Important
You are viewing documentation for an older version of Confluent Platform. For the latest, click here.
Pipelining with Kafka Connect and Kafka Streams¶
Overview¶
This demo shows users how to build pipelines with Apache Kafka®.
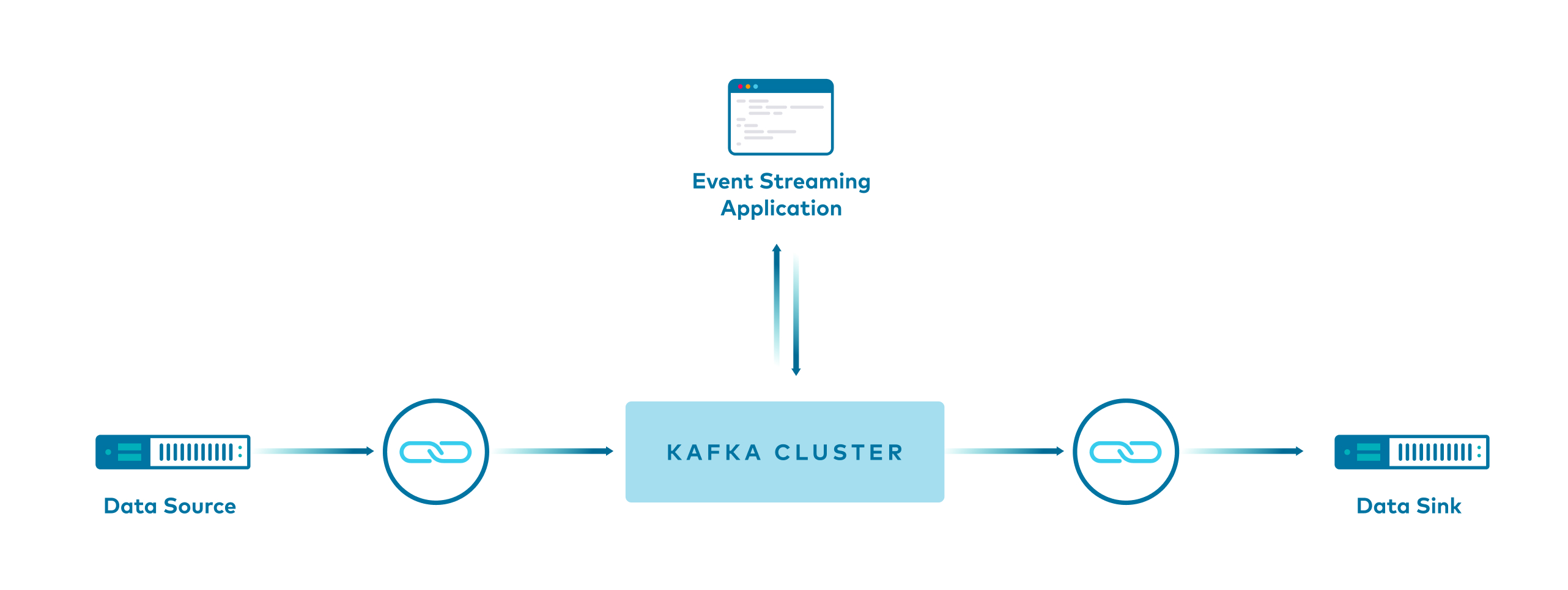
It showcases different ways to produce data to Apache Kafka® topics, with and without Kafka Connect, and various ways to serialize it for the Kafka Streams API and ksqlDB.
| Example | Produce to Kafka Topic | Key | Value | Stream Processing |
|---|---|---|---|---|
| Confluent CLI Producer with String | CLI | String | String | Kafka Streams |
| JDBC source connector with JSON | JDBC with SMT to add key | Long | Json | Kafka Streams |
| JDBC source connector with SpecificAvro | JDBC with SMT to set namespace | null | SpecificAvro | Kafka Streams |
| JDBC source connector with GenericAvro | JDBC | null | GenericAvro | Kafka Streams |
| Java producer with SpecificAvro | Producer | Long | SpecificAvro | Kafka Streams |
| JDBC source connector with Avro | JDBC | Long | Avro | ksqlDB |
Detailed walk-thru of this demo is available in the whitepaper Kafka Serialization and Deserialization (SerDes) Examples and the blogpost Building a Real-Time Streaming ETL Pipeline in 20 Minutes
Description of Data¶
The original data is a table of locations that resembles this.
id|name|sale
1|Raleigh|300
2|Dusseldorf|100
1|Raleigh|600
3|Moscow|800
4|Sydney|200
2|Dusseldorf|400
5|Chennai|400
3|Moscow|100
3|Moscow|200
1|Raleigh|700
In produces records to a Kafka topic:

The actual client application uses the methods count and sum to process this data, grouped by each city.
The output of count is:
1|Raleigh|3
2|Dusseldorf|2
3|Moscow|3
4|Sydney|1
5|Chennai|1

The output of sum is:
1|Raleigh|1600
2|Dusseldorf|500
3|Moscow|1100
4|Sydney|200
5|Chennai|400

Demo Prerequisites¶
- Download Confluent Platform
- Maven command
mvnto compile Java code timeout: used by the bash scripts to terminate a consumer process after a certain period of time.timeoutis available on most Linux distributions but not on macOS. macOS users should view the installation instructions for macOS.
Run the demo¶
Clone the examples GitHub repository and check out the
5.5.15-postbranch.git clone https://github.com/confluentinc/examples cd examples git checkout 5.5.15-post
Change directory to the connect-streams-pipeline demo.
cd connect-streams-pipeline
Run the demo, all examples, end-to-end
./start.sh
If you are running Confluent Platform, open your browser and navigate to the Confluent Control Center web interface Management -> Connect tab at http://localhost:9021/management/connect to see the data in the Kafka topics and the deployed connectors.
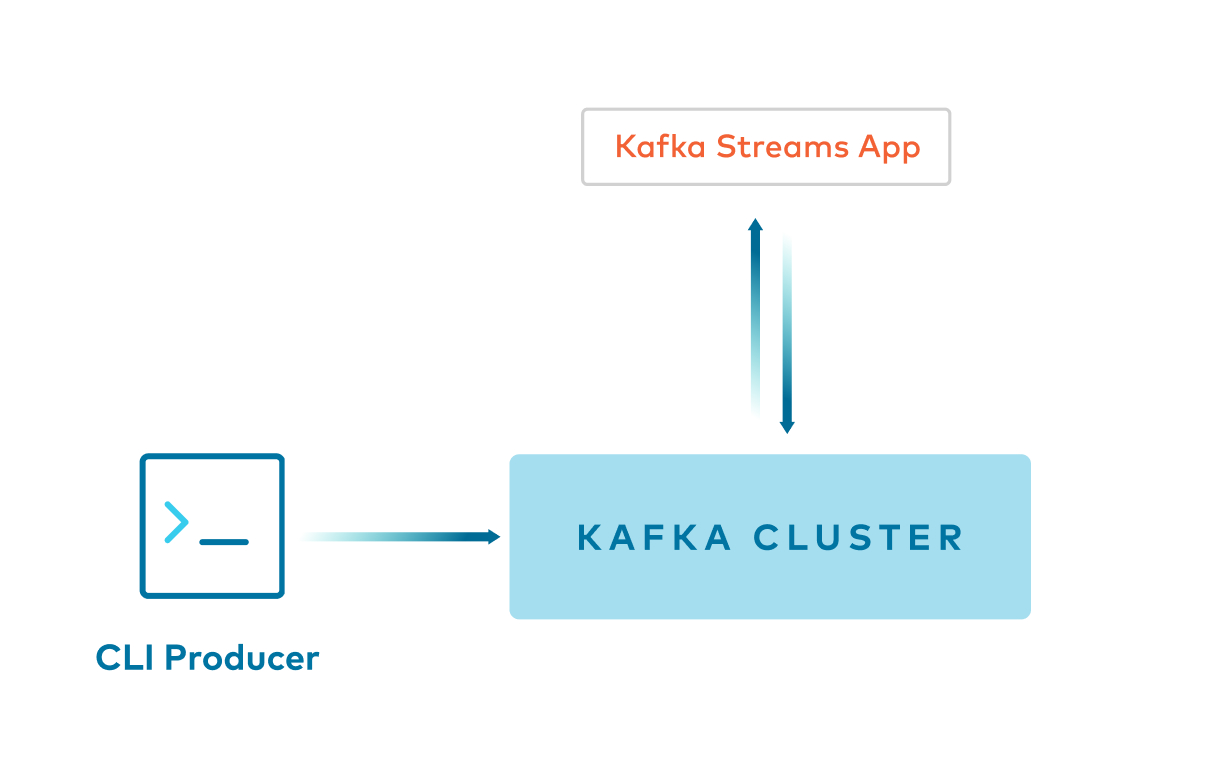
Example 1: Kafka console producer -> Key:String and Value:String¶
- Command line
confluent local produceproducesStringkeys andStringvalues to a Kafka topic. - Client application reads from the Kafka topic using
Serdes.String()for both key and value.
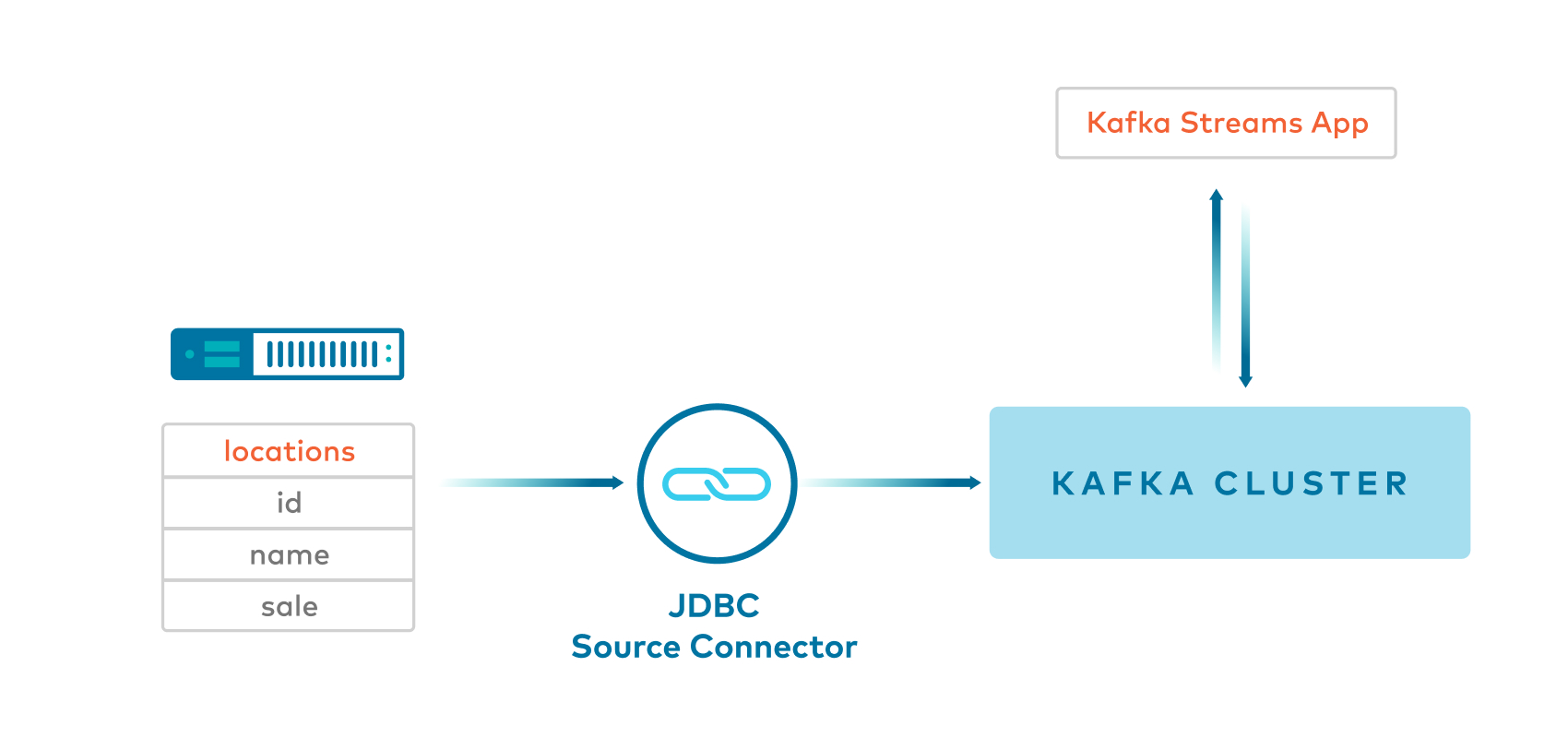
Example 2: JDBC source connector with Single Message Transformations -> Key:Long and Value:JSON¶
- Kafka Connect JDBC source connector produces JSON values, and inserts the key using single message transformations, also known as
SMTs. This is helpful because by default JDBC source connector does not insert a key. - This example uses a few SMTs including one to cast the key to an
int64. The key uses theorg.apache.kafka.connect.converters.LongConverterprovided by KAFKA-6913.
##
# Copyright 2020 Confluent Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
##
# A simple example that copies all tables from a SQLite database. The first few settings are
# required for all connectors: a name, the connector class to run, and the maximum number of
# tasks to create:
name=test-source-sqlite-jdbc-autoincrement-jdbcjson
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
# The remaining configs are specific to the JDBC source connector. In this example, we connect to a
# SQLite database stored in the file test.db, use and auto-incrementing column called 'id' to
# detect new rows as they are added, and output to topics prefixed with 'test-sqlite-jdbc-', e.g.
# a table called 'users' will be written to the topic 'test-sqlite-jdbc-users'.
connection.url=jdbc:sqlite:/usr/local/lib/retail.db
mode=incrementing
incrementing.column.name=id
topic.prefix=jdbcjson-
table.whitelist=locations
transforms=InsertKey, ExtractId, CastLong
transforms.InsertKey.type=org.apache.kafka.connect.transforms.ValueToKey
transforms.InsertKey.fields=id
transforms.ExtractId.type=org.apache.kafka.connect.transforms.ExtractField$Key
transforms.ExtractId.field=id
transforms.CastLong.type=org.apache.kafka.connect.transforms.Cast$Key
transforms.CastLong.spec=int64
key.converter=org.apache.kafka.connect.converters.LongConverter
key.converter.schemas.enable=false
value.converter=org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable=false
- Client application reads from the Kafka topic using
Serdes.Long()for key and a custom JSON Serde for the value.
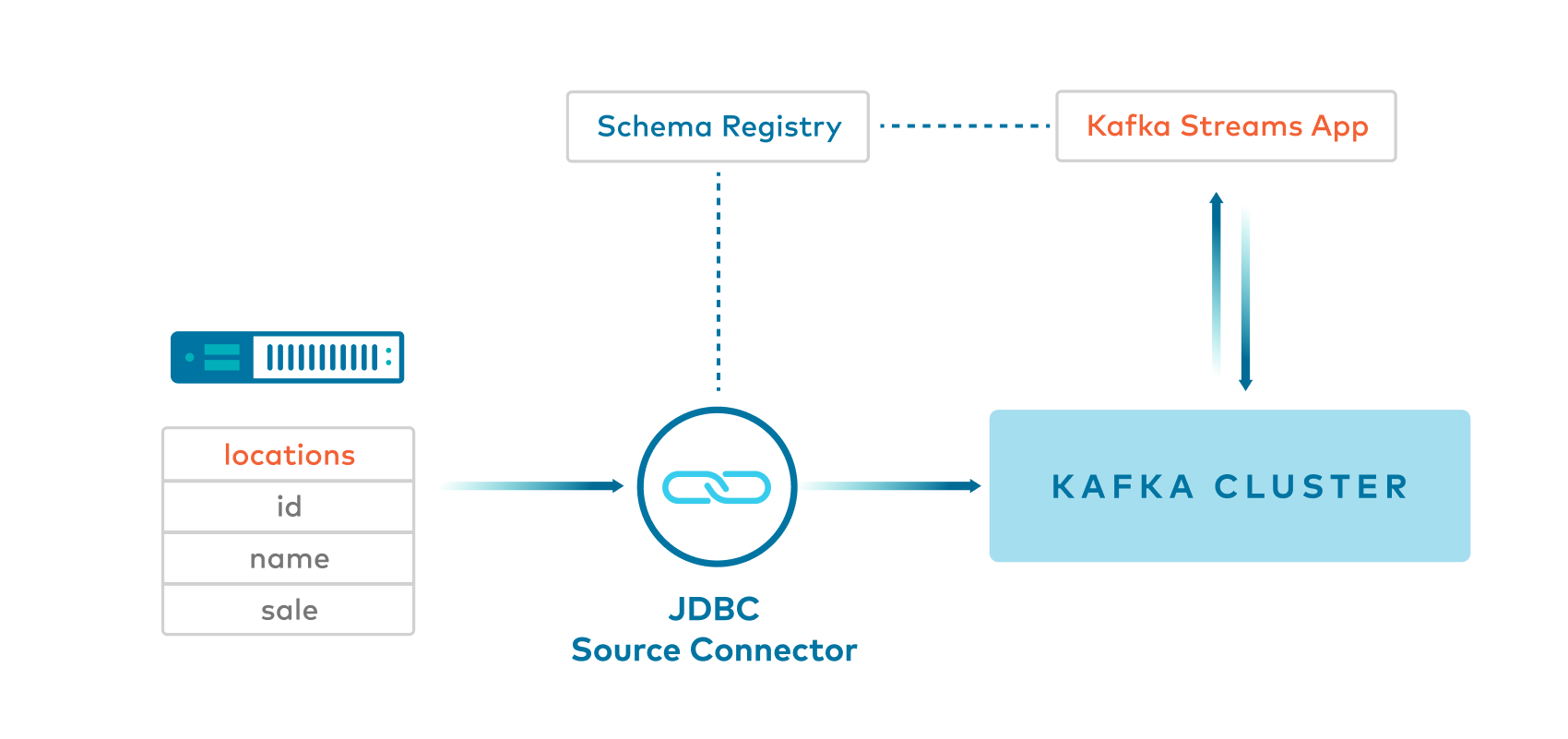
Example 3: JDBC source connector with SpecificAvro -> Key:String(null) and Value:SpecificAvro¶
- Kafka Connect JDBC source connector produces Avro values, and null
Stringkeys, to a Kafka topic. - This example uses a simple message transformation (SMT) called
SetSchemaMetadatawith code that has a fix for KAFKA-5164, allowing the connector to set the namespace in the schema. If you do not have the fix for KAFKA-5164, see Example 4 that usesGenericAvroinstead ofSpecificAvro.
##
# Copyright 2020 Confluent Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
##
# A simple example that copies all tables from a SQLite database. The first few settings are
# required for all connectors: a name, the connector class to run, and the maximum number of
# tasks to create:
name=test-source-sqlite-jdbc-autoincrement-jdbcspecificavro
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
# The remaining configs are specific to the JDBC source connector. In this example, we connect to a
# SQLite database stored in the file test.db, use and auto-incrementing column called 'id' to
# detect new rows as they are added, and output to topics prefixed with 'test-sqlite-jdbc-', e.g.
# a table called 'users' will be written to the topic 'test-sqlite-jdbc-users'.
connection.url=jdbc:sqlite:/usr/local/lib/retail.db
mode=incrementing
incrementing.column.name=id
topic.prefix=jdbcspecificavro-
table.whitelist=locations
value.converter=io.confluent.connect.avro.AvroConverter
value.converter.schema.registry.url=http://localhost:8081
value.converter.schemas.enable=true
transforms=SetValueSchema
transforms.SetValueSchema.type=org.apache.kafka.connect.transforms.SetSchemaMetadata$Value
transforms.SetValueSchema.schema.name=io.confluent.examples.connectandstreams.avro.Location
- Client application reads from the Kafka topic using
SpecificAvroSerdefor the value and then themapfunction to convert the stream of messages to haveLongkeys and custom class values.
Example 4: JDBC source connector with GenericAvro -> Key:String(null) and Value:GenericAvro¶
- Kafka Connect JDBC source connector produces Avro values, and null
Stringkeys, to a Kafka topic.
##
# Copyright 2020 Confluent Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
##
# A simple example that copies all tables from a SQLite database. The first few settings are
# required for all connectors: a name, the connector class to run, and the maximum number of
# tasks to create:
name=test-source-sqlite-jdbc-autoincrement-jdbcgenericavro
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
# The remaining configs are specific to the JDBC source connector. In this example, we connect to a
# SQLite database stored in the file test.db, use and auto-incrementing column called 'id' to
# detect new rows as they are added, and output to topics prefixed with 'test-sqlite-jdbc-', e.g.
# a table called 'users' will be written to the topic 'test-sqlite-jdbc-users'.
connection.url=jdbc:sqlite:/usr/local/lib/retail.db
mode=incrementing
incrementing.column.name=id
topic.prefix=jdbcgenericavro-
table.whitelist=locations
value.converter=io.confluent.connect.avro.AvroConverter
value.converter.schema.registry.url=http://localhost:8081
value.converter.schemas.enable=true
- Client application reads from the Kafka topic using
GenericAvroSerdefor the value and then themapfunction to convert the stream of messages to haveLongkeys and custom class values. - This example currently uses
GenericAvroSerdeand notSpecificAvroSerdefor a specific reason. JDBC source connector currently doesn’t set a namespace when it generates a schema name for the data it is producing to Kafka. ForSpecificAvroSerde, the lack of namespace is a problem when trying to match reader and writer schema because Avro uses the writer schema name and namespace to create a classname and tries to load this class, but without a namespace, the class will not be found.
Example 5: Java client producer with SpecificAvro -> Key:Long and Value:SpecificAvro¶
- Java client produces
Longkeys andSpecificAvrovalues to a Kafka topic. - Client application reads from the Kafka topic using
Serdes.Long()for key andSpecificAvroSerdefor the value.
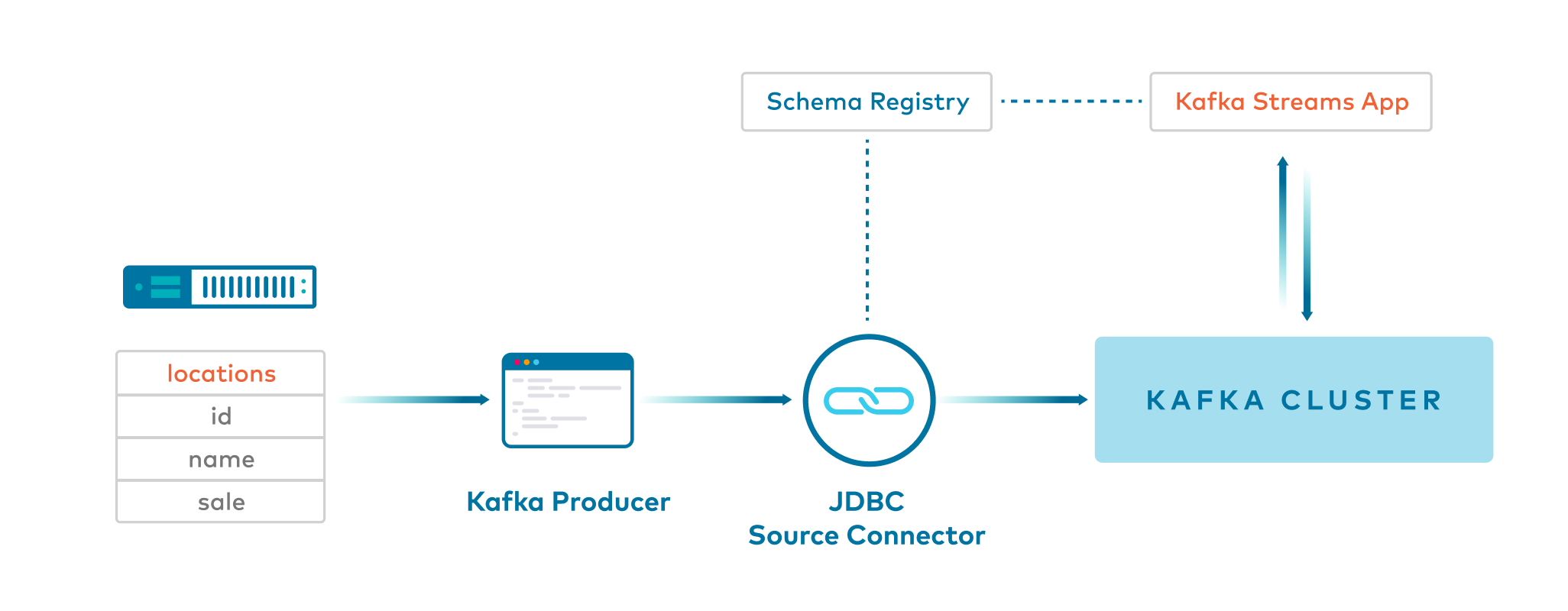
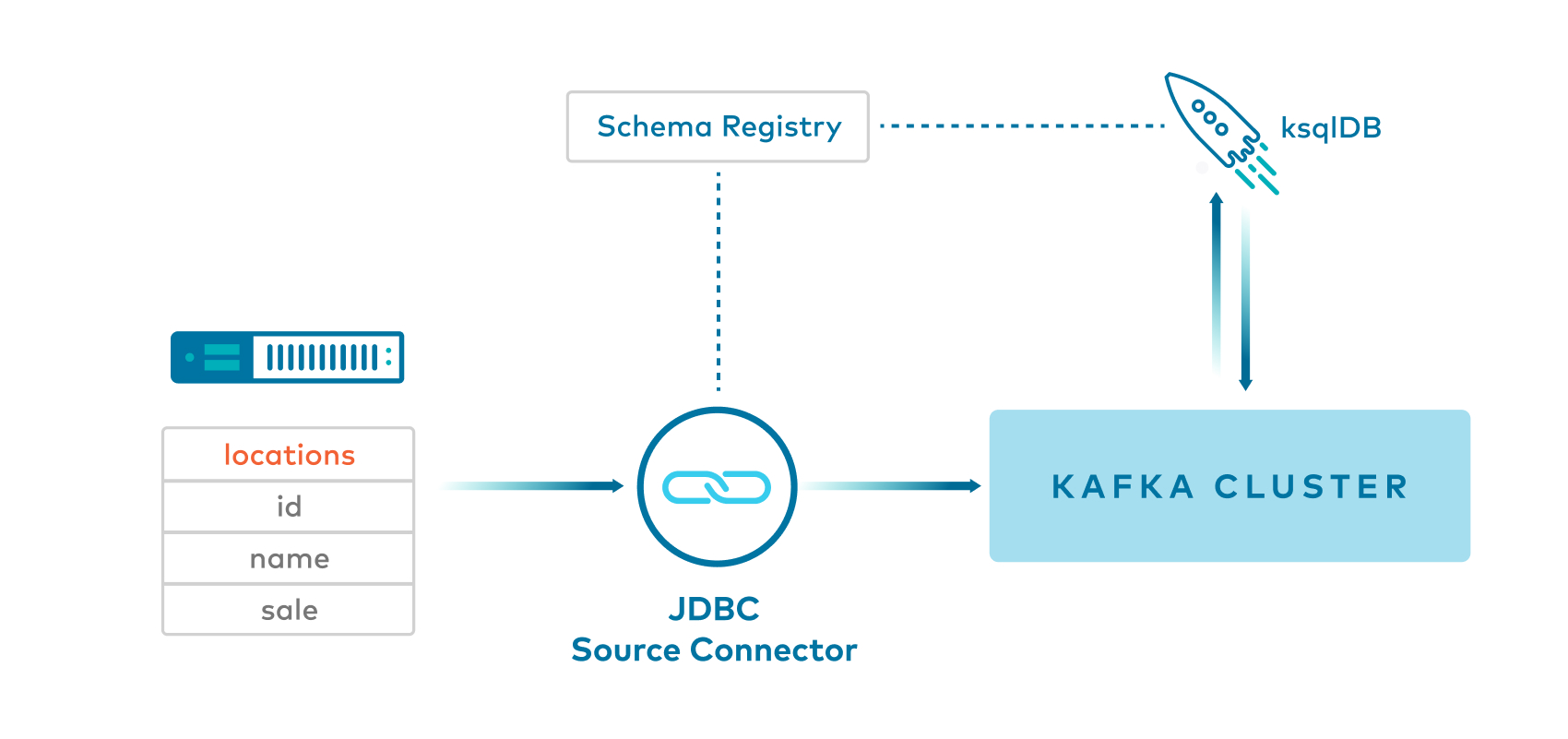
Example 6: JDBC source connector with Avro to ksqlDB -> Key:Long and Value:Avro¶
- Kafka Connect JDBC source connector produces Avro values, and null keys, to a Kafka topic.
##
# Copyright 2020 Confluent Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
##
# A simple example that copies all tables from a SQLite database. The first few settings are
# required for all connectors: a name, the connector class to run, and the maximum number of
# tasks to create:
name=test-source-sqlite-jdbc-autoincrement-jdbcavroksql
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
# The remaining configs are specific to the JDBC source connector. In this example, we connect to a
# SQLite database stored in the file test.db, use and auto-incrementing column called 'id' to
# detect new rows as they are added, and output to topics prefixed with 'test-sqlite-jdbc-', e.g.
# a table called 'users' will be written to the topic 'test-sqlite-jdbc-users'.
connection.url=jdbc:sqlite:/usr/local/lib/retail.db
mode=incrementing
incrementing.column.name=id
topic.prefix=jdbcavroksql-
table.whitelist=locations
key.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=false
value.converter=io.confluent.connect.avro.AvroConverter
value.converter.schema.registry.url=http://localhost:8081
value.converter.schemas.enable=true
- ksqlDB reads from the Kafka topic and then uses
PARTITION BYto create a new stream of messages withBIGINTkeys.
Technical Notes¶
- KAFKA-5245: one needs to provide the Serdes twice, (1) when calling
StreamsBuilder#stream()and (2) when callingKStream#groupByKey() - PR-531: Confluent distribution provides packages for
GenericAvroSerdeandSpecificAvroSerde - KAFKA-2378: adds APIs to be able to embed Kafka Connect into client applications
- KAFKA-2526: one cannot use the
--key-serializerargument in theconfluent local produceto serialize the key as aLong. As a result, in this example the key is serialized as aString. As a workaround, you could write your own kafka.common.MessageReader (e.g. check out the default implementation of LineMessageReader) and then you can specify--line-readerargument in theconfluent local produce. - KAFKA-5164: allows the connector to set the namespace in the schema.