SFTP Sink Connector for Confluent Platform
You can use the Kafka Connect SFTP Sink connector to export data from Apache Kafka® topics to files in an SFTP directory. Supported formats are CSV/TSV, Avro, JSON and Parquet.
The SFTP Sink Connector periodically polls data from Kafka and in turn writes it to the SFTP files. A partitioner is used to split the data of every Kafka partition into chunks. Each chunk of data is represented as an object. The key name encodes the topic, the Kafka partition, and the start offset of this data chunk.
If no partitioner is specified in the configuration, the default partitioner which preserves Kafka partitioning is used. The size of each data chunk is determined by the number of records written to SFTP files and by schema compatibility.
Features
The SFTP Sink Connector includes the following features:
Exactly once delivery
Records that are exported using a deterministic partitioner are delivered with exactly-once semantics regardless of the eventual consistency of SFTP. To learn more, see Exactly-once delivery on top of eventual consistency.
Dead Letter Queue
This connector supports the Dead Letter Queue (DLQ) functionality. For information about accessing and using the DLQ, see Confluent Platform Dead Letter Queue.
Multiple tasks
The SFTP Sink Connector supports running one or more tasks. You can specify the number of tasks in the tasks.max configuration parameter. This can lead to performance gains when multiple files need to be parsed.
Pluggable data format with or without schema
Out of the box, the connector supports writing data to SFTP files in Avro, CSV/TSV, JSON and parquet formats. Besides records with schema, the connector supports exporting plain JSON records without schema in text files, one record per-line. In general, the connector may accept any format that provides an implementation of the Format interface.
Pluggable partitioner
The connector comes out of the box with partitioners that support default partitioning based on Kafka partitions, field partitioning, and time-based partitioning in days or hours. You may implement your own partitioners by extending the Partitioner class. Additionally, you can customize time based partitioning by extending the TimeBasedPartitioner class.
Schema Evolution: Schema evolution only works if the records are generated with the default naming strategy, which is
TopicNameStrategy. An error may occur if other naming strategies are used. This is because records are not compatible with each other.schema.compatibilityshould be set toNONEif other naming strategies are used. This may result in small object files because the sink connector creates a new file every time the schema ID changes between records. See Subject Name Strategy for more information about naming strategies.
Client-side encryption
This connector supports Client-Side Field Level Encryption (CSFLE) and Client-Side Payload Encryption (CSPE). For more information, see Manage Client-Side Encryption.
Limitations
The SFTP Sink connector does not support the RegexRouter SMT.
License
You can use this connector for a 30-day trial period without a license key.
After 30 days, you must purchase a connector subscription which includes Confluent enterprise license keys to subscribers, along with enterprise-level support for Confluent Platform and your connectors. If you are a subscriber, you can contact Confluent Support for more information.
See Confluent Platform license for license properties and License topic configuration for information about the license topic.
Configuration Properties
For a complete list of configuration properties for the sink connector, see Configuration Reference for SFTP Sink Connector for Confluent Platform.
For an example of how to get Kafka Connect connected to Confluent Cloud, see Connect Self-Managed Kafka Connect to Confluent Cloud.
Install the SFTP Sink Connector
You can install this connector by using the confluent connect plugin install command, or by manually downloading the ZIP file.
Prerequisites
You must install the connector on every machine where Connect will run.
If you want to install the connector using Confluent Marketplace, you must install the Confluent Hub Client. This is installed by default with Confluent Enterprise.
Kafka Broker: Confluent Platform 3.3.0 or later, or Kafka 0.11.0 or later.
Connect: Confluent Platform 4.0.0 or later, or Kafka 1.0.0 or later.
Java 1.8.
Install the connector using the Confluent CLI
To install the latest connector version using Confluent Hub Client, navigate to your Confluent Platform installation directory and run the following command:
confluent connect plugin install confluentinc/kafka-connect-sftp:latest
You can install a specific version by replacing latest with a version number as shown in the following example:
confluent connect plugin install confluentinc/kafka-connect-sftp:3.2.0
Install the connector manually
Download and extract the ZIP file for your connector and then follow the manual connector installation instructions.
Quick Start
This quick start uses the SFTP Sink Connector to export data produced by the Avro console producer to SFTP directory.
First, start all the necessary services using Confluent CLI.
Tip
If not already in your PATH, add Confluent’s bin directory by running: export PATH=<path-to-confluent>/bin:$PATH
confluent local start
Every service will start in order, printing a message with its status:
Starting Zookeeper
Zookeeper is [UP]
Starting Kafka
Kafka is [UP]
Starting Schema Registry
Schema Registry is [UP]
Starting Kafka REST
Kafka REST is [UP]
Starting Connect
Connect is [UP]
Starting KSQL Server
KSQL Server is [UP]
Starting Control Center
Control Center is [UP]
Next, start the Avro console producer to import a few records to Kafka:
./bin/kafka-avro-console-producer --broker-list localhost:9092 --topic test_sftp_sink \
--property value.schema='{"type":"record","name":"myrecord","fields":[{"name":"f1","type":"string"}]}'
In the console producer, enter the following:
{"f1": "value1"}
{"f1": "value2"}
{"f1": "value3"}
The three records entered are published to the Kafka topic test_sftp_sink in Avro format.
Before starting the connector, ensure the configurations in etc/kafka-connect-sftp/quickstart-sftp.properties are properly set to your configurations of SFTP (for example, sftp.hostname must point to the proper SFTP host). Then, start connector by loading its configuration with the following command:
Caution
You must include a double dash (--) between the connector name and your flag. For more information, see this post.
confluent local load sftp-sink --config etc/kafka-connect-sftp/quickstart-sftp.properties
{
"name": "sftp-sink",
"config": {
"topics": "test_sftp_sink",
"tasks.max": "1",
"connector.class": "io.confluent.connect.sftp.SftpSinkConnector",
"confluent.topic.bootstrap.servers": "localhost:9092",
"partitioner.class": "io.confluent.connect.storage.partitioner.DefaultPartitioner",
"schema.generator.class": "io.confluent.connect.storage.hive.schema.DefaultSchemaGenerator",
"flush.size": "3",
"schema.compatibility": "NONE",
"format.class": "io.confluent.connect.sftp.sink.format.avro.AvroFormat",
"storage.class": "io.confluent.connect.sftp.sink.storage.SftpSinkStorage",
"sftp.host": "localhost",
"sftp.port": "2222",
"sftp.username": "foo",
"sftp.password": "pass",
"sftp.working.dir": "/share",
"name": "sftpconnector"
},
"tasks": []
}
To check that the connector started successfully, view the Connect worker’s log by entering:
confluent local services connect log
Towards the end of the log you should see that the connector starts, logs a few messages, and then exports data from Kafka to SFTP. Once the connector finishes ingesting data to SFTP, check that the data is available in the SFTP working directory:
You should see a file with name /topics/test_sftp_sink/partition=0/test_sftp_sink+0+0000000000.avro The file name is encoded as topic+kafkaPartition+startOffset+endOffset.format.
To extract the contents of the file, use avro-tools-1.8.2.jar (available in the Apache Archives).
Move avro-tools-1.8.2.jar to SFTP’s working directory and run the following command:
java -jar avro-tools-1.8.2.jar tojson /<working dir>/topics/test_sftp_sink/partition=0/test_sftp_sink+0+0000000000.avro
You should see the following output:
{"f1":"value1"}
{"f1":"value2"}
{"f1":"value3"}
Finally, stop the Connect worker as well as all the rest of Confluent Platform by running:
confluent local stop
Your output should resemble:
Stopping Control Center
Control Center is [DOWN]
Stopping KSQL Server
KSQL Server is [DOWN]
Stopping Connect
Connect is [DOWN]
Stopping Kafka REST
Kafka REST is [DOWN]
Stopping Schema Registry
Schema Registry is [DOWN]
Stopping Kafka
Kafka is [DOWN]
Stopping Zookeeper
Zookeeper is [DOWN]
Or, stop all the services and additionally wipe out any data generated during this quick start by running:
confluent local destroy
Your output should resemble:
Stopping Control Center
Control Center is [DOWN]
Stopping KSQL Server
KSQL Server is [DOWN]
Stopping Connect
Connect is [DOWN]
Stopping Kafka REST
Kafka REST is [DOWN]
Stopping Schema Registry
Schema Registry is [DOWN]
Stopping Kafka
Kafka is [DOWN]
Stopping Zookeeper
Zookeeper is [DOWN]
Deleting: /var/folders/ty/rqbqmjv54rg_v10ykmrgd1_80000gp/T/confluent.PkQpsKfE
SFTP file names
The SFTP data model is a flat structure. Each record gets stored into a file and the name of each file serves as the unique key. Generally, the hierarchy of files in which records get stored follow this format:
<prefix>/<topic>/<encodedPartition>/<topic>+<kafkaPartition>+<startOffset>.<format>
where:
<prefix>is specified with the connector’ssftp.working.dirconfiguration property, which defaults to the literal valuetopicsand helps create file with a name that don’t clash with existing file’s name in the same directory.<topic>corresponds to the name of the Kafka topic from which the records were read.<encodedPartition>is generated by the SFTP sink connector’s partitioner (see Partitioning records into SFTP files).<kafkaPartition>is the Kafka partition number from which the records were read.<startOffset>is the Kafka offset of the first record written to this file.<format>is the extension identifing the format in which the records are serialized in this SFTP file.
Partitioning records into SFTP files
The SFTP sink connector’s partitioner determines how records read from a Kafka topic are partitioned into SFTP directories. The partitioner determines the <encodedPartition> portion of the SFTP file names (see SFTP file names).
The partitioner is specified in the connector configuration with the partitioner.class configuration property. The SFTP sink connector comes with the following partitioners:
Default (Kafka) Partitioner: The
io.confluent.connect.storage.partitioner.DefaultPartitionerpreserves the same topic partitions as in Kafka, and records from each topic partition ultimately end up in SFTP file with names that include the Kafka topic and Kafka partitions. The<encodedPartition>is always<topicName>/partition=<kafkaPartition>, resulting in SFTP file names of the form<prefix>/<topic>/partition=<kafkaPartition>/<topic>+<kafkaPartition>+<startOffset>.<format>.Field Partitioner: The
io.confluent.connect.storage.partitioner.FieldPartitionerdetermines the partition from the field within each record identified by the connector’spartition.field.nameconfiguration property, which has no default. This partitioner requiresSTRUCTrecord type values. The<encodedPartition>is always<topicName>/<fieldName>=<fieldValue>, resulting in SFTP file names of the form<prefix>/<topic>/<fieldName>=<fieldValue>/<topic>+<kafkaPartition>+<startOffset>.<format>.Time-Based Partitioner: The
io.confluent.connect.storage.partitioner.TimeBasedPartitionerdetermines the partition from the year, month, day, hour, minutes, and/or seconds. This partitioner requires the following connector configuration properties:The
path.formatconfiguration property specifies the pattern used for the<encodedPartition>portion of the SFTP file name. For example, whenpath.format='year'=YYYY/'month'=MM/'day'=dd/'hour'=HH, SFTP file names will have the form<prefix>/<topic>/year=YYYY/month=MM/day=dd/hour=HH/<topic>+<kafkaPartition>+<startOffset>.<format>.The
partition.duration.msconfiguration property defines the maximum granularity of the SFTP files within a single encoded partition directory. For example, settingpartition.duration.ms=600000(10 minutes) will result in each SFTP file in that directory having no more than 10 minutes of records.The
localeconfiguration property specifies the JDK’s locale used for formatting dates and times. For example, useen-USfor US English,en-GBfor UK English,fr-FRfor French (in France). These may vary by Java version; see the available locales.The
timezoneconfiguration property specifies the current timezone in which the dates and times will be treated. Use standard short names for timezones such asUTCor (without daylight savings)PST,EST, andECT, or longer standard names such asAmerica/Los_Angeles,America/New_York, andEurope/Paris. These may vary by Java version; see the available timezones within each locale, such as those within the “en_US” locale.The
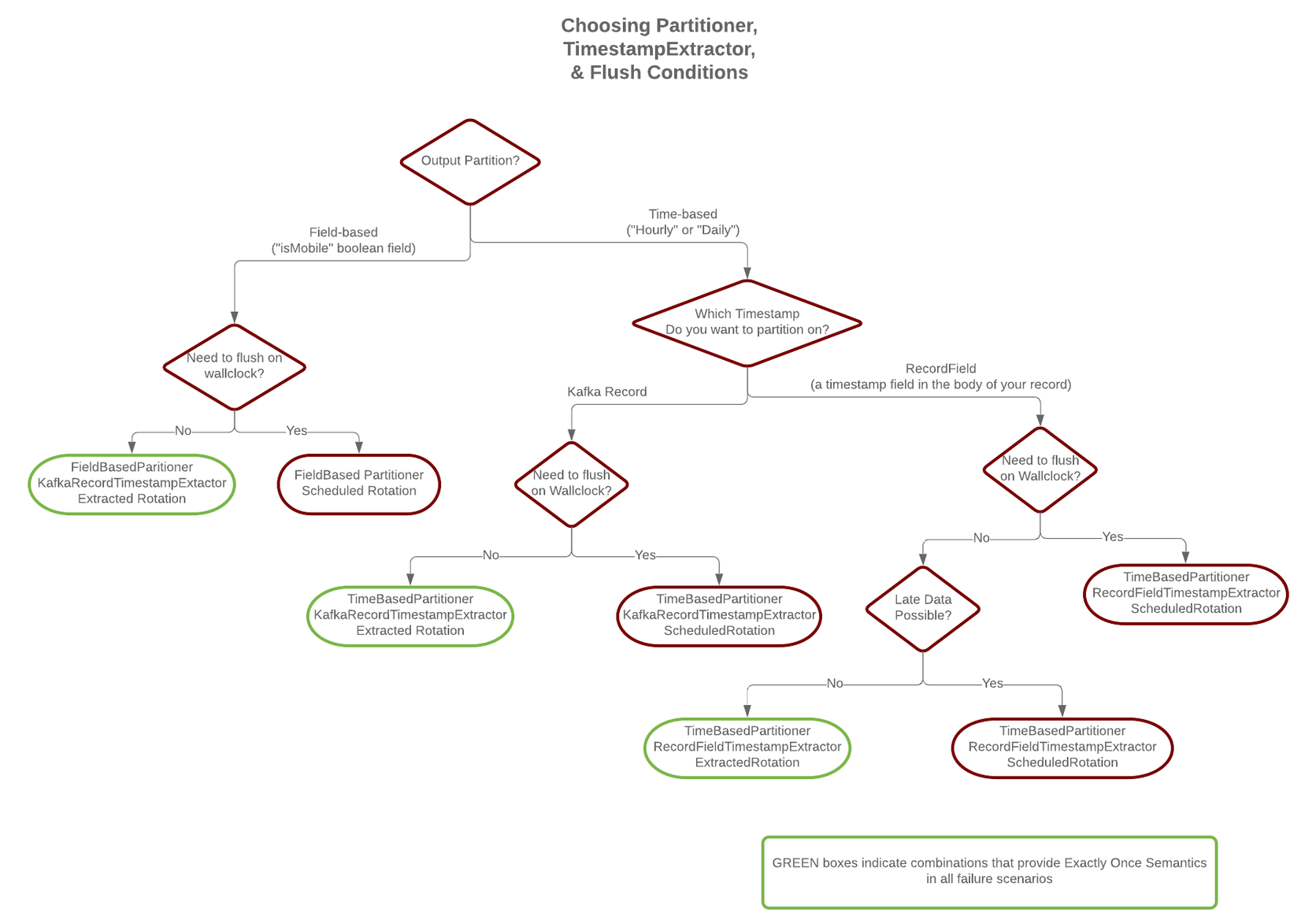
timestamp.extractorconfiguration property determines how to obtain a timestamp from each record. Values can includeWallclock(the default) to use the system time when the record is processed,Recordto use the timestamp of the Kafka record denoting when it was produced or stored by the broker,RecordFieldto extract the timestamp from one of the fields in the record’s value as specified by thetimestamp.fieldconfiguration property.
Daily Partitioner: The
io.confluent.connect.storage.partitioner.DailyPartitioneris equivalent to the TimeBasedPartitioner withpath.format='year'=YYYY/'month'=MM/'day'=ddandpartition.duration.ms=86400000(one day, for one SFTP file in each daily directory). This partitioner always results in SFTP file names of the form<prefix>/<topic>/year=YYYY/month=MM/day=dd/<topic>+<kafkaPartition>+<startOffset>.<format>. This partitioner requires the following connector configuration properties:The
localeconfiguration property specifies the JDK’s locale used for formatting dates and times. For example, useen-USfor US English,en-GBfor UK English,fr-FRfor French (in France). These may vary by Java version; see the available locales.The
timezoneconfiguration property specifies the current timezone in which the dates and times will be treated. Use standard short names for timezones such asUTCor (without daylight savings)PST,EST, andECT, or longer standard names such asAmerica/Los_Angeles,America/New_York, andEurope/Paris. These may vary by Java version; see the available timezones within each locale, such as those within the “en_US” locale.The
timestamp.extractorconfiguration property determines how to obtain a timestamp from each record. Values can includeWallclock(the default) to use the system time when the record is processed,Recordto use the timestamp of the Kafka record denoting when it was produced or stored by the broker,RecordFieldto extract the timestamp from one of the fields in the record’s value as specified by thetimestamp.fieldconfiguration property.
Hourly Partitioner: The
io.confluent.connect.storage.partitioner.HourlyPartitioneris equivalent to the TimeBasedPartitioner withpath.format='year'=YYYY/'month'=MM/'day'=dd/'hour'=HHandpartition.duration.ms=3600000(one hour, for one SFTP file in each hourly directory). This partitioner always results in SFTP file names of the form<prefix>/<topic>/year=YYYY/month=MM/day=dd/hour=HH/<topic>+<kafkaPartition>+<startOffset>.<format>. This partitioner requires the following connector configuration properties:The
localeconfiguration property specifies the JDK’s locale used for formatting dates and times. For example, useen-USfor US English,en-GBfor UK English,fr-FRfor French (in France). These may vary by Java version; see the available locales.The
timezoneconfiguration property specifies the current timezone in which the dates and times will be treated. Use standard short names for timezones such asUTCor (without daylight savings)PST,EST, andECT, or longer standard names such asAmerica/Los_Angeles,America/New_York, andEurope/Paris. These may vary by Java version; see the available timezones within each locale, such as those within the “en_US” locale.The
timestamp.extractorconfiguration property determines how to obtain a timestamp from each record. Values can includeWallclock(the default) to use the system time when the record is processed,Recordto use the timestamp of the Kafka record denoting when it was produced or stored by the broker,RecordFieldto extract the timestamp from one of the fields in the record’s value as specified by thetimestamp.fieldconfiguration property.
As noted below, the choice of timestamp.extractor affects whether the SFTP sink connector can support exactly once delivery.
You can also choose to use a custom partitioner by implementing the io.confluent.connect.storage.partitioner.Partitioner interface, packaging your implementation into a JAR file, and then:
Place the JAR file into the
share/java/kafka-connect-sftpdirectory of your Confluent Platform installation on each worker node.Restart all of the Connect worker nodes. #. Configure SFTP sink connectors to use your fully-qualified partitioner class name.
SFTP File Formats
The SFTP sink connector can serialize multiple records into each SFTP file using a number of formats. The connector’s format.class configuration property identifies the name of the Java class that implements the io.confluent.connect.storage.format.Format interface. The SFTP sink connector comes with several implementations:
Avro: Use
format.class=io.confluent.connect.sftp.sink.format.avro.AvroFormatto write the SFTP file as an Avro container file and include the Avro schema in the container file followed by one or more records. The connector’savro.codecconfiguration property specifies the Avro compression code, and values can benull(the default) for no Avro compression,deflateto use the deflate algorithm as specified in RFC 1951,snappyto use Google’s Snappy compression library, andbzip2for BZip2 compression. Optionally setenhanced.avro.schema.support=trueto enable enum symbol preservation and package name awareness.JSON: Use
format.class=io.confluent.connect.sftp.sink.format.json.JsonFormatto write the SFTP file containing one JSON serialized record per line. The connector’ssftp.compression.typeconfiguration property can be set tonone(the default) for no compression orgzipfor GZip compression.Parquet: Use
format.class=io.confluent.connect.sftp.sink.format.parquet.ParquetFormatto write the SFTP file as a parquet container file and will include the Avro schema in the container file followed by one or more records.CSV: Use
format.class=io.confluent.connect.sftp.sink.format.csv.CsvFormatto write the SFTP file containing a comma-separated line for each record.TSV: Use
format.class=io.confluent.connect.sftp.sink.format.tsv.TsvFormatto write the SFTP file containing a tab space separated line for each record.
You can also choose to use a custom partitioner by implementing the io.confluent.connect.storage.format.Format interface, packaging your implementation into a JAR file, and then:
Place the JAR file into the
share/java/kafka-connect-sftpdirectory of your Confluent Platform installation on each worker node.Restart all of the Connect worker nodes. #. Configure SFTP sink connectors with
format.classset to the fully-qualified class name of your format implementation.
Exactly-once delivery on top of eventual consistency
The SFTP Sink Connector is able to provide exactly-once semantics to its consumers, under the condition that the connector is supplied with a deterministic partitioner.
Currently, out of the available partitioners, the default and field partitioners are always deterministic. TimeBasedPartitioner can be deterministic with some configurations, discussed below. This implies that, when any of these partitioners is used, splitting of files always happens at the same offsets for a given set of Kafka records. These partitioners take into account flush.size and schema.compatibility to decide when to roll and save a new file to SFTP directories. The connector always delivers files in SFTP that contain the same records, even under the presence of failures. If a connector task fails before an upload completes, the file does not become visible to SFTP. If, on the other hand, a failure occurs after the upload has completed but before the corresponding offset is committed to Kafka by the connector, then a re-upload will take place. However, such a re-upload is transparent to the user of the SFTP, who at any time will have access to the same records made eventually available by successful uploads to SFTP files and directories.
To guarantee exactly-once semantics with the TimeBasedPartitioner, the connector must be configured to use a deterministic implementation of TimestampExtractor and a deterministic rotation strategy. The deterministic timestamp extractors are Kafka records (timestamp.extractor=Record) or record fields (timestamp.extractor=RecordField). The deterministic rotation strategy configuration is rotate.interval.ms (setting rotate.schedule.interval.ms is nondeterministic and will invalidate exactly-once guarantees).