
Kafka Log Compaction
Apache Kafka® is an open-source distributed streaming system used for stream processing, real-time data pipelines, and data integration at scale.
This topic describes why Kafka log compaction and retention are essential features of Kafka that help ensure the integrity of data within a Kafka topic partition.
Topic compaction
Topic compaction is a mechanism that allows you to retain the latest value for each message key in a topic, while discarding older values. It guarantees that the latest value for each message key is always retained within the log of data contained in that topic, making it ideal for use cases such as restoring state after system failure or reloading caches after application restarts. Continue reading to learn about log compaction and retention in more detail and to understand how they work to preserve the accuracy of data streams.
Retention example
In the example that follows, there is a topic that contains user email addresses; every time a user updates their email address this topic receives a message using the user ID as the primary key. Over a period of time, the following messages are sent for user ID 123. In this example, each message corresponds to an email address change. (messages for other IDs are omitted):
123 => bill@microsoft.com
.
.
.
123 => bill@gatesfoundation.org
.
.
.
123 => bill@gmail.com
Log compaction provides a granular retention mechanism so at least the last update for each primary key is retained. For the example, bill@gmail.com would be retained. This guarantees that the log contains a full snapshot of the final value for every key, not just keys that changed recently. This means downstream consumers can restore their own state off this topic requiring the retention of a complete log of all changes.
Following are some use cases where this is important:
Database change subscriptions. You may have a data set in multiple data systems and often one of these systems is a database. For example you might have the cache, search cluster, and Hadoop. If you are handling the real-time updates you only need the recent log, but if you want to be able to reload the cache or restore a failed search node you may need a complete data set.
Event sourcing. While not enabled by compaction, compaction does ensure you always know the latest state of each key, which is important for event sourcing.
Journaling for high-availability. A process that does local computation can be made fault-tolerant by logging out changes that it makes to its local state so another process can reload these changes and carry on if it should fail. A concrete example of this is handling counts, aggregations, and other “group by”-like processing in a stream processing system. Kafka Streams uses this feature for this purpose.
Important
Compacted topics must have records with keys in order to implement record retention.
Compaction in Kafka does not guarantee there is only one record with the same key at any one time. There may be multiple records with the same key, including the tombstone, because compaction timing is non-deterministic. Compaction is only done when the topic partition satisfies a few certain conditions, such as dirty ratio, or records in inactive segment files, etc.
In each of these cases, you primarily must handle the real-time feed of changes, but occasionally, when a machine crashes or data needs to be reloaded or reprocessed, you must do a full load. Log compaction enables feeding both of these use cases off the same backing topic. This style log usage is described in more detail in the blog post, The Log by Jay Kreps.
Simply, if the system had infinite log retention, and every change was logged, the state of the system at every moment from when it started would be captured. Using this log, the system could be restored to any point in time by replaying the first N records in the log. However, this hypothetical complete log is not practical for systems that update a single record many times, as the log will grow without bound. The simple log retention mechanism that discards old updates bounds space, but the log cannot be used to restore the current state, meaning restoring from the beginning of the log no longer recreates the current state as old updates may not be captured.
Log compaction is a mechanism to provide finer-grained per-record retention instead of coarser-grained time-based retention. Records with the same primary key are selectively removed when there is a more recent update. This way the log is guaranteed to have at least the last state for each key.
This retention policy can be set per-topic, so a single cluster can have some topics where retention is enforced by size or time and other topics where retention is enforced by compaction.
Unlike most log-structured storage systems Kafka is built for subscription and organizes data for fast linear reads and writes. Kafka acts as a source-of-truth store so it is useful even in situations where the upstream data source would not otherwise be replayable.
Compaction in action
The following image provides the logical structure of a Kafka log, at a high level, with the offset for each message.
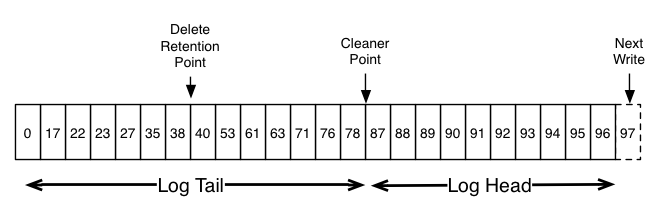
The head of the log is identical to a traditional Kafka log. It has dense, sequential offsets and retains all messages. Log compaction adds an option for handling the tail of the log.
The image shows a log with a compacted tail. However, the messages in the tail of the log retain the original offset assigned when they were first written. Also, all offsets remain valid positions in the log, even if the message with that offset has been compacted away; in this case this position is indistinguishable from the next highest offset that does appear in the log. For example, in the previous image, the offsets 36, 37, and 38 are all equivalent positions and a read beginning at any of these offsets would return a message set beginning with 38.
Compaction enables deletes
Compaction also enables deletes. A message with a key and a null payload (note that a string value of null is not sufficient) will be treated as a delete from the log. These null payload messages are also called tombstones. Similar to when a new message with the same key arrives, this delete marker results in the deletion of the previous message with the same key. However, delete markers (tombstones) are special in that they are also cleaned out of the log after a period of time to free up space. This point is time is marked as the Delete Retention Point in the previous image, and is configured with delete.retention.ms on a topic.
View of compaction
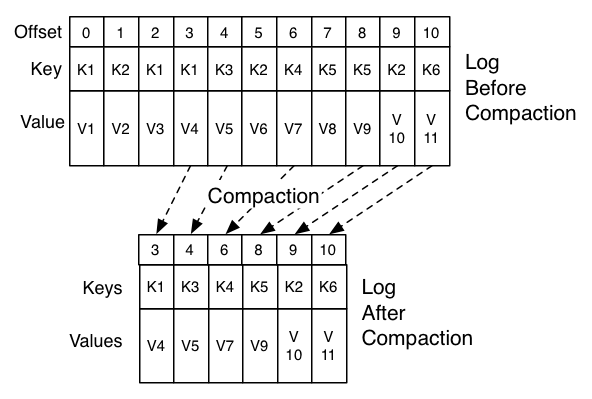
Compaction is done in the background by periodically recopying log segments. Cleaning does not block reads and can be throttled to use no more than a configurable amount of I/O throughput to avoid impacting producers and consumers. The actual process of compacting a log segment looks something like the following:
Topic compaction video
For an excellent video that describes log compaction in more detail, watch:
Compaction guarantees
Log compaction guarantees the following:
Any consumer that stays caught-up to the head of the log will see every message that is written; these messages will have sequential offsets. The topic’s
min.compaction.lag.msproperty can be used to guarantee the minimum length of time that must pass after a message is written before it could be compacted. It provides a lower bound on how long each message will remain in the uncompacted head. The topic’smax.compaction.lag.msproperty can be used to guarantee the maximum delay between the time a message is written and the time the message becomes eligible for compaction.Ordering of messages is always maintained. Compaction will never reorder messages, just remove some.
The offset for a message never changes. It is the permanent identifier for a position in the log.
Any consumer progressing from the start of the log will see at least the final state of all records in the order they were written. Additionally, all delete markers for deleted records will be seen, provided the consumer reaches the head of the log in a time period less than the topic’s
delete.retention.mssetting (the default is 24 hours). In other words: since the removal of delete markers happens concurrently with reads, it is possible for a consumer to miss delete markers if it lags by more thandelete.retention.ms.
Configure compaction
Following are some important topic configuration properties for log compaction.
cleanup.policyEnable log compaction by setting the cleanup policy on a topic. This topic-level setting overrides the broker-level default
log.cleanup.policyproperty. Add the property either at topic creation time or using thealtercommand. For more information on modifying a topic setting, see Change the retention value for a topic.min.compaction.lag.msThe log cleaner can be configured to retain a minimum amount of the uncompacted “head” of the log. This is enabled by setting the compaction time lag. Use the
minsetting to prevent messages newer than a minimum message age from being subject to compaction. If not set, all log segments are eligible for compaction except for the last segment, meaning the one currently being written to. The active segment will not be compacted even if all of its messages are older than the minimum compaction time lag. The log cleaner can be configured to ensure a maximum delay after which the uncompacted “head” of the log becomes eligible for log compaction.max.compaction.lag.msUse this setting to prevent logs with low produce rates from remaining ineligible for compaction for an unbounded duration. If not set, logs that do not exceed
min.cleanable.dirty.ratioare not compacted. Note that this compaction deadline is not a hard guarantee since it is still subjected to the availability of log cleaner threads and the actual compaction time. You will want to monitor theuncleanable.partitions.count,max.clean.time.secsandmax.compaction.delay.secsmetrics. For more about monitoring logs in Kafka, see Monitor Log Metrics.delete.retention.msConfigures the amount of time to retain delete tombstone markers for log compacted topics. This setting also gives a bound on the time in which a consumer must complete a read starting from offset 0 to ensure that they get a valid snapshot of the state of the topic. Use this setting to help prevent tombstones from being collected before a consumer completes their scan.
Confluent Tip
Read more about these topic configuration values in the Confluent Platform documentation. See:
Note
This website includes content developed at the Apache Software Foundation under the terms of the Apache License v2.