マルチリージョンクラスターのアーキテクチャパターン¶
概要¶
Confluent Cloud と Confluent Platform は、たとえばディザスターリカバリや移行の目的で、または地理的な理由から、複数のリージョン(データセンター)で使用されることがよくあります。Confluent Cloud と Confluent Platform には、マルチリージョンアーキテクチャをサポートするいくつかの機能と製品が含まれています。
以降のセクションでは、一般的なマルチリージョンアーキテクチャについて、ユースケースや高レベルでの実装に関する推奨事項とともに説明します。
マルチリージョンアーキテクチャを理解して検討するには、イベントストリーミングに関する十分な知識が必要です。これらのアーキテクチャを検討するときは、ガイダンスについて Confluent にお問い合わせください。
用語¶
| 用語 | 説明 |
|---|---|
| 目標復旧時点(RPO) | 障害が発生した場合に、フェイルオーバーによってデータの履歴のどの時点から再開する必要があるかを表します。つまり、障害の発生時に許容できるデータの損失量と言い換えることもできます。RPO をゼロにするには、同期レプリケーションが必要です。 |
| 目標復旧時間(RTO) | 障害が発生した場合に、フェイルオーバーの完了までに許容される経過時間を表します。つまり、フェイルオーバー操作にかかる時間です。RTO をゼロにするには、シームレスなクライアントフェイルオーバーが必要です。 |
| リージョン | データセンターと同様の意味を持ちます。"完全稼働リージョン" では、アプリケーションのインフラストラクチャのすべてを実行できます。"軽量リージョン" では、1 つの ZooKeeper ホストなど、ごく小規模なインフラストラクチャのみを実行できます。 |
| エンドユーザー | Confluent を使用しているアプリケーションを使用する人またはコンピューター。 |
| アプリケーション | エンドユーザーにインターフェイスを提供し、バックエンドの Confluent Cloud または Confluent Platform とやり取りを行うソフトウェア。 |
| ディザスターリカバリ(DR) | 災害(このドキュメントの文脈ではリージョン全体の障害)からのアプリケーションの復旧を可能にする、アーキテクチャ、実装、ツール、ポリシー、手順をまとめて表す包括的な用語。 |
| 高可用性(HA) | 高可用性システムは、障害の発生時にも操作を継続することができます。マルチリージョンアーキテクチャのコンテキストでは、Confluent を基盤とする高可用性アプリケーションは、リージョン全体で障害が発生しても運用を継続できます。HA アプリケーションには、ディザスターリカバリポリシーが用意されています。 |
| Event | Confluent Cloud または Confluent Platform との間で生成または消費される単一のメッセージ。 |
| ミリ秒(ms) | 1 秒の 1/1000。 |
マルチリージョンを導入する理由¶
次の 1 つ以上の理由から、マルチリージョンアーキテクチャはアプリケーションにとって利点となる可能性があります。
- リージョン障害時のディザスターリカバリ: リージョン全体の障害が発生した場合、マルチリージョンアーキテクチャでは、別のリージョンにフェイルオーバーして RTO および RPO を短縮できます。
- グローバル操作のレイテンシを最小化: 地域に応じて、たとえば北米のエンドユーザーは北米のリージョンに接続し、ヨーロッパのエンドユーザーはヨーロッパのリージョンに接続します。これにより、各エンドユーザーのレイテンシが最小限に抑えられます。
- データ主権: 特定の主権に含まれるエンドユーザーのデータは、その主権を維持する必要があり、主権から逸脱する場合は集約または匿名化しなければなりません。
- データガバナンス: データ主権と同様に、アプリケーションによっては、主権に関する法規制によらなくても、特定のデータが特定のリージョンまたはネットワークの外部に流出しないようにすることを求めるものがあります。
- ネットワーク分離: アプリケーションによっては、ネットワークセキュリティを強化するために、ネットワーク DMZ の内側で、または DMZ を通じて Confluent Platform を使用するものがあります。
マルチリージョンを導入しない理由¶
すべてのアプリケーションにマルチリージョンアーキテクチャが求められるわけではありません。たとえば、多くのスタートアップ企業では、リージョン全体の障害時に低 RPO や 低 RTO を要求する SLA はありません。
さらに、単一リージョンアーキテクチャの方がシンプルであり、運用と管理が簡単です。
マルチクラスターレプリケーション(ミラーリング)¶
マルチクラスターレプリケーションアーキテクチャでは、1 つのリージョン内の一部またはすべてのイベントが、別のリージョンにレプリケート(ミラーリング)されます。これらのリージョンは、それぞれ送信元と送信先と呼ばれることがあります。
このアーキテクチャでは、RPO や RTO を短縮する試みは行われません。代わりにこのアーキテクチャは、移行などのさまざまなユースケースで必要とされます。技術的には、前述の 2 リージョンアーキテクチャもマルチクラスターレプリケーションアーキテクチャです。
このアーキテクチャが適するシナリオについては、このアーキテクチャのユースケースを参照してください。
使用に適する状況¶
このアーキテクチャは、次のユースケースのいずれかで使用します。
使用に適さない状況¶
高可用性やディザスターリカバリのためにマルチリージョンアーキテクチャが求められる場合は、このアーキテクチャを使用しないでください。
ユースケース¶
セルフマネージド型の Confluent Platform から Confluent Cloud への移行¶
アプリケーションでの Confluent の利用方法をセルフマネージド型の Confluent Platform デプロイから Confluent Cloud に移行する場合は、レプリケーションアーキテクチャを使用して、アプリケーションのイベントとコンポーネントを少しずつ Confluent Cloud に移行します。この段階的な方法により、管理しやすい小規模なチャンク単位で移行を進めることができるため、移行が原因で発生するダウンタイムを短縮または削減できる可能性があります。
リフトアンドシフト移行¶
リフトアンドシフト移行は、セルフマネージド型の Confluent Platform から Confluent Cloud への移行と非常によく似ています。ただし、元のアプリケーションが代替メッセージングシステムを使用している可能性があります。
このユースケースでは、レプリケーションコンポーネントを使用するのではなく、ソースコネクターまたはブリッジを使用します。Cluster Linking、Replicator、MirrorMaker のようなレプリケーションコンポーネントは、いずれも 1 つの Confluent Platform クラスターから別のクラスターにイベントをレプリケートするのに対して、ソースコネクターやブリッジは、代替メッセージングシステムから読み取って Confluent クラスターに生成するように設計されています。
ネットワーク分離¶
アプリケーションによっては、特定のイベントを特定のリージョンまたはネットワークでのみ利用できるようにし、他のイベントを分離されたリージョンまたはネットワークで利用できるようにすることが必要な場合があります。
このようなアプリケーションでは、多くの場合、リージョンまたはネットワークごとに独立した Confluent クラスターを使用し、1 つのクラスターを別のクラスターにレプリケートします。
データガバナンス¶
データガバナンスのユースケースは、上記のネットワーク分離のユースケースと非常によく似ています。ただし、イベントが特定のリージョンに制限されるのはネットワークセキュリティ以外の理由によります。後述の集約アーキテクチャも参照してください。
実装に関する推奨事項¶
- Cluster Linking を使用します。
2 リージョン、アクティブ/パッシブ¶
2 リージョンのアクティブ/パッシブアーキテクチャには 2 つの完全稼働リージョンが含まれ、それぞれが別個の Confluent クラスターを実行します。一方のクラスターは、すべての生成リクエストと消費リクエストに対応する "アクティブ" クラスターです。2 番目の "パッシブ" クラスターは "アクティブ" クラスターのコピーですが、これに対してアプリケーションは実行されません。"アクティブ" リージョンで障害が発生すると、アプリケーションは "パッシブ" リージョンにフェイルオーバーします。2 リージョンのアクティブ/アクティブアーキテクチャとの主な違いとして、アクティブ/パッシブアーキテクチャでは、アプリケーションが実行されるのは通常の運用状況でも一方のリージョンだけです。
このアーキテクチャでは、RPO と RTO は 0 より大きくなります。RPO が 0 より大きいのは、リージョン間レプリケーションが非同期であるためです。アプリケーションを別の Confluent クラスターにフェイルオーバーする必要があるため、RTO は 0 より大きくなります。
このアーキテクチャでは、アプリケーション全体がアクティブリージョン内で実行され、ローカルリージョンから生成および消費します。ローカルのアクティブリージョンに生成されたイベントはすべて、パッシブバックアップリージョンに非同期にレプリケートされます。
フェイルオーバーがトリガーされると、アプリケーションがパッシブリージョンで起動され、パッシブリージョンから生成および消費します。
使用に適する状況¶
利用可能なリージョンが 2 つだけの場合、ネットワークレイテンシが 50 ミリ秒より大きい場合、または通常の運用状況でアプリケーションを実行するリージョンを 1 つだけにする必要がある場合は、このアーキテクチャを使用することを検討します。
使用に適さない状況¶
RTO や RPO を 0 または 0 に近い値にする必要がある場合は、このアーキテクチャを使用しないでください。
ユースケース¶
オンプレミスと限定されたリージョン¶
このアーキテクチャは、複数のリージョンへのアクセスに制限のあるオンプレミスの顧客に選択されることがよくあります。たとえば、顧客の環境は、1 つのプライマリ("アクティブ")リージョンと、ディザスターリカバリのシナリオでのみ使用される小規模な("パッシブ")リージョンで構成されていることがあります。
短期的なディザスターリカバリ¶
スタートアップ企業や Confluent の導入初期にある企業では、より低い RTO や RPO を実現する高度なアーキテクチャを実装するまでの短期的なディザスターリカバリソリューションとして、このアーキテクチャを選択することがあります。
実装に関する推奨事項¶
Cluster Linking を使用します。
2 リージョン、アクティブ/アクティブ¶
2 リージョンのアクティブ/アクティブアーキテクチャには 2 つの完全稼働リージョンが含まれ、それぞれが別個の Confluent クラスターを実行します。各クラスターは、もう 1 つのクラスターのコピーです。1 つのリージョンで障害が発生すると、アプリケーションはもう 1 つのリージョンにフェイルオーバーします。
このアーキテクチャでは、RPO は 0 より大きく、RTO は 0 とほぼ同じになります。RPO が 0 より大きいのは、リージョン間レプリケーションが非同期であるためです。常に少なくとも 1 つのリージョンが実行されているため、RTO は非常に低い値にすることができます。アーキテクチャでは、障害を検出する必要があり、(ロードバランサーや DNS などを使用して)トラフィックアップストリームを残りのアクティブクラスターに転送します。RTO を 0 に近づけるには、アプリケーションを両方の完全稼働リージョンにデプロイする必要があります。
RTO=0 を実現するには、アプリケーションを両方の完全稼働リージョンにデプロイする必要があります。ほとんどの場合、各エンドユーザーは、たとえば地理的な DNS ルーティングによって 1 つのリージョンにのみ接続します。リージョンで障害が発生すると、エンドユーザーは別のアクティブなリージョンに送られます。
使用に適する状況¶
利用可能な完全稼働リージョンが 2 つだけの場合、またはリージョン間のネットワークレイテンシが 50 ミリ秒を超える場合は、このアーキテクチャを使用することを検討します。
また、このアーキテクチャは、アプリケーションを 2 つのリージョンで同時に実行できる場合にのみ検討してください。
使用に適さない状況¶
一方のリージョンの処理能力が他方よりも低い場合や、慣習的または機能的な理由でアプリケーションの 2 つのコピーを同時に実行できない場合など、アプリケーションを 2 つのリージョンでアクティブに実行できないときは、このアーキテクチャを使用することはできません。
ユースケース¶
消費者銀行¶
多くの消費者銀行では、RPO と RTO を低く抑えるかゼロにする必要があり、単一の国内または大陸内の消費者のみを対象としています。ただし、オンプレミスで運用している消費者銀行では、完全稼働リージョンが 2 つしか利用できないことがあり、その場合はこのアーキテクチャが理想的です。
電気通信¶
電気通信も、消費者銀行とよく似た特性を持つ傾向があります。つまり、RPO と RTO を低く抑えるかゼロにする必要があり、単一の国内または大陸内の消費者を対象とし、2 つの完全稼働リージョンにのみアクセスします。
実装に関する推奨事項¶
Cluster Linking を使用します。
集約(ハブとスポーク)¶
集約アーキテクチャには 1 つまたは多数のリージョンが含まれ、それぞれが独自のローカル Confluent クラスターとアプリケーションを実行します。ローカルイベントのすべてまたはサブセットが、単一の集約 Confluent クラスターにレプリケートされます。通常、集約クラスターはローカルクラスターよりも大規模です。集約クラスターは "ハブ" と呼ばれ、他のリージョンは "スポーク" と呼ばれることがあります。
このアーキテクチャでは、RPO は 0 より大きく、RTO は 0 以上になります。RPO が 0 より大きいのは、リージョン間レプリケーションが非同期であるためです。RTO は、エンドユーザーを自動的に別のリージョンにリダイレクトできる場合にゼロとなります。それ以外の場合、RTO は 0 よりも大きくなります。
集約アーキテクチャは一般に、次のいずれかのシナリオで使用されます。
各スポークリージョンでローカル地域の顧客にサービスを提供しながら、すべてのイベントのグローバルなビューも必要となるようなグローバル操作をサポートする場合。
データガバナンスをサポートするために、チームごとに独立した Confluent クラスターを使用する環境で、チームをまたいだイベントを必要とするアプリケーション向けに、イベントを集約クラスターにレプリケートする場合。これらのクラスターは、同じリージョン内で実行することも、分離されたリージョンで実行することもできます。
使用に適する状況¶
グローバルアプリケーションでは、各アプリケーションインスタンスを互いに独立して実行できる場合、エンドユーザーのレイテンシが低い場合、データセンター間のネットワークレイテンシが 50 ミリ秒よりも大きい場合、および分析などの目的でイベントを集約する必要がある場合にのみ、このアーキテクチャを使用できます。
データガバナンスの目的では、アプリケーションのデータガバナンス要件を満たすために厳密に分離されたクラスターが必要な場合にのみ、このアーキテクチャを使用できます。
使用に適さない状況¶
アプリケーションが本当にグローバルでない場合は、このアーキテクチャを使用しないでください。また、Confluent のネイティブのデータガバナンス機能によってアプリケーションのデータガバナンス要件に十分に対応できる場合も、このアーキテクチャを使用しないでください。
ユースケース¶
デジタル広告のクリックおよびインプレッション追跡¶
スポークリージョンでは、ローカル Confluent クラスターを使用して、地域向けの広告配信アプリケーションと広告追跡アプリケーションを実行します。各スポーククラスターは、より大きな Confluent クラスターを実行している集約ハブリージョンにクリックとインプレッションのデータをレプリケートし、そこで広告分析が実行されます。
オンラインゲーム¶
オンラインゲームの多くのユースケースは、デジタル広告のクリックおよびインプレッション追跡のユースケースと同様ですが、異なる点として、スポークリージョンがゲームサーバーを実行し、ハブクラスターがゲーム分析を実行します。
実店舗およびオンラインの小売業¶
実店舗を持つ小売業者や e コマースの小売業者では、ローカルアプリケーションをサポートする Confluent Cluster をそれぞれの店舗("スポーク")で運用することがよくあります。ハブクラスターとの間でイベントがレプリケートされ、分析や在庫情報の更新などが行われます。
接客業¶
上記の小売業者と同様に、接客業者でも、ローカルアプリケーションをサポートするオンサイトの Confluent クラスター("スポーク")と、分析用のハブクラスターを運用することがよくあります。
実装に関する推奨事項¶
スポーククラスターからハブクラスターにイベントをレプリケートするには、Cluster Linking を使用します。
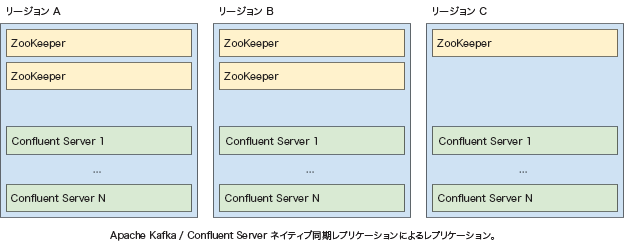
ストレッチクラスター 3 リージョン¶
ストレッチ 3 リージョンクラスターアーキテクチャには、ネットワークレイテンシが 50 ミリ秒以内(ping による)のリージョンが 3 つ含まれます。Confluent Server と ZooKeeper が 3 つのリージョンに均等に配置され、単一のストレッチクラスターを形成します。
ストレッチクラスターでは、RPO=0 と RTO=0 が実現されます。
ストレッチクラスターがデプロイされる環境として最も一般的なのは、3 つのアベイラビリティゾーン(AZ)を持つパブリッククラウドリージョンです。この場合、各アベイラビリティゾーンは疑似リージョンと見なされ、1 つの AZ で障害が発生しても Confluent クラスターの可用性は維持されます。ただし、リージョン全体で障害が発生した場合は、Confluent クラスターが利用不可能になることがあります。
ストレッチクラスターアーキテクチャはパブリッククラウドの外部でも使用され、パブリッククラウドリージョン間で使用されることもあります。たとえば、米国では、パブリッククラウドでもオンプレミスでも、西部、中部、東部のリージョンで 1 つのストレッチクラスターを構成することができます。この場合、リージョン全体で障害が発生しても、Confluent クラスターは利用可能な状態に保たれます。
Confluent Cloud の 標準 および 専用 クラスターを、1 つのリージョン内の 3 つの AZ に広がるストレッチクラスターとしてプロビジョニングできます。
使用に適する状況¶
- ストレッチクラスターは、3 つの完全稼働リージョンで Confluent を実行でき、すべてのリージョン間のネットワークレイテンシが 50 ミリ秒以下の場合に使用します。
- ストレッチクラスターは、アプリケーションが一度に 1 つのリージョンの障害に耐えられれば十分である場合に使用します。ストレッチクラスターアーキテクチャでは、2 つの完全稼働リージョンで障害が発生した場合は動作を継続できません。これは、ZooKeeper クォーラムが不完全になるためです。
- ストレッチクラスターアーキテクチャは、単一の国内または小規模な大陸内に配置されるアプリケーションで最もよく使用されます。
使用に適さない状況¶
- 大陸をまたぐ場合など、リージョン間のネットワークレイテンシが 50 ミリ秒を超える場合は、ストレッチクラスターを使用しないでください。
- 利用できる完全稼働リージョンが 3 つよりも少ない場合は、ストレッチクラスターを使用しないでください。
ユースケース¶
消費者銀行¶
多くの消費者銀行では、RPO と RTO を低く抑えるかゼロにする必要があり、単一の国内または大陸内の消費者のみを対象としています。多くの場合、このような消費者銀行では、特に消費者に接するアプリケーションのためにストレッチクラスターを使用して、1 つの国または大陸に 3 つのリージョンを展開します。たとえば、米国では、西部、中部、東部というリージョンがよく使用されます。
ちなみに
RPO と RTO をゼロに近づける方法について詳しくは、ブログ記事「Automatic Observer Promotion Brings Fast and Safe Multi-Datacenter Failover with Confluent Platform 6.1」を参照してください。以下で取り上げるユースケースを補完する内容となっています。
電気通信¶
通常、電気通信には消費者銀行とよく似た特性があります。つまり、RPO と RTO を低く抑えるかゼロにする必要があり、単一の国内または大陸内の消費者を対象としています。このような特性はストレッチクラスターアーキテクチャに適しています。
ちなみに
RPO と RTO をゼロに近づける方法について詳しくは、ブログ記事「Automatic Observer Promotion Brings Fast and Safe Multi-Datacenter Failover with Confluent Platform 6.1」を参照してください。以下で取り上げるユースケースを補完する内容となっています。
実装に関する推奨事項¶
Confluent をデプロイしてラック認識を構成し、Confluent Server および ZooKeeper ホストをリージョン間に均等に配置します。ラック認識によりレプリカの配置を確認して、各リージョン(ラック)に少なくとも 1 つのトピックパーティションレプリカが存在するようにします。
5 台のホストの ZooKeeper デプロイでは、2 つのリージョンに ZooKeeper ホストを 2 台ずつ配置し、3 番目のリージョンに 1 台の ZooKeeper ホストを配置します。
アーキテクチャ図¶
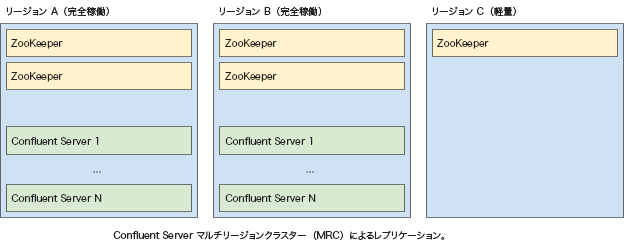
ストレッチクラスター 2.5 リージョン(Confluent Platform のみ)¶
ストレッチ 2.5 リージョンアーキテクチャには、2 つの完全稼働リージョンと 1 つの軽量(0.5)リージョンが含まれ、1 つのストレッチクラスターを実行します。完全稼働リージョンでは同数の Confluent Server および ZooKeeper ホストを実行し、軽量リージョンでは 1 つの ZooKeeper を実行します。いずれか 1 つのリージョンで障害が発生しても、ZooKeeper クォーラムは利用可能な状態が維持されます。完全稼働リージョンで障害が発生した場合、アプリケーションは他のリージョンにフェイルオーバーします。
このアーキテクチャでは、RPO は 0 より大きく、RTO は 0 以上になります。RPO が 0 より大きいのは、リージョン間レプリケーションが非同期であるためです。RTO は、アプリケーションインスタンスが各リージョンで動作している場合にゼロになります。そうでない場合は、アプリケーションを別のリージョンにフェイルオーバーする必要があるため、RTO は 0 より大きくなります。
使用に適する状況¶
利用可能な完全稼働リージョンが 2 つだけの場合、軽量リージョンを 1 つ利用できるのであれば、このアーキテクチャを使用することを検討します。各リージョン間のネットワークレイテンシは 50 ミリ秒以内であることが必要です。
使用に適さない状況¶
リージョン間のレイテンシが 50 ミリ秒を超える場合や、合計で 2 つのリージョンしか利用できない場合は、このアーキテクチャを使用しないでください。
ユースケース¶
消費者銀行¶
多くの消費者銀行では、RPO と RTO を低く抑えるかゼロにする必要があり、単一の国内または大陸内の消費者のみを対象としています。ただし、オンプレミスで運用している消費者銀行では、3 つの完全稼働リージョンを利用できるとは限りません。その場合には、このアーキテクチャが有力な選択肢となります。通常、3 番目の軽量リージョンはパブリッククラウドリージョンです。ZooKeeper には Confluent クラスターに関するメタデータしか含まれないため、パブリッククラウドでの ZooKeeper の実行が情報セキュリティチームに問題視されることはほとんどありません。
電気通信¶
通常、電気通信には消費者銀行とよく似た特性があります。つまり、RPO と RTO を低く抑えるかゼロにする必要があり、単一の国内または大陸内の消費者を対象とし、2 つの完全稼働リージョンと 1 つの軽量リージョンにアクセスします。
実装に関する推奨事項¶
3 つのすべてのリージョンに ZooKeeper をデプロイします。5 台のホストの ZooKeeper クラスターでは、1 つの完全稼働リージョンに 2 台、もう 1 つの完全稼働リージョンに 2 台をデプロイし、軽量リージョンに 5 台目をデプロイします。同数の Confluent Server ホストを完全稼働リージョンにデプロイします。
Multi-Region Clusters を有効にして、自己昇格型オブザーバーとともに構成します。トピックを作成して、各トピックが 1 つのリージョンにレプリカを持ち、もう 1 つのリージョンにオブザーバーを持つようにします。
完全稼働リージョンの 1 つで障害が発生した場合、アプリケーションが両方のリージョンで実行されていれば、自動的にフェイルオーバーが行われます。ただし、障害の起きたリージョンで特定のアプリケーションが実行されていると、障害の程度によっては、それらのアプリケーションを 2 番目のリージョンで再起動することが必要になる場合があります。
MRC は Confluent Platform でのみ使用可能であることに注意してください。
アーキテクチャ図¶
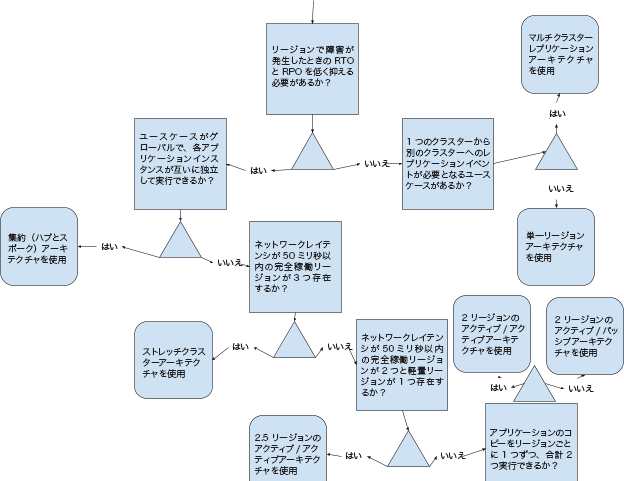
ユースケースに最適なアーキテクチャの選択¶
どのアーキテクチャが最適かを判断するには、以下のデシジョンツリーを使用します。
最初に述べたとおり、マルチリージョンアーキテクチャを理解して検討するには、イベントストリーミングに関する十分な知識が必要です。これらのアーキテクチャを検討するときは、ガイダンスについて Confluent にお問い合わせください。
マルチリージョンオプションの比較チャート¶
| 製品 | Confluent Cloud のサポート | RPO | RTO | 説明 |
|---|---|---|---|---|
| ネイティブの Apache Kafka® および Confluent Server レプリケーション | ○ | 0 | 0 | Kafka、Confluent Server は、トピックパーティションレプリカ間でネイティブにイベントを同期レプリケートします。 |
| Cluster Linking | あり、Confluent Cloud へのセルフマネージド型接続 | > 0 | > 0 | Cluster Linking は、一方のクラスターから他方のクラスターにトピックとメタデータを完全にミラーリングし、Confluent Server ブローカーに組み込まれます。 |
| MirrorMaker | あり、Confluent Cloud へのセルフマネージド型接続 | > 0 | > 0 | KIP-382 |
| Multi-Region Clusters | いいえ | > 0 | >= 0 | マルチリージョンクラスター(MRC)は、シームレスなフェイルオーバーとシンプルなマルチリージョンアーキテクチャをサポートする機能セットです。 |