
Pipelining with Kafka Connect and Kafka Streams in Confluent Platform
Overview
This example shows users how to build pipelines with Apache Kafka® in Confluent Platform.
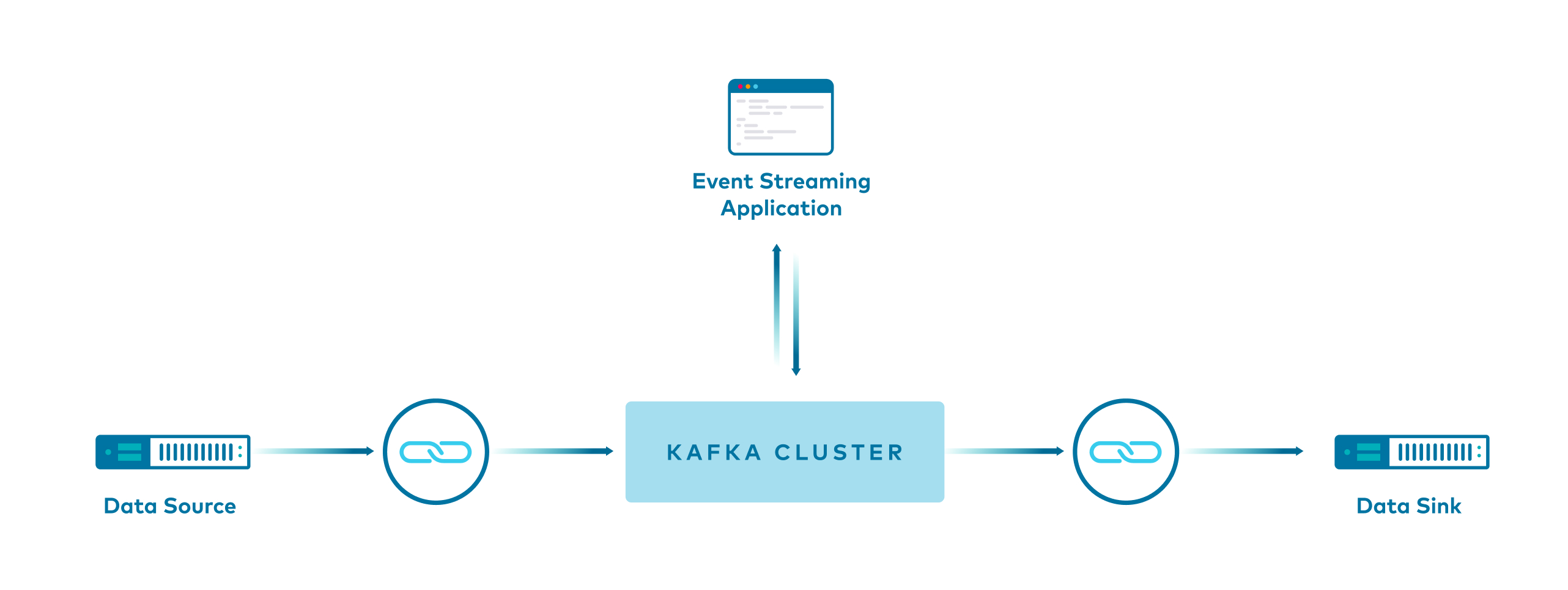
It showcases different ways to produce data to Kafka topics, with and without Kafka Connect, and various ways to serialize it for the Kafka Streams API and ksqlDB.
Example | Produce to Kafka Topic | Key | Value | Stream Processing |
|---|---|---|---|---|
Confluent CLI Producer with String | CLI | String | String | Kafka Streams |
JDBC source connector with JSON | JDBC with SMT to add key | Long | Json | Kafka Streams |
JDBC source connector with SpecificAvro | JDBC with SMT to set namespace | null | SpecificAvro | Kafka Streams |
JDBC source connector with GenericAvro | JDBC | null | GenericAvro | Kafka Streams |
Java producer with SpecificAvro | Producer | Long | SpecificAvro | Kafka Streams |
JDBC source connector with Avro | JDBC | Long | Avro | ksqlDB |
Detailed walk-thru of this example is available in the whitepaper Kafka Serialization and Deserialization (SerDes) Examples and the blog post Building a Real-Time Streaming ETL Pipeline in 20 Minutes
Confluent Cloud
You can apply the same concepts explained in this example to Confluent Cloud. Confluent Cloud also has fully managed connectors that you can use, instead of self-managing your own, so that you can run 100% in the cloud. To try it out, create your own Confluent Cloud instance (see the ccloud-stack utility for Confluent Cloud for an easy way to spin up a new environment), deploy a connector, and then point your applications to Confluent Cloud.
Description of Data
The original data is a table of locations that resembles this.
id|name|sale
1|Raleigh|300
2|Dusseldorf|100
1|Raleigh|600
3|Moscow|800
4|Sydney|200
2|Dusseldorf|400
5|Chennai|400
3|Moscow|100
3|Moscow|200
1|Raleigh|700
It produces records to a Kafka topic:

The actual client application uses the methods count and sum to process this data, grouped by each city.
The output of count is:
1|Raleigh|3
2|Dusseldorf|2
3|Moscow|3
4|Sydney|1
5|Chennai|1

The output of sum is:
1|Raleigh|1600
2|Dusseldorf|500
3|Moscow|1100
4|Sydney|200
5|Chennai|400

Prerequisites
This tutorial runs Confluent Platform in Docker. Before proceeding: - Install Docker Desktop or Docker Engine (version 19.03.0 or later) if you don’t already have it - Install the Docker Compose plugin if you don’t already have it. This isn’t necessary if you have Docker Desktop since it includes Docker Compose. - Start Docker if it’s not already running, either by starting Docker Desktop or, if you manage Docker Engine with
systemd, via systemctl - Verify that Docker is set up properly by ensuring no errors are output when you rundocker infoanddocker compose versionon the command lineMaven command
mvnto compile Java codetimeout: used by the bash scripts to terminate a consumer process after a certain period of time.timeoutis available on most Linux distributions but not on macOS. macOS users can installtimeoutviabrew install coreutils.
Run example
Clone the examples GitHub repository and check out the
7.7.10-postbranch.git clone https://github.com/confluentinc/examples cd examples git checkout 7.7.10-post
Change directory to the connect-streams-pipeline example.
cd connect-streams-pipeline
Run the examples end-to-end:
./start.sh
Open your browser and navigate to the Confluent Control Center (Legacy) web interface Management -> Connect tab to see the data in the Kafka topics and the deployed connectors.
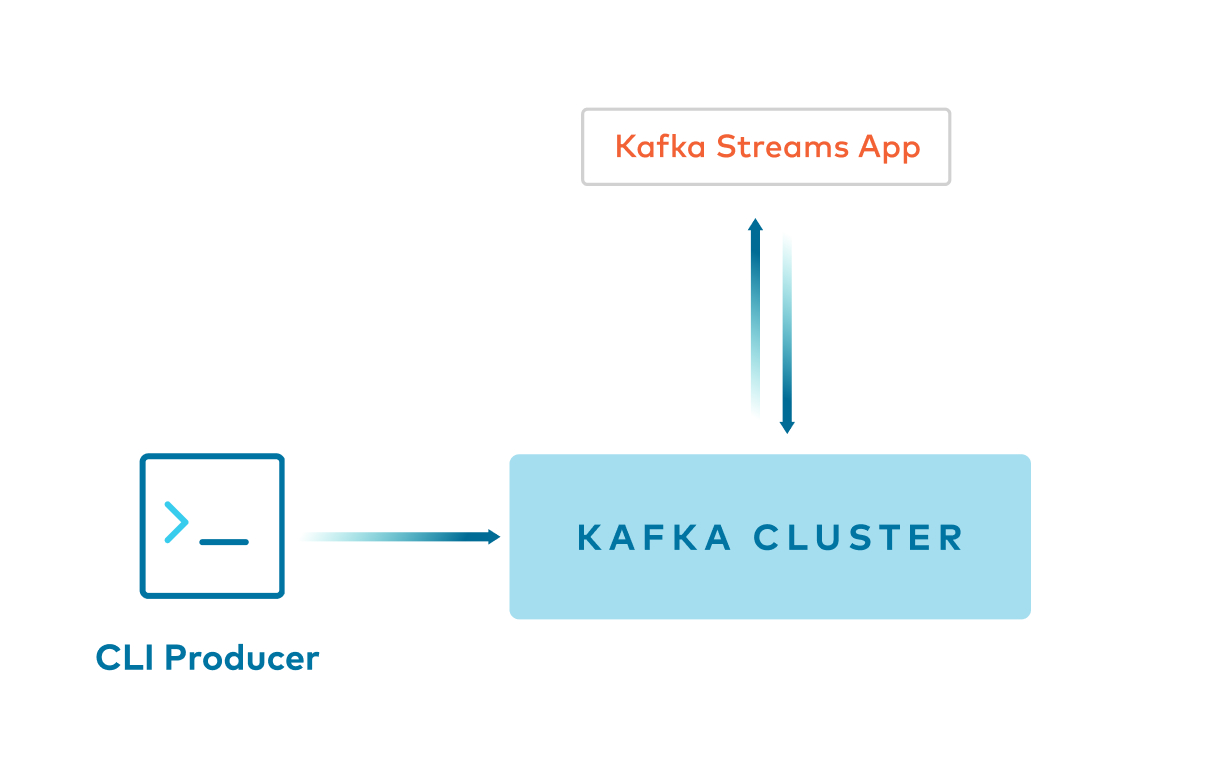
Example 1: Kafka console producer -> Key:String and Value:String
Command line
kafka-console-producerproducesStringkeys andStringvalues to a Kafka topic.Client application reads from the Kafka topic using
Serdes.String()for both key and value.
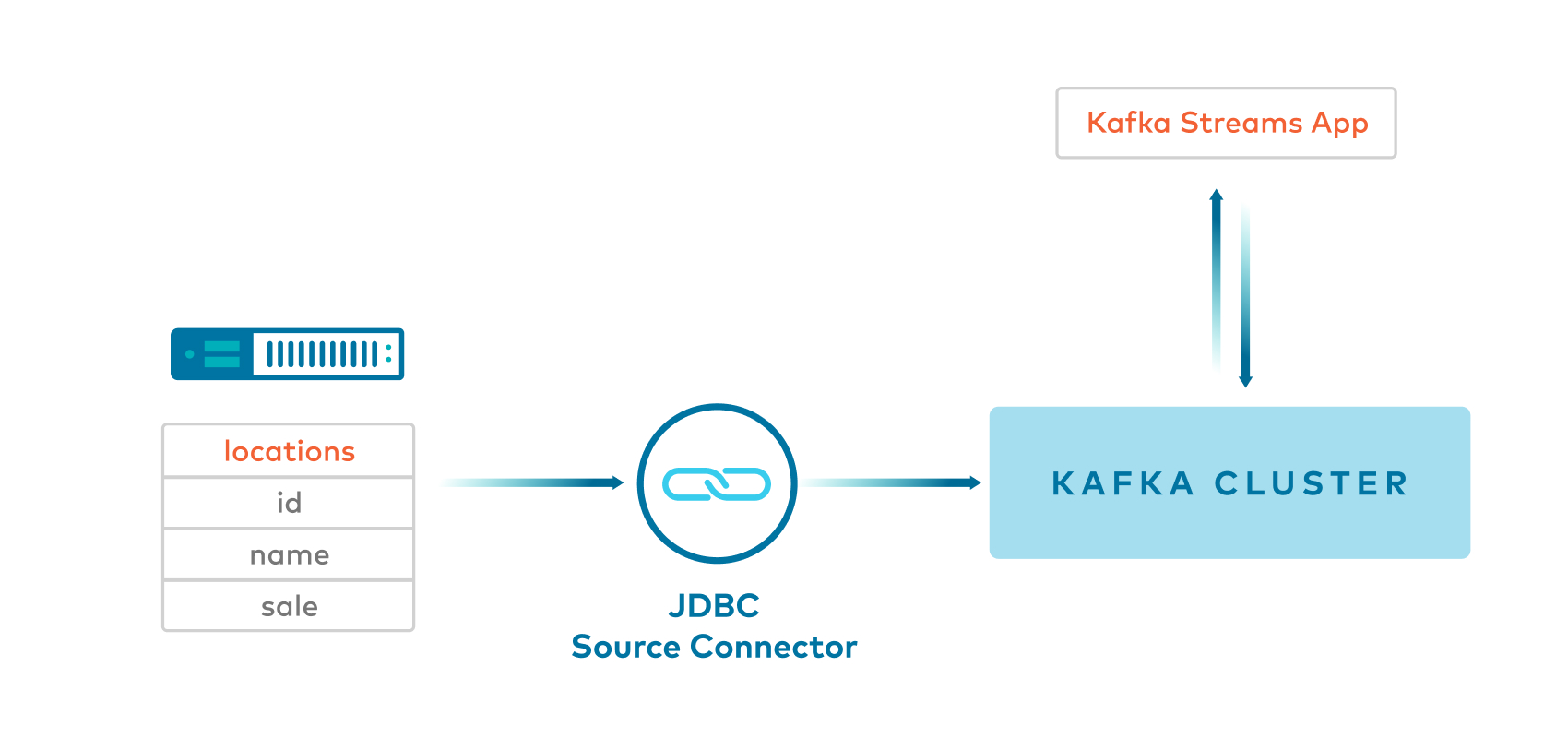
Example 2: JDBC source connector with Single Message Transformations -> Key:Long and Value:JSON
Kafka Connect JDBC source connector produces JSON values, and inserts the key using single message transformations, also known as
SMTs. This is helpful because by default JDBC source connector does not insert a key.This example uses a few SMTs including one to cast the key to an
int64. The key uses theorg.apache.kafka.connect.converters.LongConverterprovided by KAFKA-6913.
{
"name": "test-source-sqlite-jdbc-autoincrement-jdbcjson",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"tasks.max": "1",
"key.converter": "org.apache.kafka.connect.converters.LongConverter",
"key.converter.schemas.enable": "false",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"transforms": "InsertKey, ExtractId, CastLong",
"transforms.InsertKey.type": "org.apache.kafka.connect.transforms.ValueToKey",
"transforms.InsertKey.fields": "id",
"transforms.ExtractId.type": "org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.ExtractId.field": "id",
"transforms.CastLong.type": "org.apache.kafka.connect.transforms.Cast$Key",
"transforms.CastLong.spec": "int64",
"connection.url": "jdbc:sqlite:/usr/local/lib/retail.db",
"mode": "incrementing",
"incrementing.column.name": "id",
"topic.prefix": "jdbcjson-",
"table.whitelist": "locations"
}
}
Client application reads from the Kafka topic using
Serdes.Long()for key and a custom JSON Serde for the value.
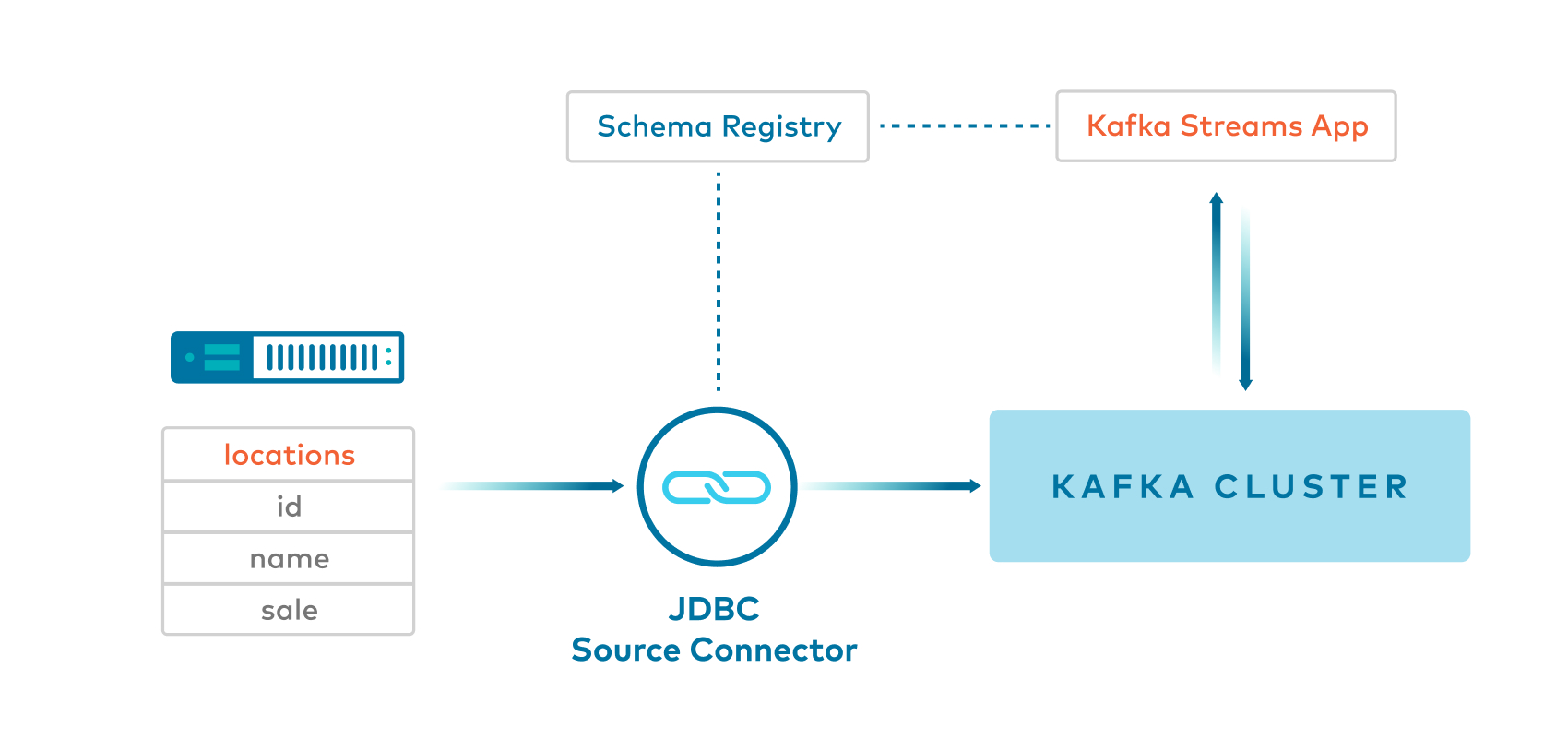
Example 3: JDBC source connector with SpecificAvro -> Key:String(null) and Value:SpecificAvro
Kafka Connect JDBC source connector produces Avro values, and null
Stringkeys, to a Kafka topic.This example uses a single message transformation (SMT) called
SetSchemaMetadatawith code that has a fix for KAFKA-5164, allowing the connector to set the namespace in the schema. If you do not have the fix for KAFKA-5164, see Example 4 that usesGenericAvroinstead ofSpecificAvro.
{
"name": "test-source-sqlite-jdbc-autoincrement-jdbcspecificavro",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"tasks.max": "1",
"key.converter": "org.apache.kafka.connect.converters.LongConverter",
"key.converter.schemas.enable": "false",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter.schemas.enable": "true",
"transforms": "SetValueSchema",
"transforms.SetValueSchema.type": "org.apache.kafka.connect.transforms.SetSchemaMetadata$Value",
"transforms.SetValueSchema.schema.name": "io.confluent.examples.connectandstreams.avro.Location",
"connection.url": "jdbc:sqlite:/usr/local/lib/retail.db",
"mode": "incrementing",
"incrementing.column.name": "id",
"topic.prefix": "jdbcspecificavro-",
"table.whitelist": "locations"
}
}
Client application reads from the Kafka topic using
SpecificAvroSerdefor the value and then themapfunction to convert the stream of messages to haveLongkeys and custom class values.
Example 4: JDBC source connector with GenericAvro -> Key:String(null) and Value:GenericAvro
Kafka Connect JDBC source connector produces Avro values, and null
Stringkeys, to a Kafka topic.
{
"name": "test-source-sqlite-jdbc-autoincrement-jdbcgenericavro",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"tasks.max": "1",
"key.converter": "org.apache.kafka.connect.converters.LongConverter",
"key.converter.schemas.enable": "false",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter.schemas.enable": "true",
"connection.url": "jdbc:sqlite:/usr/local/lib/retail.db",
"mode": "incrementing",
"incrementing.column.name": "id",
"topic.prefix": "jdbcgenericavro-",
"table.whitelist": "locations"
}
}
Client application reads from the Kafka topic using
GenericAvroSerdefor the value and then themapfunction to convert the stream of messages to haveLongkeys and custom class values.This example currently uses
GenericAvroSerdeand notSpecificAvroSerdefor a specific reason. JDBC source connector currently doesn’t set a namespace when it generates a schema name for the data it is producing to Kafka. ForSpecificAvroSerde, the lack of namespace is a problem when trying to match reader and writer schema because Avro uses the writer schema name and namespace to create a classname and tries to load this class, but without a namespace, the class will not be found.
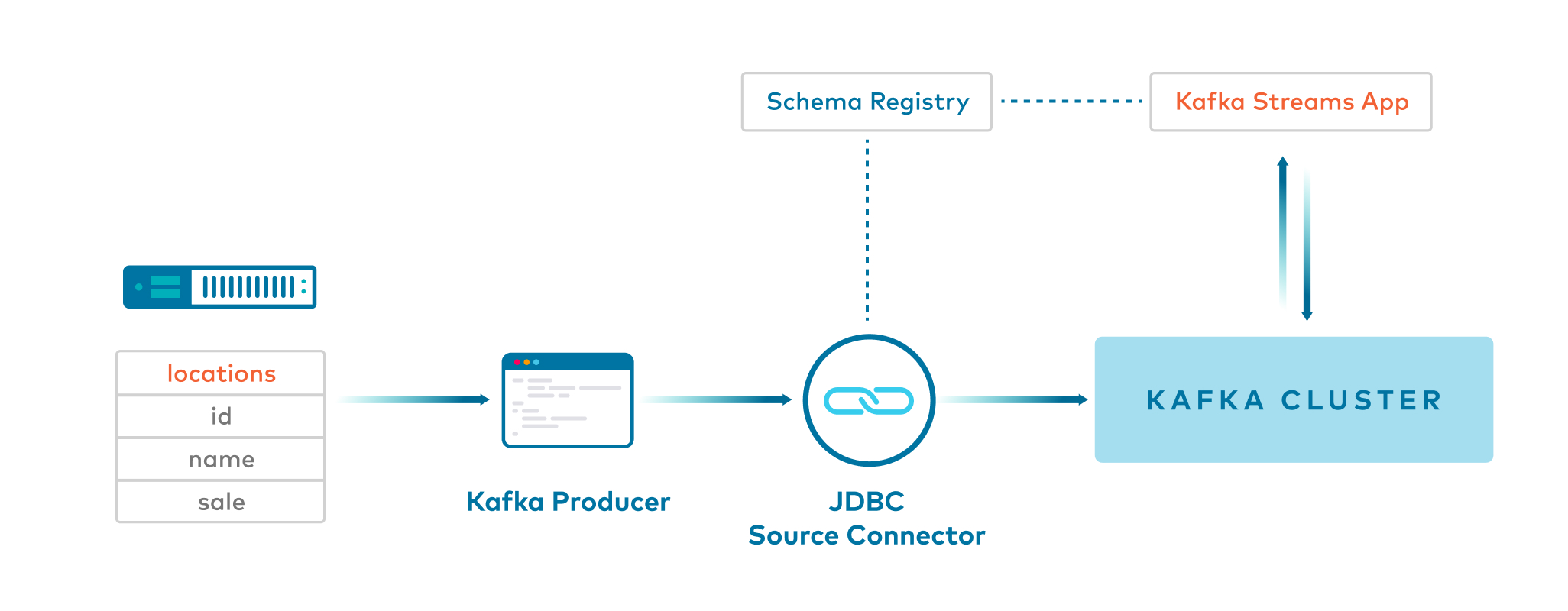
Example 5: Java client producer with SpecificAvro -> Key:Long and Value:SpecificAvro
Java client produces
Longkeys andSpecificAvrovalues to a Kafka topic.Client application reads from the Kafka topic using
Serdes.Long()for key andSpecificAvroSerdefor the value.
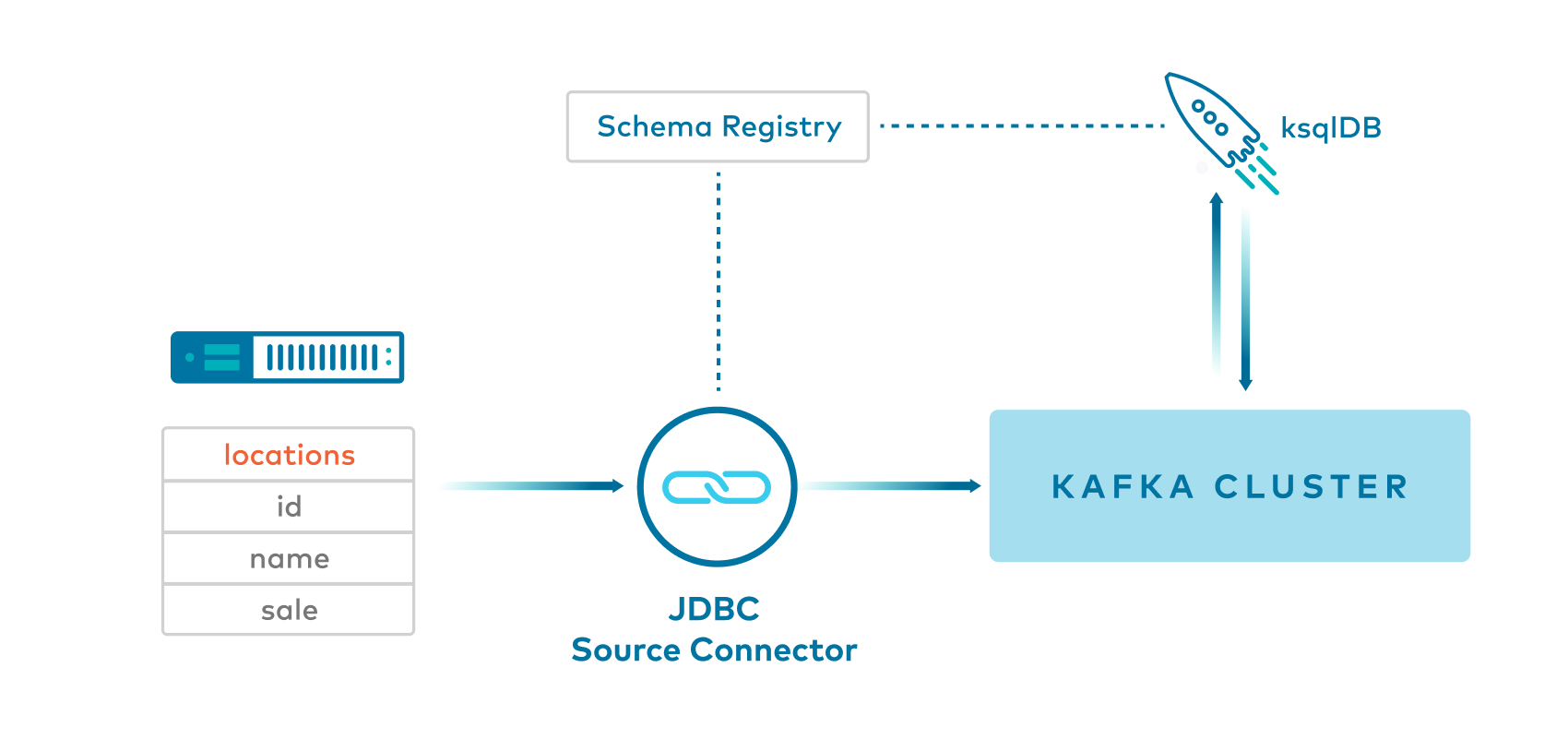
Example 6: JDBC source connector with Avro to ksqlDB -> Key:Long and Value:Avro
Kafka Connect JDBC source connector produces Avro values, and null keys, to a Kafka topic.
{
"name": "test-source-sqlite-jdbc-autoincrement-jdbcavroksql",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"tasks.max": "1",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter.schemas.enable": "true",
"connection.url": "jdbc:sqlite:/usr/local/lib/retail.db",
"mode": "incrementing",
"incrementing.column.name": "id",
"topic.prefix": "jdbcavroksql-",
"table.whitelist": "locations"
}
}
ksqlDB reads from the Kafka topic and then uses
PARTITION BYto create a new stream of messages withBIGINTkeys.
Technical Notes
KAFKA-5245: one needs to provide the Serdes twice, (1) when calling
StreamsBuilder#stream()and (2) when callingKStream#groupByKey()PR-531: Confluent distribution provides packages for
GenericAvroSerdeandSpecificAvroSerdeKAFKA-2378: adds APIs to be able to embed Kafka Connect into client applications
KAFKA-2526: one cannot use the
--key-serializerargument inkafka-console-producerto serialize the key as aLong. As a result, in this example the key is serialized as aString. As a workaround, you could write your own kafka.common.MessageReader (e.g. check out the default implementation of LineMessageReader) and then you can specify--line-readerargument inkafka-console-producer.KAFKA-5164: allows the connector to set the namespace in the schema.