
Configure Cluster Linking on Confluent Platform
This page describes how to configure Cluster Linking with various Confluent tools, products, and security options.
Using Cluster Linking with Confluent for Kubernetes
You can use Cluster Linking with Confluent Platform deployed with Confluent for Kubernetes.
Confluent for Kubernetes 2.2 released built-in Cluster Linking support, as described in this section of the CFK documentation: Cluster Linking using Confluent for Kubernetes.
To configure Cluster Linking on earlier versions of CFK, use configOverrides in the Kafka custom resource. See Configuration Overrides. in the CFK documentation for more information about using configOverrides.
Also, pre Confluent Platform 7.0.0 releases required that you include a configOverrides section on the server to specify confluent.cluster.link.enable: "true". For Confluent Platform 7.0.0 and later releases, Cluster Linking is enabled by default, so this element of the configuration is no longer needed, regardless of the Confluent for Kubernetes version.
For example:
apiVersion: platform.confluent.io/v1beta1
kind: Kafka
metadata:
name: kafka
namespace: confluent
spec:
replicas: 3
image:
application: confluentinc/cp-server:7.6.12
init: confluentinc/confluent-init-container:2.0.1
configOverrides:
server:
- confluent.cluster.link.enable=true # Enable Cluster Linking
Using Cluster Linking with Ansible
You can use Cluster Linking with Confluent Platform deployed with Ansible.
Starting in Confluent Platform 7.0.0, Cluster Linking is enabled by default, so no changes are needed to the configuration file.
Tip
Pre Confluent Platform 7.0.0 releases required that you add a broker configuration property to the kafka_broker_custom_properties section in the inventory as described in Configure Confluent Platform with Ansible, to set confluent.cluster.link.enable: "true". If you are upgrading from an earlier release, this configuration can be deleted, as it is no longer needed.
Link Properties
Several configurations are available for cluster links. The following sections describe how to set these using the CLI commands, and then list the available properties.
Note that Cluster Linking configurations are isolated from Kafka broker configurations, as such there is no property inheritance from Kafka broker to Cluster Linking. Only properties passed during cluster links create and update will override Cluster Linking behavior.
Setting Properties on a Cluster Link
You can set configurations on each, individual cluster link. To do this, provide the configurations as “key=value” pairs in a properties file, and pass the file as an argument to the CLI commands using either:
the
--config-fileflag, when you first create the link,Or, the
--add-config-fileflag to update configurations on an existing link.
Alternatively, you can specify or update properties for the cluster link by providing “key=value” pairs directly on the command line, using either:
the
--configflag, when you first create the link,Or, the
--add-configflag to update configurations on an existing link.
Tip
When updating the configuration for an existing cluster link, pass in only those configs that change. Be especially mindful when you are using a config file with
--add-config--file(where it would be easy to pass in a full set of configs) that it contains only the configs you want to update. For example,my-update-configs.txtmight include:consumer.offset.sync.ms=25384 topic.config.sync.ms=38254
You can change several aspects of a cluster link configuration, but you cannot change its source cluster (source cluster ID), prefix, or the link name.
Examples and command syntax for specifying link properties in a file and at the command line are shown in in Creating a cluster link and in Altering a cluster link, and in the Tutorial: Share Data Across Topics Using Cluster Linking for Confluent Platform.
Configuration Options
These properties are available to specify for the cluster link.
If you disable a feature that has filters (ACL sync, consumer offset sync, auto create mirror topics) after having it enabled initially, then any existing filters will be cleared (deleted) from the cluster link.
acl.filtersJSON string that lists the ACLs to migrate. Define the ACLs in a file,
acl.filters.json, and pass the file name as an argument to--acl-filters-json-file. See Migrating ACLs from Source to Destination Cluster for examples of how to define the ACLs in the JSON file.Type: string
Default: “”
Note
Populate
acl.filtersby passing a JSON file on the command line that specifies the ACLs as described in Migrating ACLs from Source to Destination Cluster.acl.sync.enableWhether or not to migrate ACLs. To learn more, see Migrating ACLs from Source to Destination Cluster.
Type: boolean
Default: false
acl.sync.msHow often to refresh the ACLs, in milliseconds (if ACL migration is enabled). The default is 5000 milliseconds (5 seconds).
Type: int
Default: 5000
auto.create.mirror.topics.enableWhether or not to auto-create mirror topics based on topics on the source cluster. When set to “true”, mirror topics will be auto-created. Setting this option to “false” disables mirror topic creation and clears any existing filters. For details on this option, see auto-create mirror topics.
auto.create.mirror.topics.filtersA JSON object with one property,
topicFilters, that contains an array of filters to apply to indicate which topics should be mirrored. For details on this option, see auto-create mirror topics.
cluster.link.prefixA prefix that is applied to the names of the mirror topics. The same prefix is applied to consumer groups when consumer.group.prefix.enable is set to
true. To learn more, see “Prefixing Mirror Topics and Consumer Group Names” in Mirror Topics.Note
The prefix cannot be changed after the cluster link is created.
Type: string
Default: null
cluster.link.pausedWhether or not the cluster link is running or paused. The default is false.
Type: boolean
Default: false
cluster.link.retry.timeout.msThe number of milliseconds after which failures are no longer retried and partitions are marked as failed. If the source topic is deleted and re-created within this timeout, the link may contain records from the old as well as the new topic.
Type: int
Default: 300000 (5 minutes)
availability.check.msHow often the cluster link checks to see if the source cluster is available. The frequency with which the cluster link checks is specified in milliseconds.
Type: int
Default: 60000 (1 minute)
A cluster link regularly checks whether the source cluster is still available for mirroring data by performing a
DescribeClusteroperation (bounded bydefault.api.timeout.ms). If the source cluster becomes unavailable (for example, because of an outage or disaster), then the cluster link signals this by updating its status and the status of its mirror topics.availability.check.msworks in tandem availability.check.consecutive.failure.threshold.
availability.check.consecutive.failure.thresholdThe number of consecutive failed availability checks the source cluster is allowed before the cluster link status becomes
SOURCE_UNAVAILABLE.Type: int
Default: 5
If, for example, the default (5) is used, the source cluster is determined to be unavailable after 5 failed checks in a row. If availability.check.ms and
default.api.timeout.msare also set to their defaults of 1 minute and there are 5 failed checks, then the cluster link will show asSOURCE_UNAVAILABLEafter 5 * (1+1) mins = 10 minutes. Note that this reflects that source unavailability is detected afteravailability.check.consecutive.failure.threshold* (default.api.timeout.ms+availability.check.ms), taking into account theDescribeClusteroperation performed as a part of availability.check.ms.connections.max.idle.msIdle connections timeout. The server socket processor threads close any connections that idle longer than this.
Type: int
Default: 600000
connection.modeUsed only for source-initiated links. Set this to INBOUND on the destination cluster’s link (which you create first). Set this to OUTBOUND on the source cluster’s link (which you create second). You must use this in combination with
link.mode. This property should only be set for source-initiated cluster links.Type: string
Default: OUTBOUND
consumer.offset.group.filtersJSON to denote the list of consumer groups to be migrated. To learn more, see Migrating consumer groups from source to destination cluster.
Type: string
Default: “”
Note
Consumer group filters should only include groups that are not being used on the destination. This will help ensure that the system does not override offsets committed by other consumers on the destination. The system attempts to work around filters containing groups that are also used on the destination, but in these cases there are no guarantees; offsets may be overwritten. For mirror topic “promotion” to work, the system must be able to roll back offsets, which cannot be done if the group is being used by destination consumers.
consumer.offset.sync.enableWhether or not to migrate consumer offsets from the source cluster.
If you set this up and run Cluster Linking, then later disable it, the filters will be cleared (deleted) from the cluster link.
Type: boolean
Default: false
consumer.offset.sync.msHow often to sync consumer offsets, in milliseconds, if enabled.
Type: int
Default: 30000
consumer.group.prefix.enableWhen set to
true, the prefix specified for the cluster link prefix is also applied to the names of consumer groups. The cluster link prefix must be specified in order for the consumer group prefix to be applied. To learn more, see “Prefixing Mirror Topics and Consumer Group Names” in Mirror Topics.Type: boolean
Default: false
Note
Consumer group prefixing cannot be enabled for bidirectional links.
num.cluster.link.fetchersNumber of fetcher threads used to replicate messages from source brokers in cluster links.
Type: int
Default: 1
topic.config.sync.msHow often to refresh the topic configs, in milliseconds.
Type: int
Default: 5000
local.listener.nameFor a source initiated link, an alternative listener to be used by the cluster link on the source cluster. For more, see Understanding Listeners in Cluster Linking
link.modeUsed only for source-initiated links. Set this to DESTINATION on the destination cluster’s link (which you create first). Set this to SOURCE on the source cluster’s link (which you create second). For bidirectional mode, set this to BIDIRECTIONAL on both clusters. You must use this in combination with
connection.mode. This property should only be set for source-initiated cluster links.Type: string
Default: DESTINATION
mirror.start.offset.specWhether to get the full history of a mirrored topic (
earliest), exclude the history and get only thelatestversion, or to get the history of the topic starting at a given timestamp.Type: string
Default: earliest
If set to a value of
earliest(the default), new mirror topics get the full history of their associated topics.If set to a value of
latest, new mirror topics will exclude the history and only replicate messages sent after the mirror topic is created.If set to a timestamp in ISO 8601 format (
YYYY-MM-DDTHH:mm:SS.sss), new mirror topics get the history of the topics starting from the timestamp.
When a mirror topic is created, it reads the value of this configuration and begins replication accordingly. If the setting is changed, it does not affect existing mirror topics; new mirror topics use the new value when they’re created.
If some mirror topics need to start from earliest and some need to start from latest, there are two options:
Change the value of the cluster link’s
mirror.start.offset.specto the desired starting position before creating the mirror topic, orUse two distinct cluster links, each with their own value for
mirror.start.offset.spec, and create mirror topics on the appropriate cluster link as desired.
topic.config.sync.msHow often to refresh the topic configs, in milliseconds.
Type: int
Default: 5000
Kafka broker configurations
Several properties specific to Cluster Linking are available to set on the brokers. A full reference is provided in Kafka Broker and Controller Configuration Reference for Confluent Platform. Broker properties related to Cluster Linking are prefixed with confluent.cluster.link.
The following entries provide additional explanation for a few of these.
confluent.cluster.link.enableEnables or disables Cluster Linking. In Confluent Platform 7.0.0 and later versions, the default is
true, Cluster Linking is enabled by default. To learn how to turn off Cluster Linking, see Disabling Cluster Linking.confluent.cluster.link.allow.config.providersIf true, allow cluster link to use configuration providers to resolve the cluster link configurations. Existing cluster links that use configuration providers to resolve the configurations will not be impacted when
cluster.link.allow.config.providersis set tofalse. The next alter cluster link configurations will throwInvalidConfigexception instead. The default value istrue.
Common Configuration Options
The following subset of common properties, although not specific to Cluster Linking, may be particularly relevant to setting up and managing cluster links. These are common across Confluent Platform for clients, brokers, and security configurations, and are described in their respective sections per the links provided.
Client Configurations
For a full list of AdminClient configurations, see Kafka AdminClient Configurations for Confluent Platform.
bootstrap.serversclient.dns.lookupmetadata.max.age.msretry.backoff.msrequest.timeout.ms
Cluster Link Replication Configurations
These configuration options are fully described in Kafka Broker and Controller Configuration Reference for Confluent Platform.
replica.fetch.backoff.msreplica.fetch.max.bytesreplica.fetch.min.bytesreplica.fetch.response.max.bytesreplica.fetch.wait.max.msreplica.socket.receive.buffer.bytesreplica.socket.timeout.ms
Client SASL and TLS/SSL Configurations
sasl.client.callback.handler.classsasl.jaas.configsasl.kerberos.kinit.cmdsasl.kerberos.min.time.before.reloginsasl.kerberos.service.namesasl.kerberos.ticket.renew.jittersasl.kerberos.ticket.renew.window.factorsasl.login.callback.handler.classsasl.login.classsasl.login.refresh.buffer.secondssasl.login.refresh.min.period.secondssasl.login.refresh.window.factorsasl.login.refresh.window.jittersasl.mechanismsecurity.protocolssl.cipher.suitesssl.enabled.protocolsssl.endpoint.identification.algorithmssl.engine.factory.classssl.key.passwordssl.keymanager.algorithmssl.keystore.locationssl.keystore.passwordssl.keystore.typessl.protocolssl.providerssl.secure.random.implementationssl.trustmanager.algorithmssl.truststore.locationssl.truststore.passwordssl.truststore.type
Configuring Reconnection Speed and Behavior
A cluster link has two sets of configuration options, both exponential times, which control connections. These are the same options that Apache Kafka® clients have.
reconnect.backoff.msandreconnect.backoff.max.ms- These options determine how soon the cluster link retries after a connection failure. These are 50ms and 10s by default for cluster links.socket.connection.setup.timeout.msandsocket.connection.setup.timeout.max.ms- These options determine how long the cluster link waits for a connection attempt to succeed before breaking and retrying after a “reconnect backoff”. These are 10s and 30s, respectively, by default.
On Confluent Platform clusters, reducing the values for these options may give faster reconnection speeds, at the expense of CPU and network usage.
These options cannot be updated by cluster links that have a Confluent Cloud destination cluster.
Bidirectional Cluster Linking
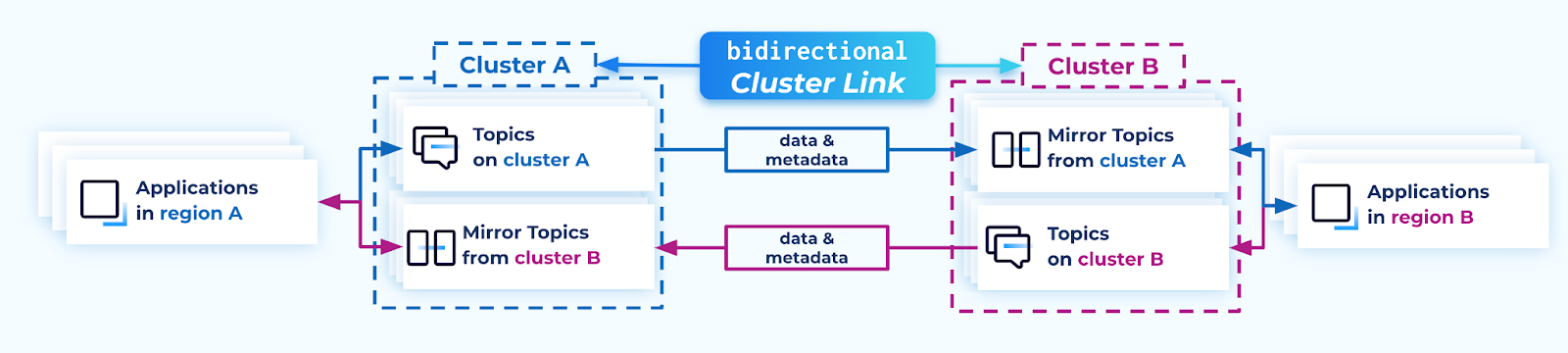
Cluster Linking bidirectional mode (a bidirectional cluster link) enables better Disaster Recovery and active/active architectures, with data and metadata flowing bidirectionally between two or more clusters.
Mental model
A useful analogy is to consider a cluster link as a bridge between two clusters.
By default, a cluster link is a one-way bridge: topics go from a source cluster to a destination cluster, with data and metadata always flowing from source to destination.
In contrast, a bidirectional cluster link is a two-way bridge: topics on either side can go to the other cluster, with data and metadata flowing in both directions.
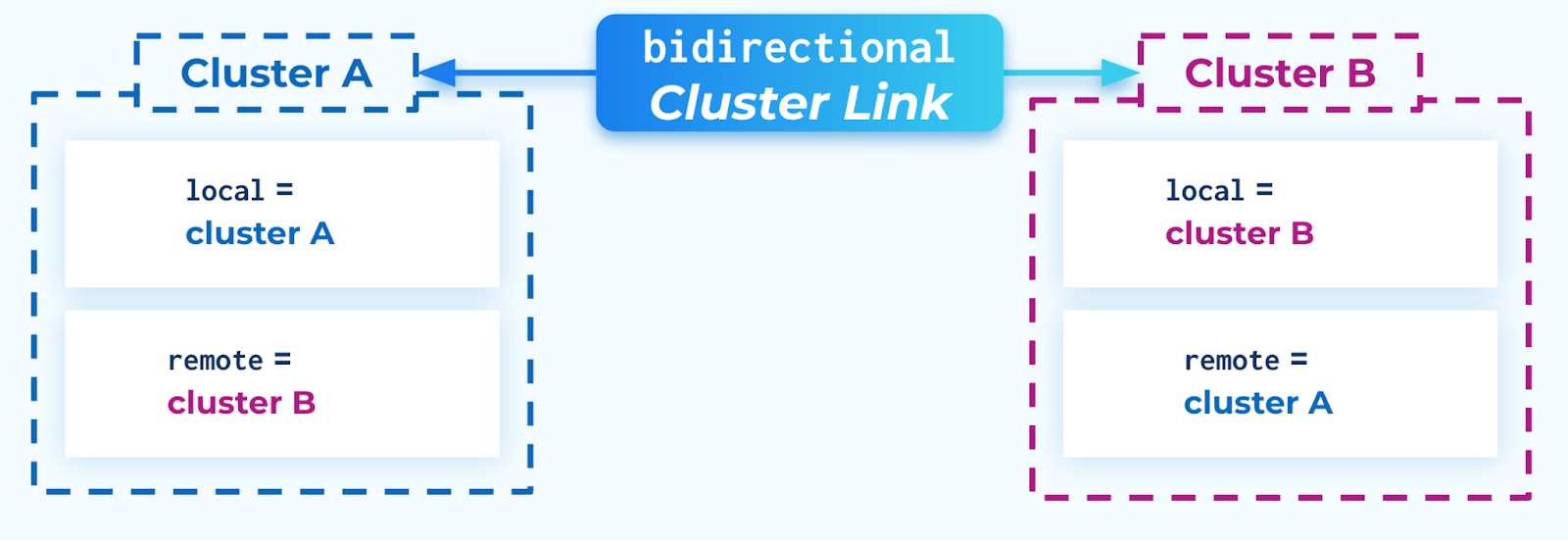
In the case of a “bidirectional” cluster link, there is no “source” or “destination” cluster. Both clusters are equal, and can function as a source or destination for the other cluster. Each cluster sees itself as the “local” cluster and the other cluster as the “remote” cluster.
Benefits
Bidirectional cluster links are advantageous in disaster recovery (DR) architectures, and certain types of migrations, as described below.
Disaster recovery
Bidirectional cluster links are useful for Disaster Recovery, both active/passive and active/active.
In a disaster recovery setup, two clusters in different regions are deployed so that at least one cluster is available at all times, even if a region experiences an outage. A bidirectional cluster link ensures both regions have the latest data and metadata from the other region, should one of them fail, or should applications need to be rotated from region to region for DR testing.
It is easier to test and practice DR by moving producers and consumers to the DR cluster and reversing the direction of data and metadata, with fewer commands and moving pieces.
For active/passive setups, a bidirectional link:
Provides the capability to promote a mirror topic, permanently breaking the mirroring link so you can fail over and convert the read-only mirror topic into a standard, writeable topic. To learn more about this workflow, see Convert a mirror topic to a normal topic.
For active/active setups, a bidirectional link syncs all consumer offsets–from both regular topics and mirror topics–to both sides. Since consumers use a mix of regular and mirror topics, it is crucial to use a bidirectional link so that the consumer’s offsets are synced to the opposite side for failover.
Consumer-last migrations
Bidirectional cluster links are useful for certain types of migrations, where consumers are migrated after producers.
In most migrations from an old cluster to a new cluster, a default cluster link suffices because consumers are migrated before or at the same time as producers.
If there are straggling consumers on the old cluster, a bidirectional cluster link can help by ensuring their consumer offsets flow to the new cluster and are available when these consumers need to migrate. A default cluster link does not do this.
Tip
Bidirectional cluster links can only be used for this use case if the clusters fit the supported combinations described below.
Restrictions and limitations
To use bidirectional mode for Cluster Linking, both clusters must be one of these types:
Bidirectional mode is not supported if either of the clusters is a Basic or Standard Confluent Cloud cluster, a version of Confluent Platform 7.4 or earlier, or open source Apache Kafka®.
Consumer group prefixing cannot be enabled for bidirectional links. Setting consumer.group.prefix.enable to true on a bidirectional cluster link will result in an “invalid configuration” error stating that the cluster link cannot be validated due to this limitation.
Security
The cluster link will need one or more principal to represent it on each cluster, and those principals will be given cluster permissions via ACLs or RBAC, consistent with how authentication and authorization works for Cluster Linking. To learn more about authentication and authorization for Cluster Linking, see Manage Security for Cluster Linking on Confluent Cloud and Manage Security for Cluster Linking on Confluent Platform
On Confluent Cloud, the same service account or identity pool can be used for both clusters, or two separate service accounts and identity pools can be used.
Default security config for bidirectional connectivity
By default, a cluster link in bidirectional mode is configured similar to the default configuration for two cluster links.
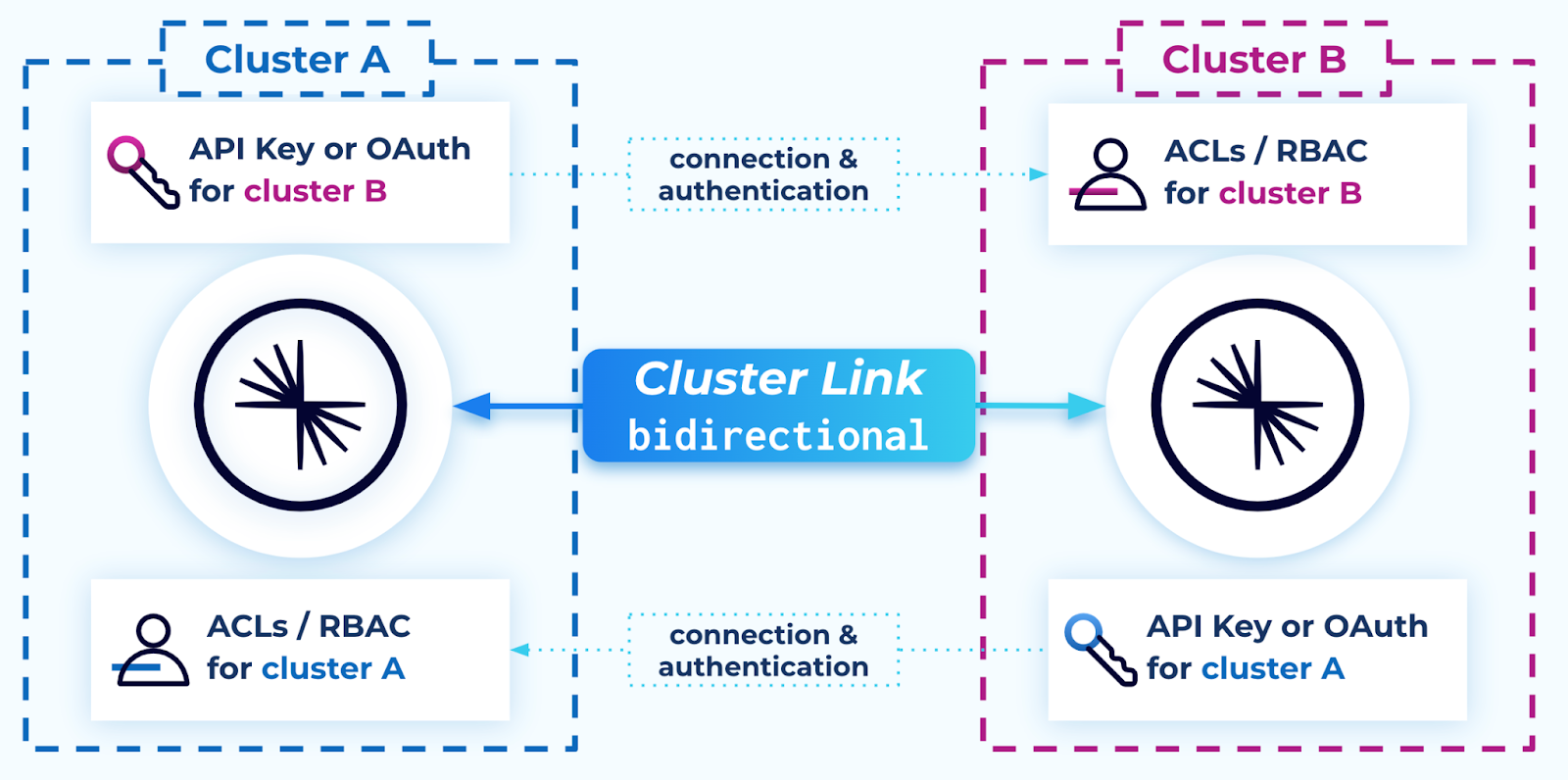
Each cluster requires:
The ability to connect (outbound) to the other cluster. (If this is not possible, see Advanced options for bidirectional Cluster Linking.)
A user to create a cluster link object on it with:
An authentication configuration (such as API key or OAuth) for a principal on its remote cluster with ACLs or RBAC role bindings giving permission to read topic data and metadata.
The Describe:Cluster ACL
The
DescribeConfigs:ClusterACL if consumer offset sync is enabled (which is recommended)The required ACLs or RBAC role bindings for a cluster link, as described in Authorization (ACLs) (the rows for a cluster link on a source cluster).
link.mode=BIDIRECTIONAL
Note
In some cases, only one cluster can reach the other. For example, if one of the clusters is in a private network or private datacenter, and the other is not. For details on how to configure a bidirectional link in this scenario, see Advanced options for bidirectional Cluster Linking.
Create a cluster link in bidirectional mode
This mini tutorial shows you how to run two clusters with bidirectional Cluster Linking for local development. You can deploy these two clusters with whatever method is best for your circumstances. The following steps show an example of how to deploy a cluster on a development laptop from the confluent-7.5.0-0 distribution.
The example commands assume that the environment variable $CONFLUENT_HOME is set to the location of your Confluent Platform install; for example, CONFLUENT_HOME=/home/ubuntu/confluent-7.5.0-0
Download Confluent Platform
Start Cluster A
Create a directory for cluster A:
mkdir a && cd a
In a dedicated terminal window in the directory for cluster A, start a ZooKeeper node for cluster A and leave it running:
Enter the following lines into the file
zk.properties, setting the path to thedataDiras desired:dataDir=/home/ubuntu/a/zookeeper-1 clientPort=2181
Start ZooKeeper.
$CONFLUENT_HOME/bin/zookeeper-server-start zk.properties
Create credentials for the Kafka cluster and for the cluster link, and a file with authentication information that will be used to issue admin commands against the cluster.
Create credentials for the Kafka cluster:
$CONFLUENT_HOME/bin/kafka-configs --zookeeper localhost:2181 --alter --add-config \ 'SCRAM-SHA-512=[iterations=8992,password=kafka-secret]' \ --entity-type users --entity-name kafka
Create credentials for the cluster link:
$CONFLUENT_HOME/bin/kafka-configs --zookeeper localhost:2181 --alter --add-config \ 'SCRAM-SHA-512=[iterations=8992,password=link-secret]' \ --entity-type users --entity-name link
Create a
CP-command.configfile with the following content:sasl.mechanism=SCRAM-SHA-512 security.protocol=SASL_PLAINTEXT sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required \ username="kafka" \ password="kafka-secret";
In a dedicated terminal window, start a broker node for cluster A and leave it running.
Create a properties file called
a1.propertieswith the following content:listeners=SASL_PLAINTEXT://:9092 advertised.listeners=SASL_PLAINTEXT://:9092 # change the value for log.dirs to any directory as appropriate log.dirs=/home/ubuntu/a/logs-1 zookeeper.connect=localhost:2181 confluent.http.server.listeners=http://localhost:8090 offsets.topic.replication.factor=1 confluent.license.topic.replication.factor=1 confluent.reporters.telemetry.auto.enable=false confluent.cluster.link.enable=true password.encoder.secret=encoder-secret authorizer.class.name=kafka.security.authorizer.AclAuthorizer inter.broker.listener.name=SASL_PLAINTEXT super.users=User:kafka sasl.enabled.mechanisms=SCRAM-SHA-512 sasl.mechanism.inter.broker.protocol=SCRAM-SHA-512 listener.name.sasl_plaintext.scram-sha-512.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="kafka" password="kafka-secret";
Start the Kafka broker:
$CONFLUENT_HOME/bin/kafka-server-start a1.properties
Start Cluster B
Create a directory for cluster B:
mkdir b && cd b
In a dedicated terminal window in the directory for cluster B, start a ZooKeeper node for cluster B and leave it running:
Enter the following lines into the file
zk.properties, setting the path to thedataDiras desired:dataDir=/home/ubuntu/b/zookeeper-1 clientPort=2981
Start ZooKeeper.
$CONFLUENT_HOME/bin/zookeeper-server-start zk.properties
Create credentials for the Kafka cluster and for the cluster link, and a file with authentication information that will be used to issue admin commands against the cluster.
Create credentials for the Kafka cluster:
$CONFLUENT_HOME/bin/kafka-configs --zookeeper localhost:2981 --alter --add-config \ 'SCRAM-SHA-512=[iterations=8992,password=kafka-secret]' \ --entity-type users --entity-name kafka
Create credentials for the cluster link:
$CONFLUENT_HOME/bin/kafka-configs --zookeeper localhost:2981 --alter --add-config \ 'SCRAM-SHA-512=[iterations=8992,password=link-secret]' \ --entity-type users --entity-name link
Create a
CP-command.configfile with the following content:sasl.mechanism=SCRAM-SHA-512 security.protocol=SASL_PLAINTEXT sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required \ username="kafka" \ password="kafka-secret";
In a dedicated terminal window, start a broker node for cluster B and leave it running.
Create a properties file called
b1.propertieswith the following content:listeners=SASL_PLAINTEXT://:9092 advertised.listeners=SASL_PLAINTEXT://:9092 # change the value for log.dirs to any directory as appropriate log.dirs=/home/ubuntu/a/logs-1 zookeeper.connect=localhost:2981 confluent.http.server.listeners=http://localhost:8990 offsets.topic.replication.factor=1 confluent.license.topic.replication.factor=1 confluent.reporters.telemetry.auto.enable=false confluent.cluster.link.enable=true password.encoder.secret=encoder-secret authorizer.class.name=kafka.security.authorizer.AclAuthorizer inter.broker.listener.name=SASL_PLAINTEXT super.users=User:kafka sasl.enabled.mechanisms=SCRAM-SHA-512 sasl.mechanism.inter.broker.protocol=SCRAM-SHA-512 listener.name.sasl_plaintext.scram-sha-512.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="kafka" password="kafka-secret";
Start the Kafka broker:
$CONFLUENT_HOME/bin/kafka-server-start b1.properties
Create the Principal and ACLs to allow the cluster link to read from cluster A
The cluster link needs a principal that is authorized to read data from cluster A. You created the “link” principal in the cluster setup step, above, and now you will assign it the required privileges.
Give the link’s principal the Describe:Cluster ACL.
$CONFLUENT_HOME/bin/kafka-acls --command-config CP-command.config --bootstrap-server localhost:9092 \ --add --allow-principal User:link --operation Describe --cluster
This ACL is specifically required for bidirectional mode.
At a minimum, give the link’s principal Read:Topics and DescribeConfigs:Topics on the topics that the cluster link is allowed to read from.
This example allows the cluster link to read data from all topics. Alternatively, only specific topic names or prefixes can be given. These can be different from the topic ACLs given on the remote cluster.
(Recommended) Assign additional ACLs for syncing consumer offsets, which is a critical feature of a bidirectional cluster link. To learn about consumer offset sync configuration options, see
consumer.offset.sync.enableandconsumer.offset.sync.msin Configuration Options.Grant the link’s principal Describe permissions on all topics.
$CONFLUENT_HOME/bin/kafka-acls --command-config CP-command.config --bootstrap-server localhost:9092 --add --allow-principal User:link --operation Describe --topic "*"
Grant the link’s principal Describe permissions on all consumer groups.
$CONFLUENT_HOME/bin/kafka-acls --command-config CP-command.config --bootstrap-server localhost:9092 --add --allow-principal User:link --operation Describe --operation Read --group "*"
Grant the link’s principal DescribeConfigs permissions on the cluster.
$CONFLUENT_HOME/bin/kafka-acls --command-config CP-command.config --bootstrap-server localhost:9992 --add --allow-principal User:link --operation DescribeConfigs --cluster
(Optional) Assign additional ACLs for syncing (migrating) ACLs or using prefixing plus auto-create mirror topics. These can be different from the ACLs given on the remote cluster.
Create the Principal and ACLs to allow the cluster link to read from cluster B
The cluster link needs a principal that is authorized to read data from cluster B.
Give the link’s principal the Describe:Cluster ACL.
$CONFLUENT_HOME/bin/kafka-acls --command-config CP-command.config --bootstrap-server localhost:9992 \ --add --allow-principal User:link --operation Describe --cluster
This ACL is specifically required for bidirectional mode.
Give the link’s principal Read:Topics and DescribeConfigs:Topics on the topics that the cluster link is allowed to read from.
$CONFLUENT_HOME/bin/kafka-acls --command-config CP-command.config --bootstrap-server localhost:9992 \ --add --allow-principal User:link --operation DescribeConfigs --operation Read --topic "*"
This example allows the cluster link to read data from all topics. Alternatively, only specific topic names or prefixes can be given. These can be different from the topic ACLs given on the remote cluster.
(Optional) Assign additional ACLs for syncing consumer offsets, syncing ACLs, or using prefixing and auto-create mirror topics. These can be different from the ACLs given on the remote cluster.
Create the cluster link objects
A cluster link object must be created on both clusters. When using the default security mode where both clusters can reach each other, either object may be created first. In this example, you will create the cluster link object on cluster B first; this is simply to demonstrate that order does not matter in this scenario.
Both cluster link objects must use the same name and the same link mode setting for this special configuration: link.mode=BIDIRECTIONAL
Apart from that, the standard cluster link configurations are valid and the standard Cluster Linking commands work the same.
Create the cluster link on cluster B
Create a config file called
b-link.configthat points to cluster A’s bootstrap servers, and specifieslink.mode=BIDIRECTIONALalong with authentication details.bootstrap.servers=localhost:9092 link.mode=BIDIRECTIONAL # authentication for the link principal - update these sasl.mechanism=SCRAM-SHA-512 security.protocol=SASL_PLAINTEXT sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required \ username="link" \ password="link-secret";
Note that more cluster link configurations can be added to this file if desired. These will be applied to data and metadata coming to cluster B only, and will not affect cluster A.
Run the following CLI command to create a link named “bidirectional-link”. (You can set the link name to something different per your preference, but these link names must be identical on both clusters.)
$CONFLUENT_HOME/bin/kafka-cluster-links --create --link bidirectional-link \ --config-file b-link.config --bootstrap-server localhost:9992 \ --command-config CP-command.config
Create the cluster link on cluster A
Create a config file called
a-link.configthat points to cluster B’s bootstrap servers, and specifieslink.mode=BIDIRECTIONALalong with authentication details.bootstrap.servers=localhost:9992 link.mode=BIDIRECTIONAL # authentication for the link principal - update these sasl.mechanism=SCRAM-SHA-512 security.protocol=SASL_PLAINTEXT sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required \ username="link" \ password="link-secret";
Note that more cluster link configurations can be added to this file if desired. These will be applied to data and metadata coming to cluster A only, and will not affect cluster B.
Run the following CLI command to create a link named “bidirectional-link”. (You can set the link name to something different per your preference, but these link names must be identical on both clusters.)
$CONFLUENT_HOME/bin/kafka-cluster-links --create --link bidirectional-link \ --config-file a-link.config --bootstrap-server localhost:9092 \ --command-config CP-command.config
Create topics and mirror topics
Create a topic on Cluster A:
$CONFLUENT_HOME/bin/kafka-topics --topic from-a --create --partitions 6 --replication-factor 1 \ --command-config CP-command.config --bootstrap-server localhost:9092
Create a corresponding mirror topic on Cluster B:
$CONFLUENT_HOME/bin/kafka-mirrors --create --mirror-topic from-a --link bidirectional-link \ --replication-factor 1 --command-config CP-command.config --bootstrap-server localhost:9992
Create a topic on Cluster B:
$CONFLUENT_HOME/bin/kafka-topics --topic b-was-here --create --partitions 6 --replication-factor 1 \ --command-config CP-command.config --bootstrap-server localhost:9992
Create a corresponding mirror topic on Cluster A:
$CONFLUENT_HOME/bin/kafka-mirrors --create --mirror-topic b-was-here --link bidirectional-link \ --replication-factor 1 --command-config CP-command.config --bootstrap-server localhost:9092
Advanced options for bidirectional Cluster Linking
In advanced situations, security requirements may require that only one cluster can reach the other and/or that security credentials be stored on only one cluster. For example, if one of the clusters has private networking or is located in a datacenter, and the other cluster is configured with Internet networking.
An advanced option for bidirectional Cluster Linking is a “unidirectional” security configuration for private-to-public or Confluent Platform to Confluent Cloud with a source-initiated link. In this case, a bidirectional cluster link can be configured such that only the more privileged (private) cluster connects to the remote cluster, and not the other way around. This is similar to a source-initiated cluster link.
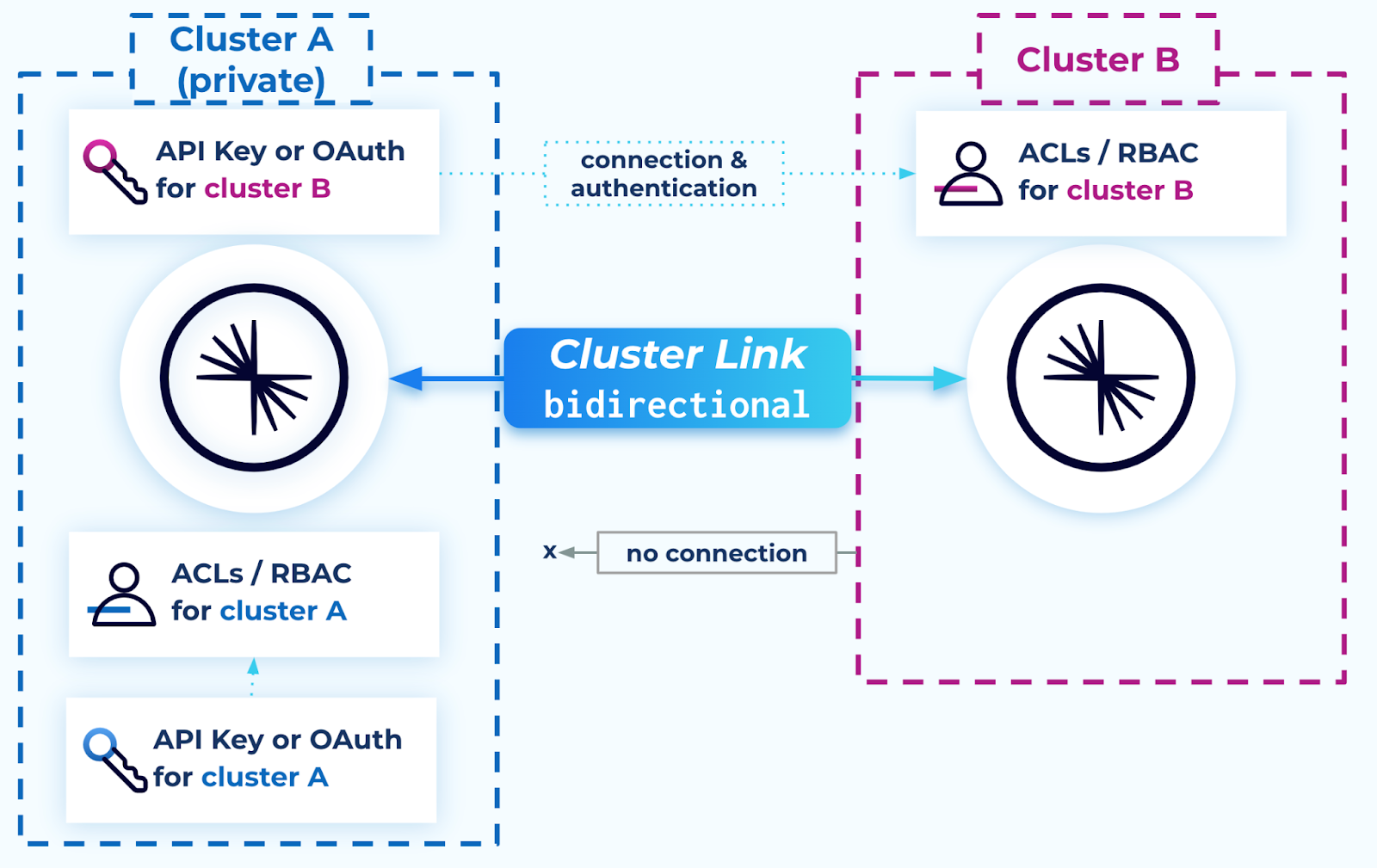
Step 1. Configure the link on the public cluster
The less privileged cluster (cluster B in the diagram above) requires:
A user to create a cluster link on it first (before its remote cluster), with
connection.mode=INBOUNDandlink.mode=BIDIRECTIONAL.
For example, create a b-link.config file for cluster B as shown:
link.mode=BIDIRECTIONAL
connection.mode=INBOUND
Then, run the command to create an INBOUND only link on cluster B, including a call to your b-link.config:
$CONFLUENT_HOME/bin/kafka-cluster-links --create --link bidirectional-link \
--config-file b-link.config --bootstrap-server localhost:9992 \
--command-config CP-command.config
Step 2. Configure the link on the private cluster
The more privileged / private cluster (cluster A in the diagram) requires:
Connectivity to its remote cluster (one-way connectivity is acceptable; such as AWS PrivateLink)
A user to create a cluster link object on it second (after the remote cluster) with the following configuration:
# bootstrap of the remote cluster bootstrap.servers=localhost:9992 link.mode=BIDIRECTIONAL # authentication for the link principal on the remote cluster sasl.mechanism=SCRAM-SHA-512 security.protocol=SASL_PLAINTEXT sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required \ username="link" \ password="link-secret"; # authentication for the link principal on the local cluster local.sasl.mechanism=SCRAM-SHA-512 local.security.protocol=SASL_PLAINTEXT local.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required \ username="link" \ password="link-secret";
Additional configurations can be included in this file as needed, per cluster link configurations.
An authentication configuration (such as API key or OAuth) for a principal on its remote cluster with ACLs or RBAC role bindings giving permission to read topic data and metadata.
Alter:Cluster ACL – this is unique to the advanced mode
Describe:Cluster ACL
The required ACLs or RBAC role bindings for a cluster link, as described in Manage Security for Cluster Linking on Confluent Platform (for a cluster link on a source cluster and for a source-initiated link on the destination cluster).
Local authentication (unique to the unidirectional mode): An authentication configuration (such as API key or OAuth) for a principal on its own cluster with ACLs or RBAC role bindings giving permission to read topic data and the Describe:Cluster ACL
The required ACLs or RBAC role bindings as described giving permission to read topic data and the Describe:Cluster ACL, as described in Manage Security for Cluster Linking on Confluent Platform. This authentication configuration never leaves this cluster. The lines for these configurations must be prefixed with
local.to indicate that they belong to the local cluster.Link mode set to
link.mode=BIDIRECTIONAL
For example, run the following command to create a bidirectional INBOUND/OUTBOUND link on the private cluster (cluster A in the diagram), including the call to your cluster A config file:
$CONFLUENT_HOME/bin/kafka-cluster-links --create --link bidirectional-link \
--config-file a-link.config \
--bootstrap-server localhost:9092 --command-config CP-command.config
Required Configurations for Control Center (Legacy)
Cluster Linking requires embedded v3 Confluent REST Proxy to communicate with Confluent Control Center (Legacy) and properly display mirror topics on the Control Center (Legacy) UI. If the REST configurations are not implemented, mirror topics will display in Control Center (Legacy) as regular topics, showing inaccurate information. (To learn more, see Known limitations and best practices.)
Configure REST Endpoints in the Control Center (Legacy) properties file
If you want to use Control Center (Legacy) with Cluster Linking, you must configure the Control Center (Legacy) cluster with REST endpoints to enable HTTP servers on the brokers. If this is not configured properly for all brokers, Cluster Linking will not be accessible from Confluent Control Center (Legacy).
In the appropriate Control Center (Legacy) properties file (for example $CONFLUENT_HOME/etc/confluent-control-center/control-center-dev.properties or control-center.properties), use confluent.controlcenter.streams.cprest.url to define the REST endpoints for controlcenter.cluster. The default is http://localhost:8090, as shown below.
# Kafka REST endpoint URL
confluent.controlcenter.streams.cprest.url="http://localhost:8090"
Identify the associated URL for each broker. If you have multiple brokers in the cluster, use a comma-separated list.
See also
confluent.controlcenter.streams.cprest.url in the Control Center Configuration Reference
Configure authentication for REST endpoints on Kafka brokers (Secure Setup)
Tip
Cluster Linking does not require the Metadata Service (MDS) or security to run, but if you want to configure security, you can get started with the following example which shows an MDS client configuration for RBAC.
You can use
confluent.metadata.server.listeners(which will enable the Metadata Service) instead ofconfluent.http.server.listenersto listen for API requests. Use eitherconfluent.metadata.server.listenersorconfluent.http.server.listeners, but not both. If a listener uses HTTPS, then appropriate TLS/SSL configuration parameters must also be set. To learn more, see Admin REST APIs Configuration Options for Confluent Server.
To run Cluster Linking in a secure setup, you must configure authentication for REST endpoints in each of the Kafka broker server.properties files. If the Kafka broker files are missing these configs, Control Center (Legacy) will not be able to access Cluster Linking in a secure setup.
At a minimum, you will need the following configurations.
# EmbeddedKafkaRest: HTTP Auth Configuration
kafka.rest.kafka.rest.resource.extension.class=io.confluent.kafkarest.security.KafkaRestSecurityResourceExtension
kafka.rest.rest.servlet.initializor.classes=io.confluent.common.security.jetty.initializer.InstallBearerOrBasicSecurityHandler
Here is an example of an MDS client configuration for Kafka RBAC in a broker server.properties file .
# EmbeddedKafkaRest: Kafka Client Configuration
kafka.rest.bootstrap.servers=<host:port>, <host:port>, <host:port>
kafka.rest.client.security.protocol=SASL_PLAINTEXT
# EmbeddedKafkaRest: HTTP Auth Configuration
kafka.rest.kafka.rest.resource.extension.class=io.confluent.kafkarest.security.KafkaRestSecurityResourceExtension
kafka.rest.rest.servlet.initializor.classes=io.confluent.common.security.jetty.initializer.InstallBearerOrBasicSecurityHandler
kafka.rest.public.key.path=<rbac_enabled_public_pem_path>
# EmbeddedKafkaRest: MDS Client configuration
kafka.rest.confluent.metadata.bootstrap.server.urls=<host:port>, <host:port>, <host:port>
kafka.rest.ssl.truststore.location=<truststore_location>
kafka.rest.ssl.truststore.password=<password>
kafka.rest.confluent.metadata.http.auth.credentials.provider=BASIC
kafka.rest.confluent.metadata.basic.auth.user.info=<user:password>
kafka.rest.confluent.metadata.server.urls.max.age.ms=60000
kafka.rest.client.confluent.metadata.server.urls.max.age.ms=60000
See also
Configure Security for the Admin REST APIs for Confluent Server
Scripted Confluent Platform Demo, On-Prem Tutorial, Security section provides examples of different types of configurations
Disabling Cluster Linking
To disable Cluster Linking on a cluster running Confluent Enterprise version 7.0.0 or later, add the following line to the broker configuration on the destination cluster (for example $CONFLUENT_HOME/etc/server.properties).
confluent.cluster.link.enable=false
This will disable creating cluster links with that cluster as the destination, or “source initiated cluster links” with that cluster as the source. Note: this will not disable creating a destination-initiated cluster link with this cluster as its source.
Cluster Linking is not available as a dynamic configuration. It must either be enabled before starting the brokers, or to enable it on a running cluster where it was previously turned off, set the configuration confluent.cluster.link.enable=true on the brokers and restart them to perform a rolling update.
Understanding Listeners in Cluster Linking
For a forward connection, the target server knows which listener the connection came in on and associates the listener with that connection. When a metadata request arrives on that connection, the server returns metadata corresponding to the listener.
For example, in Confluent Cloud, when a client on the external listener asks for the leader of topicA, it always gets the external endpoint of the leader and never the internal one, because the system knows the listener name from the connection.
For reverse connections, the target server (that is, the source cluster) established the connection. When the connection is reversed, this target server needs to know which listener to associate the reverse connection with; that is, for example, which endpoint it should return to the destination for its leader requests.
By default, the listener is associated based on the source cluster where the link was created. In most cases this is sufficient because typically a single external listener is used. On Confluent Cloud, this default is used and you cannot override it.
On self-managed Confluent Platform, you have the option to override the default listener/connection association. This provides the flexibility to create the source link on an internal listener but associate the external listener with the reverse connection.
The configuration local.listener.name refers to source cluster listener name. By default, this is the listener that was used to create the source link. If you want to use a different listener, you must explicitly configure it. If Confluent Cloud is the source, then it would be the external listener (default) and cannot be overridden.
For the destination, the listener is determined by bootstrap.servers and cannot be overridden.