Confluent Platform のクイックスタート¶
Confluent Platform といくつかの SQL ステートメントを使用して、サンプルのデータストリームを処理するリアルタイムアプリケーションを構築します。
このクイックスタートでは、以下のことを行います。
- Confluent Platform と Apache Kafka® の インストールと実行
- リアルタイムの模擬データの 生成
- データを保管する トピックの作成
- データに対する リアルタイムのストリームの作成
- SQL ステートメントによる クエリとストリームの結合
- 新しいイベントが到着すると更新される ビューの構築
- ストリーミングアプリの トポロジーの視覚化
すべて終えると、よく使われる SQL ステートメントを使用して、データストリームを消費し、処理を行うリアルタイムアプリができあがります。
ちなみに
- 以下の手順では Docker または tar アーカイブを使用しますが、Confluent Platform をインストールするには、パッケージマネージャーや
systemd、Kubernetes、Ansible など、他にも方法があります。詳細については「オンプレミスのデプロイ」を参照してください。 - フルマネージド型の環境で Confluent を実行する場合は、Confluent Cloud のクイックスタート をお試しください。
前提条件¶
Docker と tar アーカイブのどちらを使用するかによって、Confluent Platform のインストールに関する考慮事項や要件に違いがあります。
以下の手順では、Docker および Docker Compose を使用して Confluent Platform をダウンロードし、実行します。
- 考慮事項
- ダウンロードに比較的長い時間(最大で数分程度)がかかります。
- 最短のステップ数でインストールと起動ができます。
dockerとdocker-composeが必要です。- アンインストールには
docker system pruneを使用します。
- 前提条件
- Docker
- Docker バージョン 1.11 またはそれ以降が インストールされ動作している。
- Docker Compose が インストール済みである 。Docker Compose は、Docker for Mac および Docker for Windows でデフォルトでインストールされます。
- Mac: Docker のメモリーが少なくとも 6 GB 割り当てられていること(Mac)。Docker Desktop for Mac を使用しているとき、Docker メモリーの割り当てはデフォルトで 2 GB です。Docker Desktop アプリでデフォルトの割り当てを 6 GB に変更するには、Preferences、Resources、Advanced の順に移動します。
- Windows: Docker Desktop for Windows は WSL 2 上で実行されます。詳細については、『How to Run Confluent on Windows in Minutes』を参照してください。
- インターネット接続
- Confluent Platform で現在サポートされる オペレーティングシステム
- Docker でのネットワークと Kafka
- 内部コンポーネントと外部コンポーネントが Docker ネットワークに通信できるように、ホストとポートを構成します。詳細については、こちらの記事 を参照してください。
- curl のインストール(任意)
- 以下の手順では、Docker Compose ファイルをダウンロードします。ダウンロードにはさまざまな方法がありますが、この手順では、ファイルのダウンロードに使用できる具体的なコマンドとして
curlを説明します。
- 以下の手順では、Docker Compose ファイルをダウンロードします。ダウンロードにはさまざまな方法がありますが、この手順では、ファイルのダウンロードに使用できる具体的なコマンドとして
- Docker
以下の手順では、tar アーカイブを使用して Confluent Platform をインストールします。
- 考慮事項
- 短時間でダウンロードできます
- インストールと起動に必要なステップが多くなります。
tarコマンドが必要です。- パスに CONFLUENT_HOME を追加する必要があります。
- アンインストールには
rm -rfを使用します。
- 前提条件
- インターネット接続
- Confluent Platform で現在サポートされる オペレーティングシステム
- サポートされているバージョンの Java。このバージョンの Confluent Platform では Java 8 および Java 11 がサポートされています(Java 9 と 10 はサポート対象外)。詳細については、 サポートされている Java バージョン を参照してください。
ステップ 1: Confluent Platform のダウンロードと起動¶
このステップでは、Docker イメージまたはアーカイブファイルの形式で Confluent Platform のバイナリをダウンロードします。
次のように、Confluent Platform all-in-one Docker Compose ファイル の内容をダウンロードするか、コピーします。
curl --silent --output docker-compose.yml \ https://raw.githubusercontent.com/confluentinc/cp-all-in-one/7.1.1-post/cp-all-in-one/docker-compose.yml-dオプションを指定して Confluent Platform スタックを起動し、デタッチモードで実行します。docker-compose up -d
Confluent Platform の各コンポーネントはそれぞれ別のコンテナーで起動されます。出力は以下のようになります。
Creating network "cp-all-in-one_default" with the default driver Creating zookeeper ... done Creating broker ... done Creating schema-registry ... done Creating rest-proxy ... done Creating connect ... done Creating ksql-datagen ... done Creating ksqldb-server ... done Creating control-center ... done Creating ksqldb-cli ... done
サービスが稼働中であるかを検証します。
docker-compose ps
出力は以下のようになります。
Name Command State Ports ------------------------------------------------------------------------------------------ broker /etc/confluent/docker/run Up 0.0.0.0:29092->29092/tcp, 0.0.0.0:9092->9092/tcp connect /etc/confluent/docker/run Up 0.0.0.0:8083->8083/tcp, 9092/tcp control-center /etc/confluent/docker/run Up 0.0.0.0:9021->9021/tcp ksqldb-cli /bin/sh Up ksql-datagen bash -c echo Waiting for K ... Up ksqldb-server /etc/confluent/docker/run Up 0.0.0.0:8088->8088/tcp rest-proxy /etc/confluent/docker/run Up 0.0.0.0:8082->8082/tcp schema-registry /etc/confluent/docker/run Up 0.0.0.0:8081->8081/tcp zookeeper /etc/confluent/docker/run Up 0.0.0.0:2181->2181/tcp, 2888/tcp, 3888/tcp数分後、ステートが Up になっていないコンポーネントがある場合は、再度
docker-compose up -dコマンドを実行するか、docker-compose restart <image-name>を試します。以下に例を示します。docker-compose restart control-center
Confluent パッケージアーカイブ から
confluent-7.1.1.tar.gzパッケージをダウンロードします。tarコマンドを使用してアーカイブファイルを展開します。tar -xvf confluent-7.1.1.tar.gz
tarコマンドによりconfluent-7.1.1ディレクトリが作成されます。これが Confluent のホームディレクトリになります。lsコマンドを実行して、内容を確認します。ls -al confluent-7.1.1
出力は以下のようになります。
-rw-r--r-- 1 jim jim 871 May 19 21:36 README drwxr-xr-x 3 jim jim 4096 May 19 20:25 bin drwxr-xr-x 17 jim jim 4096 May 19 20:25 etc drwxr-xr-x 3 jim jim 4096 May 19 20:21 lib drwxr-xr-x 3 jim jim 4096 May 19 20:25 libexec drwxr-xr-x 7 jim jim 4096 May 19 20:25 share drwxr-xr-x 2 jim jim 4096 May 19 21:36 src
Confluent Platform のホームディレクトリの環境変数を設定します。
export CONFLUENT_HOME=confluent-7.1.1
Confluent Platform の
binディレクトリを PATH に追加します。export PATH=$PATH:$CONFLUENT_HOME/bin
confluentコマンドを実行してインストールのテストを行います。confluent --help
出力に、Confluent Platform の管理に使用できるコマンドが表示されます。
Confluent Hub クライアントを使用して、Kafka Connect Datagen Source Connector をインストールします。このコネクターで生成される模擬データはデモ専用であり、本稼働環境には適しません。
confluent-hub install \ --no-prompt confluentinc/kafka-connect-datagen:latestちなみに
Confluent Hub は、パッケージ済みのオンラインライブラリであり、Confluent Platform および Kafka 用にそのままインストールできる拡張機能またはアドオンです。
Confluent CLI confluent local services start コマンドを使用して、Confluent Platform を起動します。このコマンドにより、すべての Confluent Platform コンポーネント(Kafka、ZooKeeper、Schema Registry、HTTP REST Proxy for Kafka、Kafka Connect、ksqlDB、Control Center を含む)が起動します。
重要
confluent local コマンドは、単一ノードの開発環境向けであり、本稼働環境には適していません。生成されるデータは一過性で、一時的なものです。本稼働環境対応のワークフローについては、「Confluent Platform のインストールおよびアップグレード」を参照してください。
confluent local services start出力は以下のようになります。
Starting Zookeeper Zookeeper is [UP] Starting Kafka Kafka is [UP] Starting Schema Registry Schema Registry is [UP] Starting Kafka REST Kafka REST is [UP] Starting Connect Connect is [UP] Starting KSQL Server KSQL Server is [UP] Starting Control Center Control Center is [UP]
ステップ 2: データを保管する Kafka トピックの作成¶
Confluent Platform では、リアルタイムストリーミングイベントは Kafka トピックに保管されます。トピックとは、基本的には追加のみのログです。詳細については、Apache Kafka の概要 を参照してください。
このステップでは、Confluent Control Center を使用して 2 つのトピックを作成します。Control Center は、本稼働環境のデータパイプラインおよびイベントストリーミングアプリケーションを構築およびモニタリングするための機能を備えています。
トピック名は pageviews と users です。この後の手順では、これらのトピックに対してデータを生成するデータジェネレーターを作成します。
pageviews トピックの作成¶
Confluent Control Center では、UI で数回クリックするだけでトピックを作成できます。
Control Center (http://localhost:9021)に移動します。Control Center が起動し、読み込みが完了するまでに 1 ~ 2 分かかる場合があります。
controlcenter.cluster タイルをクリックします。
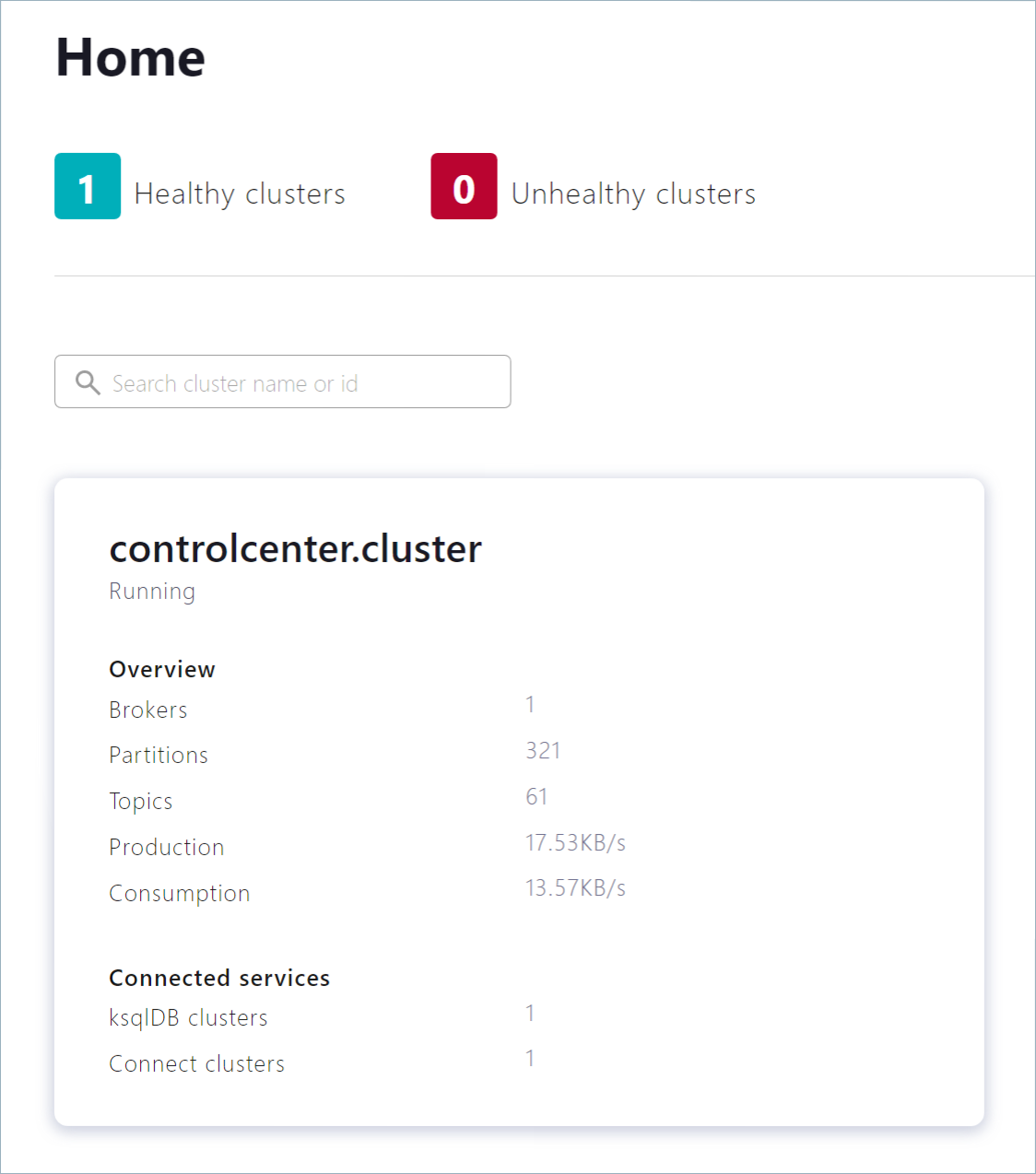
ナビゲーションメニューで Topics をクリックしてトピックのリストを開きます。Add a topic をクリックして
pageviewsトピックの作成を開始します。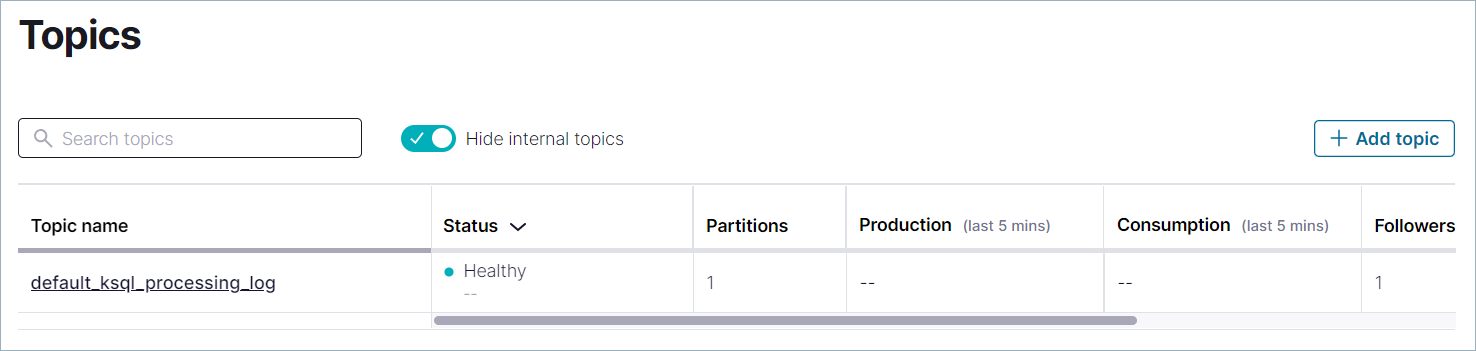
Topic name フィールドに
pageviewsと入力し、Create with defaults をクリックします。トピック名では大文字と小文字が区別されます。**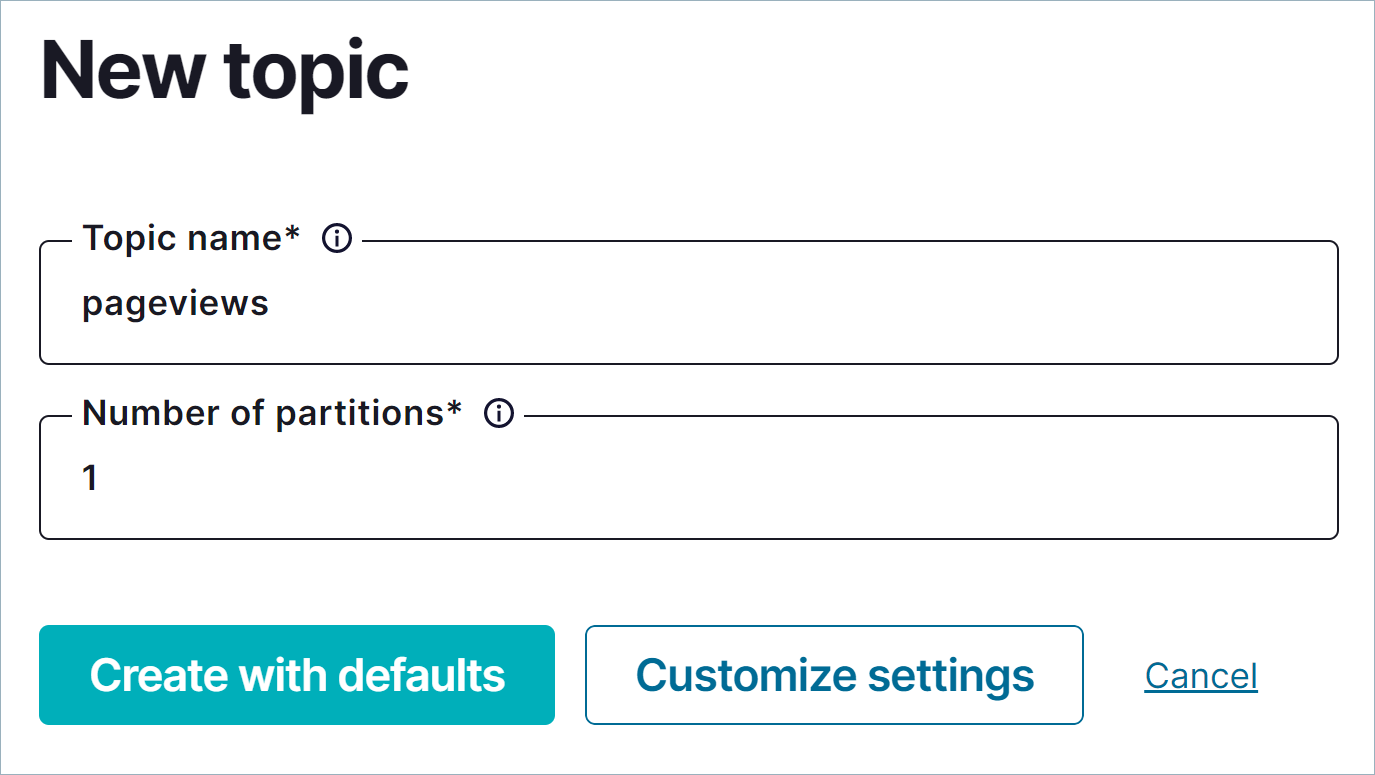
users トピックの作成¶
前のステップと同じ手順を実行して、users トピックを作成します。
ナビゲーションメニューで Topics をクリックしてトピックのリストを開きます。Add a topic をクリックして
usersトピックの作成を開始します。Topic name フィールドに
usersと入力し、Create with defaults をクリックします。users ページで、Configuration をクリックして
usersトピックの詳細を確認します。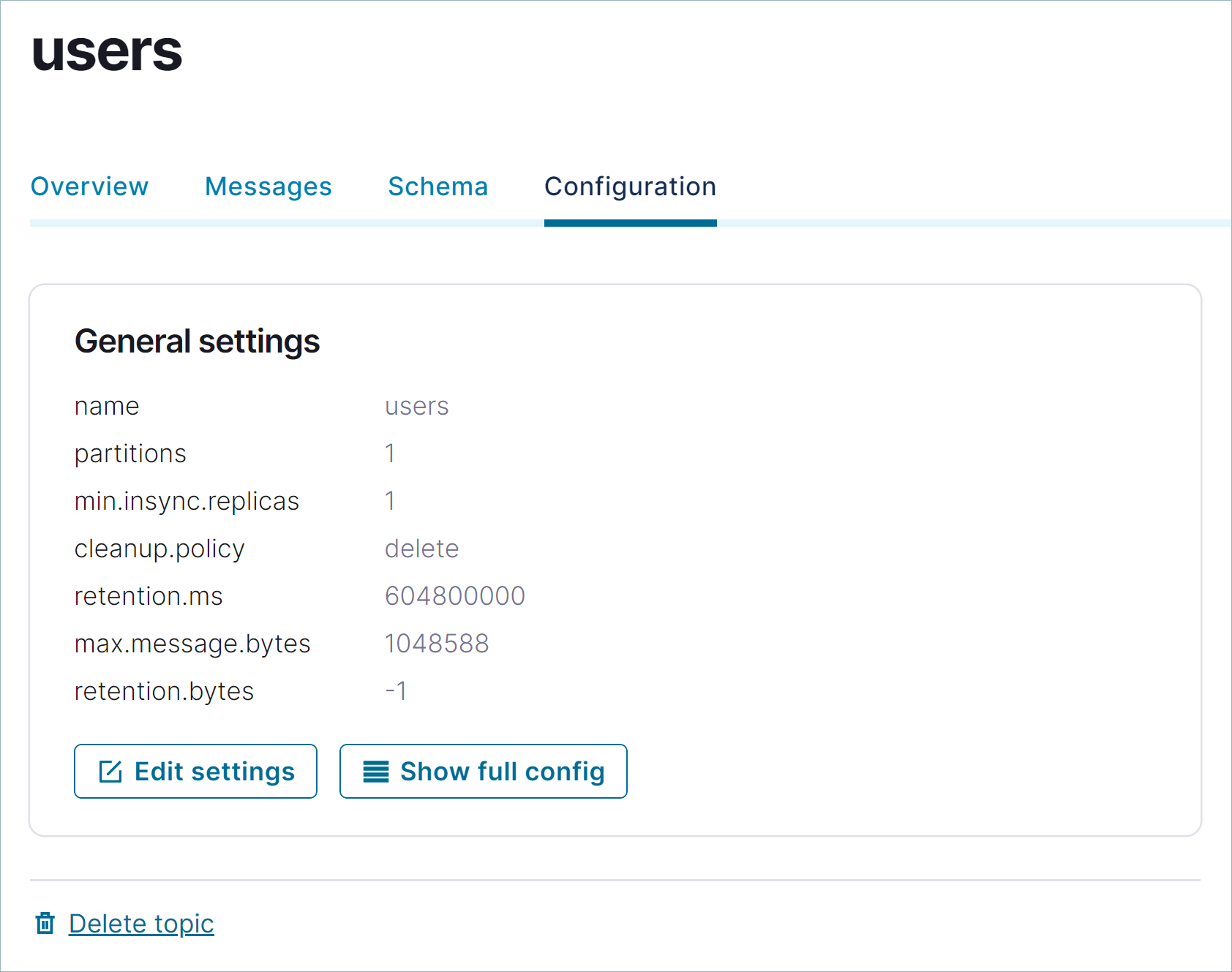
ステップ 3: 模擬データの生成¶
In Confluent Platform, you get events from an external source by using a connector, which enables streaming large volumes of data to and from your cluster. Confluent publishes many connectors for integrating with external systems, like MongoDb and Elasticsearch. For more information, see Connect Overview.
このステップでは、Datagen Source Connector を実行して模擬データを生成します。模擬データは、前のステップで作成した pageviews トピックおよび users トピックに保管されます。
ナビゲーションメニューで Connect をクリックします。
Connect clusters リストで
connect-defaultクラスターをクリックします。Add connector をクリックして、pageviews データ用のコネクターを作成します。
DatagenConnectorタイルを選択します。ちなみに
ソースコネクターのみを表示するには、Filter by category をクリックし、Sources を選択します。
名前 フィールドで、コネクターの名前として
datagen-pageviewsを入力します。次の構成値を入力します。
- Key converter class:
org.apache.kafka.connect.storage.StringConverter。 - kafka.topic:
pageviews。 - max.interval:
100。 - quickstart:
pageviews。
- Key converter class:
Next をクリックして、コネクターの構成を確認します。設定に問題がない場合は、Launch をクリックします。
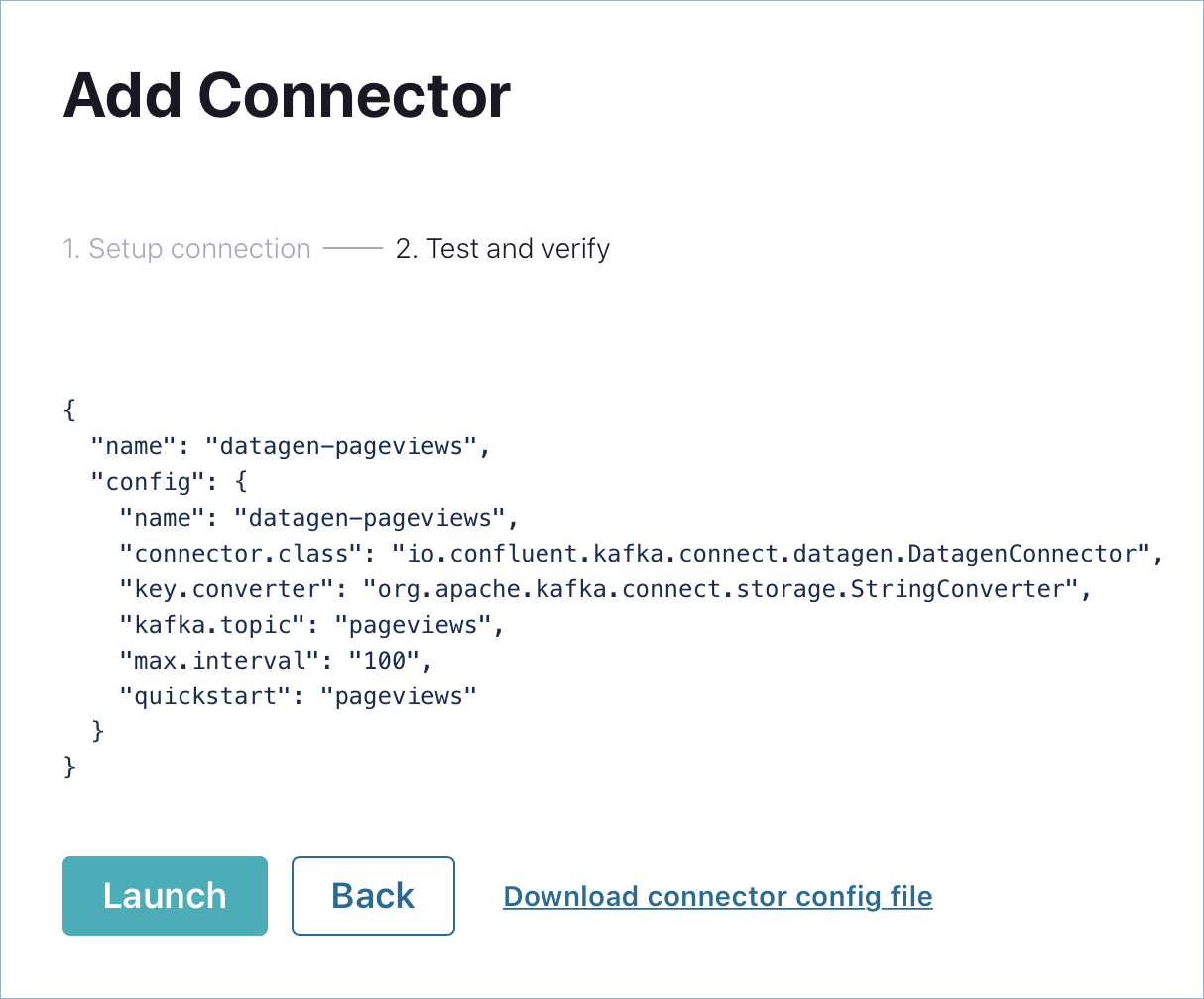
Datagen Source Connector コネクターの 2 つ目のインスタンスを実行し、users トピックに対して模擬データを生成します。
ナビゲーションメニューで Connect をクリックします。
Connect clusters リストで
connect-defaultをクリックします。Add connector をクリックします。
DatagenConnectorタイルを選択します。名前 フィールドで、コネクターの名前として
datagen-usersを入力します。次の構成値を入力します。
- Key converter class:
org.apache.kafka.connect.storage.StringConverter - kafka.topic:
users - max.interval:
1000 - quickstart:
users
- Key converter class:
Next をクリックして、コネクターの構成を確認します。設定に問題がない場合は、Launch をクリックします。
ナビゲーションメニューで Topics をクリックし、リストにある users をクリックします。
Messages をクリックして、
datagen-usersコネクターがusersトピックに対してデータを生成していることを確認します。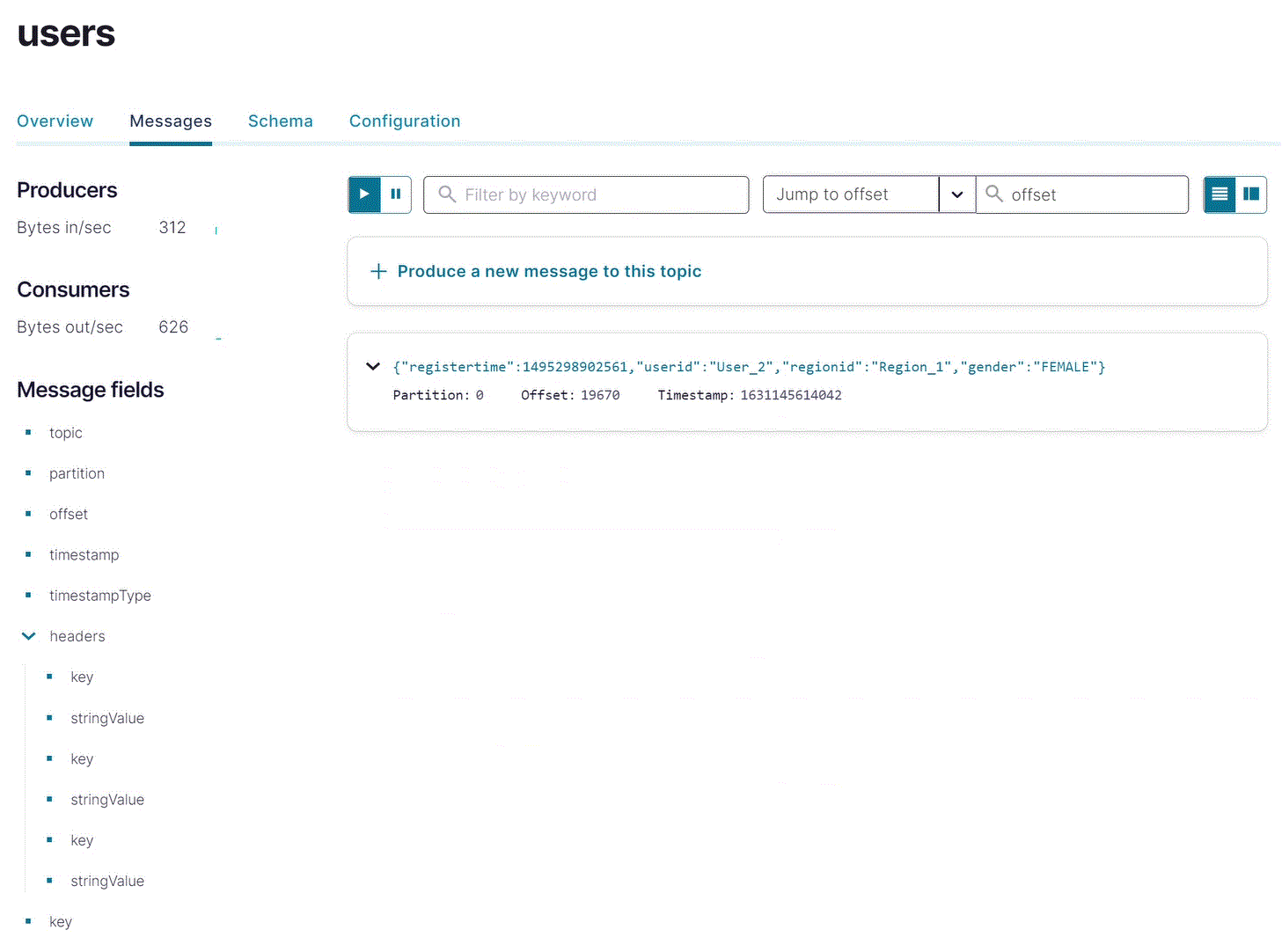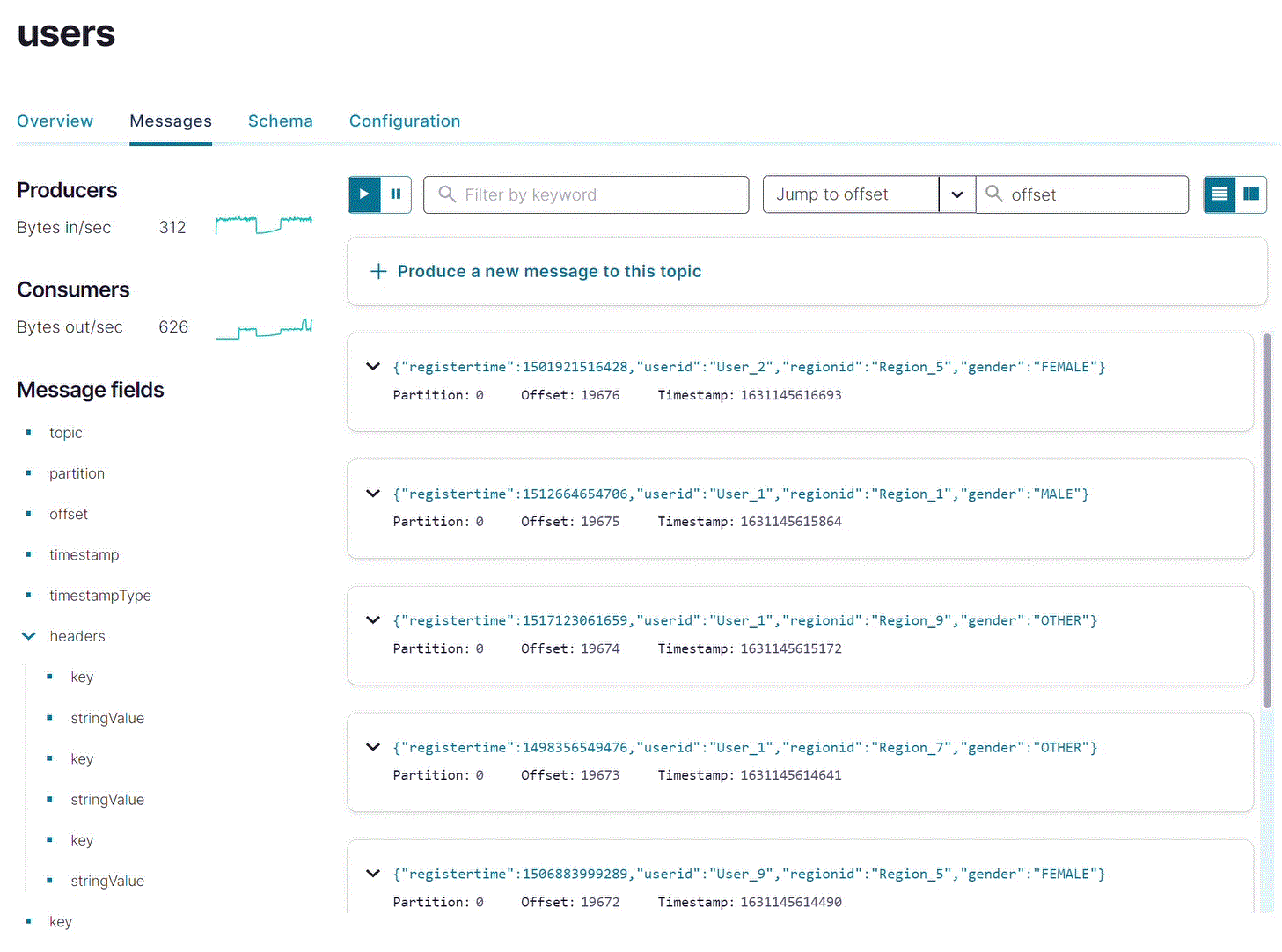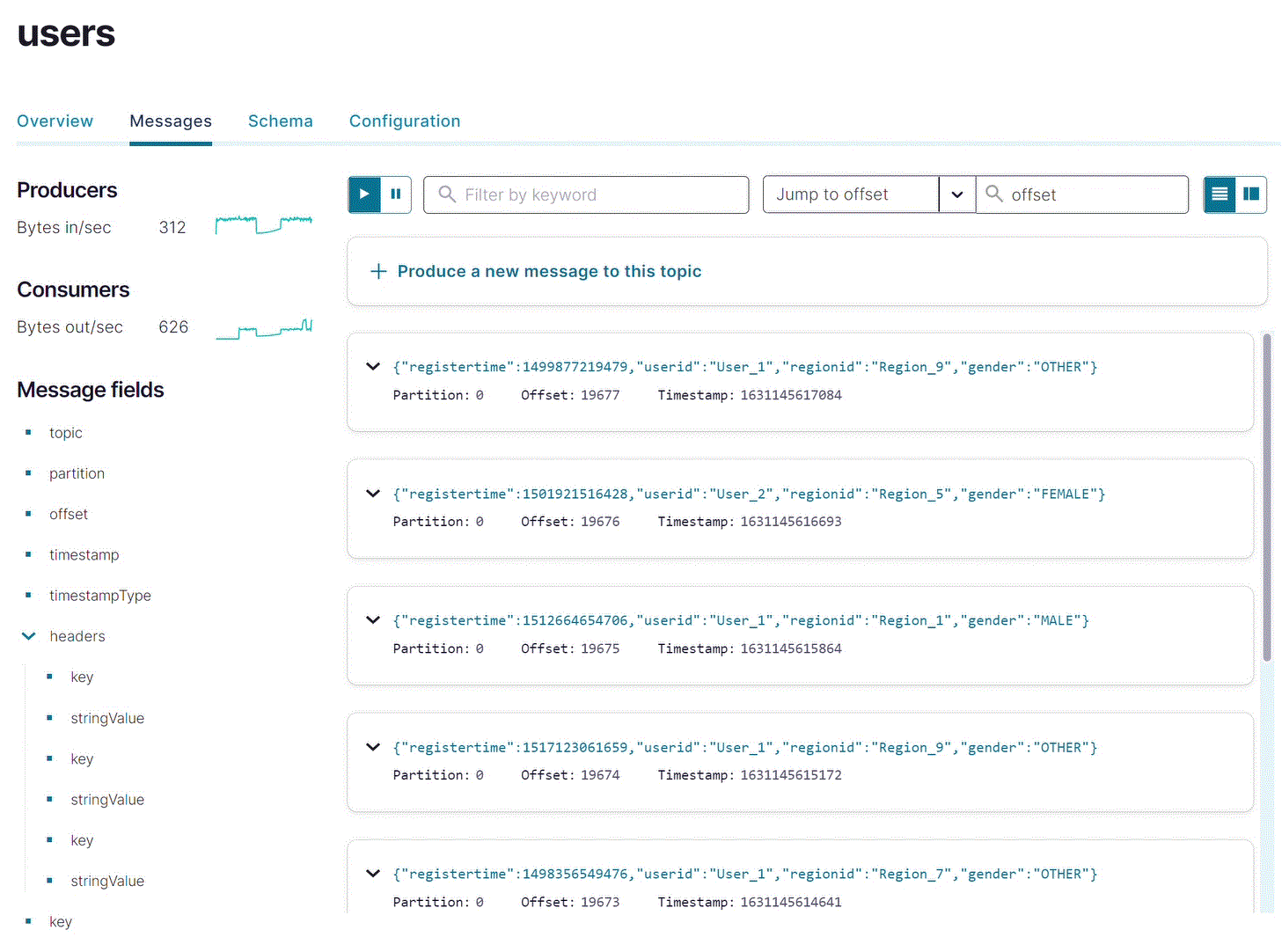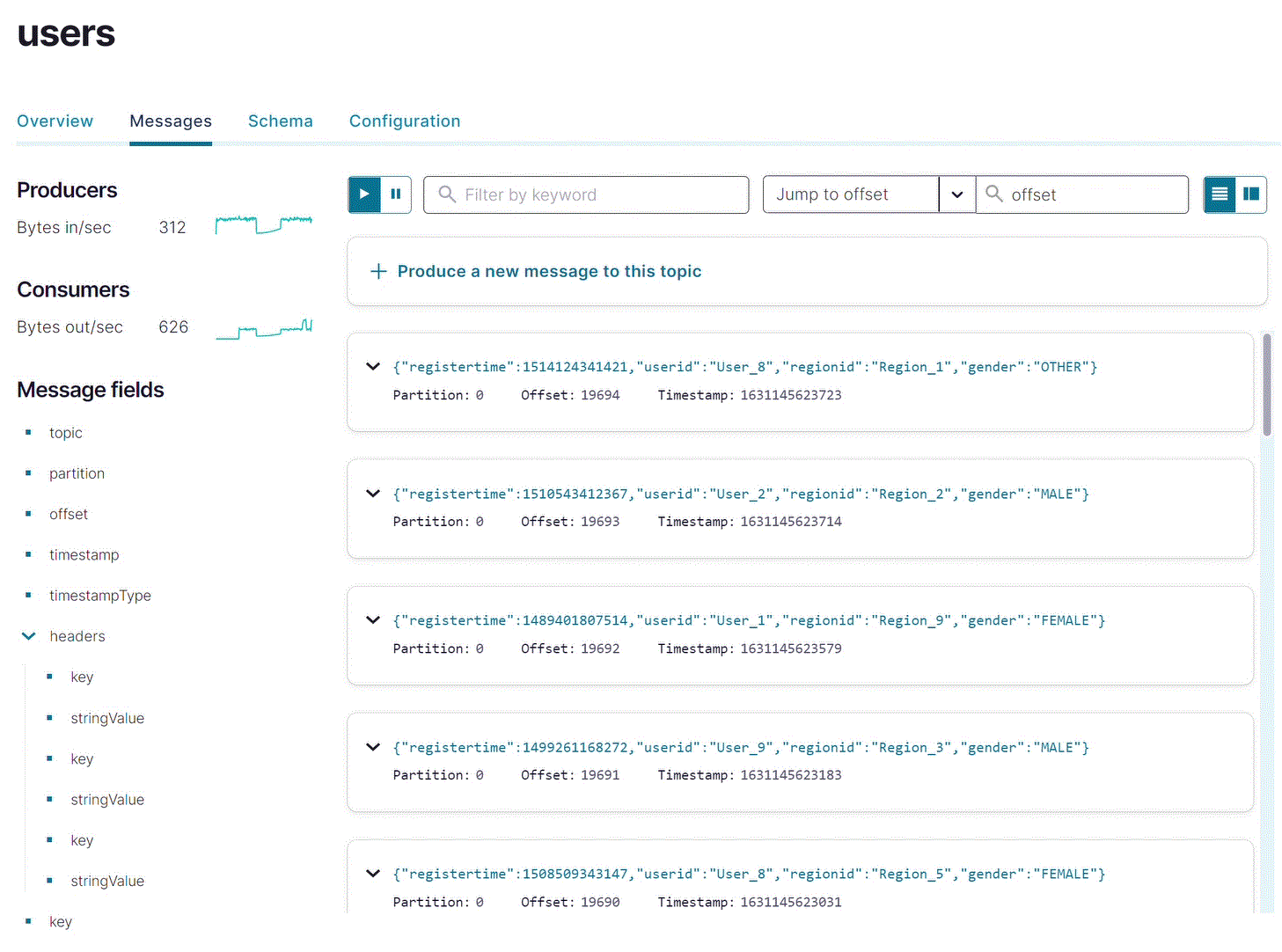
トピックのスキーマの検査¶
デフォルトでは、Datagen Source Connector では Avro フォーマットでデータが生成されます。このフォーマットで pageviews および users メッセージのスキーマが定義されます。
Schema Registry により、クラスターに送信されたメッセージのスキーマが正しいことが確認されます。詳細については、「Schema Registry の概要」を参照してください。
ナビゲーションメニューで Topics をクリックし、トピックリストにある pageviews をクリックします。
Schema をクリックして、
pageviewsメッセージ値に適用される Avro スキーマを確認します。出力は以下のようになります。
{ "connect.name": "ksql.pageviews", "fields": [ { "name": "viewtime", "type": "long" }, { "name": "userid", "type": "string" }, { "name": "pageid", "type": "string" } ], "name": "pageviews", "namespace": "ksql", "type": "record" }
ステップ 4: SQL ステートメントを使用したストリームおよびテーブルの作成¶
このステップでは、よく使われる SQL 構文を使用して、pageviews トピックのストリームおよび users トピックのテーブルを作成します。トピックにストリームまたはテーブルを登録すると、そのストリームまたはテーブルを SQL ステートメントで使用できます。
注釈
ストリーム は、これまでに発生した一連のファクト(イベント)を表す、変更不可で追加のみのコレクションです。一度ストリームに挿入された行を変更することはできません。新しい行をストリームの末尾に追加することができますが、既存の行をアップグレードまたは削除することはできません。
テーブル は、時間の経過に伴う変更をモデル化した、変更可能なコレクションです。キーごとの最新のデータを表示するには、行キーを使用します。各キーの最新の行を除くすべての行が定期的に削除されます。また、各行にタイムスタンプがあるため、"ウィンドウ化" されたテーブルを定義できます。これにより、集約や結合などのステートフルな操作で、同じキーを持つレコードを期間ごとにグループ化する方法を制御できます。ウィンドウはレコードキーで追跡されます。
ストリームとテーブルを組み合わせることでデータベースが実現されます。詳細については、『Stream Processing』を参照してください。
ストリーム処理アプリケーション用のデータベースである ksqlDB に SQL エンジンが実装されています。以下のステップでは、よく使われる SQL 構文を使用してリアルタイムデータを処理できる ksqlDB アプリケーションを作成する方法を説明します。
このサンプルアプリでは、次のストリーム処理操作を示します。
pageviewsストリームとusersテーブルを 結合 して、拡張されたページビューイベントのストリームを作成します。拡張されたストリームに
regionフィールドの フィルター を適用します。フィルターを適用したストリームの ウィンドウ化されたビュー を作成して、最近更新された行のみが表示されるようにします。ウィンドウの サイズ は 30 秒とします。
ちなみに
これらの処理ステップは、3 つの SQL ステートメントのみで実装されます。
以下のステップでは、CREATE STREAM と CREATE TABLE のステートメントを使用して、pageviews トピックおよび users トピックのテーブルにストリームを登録する方法を説明します。ストリームまたはテーブルをトピックに登録すると、トピックのデータに対して SQL クエリを実行できます。
ナビゲーションメニューで ksqlDB をクリックします。
ksqlDBアプリケーションをクリックして、ksqlDB ページを開きます。SQL ステートメントの編集用、および作成したストリームとテーブルのモニタリング用のタブがあります。以下の SQL をコピーして、エディターウィンドウに貼り付けます。このステートメントは、
pageviewsトピックにpageviews_streamという名前のストリームを登録します。ストリーム名およびテーブル名では、大文字と小文字が区別されません。CREATE STREAM pageviews_stream WITH (KAFKA_TOPIC='pageviews', VALUE_FORMAT='AVRO');
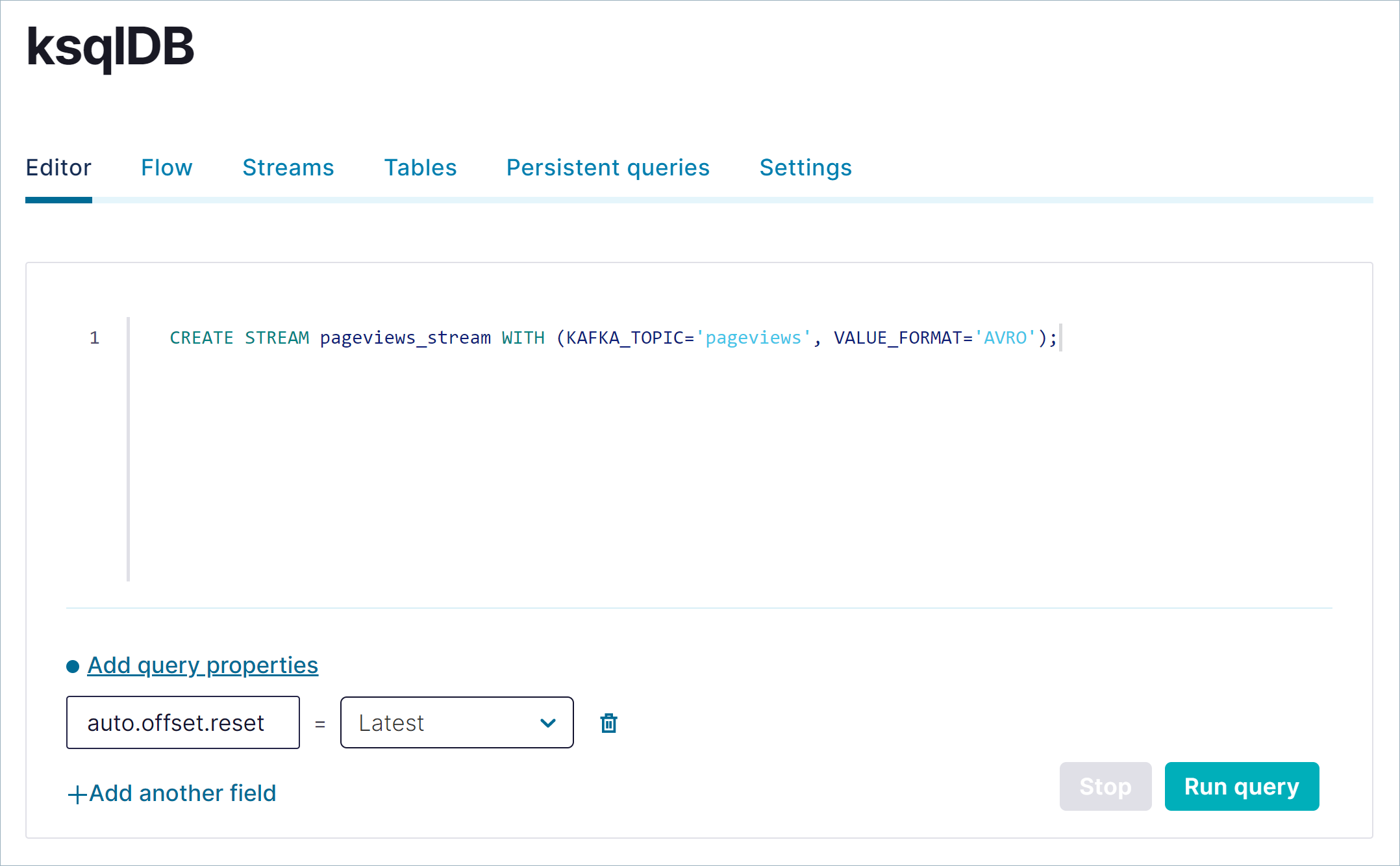
Run query をクリックしてステートメントを実行します。結果ウィンドウの出力は次のようになります。
{ "@type": "currentStatus", "statementText": "CREATE STREAM PAGEVIEWS_STREAM (VIEWTIME BIGINT, USERID STRING, PAGEID STRING) WITH (KAFKA_TOPIC='pageviews', KEY_FORMAT='KAFKA', VALUE_FORMAT='AVRO', VALUE_SCHEMA_ID=2);", "commandId": "stream/`PAGEVIEWS_STREAM`/create", "commandStatus": { "status": "SUCCESS", "message": "Stream created", "queryId": null }, "commandSequenceNumber": 2, "warnings": [] }
SELECT クエリを使用して、データがストリームを移動していることを確認します。以下の SQL をエディターにコピーして Run query をクリックします。
SELECT * FROM pageviews_stream EMIT CHANGES;
出力は以下のようになります。
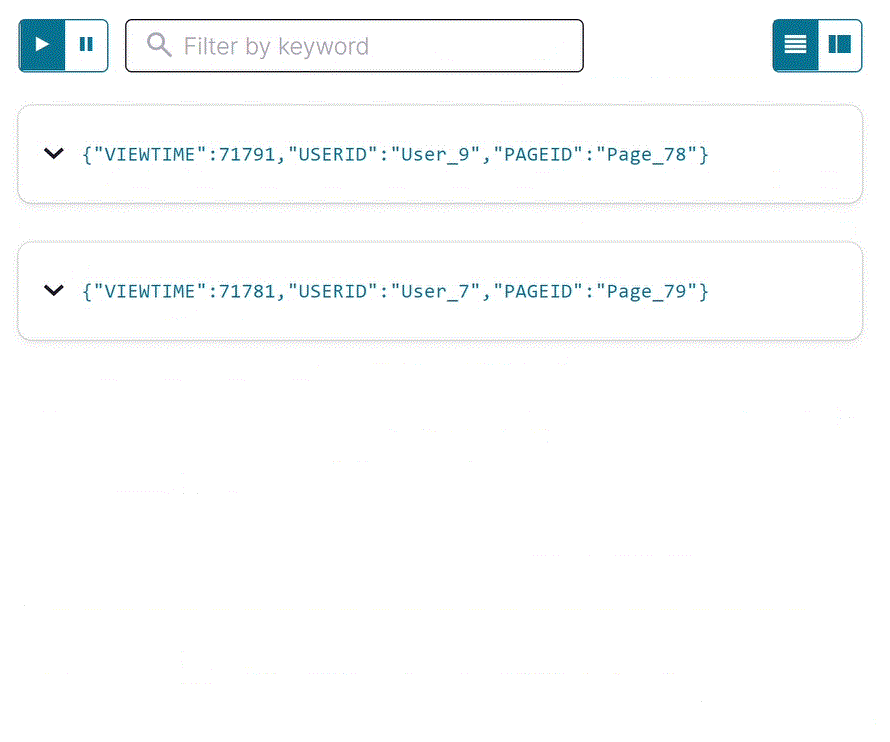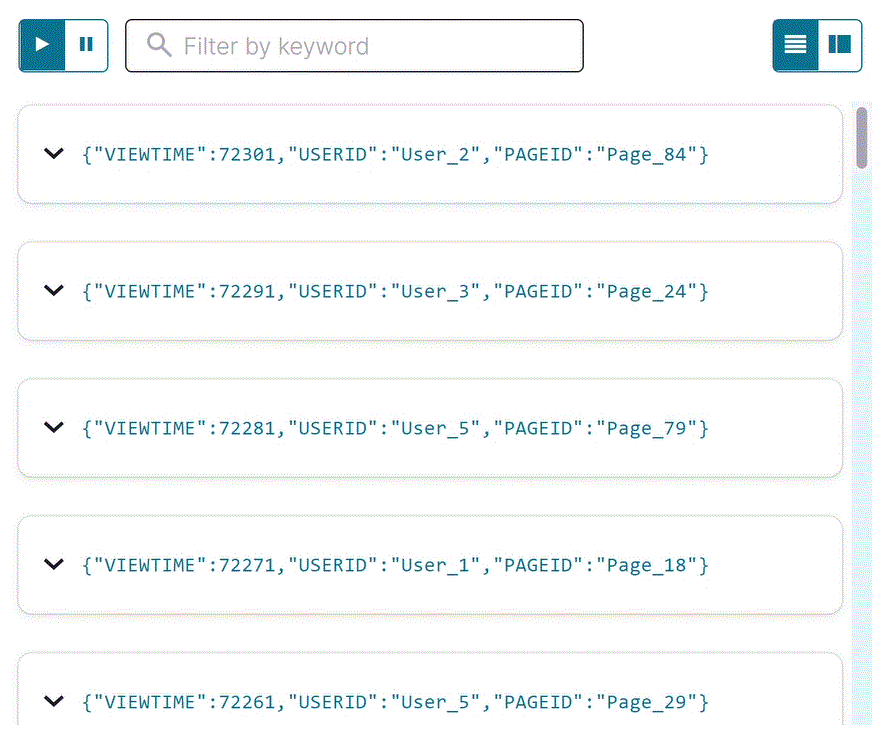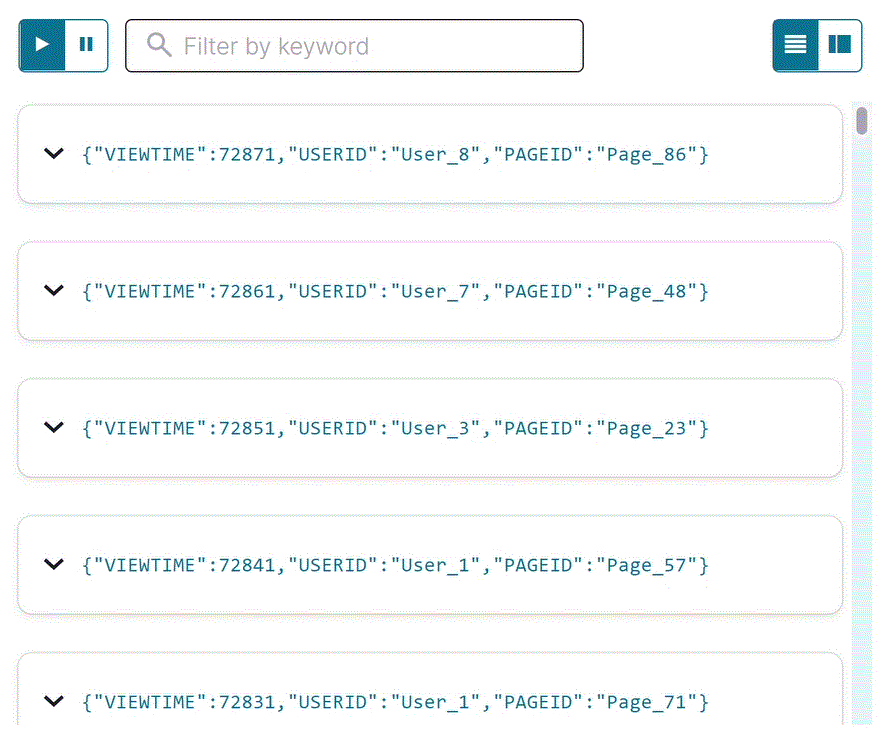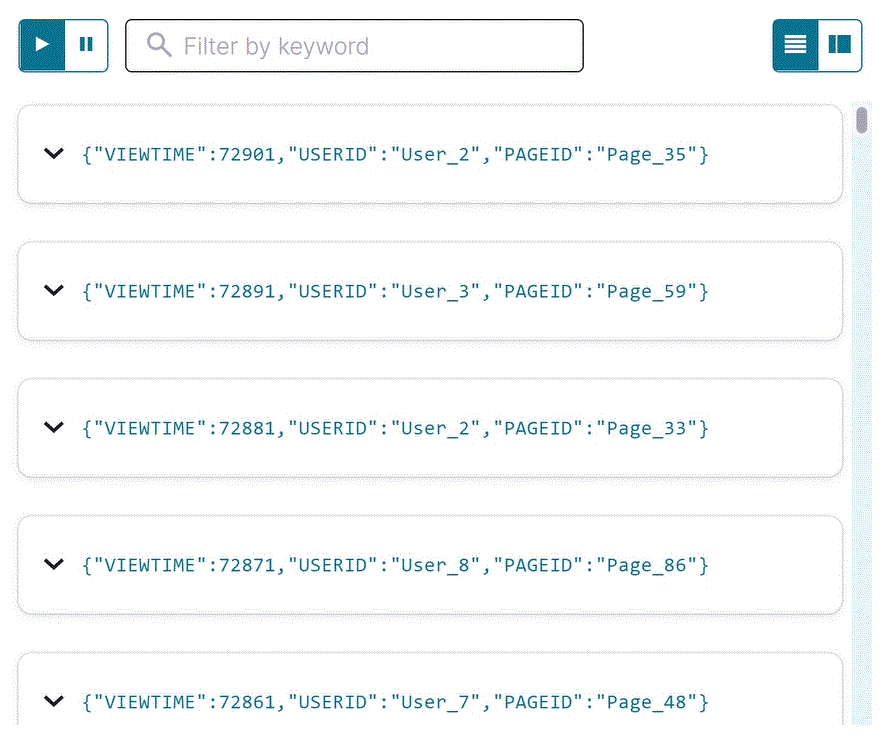
Stop をクリックして SELECT クエリを終了します。
重要
SELECT クエリを停止しても、ストリーム内のデータの移動は停止しません。
以下の SQL をエディターウィンドウにコピーして Run query をクリックします。このステートメントは、
usersトピックにusers_tableという名前のテーブルを登録します。CREATE TABLE users_table (id VARCHAR PRIMARY KEY) WITH (KAFKA_TOPIC='users', VALUE_FORMAT='AVRO');
出力は以下のようになります。
{ "@type": "currentStatus", "statementText": "CREATE TABLE USERS_TABLE (ID STRING PRIMARY KEY, REGISTERTIME BIGINT, USERID STRING, REGIONID STRING, GENDER STRING) WITH (KAFKA_TOPIC='users', KEY_FORMAT='KAFKA', VALUE_FORMAT='AVRO', VALUE_SCHEMA_ID=2);", "commandId": "table/`USERS_TABLE`/create", "commandStatus": { "status": "SUCCESS", "message": "Table created", "queryId": null }, "commandSequenceNumber": 4, "warnings": [] }
テーブルを登録する際には、PRIMARY KEY を指定する必要があります。ksqlDB のテーブルは、他の SQL システムのテーブルと同様です。テーブルにはゼロ行以上の行があり、各行は PRIMARY KEY で識別されます。
ストリームおよびテーブルのスキーマの確認¶
Schema Registry は Confluent Platform とともにインストールされ、スタックで実行されます。そのため、CREATE STREAM および CREATE TABLE のステートメントでメッセージスキーマを指定する必要はありません。Avro、JSON_SR、および Protobuf フォーマットでは、Schema Registry により自動的にスキーマが推測されます。
Streams をクリックして、現在登録されているストリームを確認します。リストで PAGEVIEWS_STREAM をクリックして、ストリームの詳細を確認します。
Schema セクションで、
datagen-pageviewsコネクターで生成されたメッセージ値のフィールド名とデータ型を確認できます。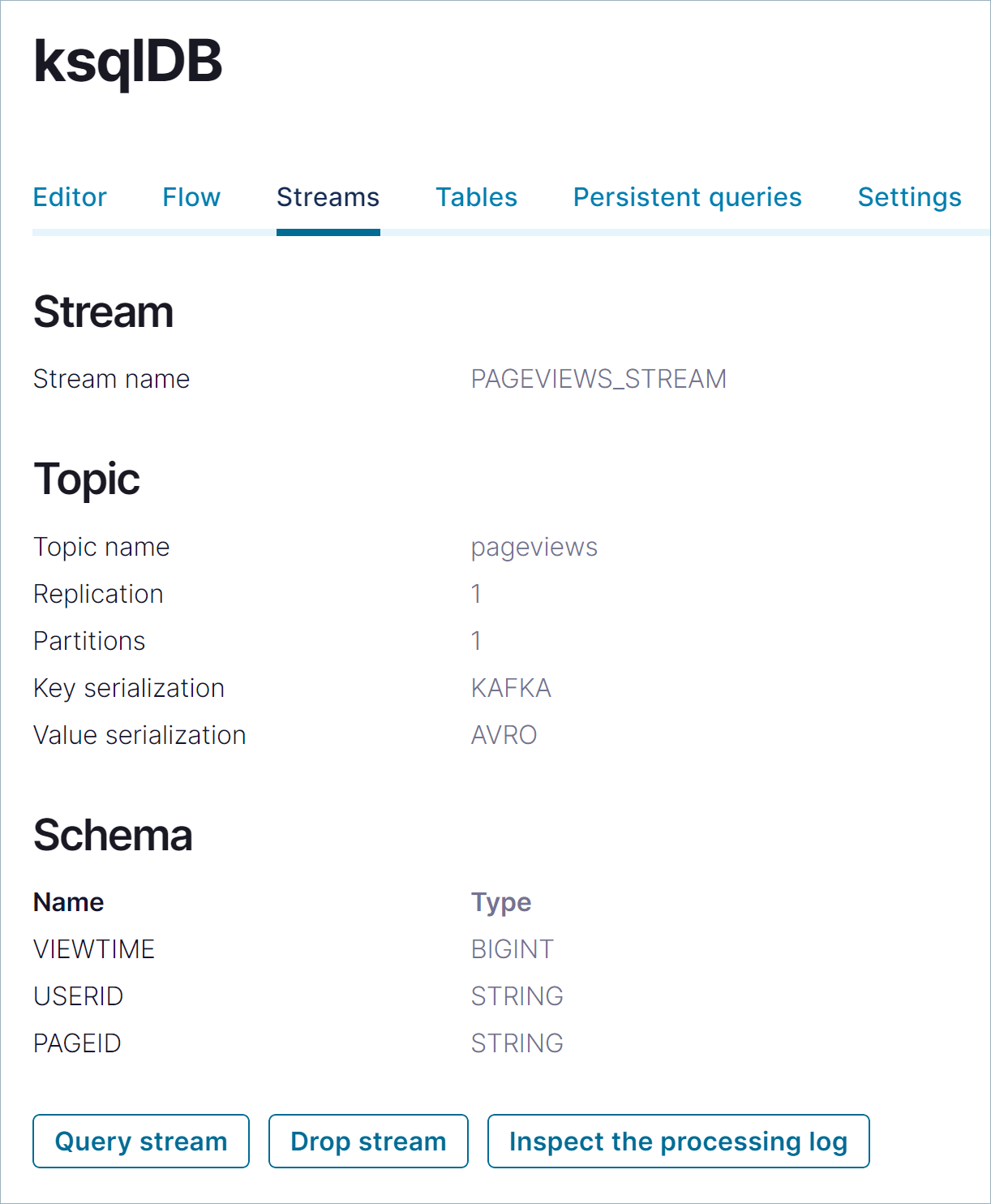
Tables をクリックして、現在登録されているテーブルを確認します。リストで USERS_TABLE をクリックして、テーブルの詳細を確認します。
Schema セクションで、
datagen-usersコネクターで生成されたメッセージ値のフィールド名とデータ型を確認できます。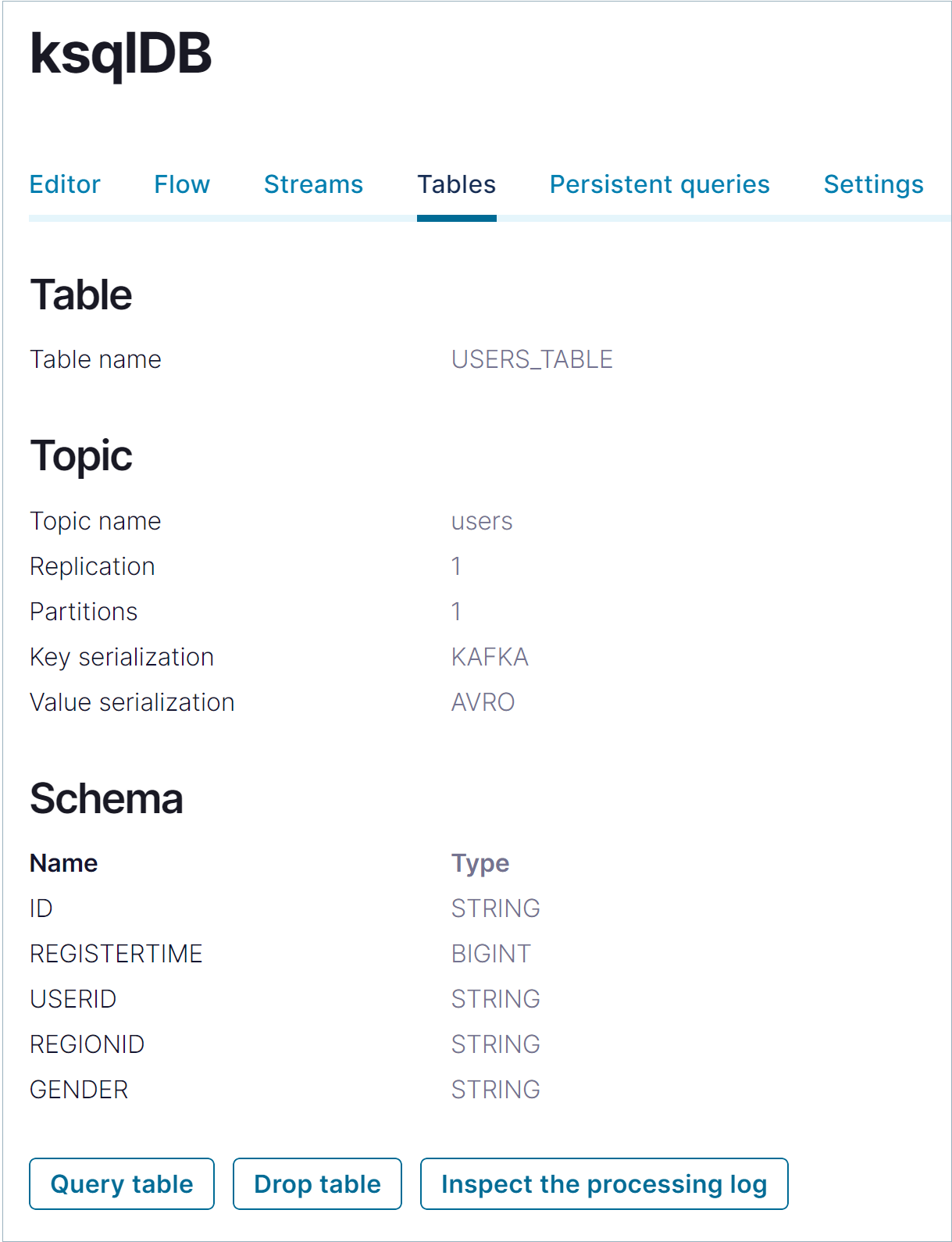
データを処理するクエリの作成¶
このステップでは、ページビューおよびユーザー行を検査して処理する SQL クエリを記述します。さまざまな種類のクエリを作成できます。
- 一時クエリ: 永続的でない、クライアント側のクエリです。LIMIT 句を使用するか、手動で終了します。一時クエリでは新しいトピックは作成されません。
- 永続的なクエリ: サーバー側のクエリであり、新しいストリームまたはテーブルが出力され、これらには新しいトピックが使用されます。TERMINATE ステートメントを発行するまで実行されます。永続的なクエリの構文では、CREATE STREAM AS SELECT または CREATE TABLE AS SELECT のステートメントが使用されます。
- プッシュクエリ: サブスクリプションに対して継続的に結果を生成するクエリです。プッシュクエリの構文では、EMIT CHANGES キーワードが使用されます。プッシュクエリには、一時的なものと永続的なものがあります。
- プルクエリ: 従来型のリレーショナルデータベースに対するクエリのように、「現在」時点の結果を取得するクエリです。プルクエリは 1 回ずつ実行され、テーブルの現在の状態が返されます。テーブルは新しいイベントの到着ごとに順次更新されるため、プルクエリは低レイテンシで実行されることが予想されます。プルクエリはすべて一時クエリです。
pageviews のクエリ¶
Editor をクリックしてクエリエディターに戻ります。
以下の SQL をエディターにコピーして Run query をクリックします。このステートメントでは、
pageviews_streamの 3 行を返す一時クエリを作成します。SELECT pageid FROM pageviews_stream EMIT CHANGES LIMIT 3;
出力は以下のようになります。
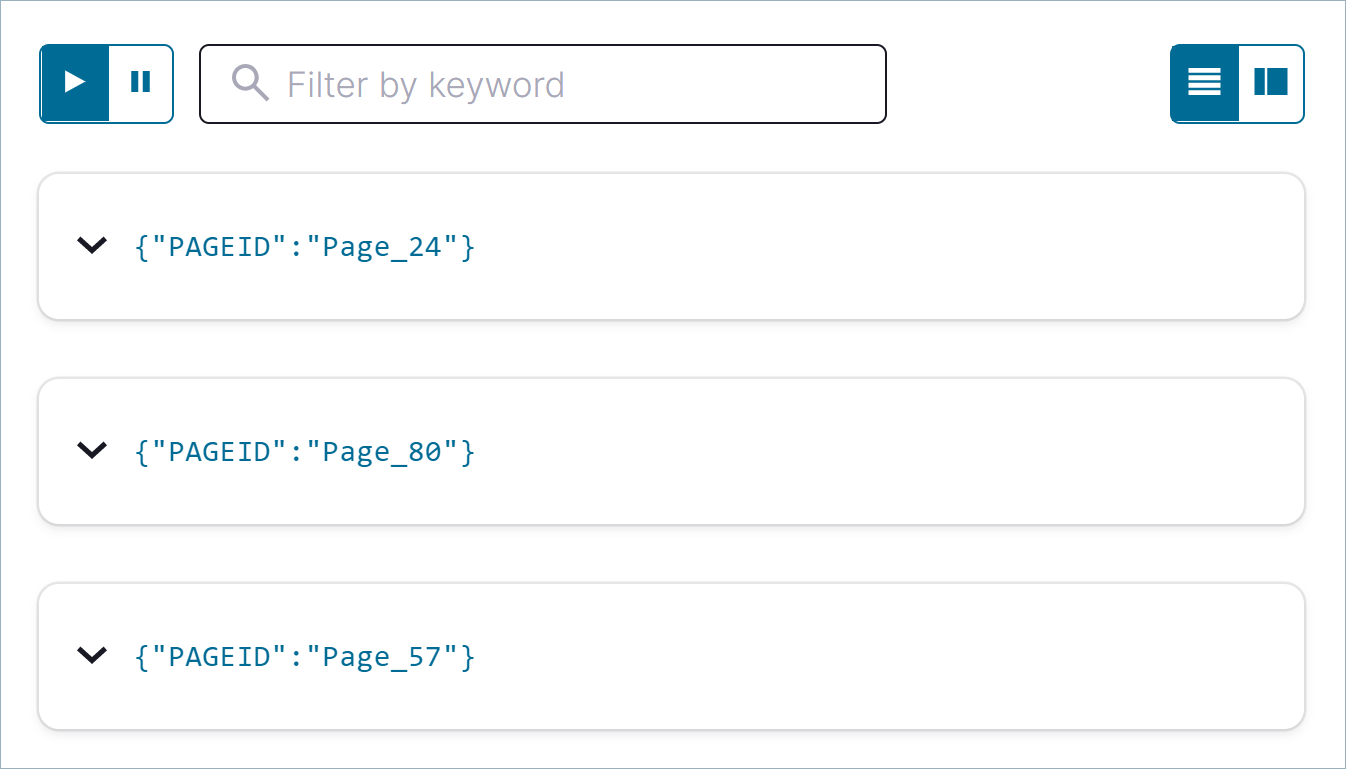
Card view アイコンまたは Table view アイコンをクリックして出力のレイアウトを変更します。
ストリームとテーブルの結合¶
このステップでは、pageviews_stream と users_table を userid キーで結合する永続的なクエリを使用して user_pageviews という名前のストリームを作成します。この結合により、ページビューデータが拡張され、ページを参照したユーザーの情報が付加されます。結合された行は、新しい "シンク" トピックに書き込まれます。デフォルトでは、このシンクトピックの名前は新しいストリームと同じです。
ちなみに
WITH 句で KAFKA_TOPIC キーワードを使用すると、シンクトピックの名前を指定できます。
以下のステップでは、ストリームとテーブルを結合し、結合後のストリームの出力を表示する方法を説明します。
以下の SQL をエディターにコピーして Run query をクリックします。
CREATE STREAM user_pageviews AS SELECT users_table.id AS userid, pageid, regionid, gender FROM pageviews_stream LEFT JOIN users_table ON pageviews_stream.userid = users_table.id EMIT CHANGES;
出力は以下のようになります。
{ "@type": "currentStatus", "statementText": "CREATE STREAM USER_PAGEVIEWS WITH (KAFKA_TOPIC='USER_PAGEVIEWS', PARTITIONS=1, REPLICAS=1) AS SELECT\n USERS_TABLE.ID USERID,\n PAGEVIEWS_STREAM.PAGEID PAGEID,\n USERS_TABLE.REGIONID REGIONID,\n USERS_TABLE.GENDER GENDER\nFROM PAGEVIEWS_STREAM PAGEVIEWS_STREAM\nLEFT OUTER JOIN USERS_TABLE USERS_TABLE ON ((PAGEVIEWS_STREAM.USERID = USERS_TABLE.ID))\nEMIT CHANGES;", "commandId": "stream/`USER_PAGEVIEWS`/create", "commandStatus": { "status": "SUCCESS", "message": "Created query with ID CSAS_USER_PAGEVIEWS_5", "queryId": "CSAS_USER_PAGEVIEWS_5" }, "commandSequenceNumber": 6, "warnings": [] }
ちなみに
- 出力で強調表示されている行で、クエリの内部識別子が
CSAS_USER_PAGEVIEWS_5であることがわかります。先頭に "CSAS" が付いており、これは CREATE STREAM AS SELECT の頭文字を取ったものです。 - テーブルの識別子には、先頭に "CTAS" が付いており、これは CREATE TABLE AS SELECT の頭文字を取ったものです。
- 出力で強調表示されている行で、クエリの内部識別子が
Streams をクリックして、アクセスできるストリームのリストを開きます。
USER_PAGEVIEWS を選択し、Query stream をクリックします。
エディターが開いて SELECT 一時クエリが表示され、
user_pageviewsストリームのストリーミング出力が結果ウィンドウに表示されます。結合されたストリームには、pageviews_streamとusers_tableのすべてのフィールドが含まれます。注釈
クエリでは EMIT CHANGES 構文が使用されており、これが "プッシュクエリ" であることがわかります。プッシュクエリでは、ストリームまたはテーブルに対するクエリを実行して、結果に対するサブスクリプションを使用できます。停止するまで継続されます。詳細については、プッシュクエリ を参照してください。
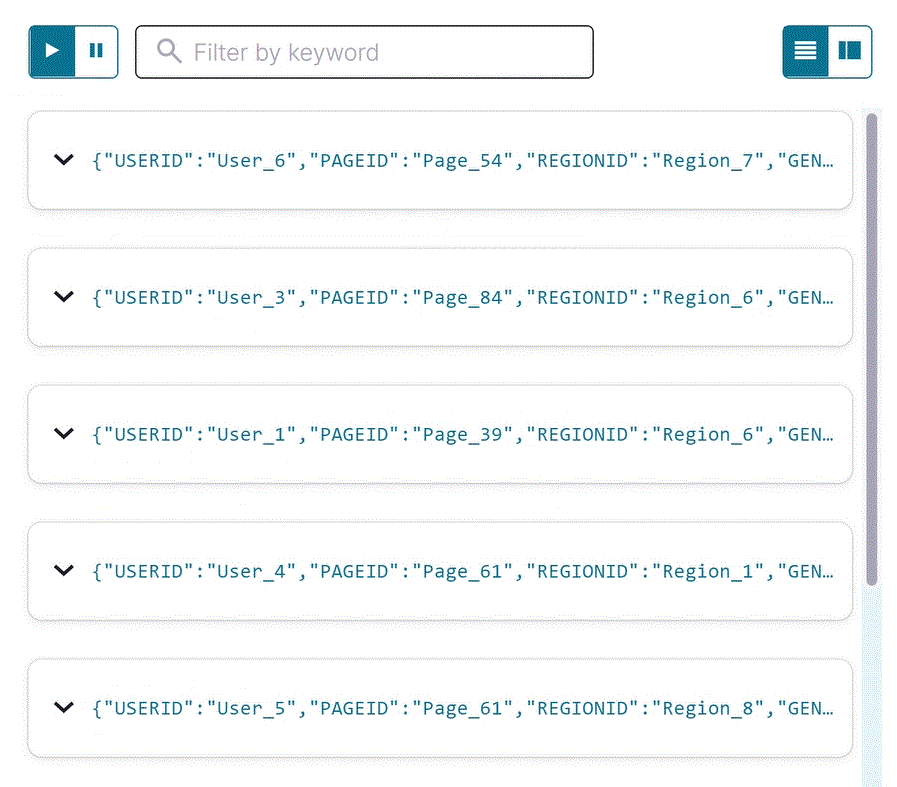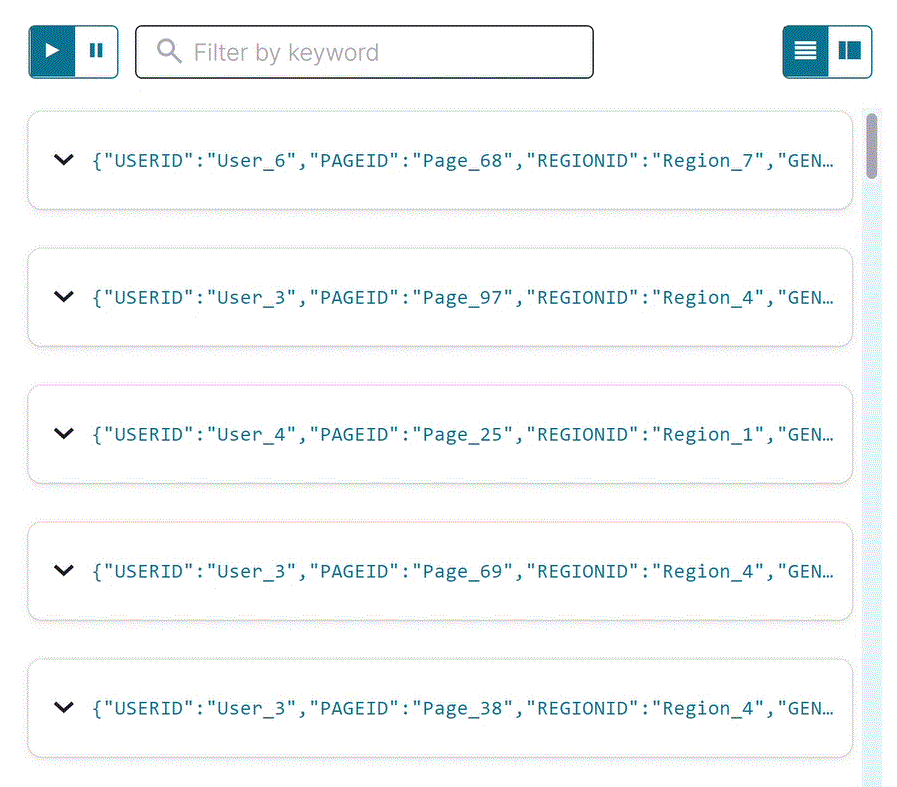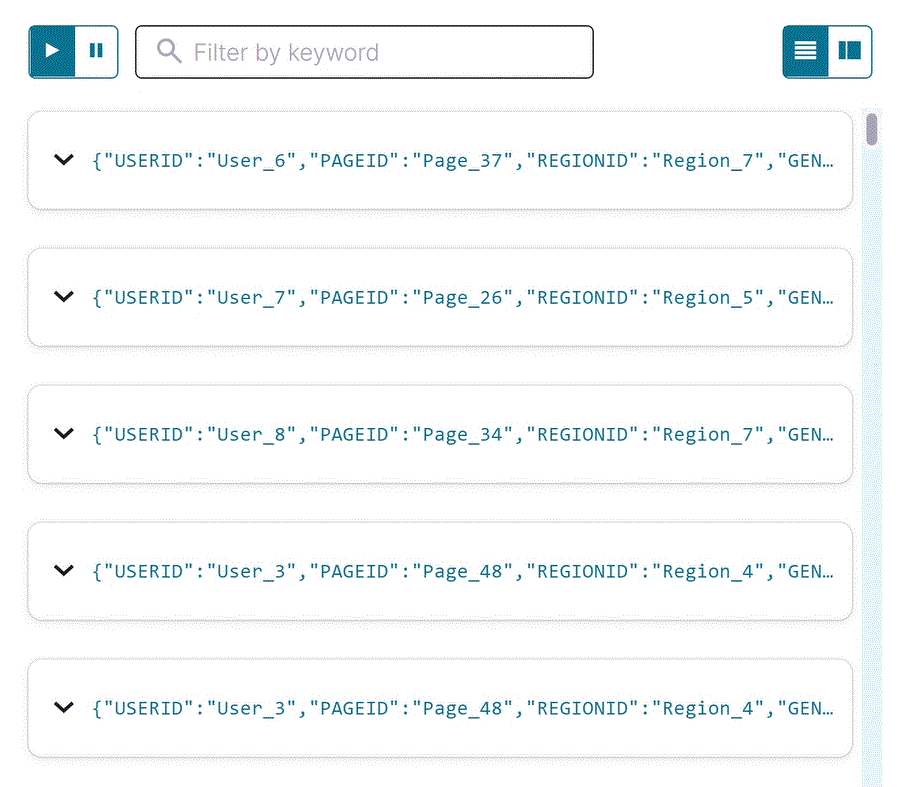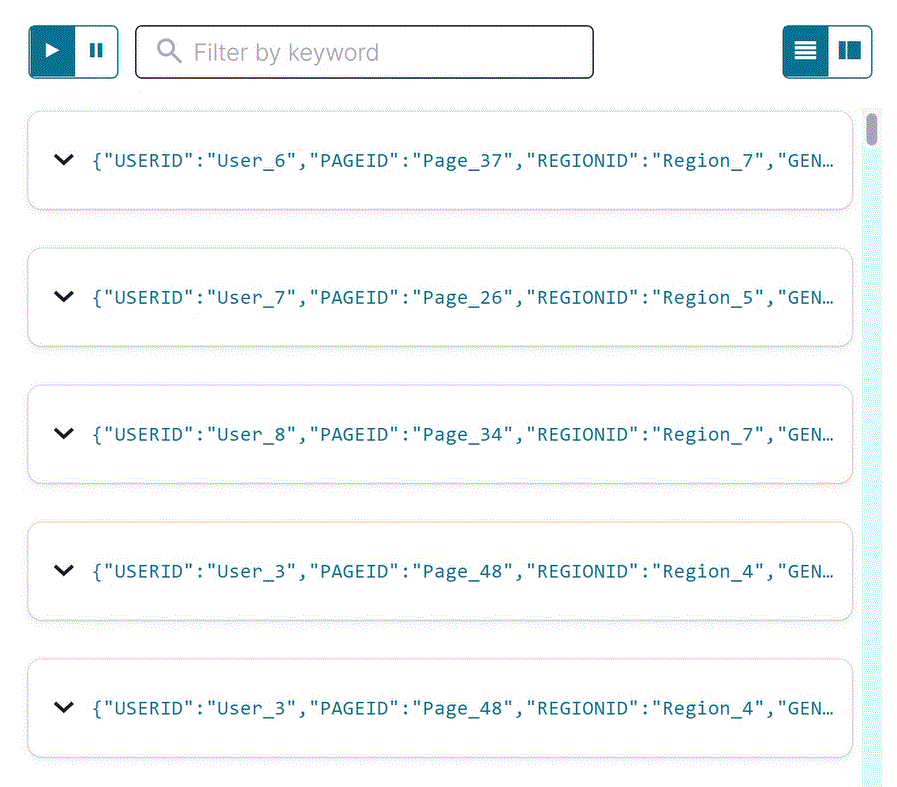
Stop をクリックして一時的なプッシュクエリを終了します。
ストリームへのフィルターの適用¶
このステップでは、pageviews_region_like_89 という名前のストリームを作成します。このストリームは、末尾が 8 または 9 の regionid 値を含む user_pageviews 行で構成されます。このクエリの結果は pageviews_filtered_r8_r9 という名前の新しいトピックに書き込まれます。トピック名は、KAFKA_TOPIC キーワードを使用してクエリ内で明示的に指定されています。
以下の SQL をエディターにコピーして Run query をクリックします。
CREATE STREAM pageviews_region_like_89 WITH (KAFKA_TOPIC='pageviews_filtered_r8_r9', VALUE_FORMAT='AVRO') AS SELECT * FROM user_pageviews WHERE regionid LIKE '%_8' OR regionid LIKE '%_9' EMIT CHANGES;
出力は以下のようになります。
{ "@type": "currentStatus", "statementText": "CREATE STREAM PAGEVIEWS_REGION_LIKE_89 WITH (KAFKA_TOPIC='pageviews_filtered_r8_r9', PARTITIONS=1, REPLICAS=1, VALUE_FORMAT='AVRO') AS SELECT *\nFROM USER_PAGEVIEWS USER_PAGEVIEWS\nWHERE ((USER_PAGEVIEWS.REGIONID LIKE '%_8') OR (USER_PAGEVIEWS.REGIONID LIKE '%_9'))\nEMIT CHANGES;", "commandId": "stream/`PAGEVIEWS_REGION_LIKE_89`/create", "commandStatus": { "status": "SUCCESS", "message": "Created query with ID CSAS_PAGEVIEWS_REGION_LIKE_89_7", "queryId": "CSAS_PAGEVIEWS_REGION_LIKE_89_7" }, "commandSequenceNumber": 8, "warnings": [] }
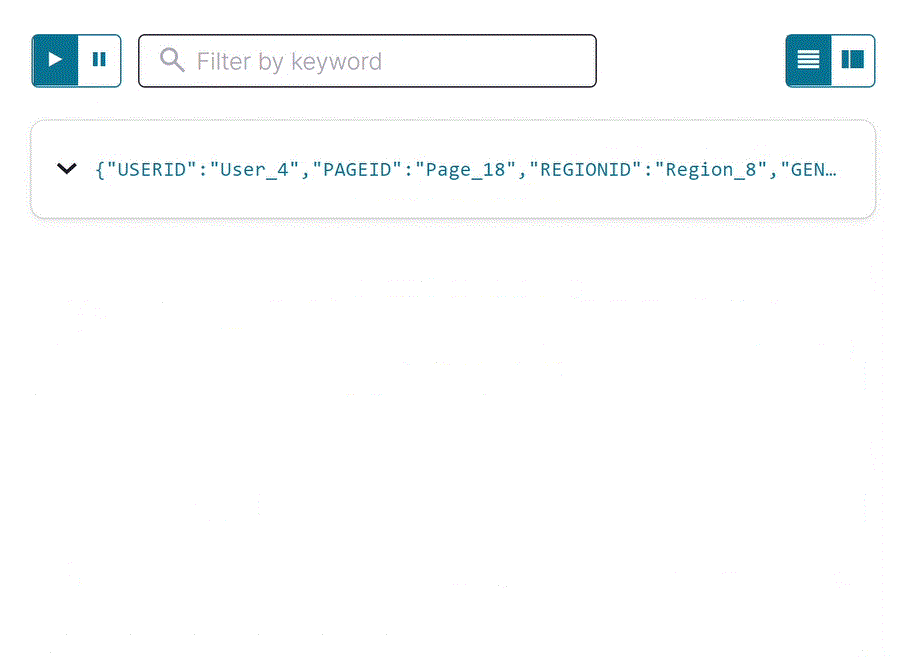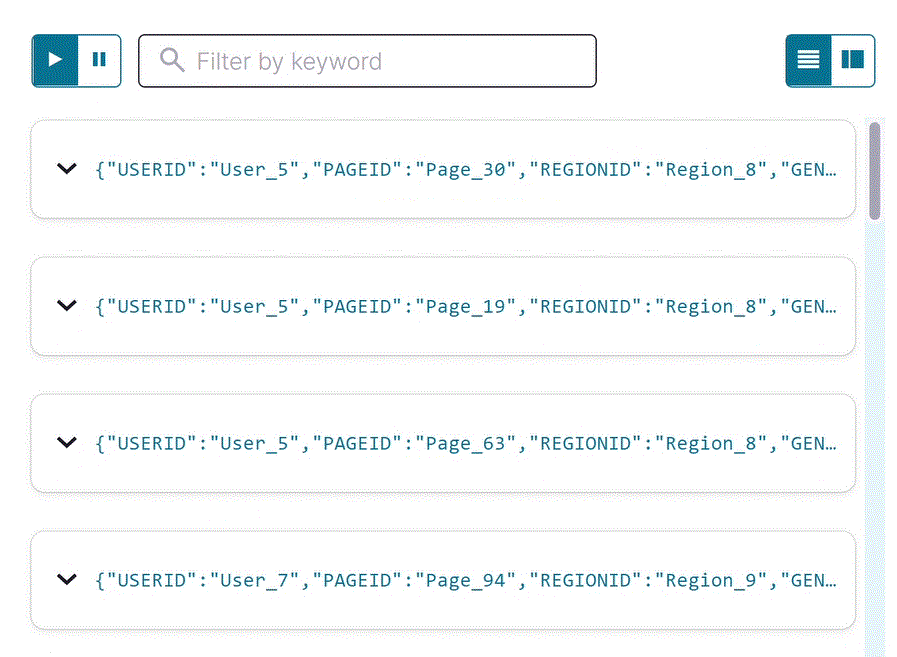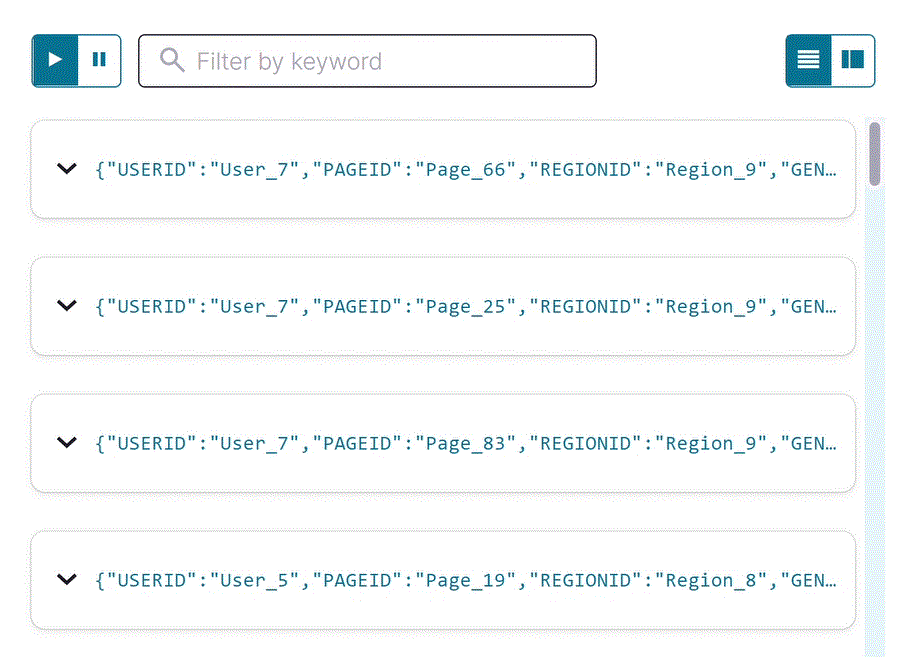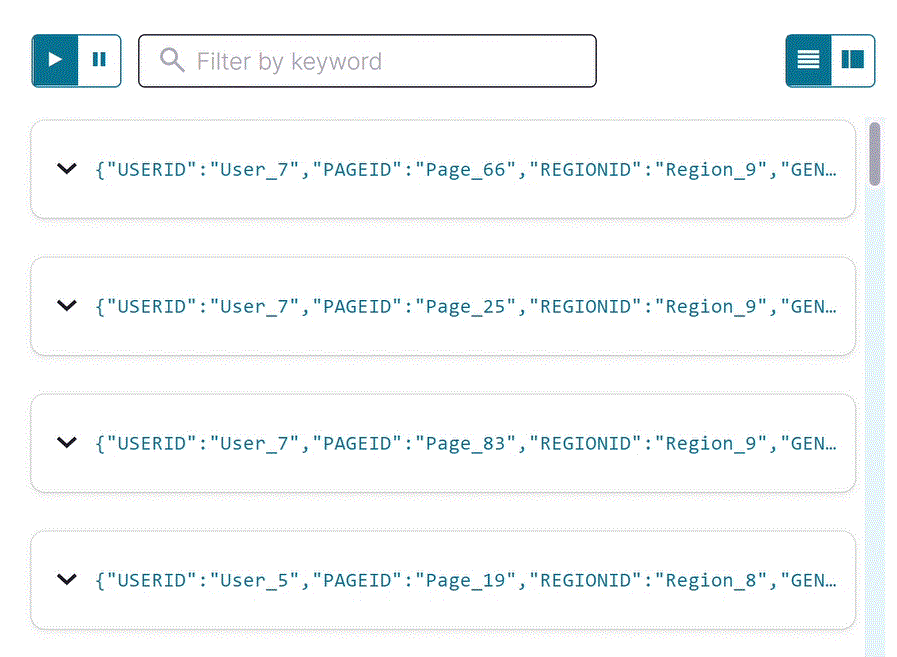
pageviews_region_like_89ストリームのフィルターが適用された出力を確認します。以下の SQL をエディターにコピーして Run query をクリックします。SELECT * FROM pageviews_region_like_89 EMIT CHANGES;
出力は以下のようになります。
ウィンドウ化されたビューの作成¶
このステップでは、pageviews_per_region_89 という名前のテーブルを作成して、SIZE が 30 秒の タンブリングウィンドウ でリージョン 8 および 9 からのページビューの数をカウントします。クエリの結果は、行をカウントしてグループ化する集計であるため、結果はストリームではなくテーブルです。
以下の SQL をエディターにコピーして Run query をクリックします。
CREATE TABLE pageviews_per_region_89 WITH (KEY_FORMAT='JSON') AS SELECT userid, gender, regionid, COUNT(*) AS numusers FROM pageviews_region_like_89 WINDOW TUMBLING (SIZE 30 SECOND) GROUP BY userid, gender, regionid HAVING COUNT(*) > 1 EMIT CHANGES;
出力は以下のようになります。
{ "@type": "currentStatus", "statementText": "CREATE TABLE PAGEVIEWS_PER_REGION_89 WITH (KAFKA_TOPIC='PAGEVIEWS_PER_REGION_89', KEY_FORMAT='JSON', PARTITIONS=1, REPLICAS=1) AS SELECT\n PAGEVIEWS_REGION_LIKE_89.GENDER GENDER,\n PAGEVIEWS_REGION_LIKE_89.REGIONID REGIONID,\n COUNT(*) NUMUSERS\nFROM PAGEVIEWS_REGION_LIKE_89 PAGEVIEWS_REGION_LIKE_89\nWINDOW TUMBLING ( SIZE 30 SECONDS ) \nGROUP BY PAGEVIEWS_REGION_LIKE_89.GENDER, PAGEVIEWS_REGION_LIKE_89.REGIONID\nHAVING (COUNT(*) > 1)\nEMIT CHANGES;", "commandId": "table/`PAGEVIEWS_PER_REGION_89`/create", "commandStatus": { "status": "SUCCESS", "message": "Created query with ID CTAS_PAGEVIEWS_PER_REGION_89_9", "queryId": "CTAS_PAGEVIEWS_PER_REGION_89_9" }, "commandSequenceNumber": 10, "warnings": [] }
pageviews_per_region_89テーブルのウィンドウ化された出力を確認します。以下の SQL をエディターにコピーして Run query をクリックします。SELECT * FROM pageviews_per_region_89 EMIT CHANGES;
出力は以下のようになります。

NUMUSERS 列は、30 秒の時間枠内にクリックしたユーザーの数を示しています。
プルクエリを使用したテーブルのスナップショットの作成¶
プルクエリを使用して、テーブルの現在のステートを取得できます。プルクエリでは、クエリの発行時点での指定のキーの行が返されます。プルクエリは 1 回実行されると終了します。
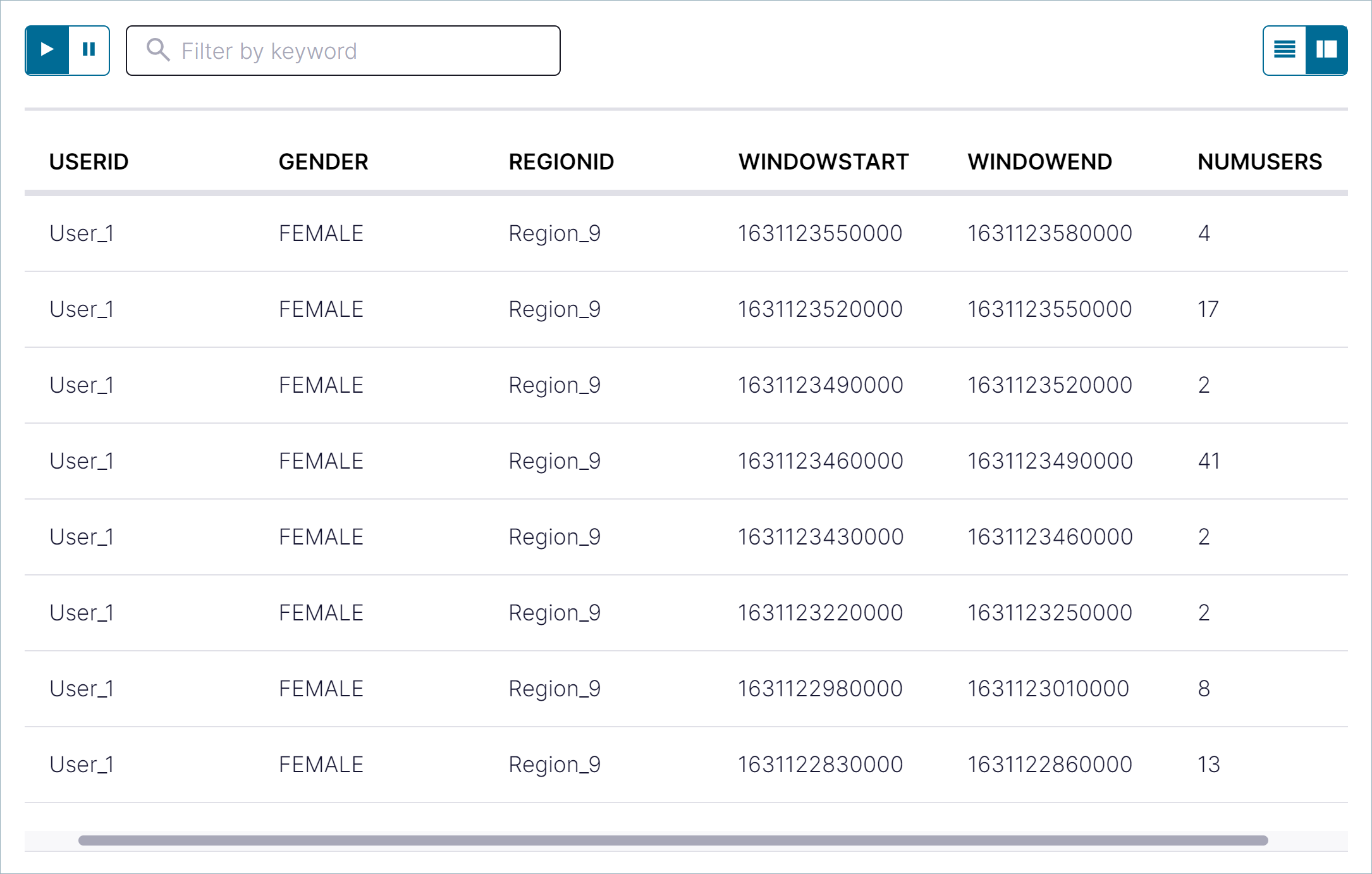
このステップでは、pageviews_per_region_89 テーブルに対してクエリを実行して、Region_9 で User_1 を含むすべての行を取得します。
以下の SQL をエディターにコピーして Run query をクリックします。
SELECT * FROM pageviews_per_region_89
WHERE userid = 'User_1' AND gender='FEMALE' AND regionid='Region_9';
出力は以下のようになります。
ストリームとテーブルの確認¶
All available streams and tables ペインには、アクセスできるすべてのストリームおよびテーブルが表示されます。PAGEVIEWS_PER_REGION をクリックして、
pageviews_per_regionテーブルのフィールドを確認します。
All available streams and tables セクションで KSQL_PROCESSING_LOG をクリックすると、処理ログのフィールドが表示されます。これには、ネストしたデータ構造も含まれます。処理ログでは、SQL ステートメントの処理中に発生したエラーを確認できます。他のストリームと同様に、処理ログに対してクエリを実行することができます。詳細については、『Processing log』を参照してください。
Persistent queries をクリックして、作成したストリームとテーブルを確認します。

このページでは、クエリが実行されているかどうかの確認、クエリの情報の確認、実行中のクエリの終了ができます。
ステップ 5: アプリのストリームトポロジーの視覚化¶
作成したストリーミングアプリケーションでは、Datagen コネクターから pageviews トピックおよび users トピックにイベントが流れます。行に対して結合とフィルターの処理が行われ、最後のステップでは、ストリーミングデータのテーブルビューで行が集計されます。
フロービューを使用してシステム全体をエンドツーエンドで確認することができます。
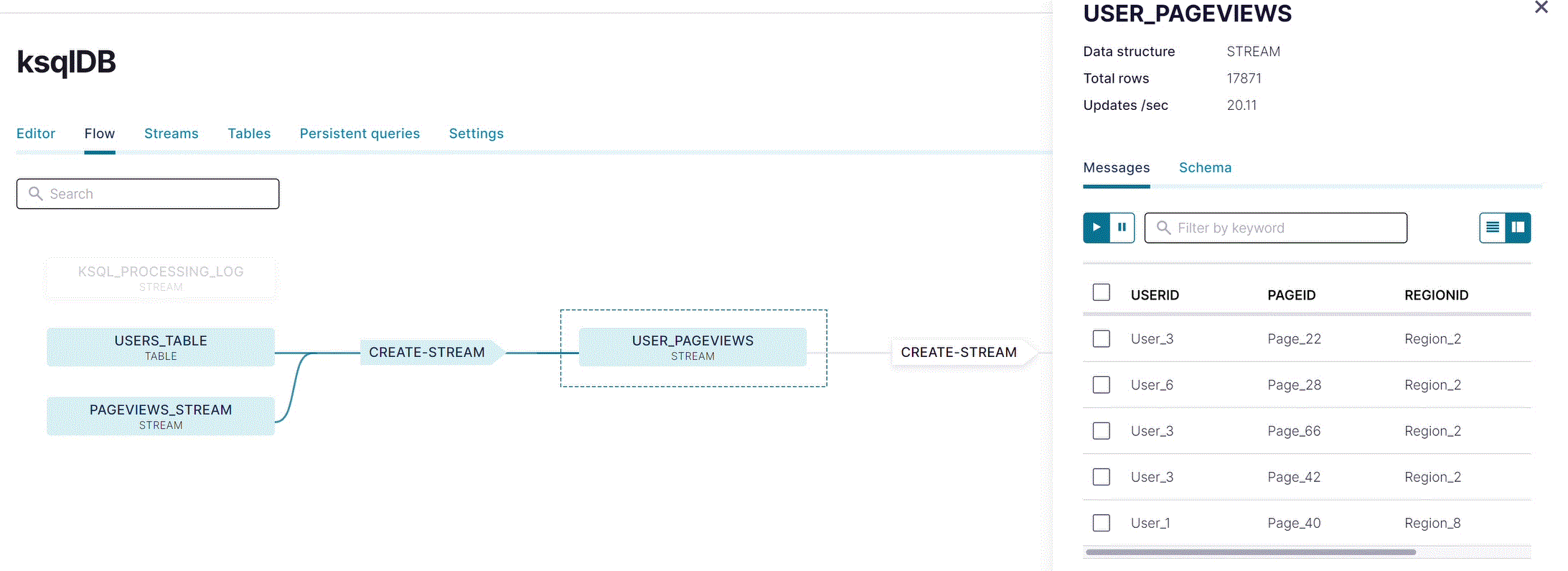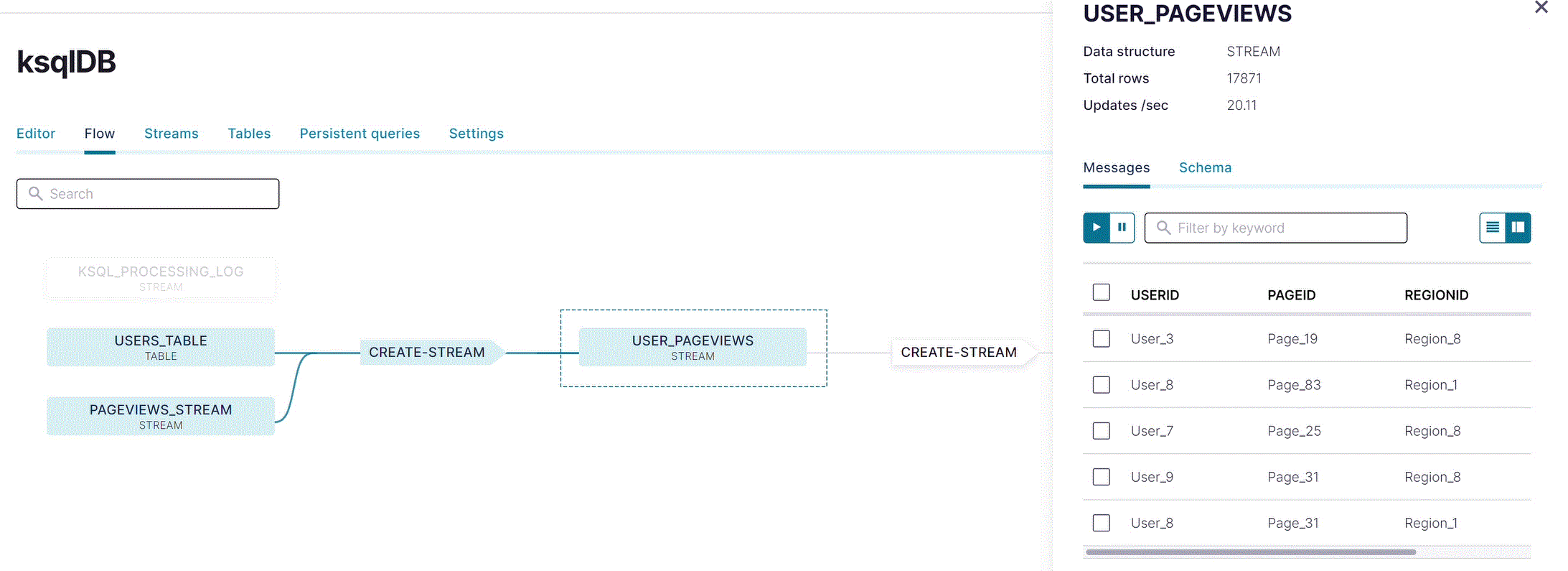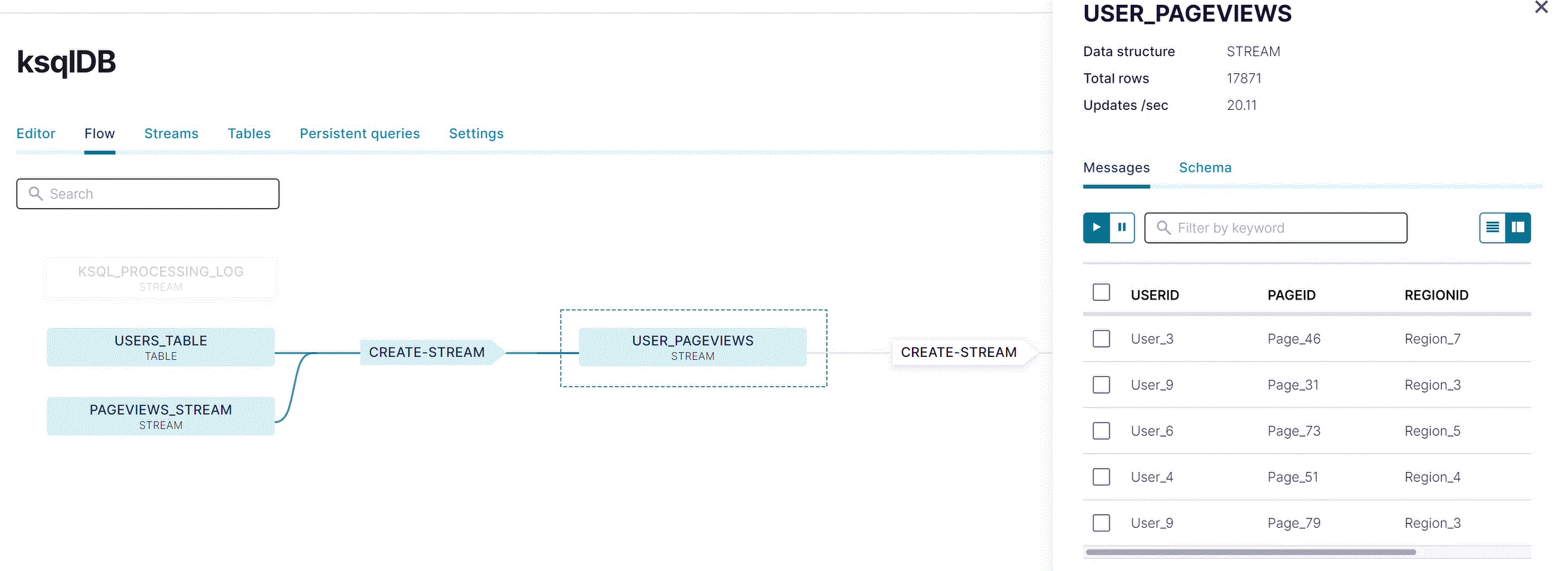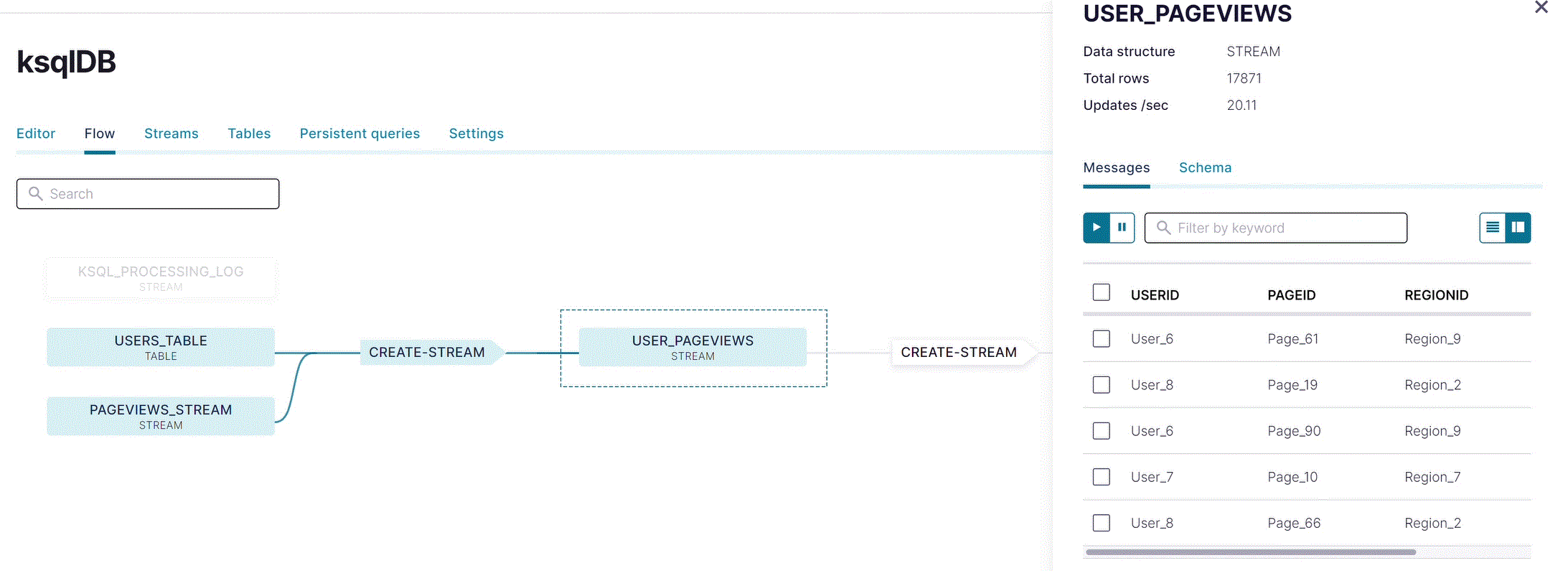
Flow をクリックして、フロービューを開きます。アプリのストリームトポロジーが表示されます。ストリーム、テーブル、それらを作成するために実行したステートメントを確認できます。
USER_PAGEVIEWS をクリックして、結合されたストリームを確認します。
図の中の他のノードをクリックして、アプリ内を流れるデータを確認します。
ステップ 6: アンインストールとクリーンアップ¶
Confluent Platform の操作が済んだら、簡単な手順で削除できます。削除すると、ストレージやその他のシステムリソースが解放されます。
Docker での作業が完了したら、Docker コンテナーおよびイメージを停止し、削除することができます。
以下のコマンドを実行して、Confluent の Docker コンテナーを停止します。
docker-compose stop
Docker コンテナーを停止した後に、以下のコマンドを実行して Docker システムを削除します。これらのコマンドを実行すると、コンテナー、ネットワーク、ボリューム、イメージが削除され、ディスク領域が解放されます。
docker system prune -a --volumes --filter "label=io.confluent.docker"詳細については、Docker の公式ドキュメントを参照してください。
ローカルインストールでの作業が完了したら、Confluent Platform を停止できます。
Confluent CLI confluent local services connect stop コマンドを使用して、Confluent Platform を停止します。
confluent local services stopconfluent local destroy コマンドを使用して、Confluent Platform インスタンスのデータを削除します。
confluent local destroy
次のステップ¶
- このクイックスタートの自動化バージョン を実行できます。これは、Confluent Platform のローカルインストール向けです。
- Confluent 開発者: ここに用意されているさまざまなコースで Confluent Platform のプログラミングを学べます。
- Confluent Education: さまざまなリソースやハンズオントレーニング、認定試験など、トレーニングや認定に関するガイダンスが用意されています。
- AWS ワークショップ: フルマネージド型の Confluent Cloud on AWS を使用して、リアルタイムにクレジットアプリケーションを処理するサンプルアプリを作成できます。
- ksqlDB ドキュメント: ストリーミング ETL、リアルタイムモニタリング、異常検出などのユースケースについて、ksqlDB を使用したデータ処理について確認できます。一連の スクリプト化されたデモ により、ksqlDB の使用方法も参照してください。
- Kafka チュートリアル: ステップバイステップの指示に従って、基本的な Kafka、Kafka Streams、ksqlDB のチュートリアルを試してみることができます。
- Kafka Streams ドキュメント: ストリーム処理アプリケーションを Java または Scala で構築する方法を確認できます。
- Kafka Connect ドキュメント: Kafka を他のシステムと連携させ、すぐに使用できるコネクター をダウンロードして、Kafka 内外のデータをリアルタイムで簡単に取り込む方法を確認できます。
- Kafka クライアントドキュメント: Go、Python、.NET、C/C++ などのプログラミング言語を使用して、Kafka に対してデータの読み取りおよび書き込みを行う方法を確認できます。
- ビデオ、デモ、および参考文献: Confluent Platform のチュートリアルやサンプルを試したり、デモやスクリーンキャストを参照したり、ホワイトペーパーやブログで調べたりすることができます。