Important
You are viewing documentation for an older version of Confluent Platform. For the latest, click here.
KSQL and Kafka Streams¶
KSQL is the streaming SQL engine for Apache Kafka®. With KSQL, you can write real-time streaming applications by using a SQL-like query language.
Kafka Streams is the Apache Kafka® library for writing streaming applications and microservices in Java and Scala.
KSQL is built on Kafka Streams, a robust stream processing framework that is part of Kafka.
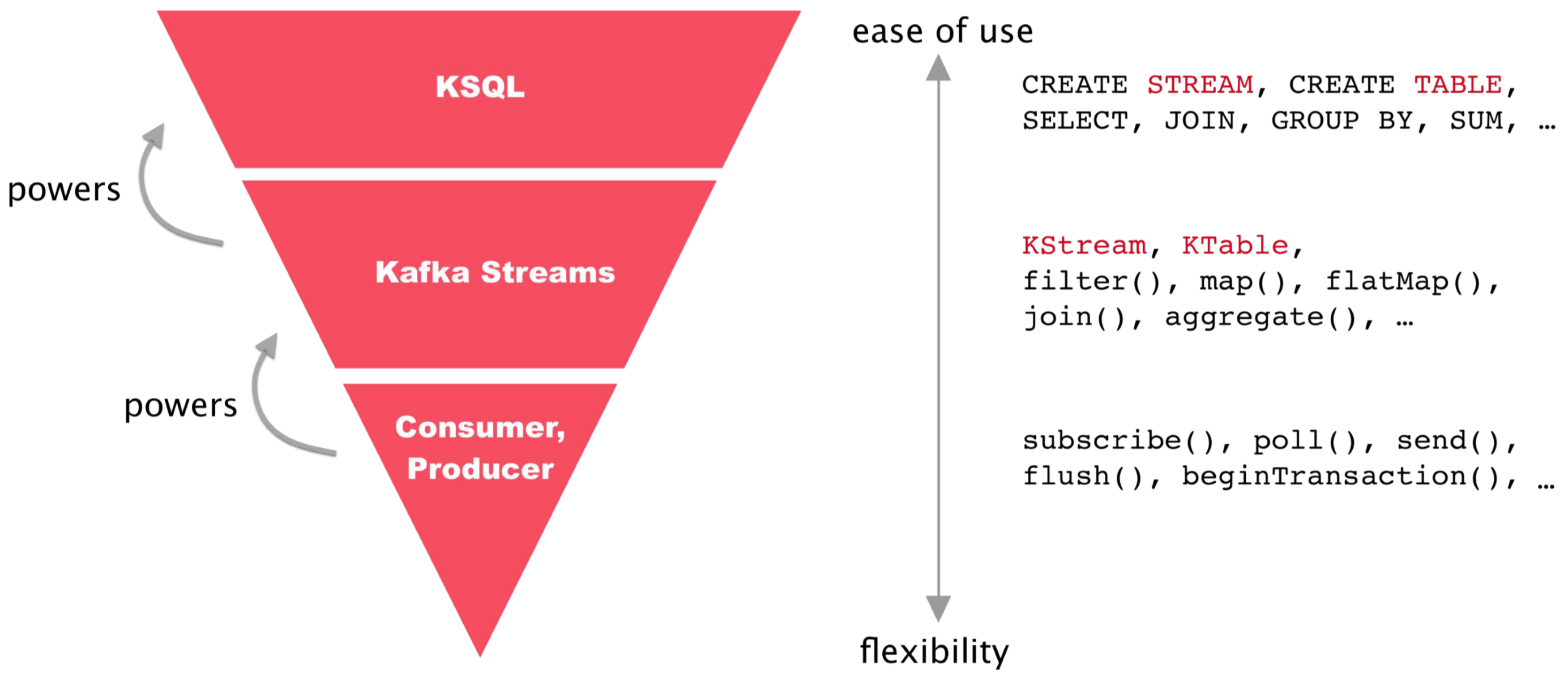
KSQL gives you the highest level of abstraction for implementing real-time streaming business logic on Kafka topics. KSQL automates much of the complex programming that’s required for real-time operations on streams of data, so that one line of KSQL can do the work of a dozen lines of Java and Kafka Streams.
For example, to implement simple fraud-detection logic on a Kafka topic named
payments, you could write one line of KSQL:
CREATE STREAM fraudulent_payments AS
SELECT fraudProbability(data) FROM payments
WHERE fraudProbability(data) > 0.8;
The equivalent Java code on Kafka Streams might resemble:
// Example fraud-detection logic using the Kafka Streams API.
object FraudFilteringApplication extends App {
val builder: StreamsBuilder = new StreamsBuilder()
val fraudulentPayments: KStream[String, Payment] = builder
.stream[String, Payment]("payments-kafka-topic")
.filter((_ ,payment) => payment.fraudProbability > 0.8)
fraudulentPayments.to("fraudulent-payments-topic")
val config = new java.util.Properties
config.put(StreamsConfig.APPLICATION_ID_CONFIG, "fraud-filtering-app")
config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-broker1:9092")
val streams: KafkaStreams = new KafkaStreams(builder.build(), config)
streams.start()
}
KSQL is easier to use, and Kafka Streams is more flexible. Which technology you choose for your real-time streaming applications depends on a number of considerations. Keep in mind that you can use both KSQL and Kafka Streams together in your implementations.
Differences Between KSQL and Kafka Streams¶
The following table summarizes some of the differences between KSQL and Kafka Streams.
| Differences | KSQL | Kafka Streams |
|---|---|---|
| You write: | KSQL statements | JVM applications |
| Graphical UI | Yes, in Confluent Control Center | No |
| Console | Yes | No |
| Data formats | Avro, JSON, CSV | Any data format, including Avro, JSON, CSV, Protobuf, XML |
| REST API included | Yes | No, but you can implement your own |
| Runtime included | Yes, the KSQL server | Applications run as standard JVM processes |
| Queryable state | No | Yes |
Developer Workflows¶
There are different workflows for KSQL and Kafka Streams when you develop streaming applications.
- KSQL
- You write KSQL queries interactively and view the results in real-time, either in the KSQL CLI or in Confluent Control Center. You can save a .sql file and deploy it to production as a “headless” application, which runs without a GUI, CLI, or REST interface on KSQL servers.
- Kafka Streams
- You write code in Java or Scala, recompile, and run and test the application in an IDE, like IntelliJ. You deploy the application to production as a jar file that runs in a Kafka cluster.
KSQL and Kafka Streams: Where to Start?¶
Use the following table to help you decide between KSQL and Kafka Streams as a starting point for your real-time streaming application development.
| Start with KSQL when… | Start with Kafka Streams when… |
|---|---|
|
|
Usually, KSQL isn’t a good fit for BI reports, ad-hoc querying, or queries with random access patterns, because it’s a continuous query system on data streams.
To get started with KSQL, try the KSQL Tutorials and Examples.
To get started with Kafka Streams, try the Tutorial: Creating a Streaming Data Pipeline.