Important
You are viewing documentation for an older version of Confluent Platform. For the latest, click here.
Multi-Datacenter Replication¶
Confluent Platform can be deployed in multiple datacenters. Multi datacenter deployments enable use-cases such as:
- Active-active geo-localized deployments: allows users to access a near-by data center to optimize their architecture for low latency and high performance
- Active-passive disaster recover (DR) deployments: in an event of a partial or complete datacenter disaster, allow failing over applications to use Confluent Platform in a different datacenter.
- Centralized analytics: Aggregate data from multiple Apache Kafka® clusters into one location for organization-wide analytics
- Cloud migration: Use Kafka to synchronize data between on-prem applications and cloud deployments
Replication of events in Kafka topics from one cluster to another is the foundation of Confluent’s multi datacenter architecture. Replication can be done with Confluent Replicator or using the open source MirrorMaker.
Confluent Replicator allows you to easily and reliably replicate topics from one Kafka cluster to another. In addition to copying the messages, Replicator will create topics as needed preserving the topic configuration in the source cluster. This includes preserving the number of partitions, the replication factor, and any configuration overrides specified for individual topics. The diagram below shows the Replicator architecture. Notice how Replicator uses the Kafka Connect APIs and Workers to provide high availability, load-balancing and centralized management.
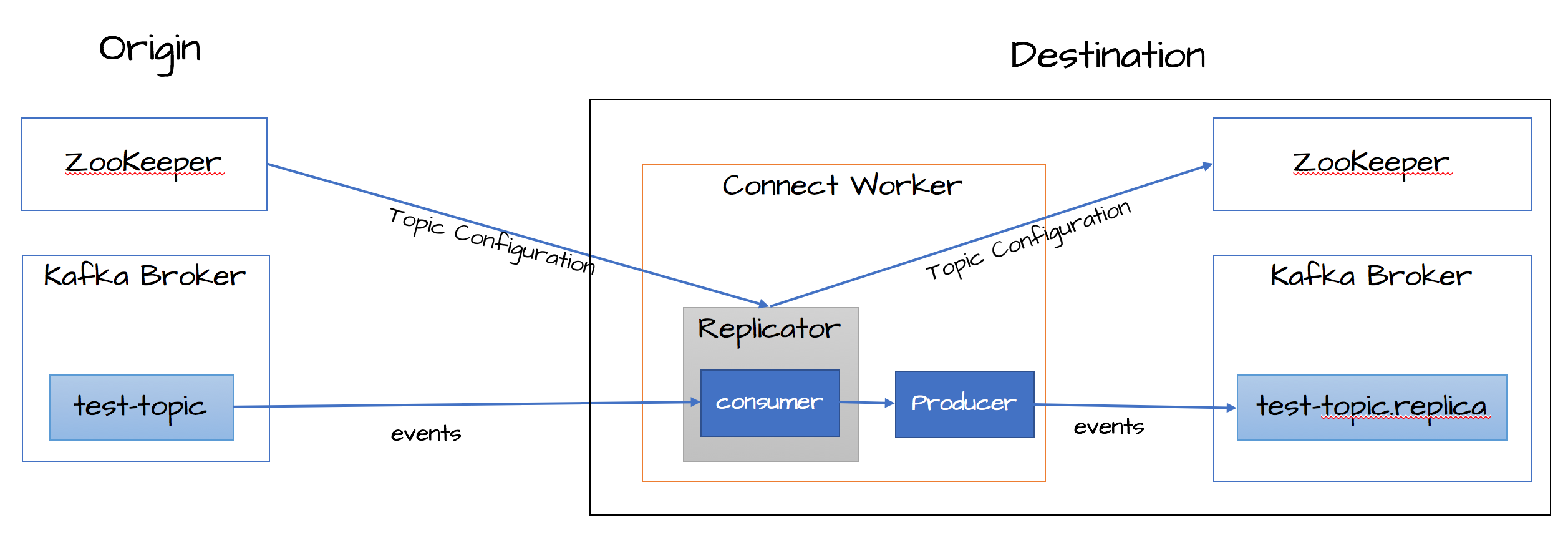
Replicator Architecture
MirrorMaker is a stand-alone tool for copying data between two Kafka clusters. Confluent Replicator is a more complete solution that handles topic configuration and data, and integrates with Kafka Connect and Confluent Control Center to improve availability, scalability and ease of use. See the section on comparing MirrorMaker to Confluent Replicator for more detail.
Follow these guidelines for configuring a multi datacenter deployment:
- Use the Replicator quick start to set up replication between two Kafka clusters.
- Learn how to install and configure Replicator and other Confluent Platform components in multi datacenter environments.
- Before running Replicator in production, make sure you read the monitoring and tuning guide.
- Review the Confluent Replicator example in the Confluent Platform demo. The demo shows users how to deploy a Kafka streaming ETL using KSQL for stream processing and Confluent Control Center for monitoring, along with Replicator to replicate data.
- For a practical guide to designing and configuring multiple Kafka clusters to be resilient in case of a disaster scenario, see the Disaster Recovery white paper. This white paper provides a plan for failover, failback, and ultimately successful recovery.