
Kafka Replication and Committed Messages
Apache Kafka® is an open-source distributed streaming system used for stream processing, real-time data pipelines, and data integration at scale.
This topic describes how Kafka replication is configured and works, and how it enables committed messages.
Replication overview
Kafka replicates the event log for each topic’s partitions across a configurable number of servers. This replication factor is configured at the topic level, and the unit of replication is the topic partition. This enables automatic failover to these replicas when a server in the cluster fails so messages remain available.
Under non-failure conditions, each partition in Kafka has a single leader and zero or more followers. In Kafka, all topics must have a replication factor configuration value. The replication factor includes the total number of replicas including the leader, which means that topics with a replication factor of one (1) are topics that are not replicated.
All reads and writes go to the leader of the partition.
Typically, there are many more partitions than brokers and the leaders are evenly distributed among brokers. The logs on the followers are identical to the leader’s log; all have the same offsets and messages in the same order. Although at any given time, the leader may have a few unreplicated messages at the end of its log.
The following image shows a topic with three partitions and how they might be replicated across three brokers.
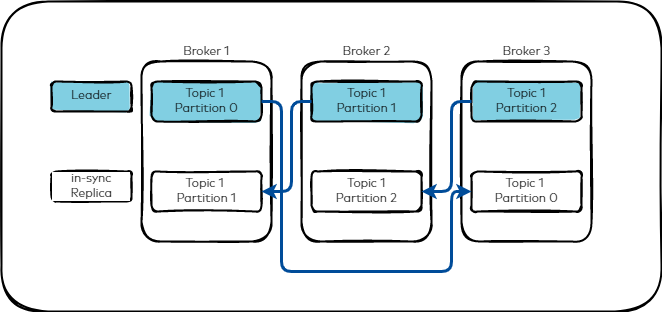
Followers consume messages from the leader like a Kafka consumer would and apply them to their own log. Followers pulling from the leader enables the follower to batch log entries applied to their log.
As with most distributed systems, automatically handling failures requires having a precise definition of what it means for a node to be alive. For Kafka node to be considered alive, it has to meet two conditions
A node must be able to maintain its session with the controller
If it is a follower it must replicate the writes happening on the leader and not fall “too far” behind
These nodes are called “in sync” versus “alive” or “failed”. The leader keeps track of the set of in-sync nodes. If a follower fails, gets stuck, or falls behind, the leader will remove it from the list of in-sync replicas. The replica.lag.time.max.ms configuration specifies what replicas are considered stuck or lagging.
In distributed systems terminology, Kafka attempts to handle “fail/recover” scenarios where nodes suddenly cease working and then later recover, but does not handle Byzantine failures, in which nodes produce arbitrary or malicious responses due to foul play or bugs.
In-sync replicas and producer acks
Kafka guarantees that a committed message will not be lost, as long as there is at least one in-sync replica alive at all times. In this context, a committed message means that all in-sync replicas for a partition have applied the message to their log. Consumers will only receive committed messages, meaning a consumer will never see a message that is potentially lost if a leader fails.
To enable this functionality, a producer provides the acks property, which controls whether the producer waits for the message to be committed, balancing latency versus durability for that producer.
Use the acks=all setting to request acknowledgment that a message has been written to the full set of in-sync replicas. You configure how many in-sync replicas are required with the min.insync.replicas property at the topic level.
If a producer requires less stringent acknowledgment (acks=0 or acks=1), the producer will receive the acknowledgment earlier. With acks=0, the producer will immediately ack without waiting for the response from the server. With acks=1, the server will ack to the producer if the messages are written to the leader’s local log. Then, the messages are available to the consumers after they are replicated to all the in-sync replicas (ISRs). Note that, if the number of ISRs is less than the minimum setting, the messages will not be available to the consumers until the number of ISRs has reached the minimal setting and the messages are replicated to all the ISRs.
Kafka remains available in the presence of node failures after a short fail-over period, but may not remain available in the presence of network partitions.
Replicated logs: quorums, ISRs, and state machines
As discussed previously, a Kafka partition is a replicated log. The replicated log is one of the most basic primitives in distributed data systems, and there are many approaches for implementing one. A replicated log can be used as a primitive for implementing distributed systems in the state-machine style.
A replicated log models the process of coming into consensus on the order of a series of values, generally numbering the log entries 0, 1, 2 and so on. The simplest way to implement this is with a leader that chooses the ordering of values provided to it. As long as the leader remains alive, all followers need to only copy the values in the order specified by the leader.
When a leader fails, a new leader must be chosen from the followers, but followers may fall behind or crash so the chosen follower must be up-to-date. The fundamental guarantee a log replication algorithm provides is that if we tell a client a message is committed, and the leader fails, the newly-elected leader must also have that message. This results in a tradeoff: if the leader waits for more followers to acknowledge a message before declaring it committed, then there are more electable leaders.
A quorum occurs when when you choose the number of acknowledgements required and the number of logs that must be compared to elect a leader so that an overlap is guaranteed.
One approach to this is to use a majority vote for both the commit decision and the leader election. A downside of majority vote is that the majority of nodes must be running to tolerate a failure. With majority vote, tolerating one failure requires three copies of the data, tolerating two failures requires five copies of the data.
However, majority vote has a nice property: latency depends on only the fastest servers. That is, if the replication factor is three, the latency is determined by the faster follower not the slower one.
Kafka running with ZooKeeper takes a slightly different approach to choosing its quorum set. Instead of majority vote, Kafka dynamically maintains a set of in-sync replicas (ISR) that are caught-up to the leader. Only members of this set are eligible for election as leader. A write to a Kafka partition is not considered committed until all in-sync replicas have received the write. This ISR set is persisted to Zookeeper whenever it changes, and any replica in the ISR is eligible to be elected leader. This is an important factor for Kafka’s usage model where there are many partitions and ensuring leadership balance is important. With this ISR model and f+1 replicas, a Kafka topic can tolerate f failures without losing committed messages.
For most use cases, this tradeoff is a reasonable one. In practice, to tolerate f failures, both the majority vote and ISR approach will wait for the same number of replicas to acknowledge before committing a message. For example, to survive one failure:
A majority vote quorum needs three replicas and one acknowledgement
The ISR approach requires two replicas and one acknowledgement
The ability to commit without the slowest servers is an advantage of the majority vote approach.
Another important design distinction is that Kafka does not require that crashed nodes recover with all their data intact. Often replication algorithms depend on the existence of “stable storage” that cannot be lost in any failure-recovery scenario without potential consistency violations. There are two primary problems with this assumption.
Disk errors are the most common problem observed in the real operation of persistent data systems and they often do not leave data intact.
Requiring the use of fsync on every write for consistency guarantees can reduce performance by two to three orders of magnitude. The Kafka protocol for allowing a replica to rejoin the ISR ensures that before rejoining, it must fully re-sync again even if it lost unflushed data in its crash.
Unclean leader election and partition loss
Note that Kafka’s guarantee for data loss relies on at least one replica remaining in sync. If all the nodes replicating a partition die, this guarantee is invalidated.
If all of the replicas die, there are two possible behaviors:
Wait for a replica in the ISR to come back to life and choose this replica as the leader with the hope it retains all of its data.
Choose the first replica (not necessarily in the ISR) that comes back to life as the leader.
This is a simple tradeoff between availability and consistency. If the system waits for replicas in the ISR, then it will remain unavailable as long as those replicas are down. If the ISR replicas were destroyed or their data was lost, the system is permanently down. If, on the other hand, a non-in-sync replica comes back to life and it becomes the leader, then its log becomes the source of truth even though it is not guaranteed to have every committed message. By default from version 0.11.0.0, Kafka chooses the first strategy and favors waiting for a consistent replica. This behavior can be changed using configuration property unclean.leader.election.enable, to support use cases where uptime is preferable to consistency.
This tradeoff is not specific to Kafka, and exists in any quorum-based scheme. For example in a majority voting quorum, if a majority of servers suffer permanent failures, then you must either choose to lose 100% of your data or violate consistency by taking what remains on an existing server as your new source of truth.
Replica management
The previous section on replicated logs covers a single log, in other words, one topic partition. However a Kafka cluster manages hundreds or thousands of these partitions. Kafka attempts to balance partitions within a cluster in a round-robin fashion. This avoids clustering all partitions for high-volume topics on a small number of nodes. Likewise, Kafka also tries to balance leadership so that each node is the leader for a proportional share of its partitions.
The leadership election process is the critical window of unavailability, and must be optimized. To accomplish this, one of the brokers is elected as the “controller”. This broker controller detects failures at the broker level and changes the leader of all affected partitions when a broker fails. The result is leadership change notifications are batched, which makes the election process fast for a large number of partitions. If the controller fails, one of the surviving brokers will become the new controller.