Important
You are viewing documentation for an older version of Confluent Platform. For the latest, click here.
Confluent Replicator¶
The Confluent Replicator allows you to easily and reliably replicate topics from one Apache Kafka® cluster to another. In addition to copying the messages, this connector will create topics as needed preserving the topic configuration in the source cluster. This includes preserving the number of partitions, the replication factor, and any configuration overrides specified for individual topics.
The diagram below shows a typical multi-datacenter deployment in which the data from two Kafka clusters, located in separate datacenters is aggregated in a separate cluster located in another datacenter. Throughout this document, the origin of the copied data is referred to as the “source” cluster while the target of the copied data is referred to as the “destination.”
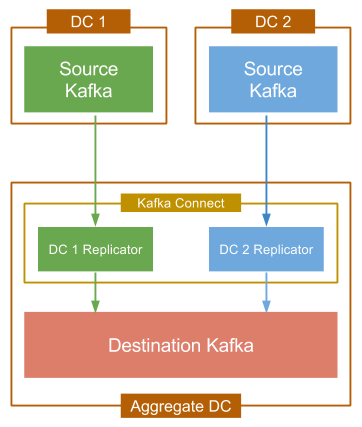
Replication to an Aggregate Cluster
Each source cluster requires a separate instance of the Replicator. For convenience you can run them in the same Connect cluster, which is typically located in the aggregate datacenter.
Features¶
The Confluent Replicator supports the following features:
- Topic selection using whitelists, blacklists, and regular expressions.
- Dynamic topic creation in the destination cluster with matching partition counts, replication factors, and topic configuration overrides.
- Automatic resizing of topics when new partitions are added in the source cluster.
- Automatic reconfiguration of topics when topic configuration changes in the source cluster.
- Starting with Confluent Platform 5.0.0, you can migrate from MirrorMaker to Replicator on existing datacenters. Migration from MirrorMaker to Replicator is not supported in earlier versions of Confluent Platform.
Requirements¶
From a high level, the Replicator works like a consumer group with the partitions of the replicated topics from the source cluster divided between the connector’s tasks. The Confluent Replicator periodically polls the source cluster for changes to the configuration of replicated topics and the number of partitions, and updates the destination cluster accordingly by creating topics or updating configuration. For this to work correctly, the following is required:
- The connector’s principal must have permission to create and modify topics in the destination cluster. This requires write access to the corresponding ZooKeeper.
- The default topic configurations in the source and destination
clusters must match. In general, aside from any broker-specific
settings (such as
broker.id), you should use the same broker configuration in both clusters. - The destination Kafka cluster must have a similar capacity as the source cluster. In particular, since the Replicator will preserve the replication factor of topics in the source cluster, which means that there must be at least as many brokers as the maximum replication factor used. If not, topic creation will fail until the destination cluster has the capacity to support the same replication factor. Note in this case, that topic creation will be retried automatically by the connector, so replication will begin as soon as the destination cluster has enough brokers.
- The
dest.kafka.bootstrap.serversdestination connection setting in the Replicator properties file must be configured to use a single destination cluster, even when using multiple source clusters. For example, the figure shown at the start of this section shows two source clusters in different datacenters targeting a single aggregate destination cluster. Note that the aggregate destination cluster must have a similar capacity as the total of all associated source clusters.
Install Replicator Connector¶
Important
This connector is bundled natively with Confluent Platform. If you have Confluent Platform installed and running, there are no additional steps required to install.
If you are using Confluent Platform using only Confluent Community components, you can install the connector using the Confluent Hub client (recommended) or you can manually download the ZIP file.
Install the connector using Confluent Hub¶
- Prerequisite
- Confluent Hub Client must be installed. This is installed by default with Confluent Enterprise.
Navigate to your Confluent Platform installation directory and run this command to install the latest (latest) connector version.
The connector must be installed on every machine where Connect will be run.
confluent-hub install confluentinc/kafka-connect-replicator:latest
You can install a specific version by replacing latest with a version number. For example:
confluent-hub install confluentinc/kafka-connect-replicator:5.1.4
Install Connector Manually¶
Download and extract the ZIP file for your connector and then follow the manual connector installation instructions.
License¶
You can use this connector for a 30-day trial period without a license key.
After 30 days, this connector is available under a Confluent enterprise license. Confluent issues enterprise license keys to subscribers, along with providing enterprise-level support for Confluent Platform and your connectors. If you are a subscriber, please contact Confluent Support at support@confluent.io for more information.
See Confluent Platform license for license properties and License topic configuration for information about the license topic.
Quick Start¶
The Confluent Replicator quick start configuration is included in the source repository in
./etc/kafka-connect-replicator/quickstart-replicator.properties.
This quick start uses the replicator as an executable. For more information on how to use the replicator as a connector, see As a Connector.
A sample configuration for a Replicator is shown below:
# basic connector configuration
name=replicator-source
connector.class=io.confluent.connect.replicator.ReplicatorSourceConnector
key.converter=io.confluent.connect.replicator.util.ByteArrayConverter
value.converter=io.confluent.connect.replicator.util.ByteArrayConverter
header.converter=io.confluent.connect.replicator.util.ByteArrayConverter
tasks.max=4
# source cluster connection info
src.kafka.bootstrap.servers=localhost:9082
# destination cluster connection info
dest.kafka.bootstrap.servers=localhost:9092
# configure topics to replicate
topic.whitelist=test-topic
#topic.blacklist=
#topic.regex=
topic.rename.format=${topic}.replica
The main items you need to configure are the source connection endpoints for the Kafka brokers, the list of topics to be replicated, and the topic rename format. A full description of the available configuration items can be found here.
The ZooKeeper connection information is no longer required since Confluent Platform 4.1. If you are running earlier versions prior to Confluent Platform 4.1, please consult the appropriately versioned documentation.
Start the destination cluster¶
Tip
These instructions assume you are installing Confluent Platform by using ZIP or TAR archives. For more information, see On-Premises Deployments.
Start a ZooKeeper server. All services are assumed to be running on
localhost.# Start ZooKeeper. Run this command in its own terminal. ./bin/zookeeper-server-start ./etc/kafka/zookeeper.propertiesStart a Kafka broker that will serve as the single node Kafka cluster.
# Start Kafka. Run this command in its own terminal. ./bin/kafka-server-start ./etc/kafka/server.properties
For complete details on getting these services up and running see the quick start instructions for Confluent Platform.
Start the source cluster¶
The Kafka in the source cluster is configured on port 9082, ZooKeeper is configured on 2171.
Copy the configuration files to a temporary location and modify so that they do not conflict with the destination cluster.
For example, you can run the following commands on Mac:
# Copy the config files to /tmp cp ./etc/kafka/zookeeper.properties /tmp/zookeeper_source.properties cp ./etc/kafka/server.properties /tmp/server_source.properties # Update the port numbers sed -i '' -e "s/2181/2171/g" /tmp/zookeeper_source.properties sed -i '' -e "s/9092/9082/g" /tmp/server_source.properties sed -i '' -e "s/2181/2171/g" /tmp/server_source.properties sed -i '' -e "s/#listen/listen/g" /tmp/server_source.properties # Update data directories sed -i '' -e "s/zookeeper/zookeeper_source/g" /tmp/zookeeper_source.properties sed -i '' -e "s/kafka-logs/kafka-logs-source/g" /tmp/server_source.properties
Start the source cluster.
# Start ZooKeeper. Run this command in its own terminal. ./bin/zookeeper-server-start /tmp/zookeeper_source.properties # Start Kafka. Run this command in its own terminal. ./bin/kafka-server-start /tmp/server_source.properties
Configure and Run Replicator as an Executable¶
The simplest way to run Replicator is as an executable from a script or from a Docker image.
A full list of command line arguments is found with replicator -h.
Create consumer and producer configs with minimum requirements:
replicator_consumer.properties:bootstrap.servers=localhost:9082replicator_producer.properties:bootstrap.servers=localhost:9092Ensure the replication factors are set to
1for local development, if they are not already:echo "confluent.topic.replication.factor=1" >> ./etc/kafka-connect-replicator/quickstart-replicator.properties echo "offset.storage.replication.factor=1" >> ./etc/kafka-connect-replicator/quickstart-replicator.properties echo "config.storage.replication.factor=1" >> ./etc/kafka-connect-replicator/quickstart-replicator.properties echo "status.storage.replication.factor=1" >> ./etc/kafka-connect-replicator/quickstart-replicator.properties
Start the Replicator:
./bin/replicator --cluster.id new-cluster-id \ --producer.config replicator_producer.properties \ --consumer.config replicator_consumer.properties \ --replication.config ./etc/kafka-connect-replicator/quickstart-replicator.properties
This will generate a Connect distributed worker configuration from the inputs and internally run a Connect worker with that configuration.
You can start additional Replicator processes with the same command. Instances with the same cluster.id
will join the cluster, and new cluster.id’s will create new clusters.
If any Replicator configuration properties are different than the currently deployed Replicator instance, the existing Replicator’s configuration is updated.
See Testing section to test your setup.
Configure and Run Replicator as a Connector (Advanced)¶
The Connect worker configuration should match the settings in the destination cluster:
# Connect standalone worker configuration
src.kafka.bootstrap.servers = localhost:9092
The topic.whitelist setting is an explicit list of the topics you
want replicated. In this tutorial, the test-topic is replicated.
The topic.rename.format setting provides the
capability to rename topics in the destination cluster. In the quickstart-replicator.properties,
${topic}.replica is used, where ${topic} will be
substituted with the topic name from the source cluster. That means
that the test-topic we’re replicating from the source cluster will
be renamed to test-topic.replica in the destination cluster.
Create a topic named
test-topicin the source cluster with the following command:./bin/kafka-topics --create --topic test-topic --replication-factor \ 1 --partitions 4 --zookeeper localhost:2171
Update the quick start configuration and then run the connector in a standalone Kafka Connect worker:
./bin/connect-standalone ./etc/schema-registry/connect-avro-standalone.properties \ ./etc/kafka-connect-replicator/quickstart-replicator.properties
When the connector has finished initialization, it will check the source cluster for topics that need to be replicated. In this case, it will find
test-topicand will try to create the corresponding topic in the destination cluster.
Test Your Replicator¶
If you haven’t already, create a topic named
test-topicin the source cluster with the following command:./bin/kafka-topics --create --topic test-topic --replication-factor \ 1 --partitions 4 --zookeeper localhost:2171 ./bin/kafka-topics --describe --topic test-topic.replica --zookeeper localhost:2181
Note that the existence of
test-topic.replicais being checked. After verifying the topic’s existence, you should confirm that four partitions were created. In general, the Replicator will ensure that the destination topic has at least as many partitions as the source topic. It is fine if it has more, but since the Replicator preserves the partition assignment of the source data, any additional partitions will not be utilized.At any time after you’ve created the topic in the source cluster, you can begin sending data to it using a Kafka producer to write to
test-topicin the source cluster. You can then confirm that the data has been replicated by consuming fromtest-topic.replicain the destination cluster. For example, to send a sequence of numbers using Kafka’s console producer, you can use the following command:seq 10000 | ./bin/kafka-console-producer --topic test-topic --broker-list localhost:9082
You can then confirm delivery in the destination cluster using the console consumer:
./bin/kafka-console-consumer --from-beginning --topic test-topic.replica \ --bootstrap-server localhost:9092
Topic Renaming¶
By default, the Replicator is configured to use the same topic name in both the source and destination clusters. This works fine if you are only replicating from a single cluster. When copying data from multiple clusters to a single destination (i.e. the aggregate use case), you should use a separate topic for each source cluster in case there are any configuration differences between the topics in the source clusters.
It is possible to use the same Kafka cluster as the source and destination as long as you ensure that the replicated topic name is different. This is not a recommended pattern since generally you should prefer Kafka’s built-in replication within the same cluster, but it may be useful in some cases (e.g. testing).
Periodic Metadata Updates¶
The replicator periodically checks topics in the source cluster to
tell whether there are any new topics which need to be replicated, and
whether there are any configuration changes (e.g. increases in the
number of partitions). The frequency of this checking is controlled
with the metadata.max.age.ms setting in the connector
configuration. The default is set to 2 minutes, which is intended to
provide reasonable responsiveness to configuration changes while
ensuring that the connector does not add any unnecessary load on the
source cluster. You can lower this setting to detect changes quicker,
but it’s probably not advisable as long as topic
creation/reconfiguration is relatively rare (as is most common).
Security¶
Replicator supports communication with secure Kafka over SSL for both the source and destination clusters. Differing SSL configurations can be used on the source and destination clusters. You can configure replicator connections to source and destination Kafka with:
- SSL. You can use different SSL configurations on the source and destination clusters.
- SASL/SCRAM.
- SASL/GSSAPI.
- SASL/PLAIN.
You can configure ZooKeeper by passing the name of its JAAS file as a JVM parameter when starting:
export KAFKA_OPTS="-Djava.security.auth.login.config=etc/kafka/zookeeper_jaas.conf"
bin/zookeeper-server-start etc/kafka/zookeeper.properties
Important
The source and destination ZooKeeper must be secured with the same credentials.
To configure security on the source cluster, see the connector configurations here. To configure security on the destination cluster, see the general security configuration for Connect workers here.