
Kafka Consumer Design: Consumers, Consumer Groups, and Offsets
Apache Kafka® is an open-source distributed streaming system used for stream processing, real-time data pipelines, and data integration at scale.
This topic covers Apache Kafka® consumer design, including how consumers pull data from brokers, the concept of consumer groups, and how consumer offsets are used to track the position of consumers in the log.
What is a consumer?
An Kafka consumer is a client application that reads and processes events from a broker. A consumer issues fetch requests to brokers that are leading partitions that it wants to consume from. When a consumer issues a request, it specifies a log offset, and then receives a chunk of log that starts with the offset position specified. This gives the consumer control over what it consumes, and it can specify an offset to reconsume data if needed.
This topic discusses why Kafka was designed with a consumer pull system, and how a consumer’s position is tracked through offsets.
Push versus pull design
The goal of any messaging system is to fully use the consumer with the correct transfer rate.
Kafka follows a traditional messaging system design in that data is pushed by the producer to the broker and pulled from the broker by the consumer. Other log-centric systems, such as Scribe and Apache Flume, follow a push-based model where data is pushed to the consumers.
An advantage of a pull-based system is that if a consumer falls behind production, they can catch up. Another advantage is that a pull-based system enables aggressive batching of data sent to the consumer. In contrast, a push-based system must either send a request immediately or accumulate more data and then send it later without knowledge of whether the downstream consumer will be able to process it immediately. If tuned for low latency, this can result in sending a single message at a time only for the transfer to be buffered. A pull-based design fixes this by having the consumer pull all available messages after their current position in the log so there is optimal batching without introducing unnecessary latency.
Consumer groups and group IDs
In Kafka, a consumer group is a set of consumers from the same application that work together to consume and process messages from one or more topics. Remember that each topic is divided into a set of ordered partitions. Each partition is consumed by exactly one consumer within each consumer group at any given time.
A consumer group has a group.id and every consumer in that group is assigned the same group.id. To initialize a consumer, you set its group.id property, instantiate the consumer with this set in its configuration, and subscribe to topics. Once a group.id is set, each new consumer instance that uses this group.id is added to the group, treated as a member, and participates in partition assignment.
On the server (broker) side, Kafka uses a Group coordinator to help balance the load across the group. The Group coordinator is determined by the group.id. The Group coordinator helps to distribute the data in the subscribed topics to the consumer group instances evenly and it keeps things balanced when group membership changes occur.
The Group coordinator facilitates partition assignment and helps maintain balance across the group when membership changes occur and as topic metadata changes. The coordinator uses an internal Kafka topic called __consumer_offsets to keep track of group metadata. In a typical Kafka cluster, there are several group coordinators which enables efficient management of multiple consumer groups.
Consumer rebalance protocols and partition assignments
Kafka uses a rebalance protocol that determines how to assign partitions to consumers within a group and how those assignments change as consumers join, leave the group, or topic metadata changes. The rebalance protocol is fundamental to how a consumer group operates. Kafka 4.0 currently supports two rebalance protocols: the original “classic” protocol and a new, “consumer rebalance” protocol. The newer protocol had General Availability (GA) in Kafka 4.0 version, you must use a client that supports 4.0 to use the consumer rebalance protocol.
The classic protocol uses a single leader from among the group to collect metadata from group members, perform client-side partition assignment, and submit the plan to the broker’s group coordinator. The new consumer rebalance protocol eliminates the group leader by allowing each consumer to subscribe to topics, the broker-side group coordinator collects the subscription, and computes this data into final group assignments.
Each protocol defines the group behavior during rebalances and so determines consumer types, classic or “new” consumer. Classic consumers follow the older leader-based model. New consumers support distributed assignment, incremental rebalancing, and reduced disruption. The new consumer rebalance protocol is enabled by default on the server in the Kafka 4.0 version and in Confluent Cloud. Clients must explicitly enable the new consumer rebalance protocol.
The following table details the behavior differences between the two protocols:
Classic Protocol | Consumer Protocol | |
|---|---|---|
group coordinator role | Broker-side component that manages group membership and receives assignment from the group client leader. | Broker-side component that manages group membership and computes assignment for all members. |
group leader | One member performs assignment on behalf of the group. | Not used. No leader election occurs. |
partition assignment | Client-side: group assignment logic is in the client leader. | Server-side: individual consumer subscribes to a topic, may suggest an assignor, but final assignments orchestrated by the broker-side coordinator. |
rebalance trigger | Triggered by group membership or topic metadata changes. Partition assignments are globally synchronized by the leader. | Triggered by group membership or topic metadata changes, partitions are incrementally assigned to consumers. |
rebalance behavior | Eager or Cooperative: assignor dependent. In some circumstances, all consumers may pause and revoke all partitions. | Incremental reassignment with minimal disruption. |
disruption during rebalance | High: all consumers pause until reassignment completes. | Low: unaffected consumers continue processing during rebalance. |
assignment | Handled by one group leader among the consumers. | Broker coordinator receives consumer subscriptions, validates them, computes, and then orchestrates assignment. |
compatibility | Available in all Kafka versions supporting consumer groups. | General Availability (GA) in Kafka 4.0 version and requires the |
For detailed information about using either the new consumer or classic rebalance protocol with Confluent Cloud, see the Kafka Consumer in Confluent Cloud. Presently, Confluent Platform does not support the new consumer protocol. For more information about using the classic protocol with Confluent Platform, see the Kafka Consumer in Confluent Platform.
Tracking consumer position
It is important that a messaging system tracks what has been consumed. Typically, this tracking is stored on the server, which means that as a message is handed to a consumer, the server either immediately records its delivery or it waits for acknowledgement from the consumer and then records it.
In Kafka, the broker and consumer must agree on what has been consumed. If there isn’t agreement, issues can occur. For example, if a broker records a message as consumed immediately after sending it, and the consumer crashes or the request times out, the message doesn’t get processed by the consumer and that message is lost. Alternatively, the broker can wait for acknowledgement from the consumer before recording the message as consumed. In this example, if the consumer processes the message but fails before it can send an acknowledgement, then the message will be consumed twice.
Kafka solves these tracking issues by utilizing consumer offsets.
Consumer offsets
A consumer offset is used to track the progress of a consumer group. An offset is a unique identifier, an integer, which marks the next record that should be read by the consumer in a partition. Since an offset is an integer, consumer state is relatively small. Also the offset is periodically checkpointed to the __consumer_offsets internal topic. This topic is used to store the current offset position for each consumer group, partition and consumer.
You can think about a consumer offset as a bookmark to indicate where a consumer should resume reading from, if there is a pause in reading.
By storing the consumer offsets in a separate topic, Kafka enables consumers to read the last offset from the __consumer_offsets topic and resume processing from where they left off in case of failures or restarts.
Consumer position illustrated
When a consumer group is first initialized, the consumers typically begin reading from either the earliest or latest offset in each partition. The messages in each partition log are then read sequentially. As the consumer makes progress, it commits the offsets of messages it has successfully processed.
In the following image that follows, there are 4 positioned marked:
The consumer’s current position at offset 6.
The last committed offset at offset 1. It’s important to note that the committed offset refers to the next offset the consumer intends to read, not the offset of the last successfully processed message.
The high watermark at offset 10. The high watermark is the offset of the last message that was successfully copied to all of the log’s replicas.
The log end offset at position 14. This is the offset of the last message written to the log.
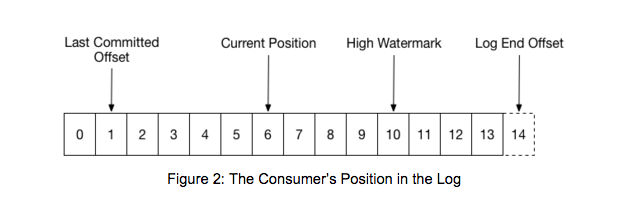
When a partition gets reassigned to another consumer in the group, the initial position is set to the last committed offset. If the consumer in the example above suddenly crashed, then the group member taking over the partition would begin consumption from offset 1. In that case, it would have to reprocess the messages up to the crashed consumer’s position of 6.
A consumer can only read up to the high watermark. This prevents the consumer from reading unreplicated data which could later be lost. [1]
For examples of how to a command-line tools to view consumer groups and offsets in Kafka, see View Consumer Group Info in Kafka.