Azure Cosmos DB Source Connector for Confluent Cloud¶
The fully-managed Azure Cosmos Source connector for Confluent Cloud reads records from an Azure Cosmos database and writes data to Apache Kafka® topics in Confluent Cloud.
Features¶
The Azure Cosmos DB Source connector supports the following features:
- Topic to Container mapping: The connector can map a container (table) to an individual Kafka topic (that is,
topic1#con1,topic2#con2). - At least once delivery: This connector guarantees that records from the Kafka topic are delivered at least once.
- Supports multiple tasks: The connector supports running one or more tasks. More tasks may improve performance. Note that one container (table) can be handled by one task.
- Offset management capabilities: Supports offset management. For more information, see Manage custom offsets.
For more information and examples to use with the Confluent Cloud API for Connect, see the Confluent Cloud API for Managed and Custom Connectors section.
Limitations¶
Be sure to review the following information.
- For connector limitations, see Azure Cosmos DB Source Connector limitations.
- If you plan to use one or more Single Message Transforms (SMTs), see SMT Limitations.
- If you plan to use Confluent Cloud Schema Registry, see Schema Registry Enabled Environments.
Manage custom offsets¶
Custom offsets for managed connectors is Early Access
Confluent uses Early Access releases to gather feedback. This service should be used only for evaluation and non-production testing purposes, or to provide feedback to Confluent, particularly as it becomes more widely available in follow-on preview editions.
Early Access is intended for evaluation use in development and testing environments only and not for production use. The warranty, SLA, and Support Services provisions of your agreement with Confluent do not apply to Early Access. Confluent considers Early Access to be a Proof of Concept as defined in the Confluent Cloud Terms of Service. Confluent may discontinue providing preview releases of the Early Access releases at any time at the sole discretion of Confluent.
You can manage the offsets for this connector. Offsets provide information on the point in the source system from which the connector accesses data. For more information, see Manage Offsets for Fully-Managed Connectors.
To manage offsets:
- Manage offsets using Confluent Cloud APIs. For more information, see Cluster API reference.
Note
The Azure Cosmos DB Source connector allows reading from multiple containers using a single connector. In the following examples, the connector is reading from two different containers and writing to two different topics. Therefore, the offset is an array with two elements, each of which specifies a container and database name.
To get the current offset, make a GET request that specifies the environment, Kafka cluster, and connector name.
GET /connect/v1/environments/{environment_id}/clusters/{kafka_cluster_id}/connectors/{connector_name}/offsets
Host: https://api.confluent.cloud
Response:
Successful calls return HTTP 200 with a JSON payload that describes the offset.
{
"id": "lcc-example123",
"name": "{connector_name}",
"offsets": [
{
"partition": {
"Container": "container2",
"DatabaseName": "my-cosmos-db"
},
"offset": {
"recordContinuationToken": "\"24764\""
}
},
{
"partition": {
"Container": "container1",
"DatabaseName": "my-cosmos-db"
},
"offset": {
"recordContinuationToken": "\"18460\""
}
}
],
"metadata": {
"observed_at": "2024-03-28T17:57:48.139635200Z"
}
}
Responses include the following information:
- The position of latest offset.
- The observed time of the offset in the metadata portion of the payload. The
observed_attime indicates a snapshot in time for when the API retrieved the offset. A running connector is always updating its offsets. Useobserved_atto get a sense for the gap between real time and the time at which the request was made. By default, offsets are observed every minute. Calling get repeatedly will fetch more recently observed offsets. - Information about the connector.
To update the offset, make a POST request that specifies the environment, Kafka cluster, and connector
name. Include a JSON payload that specifies new offset and a patch type.
POST /connect/v1/environments/{environment_id}/clusters/{kafka_cluster_id}/connectors/{connector_name}/offsets/request
Host: https://api.confluent.cloud
{
"type": "PATCH",
"offsets": [
{
"partition": {
"Container": "container2",
"DatabaseName": "my-cosmos-db"
},
"offset": {
"recordContinuationToken": "\"20000\""
}
},
{
"partition": {
"Container": "container1",
"DatabaseName": "my-cosmos-db"
},
"offset": {
"recordContinuationToken": "\"18000\""
}
}
]
}
Considerations:
- You can only make one offset change at a time for a given connector.
- This is an asynchronous request. To check the status of this request, you must use the check offset status API. For more information, see Get the status of an offset request.
- For source connectors, the connector attempts to read from the position defined by the requested offsets.
Response:
Successful calls return HTTP 202 Accepted with a JSON payload that describes the offset.
{
"id": "lcc-example123",
"name": "{connector_name}",
"offsets": [
{
"partition": {
"Container": "container2",
"DatabaseName": "my-cosmos-db"
},
"offset": {
"recordContinuationToken": "\"20000\""
}
},
{
"partition": {
"Container": "container1",
"DatabaseName": "my-cosmos-db"
},
"offset": {
"recordContinuationToken": "\"18000\""
}
}
],
"requested_at": "2024-03-28T17:58:45.606796307Z",
"type": "PATCH"
}
Responses include the following information:
- The requested position of the offsets in the source.
- The time of the request to update the offset.
- Information about the connector.
To delete the offset, make a POST request that specifies the environment, Kafka cluster, and connector
name. Include a JSON payload that specifies the delete type.
POST /connect/v1/environments/{environment_id}/clusters/{kafka_cluster_id}/connectors/{connector_name}/offsets/request
Host: https://api.confluent.cloud
{
"type": "DELETE"
}
Considerations:
- This is an asynchronous request. To check the status of this request, you must use the check offset status API. For more information, see Get the status of an offset request.
- Do not issue delete and patch requests at the same time.
- If the offset you intend to delete is not found, the connector continues from where it left off.
- If you want to start reading from the beginning with Azure Cosmos DB Source connector, you must update the
offset to set
recordContinuationTokento0.
Response:
Successful calls return HTTP 202 Accepted with a JSON payload that describes the result.
{
"id": "lcc-example123",
"name": "{connector_name}",
"offsets": [],
"requested_at": "2024-03-28T17:59:45.606796307Z",
"type": "DELETE"
}
Responses include the following information:
- Empty offsets.
- The time of the request to delete the offset.
- Information about Kafka cluster and connector.
- The type of request.
To get the status of a previous offset request, make a GET request that specifies the environment, Kafka cluster, and connector
name.
GET /connect/v1/environments/{environment_id}/clusters/{kafka_cluster_id}/connectors/{connector_name}/offsets/request/status
Host: https://api.confluent.cloud
Considerations:
- The status endpoint always shows the status of the most recent PATCH/DELETE operation.
Response:
Successful calls return HTTP 200 with a JSON payload that describes the result. The following is an example
of an applied patch.
{
"request": {
"id": "lcc-example123",
"name": "{connector_name}",
"offsets": [
{
"partition": {
"Container": "container2",
"DatabaseName": "my-cosmos-db"
},
"offset": {
"recordContinuationToken": "\"20000\""
}
},
{
"partition": {
"Container": "container1",
"DatabaseName": "smy-cosmos-db"
},
"offset": {
"recordContinuationToken": "\"18000\""
}
}
],
"requested_at": "2024-03-28T17:58:45.606796307Z",
"type": "PATCH"
},
"status": {
"phase": "APPLIED",
"message": "The Connect framework-managed offsets for this connector have been altered successfully. However, if this connector manages offsets externally, they will need to be manually altered in the system that the connector uses."
},
"previous_offsets": [
{
"partition": {
"Container": "container2",
"DatabaseName": "my-cosmos-db"
},
"offset": {
"recordContinuationToken": "\"24764\""
}
},
{
"partition": {
"Container": "container1",
"DatabaseName": "my-cosmos-db"
},
"offset": {
"recordContinuationToken": "\"18460\""
}
}
],
"applied_at": "2024-03-28T17:58:48.079141883Z"
}
Responses include the following information:
- The original request, including the time it was made.
- The status of the request: applied, pending, or failed.
- The time you issued the status request.
- The previous offsets. These are the offsets that the connector last updated prior to updating the offsets. Use these to try to restore the state of your connector if a patch update causes your connector to fail or to return a connector to its previous state after rolling back.
JSON payload¶
The table below offers a description of the unique fields in the JSON payload for managing offsets of the CosmosDB Source connector.
| Field | Definition | Required/Optional |
|---|---|---|
Container |
The value from connect.cosmos.containers.topicmap in the connector configuration, which is the format topic#container.
For example, topic2#container2 |
Required |
DatabaseName |
The value from connect.cosmos.databasename in the connector configuration. |
Required |
recordContinuationToken |
The last processed changeFeed or the point in the changeFeed to begin processing. | Required |
Quick Start¶
Use this quick start to get up and running with the Confluent Cloud Azure Cosmos DB Source connector. The quick start provides the basics of selecting the connector and configuring it to stream events from a database to Kafka.
- Prerequisites
Authorized access to a Confluent Cloud cluster on Amazon Web Services (AWS), Microsoft Azure (Azure), or Google Cloud.
The Confluent CLI installed and configured for the cluster. See Install the Confluent CLI.
Schema Registry must be enabled to use a Schema Registry-based format (for example, Avro, JSON_SR (JSON Schema), or Protobuf).
Authorized access to read data Azure Cosmos. For more information, see Secure access to data in Azure Cosmos DB.
The Azure Cosmos DB is configured to use the Core (SQL) API.
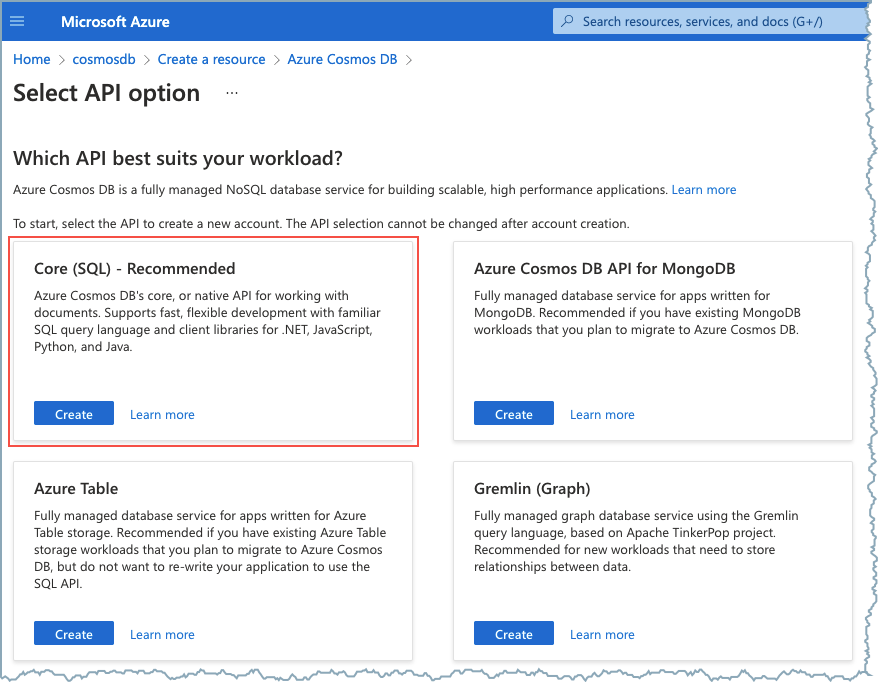
Core (SQL) API selection¶
Using the Confluent Cloud Console¶
Step 1: Launch your Confluent Cloud cluster¶
See the Quick Start for Confluent Cloud for installation instructions.
Step 2: Add a connector¶
In the left navigation menu, click Connectors. If you already have connectors in your cluster, click + Add connector.
Step 4: Enter the connector details¶
Note
- Make sure you have all your prerequisites completed.
- An asterisk ( * ) designates a required entry.
At the Add Azure Cosmos DB Source Connector screen, complete the following:
- Select the way you want to provide Kafka Cluster credentials. You can
choose one of the following options:
- Global Access: Allows your connector to access everything you have access to. With global access, connector access will be linked to your account. This option is not recommended for production.
- Granular access: Limits the access for your connector. You will be able to manage connector access through a service account. This option is recommended for production.
- Use an existing API key: Allows you to enter an API key and secret part you have stored. You can enter an API key and secret (or generate these in the Cloud Console).
- Click Continue.
- Add the following database connection details:
- Cosmos Endpoint: The Azure Cosmos database endpoint URL. For
example,
https://confluent-azure-cosmosdb.documents.azure.com:443/. - Cosmos Connection Key: The Azure Cosmos database connection master (primary) key.
- Cosmos Database name: The name of the Azure Cosmos database from which the connector reads data.
- Cosmos Endpoint: The Azure Cosmos database endpoint URL. For
example,
- Click Continue.
Add the following details:
- Select the output record value format (data going to the Kafka topic): AVRO, JSON, JSON_SR (JSON Schema), or PROTOBUF. Schema Registry must be enabled to use a Schema Registry-based format (for example, Avro, JSON Schema, or Protobuf). See Schema Registry Enabled Environments for additional information.
- Topic-Container map: A comma-delimited list of Kafka topics mapped
to Cosmos containers. For example:
topic1#con1,topic2#con2. The field accepts regex pattern*[\\w.-]+ *#[^,]+(, *[\\w.-]+ *#[^,]+)*. - Kafka message key enabled: Whether or not to set a Kafka message
key. Defaults to
id. - Kafka message key field: The document field to use for the Kafka
message key if the default key
idis not used.
Show advanced configurations
Schema context: Select a schema context to use for this connector, if using a schema-based data format. This property defaults to the Default context, which configures the connector to use the default schema set up for Schema Registry in your Confluent Cloud environment. A schema context allows you to use separate schemas (like schema sub-registries) tied to topics in different Kafka clusters that share the same Schema Registry environment. For example, if you select a non-default context, a Source connector uses only that schema context to register a schema and a Sink connector uses only that schema context to read from. For more information about setting up a schema context, see What are schema contexts and when should you use them?.
Task timeout: The maximum number of milliseconds (ms) the connector task reads documents before sending them to Kafka. Defaults to
5000ms.Task reader buffer size: The maximum buffer size (bytes) that the connector task buffers before sending documents to Kafka. Defaults to
10000bytes.Task batch size: The maximum number of documents the connector batches before sending to Kafka. Defaults to
100.Task poll interval: The polling interval in ms that a connector source task polls for changes. Defaults to
1000ms.Transforms and Predicates: See the Single Message Transforms (SMT) documentation for details.
For all property and value definitions, see ref:cc_azure-cosmos-source-config-properties.
Click Continue.
Based on the number of topic partitions you select, you will be provided with a recommended number of tasks.
- To change the number of tasks, use the Range Slider to select the desired number of tasks.
- Click Continue.
Verify the connection details by previewing the running configuration.
After you’ve validated that the properties are configured to your satisfaction, click Launch.
The status for the connector should go from Provisioning to Running.
Step 5: Check for files.¶
Verify that data is being produced in Kafka.
For more information and examples to use with the Confluent Cloud API for Connect, see the Confluent Cloud API for Managed and Custom Connectors section.
Using the Confluent CLI¶
To set up and run the connector using the Confluent CLI, complete the following steps.
Note
Make sure you have all your prerequisites completed.
Step 1: List the available connectors¶
Enter the following command to list available connectors:
confluent connect plugin list
Step 2: List the connector configuration properties¶
Enter the following command to show the connector configuration properties:
confluent connect plugin describe <connector-plugin-name>
The command output shows the required and optional configuration properties.
Step 3: Create the connector configuration file¶
Create a JSON file that contains the connector configuration properties. The following example shows the required connector properties.
{
"name": "CosmosDbSourceConnector_0",
"config": {
"connector.class": "CosmosDbSource",
"name": "CosmosDbSourceConnector_0",
"connect.cosmos.connection.endpoint": "https://confluent-azure-cosmosdb.documents.azure.com:443/",
"connect.cosmos.master.key": "****************************************",
"connect.cosmos.databasename": "ToDoList",
"connect.cosmos.containers.topicmap": "Kafka-Items#Items",
"output.data.format": "AVRO",
"connect.cosmos.messagekey.enabled": "true",
"kafka.auth.mode": "KAFKA_API_KEY",
"kafka.api.key": "****************",
"kafka.api.secret": "**********************************",
"tasks.max": "1"
}
}
Note the following property definitions:
"connector.class": Identifies the connector plugin name."name": Sets a name for your new connector."connect.cosmos.containers.topicmap": Enter a comma-delimited list of Kafka topics mapped to Cosmos containers. For example:topic1#con1,topic2#con2. The field accepts regex pattern*[\\w.-]+ *#[^,]+(, *[\\w.-]+ *#[^,]+)*."output.data.format"(data going to the Kafka topic): Supports AVRO, JSON_SR (JSON Schema), PROTOBUF, or JSON (schemaless). Schema Registry must be enabled to use a Schema Registry-based format (for example, Avro, JSON_SR (JSON Schema), or Protobuf). See Schema Registry Enabled Environments for additional information."connect.cosmos.messagekey.enabled": Whether or not to set a Kafka message key. Defaults toid. To set a different field for the message key, add the configuration propertyconnect.cosmos.messagekey.field.
"kafka.auth.mode": Identifies the connector authentication mode you want to use. There are two options:SERVICE_ACCOUNTorKAFKA_API_KEY(the default). To use an API key and secret, specify the configuration propertieskafka.api.keyandkafka.api.secret, as shown in the example configuration (above). To use a service account, specify the Resource ID in the propertykafka.service.account.id=<service-account-resource-ID>. To list the available service account resource IDs, use the following command:confluent iam service-account list
For example:
confluent iam service-account list Id | Resource ID | Name | Description +---------+-------------+-------------------+------------------- 123456 | sa-l1r23m | sa-1 | Service account 1 789101 | sa-l4d56p | sa-2 | Service account 2
"tasks.max": Enter the maximum number of tasks for the connector to use. More tasks may improve performance.
Single Message Transforms: See the Single Message Transforms (SMT) documentation for details about adding SMTs using the CLI.
See Configuration Properties for all property values and descriptions.
Step 3: Load the properties file and create the connector¶
Enter the following command to load the configuration and start the connector:
confluent connect cluster create --config-file <file-name>.json
For example:
confluent connect cluster create --config-file azure-cosmos-source-config.json
Example output:
Created connector CosmosDbSourceConnector_0 lcc-do6vzd
Step 4: Check the connector status.¶
Enter the following command to check the connector status:
confluent connect cluster list
Example output:
ID | Name | Status | Type | Trace
+------------+----------------------------+---------+--------+-------+
lcc-do6vzd |CosmosDbSourceConnector_0 | RUNNING | Source | |
Step 5: Check for files.¶
Verify that data is being produced in Kafka.
For more information and examples to use with the Confluent Cloud API for Connect, see the Confluent Cloud API for Managed and Custom Connectors section.
Configuration Properties¶
Use the following configuration properties with the fully-managed connector. For self-managed connector property definitions and other details, see the connector docs in Self-managed connectors for Confluent Platform.
How should we connect to your data?¶
nameSets a name for your connector.
- Type: string
- Valid Values: A string at most 64 characters long
- Importance: high
Schema Config¶
schema.context.nameAdd a schema context name. A schema context represents an independent scope in Schema Registry. It is a separate sub-schema tied to topics in different Kafka clusters that share the same Schema Registry instance. If not used, the connector uses the default schema configured for Schema Registry in your Confluent Cloud environment.
- Type: string
- Default: default
- Importance: medium
Kafka Cluster credentials¶
kafka.auth.modeKafka Authentication mode. It can be one of KAFKA_API_KEY or SERVICE_ACCOUNT. It defaults to KAFKA_API_KEY mode.
- Type: string
- Default: KAFKA_API_KEY
- Valid Values: KAFKA_API_KEY, SERVICE_ACCOUNT
- Importance: high
kafka.api.keyKafka API Key. Required when kafka.auth.mode==KAFKA_API_KEY.
- Type: password
- Importance: high
kafka.service.account.idThe Service Account that will be used to generate the API keys to communicate with Kafka Cluster.
- Type: string
- Importance: high
kafka.api.secretSecret associated with Kafka API key. Required when kafka.auth.mode==KAFKA_API_KEY.
- Type: password
- Importance: high
How should we connect to your Cosmos DB database?¶
connect.cosmos.connection.endpointCosmos endpoint URL.
- Type: string
- Importance: high
connect.cosmos.master.keyCosmos connection master (primary) key.
- Type: password
- Importance: high
connect.cosmos.databasenameName of the database to read from.
- Type: string
- Importance: high
Database details¶
connect.cosmos.containers.topicmapA comma delimited list of Kafka topics mapped to Cosmos containers. For example: topic1#con1,topic2#con2.
- Type: string
- Valid Values: Must match the regex
\s*[\w.-]+ *#[^,]+(, *[\w.-]+ *#[^,]+)* - Importance: high
Connection details¶
connect.cosmos.task.timeoutThe maximum number of milliseconds the source task will use to read documents before sending them to Kafka.
- Type: int
- Default: 5000
- Importance: low
connect.cosmos.task.buffer.sizeThe max size the container of documents (in bytes) the source task will buffer before sending them to Kafka.
- Type: int
- Default: 10000
- Valid Values: [1,…,1000000]
- Importance: low
connect.cosmos.task.batch.sizeThe max number of documents the source task will buffer before sending them to Kafka.
- Type: int
- Default: 100
- Valid Values: [1,…]
- Importance: low
connect.cosmos.task.poll.intervalThe polling interval in milliseconds that a source task polls for changes.
- Type: int
- Default: 1000
- Importance: low
Output messages¶
output.data.formatSets the output Kafka record value format. Valid entries are AVRO, JSON_SR, PROTOBUF, or JSON. Note that you need to have Confluent Cloud Schema Registry configured if using a schema-based message format like AVRO, JSON_SR, and PROTOBUF
- Type: string
- Importance: high
connect.cosmos.messagekey.enabledWhether to set the Kafka message key.
- Type: boolean
- Default: true
- Importance: high
connect.cosmos.messagekey.fieldThe document field to use as the message key.
- Type: string
- Default: id
- Importance: high
Number of tasks for this connector¶
tasks.maxMaximum number of tasks for the connector.
- Type: int
- Valid Values: [1,…]
- Importance: high
Next Steps¶
For an example that shows fully-managed Confluent Cloud connectors in action with Confluent Cloud ksqlDB, see the Cloud ETL Demo. This example also shows how to use Confluent CLI to manage your resources in Confluent Cloud.
