Important
You are viewing documentation for an older version of Confluent Platform. For the latest, click here.
Installing KSQL¶
KSQL is a component of Confluent Platform and the KSQL binaries are located at https://www.confluent.io/download/ as a part of the Confluent Platform bundle.
KSQL must have access to a running Apache Kafka® cluster, which can be in your data center, in a public cloud, Confluent Cloud, etc.
- Docker support
- You can deploy KSQL by using Docker containers. Starting with Confluent Platform 4.1.2, Confluent maintains images at Docker Hub. To start KSQL containers in configurations like “KSQL Headless Server” and “Interactive Server with Interceptors”, see Docker Configuration Parameters.
Watch the screencast of Installing and Running KSQL on YouTube.
Supported Versions and Interoperability¶
You can use KSQL with compatible Confluent Platform and Apache Kafka® versions.
| KSQL version | 5.1 |
|---|---|
| Apache Kafka version | 0.11.0 and later |
| Confluent Platform version | 3.3.0 and later |
Installation Instructions¶
Follow the instructions at Install Using the Confluent CLI.
It is also possible to install KSQL individually through standalone packages.
Starting the KSQL Server¶
The KSQL servers are run separately from the KSQL CLI client and Kafka brokers. You can deploy servers on remote machines, VMs, or containers and then the CLI connects to these remote servers.
You can add or remove servers from the same resource pool during live operations, to elastically scale query processing. You can use different resource pools to support workload isolation. For example, you could deploy separate pools for production and for testing.
You can only connect to one KSQL server at a time. The KSQL CLI does not support automatic failover to another KSQL server.
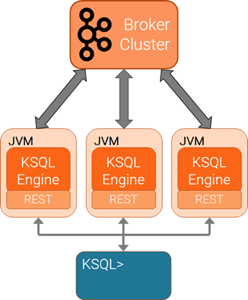
Follow these instructions to start KSQL server using the ksql-server-start script.
Tip
These instructions assume you are installing Confluent Platform by using ZIP or TAR archives. For more information, see On-Premises Deployments.
Specify your KSQL server configuration parameters. You can also set any property for the Kafka Streams API, the Kafka producer, or the Kafka consumer. The required parameters are
bootstrap.serversandlisteners. You can specify the parameters in the KSQL properties file or theKSQL_OPTSenvironment variable. Properties set withKSQL_OPTStake precedence over those specified in the properties file.A recommended approach is to configure a common set of properties using the KSQL configuration file and override specific properties as needed, using the
KSQL_OPTSenvironment variable.Here are the default settings:
bootstrap.servers=localhost:9092 listeners=http://localhost:8088
For more information, see Configuring KSQL Server.
Start a server node with this command:
$ <path-to-confluent>/bin/ksql-server-start <path-to-confluent>/etc/ksql/ksql-server.properties
Tip
You can view the KSQL server help text by running
<path-to-confluent>/bin/ksql-server-start --help.NAME server - KSQL Cluster SYNOPSIS server [ {-h | --help} ] [ --queries-file <queriesFile> ] [--] <config-file> OPTIONS -h, --help Display help information --queries-file <queriesFile> Path to the query file on the local machine. -- This option can be used to separate command-line options from the list of arguments (useful when arguments might be mistaken for command-line options) <config-file> A file specifying configs for the KSQL Server, KSQL, and its underlying Kafka Streams instance(s). Refer to KSQL documentation for a list of available configs. This option may occur a maximum of 1 times
Have a look at this page for instructions on running KSQL in non-interactive (aka headless) mode.
Starting the KSQL CLI¶
The KSQL CLI is a client that connects to the KSQL servers.
You can start the KSQL CLI by providing the connection information to the KSQL server.
$ LOG_DIR=./ksql_logs <path-to-confluent>/bin/ksql http://localhost:8088
Important
By default KSQL attempts to store its logs in a directory called logs that is relative to the location
of the ksql executable. For example, if ksql is installed at /usr/local/bin/ksql, then it would
attempt to store its logs in /usr/local/logs. If you are running ksql from the default Confluent Platform
location, <path-to-confluent>/bin, you must override this default behavior by using the LOG_DIR variable.
After KSQL is started, your terminal should resemble this.
===========================================
= _ __ _____ ____ _ =
= | |/ // ____|/ __ \| | =
= | ' /| (___ | | | | | =
= | < \___ \| | | | | =
= | . \ ____) | |__| | |____ =
= |_|\_\_____/ \___\_\______| =
= =
= Streaming SQL Engine for Apache Kafka® =
===========================================
Copyright 2018 Confluent Inc.
CLI v5.1.4, Server v5.1.4 located at http://localhost:8088
Having trouble? Type 'help' (case-insensitive) for a rundown of how things work!
ksql>
Tip
You can view the KSQL CLI help text by running <path-to-confluent>/bin/ksql --help.
NAME
ksql - KSQL CLI
SYNOPSIS
ksql [ --config-file <configFile> ] [ {-h | --help} ]
[ --output <outputFormat> ]
[ --query-row-limit <streamedQueryRowLimit> ]
[ --query-timeout <streamedQueryTimeoutMs> ] [--] <server>
OPTIONS
--config-file <configFile>
A file specifying configs for Ksql and its underlying Kafka Streams
instance(s). Refer to KSQL documentation for a list of available
configs.
-h, --help
Display help information
--output <outputFormat>
The output format to use (either 'JSON' or 'TABULAR'; can be changed
during REPL as well; defaults to TABULAR)
--query-row-limit <streamedQueryRowLimit>
An optional maximum number of rows to read from streamed queries
This options value must fall in the following range: value >= 1
--query-timeout <streamedQueryTimeoutMs>
An optional time limit (in milliseconds) for streamed queries
This options value must fall in the following range: value >= 1
--
This option can be used to separate command-line options from the
list of arguments (useful when arguments might be mistaken for
command-line options)
<server>
The address of the Ksql server to connect to (ex:
http://confluent.io:9098)
This option may occur a maximum of 1 times
Configuring KSQL for Confluent Cloud¶
You can use KSQL with a Kafka cluster in Confluent Cloud. For more information, see Connecting ksqlDB to Confluent Cloud.