Tutorial: Add and Remove Brokers with Self-Balancing in Confluent Platform
This example describes how to set up a local, multi-broker cluster running with proper configurations for replication factors, and test Self-Balancing by removing a broker and monitoring the rebalance.
Following broker removal, you add a broker to the cluster and monitor the redistribution of data to fill the empty broker.
Most tasks are performed on the command line but Confluent Control Center is used to verify where the controller is running, and as an additional view into the progress of the rebalance.
Note
You can use this same workflow to set up a cluster on your cloud provider. Simply set the
host:portnames to represent your cloud nodes as appropriate.If you are running Self-Balancing with role-based access control (RBAC) or other security protocols, additional configuration is needed in the Kafka brokers beyond what this tutorial shows. To learn more, see Security considerations.
Configuring and starting controllers and brokers in KRaft mode
As of Confluent Platform 8.0, ZooKeeper is no longer available. Confluent recommends migrating to Kraft mode . To learn more about running Kafka in KRaft mode, see KRaft Overview for Confluent Platform, KRaft Configuration for Confluent Platform, and the Platform Quick Start. To learn about migrating from older versions, see Migrate from ZooKeeper to KRaft on Confluent Platform.
This tutorial provides examples for KRaft mode only. Earlier versions of this documentation (such as version 7.9) provide examples for both KRaft and ZooKeeper.
The examples show an isolated mode configuration for a multi-broker cluster managed by a single controller. As shown in the steps below, you will use $CONFLUENT_HOME/etc/kafka/broker.properties and $CONFLUENT_HOME/etc/kafka/controller.properties as the basis to create a controller ($CONFLUENT_HOME/etc/kafka/controller-sbc.properties) and multiple brokers to test Self-Balancing.
Prerequisites
Before proceeding with the example, verify that you have the following installed on your local machine:
Java 11, or 17 (recommended) to run Confluent Platform (For details on Java requirements, see Java in System Requirements for Confluent Platform.)
Environment variables
As part of setup tasks described in this tutorial, you will be using these shell environment variables:
$CONFLUENT_HOME - Indicates the full path to your local Confluent Platform installation. You should set this up now. For example, change directories into your local Confluent Platform install, and type the following from the top level of the directory:
export CONFLUENT_HOME=`pwd`
$CONTROL_CENTER_HOME - Indicates full path to your Confluent Control Center installation, as described in (Optional) Install and configure Confluent Control Center.
$KAFKA_CLUSTER_ID - Generated
random-uuidfor the cluster, as described in Start the controller and brokers.
Configure Kafka brokers
This example demos a cluster with five brokers. These steps guide you through two passes on the broker properties files, first to configure some basics in the default properties file that will apply to all brokers, then to create four additional properties files based on the original and set up a multi-broker cluster. When you have completed the setup, you will have a total of five properties files, one per broker.
Tip
You can use this same model for a cluster with more or fewer brokers. Using more than 3 brokers simplifies configuration for a scenario where you will remove a broker, since many of the Confluent Platform internal topics default to a replication factor of 3.
Create broker-0 to use a template for the other brokers
Make a copy of broker.properties and rename the copy to use as the prototype broker for this tutorial.
cp $CONFLUENT_HOME/etc/kafka/broker.properties $CONFLUENT_HOME/etc/kafka/broker-0.properties
In $CONFLUENT_HOME/etc/kafka/broker-0.properties, make the following changes, and save the file.
Enable the Metrics Reporter for Control Center
When the Monitor Kafka with Metrics Reporter in Confluent Platform is enabled, it populates the Brokers Overview page in Control Center with metrics on all brokers, along with a clickable list where you can drill down on each individual broker to get a detail view of statistics and an option to remove a broker. If this setting is not enabled, Control Center will not display broker metrics or management options.
When uncommented, these lines allow the brokers to send metrics to Control Center, and specify that the metrics cluster has a single broker. This configuration can apply to all brokers in the cluster. Note you will leave confluent.metrics.reporter.bootstrap.servers=localhost:9092 commented out. In subsequent steps, you will modify this configuration to point to a list of all brokers by adding a line at the end of the files for all brokers and the controller.
metric.reporters=io.confluent.metrics.reporter.ConfluentMetricsReporterconfluent.metrics.reporter.topic.replicas=1
Run these commands to update the Metrics Reporter configurations.
sed -i '' -e "s/#metric.reporters=/metric.reporters=/g" $CONFLUENT_HOME/etc/kafka/broker-0.properties
sed -i '' -e "s/#confluent.metrics.reporter.topic.replicas=1/confluent.metrics.reporter.topic.replicas=1/g" $CONFLUENT_HOME/etc/kafka/broker-0.properties
Configure replication factors for Self-Balancing
For Self-Balancing to work if you delete a broker, replication factors must be less than the number of brokers in the cluster, but enough that replication can take place. For example, you can’t have a topic with a replication factor of 1 because if the topic is on a broker that gets deleted there won’t be a replica to use for the rebalancing. You will get an error when you try to delete a broker (Error while executing broker removal).
The following steps show you how to reset replication factors and replicas to 2, and uncomment the properties if needed so that your changes go into effect. When you complete these steps, your file should show the following configs:
offsets.topic.replication.factor=2transaction.state.log.replication.factor=2confluent.license.topic.replication.factor=2confluent.metadata.topic.replication.factor=2confluent.balancer.topic.replication.factor=2
Run this command to update replication factors for the broker. The metrics cluster will have a single broker.
sed -i '' -e "s/replication.factor=1/replication.factor=2/g" $CONFLUENT_HOME/etc/kafka/broker-0.properties
Tip
When you create your topics, make sure that they also have the needed replication factor, depending on the number of brokers. This is described in subsequent sections.
Limiting replication factors to 2 provides the option to shrink the cluster to as few as 2 brokers and expand back up to 5.
Verify that Self-Balancing is enabled
Verify that Self-Balancing is enabled on all brokers. (Later you will also enable it on the controller.) The value for this property must be specified as true and the line must be uncommented:
confluent.balancer.enable=true
If confluent.balancer.enable is not explicitly specified or if this line is commented out, it will default to false (off).
sed -i '' -e "s/#confluent.balancer.enable=true/confluent.balancer.enable=true/g" $CONFLUENT_HOME/etc/kafka/broker-0.properties
Save the file
You now have an updated version of broker-0.properties to use as the basis for your brokers. If you updated the file using the copy-paste commands, you are ready to go. If you updated the file, manually, save it.
Create a basic configuration for a five-broker cluster
You will start with the broker/server properties file you updated for Metrics Reporter, replication factors, and Self-Balancing in the previous steps, then copy it and modify the configurations as shown below, renaming the new files to represent the other four brokers.
Configuration snapshot preview
The table below shows a summary of the per-broker configurations you will specify for each of these files, as a reference to check against. The steps in the next sections guide you through a quick way to set up these files, using existing the existing broker-0.properties file as a basis for your specialized ones. To get started, skip to the next section: Configure the servers.
File | Configurations |
|---|---|
controller-sbc.properties | You will update the values for these basic properties to make them unique for the controller:
|
broker-0.properties | You will update the values for these basic properties to make them unique:
Add the following listener configuration to specify the REST endpoint for this broker:
|
broker-1.properties | You will update the values for these basic properties to make them unique:
Provide the listener configuration to specify the REST endpoint unique to this broker:
|
broker-2.properties | You will update the values for these basic properties to make them unique:
Provide the listener configuration to specify the REST endpoint unique to this broker:
|
broker-3.properties | You will update the values for these basic properties to make them unique:
Provide the listener configuration to specify the REST endpoint unique to this broker:
|
broker-4.properties | You will update the values for these basic properties to make them unique:
Provide the listener configuration to specify the REST endpoint unique to this broker:
|
Configure the servers
Start with the broker-0.properties file you updated in the previous sections with regard to replication factors and enabling Self-Balancing Clusters. You will make a few more changes to this file, then use it as the basis for the other servers.
Update the node ID, controller quorum bootstrap server, listeners, and enable telemetry for the first broker:
sed -i '' -e "s/node.id=2/node.id=0/g" $CONFLUENT_HOME/etc/kafka/broker-0.properties
sed -i '' -e "s/9093/9097/g" $CONFLUENT_HOME/etc/kafka/broker-0.properties
sed -i '' -e "s/#confluent.metadata.server.listeners/confluent.metadata.server.listeners/g" $CONFLUENT_HOME/etc/kafka/broker-0.properties
sed -i '' -e "s/#confluent.telemetry.enabled=true/confluent.telemetry.enabled=true/g" $CONFLUENT_HOME/etc/kafka/broker-0.properties
echo "confluent.reporters.telemetry.auto.enable=true" >> $CONFLUENT_HOME/etc/kafka/broker-0.properties
Copy the properties file for the first broker to use as a basis for the other four:
cp $CONFLUENT_HOME/etc/kafka/broker-0.properties $CONFLUENT_HOME/etc/kafka/broker-1.properties
cp $CONFLUENT_HOME/etc/kafka/broker-0.properties $CONFLUENT_HOME/etc/kafka/broker-2.properties
cp $CONFLUENT_HOME/etc/kafka/broker-0.properties $CONFLUENT_HOME/etc/kafka/broker-3.properties
cp $CONFLUENT_HOME/etc/kafka/broker-0.properties $CONFLUENT_HOME/etc/kafka/broker-4.properties
Update the node ID, listener, and data directories for broker-1, and then update the REST endpoint listener for this broker:
sed -i '' -e "s/node.id=0/node.id=1/g" $CONFLUENT_HOME/etc/kafka/broker-1.properties
sed -i '' -e "s/9092/9093/g" $CONFLUENT_HOME/etc/kafka/broker-1.properties
sed -i '' -e "s/kraft-broker-logs/kraft-broker-logs-1/g" $CONFLUENT_HOME/etc/kafka/broker-1.properties
sed -i '' -e "s/8090/8091/g" $CONFLUENT_HOME/etc/kafka/broker-1.properties
Update the node ID, listener, controller, and data directories for broker-2, and then update the REST endpoint listener for this broker:
sed -i '' -e "s/node.id=0/node.id=2/g" $CONFLUENT_HOME/etc/kafka/broker-2.properties
sed -i '' -e "s/9092/9094/g" $CONFLUENT_HOME/etc/kafka/broker-2.properties
sed -i '' -e "s/kraft-broker-logs/kraft-broker-logs-2/g" $CONFLUENT_HOME/etc/kafka/broker-2.properties
sed -i '' -e "s/8090/8092/g" $CONFLUENT_HOME/etc/kafka/broker-2.properties
Update the node ID, listener, controller, and data directories for broker-3, and then update the REST endpoint listener for this broker:
sed -i '' -e "s/node.id=0/node.id=3/g" $CONFLUENT_HOME/etc/kafka/broker-3.properties
sed -i '' -e "s/9092/9095/g" $CONFLUENT_HOME/etc/kafka/broker-3.properties
sed -i '' -e "s/kraft-broker-logs/kraft-broker-logs-3/g" $CONFLUENT_HOME/etc/kafka/broker-3.properties
sed -i '' -e "s/8090/8093/g" $CONFLUENT_HOME/etc/kafka/broker-3.properties
Update the node ID, listener, controller, and data directories for broker-4, and then update the REST endpoint listener for this broker.
sed -i '' -e "s/node.id=0/node.id=4/g" $CONFLUENT_HOME/etc/kafka/broker-4.properties
sed -i '' -e "s/9092/9096/g" $CONFLUENT_HOME/etc/kafka/broker-4.properties
sed -i '' -e "s/kraft-broker-logs/kraft-broker-logs-4/g" $CONFLUENT_HOME/etc/kafka/broker-4.properties
sed -i '' -e "s/8090/8094/g" $CONFLUENT_HOME/etc/kafka/broker-4.properties
For all brokers, now update
confluent.metrics.reporter.bootstrap.servers. Referencing the list of all brokers, allows the metrics reporter to discover the entire cluster. (You must do this at this point, after you have made all previous updates to the broker properties files, otherwise the port updates performed for other purposes would overwrite the port numbers in this list. The echo command will add the line to end of each broker file, and supersede the default line#confluent.metrics.reporter.bootstrap.servers=localhost:9092, which is exactly what you want.)echo "confluent.metrics.reporter.bootstrap.servers=localhost:9092,localhost:9093,localhost:9094,localhost:9095,localhost:9096" >> $CONFLUENT_HOME/etc/kafka/broker-0.properties
echo "confluent.metrics.reporter.bootstrap.servers=localhost:9092,localhost:9093,localhost:9094,localhost:9095,localhost:9096" >> $CONFLUENT_HOME/etc/kafka/broker-1.properties
echo "confluent.metrics.reporter.bootstrap.servers=localhost:9092,localhost:9093,localhost:9094,localhost:9095,localhost:9096" >> $CONFLUENT_HOME/etc/kafka/broker-2.properties
echo "confluent.metrics.reporter.bootstrap.servers=localhost:9092,localhost:9093,localhost:9094,localhost:9095,localhost:9096" >> $CONFLUENT_HOME/etc/kafka/broker-3.properties
echo "confluent.metrics.reporter.bootstrap.servers=localhost:9092,localhost:9093,localhost:9094,localhost:9095,localhost:9096" >> $CONFLUENT_HOME/etc/kafka/broker-4.properties
Finally, create
controller-sbc.properties, update the controller node ID, controller quorum bootstrap server, listener port, telemetry and metrics reporters, and enable self-balancing:cp $CONFLUENT_HOME/etc/kafka/controller.properties $CONFLUENT_HOME/etc/kafka/controller-sbc.properties
sed -i '' -e "s/node.id=1/node.id=5/g" $CONFLUENT_HOME/etc/kafka/controller-sbc.properties
sed -i '' -e "s/9093/9097/g" $CONFLUENT_HOME/etc/kafka/controller-sbc.properties
sed -i '' -e "s/#metric.reporters=/metric.reporters=/g" $CONFLUENT_HOME/etc/kafka/controller-sbc.properties
sed -i '' -e "s/#confluent.metrics.reporter.topic.replicas=1/confluent.metrics.reporter.topic.replicas=1/g" $CONFLUENT_HOME/etc/kafka/controller-sbc.properties
sed -i '' -e "s/#confluent.telemetry.enabled=true/confluent.telemetry.enabled=true/g" $CONFLUENT_HOME/etc/kafka/controller-sbc.properties
echo "confluent.reporters.telemetry.auto.enable=true" >> $CONFLUENT_HOME/etc/kafka/controller-sbc.properties
sed -i '' -e "s/#confluent.balancer.enable=true/confluent.balancer.enable=true/g" $CONFLUENT_HOME/etc/kafka/controller-sbc.properties
echo "confluent.balancer.data.enabled=true" >> $CONFLUENT_HOME/etc/kafka/controller-sbc.properties
echo "confluent.metrics.reporter.bootstrap.servers=localhost:9092,localhost:9093,localhost:9094,localhost:9095,localhost:9096" >> $CONFLUENT_HOME/etc/kafka/controller-sbc.properties
Note that Self-Balancing must be enabled on the controller. It shouldn’t be necessary to enable it on the brokers.
If confluent.balancer.enable is not explicitly specified or if this line is commented out, it will default to false (off).
When you have completed this step, you will have five properties files and a controller that match the configurations shown in Configuration snapshot preview.
broker-0.propertieswhich corresponds to node/broker 0broker-1.propertieswhich corresponds to node/broker 1broker-2.propertieswhich corresponds to node/broker 2broker-3.propertieswhich corresponds to node/broker 3broker-4.propertieswhich corresponds to node/broker 4controller-sbc.properties, which will serve as the Controller.
Run this command to list the files:
ls $CONFLUENT_HOME/etc/kafka/
Start Confluent Platform, create topics, and generate test data
Self-Balancing Clusters can take up to 30 minutes to initialize and collect metrics. Attempting to remove brokers during this startup process will result in an error due to insufficient metrics. Therefore, once you have started all the components, allow some time for Self-Balancing to initialize before beginning the tutorial steps below. To learn more, see Broker removal attempt fails during Self-Balancing initialization in the Troubleshooting section.
Follow these steps to start the servers in separate command windows, create topics, and generate data to the topics.
Note that the recommended path is to test this first without Control Center (which requires additional configurations to the brokers and controller). Once you verify that everything is working correctly, you can either move forward using only the Confluent CLI or pause everything to add some additional configurations for Control Center. Both of these options are described in subsequent steps.
Start the controller and brokers
In KRaft mode, you must run the following commands from $CONFLUENT_HOME to generate a random cluster ID, and format log directories for the controller and each broker in dedicated command windows. You will then start the controller and brokers from those same dedicated windows.
The kafka-storage command is run only once per broker/controller. You cannot use the kafka-storage command to update an existing cluster. If you make a mistake in configurations at that point, you must recreate the directories from scratch, and work through the steps again.
Controller
In a new dedicated command window, change directories into
$CONFLUENT_HOMEto run the KRaft setup commands and start the controller.cd $CONFLUENT_HOME
Generate a
random-uuidfor the cluster using the kafka-storage tool.KAFKA_CLUSTER_ID="$(bin/kafka-storage random-uuid)"
Get the value for $KAFKA_CLUSTER_ID and save it somewhere, or add it to your
.bash_profile,.bashrc,.zshor similar so that it is available to you in new command windows for running the brokers. Alternatively, in each new broker window, manually assign the ID with:export KAFKA_CLUSTER_ID=<KAFKA-CLUSTER-ID>. You will need this same cluster ID to start the controller and all of the brokers.echo $KAFKA_CLUSTER_ID
Format the log directories for the controller:
./bin/kafka-storage format -t $KAFKA_CLUSTER_ID -c $CONFLUENT_HOME/etc/kafka/controller-sbc.properties --ignore-formatted --standalone
Start the controller:
kafka-server-start $CONFLUENT_HOME/etc/kafka/controller-sbc.properties
broker-0.properties (node 0)
In a new command window dedicated to running node 0, change directories into
$CONFLUENT_HOMEto run the KRaft setup commands and start your first broker.cd $CONFLUENT_HOME
Make sure that the KAFKA_CLUSTER_ID you generated for the controller is available in this shell as an environment variable (either by exporting it here manually with
export KAFKA_CLUSTER_ID=<KAFKA-CLUSTER-ID>or pre-set in a profile).echo $KAFKA_CLUSTER_ID
Format the log directories for this broker:
./bin/kafka-storage format -t $KAFKA_CLUSTER_ID -c $CONFLUENT_HOME/etc/kafka/broker-0.properties --ignore-formatted
Start the broker:
kafka-server-start $CONFLUENT_HOME/etc/kafka/broker-0.properties
broker-1.properties (node 1)
In a new command window dedicated to running node 1, change directories into
$CONFLUENT_HOMEto run the KRaft setup commands and start broker-1.cd $CONFLUENT_HOME
Make sure that the KAFKA_CLUSTER_ID you generated for the controller is available in this shell as an environment variable (either by exporting it here manually with
export KAFKA_CLUSTER_ID=<KAFKA-CLUSTER-ID>or pre-set in a profile).echo $KAFKA_CLUSTER_ID
Format the log directories for broker-1:
./bin/kafka-storage format -t $KAFKA_CLUSTER_ID -c $CONFLUENT_HOME/etc/kafka/broker-1.properties --ignore-formatted
Start the broker:
kafka-server-start $CONFLUENT_HOME/etc/kafka/broker-1.properties
broker-2.properties (node 2)
In a new command window dedicated to running node 2, change directories into
$CONFLUENT_HOMEto run the KRaft setup commands and start broker-2.cd $CONFLUENT_HOME
Make sure that the KAFKA_CLUSTER_ID you generated for the controller is available in this shell as an environment variable (either by exporting it here manually with
export KAFKA_CLUSTER_ID=<KAFKA-CLUSTER-ID>or pre-set in a profile)echo $KAFKA_CLUSTER_ID
Format the log directories for this broker-2:
./bin/kafka-storage format -t $KAFKA_CLUSTER_ID -c $CONFLUENT_HOME/etc/kafka/broker-2.properties --ignore-formatted
Start the broker:
kafka-server-start $CONFLUENT_HOME/etc/kafka/broker-2.properties
broker-3.properties (node 3)
In a new command window dedicated to running node 3, change directories into
$CONFLUENT_HOMEto run the KRaft setup commands and start broker-3.cd $CONFLUENT_HOME
Make sure that the KAFKA_CLUSTER_ID you generated for the controller is available in this shell as an environment variable (either by exporting it here manually with
export KAFKA_CLUSTER_ID=<KAFKA-CLUSTER-ID>or pre-set in a profile).echo $KAFKA_CLUSTER_ID
Format the log directories for this broker-3:
./bin/kafka-storage format -t $KAFKA_CLUSTER_ID -c $CONFLUENT_HOME/etc/kafka/broker-3.properties --ignore-formatted
Start the broker:
kafka-server-start $CONFLUENT_HOME/etc/kafka/broker-3.properties
broker-4.properties (node 4)
In a new command window dedicated to running node 4, change directories into
$CONFLUENT_HOMEto run the following KRaft setup commands for broker-4.cd $CONFLUENT_HOME
Make sure that the KAFKA_CLUSTER_ID you generated for the controller is available in this shell as an environment variable (either by exporting it here manually with
export KAFKA_CLUSTER_ID=<KAFKA-CLUSTER-ID>or pre-set in a profile).echo $KAFKA_CLUSTER_ID
Format the log directories for this broker-4:
./bin/kafka-storage format -t $KAFKA_CLUSTER_ID -c $CONFLUENT_HOME/etc/kafka/broker-4.properties --ignore-formatted
Start the broker:
kafka-server-start $CONFLUENT_HOME/etc/kafka/broker-4.properties
Create a topic and test the cluster
You should now have a controller and 5 brokers up-and-running. Follow these steps to create a topic, list topics, and run some other commands to verify that the cluster is running and working successfully. At this point, the recommended path is to make sure this is working properly before taking the optional step of setting up Confluent Control Center, or proceeding to removing/adding brokers to test rebalancing.
Create one or more topics with 3 partitions and a replication factor of 2.
kafka-topics --create --topic my-sbc-test --partitions 3 --replication-factor 2 --bootstrap-server localhost:9092
You should get a confirmation that the topic was successfully created. Also, you can get a list of existing topics as follows:
kafka-topics --list --bootstrap-server localhost:9092
Get detailed information on a particular topic with the
--describeoption:kafka-topics --describe --topic my-sbc-test --bootstrap-server localhost:9092
Or, get detailed information on all topics with the
--describeoption:kafka-topics --describe --bootstrap-server localhost:9092
For Self-Balancing to work, topics must have a replication factor that maps properly to the number of brokers in the cluster. The replication factor must be greater than 1, but less than the total number of brokers. A five broker cluster requires a replication factor of between 2 and 4.
Create topics with multiple partitions to distribute the data across all five brokers, as in the above examples.
What’s next
At this point you are ready to monitor and test Self-Balancing by removing and then adding back in a broker, and monitoring the rebalance during these operations.
The following sections provide two different ways of doing so (command line or Control Center). If you want to try both, you can proceed through these steps in order and use Confluent Control Center and the command line interchangeably, but the expectation is that you will prefer either the command line or Control Center as your primary method of working with Self-Balancing.
If you want to use Control Center either exclusively or alongside the Confluent CLI, then go to the next section ((Optional) Install and configure Confluent Control Center) and follow the instructions, which guide you through stopping the brokers and controller, download and install of Control Center, configuration changes to Control Center and to the brokers and controllers, and restart of all components.
Or,
If you do not want to use Control Center right now, and stick with only the Confluent CLI, skip to Use the command line to test rebalancing.
(Optional) Install and configure Confluent Control Center
Confluent Control Center is not a requirement for running Self-Balancing or for this tutorial, but it does give further visibility into the process, and provide additional monitoring context. You can use Control Center to verify your starting configuration and monitor the progress of the rebalance, in addition to command line output.
As of Confluent Platform 8.0, Control Center ships, installs, and runs independently of Confluent Platform, as described in Single-node manual installation. Since this packaging, install, and run process is new in 8.0, and a bit complicated as it relates to testing a fiver-broker cluster with Self-Balancing, full instructions are provided below to get you started. The monitoring backend now uses Prometheus for metrics collection, which serves as the dedicated metrics store and query engine for Control Center. The new Control Center (next generation) can scale to monitor larger workloads compared to the old version.
While you can accomplish the following tasks in any order, the suggested sequence will avoid logging errors on running brokers and controllers that would be caused by adding the Control Center telemetry configs to the Confluent Platform files before you have Prometheus and Control Center running to collect those metrics. (The errors would look similar to this: ERROR Failed to send request POST http://localhost:9090/api/v1/otlp/v1/metrics.)
1. Download, extract, and configure Control Center
Download, extract, and configure Control Center to run a Single-node manual installation using the archives (not Docker). Note that the Control Center installation will live and run in its own directory ($CONTROL_CENTER_HOME) at the same level as $CONFLUENT_HOME. This is different from the setup in previous versions of Confluent Platform, where Control Center resided in a subdirectory under $CONFLUENT_HOME.
Download Control Center and unzip/extract the
tar.gzfile.wget https://packages.confluent.io/confluent-control-center-next-gen/archive/confluent-control-center-next-gen-2.2.0.tar.gztar -xvf confluent-control-center-next-gen-2.2.0.tar.gz
Change directories (cd) into
confluent-control-center-next-gen-2.2.0-0to make modifications to the C3 files.cd confluent-control-center-next-gen-2.2.0
Configure $CONTROL_CENTER_HOME for convenience, and verify it.
export CONTROL_CENTER_HOME=`pwd`
echo $CONTROL_CENTER_HOME
2. Configure Control Center with REST endpoints and advertised listeners
You must tell Control Center about the REST endpoints for all brokers in your cluster, and the advertised listeners for the other components you may want to run. Without these configurations, the brokers and components will not show up on Control Center.
In $CONTROL_CENTER_HOME/etc/confluent-control-center/control-center-dev.properties, you must replace the default value for the Kafka REST endpoint URL to include all brokers. You can either:
Manually edit the file with a copy-paste of the following lines to match your multi-broker configuration, and save the file:
# Kafka REST endpoint URL confluent.controlcenter.streams.cprest.url=http://localhost:8090,http://localhost:8091,http://localhost:8092,http://localhost:8093,http://localhost:8094
Or:
Use these two commands to update this configuration in the file:
sed -i '' -e "s/confluent.controlcenter.streams.cprest.url/#confluent.controlcenter.streams.cprest.url/g" $CONTROL_CENTER_HOME/etc/confluent-control-center/control-center-dev.properties
echo "confluent.controlcenter.streams.cprest.url=http://localhost:8090,http://localhost:8091,http://localhost:8092,http://localhost:8093,http://localhost:8094" >> $CONTROL_CENTER_HOME/etc/confluent-control-center/control-center-dev.properties
Tip
Self-Balancing doesn’t need embedded REST Proxy, but Control Center depends on it to manage Self-Balancing. To learn more, see Required Configurations for Control Center in Self-Balancing Configuration Options and confluent.controlcenter.streams.cprest.url in the Control Center Configuration Reference for Confluent Platform.
3. Start Prometheus and (Control Center)
If you are not already there, change directories into $CONTROL_CENTER_HOME.
cd $CONTROL_CENTER_HOME
Start Prometheus in this dedicated window.
On Linux or Windows, use the following command:
bin/prometheus-start
On Mac OS:
(Optional) Edit/update
bin/prometheus-startto run on Mac as follows, and save the file. (If you do not make these changes to the file, Prometheus will still run, but will not output any visible logging information to indicate that it is running.)At the end of the last line in the file replace,
&>> $LOG_FILEwith2>&1 | tee -a "$LOG_FILE". So instead of the end of the last line looking like this:$METRICS_RETENTION_DAYS &>> $LOG_FILE, it should look like this:$METRICS_RETENTION_DAYS 2>&1 | tee -a "$LOG_FILE"Start Prometheus using the following Mac specific command.
bash bin/prometheus-start
Start Control Center in a dedicated window. If you have not stored $CONTROL_CENTER_HOME into a profile, remember to set this variable in the new shell to point to your Control Center installation, as you did before.
cd $CONTROL_CENTER_HOME
./bin/control-center-start $CONTROL_CENTER_HOME/etc/confluent-control-center/control-center-dev.properties
4. Configure the controller and brokers to send metrics to Control Center with Prometheus
In the following next steps, you will configure your Kafka brokers and controller to export their metrics using the confluent.telemetry.exporter._c3.client.base.url setting to push OTLP (OpenTelemetry Protocol) metrics. Control Center will act as an OTLP receiver, listening on localhost:9090 for the incoming metrics.
If you have the controller and brokers running (per the previous steps), stop these components in the reverse order from which you started them.
Stop each broker by using Ctrl-C in each window.
Finally, stop the controller with Ctrl-C in its window.
Leave the windows open so that you can quickly re-start the controller and brokers after you’ve added the additional required configurations.
Add the following lines to the end of the properties files for the controller and each one of the brokers to emit metrics to Prometheus, the OTLP endpoint. (The fourth line with the value for
confluent.telemetry.exporter._c3.metrics.include=iis very long. Simply copy the code block as provided and paste it in at the end of the properties files. This line will paste in as a single line, even though it shows as wrapped in the documentation.)metric.reporters=io.confluent.telemetry.reporter.TelemetryReporter confluent.telemetry.exporter._c3.type=http confluent.telemetry.exporter._c3.enabled=true confluent.telemetry.exporter._c3.metrics.include=io.confluent.kafka.server.request.(?!.*delta).*|io.confluent.kafka.server.server.broker.state|io.confluent.kafka.server.replica.manager.leader.count|io.confluent.kafka.server.request.queue.size|io.confluent.kafka.server.broker.topic.failed.produce.requests.rate.1.min|io.confluent.kafka.server.tier.archiver.total.lag|io.confluent.kafka.server.request.total.time.ms.p99|io.confluent.kafka.server.broker.topic.failed.fetch.requests.rate.1.min|io.confluent.kafka.server.broker.topic.total.fetch.requests.rate.1.min|io.confluent.kafka.server.partition.caught.up.replicas.count|io.confluent.kafka.server.partition.observer.replicas.count|io.confluent.kafka.server.tier.tasks.num.partitions.in.error|io.confluent.kafka.server.broker.topic.bytes.out.rate.1.min|io.confluent.kafka.server.request.total.time.ms.p95|io.confluent.kafka.server.controller.active.controller.count|io.confluent.kafka.server.session.expire.listener.zookeeper.disconnects.total|io.confluent.kafka.server.request.total.time.ms.p999|io.confluent.kafka.server.controller.active.broker.count|io.confluent.kafka.server.request.handler.pool.request.handler.avg.idle.percent.rate.1.min|io.confluent.kafka.server.session.expire.listener.zookeeper.disconnects.rate.1.min|io.confluent.kafka.server.controller.unclean.leader.elections.rate.1.min|io.confluent.kafka.server.replica.manager.partition.count|io.confluent.kafka.server.controller.unclean.leader.elections.total|io.confluent.kafka.server.partition.replicas.count|io.confluent.kafka.server.broker.topic.total.produce.requests.rate.1.min|io.confluent.kafka.server.controller.offline.partitions.count|io.confluent.kafka.server.socket.server.network.processor.avg.idle.percent|io.confluent.kafka.server.partition.under.replicated|io.confluent.kafka.server.log.log.start.offset|io.confluent.kafka.server.log.tier.size|io.confluent.kafka.server.log.size|io.confluent.kafka.server.tier.fetcher.bytes.fetched.total|io.confluent.kafka.server.request.total.time.ms.p50|io.confluent.kafka.server.tenant.consumer.lag.offsets|io.confluent.kafka.server.session.expire.listener.zookeeper.expires.rate.1.min|io.confluent.kafka.server.log.log.end.offset|io.confluent.kafka.server.broker.topic.bytes.in.rate.1.min|io.confluent.kafka.server.partition.under.min.isr|io.confluent.kafka.server.partition.in.sync.replicas.count|io.confluent.telemetry.http.exporter.batches.dropped|io.confluent.telemetry.http.exporter.items.total|io.confluent.telemetry.http.exporter.items.succeeded|io.confluent.telemetry.http.exporter.send.time.total.millis|io.confluent.kafka.server.controller.leader.election.rate.(?!.*delta).*|io.confluent.telemetry.http.exporter.batches.failed confluent.telemetry.exporter._c3.client.base.url=http://localhost:9090/api/v1/otlp confluent.telemetry.exporter._c3.client.compression=gzip confluent.telemetry.exporter._c3.api.key=dummy confluent.telemetry.exporter._c3.api.secret=dummy confluent.telemetry.exporter._c3.buffer.pending.batches.max=80 confluent.telemetry.exporter._c3.buffer.batch.items.max=4000 confluent.telemetry.exporter._c3.buffer.inflight.submissions.max=10 confluent.telemetry.metrics.collector.interval.ms=60000 confluent.telemetry.remoteconfig._confluent.enabled=false confluent.consumer.lag.emitter.enabled=true
Save the updated files.
5. Restart the controller and brokers
Now that you have the controller and brokers configured to send metrics to Control Center, you can restart them, and monitor Self-Balancing with Control Center.
If you left the windows open, you should have the proper $KAFKA_CLUSTER_ID in every shell, and can simply restart each component in its requisite window as shown below. If you closed the windows and/or don’t have the $KAFKA_CLUSTER_ID saved in a profile, you will need to export it again into each window before starting each component.
Restart the controller:
kafka-server-start $CONFLUENT_HOME/etc/kafka/controller-sbc.properties
Restart each of the brokers in separate windows:
kafka-server-start $CONFLUENT_HOME/etc/kafka/broker-0.properties
kafka-server-start $CONFLUENT_HOME/etc/kafka/broker-1.properties
kafka-server-start $CONFLUENT_HOME/etc/kafka/broker-2.properties
kafka-server-start $CONFLUENT_HOME/etc/kafka/broker-3.properties
kafka-server-start $CONFLUENT_HOME/etc/kafka/broker-4.properties
Use the command line to test rebalancing
The following sections describe how to send data to topics, remove a broker, and monitor the progress of the rebalance using the command kafka-remove-brokers. If you restart the broker (essentially, “adding” a broker), Self-Balancing redistributes the data again across all nodes.
List topics and generate data to your test topic
Get a list of existing topics as follows:
kafka-topics --list --bootstrap-server localhost:9092
You should see the Self-Balancing test topic you created in a previous step (Create a topic and test the cluster) included in the list.
Generate data to topics.
In a separate command window, use the
kafka-producer-perf-testcommand to produce data to the topicmy-sbc-test.kafka-producer-perf-test \ --producer-props bootstrap.servers=localhost:9092 \ --topic my-sbc-test \ --record-size 1000 \ --throughput 1000 \ --num-records 3600000
If you created additional topics, you can use this command to send data to those topics, also.
Verify status of brokers and topic data
Use the command line to verify the current status of the deployment, including topics, topic data distribution, and number of brokers.
Use
kafka-broker-api-versionsandgrepforidto view the brokers online.kafka-broker-api-versions --bootstrap-server localhost:9092 | grep 'id: '
Your output should resemble:
localhost:9095 (id: 3 rack: null) -> ( localhost:9093 (id: 1 rack: null) -> ( localhost:9096 (id: 4 rack: null) -> ( localhost:9094 (id: 2 rack: null) -> ( localhost:9092 (id: 0 rack: null) -> (
Use
kafka-topics --describeto view information about the test topic you created.kafka-topics --bootstrap-server localhost:9092 --topic my-sbc-test --describe
Your output should resemble:
Topic: my-sbc-test PartitionCount: 3 ReplicationFactor: 2 Configs: segment.bytes=1073741824 Topic: my-sbc-test Partition: 0 Leader: 0 Replicas: 0,4 Isr: 0,4 Offline: Topic: my-sbc-test Partition: 1 Leader: 4 Replicas: 4,1 Isr: 4,1 Offline: Topic: my-sbc-test Partition: 2 Leader: 1 Replicas: 1,2 Isr: 1,2 Offline:
Remove a broker
With Self-Balancing enabled, and Confluent Platform up and running, use kafka-remove-brokers to delete a broker and monitor the rebalancing.
Before you start on these steps, make sure that Confluent Platform and Self-Balancing have been running for at least 20 minutes to give Self-Balancing time to initialize. (To learn more, see Broker removal attempt fails during Self-Balancing initialization in Troubleshooting.)
Also, for this example, do not delete the controller which in this case is broker ID 0.
Important
In practice, you can remove a lead broker. It may cause a short delay in cluster balancing, which is why we suggest not doing so for this example. To learn more, What happens if the lead broker (controller) is removed or lost?.
If the broker you attempt to remove contains the only replica for a topic, the broker removal will fail. To learn more, see Limitations.
You can remove a broker in KRaft mode and the
UnregisterBrokercommand is automatically called. You should not call it manually.
Remove a broker.
For example, the following command removes broker 1 and moves its data to remaining brokers in the cluster..
kafka-remove-brokers --bootstrap-server localhost:9092,localhost:9093,localhost:9094,localhost:9095,localhost:9096 \ --broker-id 1 --delete 1>&2 | grep -v SLF4J
Self-Balancing acknowledges the command and provides feedback similar to the following.
Initiating remove broker call... Started remove broker task for broker 1. You can check its status by calling this command again with the `--describe` option.
Monitor the progress of the rebalance from the command line.
You can track the shutdown and rebalance operation by plugging in the
--describeoption to the above command in place of the--delete:kafka-remove-brokers --bootstrap-server localhost:9092,localhost:9093,localhost:9094,localhost:9095,localhost:9096 \ --broker-id 1 --describe 1>&2 | grep -v SLF4J
On an in-progress rebalance, you will get feedback similar to the following.
Broker 1 removal status: Partition Reassignment: IN_PROGRESS Broker Shutdown: COMPLETE
When broker removal is complete, the
--describecommand will show the following.Broker 1 removal status - SUCCESS. Sub-task statuses: Broker Replica Exclusion: COMPLETED Partition Reassignment: COMPLETED Broker Shutdown: COMPLETED Shutdown Scheduled: true Operation Creation Time: 2025-06-16_22:49:27 UTC Operation Last Update Time: 2025-06-16_22:50:05 UTC
Note
If you get the following error, it is likely that Self-Balancing is still initializing, which can take up to 30 minutes. If this happens, retry broker removal after several minutes, and it should succeed.
Broker 1 removal status: Partition Reassignment: FAILED Broker Shutdown: CANCELED
Rerun
kafka-broker-api-versionsto view the brokers online.kafka-broker-api-versions --bootstrap-server localhost:9092 | grep 'id: '
Your output should resemble:
localhost:9092 (id: 0 rack: null) -> ( localhost:9096 (id: 4 rack: null) -> ( localhost:9094 (id: 2 rack: null) -> ( localhost:9095 (id: 3 rack: null) -> (
You can see that broker 1 is now offline.
You can also rerun
kafka-topics --describeon all topics or a specific topic with the following commands. These may or may not show changes related to the rebalance, but will verify that topics and topic data are still available.kafka-topics --describe --bootstrap-server localhost:9092 kafka-topics --bootstrap-server localhost:9092 --topic my-sbc-test --describe
Add a broker (restart)
You can restart the broker after the broker removal operation (previous section) is completed. (This provides an example of “adding a broker”, just using the same broker you removed to simplify the walkthrough.)
Restart the broker (for example broker 1) and watch the rebalance.
The easiest way to do this is to return to the command window where you started broker 1. You should see that the broker has been stopped. Hit the up arrow on your keyboard, and then press return to rerun the same command you started this with originally:
./bin/kafka-server-start etc/kafka/server-1.propertiesSelf-Balancing acknowledges the command and provides feedback similar to the following, as the broker reboots.
[2020-06-26 17:45:44,986] INFO BROKER Aggregator rolled out 1 new windows, reset 1 windows, current window range [1593213000000, 1593219000000], abandon 0 samples. (com.linkedin.cruisecontrol.monitor.sampling.aggregator.MetricSampleAggregator) [2020-06-26 17:46:06,314] INFO DataBalancer: Scheduling DataBalanceEngine broker addition: [1] (io.confluent.databalancer.ConfluentDataBalanceEngine) [2020-06-26 17:46:06,314] INFO DataBalancer: Starting addBrokers call (io.confluent.databalancer.ConfluentDataBalanceEngine)
When the broker is up, rerun
kafka-broker-api-versionsto view all brokers online.kafka-broker-api-versions --bootstrap-server localhost:9092 | grep 'id: ' Your output should resemble:
localhost:9095 (id: 3 rack: null) -> ( localhost:9093 (id: 1 rack: null) -> ( localhost:9096 (id: 4 rack: null) -> ( localhost:9094 (id: 2 rack: null) -> ( localhost:9092 (id: 0 rack: null) -> (
You can see that broker 1 is back online.
Use Control Center to test rebalancing
The following sections describe how to remove a broker and monitor the progress of the rebalance using the Control Center. If you restart the broker, Self-Balancing redistributes the data again across all nodes.
Before continuing with this section, make sure you have installed and configured Control Center as described in (Optional) Install and configure Confluent Control Center.
To learn more about working with Self-Balancing on Control Center, see Self-balancing in the Control Center guide.
Verify status of brokers and topic data
Use Control Center to verify the current status of the deployment, including Self-Balancing settings, lead broker (controller), topic data, and number of brokers. For a local deployment, Control Center is available at http://localhost:9021/ in your web browser.
To verify where the controller is running, go to Control Center, select the cluster, and click Brokers. In this example, the controller is running on broker 0.
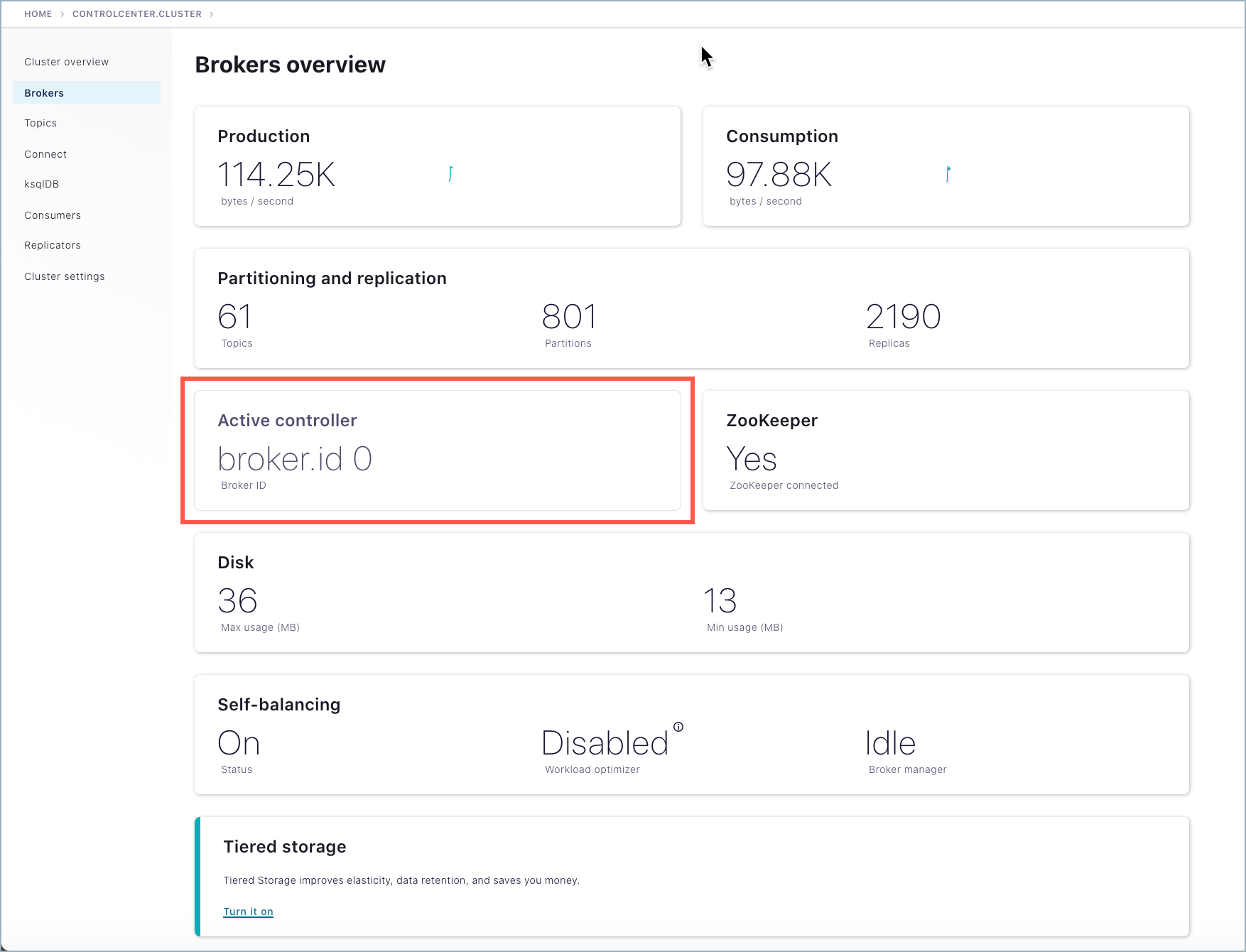
Tip
If broker metrics and the list of brokers are not showing on the Brokers overview page, verify that the Metrics Reporter is enabled, as described in Enable the Metrics Reporter for Control Center. If not, stop the brokers, edit the files, and restart.
To view the status of Self-Balancing broker tasks, click Brokers, then click the Self-Balancing card.
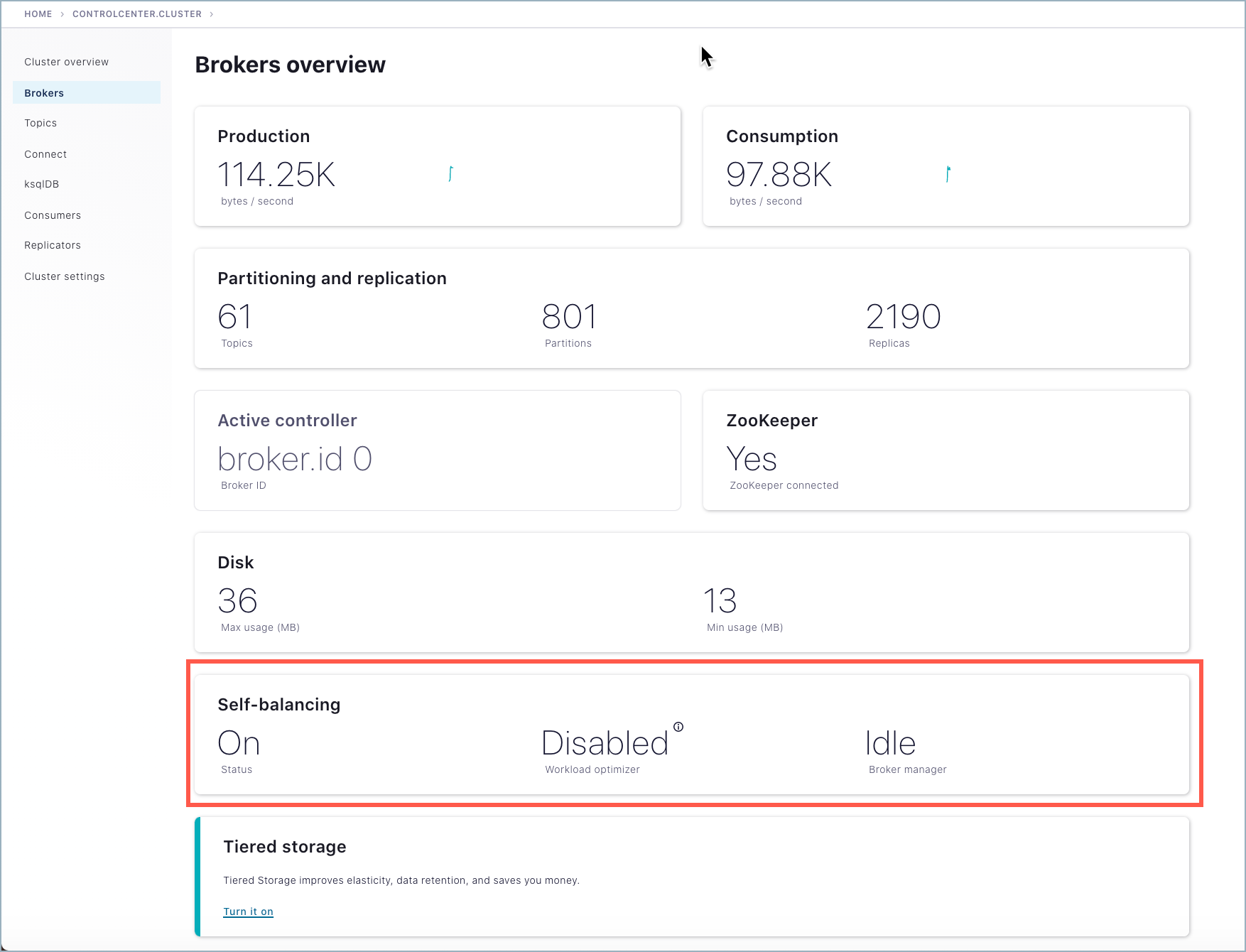
Tip
The Self-Balancing card on the Brokers overview indicates whether Self-Balancing is on, and also the status of the workload optimizer:
When Self-Balancing is set to trigger Only when brokers are added or removed (the default), the Self-Balancing card shows “Workload optimizer” as “Disabled”.
When Self-Balancing is set to trigger Anytime, the Self-Balancing card shows “Workload optimizer” as “Balanced” if no rebalancing is in progress, or one of the work-in-progress statuses during a rebalance.
To learn more, see Self-balancing in the Control Center guide.
Self-Balancing shows the task status for each broker in the cluster. (You’ll see this in action in the next sections on removing a broker and adding one back in.)
To view all brokers online, scroll to the bottom of the Brokers page to see the detailed broker list.

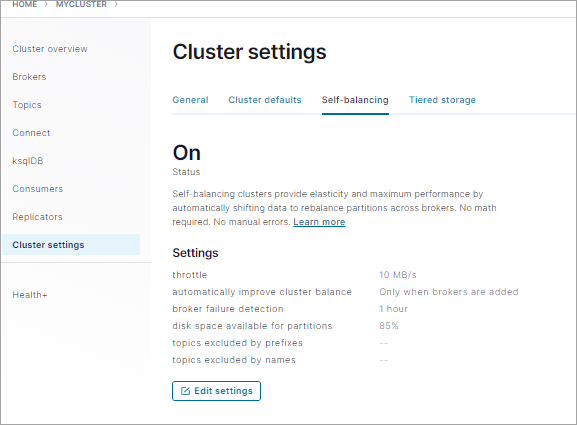
To verify that Self-Balancing is enabled, click Cluster settings > Self-balancing tab.
To view the generated messages for a topic, select Topics > my-sbc-test > Messages tab.
Remove a broker
With Self-Balancing enabled, and Confluent Platform up and running, delete a broker and monitor the rebalancing. For this example, make sure that you do not delete the controller, which in example is broker ID 0.
Important
In practice, you can remove a lead broker. It may cause a short delay in cluster balancing, which is why we suggest not doing so for this example. To learn more, What happens if the lead broker (controller) is removed or lost?.
If the broker you attempt to remove contains the only replica for a topic, the broker removal will fail. To learn more, see Limitations.
You can remove a broker in KRaft mode and the
UnregisterBrokercommand is automatically called. You should not call it manually.
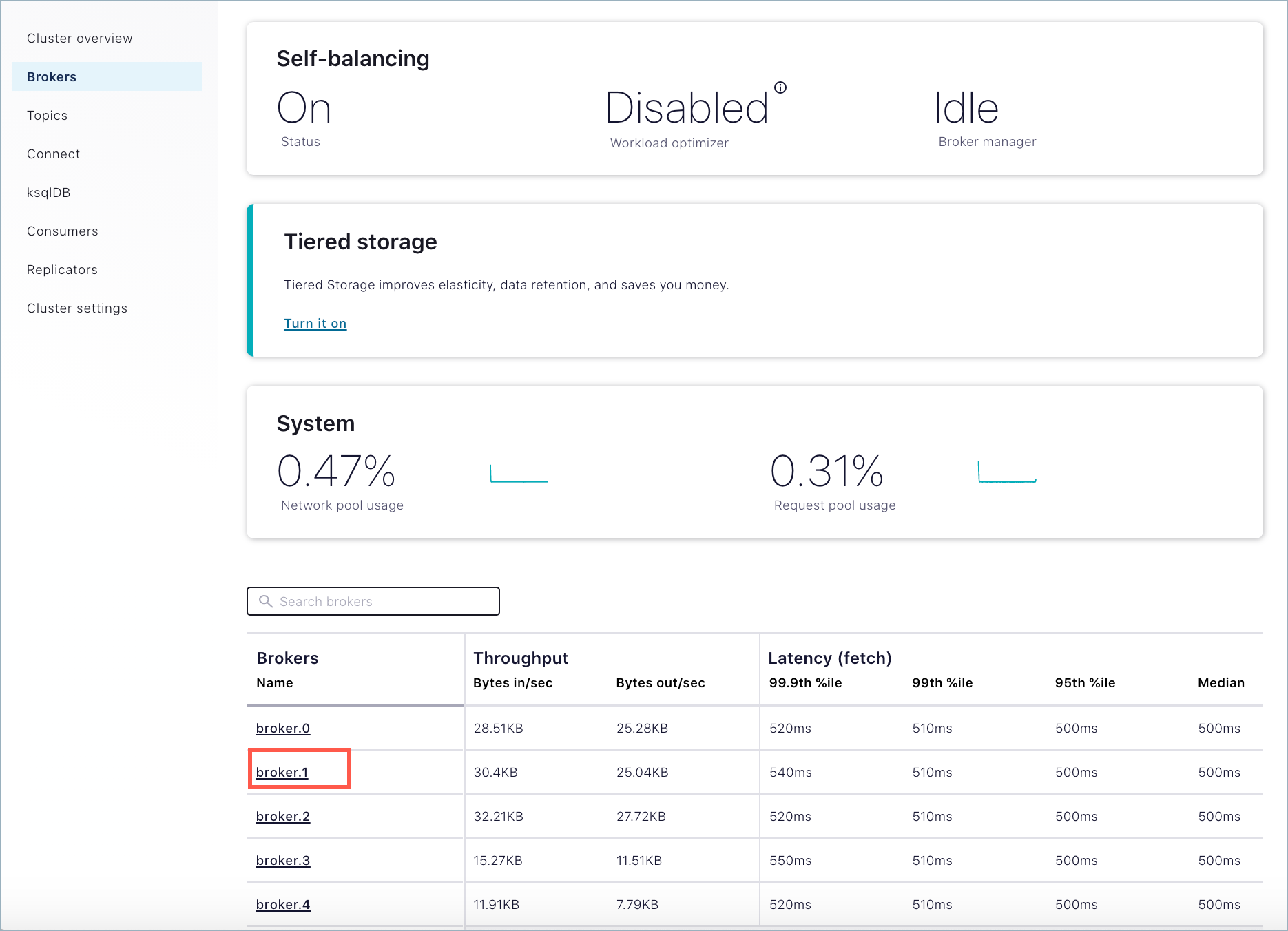
Remove a broker using the Control Center option on the Brokers overview page.
Select Brokers, scroll to the bottom of the Overview page to view the list of brokers currently online.
Click the broker you want to remove. (Clicking a broker drills down to broker details and also provides a remove option).
On the broker details Configuration tab, click Remove broker, then type REMOVE in the input field to verify that you want to take this action.
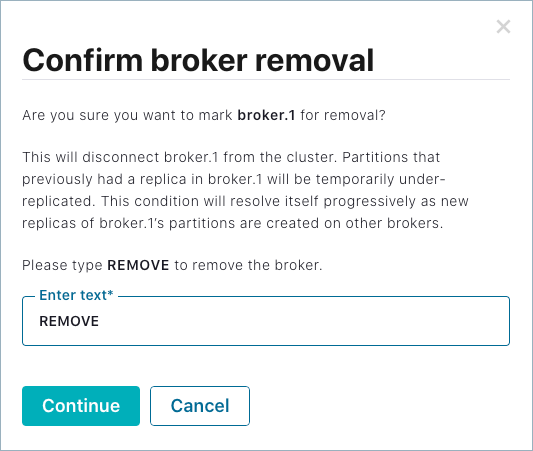
Click Continue to start the remove broker task.
Note
If you get an error message that broker removal failed due to insufficient metrics, Self-Balancing is still initializing, which can take up to 30 minutes. If this happens, retry broker removal after several minutes, and it should succeed.
Use the Control Center to monitor the rebalance.
On Control Center, click Brokers > Self-balancing to track the progress.
Self-Balancing shows the detailed status for each broker in the cluster. In this case, broker 1 shows an
in-progressstatus under Remove broker tasks.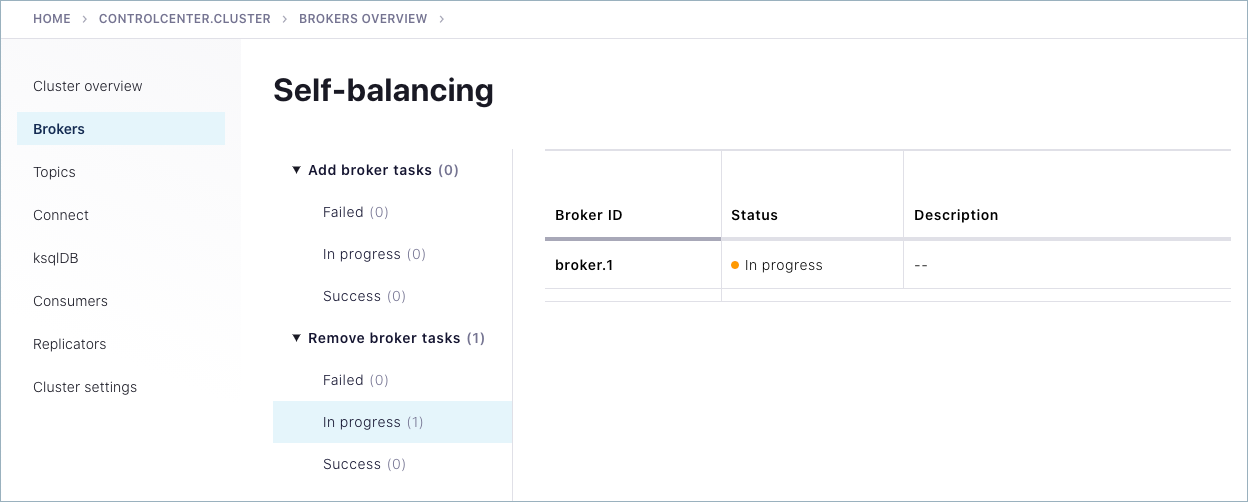
While the remove operation is in progress, the broker being removed shows a red “failed” indicator on the brokers list at the bottom of the Brokers overview page.
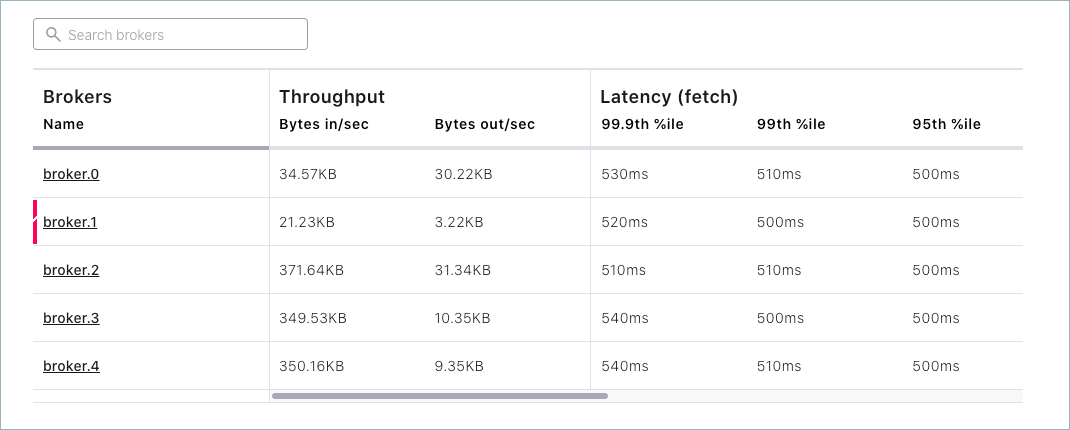
When the rebalance is complete, the Self-Balancing page shows that the broker was successfully removed:
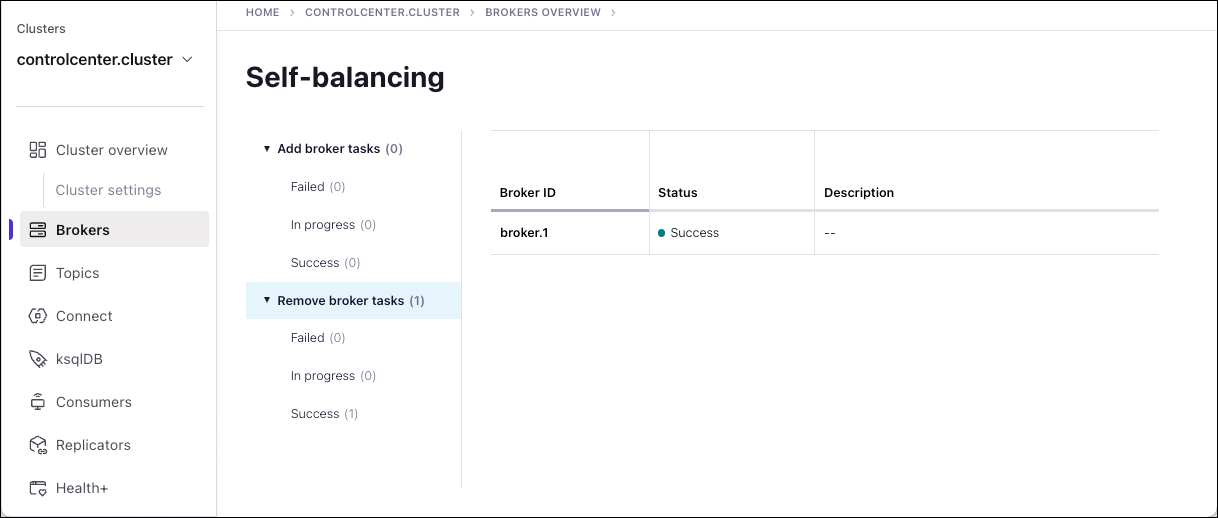
And the Brokers overview page will show only 4 brokers in the list: 0, 2, 3 and 4.
Add a broker (restart)
Restart the broker (for example broker 1) and watch the rebalance. (This provides an example of “adding a broker”, just using the same broker you removed to simplify the walkthrough.)
To restart a broker, you must use the command line. Return to the command window where you started broker 1. You should see that the broker has been stopped. Hit the up arrow on your keyboard, and then press return to rerun the same command you started this with originally:
kafka-server-start etc/kafka/server-1.propertiesSelf-Balancing acknowledges the command and provides feedback similar to the following.
[2020-06-26 17:45:44,986] INFO BROKER Aggregator rolled out 1 new windows, reset 1 windows, current window range [1593213000000, 1593219000000], abandon 0 samples. (com.linkedin.cruisecontrol.monitor.sampling.aggregator.MetricSampleAggregator) [2020-06-26 17:46:06,314] INFO DataBalancer: Scheduling DataBalanceEngine broker addition: [1] (io.confluent.databalancer.ConfluentDataBalanceEngine) [2020-06-26 17:46:06,314] INFO DataBalancer: Starting addBrokers call (io.confluent.databalancer.ConfluentDataBalanceEngine)
Use Control Center to monitor the progress of Self-Balancing (Brokers > Self-balancing).
For example, as the broker is being added back in, you should see an in-progress indicator under Add broker tasks.
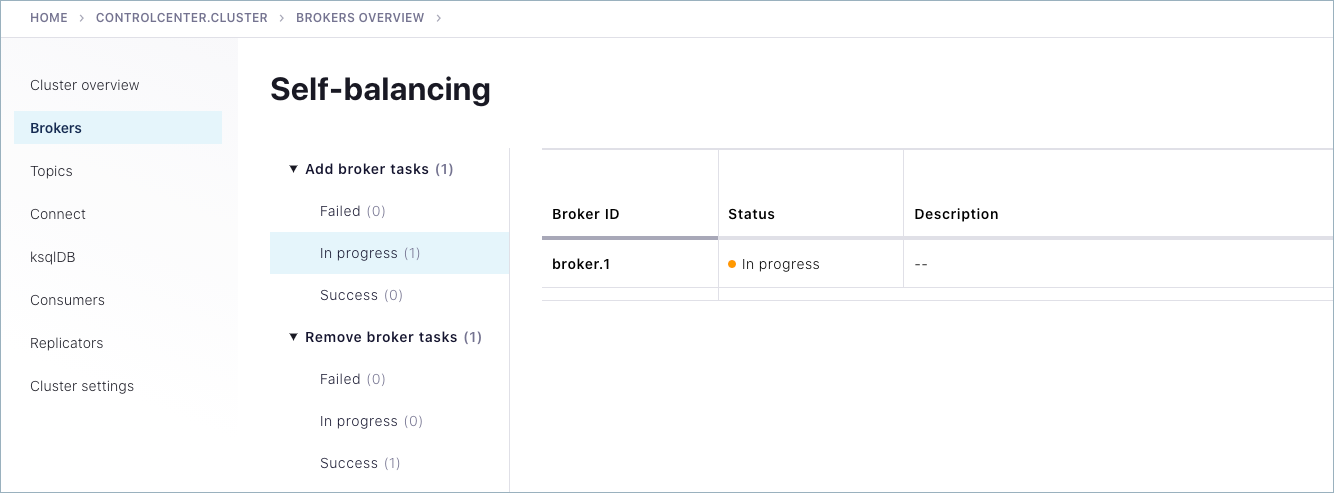
When the rebalance is complete, navigate to the broker list at the bottom of the Brokers page to verify that broker 1 is back online, for a total of five brokers.
Shutdown and cleanup tasks
Run the following shutdown and cleanup tasks.
Stop the
kafka-producer-perf-testwith Ctl-C in its respective command window.Stop the all of the other components with Ctl-C in their respective command windows, in reverse order in which you started them. For example, stop each of the brokers first, then the controller, then Control Center, and finally Prometheus.
Remove log directories from
/tmp.
(Optional) Running the other components
You can run configure and run additional components as a part of the Self-Balancing tests, if desired, but these are not integral to this tutorial.
If you want to run Connect, ksqlDB, or Schema Registry with Confluent Platform, do the following:
Edit the properties files for Connect, ksqlDB, or Schema Registry search and replace any
replication.factorvalues to either 2 or 3 (to work with your five broker cluster). Ifreplication.factorvalues are set to less than 2 or greater than 4, this will result in system topics with replication factors that prevent graceful broker removal with Self-Balancing.For example, if you want to run Connect, you could set replication factors in
$CONFLUENT_HOME/etc/kafka/connect-distributed.propertiesto a value of “2”:offset.storage.replication.factor=2config.storage.replication.factor=2status.storage.replication.factor=2
You could run this command to update replication configurations for Connect:
sed -i '' -e "s/replication.factor=1/replication.factor=2/g" $CONFLUENT_HOME/etc/kafka/connect-distributed.properties
In
$CONTROL_CENTER_HOME/etc/confluent-control-center/control-center-dev.properties, verify that the configurations for Kafka Connect, ksqlDB, and Schema Registry match the following settings to provide Control Center with the default advertised URLs for the component clusters:# A comma separated list of Connect host names confluent.controlcenter.connect.cluster=http://localhost:8083 # KSQL cluster URL confluent.controlcenter.ksql.ksqlDB.url=http://localhost:8088 # Schema Registry cluster URL confluent.controlcenter.schema.registry.url=http://localhost:8081
Start Prometheus, Control Center, and Confluent Platform as described in previous sections.
Start the optional components in separate windows.
(Optional) Kafka Connect for Confluent Platform
connect-distributed $CONFLUENT_HOME/etc/kafka/connect-distributed.properties
Optional) ksqlDB
ksql-server-start $CONFLUENT_HOME/etc/ksqldb/ksql-server.properties
(Optional) Schema Registry overview
schema-registry-start $CONFLUENT_HOME/etc/schema-registry/schema-registry.properties