Important
You are viewing documentation for an older version of Confluent Platform. For the latest, click here.
Tutorial: Replicating Data Between Clusters¶
This guide describes how to start two Apache Kafka® clusters and then a Replicator process to replicate data between them. Note that for tutorial purposes, we are running both clusters on the same machine. In order to do that, we jump through a hoop or two to make sure each cluster has its own ports and data directories. You will not need to perform these changes on the ZooKeeper and Broker configuration if you are running in a normal environment where each cluster has its own servers.
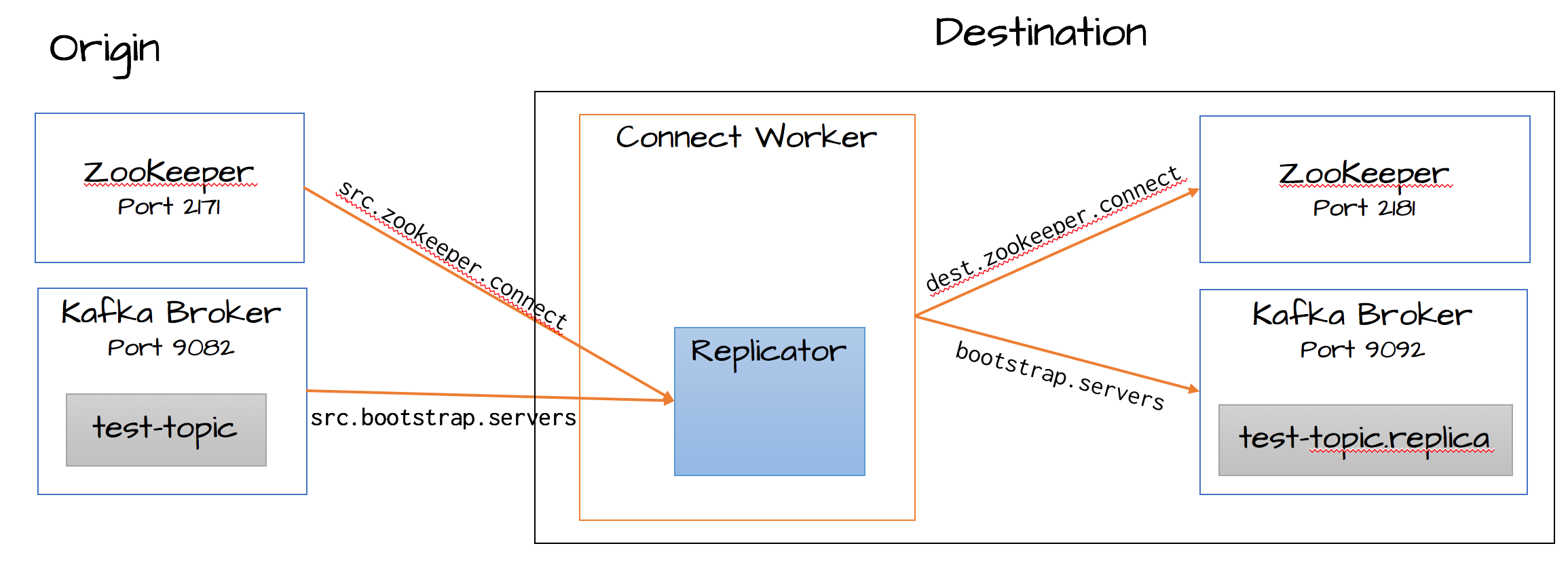
Replicator Quick Start Configuration
Start the destination cluster¶
First, startup a ZooKeeper server. In this guide, we are assuming services will run on localhost.
# Start ZooKeeper. Run this command in its own terminal.
<path-to-confluent>/bin/zookeeper-server-start <path-to-confluent>/etc/kafka/zookeeper.properties
Tip
These instructions assume you are installing Confluent Platform by using ZIP or TAR archives. For more information, see On-Premises Deployments.
Next, startup a Kafka broker that will serve as our single node Kafka cluster.
# Start Kafka. Run this command in its own terminal.
<path-to-confluent>/bin/kafka-server-start <path-to-confluent>/etc/kafka/server.properties
For complete details on getting these services up and running see the quick start instructions for Confluent Platform.
Note
The destination cluster should be running the same (or higher) version of Confluent Platform as the source cluster (the reason for this is that Replicator runs within a Connect Cluster linked to the destination cluster, and it reads messages from the source cluster – so will not be able to interpret this message format if the destination is runnind an older version).
Start the origin cluster¶
While we configured the destination cluster to run on default ports, we will need to run the origin cluster on a different port to avoid collisions. The Kafka in the origin cluster is configured on port 9082, ZooKeeper is configured on 2171. Copy the configuration files to a temporary location and modify them so they do not conflict with the destination cluster.
#Copy the config files to /tmp
cp <path-to-confluent>/etc/kafka/zookeeper.properties /tmp/zookeeper_origin.properties
cp <path-to-confluent>/etc/kafka/server.properties /tmp/server_origin.properties
#Update the port numbers
sed -i '' -e "s/2181/2171/g" /tmp/zookeeper_origin.properties
sed -i '' -e "s/9092/9082/g" /tmp/server_origin.properties
sed -i '' -e "s/2181/2171/g" /tmp/server_origin.properties
sed -i '' -e "s/#listen/listen/g" /tmp/server_origin.properties
#Update data directories
sed -i '' -e "s/zookeeper/zookeeper_origin/g" /tmp/zookeeper_origin.properties
sed -i '' -e "s/kafka-logs/kafka-logs-origin/g" /tmp/server_origin.properties
From here, you can start up the origin cluster.
# Start ZooKeeper. Run this command in its own terminal.
<path-to-confluent>/bin/zookeeper-server-start /tmp/zookeeper_origin.properties
# Start Kafka. Run this command in its own terminal.
<path-to-confluent>/bin/kafka-server-start /tmp/server_origin.properties
Create a topic¶
Now, lets create a topic named “test-topic” in the origin cluster with the following command:
<path-to-confluent>/bin/kafka-topics --create --topic test-topic --replication-factor 1 --partitions 1 --zookeeper localhost:2171
Once we configure and run Replicator, this topic will get replicated to the destination cluster with the exact configuration we defined above. Note that for the sake of this example, we created a topic with just one partition. Replicator will work with any number of topics and partitions.
Configure and run Replicator¶
Confluent Replicator runs as a Connector in the Kafka Connect framework. In the quick start guide we will start a stand-alone Connect Worker process that runs Replicator as a Connector. For complete details on Connect see Kafka Connect.
The script that runs the stand-alone Connect Worker takes two configuration files. The first is the configuration for the Connect Worker itself and the second is the configuration for the Replicator.
Note
Replicator is responsible for reading events from the origin cluster. It then passes the events to the Connect Worker which is responsible for writing the events to the destination cluster. Therefore we configure Replicator with information about the origin and the Worker with information about the destination.
We’ll start by configuring the Connect Worker, and then configure Replicator.
The Worker configuration file is <path-to-confluent>/etc/kafka/connect-standalone.properties, edit the file and make sure it contains the addresses of brokers from the destination cluster. The default broker list will match the destination cluster we started earlier:
# Connect Standalone Worker configuration
bootstrap.servers=localhost:9092
Next, we will look at the Replicator configuration file, <path-to-confluent>/etc/kafka-connect-replicator/quickstart-replicator.properties:
name=replicator
connector.class=io.confluent.connect.replicator.ReplicatorSourceConnector
tasks.max=4
key.converter=io.confluent.connect.replicator.util.ByteArrayConverter
value.converter=io.confluent.connect.replicator.util.ByteArrayConverter
src.kafka.bootstrap.servers=localhost:9082
src.zookeeper.connect=localhost:2171
dest.zookeeper.connect=localhost:2181
topic.whitelist=test-topic
topic.rename.format=${topic}.replica
Note
Starting with version 4.1.0, configuring direct connections to ZooKeeper through Replicator properties is now optional. If omitted, Replicator will contact Kafka for topic management, metadata refresh as well as for storing the Confluent license. The changes required in order to use the new functionality are minimal, and can be enabled selectively for the origin, the destination, both, or neither.
Below you see how Replicator’s properties change when Replicator is configured to use Kafka as its direct point of contact, both in the origin and the destination. To use Replicator this way, edit <path-to-confluent>/etc/kafka-connect-replicator/quickstart-replicator.properties to reflect the alternative configuration as follows:
name=replicator-sans-zk
connector.class=io.confluent.connect.replicator.ReplicatorSourceConnector
tasks.max=4
key.converter=io.confluent.connect.replicator.util.ByteArrayConverter
value.converter=io.confluent.connect.replicator.util.ByteArrayConverter
src.kafka.bootstrap.servers=localhost:9082
dest.kafka.bootstrap.servers=localhost:9092
# Store license, trial or regular, in Kafka instead of Zookeeper.
# Default: confluent.topic=_command-topic
# Default: confluent.topic.replication.factor=3
# replicator.factor may not be larger than the number of Kafka brokers in the destination cluster.
# Here we set this to '1' for demonstration purposes. Always use at least '3' in production configurations.
confluent.topic.replication.factor=1
topic.whitelist=test-topic
topic.rename.format=${topic}.replica
In both examples, a few of the configuration parameters are important to understand and we’ll explain them here. You can read an explanation of all the configuration parameters in here.
key.converterandvalue.converter- Classes used to convert Kafka records to Connect’s internal format. The Connect Worker configuration specifies global converters and the default is JsonConverter. For Replication, however, no conversion is necessary. We just want to read bytes out of the origin cluster and write them to the destination with no changes. So we override the global converters with the ByteArrayConverter which just leaves the records as is.src.zookeeper.connectanddest.zookeeper.connect- Connection strings for ZooKeeper in the origin and destination clusters respectively. These are used to replicate topic configuration from origin to destination. Since version 4.1.0 these properties are optional.src.kafka.bootstrap.serversanddest.kafka.bootstrap.servers- A list of brokers in the origin and destination clusters respectively. Only the origin brokers are always required. The destination brokers should be set ifdest.zookeeper.connectis unset.topic.whitelist- An explicit list of the topics you want replicated. In this quick start, we will replicate the topic named “test-topic.”topic.rename.format- A substitution string that is used to rename topics in the destination cluster. In the snippet above, we have used${topic}.replica, where${topic}will be substituted with the topic name from the origin cluster. That means that thetest-topicwe’re replicating from the origin cluster will be renamed totest-topic.replicain the destination cluster.confluent.topicandconfluent.topic.replication.factor- If Replicator does not connect directly to ZooKeeper in the destination, Replicator will use Kafka to store your Confluent license. By default, confluent topic name is_command-topicand its replication factor is3. If using Replicator against a small destination Kafka cluster, such as in a development environment or proof of concept, you must setconfluent.topic.replication.factorto a value that is no larger than the size of the cluster. For example, if the cluster has only one broker, you must setconfluent.topic.replication.factor=1as in the example above.
Once you update the quick start configuration, you can run the connector in a standalone Kafka Connect Worker:
<path-to-confluent>/bin/connect-standalone <path-to-confluent>/etc/kafka/connect-standalone.properties \
<path-to-confluent>/etc/kafka-connect-replicator/quickstart-replicator.properties
When the connector has finished initialization, it will check the origin cluster for topics that need to be replicated. In this case, it
will find test-topic and will try to create the corresponding topic in the destination cluster. You can check this with the following command:
<path-to-confluent>/bin/kafka-topics --describe --topic test-topic.replica --zookeeper localhost:2181
Note that we’re checking the existence of test-topic.replica since test-topic was renamed according to our configuration.
After verifying the topic’s existence, you should confirm that four
partitions were created. In general, Replicator will ensure that the destination topic has as many partitions as the origin topic.
If this topic has Avro records used with Schema Registry, and the destination uses Kafka Connect sink connectors or has KSQL applications, register the existing schema used by test-topic for test-topic.replica.
At any time after you’ve created the topic in the origin cluster, you
can begin sending data to it using a Kafka producer to write to
test-topic in the origin cluster. You can then confirm that the data
has been replicated by consuming from test-topic.replica in the
destination cluster. For example, to send a sequence of numbers using
Kafka’s console producer, you can use the following command:
seq 10000 | <path-to-confluent>/bin/kafka-console-producer --topic test-topic --broker-list localhost:9082
You can then confirm delivery in the destination cluster using the console consumer:
<path-to-confluent>/bin/kafka-console-consumer --from-beginning --topic test-topic.replica --bootstrap-server localhost:9092
If the numbers 1 to 10,000 appear in the consumer output, this indicates that you have successfully created multi-cluster replication.