
PagerDuty Sink Connector for Confluent Platform [Deprecated]
Important
This connector is deprecated and will reach its end of life (EOL) on the Confluent Platform 7.9 end of support (EOS) date. Confluent recommends migrating to HTTP Sink V1 connector before the EOL date. For more information, see Connector support lifecycle policy.
The Kafka Connect PagerDuty Sink connector is used to read records from an Apache Kafka® topic and create PagerDuty incidents.
Features
The PagerDuty Sink connector offers the following features:
At least once delivery
The connector creates a PagerDuty incident for each record in Kafka topic. However, duplicates are still possible to occur when failure, rescheduling or reconfiguration happens. This semantics is followed when behavior.on.error is set to fail mode. In case of log and ignore modes, the connector promises at-most semantics.
Dead Letter Queue
This connector supports the Dead Letter Queue (DLQ) functionality. For information about accessing and using the DLQ, see Confluent Platform Dead Letter Queue.
Multiple tasks
The PagerDuty Sink connector supports running one or more tasks. You can specify the number of tasks in the tasks.max configuration parameter. This can lead to performance gains when multiple files need to be parsed.
Automatic retries
The PagerDuty Sink connector may experience network failures while connecting to the PagerDuty endpoint. The connector will automatically retry with exponential backoff to create incidents. The property pagerduty.max.retry.time.seconds controls the maximum time until which the connector will retry creating the incidents.
HTTPS proxy
The connector can connect to PagerDuty using an HTTPS proxy server.
CSFLE (Client-side Field level encryption)
This connector supports the CSFLE functionality. For more information, see Manage CSFLE.
License
You can use this connector for a 30-day trial period without a license key.
After 30 days, you must purchase a connector subscription which includes Confluent enterprise license keys to subscribers, along with enterprise-level support for Confluent Platform and your connectors. If you are a subscriber, you can contact Confluent Support for more information.
For license properties, see Confluent Platform license. For information about the license topic, see License topic configuration.
Configuration Properties
For a complete list of configuration properties for this connector, see Configuration Reference for PagerDuty Sink Connector for Confluent Platform.
For an example of how to get Kafka Connect connected to Confluent Cloud, see Connect Self-Managed Kafka Connect to Confluent Cloud.
Install PagerDuty Sink Connector
You can install this connector by using the confluent connect plugin install command, or by manually downloading the ZIP file.
Prerequisites
You must install the connector on every machine where Connect will run.
Kafka Broker: Confluent Platform 3.3.0 or later, or Kafka 0.11.0 or later.
Connect: Confluent Platform 4.0.0 or later, or Kafka 1.0.0 or later.
Java 1.8.
Team tier PagerDuty account.
An installation of the latest (
latest) connector version.To install the
latestconnector version, navigate to your Confluent Platform installation directory and run the following command:confluent connect plugin install confluentinc/kafka-connect-pagerduty:latest
You can install a specific version by replacing
latestwith a version number as shown in the following example:confluent connect plugin install confluentinc/kafka-connect-pagerduty:1.0.7
Install the connector manually
Download and extract the ZIP file for your connector and then follow the manual connector installation instructions.
Quick Start
The quick start guide uses PagerDuty Sink connector to consume records from a Kafka topic and create incidents in PagerDuty.
Get service ID
If you have a service already created in PagerDuty, you can find the Service ID by navigating to Configuration > Services. Select your service. The Service ID is in the URL bar. For example: https://connector-test.pagerduty.com/service-directory/<serviceId>.
You can add a service in PagerDuty. When you add a service, select Use our API directly as the Integration type. After the service is added, you will be redirected to the URL where you can copy the Service ID.
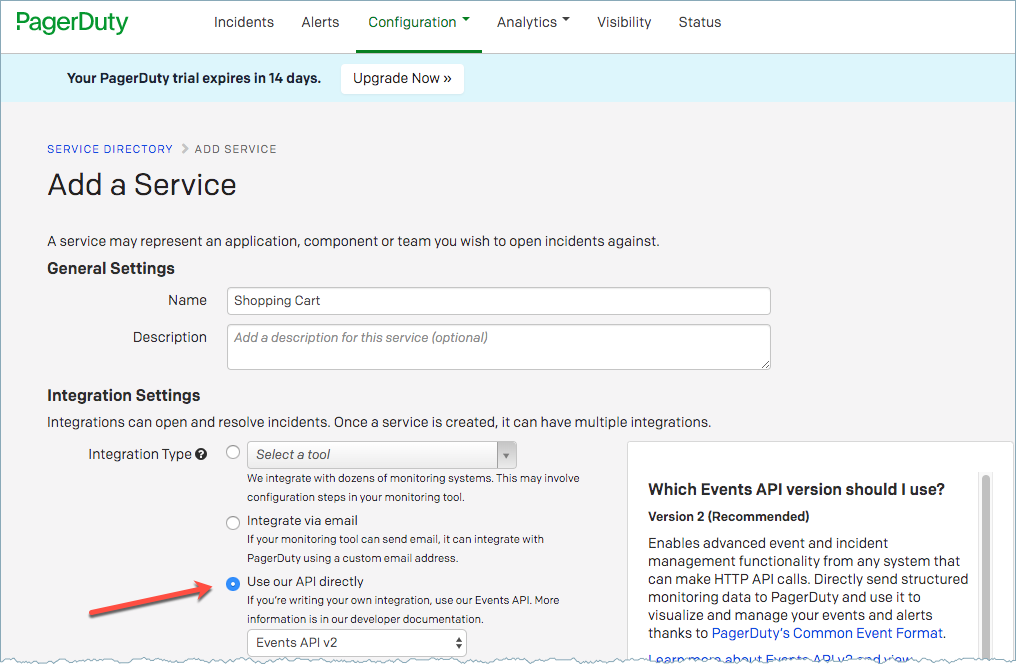
PagerDuty integration setting
Start Confluent
Start the Confluent services using the following Confluent CLI command:
confluent local start
Important
Do not use the Confluent CLI in production environments.
Property-based example
Create a configuration file pagerduty-sink.properties with the following content. This file should be placed inside the Confluent Platform installation directory. This configuration is used typically along with standalone workers.
name=pagerduty-sink-connector
topics=incidents
connector.class=io.confluent.connect.pagerduty.PagerDutySinkConnector
tasks.max=1
pagerduty.api.key=****
behavior.on.error=fail
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=io.confluent.connect.avro.AvroConverter
value.converter.schema.registry.url=http://localhost:8081
confluent.topic.bootstrap.servers=localhost:9092
confluent.topic.replication.factor=1
confluent.license=
reporter.bootstrap.servers=localhost:9092
reporter.result.topic.replication.factor=1
reporter.error.topic.replication.factor=1
Note
For details about using this connector with Kafka Connect Reporter, see Connect Reporter.
Run the connector with this configuration.
confluent local load pagerduty-sink-connector --config pagerduty-sink.properties
The output should resemble:
{
"name":"pagerduty-sink-connector",
"config":{
"topics":"incidents",
"tasks.max":"1",
"connector.class":"io.confluent.connect.pagerduty.PagerDutySinkConnector",
"pagerduty.api.key":"****",
"behavior.on.error":"fail",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter":"io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url":"http://localhost:8081",
"confluent.topic.bootstrap.servers":"localhost:9092",
"confluent.topic.replication.factor":"1",
"reporter.bootstrap.servers": "localhost:9092",
"reporter.result.topic.replication.factor":"1",
"reporter.error.topic.replication.factor":"1"
"name":"pagerduty-sink-connector"
},
"tasks":[
{
"connector":"pagerduty-sink-connector",
"task":0
}
],
"type":"sink"
}
Note
For details about using this connector with Kafka Connect Reporter, see Connect Reporter.
Confirm that the connector is in a RUNNING state.
confluent local status pagerduty-sink-connector
The output should resemble:
{
"name":"pagerduty-sink-connector",
"connector":{
"state":"RUNNING",
"worker_id":"127.0.1.1:8083"
},
"tasks":[
{
"id":0,
"state":"RUNNING",
"worker_id":"127.0.1.1:8083"
}
],
"type":"sink"
}
REST-based example
Use this setting with distributed workers. Write the following JSON to config.json, configure all of the required values, and use the following command to post the configuration to one of the distributed connect workers. Check here for more information about the Kafka Connect Kafka Connect REST Interface
{
"name" : "pagerduty-sink-connector",
"config" : {
"topics":"incidents",
"connector.class":"io.confluent.connect.pagerduty.PagerDutySinkConnector",
"tasks.max" : "1",
"pagerduty.api.key":"****",
"behavior.on.error":"fail",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter":"io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url":"http://localhost:8081",
"confluent.topic.bootstrap.servers":"localhost:9092",
"confluent.topic.replication.factor":"1",
"confluent.license":" Omit to enable trial mode ",
"reporter.bootstrap.servers": "localhost:9092",
"reporter.result.topic.replication.factor":"1",
"reporter.error.topic.replication.factor":"1"
}
}
Note
Change the confluent.topic.bootstrap.servers property to include your broker address(es) and change the confluent.topic.replication.factor to 3 for staging or production use.
Use curl to post a configuration to one of the Kafka Connect workers. Change http://localhost:8083/ to the endpoint of one of your Kafka Connect worker(s).
curl -sS -X POST -H 'Content-Type: application/json' --data @config.json http://localhost:8083/connectors
Use the following command to update the configuration of existing connector.
curl -s -X PUT -H 'Content-Type: application/json' --data @config.json http://localhost:8083/connectors/pagerduty-sink-connector/config
Confirm that the connector is in a RUNNING state by running the following command:
curl http://localhost:8083/connectors/pagerduty-sink-connector/status | jq
The output should resemble:
{
"name":"pagerduty-sink-connector",
"connector":{
"state":"RUNNING",
"worker_id":"127.0.1.1:8083"
},
"tasks":[
{
"id":0,
"state":"RUNNING",
"worker_id":"127.0.1.1:8083"
}
],
"type":"sink"
}
To produce Avro data to Kafka topic: incidents, use the following command.
./bin/kafka-avro-console-producer --broker-list localhost:9092 --topic incidents --property value.schema='{"type":"record","name":"details","fields":[{"name":"fromEmail","type":"string"}, {"name":"serviceId","type":"string"},{"name":"incidentTitle","type":"string"}]}'
While the console is waiting for the input, use the following three records and paste each of them on the console.
{"fromEmail":"user1@abc.com", "serviceId":"<your-service-id>", "incidentTitle":"Incident Title x 0"}
{"fromEmail":"user2@abc.com", "serviceId":"<your-service-id>", "incidentTitle":"Incident Title x 1"}
{"fromEmail":"user3@abc.com", "serviceId":"<your-service-id>", "incidentTitle":"Incident Title x 2"}
Note
The fromEmail in the records should be of registered PagerDuty user to allow creation of incidents
Finally, check the PagerDuty incident dashboard to see the newly created incidents.
Record schema
The PagerDuty Sink connector expects the value of records in Kafka topic to be either of type JSON String or Avro. In either case, the value should adhere to the following conditions:
Must include
fromEmail,serviceIdandincidentTitlefields in the value of the Kafka record.The
body,urgency,escalationPolicyandpriorityfields are optional.
Following is the value schema for Pagerduty incident:
{
"name":"PagerdutyValueSchema",
"type":"record",
"fields":[
{
"name":"fromEmail",
"type":"string"
},
{
"name":"serviceId",
"type":"string"
},
{
"name":"incidentTitle",
"type":"string"
},
{
"name":"priorityId",
"type":"string",
"isOptional":true
},
{
"name":"urgency",
"type":"string",
"isOptional":true
},
{
"name":"bodyDetails",
"type":"string",
"isOptional":true
},
{
"name":"escalationPolicyId",
"type":"string",
"isOptional":true
}
]
}