Resilience in Confluent Cloud¶
This topic describes resilience features built into Apache Kafka® and how Confluent implements those features in Confluent Cloud.
Kafka resilience¶
Kafka is a distributed collection of servers, known as brokers, that operate as a cluster. Brokers can span data centers or cloud provider availability zones (AZs). Kafka clusters provide highly scalable and fault-tolerant systems that support mission-critical applications.
Partitions distribute data across brokers in a cluster. You can specify how many replicas exist for each partition. One replica is the leader and the rest are followers. The leader handles read and write operations for the Kafka client, replicating write operations to followers. You can increase the the operational reliability of the cluster by enforcing a minimum number of replicas that must be in sync to allow write operations and using client configurations such as acks.
If any broker in a cluster fails, the remaining brokers ensure continuous operations. In the event of a failure, a cluster rebalance event triggers leader elections to replace the lost leaders. You must configure Kafka clients to automatically handle rebalance events.
These are the most fundamental aspects of Kafka resilience, which provides the native capability to operate in environments that require fault tolerance and scalability.
Confluent Cloud resilience¶
Confluent Cloud architecture provides two distinct decoupled pieces to separate points of failure:
- a centralized global control plane
- a data plane made up of multiple satellite instances, running in regions around the world
Data planes function independently of the control plane and other data plane instances. Data plane instances are not impacted by failures on the control plane or peer data plane instances.
Confluent Cloud monitors and records event streams to data planes. This enables Confluent Cloud to determine when data planes have issues and to know what changes have occurred over time, so that events can be replayed if necessary.
To facilitate communication between the control plane and the various data planes, Confluent Cloud uses a special Kafka cluster known as the mothership Kafka or just the mothership.
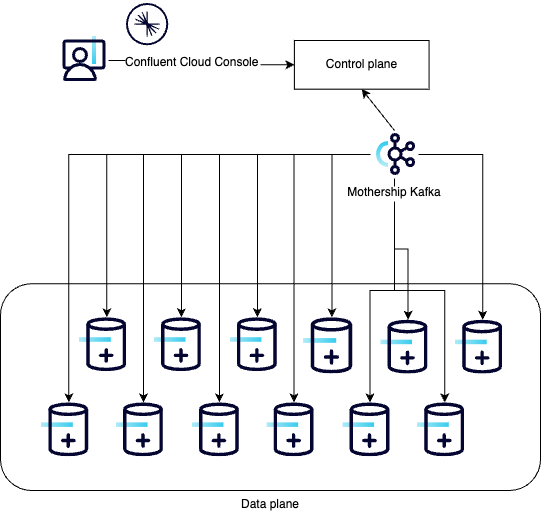
The mothership sends control messages to the data planes and forwards status updates from the data planes back to the control plane. Confluent uses a change data capture (CDC) approach, where Debezium connectors capture row-level changes committed to a Postgres database. Those changes are sent to the mothership, refined, and then sent back to microservices running in the data plane. The microservice manages state in a relational store (with its ACID guarantees) and notifies other services of change. This approach is similar to the Outbox Pattern. For Confluent this strategy is key for reliable, recoverable, and auditable communication from the control plane services to the data plane.
Data plane¶
Recovery point objective (RPO) is the amount of data you’re okay with losing because of a failure. To achieve zero RPO, you need synchronous replication, which Confluent Cloud provides. Recovery time objective (RTO) is the amount of time necessary for recovery from a failure. To have zero RTO, you must properly configure clients to failover.
RPO¶
In a multi-zone cluster, Confluent Cloud provides a replication factor of three and enforces a minimum number of two in-sync replicas. This means Confluent Cloud replicates data across three cloud provider AZs and requires two replicas to be in sync to allow write operations. This configuration provides the synchronous replication required for zero RPO. Confluent Cloud maintains full functionality as long as two AZs are operational. In other words, Confluent Cloud provides fault tolerance for the loss of a single AZ.
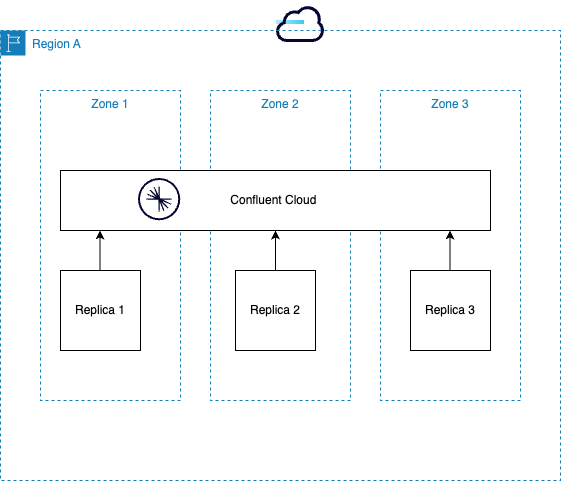
RTO¶
Loss of an AZ triggers a cluster rebalance event. This process is immediate and automatic and ensures connected applications can access data. For a single AZ failure, RTO is less than one second for Kafka clients configured according to best practices. For more information, see Producer Configurations and Kafka 101 Developer course section on Producers.