
FAQ for Cluster Linking on Confluent Platform
How do I know the data was successfully copied to the destination and can be safely deleted from the source topic?
Each mirror topic has a metric called “Max Lag” which is the maximum number of messages any of its partitions are lagging by. You can monitor this through the Metrics API, Confluent Cloud Console, or Confluent Control Center.
If you need partition-level guarantees, you can use the REST API or the CLI to describe a mirror topic and see the exact offset that each partition has replicated up to. It will be called “Last Source Fetch Offset.” Anything before that offset in that partition has been replicated.
How can I throttle a Confluent Platform to Confluent Cloud cluster link to make the best use of my bandwidth?
On Confluent Cloud, throttles are not exposed, but rather the product intelligently throttles itself to maximize your bandwidth.
For on-premises Confluent Platform, you can use the regular client throttles that Kafka supports to throttle the principal you create for the cluster link. You should create a principal for the cluster link and create source cluster credentials that you give the cluster link when you create it.
Will adding a cluster link result in throttling consumers on the source cluster?
Possibly, yes; adding a cluster link is similar to adding a new consumer with auto.offset.reset=earliest. As such, the cluster link can cause other consumers to be throttled if it pushes the total consumption above your cluster’s consume throughput quota. This depends on how much throughput your cluster link can achieve, how much data you are trying to mirror, and how much extra consume capacity you have.
Keep in mind, if you are mirroring existing topic data, the cluster link will have a “burst” of consume at the beginning to get this historical data. After it catches up, the consume rates should go down to match the production values into your source topics (assuming your cluster link can handle the production throughput).
Will adding a cluster link cause throttling of existing producers on the destination cluster?
No, it shouldn’t. Kafka client producers are prioritized over Cluster Linking destination writes.
How is the consumer offset sync accomplished?
Consumer offset sync does not mirror the internal topic _consumer_offsets, but rather uses code for the controller nodes to sync the offsets on a frequency that you can configure. To learn more, see “Syncing consumer group offsets” in Mirror Topics on Confluent Cloud and Mirror Topics on Confluent Platform .
Can I modify consumer group filters on-the-fly?
Yes, you can modify the consumer group exclude or include filters without having to stop and restart the cluster link. However, if you add consumer groups to the exclude list that were already synced, then you will need to manually delete them on the mirrored destination if you want them removed immediately. Cluster Linking does not delete consumer groups. In Confluent Cloud, consumer offsets are retained for 7 days (and automatically deleted after 7 days). To learn more, see “Syncing consumer group offsets” in Mirror Topics on Confluent Cloud and Mirror Topics on Confluent Platform .
How do I create a cluster link?
You can create a cluster link using the Confluent Cloud Console, the Confluent Cloud REST API, the Confluent CLI, the Confluent Platform AdminClient API, or Confluent for Kubernetes. To learn more, see the Cluster Linking Quick Start.
Which clusters can create cluster links?
See the supported cluster combinations described in Supported Cluster Types.
Can I prioritize one link over another?
Yes, with a caveat. You can use different client quotas on the link principal; and, thereby, give more egress bandwidth to one link compared to another if they read from the same source cluster.
You cannot, however, control this from the destination cluster, so if those links are reading from different source clusters they would likely compete for the destination cluster ingress bandwidth.
How do I create a mirror topic?
You can create a specific mirror topic using the Confluent Cloud Console, the Confluent Cloud REST API, the Confluent CLI, the Confluent Platform AdminClient API, or Confluent for Kubernetes. Alternatively, you can configure your cluster link to automatically create mirror topics that match certain prefixes. To learn more, see Mirror Topic Creation.
Can I prevent certain topics from being mirrored by a cluster link?
Yes, you can. You have several options:
If your cluster link is using
auto-create mirror topics, you can exclude those topics (or topic prefixes) from the cluster link’s auto-create mirror topic filters.If you want to make sure those topics cannot be mirrored by the cluster link under any circumstances, then do not grant authorization (via RBAC or ACLs) to the cluster link’s principal on those topics. For example, you could:
Simply not give the cluster link the role / ACLs needed for those topics (for example, give it the role for topics starting with prefix
publicbut not for any starting with prefixprivate)Give the cluster link’s principal an ACL with
permission=denyfor reading those topics. This way, no matter what other ACLs or roles the cluster link has, it will never be able to mirror those topics.
To learn more, see the Cluster Linking security sections in Confluent Cloud and Confluent Platform.
Can I override a topic configuration when using auto-create mirror topics?
Yes, to override a topic configuration when using auto-create mirror topics, you have two options:
Change the topic configuration after the mirror topic is automatically created.
Use the CLI or API to manually create the mirror topic, and override the configuration. Even if a topic matches the auto-create mirror topic filters, it can still be manually created as a mirror topic before the cluster link creates it automatically. Auto-create mirror topics runs once every 5 minutes, so the mirror topic can be manually created soon after the cluster link is created or soon after the source topic is created.
To learn more, see the auto-create mirror topics sections in Confluent Cloud and Confluent Platform.
Can I use Cluster Linking without the traffic going over the public internet?
Some customers want to use a public Confluent Cloud cluster, but do not want the Cluster Linking traffic in/out of it to traverse the public internet.
Today, there is no way to give a Confluent Cloud cluster both a public and a private bootstrap server. Therefore, any traffic that goes to the public Confluent Cloud cluster will use its public bootstrap server, regardless of which method is used (Cluster Linking, Replicator, consumer/producers, and so on).
On Amazon AWS and Microsoft Azure, traffic between two endpoints that are both on the same cloud service provider (CSP) (for example, AWS in us-west-2 to AWS in us-east-1, or Azure UK South to Azure UK West) always stays on that CSP’s backbone. So, if the two clusters you are using with Cluster Linking are on the same cloud, the traffic will stay on that CSP’s backbone and will not cross over to the public internet. See the guarantees provided in the Amazon AWS documentation and the Microsoft Azure documentation.
Does Schema Linking have the same limitations as Cluster Linking for private networking and cross-region?
No, Schema Linking does not have the same limitations as Cluster Linking for private networking. Schema Linking can use private endpoints, and is available between any two Confluent Cloud Schema Registry environments, regardless of the Kafka clusters’ network. For more information, see Enable Private Networking with Schema Registry.
I need RPO==0 (guarantee of no data loss after a failover) in Confluent Cloud. What can I do?
Cluster Linking has “asynchronous replication”, meaning it does not have an RPO==0 (also known as “synchronous”) option out-of-the-box. Achieving RPO==0 with asynchronous replication is architecturally complex. It requires producers to have a durable, multi-region cache of their most recent data. After a failover, the producers need to replay the data from the cache. This will result in duplicate events in the underlying topics, which your consumers need to tolerate.
If I want to join two topics from different clusters in ksqlDB, how can Cluster Linking help me?
A ksqlDB application can only interact with one Apache Kafka® cluster. Cluster Linking can be used to bring a topic from another cluster into a local copy on your cluster. Then, you can use ksqlDB to join the local copy (the “mirror topic”) with the second topic.
Does Cluster Linking work with mTLS?
For Confluent Platform, yes, you can use mTLS. (See Mutual TLS (mTLS) in the Cluster Linking on Confluent Platform documentation.)
On Confluent Cloud, it depends:
For Confluent Cloud to Confluent Cloud clusters: no, TLS and SASL are used under the hood.
For data coming into Confluent Cloud from open-source Apache Kafka®: yes, you can use mTLS.
For data coming into Confluent Cloud from Confluent Platform: you can use either mTLS or source-initiated cluster links with TLS+SASL. mTLS can be used for source-initiated cluster links only in hybrid scenarios where the source cluster is Confluent Platform and destination cluster is a Dedicated Confluent Cloud cluster.
How does Schema Registry multi-region disaster recovery (DR) work in Confluent Cloud?
Confluent Cloud Schema Registry is a three node cluster spanning three different zones within a region (multi-zone), meaning it can tolerate two node failures in that region. For multi-region DR, you can use Schema Linking to replicate and keep in sync schemas across two Schema Registry clusters in different regions.
How can I automatically failover Kafka clients?
On Confluent Cloud: A detailed solution for how to failover clients as quickly as possible will be published as a whitepaper.
On Confluent Platform, customers have more control than those on Confluent Cloud. This gives you an additional option:
Use a Domain Name System (DNS) service (such as Amazon Route 53) to direct Kafka clients to the “active” cluster. In this scenario, the bootstrap server points to a URL, and you update the DNS to have that URL resolve to the “active” cluster. Kafka clients do not need to change their bootstrap server on a failover.
Use the same authentication information on both clusters; so Kafka clients do not need to change their security configuration on a failover.
So, to failover clients, you simply change the DNS. When the clients start up, they will bootstrap to the “active” cluster.
The only thing to keep in mind here is that bootstrapping only happens when a client starts up. (This is an advantage of Multi-Region Clusters, since it avoids the re-bootstrapping process.) If you have any clients that are still running and survived the outage, they will need to have a way to restart in order to failover. This is less of a concern in Confluent Cloud, for two reasons:
Often a restart can be called by the Operator, if all clients are running on K8’s (Kubernetes) clusters.
On Confluent Cloud, the outage is a cloud service provider (CSP) outage in a given region. Let’s say your clients are all in the same region as the cluster they point to. For example, for an Amazon AWS cluster, suppose all clients are also on AWS and in the same region as the cluster. If there is an AWS outage in that region, no clients will survive the outage; they will all need to be restarted anyways, by definition.
How does Cluster Linking optimize network bandwidth and performance in Confluent Cloud?
Cluster Linking is a direct connection between two clusters, and retains the compression set on any topics and messages that it mirrors. This is an improvement over both Confluent Replicator and MirrorMaker 2, which require a second network hop to write the data, and do not retain compression.
For customers using Cluster Linking on Confluent Cloud, which is a fully managed service, you only need to care about:
Total bytes sent, as this is what Confluent bills on.
Throughput that can be achieved. Cluster Linking uses the throughput allocated to the clusters (50MB/s in and 150MB/s out per CKU) and is capable of maxing out that throughput as needed, even in high latency scenarios like between cloud providers or regions that are far apart from each other.
How do I perform a failover on a cluster link used primarily for data sharing?
This question describes a scenario where you are using a cluster link to share data between two clusters, but then need to perform a failover from one of the clusters to its disaster recovery (DR) cluster,
Question
For example, suppose you are data sharing between two clusters, one in Microsoft Azure and the other on Amazon AWS, and each of these clusters has a DR cluster in another region within same cloud provider.
What will the solution look like in case of a DR scenario, when a DR cluster is used as primary?
How will this affect the data sharing between two cloud providers using Cluster Linking across the clusters?
If, for example, the primary cluster goes down in Azure, and you must create new links from AWS to the DR cluster in Azure (the new primary cluster in Azure) then how do you handle the mirror topics that are originally from AWS in the new primary cluster in Azure? Can the new link reuse the existing mirror topics to stream data from the AWS topics to them? If you convert those to normal topics then those topic names already exist in the Azure cluster and you cannot create new mirror topics with same name.
Answer
If you want to resume the mirroring from AWS to the Azure DR, then you’d need to:
Store a copy of the consumer offsets for those topics on the Azure DR cluster.
Delete those topics on the Azure DR cluster (this also deletes the consumer offsets).
Using a cluster link from AWS production to the Azure DR, and recreate those topics on the Azure DR cluster, as mirror topics from AWS.
Alternatively, if your consumers can stand large numbers of duplicates (a) or can stand to miss some messages (b), then you do not need to mirror the AWS topics from Azure Production to Azure DR. Instead, when you failover, simply create the AWS topics on the Azure production cluster, and set your consumers to earliest (a) or latest (b).
Does Cluster Linking support compacted topics?
Yes, Cluster Linking works with compacted topics; which are mirrored as such from source to destination.
Compacted topics are configured to retain only the newest record for each key on a topic, regardless of retention period expiration on the message. This reduces the storage requirements for a topic and supports log compaction. This can be configured when you create a topic; for example, kafka-topics --topic topic_name --bootstrap-server localhost:9092 --config "cleanup.policy=compact" --create. The log can be configured as log.cleanup.policy=compact in $CONFLUENT_HOME/etc/kafka/server.properties.
Does Cluster Linking support bidirectional links between two clusters?
Yes, bidirectional links between two clusters is possible as long as you are mirroring different topics. For a specific topic, only unidirectional linking is supported. To learn more, see Mirror Topics .
What is the difference between unidirectional (source-initiated) and bidirectional (source-initiated) links?
With a unidirectional source-initiated link, one cluster is designated as source and the other as destination. The source cluster initiates connections to the destination. Mirror topics can only be created on the destination cluster; that is, mirroring is one-way.
With bidirectional links, either cluster can be the source or destination. Mirror topics can be created on either cluster, so you can mirror in either direction. You can configure either cluster to initiate connections. If you configure one link as inbound and other as outbound, then connectivity is similar to source initiated links. If you configure both links as outbound, connectivity is similar to two destination-initiated links. In fact, everything that can be achieved with a source-initiated link can be achieved via a bidirectional link which is why the latter is always recommended.
Data flow direction is different, since data flow is in a single direction for unidirectional link and in both directions for bidirectional links. Communication initiation direction can be configured to be the same by configuring one link as inbound and the other as outbound.
Configuration approach is similar.
On bidirectional links, either cluster can be the destination and host mirrors. Failback only works with bi-directional links since mirroring direction is reversed during failback.
As a best practice, use bidirectional links over source-initiated links because they support failback. There are no features that unidirectional, source-initiated links support that cannot be performed using bidirectional links.
On a bidirectional, source-initiated link, the INBOUND link must be created first.
For bidirectional links where one side is OUTBOUND and the other is INBOUND, the INBOUND side must be created first.
To learn more, see topics related to advanced options for bidirectional Cluster Linking.
Does Cluster Linking support repartitioning or renaming of topics?
Cluster Linking preserves the same number of partitions on any topics it mirrors. It also keeps the topic name the same, though you can optionally add a prefix before the name.
However, you can repartition or rename topics as a part of a migration. Some manual steps are required. To learn more, see Repartitioning and renaming topics in a migration for options to accomplish this.
Can Cluster Linking create circular dependencies? How can I prevent infinite loops?
No, Cluster Linking cannot create a circular dependency or infinite loop. Confluent has taken care when designing it to prevent this. To understand why Cluster Linking cannot create an infinite loop, there are several situations to consider:
Can data be replicated in an infinite loop?
Only a cluster link can write into a mirror topic.
Mirror topics are one-to-one (1:1)–only data from one source topic can go into a mirror topic.
Therefore, it is impossible for Cluster Linking to create an infinite loop of the data, because Cluster Linking cannot take data and put it into the source topic that is producing data.
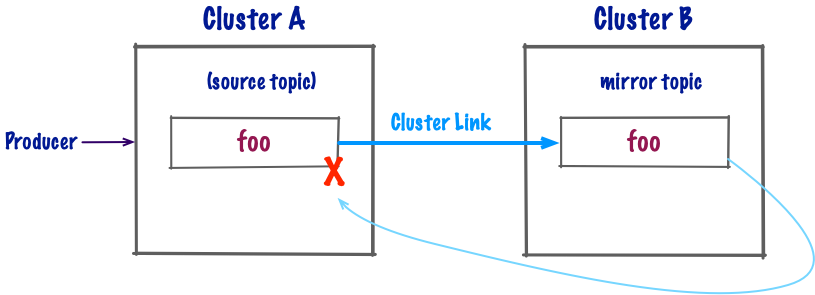
Can infinite mirror topics be created?
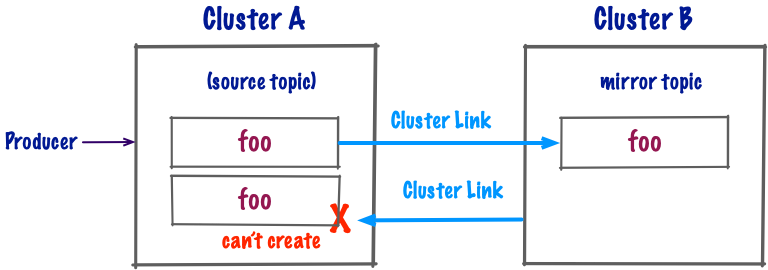
If you are not using cluster link prefixes, then this is not possible because mirror topics always keep the name as their source topic. So as soon as the first mirror topic is created, you will not be able to create more topics of that name.
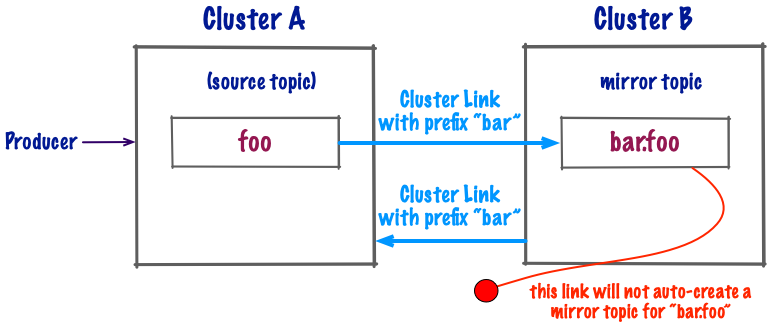
If you are using cluster link prefixes, then it would be theoretically possible to create infinite mirror topics if “auto-create mirror topics” is also enabled. For that reason, Confluent has disabled the ability to auto-create a mirror topic from another mirror topic if cluster linking prefixes are enabled. This prevents prefixed mirror topics from being created automatically in an infinite loop.
To learn more about auto-create mirror topics, see the associated sections in Confluent Cloud and Confluent Platform.