrics by category:
Tip
Confluent offers some alternatives to using JMX monitoring.
Health+: Consider monitoring and managing your environment with Confluent Health+. Ensure the health of your clusters and minimize business disruption with intelligent alerts, monitoring, and proactive support based on best practices created by the inventors of Kafka.
Confluent Control Center: You can deploy Control Center for out-of-the-box Kafka cluster monitoring so you don’t have to build your own monitoring system. Control Center (Legacy) makes it easy to manage the entire Confluent Platform deployment. Control Center (Legacy) is a web-based application that allows you to manage your cluster and to alert on triggers. Additionally, Control Center (Legacy) measures how long messages take to be delivered, and determines the source of any issues in your cluster.
Configure JMX
You can use the following JVM environment variables to configure JMX monitoring when you start Kafka or use Java system properties to enable remote JMX programmatically.
JMX_PORTThe port that JMX listens on for incoming connections.
JMX_HOSTNAMEThe hostname associated with locally created remote objects.
KAFKA_JMX_OPTSJMX options. Use this variable to override the default JMX options such as whether authentication is enabled. The default options are set as follows:
-Djava.rmi.server.hostname=127.0.0.1 -Dcom.sun.management.jmxremote=true -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=falseserver.hostnameSpecifies the host a JMX client connects to. The default islocalhost(127.0.0.1)jmxremote=trueEnables the JMX remote agent and enables the connector to listen through a specific port.jmxremote.authenticate=falseIndicates that authentication is off by default.jmxremote.ssl=false- Indicates that TLS/SSL is off by default.
For example, to start Kafka, and specify a JMX port, you can use the following command:
JMX_PORT=2020 ./bin/kafka-server-start.sh ./etc/kafka/kraft/server.properties
For more on configuring JMX, see Monitoring and Management using JMX technology. For additional topics about monitoring, see the Related content section.
View MBeans with JConsole
To see JMX monitoring in action, you can start JConsole, a utility provided with Java.
To start JConsole, use the jconsole command, and connect to the Kafka process.
After JConsole starts, if Kafka is running locally, you will see it listed as a Local Process, and you can select it. Or if you are running Kafka remotely, such as in a Docker container, select Remote Process, enter the hostname and port you specified in your JMX configuration, and click Connect.
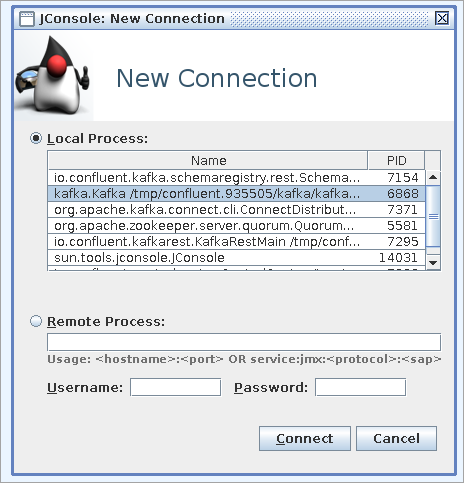
Enter a valid username and password, or if you have not configured authentication, you may be prompted to make an Insecure connection.
Once JConsole is running, you can select the MBeans tab and expand the folders to see the JMX events and attributes for those events.
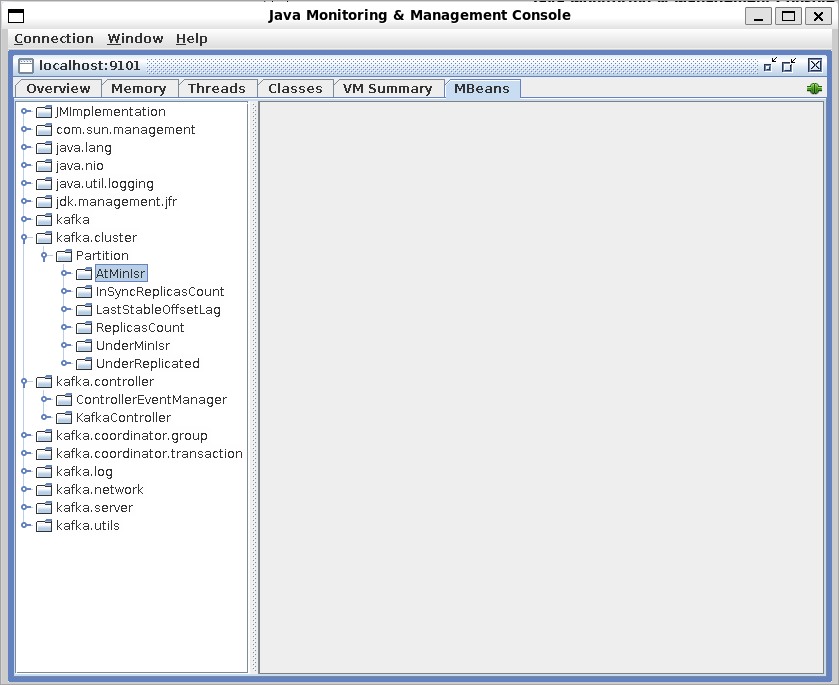
You can also view JMX metrics with console tools such Jmxterm or export JMX metrics to other monitoring tools such as Prometheus. For a demo on how to use some popular monitoring tools with Confluent products, see JMX Monitoring Stacks on GitHub.
Configure security
Password authentication and TLS/SSL are disabled for JMX by default in Kafka, however in a production environment, you should enable authentication and TLS/SSL to prevent unauthorized users from accessing your brokers.
You override the default JMX settings to enable authentication and SSL.
To learn about how to secure JMX, follow the TLS/SSL and authentication sections in Monitoring and Management Using JMX Technology.
Configure other Confluent Platform components
Use the following environment variables to override the default JMX options such as authentication settings for other Confluent Platform components.
Component | Environment Variable |
|---|---|
Confluent Control Center (Legacy) | CONTROL_CENTER_JMX_OPTS |
REST Proxy | KAFKAREST_JMX_OPTS |
ksqlDB | KSQL_JMX_OPTS |
Rebalancer | REBALANCER_JMX_OPTS |
Schema Registry | SCHEMA_REGISTRY_JMX_OPTS |
Search for a metric
Broker metrics
There are many metrics reported at the broker and controller level that can be monitored and used to troubleshoot issues with your cluster. At minimum, you should monitor and set alerts on ActiveControllerCount, OfflinePartitionsCount, and UncleanLeaderElectionsPerSec.
clientSoftwareName/clientSoftwareVersion
- MBean:
kafka.server:clientSoftwareName=(name),clientSoftwareVersion=(version),listener=(listener),networkProcessor=(processor-index),type=(type) The name and version of client software in the brokers. For example, the Kafka 2.4 Java client produces the following MBean on the broker:
kafka.server:clientSoftwareName=apache-kafka-java,clientSoftwareVersion=2.4.0,listener=PLAINTEXT,networkProcessor=1,type=socket-server-metrics
RequestRateAndQueueTimeMs
- MBean:
kafka.controller:type=ControllerChannelManager,name=RequestRateAndQueueTimeMs,brokerId=([0-9]+) The rate (requests per millisecond) at which the controller takes requests from the queue of the given broker, and the time it takes for a request to stay in this queue before it is taken from the queue. ZooKeeper mode.
ElectionRateAndTimeMs
- MBean:
kafka.controller:type=ControllerStats,name=LeaderElectionRateAndTimeMs The broker leader election rate and latency in milliseconds. This is non-zero when there are broker failures.
UncleanLeaderElectionsPerSec
- MBean:
kafka.controller:type=ControllerStats,name=UncleanLeaderElectionsPerSec The unclean broker leader election rate. Should be 0.
MessageConversionsPerSec
- MBean:
kafka.server:type=BrokerTopicMetrics,name={Produce|Fetch}MessageConversionsPerSec,topic=([-.\w]+) The message format conversion rate, for Produce or Fetch requests, per topic. Omitting ‘topic={…}’ will yield the all-topic rate.
BytesInPerSec
- MBean:
kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec,topic={topicName} The incoming byte rate from clients, per topic. Omitting ‘topic={…}’ will yield the all-topic rate.
BytesOutPerSec
- MBean:
kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec,topic={topicName} The outgoing byte rate to clients per topic. Omitting ‘topic={…}’ will yield the all-topic rate.
BytesRejectedPerSec
- MBean:
kafka.server:type=BrokerTopicMetrics,name=BytesRejectedPerSec,topic={topicName} The rejected byte rate per topic, due to the record batch size being greater than
max.message.bytesconfiguration. Omitting ‘topic={…}’ will yield the all-topic rate.
FailedFetchRequestsPerSec
- MBean:
kafka.server:type=BrokerTopicMetrics,name=FailedFetchRequestsPerSec The fetch request rate for requests that failed.
FailedProduceRequestsPerSec
- MBean:
kafka.server:type=BrokerTopicMetrics,name=FailedProduceRequestsPerSec The produce request rate for requests that failed.
InvalidMagicNumberRecordsPerSec
- MBean:
kafka.server:type=BrokerTopicMetrics,name=InvalidMagicNumberRecordsPerSec The message validation failure rate due to an invalid magic number. This should be 0.
InvalidMessageCrcRecordsPerSec
- MBean:
kafka.server:type=BrokerTopicMetrics,name=InvalidMessageCrcRecordsPerSec The message validation failure rate due to incorrect Crc checksum
InvalidOffsetOrSequenceRecordsPerSec
- MBean:
kafka.server:type=BrokerTopicMetrics,name=InvalidOffsetOrSequenceRecordsPerSec The message validation failure rate due to non-continuous offset or sequence number in batch. Normally this should be 0.
MessagesInPerSec
- MBean:
kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec,topic={topicName} The incoming message rate per topic. Omitting ‘topic={…}’ will yield the all-topic rate.
NoKeyCompactedTopicRecordsPerSec
- MBean:
kafka.server:type=BrokerTopicMetrics,name=NoKeyCompactedTopicRecordsPerSec The message validation failure rate due to no key specified for compacted topic. This should be 0.
ReassignmentBytesInPerSec
- MBean:
kafka.server:type=BrokerTopicMetrics,name=ReassignmentBytesInPerSec The incoming byte rate of reassignment traffic.
ReplicationBytesInPerSec
- MBean:
kafka.server:type=BrokerTopicMetrics,name=ReplicationBytesInPerSec,topic={topicName} The incoming byte rate from other brokers per topic. Omitting ‘topic={…}’ will yield the all-topic rate.
ReplicationBytesOutPerSec
- MBean:
kafka.server:type=BrokerTopicMetrics,name=ReplicationBytesOutPerSec The byte-out rate to other brokers.
TotalFetchRequestsPerSec
- MBean:
kafka.server:type=BrokerTopicMetrics,name=TotalFetchRequestsPerSec The fetch request rate per second.
TotalProduceRequestsPerSec
- MBean:
kafka.server:type=BrokerTopicMetrics,name=TotalProduceRequestsPerSec The produce request rate per second.
consumer-lag-offsets
- MBean:
kafka.server:type=tenant-metrics,member={memberId},topic={topicName},consumer-group={groupName},partition={Id},client-id={clientId} consumer-lag-offsetsis an attribute of the MBean listed.This metric is the difference between the last offset stored by the broker and the last committed offset for a specific consumer group name, client ID, member ID, partition ID, and topic name. This metric provides the consumer lag in offsets only and does not report latency. In addition, it is not reported for any groups that are not alive or are empty.
To enable this metric, you must set the following server properties.
confluent.consumer.lag.emitter.enabled=true # default is false confluent.consumer.lag.emitter.interval.ms=60000 # default is 60000
For more information about this metric, see Understand and Monitor Consumer Lag.
PurgatorySize (produce)
- MBean:
kafka.server:type=DelayedOperationPurgatory,delayedOperation=Produce,name=PurgatorySize The number of requests waiting in the producer purgatory. This should be non-zero when
acks=allis used on the producer.
PurgatorySize (fetch)
- MBean:
kafka.server:type=DelayedOperationPurgatory,delayedOperation=Fetch,name=PurgatorySize The number of requests waiting in the fetch purgatory. This is high if consumers use a large value for
fetch.wait.max.ms
ConsumerLag
- MBean:
kafka.server:type=FetcherLagMetrics,name=ConsumerLag,clientId=([-.\w]+),topic={topicName},partition=([0-9]+) The lag in number of messages per follower replica. This is useful to know if the replica is slow or has stopped replicating from the leader and if the associated brokers need to be removed from the In-Sync Replicas list.
linux-disk-read-bytes
- MBean:
kafka.server:type=KafkaServer,name=linux-disk-read-bytes The total number of bytes read by the broker process, including reads from all disks. The total doesn’t include reads from page cache. Available only on Linux-based systems.
linux-disk-write-bytes
- MBean:
kafka.server:type=KafkaServer,name=linux-disk-write-bytes The total number of bytes written by the broker process, including writes from all disks. Available only on Linux-based systems.
PartitionsWithLateTransactionCount
- MBean:
kafka.server:type=ReplicaManager,name=PartitionsWithLateTransactionsCount The number of partitions that have open transactions with durations exceeding the
transaction.max.timeout.msproperty value set on the broker.
UnderMinIsrPartitionCount
- MBean:
kafka.server:type=ReplicaManager,name=UnderMinIsrPartitionCount The number of partitions whose in-sync replicas count is less than
minIsr.
UnderReplicatedPartitions
- MBean:
kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions The number of under-replicated partitions (| ISR | < | current replicas |). Replicas that are added as part of a reassignment will not count toward this value. Alert if the value is greater than 0.
ReassigningPartitions
- MBean:
kafka.server:type=ReplicaManager,name=ReassigningPartitions The number of reassigning partitions.
UnderMinIsr
- MBean:
kafka.cluster:type=Partition,topic={topic},name=UnderMinIsr,partition={partition} The number of partitions whose in-sync replicas count is less than
minIsr. These partitions will be unavailable to producers who useacks=all.
InSyncReplicasCount
- MBean:
kafka.cluster:type=Partition,topic={topic},name=InSyncReplicasCount,partition={partition} A gauge metric that indicates the in-sync replica count per topic partition leader.
AtMinIsr
- MBean:
kafka.cluster:type=Partition,topic={topic}name=AtMinIsr,partition={partition} The number of partitions whose in-sync replicas count is equal to the
minIsrvalue.
ReplicasCount
- MBean:
kafka.cluster:type=Partition,topic={topic}:name=ReplicasCount,partition={partition} A gauge metric that indicates the replica count per topic partition leader.
UnderReplicated
- MBean:
kafka.cluster:type=Partition,topic={topic}::name=UnderReplicated,partition={partition} The number of partitions that are under replicated meaning the number of in-sync replicas is less than the replica count.
PartitionCount
- MBean:
kafka.server:type=ReplicaManager,name=PartitionCount The number of partitions on this broker. This should be mostly even across all brokers.
LeaderCount
- MBean:
kafka.server:type=ReplicaManager,name=LeaderCount The number of leaders on this broker. This should be mostly even across all brokers. If not, set
auto.leader.rebalance.enabletotrueon all brokers in the cluster.
RequestHandlerAvgIdlePercent
- MBean:
kafka.server:type=KafkaRequestHandlerPool,name=RequestHandlerAvgIdlePercent The average fraction of time the request handler threads are idle. Values are between
0meaning all resources are used and1meaning all resources are available.
IsrShrinksPerSec
- MBean:
kafka.server:type=ReplicaManager,name=IsrShrinksPerSec Measures the reduction of in-sync replicas per second. If a broker goes down, ISR for some of the partitions will shrink. When that broker is up again, ISR will be expanded once the replicas are fully caught up. Other than that, the expected value for both ISR shrink rate and expansion rate is 0.
IsrExpandsPerSec
- MBean:
kafka.server:type=ReplicaManager,name=IsrExpandsPerSec Measures the expansion of in-sync replicas per second. When a broker is brought up after a failure, it starts catching up by reading from the leader. Once it is caught up, it gets added back to the ISR.
DelayQueueSize
- MBean:
kafka.server:type=Produce,name=DelayQueueSize The number of producer clients currently being throttled. The value can be any number greater than or equal to
0.Important
For monitoring quota applications and throttled clients, use the Bandwidth quota, and Request quota metrics.
Bandwidth quota
- MBean:
kafka.server:type={Produce|Fetch},user={userName},client-id={clientId} Use the attributes of this metric to measure the bandwidth quota. This metric has the following attributes:
throttle-time: the amount of time in milliseconds the client was throttled. Ideally = 0.byte-rate: the data produce/consume rate of the client in bytes/sec.For (
user,client-id) quotas, specify bothuserandclient-id.If a
per-client-idquota is applied to the client, do not specifyuser.If a
per-userquota is applied, do not specifyclient-id.
Request quota
- MBean:
kafka.server:type=Request,user={userName},client-id={clientId} Use the attributes of this metric to measure request quota. This metric has the following attributes:
throttle-time: the amount of time in milliseconds the client was throttled. Ideally = 0.request-time: the percentage of time spent in broker network and I/O threads to process requests from client group.For (
user,client-id) quotas, specify bothuserandclient-id.If a
per-client-idquota is applied to the client, do not specifyuser.If a
per-userquota is applied, do not specifyclient-id.
connection-count
- MBean:
kafka.server:type=socket-server-metrics,listener={listener_name},networkProcessor={#},name=connection-count The number of currently open connections to the broker.
connection-creation-rate
- MBean:
kafka.server:type=socket-server-metrics,listener={listener_name},networkProcessor={#},name=connection-creation-rate The number of new connections established per second.
KRaft broker metrics
These metrics are only produced for a broker when running in KRaft mode.
last-applied-record-offset
- MBean:
kafka.server:type=broker-metadata-metrics,name=last-applied-record-offset The offset of the last record from the cluster metadata partition that was applied by the broker.
last-applied-record-timestamp
- MBean:
kafka.server:type=broker-metadata-metrics,name=last-applied-record-timestamp The timestamp of the last record from the cluster metadata partition that was applied by the broker.
last-applied-record-lag-ms
- MBean:
kafka.server:type=broker-metadata-metrics,name=last-applied-record-lag-ms The difference between now and the timestamp of the last record from the cluster metadata partition that was applied by the broker.
metadata-load-error-count
- MBean:
kafka.server:type=broker-metadata-metrics,name=metadata-load-error-count The number of errors encountered by the BrokerMetadataListener while loading the metadata log and generating a new MetadataDelta based on it.
metadata-apply-error-count
- MBean:
kafka.server:type=broker-metadata-metrics,name=metadata-apply-error-count The number of errors encountered by the BrokerMetadataPublisher while applying a new MetadataImage based on the latest MetadataDelta.
KRaft Quorum metrics
These metrics are reported on both controllers and brokers in a KRaft cluster.
current-state
- MBean:
kafka.server:type=raft-metrics,name=current-state The current state of this member; possible values are leader, candidate, voted, follower, unattached, observer.
current-leader
- MBean:
kafka.server:type=raft-metrics,name=current-leader The current quorum leader’s id; -1 indicates unknown.
current-vote
- MBean:
kafka.server:type=raft-metrics,name=current-vote The current voted leader’s id; -1 indicates not voted for anyone.
current-epoch
- MBean:
kafka.server:type=raft-metrics,name=current-epoch The current quorum epoch.
high-watermark
- MBean:
kafka.server:type=raft-metrics,name=high-watermark The high watermark maintained on this member; -1 if it is unknown.
log-end-offset
- MBean:
kafka.server:type=raft-metrics,name=log-end-offset The current raft log end offset.
number-unknown-voter-connections
- MBean:
kafka.server:type=raft-metrics,name=number-unknown-voter-connections The number of unknown voters whose connection information is not cached. This value of this metric is always 0.
commit-latency-avg
- MBean:
kafka.server:type=raft-metrics,name=commit-latency-avg The average time in milliseconds to commit an entry in the raft log.
commit-latency-max
- MBean:
kafka.server:type=raft-metrics,name=commit-latency-max The maximum time in milliseconds to commit an entry in the raft log.
election-latency-avg
- MBean:
kafka.server:type=raft-metrics,name=election-latency-avg The average time in milliseconds spent on electing a new leader.
election-latency-max
- MBean:
kafka.server:type=raft-metrics,name=election-latency-max The maximum time in milliseconds spent on electing a new leader.
fetch-records-rate
- MBean:
kafka.server:type=raft-metrics,name=fetch-records-rate The average number of records fetched from the leader of the raft quorum.
append-records-rate
- MBean:
kafka.server:type=raft-metrics,name=append-records-rate The average number of records appended per sec by the leader of the raft quorum.
poll-idle-ratio-avg
- MBean:
kafka.server:type=raft-metrics,name=poll-idle-ratio-avg The average fraction of time the client’s poll() is idle as opposed to waiting for the user code to process records.
Controller metrics
The following metrics are exposed by a controller, which can be a broker controller in ZooKeeper mode or a KRaft controller in KRaft mode. For more about monitoring KRaft, see Monitor KRaft.
EventQueueProcessingTimeMs
- MBean:
kafka.controller:type=ControllerEventManager,name=EventQueueProcessingTimeMs A Histogram of the time in milliseconds that requests spent being processed in the Controller Event Queue.
EventQueueSize
- MBean:
kafka.controller:type=ControllerEventManager,name=EventQueueSize Size of the controller’s event queue.
EventQueueTimeMs
- MBean:
kafka.controller:type=ControllerEventManager,name=EventQueueTimeMs Time that an event (except the Idle event) waits, in milliseconds, in the controller event queue before being processed.
ActiveBrokerCount
- MBean:
kafka.controller:type=KafkaController,name=ActiveBrokerCount The number of active brokers as observed by this controller. This metric is produced for both ZooKeeper and KRaft mode.
ActiveControllerCount
- MBean:
kafka.controller:type=KafkaController,name=ActiveControllerCount For KRaft, the number of active controllers in the cluster. Valid values are ‘0’ or ‘1’. For ZooKeeper, indicates whether the broker is the controller broker. Alert if the aggregated sum across all brokers in the cluster is anything other than 1 because there should be exactly one controller per cluster.
FencedBrokerCount
- MBean:
kafka.controller:type=KafkaController,name=FencedBrokerCount In KRaft mode, the number of fenced, but registered brokers as observed by this controller. This metric is always 0 in ZooKeeper mode.
GlobalPartitionCount
- MBean:
kafka.controller:type=KafkaController,name=GlobalPartitionCount The number of partitions across all topics in the cluster.
GlobalTopicCount
- MBean:
kafka.controller:type=KafkaController,name=GlobalTopicCount The number of global partitions as observed by this Controller.
LastAppliedRecordLagMs
- MBean:
kafka.controller:type=KafkaController,name=LastAppliedRecordLagMs The difference, in milliseconds, between now and the timestamp of the last record from the cluster metadata partition that was applied by the controller. For active controllers the value of this lag is always zero.
LastAppliedRecordOffset
- MBean:
kafka.controller:type=KafkaController,name=LastAppliedRecordOffset The offset of the last record from the cluster metadata partition that was applied by the Controller.
LastAppliedRecordTimestamp
- MBean:
kafka.controller:type=KafkaController,name=LastAppliedRecordTimestamp The timestamp of the last record from the cluster metadata partition that was applied by the controller.
LastCommittedRecordOffset
- MBean:
kafka.controller:type=KafkaController,name=LastCommittedRecordOffset The offset of the last record committed to this Controller.
MetadataErrorCount
- MBean:
kafka.controller:type=KafkaController,name=MetadataErrorCount The number of times this controller node has encountered an error during metadata log processing.
OfflinePartitionsCount
- MBean:
kafka.controller:type=KafkaController,name=OfflinePartitionsCount,partition={partition} The number of partitions that don’t have an active leader and are therefore not writable or readable. Alert if value is greater than 0.
PreferredReplicaImbalanceCount
- MBean:
kafka.controller:type=KafkaController,name=PreferredReplicaImbalanceCount The count of topic partitions for which the leader is not the preferred leader.
ReplicasIneligibleToDeleteCount
- MBean:
kafka.controller:type=KafkaController,name=ReplicasIneligibleToDeleteCount The number of ineligible pending replica deletes.
ReplicasToDeleteCount
- MBean:
kafka.controller:type=KafkaController,name=ReplicasToDeleteCount Pending replica deletes.
TopicsIneligibleToDeleteCount
- MBean:
kafka.controller:type=KafkaController,name=TopicsIneligibleToDeleteCount Ineligible pending topic deletes.
TopicsToDeleteCount
- MBean:
kafka.controller:type=KafkaController,name=TopicsToDeleteCount Pending topic deletes.
Log metrics
The following section contains metrics for logs, log cleaners, and log cleaner managers. A log directory is a directory on disk that contains one or more Kafka log segments. When a Kafka broker starts up, it registers all of the log directories that it finds on its local disk with the log manager. The log manager is responsible for managing the creation, deletion, and cleaning of log segments across all registered log directories.
LogEndOffset
- MBean:
kafka.log:type=Log,name=LogEndOffset The offset of the last message in a partition. Use with
LogStartOffsetto calculate the current message count for a topic.
LogStartOffset
- MBean:
kafka.log:type=Log,name=LogStartOffset The offset of the first message in a partition. Use with
LogEndOffsetto calculate the current message count for a topic.
NumLogSegments
- MBean:
kafka.log:type=Log:name=NumLogSegments The number of log segments that currently exist for a given partition.
Size
- MBean:
kafka.log:type=Log,name=Size A metric for the total size in bytes of all log segments that belong to a given partition.
DeadThreadCount
- MBean:
kafka.log:type=LogCleaner,name=DeadThreadCount Provides the number of dead threads for the process.
cleaner-recopy-percent
- MBean:
kafka.log:type=LogCleaner,name=cleaner-recopy-percent A metric to track the recopy rate of each thread’s last cleaning
max-buffer-utilization-percent
- MBean:
kafka.log:type=LogCleaner,name=max-buffer-utilization-percent A metric to track the maximum utilization of any thread’s buffer in the last cleaning.
max-clean-time-secs
- MBean:
kafka.log:type=LogCleaner,name=max-clean-time-secs A metric to track the maximum cleaning time for the last cleaning from each thread.
max-compaction-delay-secs
- MBean:
kafka.log:type=LogCleaner,name=max-compaction-delay-secs A metric that provides the maximum delay, in seconds, that the log cleaner will wait before compacting a log segment.
compacted-partition-bytes
- MBean:
kafka.log:type=LogCleanerManager,name=compacted-partition-bytes A gauge metric that provides compacted data in each partition.
compacted-partition-local-bytes
- MBean:
kafka.log:type=LogCleanerManager,name=compacted-partition-local-bytes A gauge metric that provides local compacted data in each partition. Confluent Server only.
compacted-partition-tiered-bytes
- MBean:
kafka.log:type=LogCleanerManager,name=compacted-partition-tiered-bytes A gauge metric that provides compacted data in each partition when using tiered storage. Confluent Server only.
max-dirty-percent
- MBean:
kafka.log:type=LogCleanerManager,name=max-dirty-percent A gauge metric that provides the maximum percentage of the log segment that can contain dirty messages before the log cleaner will begin cleaning it.
time-since-last-run-ms
- MBean:
kafka.log:type=LogCleanerManager,name=time-since-last-run-ms A gauge metric that provides the time, in milliseconds, since the log cleaner last ran.
OfflineLogDirectoryCount
- MBean:
kafka.log:type=LogManager,name=OfflineLogDirectoryCount A metric that describes the number of log directories that are registered with the log manager, but are currently offline.
LogFlushRateAndTimeMs
- MBean:
kafka.log:type=LogFlushStats,name=LogFlushRateAndTimeMs Log flush rate and time in milliseconds.
uncleanable-bytes
- MBean:
kafka.log:logDirectory="{/log-directory}":type=LogCleanerManager:name=uncleanable-bytes A metric that provides information about the total number of bytes in log segments for a specified log directory that cannot be cleaned by the log cleaner due to retention policy or other configuration settings.
uncleanable-partitions-count
- MBean:
kafka.log:logDirectory="{/log-directory}":type=LogCleanerManager:name=uncleanable-partitions-count A gauge metric that tracks the number of partitions marked as uncleanable for each log directory.
LogDirectoryOffline
- MBean:
kafka.log:logDirectory="{/log-directory}":type=LogManager,name=LogDirectoryOffline A metric that provides the number of log directories that are currently offline and not available for use by the Kafka broker.
SegmentAppendTimeMs
- MBean:
kafka.log:type=SegmentStats,name=SegmentAppendTimeMs The time in milliseconds to append a record to the log segment. Available on Confluent Server only.
OffsetIndexAppendTimeMs
- MBean:
kafka.log:type=SegmentStats,name=OffsetIndexAppendTimeMs The time in milliseconds to append an entry to the log segment offset index. The offset index maps from logical offsets to physical file positions. Available on Confluent Server only.
TimestampIndexAppendTimeMs
- MBean:
kafka.log:type=SegmentStats,name=TimestampIndexAppendTimeMs The time in milliseconds to append an entry to the log segment timestamp index. Available on Confluent Server only.
Network metrics
Kafka brokers can generate a lot of network traffic because they collect and distribute data for processing. You can use the following metrics to help evaluate whether your Kafka deployment is communicating efficiently.
RequestQueueSize
- MBean:
kafka.network:type=RequestChannel,name=RequestQueueSize Size of the request queue. A congested request queue will not be able to process incoming or outgoing requests.
ResponseQueueSize
- MBean:
kafka.network:type=RequestChannel,name=ResponseQueueSize Size of the response queue. The response queue is unbounded. A congested response queue can result in delayed response times and memory pressure on the broker.
ErrorsPerSec
- MBean:
kafka.network:type=RequestMetrics,name=ErrorsPerSec,request={requestType},error={error-code} Indicates the number of errors in responses counted per-request-type, per-error-code. If a response contains multiple errors, all are counted. error=NONE indicates successful responses.
LocalTimeMs
- MBean:
kafka.network:type=RequestMetrics,name=LocalTimeMs,request={Produce|FetchConsumer|FetchFollower} Time in milliseconds the request is processed at the leader.
MessageConversionsTimeMs
- MBean:
kafka.network:type=RequestMetrics,name=MessageConversionsTimeMs,request={Produce|Fetch} Time in milliseconds spent on message format conversions.
RemoteTimeMs
- MBean:
kafka.network:type=RequestMetrics,name=RemoteTimeMs,request={Produce|FetchConsumer|FetchFollower} Time in milliseconds the request waits for the follower. This is non-zero for produce requests when
ack=-1oracks=all.
RequestBytes
- MBean:
kafka.network:type=RequestMetrics,name=RequestBytes,request={requestType} Request size in bytes.
RequestQueueTimeMs
- MBean:
kafka.network:type=RequestMetrics,name=RequestQueueTimeMs,request={Produce|FetchConsumer|FetchFollower} Time in milliseconds that the request waits in the request queue.
RequestsPerSec
- MBean:
kafka.network:type=RequestMetrics,name=RequestsPerSec,request={Produce|FetchConsumer|FetchFollower},version=([0-9]+) The request rate.
versionrefers to the API version of the request type. To get the total count for a specific request type, make sure that JMX monitoring tools aggregate across different versions.
ResponseSendTimeMs
- MBean:
kafka.network:type=RequestMetrics,name=ResponseSendTimeMs,request={Produce|FetchConsumer|FetchFollower} Time to send the response.
TemporaryMemoryBytes
- MBean:
kafka.network:type=RequestMetrics,name=TemporaryMemoryBytes,request={Produce|Fetch} Temporary memory, in bytes, used for message format conversions and decompression.
TotalTimeMs
- MBean:
kafka.network:type=RequestMetrics,name=TotalTimeMs,request={Produce|FetchConsumer|FetchFollower} The total time in milliseconds to serve the specified request. - Produce: requests from producers to send data - FetchConsumer: requests from consumers to get data - FetchFollower: requests from follower brokers that are the followers of a partition to get new data
ExpiredConnectionsKilledCount
- MBean:
kafka.network:type=SocketServer,name=ExpiredConnectionsKilledCount The total number of connections disconnected, across all processors, due to a client not re-authenticating and then using the connection beyond its expiration time for anything other than re-authentication. Ideally 0 when re-authentication is enabled, implying there are no longer any older, pre-2.2.0 clients connecting to this broker
NetworkProcessorAvgIdlePercent
- MBean:
kafka.network:type=SocketServer,name=NetworkProcessorAvgIdlePercent The average fraction of time the network processor threads are idle. Values are between
0(all resources are used) and1(all resources are available).Ideally this is less than 0.3.
ZooKeeper metrics
Important
As of Confluent Platform 7.5, ZooKeeper is deprecated for new deployments. Confluent recommends KRaft mode for new deployments. For more information, see KRaft Overview.
ZooKeeper state transition counts are exposed as metrics, which can help to spot problems with your cluster. For example, such as broker connections to ZooKeeper. The metrics show the transitions rate per second for each one of the possible states. Here is the list of the counters we expose, one for each possible ZooKeeper client state.
ZooKeeperDisconnectsPerSec
- MBean:
kafka.server:type=SessionExpireListener,name=ZooKeeperDisconnectsPerSec A meter that provides the number of recent ZooKeeper client disconnects. Note that this metric does not tell you the number of disconnected clients or if ZooKeeper is down. The number does not change when a connection that was reported as disconnected is reestablished. In addition, this count returns to zero after about 90 minutes, even if the client never successfully reconnects to ZooKeeper. If you are checking system health,
ZooKeeperExpiresPerSecis a better metric to help you determine this.
ZooKeeperExpiresPerSec
- MBean:
kafka.server:type=SessionExpireListener,name=ZooKeeperExpiresPerSec The ZooKeeper session has expired. Note that when a session expires it could result in leader changes or possibly a new controller. You should monitor the number of these events across a Kafka cluster and if the overall number is high, you can do the following:
Check the health of your network
Check for garbage collection issues and tune it accordingly
If necessary, increase the session time out by setting the value of
zookeeper.session.timeout.ms.
Following are additional ZooKeeper metrics you can optionally observe on a Kafka broker.
ZooKeeperSyncConnectsPerSec
- MBean:
kafka.server:type=SessionExpireListener,name=ZooKeeperSyncConnectsPerSec Reports the number of ZooKeeper client connections per second to execute operations.
ZooKeeperAuthFailuresPerSec
- MBean:
kafka.server:type=SessionExpireListener,name=ZooKeeperAuthFailuresPerSec Reports the number of attempts to connect to the ensemble that failed because the client has not provided correct credentials.
ZooKeeperReadOnlyConnectsPerSec
- MBean:
kafka.server:type=SessionExpireListener,name=ZooKeeperReadOnlyConnectsPerSec The server the client is connected to is currently LOOKING, which means that it is neither FOLLOWING nor LEADING. Consequently, the client can only read the ZooKeeper state, but not make any changes (create, delete, or set the data of znodes).
ZooKeeperSaslAuthenticationsPerSec
- MBean:
kafka.server:type=SessionExpireListener,name=ZooKeeperSaslAuthenticationsPerSec Indicates the number of times the client has successfully authenticated per second.
SessionState
- MBean:
kafka.server:type=SessionExpireListener,name=SessionState The connection status of broker’s ZooKeeper session. Expected value is
CONNECTED.
Producer metrics
The following metrics are available on a producer instance. These metrics are attributes on the associated MBean.
waiting-threads
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The number of user threads blocked waiting for buffer memory to enqueue their records. Kafka 3.1.1 and later.
buffer-total-bytes
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The maximum amount of buffer memory the client can use whether or not it is available. Kafka 3.1.1 and later.
buffer-available-bytes
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The total amount of buffer memory that is not being used, either unallocated or in the free list. Kafka 3.1.1 and later.
bufferpool-wait-time
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The fraction of time an appender waits for space allocation. Kafka 3.1.1 and later.
bufferpool-wait-time-ns-total
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The total time in nanoseconds an appender waits for space allocation in nanoseconds. Kafka 3.1.1 and later.
flush-time-ns-total
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The total time in nanoseconds the producer spent in
Producer.flush. Kafka 3.1.1 and later.
txn-init-time-ns-total
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The total time in nanoseconds that the producer spent initializing transactions for exactly-once semantics. Kafka 3.1.1 and later.
txn-begin-time-ns-total
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The total time in nanoseconds the producer spent in
beginTransactionfor exactly-once semantics. Kafka 3.1.1 and later.
txn-send-offsets-time-ns-total
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The total time the producer spent sending offsets to transactions in nanoseconds for exactly-once semantics. Kafka 3.1.1 and later.
txn-commit-time-ns-total
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The total time in nanoseconds the producer spent committing transactions for exactly-once semantics.
txn-abort-time-ns-total
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The total time in nanoseconds the producer spent aborting transactions for exactly-once semantics. Kafka 3.1.1 and later.
batch-size-avg
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The average number of bytes sent per partition per-request. Global request metric.
batch-size-max
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The maximum number of bytes sent per partition per-request. Global request metric.
batch-split-rate
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The average number of batch splits per second. Global request metric.
batch-split-total
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The total number of batch splits. Global request metric.
compression-rate-avg
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The average compression rate of record batches, defined as the average ratio of the compressed batch size over the uncompressed size. Global request metric.
incoming-byte-rate
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The average number of incoming bytes received per second from all servers. Global request metric.
metadata-age
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The age, in seconds, of the current producer metadata being used. Global request metric.
outgoing-byte-rate
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The average number of bytes sent per second to all servers. Global request metric.
produce-throttle-time-avg
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The average time in milliseconds a request was throttled by a broker. Global request metric.
produce-throttle-time-max
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The maximum time in milliseconds a request was throttled by a broker. Global request metric.
record-error-rate
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The average per-second number of record sends that resulted in errors. Global request metric.
record-error-total
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The total number of record sends that resulted in errors. Global request metric.
record-queue-time-avg
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The average time in milliseconds record batches spent in the send buffer. Global request metric.
record-queue-time-max
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The maximum time in milliseconds record batches spent in the send buffer. Global request metric.
record-retry-rate
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The average per-second number of retried record sends. Global request metric.
record-retry-total
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The total number of retried record sends. Global request metric.
record-send-rate
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The average number of records sent per second. Global request metric.
record-send-total
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The total number of records sent. Global request metric.
record-size-avg
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The average record size. Global request metric.
record-size-max
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The maximum record size. Global request metric.
records-per-request-avg
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The average number of records per request. Global request metric.
request-rate
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The average number of requests sent per second. Global request metric.
requests-in-flight
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The current number of in-flight requests awaiting a response. Global request metric.
bufferpool-wait-time-ns-total
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The total time in nanoseconds a producer waits for space allocation. Global connection metric.
connection-close-rate
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The connections closed per second in the window. Global connection metric.
connection-count
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The current number of active connections. Global connection metric.
connection-creation-rate
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The number of new connections established per second in the window. Global connection metric.
io-ratio
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The fraction of time the I/O thread spent doing I/O. Global connection metric.
io-time-ns-avg
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The average length of time for I/O per select call in nanoseconds. Global connection metric.
io-time-ns-total
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The total time the I/O thread spent doing I/O in nanoseconds. Global connection metric.
io-wait-ratio
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The fraction of time the I/O thread spent waiting. Global connection metric.
io-wait-time-ns-avg
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The average length of time the I/O thread spent waiting for a socket ready for reads or writes in nanoseconds. Global connection metric.
io-wait-time-ns-total
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The total length of time the I/O thread spent waiting for a socket ready for reads or writes in nanoseconds. Global connection metric.
select-rate
- MBean:
kafka.producer:type=producer-metrics,client-id={clientId} The number of times the I/O layer checked for new I/O to perform per second. Global connection metric.
Besides the producer global request metrics, the following metrics are also available per broker:
incoming-byte-rate
- MBean:
kafka.producer:type=producer-node-metrics,client-id={clientId},node-id=([0-9]+) The average number of bytes received per second from the broker.
outgoing-byte-rate
- MBean:
kafka.producer:type=producer-node-metrics,client-id={clientId},node-id=([0-9]+) The average number of bytes sent per second to the broker.
request-size-avg
- MBean:
kafka.producer:type=producer-node-metrics,client-id={clientId},node-id=([0-9]+) The average size of all requests in the window for a broker.
request-size-max
- MBean:
kafka.producer:type=producer-node-metrics,client-id={clientId},node-id=([0-9]+) The maximum size of any request sent in the window for a broker.
request-rate
- MBean:
kafka.producer:type=producer-node-metrics,client-id={clientId},node-id=([0-9]+) The average number of requests sent per second to the broker.
response-rate
- MBean:
kafka.producer:type=producer-node-metrics,client-id={clientId},node-id=([0-9]+) The average number of responses received per second from the broker.
In addition to the producer global request metrics, the following metric attributes are available per topic:
byte-rate
- MBean:
kafka.producer:type=producer-topic-metrics,client-id="{clientId}",topic="{topic} The average number of bytes sent per second for a topic.
byte-total
- MBean:
kafka.producer:type=producer-topic-metrics,client-id="{clientId}",topic="{topic} The total number of bytes sent for a topic.
compression-rate
- MBean:
kafka.producer:type=producer-topic-metrics,client-id="{clientId}",topic="{topic} The average compression rate of record batches for a topic. This is computed by averaging the compression ratios of the record batches. The compression ratio is computed by dividing the compressed batch size by the uncompressed size.
record-error-rate
- MBean:
kafka.producer:type=producer-topic-metrics,client-id="{clientId}",topic="{topic} The average per-second number of record sends that resulted in errors for a topic.
record-error-total
- MBean:
kafka.producer:type=producer-topic-metrics,client-id="{clientId}",topic="{topic} The total number of record sends that resulted in errors for a topic.
record-retry-rate
- MBean:
kafka.producer:type=producer-topic-metrics,client-id="{clientId}",topic="{topic} The average per-second number of retried record sends for a topic.
record-retry-total
- MBean:
kafka.producer:type=producer-topic-metrics,client-id="{clientId}",topic="{topic} The total number of retried record sends for a topic.
record-send-rate
- MBean:
kafka.producer:type=producer-topic-metrics,client-id="{clientId}",topic="{topic} The average number of records sent per second for a topic.
record-send-total
- MBean:
kafka.producer:type=producer-topic-metrics,client-id="{clientId}",topic="{topic} The total number of records sent for a topic.
Consumer metrics
A consumer instance exposes the following metrics. These metrics are attributes on the listed MBean.
committed-time-ns-total
- MBean:
kafka.consumer:type=consumer-metrics,client-id={clientId} The cumulative sum of time in nanoseconds elapsed during calls to
Consumer.committed. Kafka 3.1.1 and later.
commit-sync-time-ns-total
- MBean:
kafka.consumer:type=consumer-metrics,client-id={clientId} The cumulative sum of time in nanoseconds elapsed during calls to
Consumer.commitSync. Kafka 3.1.1 and later.
time-between-poll-avg
- MBean:
kafka.consumer:type=consumer-metrics,client-id={clientId} The average delay between invocations of
poll(). Kafka 2.4.0 and later.
time-between-poll-max
- MBean:
kafka.consumer:type=consumer-metrics,client-id={clientId} The maximum delay between invocations of
poll(). Kafka 2.4.0 and later.
last-poll-seconds-ago
- MBean:
kafka.consumer:type=consumer-metrics,client-id={clientId} The number of seconds since the last
poll()invocation. Kafka 2.4.0 and later.
poll-idle-ratio-avg
- MBean:
kafka.consumer:type=consumer-metrics,client-id={clientId} The average fraction of time the consumer’s
poll()is idle as opposed to waiting for the user code to process records. Kafka 2.4.0 and later.
bytes-consumed-rate
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}" The average number of bytes consumed per second.
bytes-consumed-total
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}" The total number of bytes consumed.
fetch-latency-avg
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}" The average time taken for a fetch request.
fetch-latency-max
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}" The maximum time taken for a fetch request.
fetch-rate
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}" The number of fetch requests per second.
fetch-size-avg
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}" The average number of bytes fetched per request.
fetch-size-max
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}" The maximum number of bytes fetched per request.
fetch-throttle-time-avg
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}" The average throttle time in milliseconds. When quotas are enabled, the broker may delay fetch requests in order to throttle a consumer which has exceeded its limit. This metric indicates how throttling time has been added to fetch requests on average.
fetch-throttle-time-max
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}" The maximum throttle time in milliseconds.
fetch-total
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}" The total number of fetch requests.
records-consumed-rate
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}" The average number of records consumed per second.
records-consumed-total
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}" The total number of records consumed.
records-lag-max
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}" The maximum lag in terms of number of records for any partition in this window. An increasing value over time is your best indication that the consumer group is not keeping up with the producers.
records-lead-min
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}" The minimum lead in terms of number of records for any partition in this window.
records-per-request-avg
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}" The average number of records in each request.
bytes-consumed-rate
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}",topic="{topic}" The average number of bytes consumed per second for a specific topic.
bytes-consumed-total
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}",topic="{topic}" The total number of bytes consumed for a specific topic.
fetch-size-avg
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}",topic="{topic}" The average number of bytes fetched per request for a specific topic.
fetch-size-max
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}",topic="{topic}" The maximum number of bytes fetched per request for a specific topic.
records-consumed-rate
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}",topic="{topic}" The average number of records consumed per second for a specific topic.
records-consumed-total
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}",topic="{topic}" The total number of records consumed for a specific topic.
records-per-request-avg
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,client-id="{clientId}",topic="{topic}" The average number of records in each request for a specific topic.
preferred-read-replica
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,partition="{partition}",topic="{topic}",client-id="{clientId} The current read replica for the partition, or -1 if reading from leader.
records-lag
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,partition="{partition}",topic="{topic}",client-id="{clientId} The latest lag of the specified partition.
records-lag-avg
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,partition="{partition}",topic="{topic}",client-id="{clientId} The average lag of the specified partition.
records-lag-max
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,partition="{partition}",topic="{topic}",client-id="{clientId} The maximum lag of the specified partition.
records-lead
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,partition="{partition}",topic="{topic}",client-id="{clientId} The latest lead of the specified partition.
records-lead-avg
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,partition="{partition}",topic="{topic}",client-id="{clientId} The average lead of the specified partition.
records-lead-min
- MBean:
kafka.consumer:type=consumer-fetch-manager-metrics,partition="{partition}",topic="{topic}",client-id="{clientId} The min lead of the specified partition.
incoming-byte-rate
- MBean:
kafka.consumer:type=consumer-metrics,client-id={clientId} The average number of incoming bytes received per second from all servers. Global request metric.
outgoing-byte-rate
- MBean:
kafka.consumer:type=consumer-metrics,client-id={clientId} The average number of outgoing bytes sent per second to all servers. Global request metric.
request-latency-avg
- MBean:
kafka.consumer:type=consumer-metrics,client-id={clientId} The average request latency in milliseconds. Global request metric.
request-latency-max
- MBean:
kafka.consumer:type=consumer-metrics,client-id={clientId} The maximum request latency in milliseconds. Global request metric.
request-rate
- MBean:
kafka.consumer:type=consumer-metrics,client-id={clientId} The average number of requests sent per second. Global request metric.
response-rate
- MBean:
kafka.consumer:type=consumer-metrics,client-id={clientId} The average number of responses received per second. Global request metric.
connection-count
- MBean:
kafka.consumer:type=consumer-metrics,client-id={clientId} The current number of active connections. Consumer global connection metric.
connection-creation-rate
- MBean:
kafka.consumer:type=consumer-metrics,client-id={clientId} The number of new connections established per second in the window. Consumer global connection metric.
connection-close-rate
- MBean:
kafka.consumer:type=consumer-metrics,client-id={clientId} The number of connections closed per second in the window. Consumer global connection metric.
io-ratio
- MBean:
kafka.consumer:type=consumer-metrics,client-id={clientId} The fraction of time the I/O thread spent doing I/O. Consumer global connection metric.
io-time-ns-avg
- MBean:
kafka.consumer:type=consumer-metrics,client-id={clientId} The average length of time for I/O per select call in nanoseconds. Consumer global connection metric.
io-wait-ratio
- MBean:
kafka.consumer:type=consumer-metrics,client-id={clientId} The fraction of time the I/O thread spent waiting. Consumer global connection metric.
io-wait-time-ns-avg
- MBean:
kafka.consumer:type=consumer-metrics,client-id={clientId} The average length of time the I/O thread spent waiting for a socket ready for reads or writes in nanoseconds. Consumer global connection metric.
select-rate
- MBean:
kafka.consumer:type=consumer-metrics,client-id={clientId} The number of times the I/O layer checked for new I/O to perform per second. Consumer global connection metric.
incoming-byte-rate
- MBean:
kafka.consumer:type=consumer-node-metrics,client-id={clientId},node-id=([0-9]+) The average number of bytes received per second from the specified broker.
outgoing-byte-rate
- MBean:
kafka.consumer:type=consumer-node-metrics,client-id={clientId},node-id=([0-9]+) The average number of bytes sent per second to the specified broker.
request-size-avg
- MBean:
kafka.consumer:type=consumer-node-metrics,client-id={clientId},node-id=([0-9]+) The average size of all requests in the window for a specified broker.
request-size-max
- MBean:
kafka.consumer:type=consumer-node-metrics,client-id={clientId},node-id=([0-9]+) The maximum size of any request sent in the window for a specified broker.
request-rate
- MBean:
kafka.consumer:type=consumer-node-metrics,client-id={clientId},node-id=([0-9]+) The average number of requests sent per second to the specified broker.
response-rate
- MBean:
kafka.consumer:type=consumer-node-metrics,client-id={clientId},node-id=([0-9]+) The average number of responses received per second from the specified broker.
Consumer group metrics
A consumer group exposes the following metrics. These metrics are attributes on the listed MBean.
assigned-partitions
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The number of partitions currently assigned to this consumer.
commit-latency-avg
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The average time taken for a commit request.
commit-latency-max
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The maximum time taken for a commit request.
commit-rate
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The number of commit calls per second.
commit-total
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The total number of commit calls.
failed-rebalance-rate-per-hour
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The number of failed group rebalance event per hour.
failed-rebalance-total
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The total number of failed group rebalances.
heartbeat-rate
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The average number of heartbeats per second. After a rebalance, the consumer sends heartbeats to the coordinator to keep itself active in the group. You can control this using the
heartbeat.interval.mssetting for the consumer. You may see a lower rate than configured if the processing loop is taking more time to handle message batches. Usually this is OK as long as you see no increase in the join rate.
heartbeat-response-time-max
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The maximum time taken to receive a response to a heartbeat request.
heartbeat-total
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The total number of heartbeats.
join-rate
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The number of group joins per second. Group joining is the first phase of the rebalance protocol. A large value indicates that the consumer group is unstable and will likely be coupled with increased lag.
join-time-avg
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The average time taken for a group rejoin. This value can get as high as the configured session timeout for the consumer, but should usually be lower.
join-time-max
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The maximum time taken for a group rejoin. This value should not get much higher than the configured session timeout for the consumer.
join-total
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The total number of group joins.
last-heartbeat-seconds-ago
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The number of seconds since the last controller heartbeat.
last-rebalance-seconds-ago
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The number of seconds since the last rebalance event.
partitions-assigned-latency-avg
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The average time taken by the
on-partitions-assignedrebalance listener callback.
partitions-assigned-latency-max
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The maximum time taken by the
on-partitions-assignedrebalance listener callback.
partitions-lost-latency-avg
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The average time taken by the
on-partitions-lostrebalance listener callback.
partitions-lost-latency-max
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The maximum time taken by the
on-partitions-lostrebalance listener callback.
partitions-revoked-latency-avg
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The average time taken by the
on-partitions-revokedrebalance listener callback.
partitions-revoked-latency-max
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The maximum time taken by the
on-partitions-revokedrebalance listener callback.
rebalance-latency-avg
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The average time taken for a group rebalance.
rebalance-latency-max
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The maximum time taken for a group rebalance.
rebalance-latency-total
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The total time taken for group rebalances so far.
rebalance-rate-per-hour
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The number of group rebalance participated per hour.
rebalance-total
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The total number of group rebalances participated.
sync-rate
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The number of group syncs per second. Group synchronization is the second and last phase of the rebalance protocol. Similar to
join-rate, a large value indicates group instability.
sync-time-avg
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The average time taken for a group sync.
sync-time-max
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The maximum time taken for a group sync.
sync-total
- MBean:
kafka.consumer:type=consumer-coordinator-metrics,client-id={clientId} The total number of group syncs.
Audit metrics
These audit metrics are specific Confluent Enterprise. For information about how audit logging works, see Audit Log Concepts.
audit-log-rate-per-minute
- MBean:
confluent-audit-metrics:name=audit-log-rate-per-minute The number of audit log entries created per minute. This metric is useful in cases where you need to know the number of audit logs created.
audit-log-fallback-rate-per-minute
- MBean:
confluent-audit-metrics:name=audit-log-fallback-rate-per-minute The rate of audit log fallback entries per minute. If the audit logging mechanism tries to write to the Kafka topic and doesn’t succeed for any reason, it writes the JSON audit log message to log4j instead. This metric is useful in cases where you need to know the fallback rate of your audit logs.
authentication-audit-log-rate
- MBean:
confluent-audit-metrics:name=authentication-audit-log-rate The number authentication audit log entries created per second.
authentication-audit-log-failure-rate
- MBean:
confluent-audit-metrics:name=authentication-audit-log-rate The number of authentication failure entries per second.
kafka-request-event-audit-log-rate
- MBean:
confluent-audit-metrics:name=kafka-request-event-audit-log-rate The number of Kafka request event audit log entries per second.
kafka-request-event-audit-log-failure-rate
- MBean:
confluent-audit-metrics:name=kafka-request-event-audit-log-failure-rate The number of Kafka request event audit log failure entries per second.
RBAC and LDAP metrics
The following metrics are exposed when you use RBAC and LDAP.
failure-start-seconds-ago
- MBean:
confluent.metadata:type=LdapGroupManager,name=failure-start-seconds-ago The number of seconds since the last failed attempt to process metadata from the LDAP server. This is reset to zero on the next successful metadata refresh. This metric is available on brokers in the metadata cluster if LDAP group-based authorization is enabled. Alert if value is greater than zero.
writer-failure-start-seconds-ago
- MBean:
confluent.metadata:type=KafkaAuthStore,name=writer-failure-start-seconds-ago The number of seconds since the last failure in the writer that updates authentication or authorization metadata on topics in the metadata cluster. This is reset to zero after the next successful metadata update. This metric is available on brokers in the metadata cluster. Alert if value is greater than zero.
reader-failure-start-seconds-ago
- MBean:
confluent.metadata:type=KafkaAuthStore,name=reader-failure-start-seconds-ago The number of seconds since the last failure in the consumer that processes authentication or authorization metadata from the topics in the metadata cluster. This is reset to zero after the next successful metadata refresh. This metric is available on all brokers configured to use RBAC. Alert if value is greater than zero.
remote-failure-start-seconds-ago
- MBean:
confluent.metadata:type=KafkaAuthStore,name=remote-failure-start-seconds-ago The number of seconds since the last failure in the metadata service, for example, due to LDAP refresh failures for a long duration. This is reset to zero when notification of successful refresh from the metadata service is processed. This metric is available on all brokers configured to use RBAC. Alert if value is greater than zero.
active-writer-count
- MBean:
confluent.metadata:type=KafkaAuthStore,name=active-writer-count The number of active writers in the metadata cluster. Alert if the sum is any number other than one because there should be exactly one writer in the metadata cluster.
metadata-status
- MBean:
confluent.metadata:type=KafkaAuthStore,name=metadata-status,topic=([-.\w]+),partition=([0-9]+) The current status of metadata on each metadata topic partition. Value may be UNKNOWN, INITIALIZING, INITIALIZED or FAILED.
record-send-rate
- MBean:
confluent.metadata:type=KafkaAuthStore,name=record-send-rate,topic=([-.\w]+),partition=([0-9]+) The average number of records sent per second to the metadata topic partitions.
record-error-rate
- MBean:
confluent.metadata:type=KafkaAuthStore,name=record-error-rate,topic=([-.\w]+),partition=([0-9]+) The average number of record send attempts per second to the metadata topic partitions that failed.
rbac-role-bindings
- MBean:
kafka.server:type=confluent-auth-store-metrics:name=rbac-role-bindings-count The number of role bindings defined. This metric is useful in cases where you need to know the exact number of role bindings that exist.
rbac-access-rules-count
- MBean:
kafka.server:type=confluent-auth-store-metrics:name=rbac-access-rules-count The number of RBAC access rules defined. This metric is useful in cases where you need to know the exact number of RBAC access rules that exist. Access rules allow or deny access to specific resources within a specific scope, unlike role bindings, which assign an RBAC role for a specific resource to a specific principal.
acl-access-rules-count
- MBean:
kafka.server:type=confluent-auth-store-metrics:name=acl-access-rules-count The number of ACL access rules defined. This metric is useful in cases where you need to know the exact number of ACLs that exist.