
Manage Self-Balancing Kafka Clusters in Confluent Platform
Self-Balancing Clusters is a Confluent feature that is designed to simplify the process of managing an Apache Kafka® cluster. With this feature enabled, a cluster automatically rebalances partitions across brokers when new brokers are added or existing brokers are removed. This ensures that data is evenly distributed across the cluster, which can improve performance and reduce the risk of data loss in the event of a broker failure.
The Self-Balancing Clusters feature is the preferred alternative to the Auto Data Balancer. For a detailed feature comparison, see Self-Balancing vs. Auto Data Balancer.
When Self-Balancing Clusters is enabled, the cordoned.log.dirs broker configuration is ignored. For more information, see Limitations and known issues.
Self-Balancing offers:
Fully automated load balancing.
Dynamic enablement, meaning you can turn it off or on while the cluster is running and set to rebalance when brokers are added or removed, or for any uneven load.
Automatic triggering of rebalance operations based on configurations you set on Control Center for Confluent Platform or in Kafka
server.propertiesfiles. You can choose to auto-balance only when brokers are added or removed, or anytime there is uneven load.Auto-monitoring of clusters for imbalances based on a large set of parameters, configurations, and runtime variables.
Continuous metrics aggregation and rebalancing plans, generated instantaneously in most cases, and executed automatically.
At-a-glance visibility into the state of your clusters, and the strategy and progress of auto-balancing through a few key metrics.
How Self-Balancing simplifies Kafka operations
Self-Balancing simplifies operational management of Kafka clusters in these ways:
When the load on the cluster is unevenly distributed, Self-Balancing automatically rebalances partitions to optimize performance.
When a new broker is added to the cluster, Self-Balancing automatically fills it with partitions.
When you want to remove a broker, use kafka-remove-brokers to shut down the broker and drain the partitions from it.
When a broker has been down for a certain amount of time, Self-Balancing automatically reassigns the partitions to other brokers.
Self-Balancing vs. Auto Data Balancer
Self-Balancing offers the following advantages over Auto Data Balancer:
Cluster balance is continuously monitored so that rebalances run whenever they are needed.
Broker failure conditions are detected and addressed automatically.
No additional tools to run (built into the brokers).
Works with Confluent Control Center and offers a REST API.
Much faster rebalancing (several orders of magnitude).
Note that Self-Balancing and Auto Data Balancer cannot be used together. If you want to run the Auto Data Balancer, you must first make sure that Self-Balancing is off.
How it works
Self-Balancing Clusters optimizes Kafka load awareness. Resource usage within a cluster can be heterogeneous. Kafka out-of-the-box does not provide an automated process to improve cluster balance, but rather requires manual calculation of how to reassign partitions.
Self-Balancing simplifies this process by moving data to spread the cluster load evenly. Self-Balancing defines the meaning of “even” based on built-in goals, although you can provide optional input through configurations.
Architecture of a Self-Balancing cluster
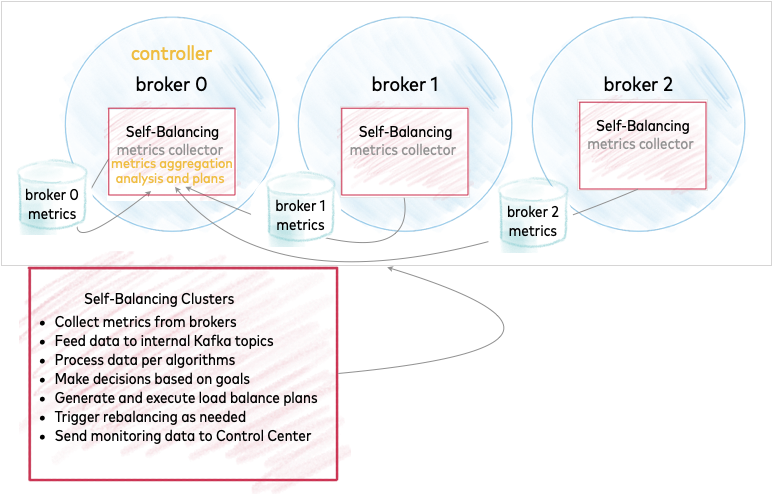
Kafka brokers collect metrics and feed the data to an internal topic on the controller, which is on the lead broker for the cluster. The controller, therefore, plays a key role in cluster balancing. You can think of the controller as the node on which Self-Balancing is actively running.
The metrics are processed and decisions are made, based on goals.
This data is fed to other internal Kafka topics for monitoring and potential actions, such as generating a load balancing plan or triggering a rebalance.
Tip
You can view all topics, including internal topics, by using the kafka-topics --list command while Confluent Platform is running, for example: kafka-topics --list --bootstrap-server localhost:9092. Self-Balancing internal topics are prefixed with _confluent_balancer_.
Enable Self-Balancing Clusters
For each broker in your cluster, set
confluent.balancer.enable=trueto enable self-balancing and make sure that this line is uncommented. To learn more, see confluent.balancer.enable.For KRaft mode, in addition to enabling self balancing on a cluster, you must set
inter.broker.listener.namein the properties file for each controller and broker in the cluster. For more information, see The balancer status for a KRaft controller hangs.To configure and monitor self-balancing from Control Center, configure the Control Center cluster with REST endpoints to enable HTTP servers on the brokers, as described in Required configurations for Control Center.
Configure the brokers with similar disk capacities so that Self-Balancing can effectively balance data across the cluster. The maximum percentage by which broker disk capacities can differ from the average capacity in the cluster is 5%.
Frequently asked questions
What defines a “balanced” cluster and what triggers a rebalance?
A balanced cluster distributes partitions, leadership, and resource usage evenly across brokers, based on Self-Balancing Clusters goals.
At a high level, the Self-Balancing Clusters feature distinguishes between two types of imbalances:
Intentional operational actions, such as adding or removing brokers. In these cases, enabling self-balancing saves the operator time and manual steps that would otherwise be required.
Ongoing cluster operations such as a hot topic or partition. This balancing is ongoing throughout the life of the cluster.
These map to the two high level configuration options you have with self-balancing enabled:
Rebalance only when a broker is added
Rebalance anytime, for any uneven load, including changes in number of available brokers
The first case is clear-cut. If brokers are added, self-healing occurs to redistribute data to the new broker or offload data from the missing broker.
The second case is more nuanced. To achieve ongoing cluster and data balance, Self-Balancing Clusters optimizes on a number of goals and also avoids unnecessary movements if rebalancing would not materially improve cluster performance. Goals include considerations for replica placement and capacity, replication factors and throughput, multiple metrics on topics and partitions, leadership, rack awareness, disk usage and capacity, network throughputs per broker, numerous load distribution targets, and more.
Note
The focus for self-balancing is on cluster performance. When self-balancing is enabled, goals are assessed in priority order and some factors impact cluster performance more than others. For example, disk distribution is not a high priority goal for self-balancing. This is because disk distribution does not directly impact cluster performance in the same way that leadership distribution does.
Self-Balancing Clusters employs continuous monitoring and data collection to track performance against these goals, and generates plans for rebalancing. A rebalance may or may not be triggered based on the implications of all weighted factors for the topology at a given moment. Furthermore, the balancing algorithm is approximate, and influenced by the factors described previously.
Tip
A cluster rebalances when a broker is removed by user request (either from the command line or the Control Center), or if a broker goes missing some period of time as specified by confluent.balancer.heal.broker.failure.threshold.ms.
Therefore, even with Self-balancing set to Rebalance only when a broker is added, the cluster will rebalance for missing brokers unless you intentionally set properties to prevent this. For example, if confluent.balancer.heal.broker.failure.threshold.ms is set to -1.
To learn more about rebalancing interaction with racks and replica placement, see Replica placement and rack configurations.
What happens if the lead broker (controller) is removed or lost?
If the lead broker (controller) is removed or lost, there is no impact to cluster integrity. In a multi-broker cluster, one of the brokers is the leader or controller and plays a key role in self-balancing (as described in Architecture of a Self-Balancing cluster). The following describes what happens when the broker running the controller is intentionally removed or crashes:
When the controller is removed or lost, a new controller is elected.
A broker removal request persists after it is made. If another broker becomes the controller, the new controller restarts and resumes the broker removal process, possibly with some delay.
The new leader picks up the remove broker request and completes it.
If the lead broker is lost during an in-progress “add broker” operation, the “add broker” operation does not complete, and is marked as failed. If the new controller does not pick this up, you may need to restart the broker you were trying to add.
To learn more about these issues, see Troubleshooting.
How do the brokers use Cruise Control?
Confluent Self-Balancing Clusters uses Cruise Control for continuous metrics aggregation and reporting, reassignment algorithms and plans, and some rebalance triggers. Unlike Cruise Control, which has to be managed separately from Kafka, Self-Balancing is built into the brokers, meaning that data balancing is supported out of the box without additional dependencies. The result is custom-made, automated load balancing optimized for your Kafka clusters on Confluent Platform, and designed to work seamlessly with other components like Tiered Storage in Confluent Platform and Configure Multi-Region Clusters in Confluent Platform.
What internal topics does the Self-Balancing Clusters feature create and use?
The Self-Balancing Clusters feature creates internal topics prefixed with _confluent_balancer_. See Self-Balancing internal topics in the Configuration and Commands Reference.
Limitations and known issues
This section lists known issues and limitations of Self-Balancing Clusters.
Note
Self-Balancing balances data across disks in clusters with Just a Bunch of Disks (JBOD) setups. For the setup and features that Self-Balancing provides for JBOD, see Use JBOD with Self-Balancing in Confluent Platform.
Self-Balancing Clusters does not respect log directory cordoning set by the
cordoned.log.dirsbroker configuration. This property was introduced in Confluent Platform 8.3 and should not be used when Self-Balancing is enabled. Any Self-Balancing operation, including automated self-healing, assigns replicas to brokers with cordoned log directories as though those directories were not cordoned. As a result, cordoning does not prevent Self-Balancing from placing new replicas on the affected brokers, which can lead to disk space exhaustion on brokers that you cordoned. For more information, see KIP-1066.If Configure Multi-Region Clusters in Confluent Platform is enabled and a topic is created with a replica placement policy, Self-Balancing will redistribute the preferred leaders among all racks that have replicas.
Attempts to remove a broker immediately after cluster startup (while self-balancing is initializing) can fail due to insufficient metrics, and attempts to remove the lead broker can also fail at another phase. The solution is to retry broker removal after a period of time. If the broker is a controller, you must run broker removal from the command line, as it may not be available on the Control Center. To learn more, see Broker removal attempt fails during Self-Balancing initialization in Troubleshooting.
There is a known issue in Confluent Platform 7.4 with setting the trigger condition for a rebalance in Control Center. For more information, see Using Control Center (7.4 docs).
To troubleshoot Self-Balancing Clusters, see the Troubleshooting section.
Configuration and monitoring
Self-Balancing Clusters are self-managed, and can be enabled while the cluster is running. In most cases, you should not have to modify the defaults. Enable self-balancing either before or after you start the cluster, and allow it to auto-balance as needed.
Get status on the balancer
APIs and commands are provided to gain visibility into status and operations of the Self-Balancing Clusters feature. To learn more, see Monitoring the balancer with kafka-rebalance-cluster.
Use Control Center
You can change self-balancing settings from Confluent Control Center (http://localhost:9021/) while the cluster is running.
Prerequisites:
You must configure the Control Center cluster with REST endpoints to enable HTTP servers on the brokers, as described in Required configurations for Control Center. This is required to make Self-Balancing Clusters accessible from Control Center.
You have not deployed with Confluent for Kubernetes (CFK). When you deploy with Confluent for Kubernetes, you cannot manage Self-Balancing through Control Center. To learn more about using Confluent for Kubernetes to manage Self-Balancing, see Scale Kafka clusters and balance data in the CFK documentation.
You can do the following from Control Center:
Turn self-balancing on or off. In the example
server.propertiesfile for ZooKeeper mode,confluent.balancer.enableis set totrue, which means self-balancing is on. (See confluent.balancer.enable.)Override the default throttle value (10485760 or 10 MB per second), which determines the maximum network bandwidth available for Self-Balancing. (confluent.balancer.throttle.bytes.per.second)
Toggle the trigger condition for rebalance to either Only when brokers are added (the default) or Anytime. (confluent.balancer.heal.uneven.load.trigger)
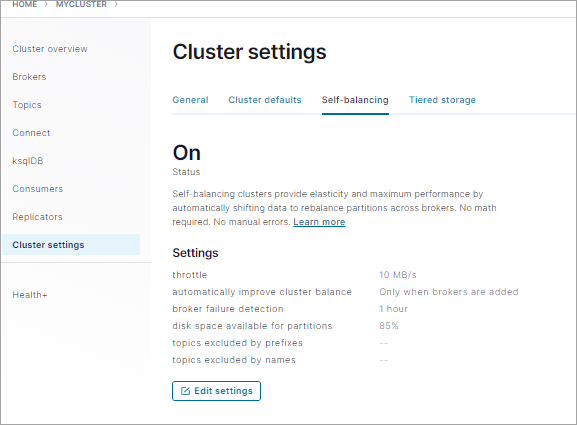
Select a cluster, click Cluster settings and select the Self-balancing tab.
The current settings are shown in the following image.
Click Edit settings.
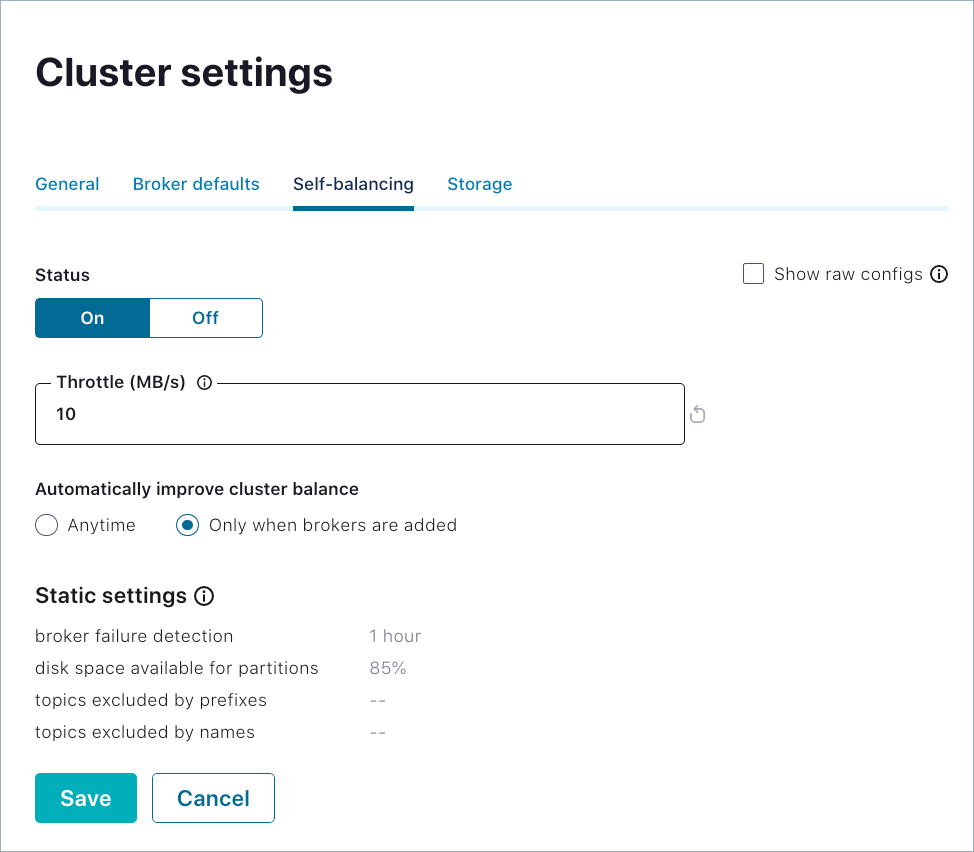
Make changes and click Save.
The updated settings are put into effect and reflected on the Self-balancing tab.
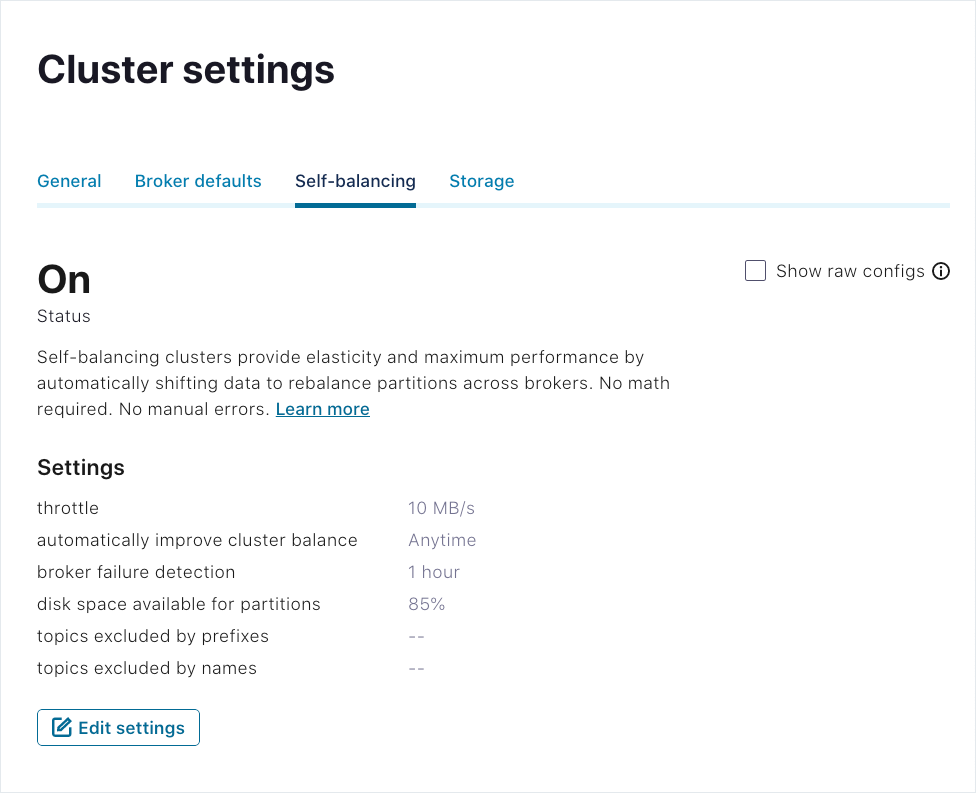
To view the property names for the Self-Balancing settings in effect (while editing or monitoring them), select Show raw configs.
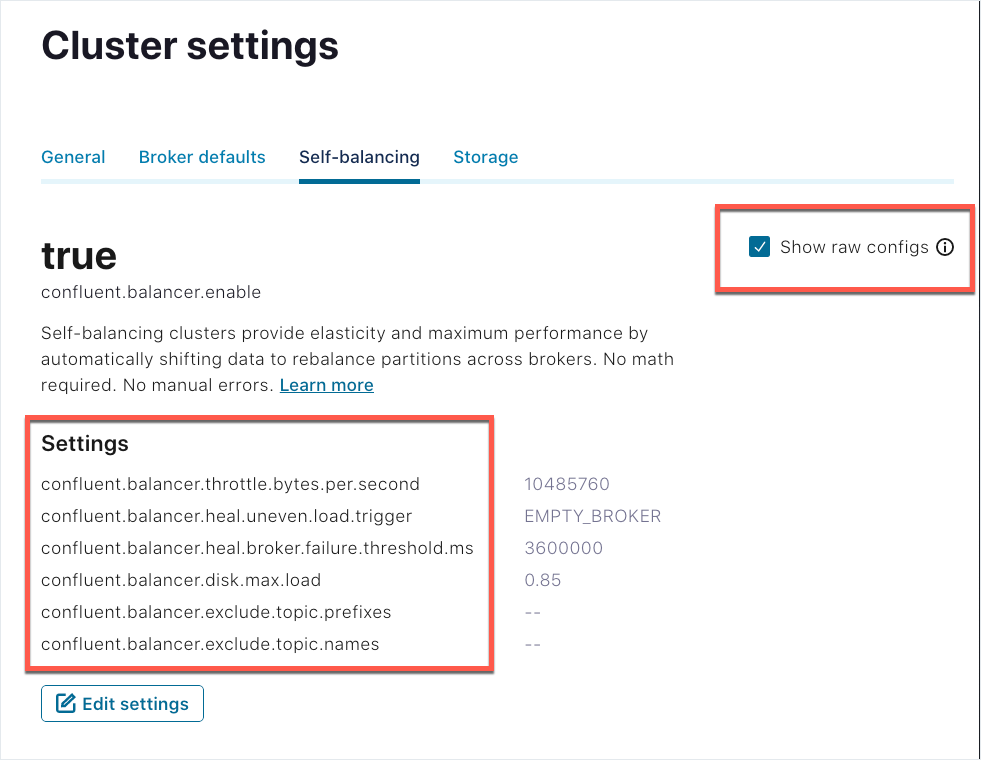
Kafka server properties and commands
In addition to the dynamic properties described earlier, more tuning parameters are exposed in the properties file for the server. These are described in Self-Balancing Cluster Configuration and Command Reference for Confluent Platform, specifically in the subtopic, Self-Balancing configuration. To update the rest of these settings, you must stop the brokers and shut down the cluster.
See Tutorial: Add and Remove Brokers with Self-Balancing in Confluent Platform for an example of how to set up and run a quick test of Self-Balancing by removing a broker and monitoring the rebalance. The example provides guidance on proper configuration of replication factors and demos the Self-Balancing specific command, kafka-remove-brokers.
Metrics for monitoring a rebalance
Confluent Platform exposes several metrics through Java Management Extensions (JMX) that are useful for monitoring rebalances initiated by Self-Balancing:
The incoming and outgoing byte rate for reassignments is tracked by
kafka.server:type=BrokerTopicMetrics,name=ReassignmentBytesInPerSecandkafka.server:type=BrokerTopicMetrics,name=ReassignmentBytesOutPerSec. These metrics are reported by each broker.The number of pending and in-progress reassignment tasks currently tracked by Self-Balancing are tracked by
kafka.databalancer:type=Executor,name=replica-action-pendingandkafka.databalancer:type=Executor,name=replica-action-in-progress. These metrics are reported from the broker with the active data balancer instance (the controller).The maximum follower lag on each broker is tracked by
kafka.server:type=ReplicaFetcherManager,name=MaxLag,clientId=Replica. Reassigning partitions causes this metric to jump to a value corresponding to the size of the partition and then slowly decay as the reassignment progresses. If this value slowly rises rather than slowly falling over time, the replication throttle is too low.
To monitor self-balancing, set the JMX_PORT environment variable before starting the cluster, then collect the reported metrics using your usual monitoring tools. To learn more, see Configure JMX for Monitoring. JMXTrans, Graphite, and Grafana are a popular combination for collecting and reporting JMX metrics from Kafka. Datadog is another popular monitoring solution.
You can view the full list of metrics for Confluent Platform in Monitor Kafka with JMX in Confluent Platform.
Replica placement and rack configurations
The following considerations apply to all rebalances.
Racks
Racks are fault domains for Kafka. All brokers in the same rack are vulnerable to simultaneous failure. Kafka uses knowledge of rack IDs to place topics initially and the Self-Balancing Clusters feature uses them during rebalances.
Self-Balancing attempts to distribute replicas evenly across racks if brokers have assigned rack IDs. Specifically, Self-Balancing tries to ensure that no rack has more than one greater replica of a partition than any other rack. Because this is for fault-tolerance, if Self-Balancing cannot achieve an even rack balance, it does not attempt any balancing at all.
You should maintain as close to an equal number of brokers on each rack as possible.
The number of brokers per rack should be at least as many as the expected number of replicas per rack.
Replica placement and multi-region clusters
If you are using both Multi-Region Clusters and Self-Balancing Clusters, you must specify the broker rack on all brokers. Your starting set of brokers and any brokers you add with self-balancing enabled must have a region or rack specified for
broker.rackin each of theirserver.propertiesfiles.Replica placement rules are used for Multi-Region Clusters, and overload the definition of “rack” to limit where replicas can be placed. Replica placement only works when racks are provided for all brokers.
If replica placement rules are specified for a topic, then this overrides the standard rack awareness policy.
Self-Balancing responds quickly to changes in replica placement rules and proactively moves replicas as needed to satisfy those placement rules.
If Self-Balancing cannot satisfy replica placements, it does not do any rebalances. See Debug rebalance failures for how to identify this.
Self-Balancing can move replicas across racks as long as doing so doesn’t violate rack awareness. This can lead to high network costs both for reassignments and ongoing replication, so multi-region clusters should specify placement rules for all topics in the cluster.
Broker capacity limits
Self-Balancing tries to ensure that brokers do not exceed the host’s capacity and, therefore, moves replicas away from overloaded brokers.
Broker capacity is measured in terms of the following metrics:
- Replica capacity
Brokers should not host more than this many replicas (default 10,000. Can be overridden by confluent.balancer.max.replicas)
- Disk capacity
Brokers should not fill their disks beyond this point (default 85%, can be overridden by confluent.balancer.disk.max.load)
- Network bytes in and out (optional)
The amount of broker network traffic should not exceed this many bytes. By default this value is set extremely high (
Long.MAX_VALUE) so Self-Balancing will not, by default, ever move replicas off a broker due to excessive network load. You can setconfluent.balancer.network.in.max.bytes.per.secondandconfluent.balancer.network.out.max.bytes.per.secondif you want to use network capacity to play a role in Self-Balancing. Note that measuring network traffic accurately can be challenging, and is highly dependent on underlying system hardware. To learn more, see Kafka Broker and Controller Configuration Reference for Confluent Platform and Self-Balancing Cluster Configuration and Command Reference for Confluent Platform.
Replica and disk distribution
Self-Balancing attempts to ensure even distribution of replicas and disk usage across the cluster but with some caveats:
Both replicas and disk usage are balanced to within approximately 20%. It is normal to view a range of replicas or disk usage across brokers, even after balancing.
Disk usage balancing activates when any broker exceeds 20% disk storage, defined by the
log.dirssetting in the broker’s properties file.These resource distribution goals are lower priority than other goals and are not met if meeting them requires violating rack awareness, replica placement, or capacity limits.
Self-Balancing attempts to balance (below-capacity) network usage and leader distribution, but these do not trigger a rebalance. For uneven resource distribution, only replica counts and disk usage above 20% are triggering factors.
Debug rebalance failures
If Self-Balancing cannot rebalance due to rack awareness, replica placement, or capacity problems, it will result in an OptimizationFailureException that should be visible in the log of the Self-Balancing broker (which is the same as the cluster controller). Looking for this exception may help identify such problems.
To learn more about troubleshooting rebalances, see What defines a “balanced” cluster and what triggers a rebalance? and Troubleshooting.
Security considerations
If you are running Self-Balancing with security configured, you must configure authentication for REST endpoints on the brokers. Without these configurations in the broker properties files, Control Center will not have access to Self-Balancing in a secure environment.
If you are using role-based access control (RBAC), the user interacting with Self-Balancing on Control Center must have the RBAC role SystemAdmin on the Kafka cluster to be able to add or remove brokers, and to perform other Self-Balancing related tasks.
For information about setting up security on Confluent Platform, see the Security Overview and the sections on authentication methods, role-based access control, RBAC and ACLs, and Enable Security for a KRaft-Based Cluster in Confluent Platform. The Scripted Confluent Platform Demo also shows various types of security enabled on an example deployment.
Troubleshooting
Following is a list of problems you may encounter while working with Self-Balancing and how to solve them.
In addition to the following troubleshooting tips, see Replica placement and rack configurations for best practices, further discussion of what triggers rebalances, and how to identify and debug rebalance failures.
Self-Balancing options do not show up on Control Center
When Self-Balancing Clusters are enabled, status and configuration options are available on Control Center Cluster Settings > Self-balancing tab. If, instead, this tab displays a message about Confluent Platform version requirements and configuring HTTP servers on the brokers, this indicates something is missing from your configurations or that you are not running the required version of Confluent Platform.
Also, if you are running Self-Balancing with security enabled, you may get an error message such as: Error 504 Gateway Timeout, which indicates that you also must configure authentication for REST endpoints in your broker files, as described in the following section.
Solution: Verify that you have the following settings and update your configuration as needed.
In the Kafka broker files, confluent.balancer.enable must be set to
trueto enable Self-Balancing.In the Control Center properties file,
confluent.controlcenter.streams.cprest.urlmust specify the associated URL for each broker in the cluster as REST endpoints forcontrolcenter.cluster, as described in Required configurations for Control Center.Security is not a requirement for Self-Balancing but if security is enabled, you must also configure authentication for REST endpoints on the brokers. In this case, you would use
confluent.metadata.server.listeners(which enables the Metadata Service) instead ofconfluent.http.server.listenersto listen for API requests. To learn more, see Security considerations.
Broker metrics are not displayed on Control Center
This issue is not specific to Self-Balancing, but related to proper configuration of multi-broker clusters, in general. You may encounter a scenario where Self-Balancing is enabled and displaying Self-Balancing options on Control Center, but broker metrics and per-broker drill-down and management options are not showing up on the Brokers Overview page. The most likely cause for this is that you did not configure the Metrics Reporter for Control Center. To do so, uncomment the following lines in properties files for all brokers. For example, in $CONFLUENT_HOME/etc/server.properties:
metric.reporters=io.confluent.metrics.reporter.ConfluentMetricsReporter
confluent.metrics.reporter.bootstrap.servers=localhost:9092
Solution: To fix this on running clusters, you must shut down Control Center and the brokers, update the Metrics Reporter configurations for the brokers, and reboot.
This configuration is covered in more detail in the Self-Balancing tutorial at Enable the Metrics Reporter for Control Center.
Consumer lag reflected on Control Center
With Self-Balancing running, you might view consumer lag reflected on the Control Center UI for the _confluent-telemetry-metrics system topic. You can ignore this, as it is not representative of message processing on this topic.
Self-Balancing reads from some internal topics but does not commit offsets to them, which results in the Confluent Control Center display showing consumer lag or no active consumer groups.
Broker removal attempt fails during Self-Balancing initialization
Self-Balancing requires up to 30 minutes to initialize and collect metrics from brokers in the cluster. If you attempt to remove a broker before metrics collection completes, the broker removal will fail almost immediately due to insufficient metrics for Self-Balancing. This is the most common use case for “remove broker” failing. The following error message will show on the command line or on Control Center, depending on which method you used for the remove operation:
Self-balancing requires a few minutes to collect metrics for rebalancing plans. Metrics collection is in process. You can try again after 900 seconds.
Solution: The solution for this is to wait 30 minutes, and retry the broker removal.
If you want to remove a controller, the same factors are at play, so you should give some time for Self-Balancing to initialize before attempting a remove operation. In this case, though, the “remove broker” operation can fail at a later phase after the target broker is already shut down. In an offline state, the broker will no longer be accessible from Control Center. If this occurs, wait for 30 minutes, then retry the remove broker operation from the command line. After Self-Balancing has initialized and had time to collect metrics, the operation should succeed, and the rebalancing plan will run.
To learn more about Self-Balancing initialization, see Self-Balancing initialization.
Broker removal cannot complete due to offline partitions
Broker removal can also fail in cases where taking a broker down will result in having fewer online brokers than the number of replicas required in your configurations.
The broker status (available with kafka-remove-brokers --describe) will remain as follows, until you restart one or more of the offline brokers:
[2020-09-17 23:40:53,743] WARN [AdminClient clientId=adminclient-1] Connection to node -5 (localhost/127.0.0.1:9096) could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient)Broker 1 removal status:
Partition Reassignment: IN_PROGRESS
Broker Shutdown: COMPLETE
A short-hand way of troubleshooting this is to ask “how many brokers are down?” and “how many replicas or replication factors must the cluster support?”
Partition reassignment (the last phase in broker removal) will fail to complete in any case where you have n brokers down, and your configuration requires n + 1 or more replicas.
Alternatively, you can consider how many online brokers you need to support the required number of replicas. If you have n brokers online, these can support at most a total of n replicas.
Solution: The solution is to restart the down brokers, and perhaps modify the cluster configuration as a whole. This might include both adding brokers and modifying replicas or replication factors. See the example that follows.
Scenarios that lead to this problem can be a combination of under-replicated topics and topics with too many replicas for the number of online brokers. Having a topic with a replication factor of 1 does not necessarily lead to a problem in and of itself.
A quick way to get an overview of configured replicas on a running cluster is to use kafka-topics --describe on a specified topic, or on the whole cluster (with no topic specified). For system topics, you can scan the replication factors and replicas on system properties (which generate system topics). The Tutorial: Add and Remove Brokers with Self-Balancing in Confluent Platform covers these commands, replicas or replication factors, and the impact of these configurations.
Too many excluded topics cause problems with Self-Balancing
Excluding too many topics (and by inference, partitions) can be counter-productive to maintaining a well-balanced cluster. In internal tests, excluding system topics which accounted for approximately 100 out of 500 total topics was enough to put Self-Balancing into a less than optimal state.
The manifest result of this is that the cluster constantly churns on rebalancing.
Solution: Reduce the number of excluded topics. The relevant configuration options to modify these settings are confluent.balancer.exclude.topic.names and confluent.balancer.exclude.topic.prefixes.
The balancer status for a KRaft controller hangs
When you are running Confluent Platform in KRaft mode and enable Self-Balancing, you might have the balancer status hang in the starting status, like the following example:
kafka-rebalance-cluster --bootstrap-server some-server-us-west-2.compute.amazonaws.com:9091 --status
Balancer status: STARTING
Solution: Set the inter.broker.listener.name in the properties file for each KRaft controller in the cluster. This is in addition to setting this property in each broker properties file. After you set this property, restart the controller.
Rebalance fails with insufficient healthy cluster capacity
A rebalance can fail with an error similar to the following:
com.linkedin.kafka.cruisecontrol.exception.OptimizationFailureException: [DiskCapacityGoal] Insufficient healthy cluster capacity for resource
This error indicates that there isn’t sufficient healthy disk capacity or that the disks are not evenly allocated. You can add disk capacity or adjust confluent.balancer.disk.max.load to a higher value so that Self-Balancing can function as expected. You should also check that the disk allocation across brokers does not vary by more than 5%. For more information, see the Confluent Support article (requires login): How to resolve insufficient healthy cluster capacity.