Important
You are viewing documentation for an older version of Confluent Platform. For the latest, click here.
Trigger management¶
Clicking the Alerts Triggers tab shows a summary of all configured triggers:
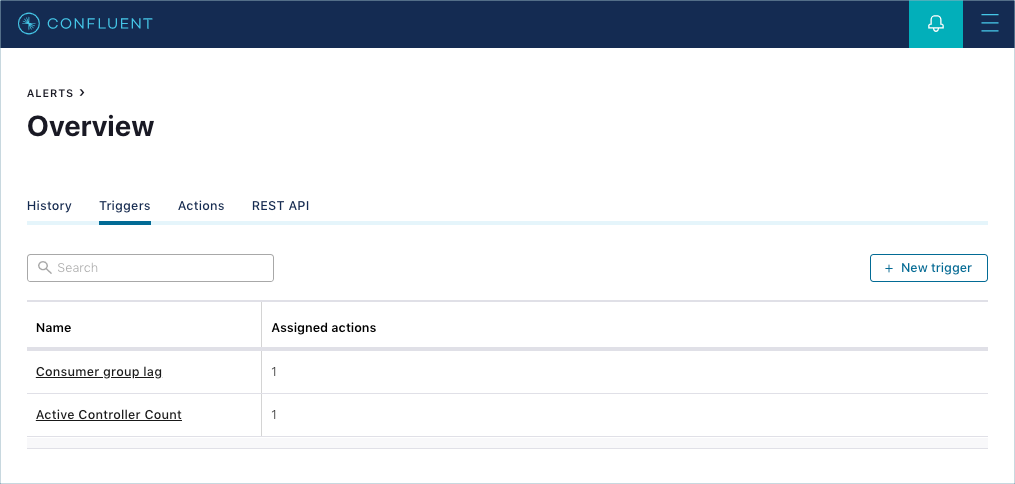
Initially, the Triggers page is blank when there aren’t any triggers defined yet.
Use the Triggers page to:
- Create a trigger using the + New trigger button.
- View and sort a summary of triggers and their assigned actions.
- Search for a trigger.
- Edit or delete an existing trigger.
New/Edit Trigger Form¶
Use the New Trigger form to define the criteria that will activate associated alert actions. Some of the fields are already pre-populated when you clicked Set up an alert from a context menu.
The following component types of triggers can be created:
Broker Triggers¶
Use this broker trigger field reference for guidance when adding a broker trigger.
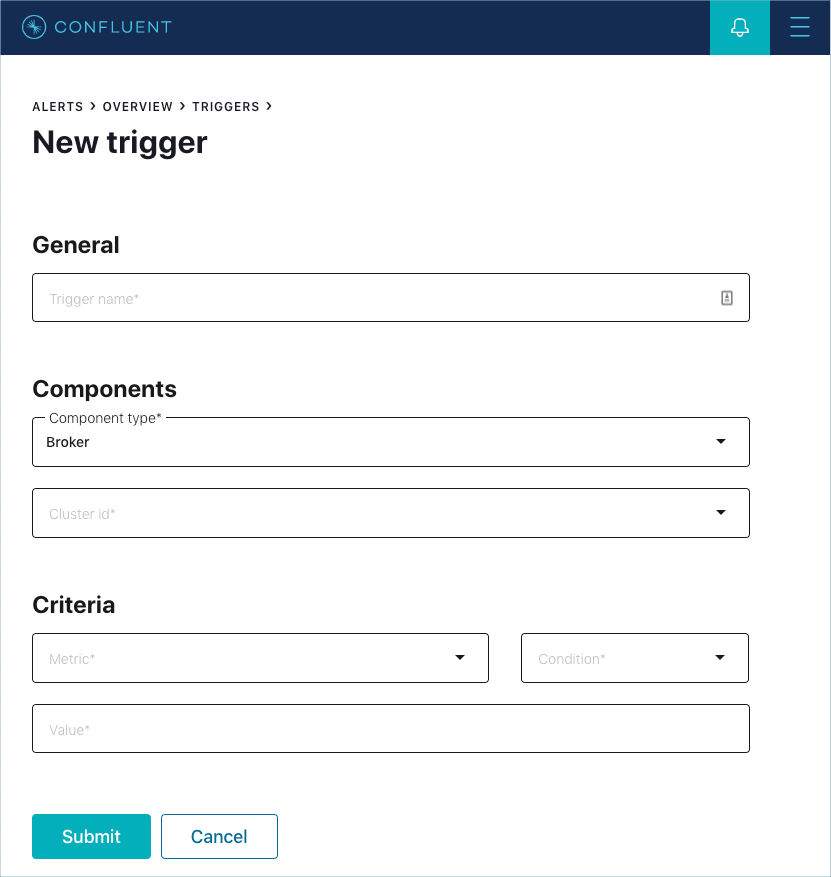
Broker trigger form
- Trigger name
A unique name used to identify the trigger (for example: Broker fetch request latency).
Note
Uniqueness is not enforced. As a recommended best practice, use unique and descriptive names to avoid confusion.
- Component type
- Select the Broker component type.
- Cluster id
Select a cluster to trigger based on conditions of individual brokers.
Warning
There is a known issue when multiple clusters are selected for a broker or cluster trigger. As a recommended best practice, only select a single cluster for the trigger. For more information, see the known issues section in the release notes.
- Metric
Values in Metric are triggered on a per-broker basis.
Important
Any broker that meets the defined Condition will trigger individually.
- Bytes in
- Number of bytes per second produced a broker.
- Bytes out
- Number of bytes per second fetched from a broker (does not account for internal replication traffic).
Note
Prior to Kafka 0.11.0.0, the
BytesOutPerSecaccounted for traffic from the consumer and internal replication. This has been changed to only account for consumer traffic for this broker. Adjust alerts accordingly.- Fetch request latency
- Latency of fetch requests to this broker at the median, 95th, 99th, or 99.9th percentile (in milliseconds).
- Production request count
- Total number of produce requests to a broker (requests per minute).
- Production request latency
- Latency of produce requests to this broker at the median, 95th, 99th, or 99.9th percentile (in milliseconds).
- Condition
- The trigger will fire when the Condition is true of the comparison between the value of the metric being monitored and the value of the Value field. Possible options are Greater than, Less than, Equal to, Not equal to, Online, or Offline, depending on the selected Metric.
- Value
- The value to which the broker Metric is compared.
Cluster Triggers¶
Use this cluster trigger field reference for guidance when adding a cluster trigger.
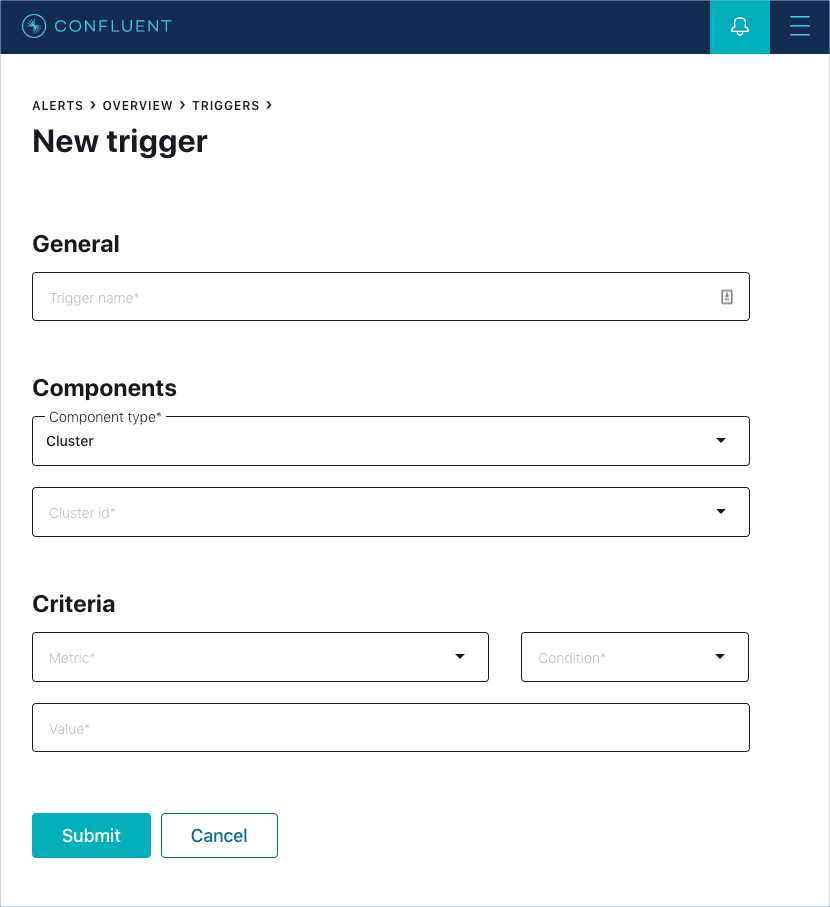
Cluster trigger form
- Trigger name
A unique name that identifies the trigger (for example:
Control Center Cluster down).Note
Uniqueness is not enforced. As a recommended best practice, use unique and descriptive names to avoid confusion.
- Component type
- Select the Cluster component type.
- Cluster id
Select a cluster to trigger based on a defined condition.
Warning
There is a known issue when multiple clusters are selected for a broker or cluster trigger. As a recommended best practice, only select a single cluster for the trigger. For more information, see the known issues section in the release notes.
- Metric
Values in Metric are triggered on a cluster-wide basis. A cluster that meets the defined Condition triggers an associated action.
- Cluster down
- A trigger should be created for Condition
Yes. See Control Center cluster down status. - Leader election rate
- Number of partition leader elections.
- Offline topic partitions
Total number of topic partitions in the cluster that are offline. This can happen if the brokers with replicas are down, or if unclean leader election is disabled and the replicas are not in sync and thus none can be elected leader (may be desirable to ensure no messages are lost).
A trigger should be created for values
> 0(Greater than zero).- Unclean election count
The number of unclean partition leader elections in the cluster reported in the last interval.
When unclean leader election is held among out-of-sync replicas, there is a possibility of data loss if any messages were not synced prior to the loss of the former leader. So if the number of unclean elections is greater than 0, investigate broker logs to determine why leaders were re-elected, and look for WARN or ERROR messages. Consider setting the broker configuration parameter
unclean.leader.election.enabletofalseso that a replica outside of the set of in-sync replicas is never elected leader.A trigger should be created for values
!= 0(Not equal to zero).- Under replicated topic partitions
Total number of topic partitions in the cluster that are under-replicated; i.e., partition with number of in-sync replicas less than replication factor.
A trigger should be created for values
> 0(Greater than zero).- ZooKeeper status
- Are brokers able to connect to ZooKeeper? ‘Offline’ / ‘Online’ are possible values.
- ZooKeeper expiration rate
- Rate at which brokers are experiencing ZooKeeper session expirations (number of expirations per second).
- Condition
- The trigger will fire when the Condition is true of the comparison between the value of the metric being monitored and the value of the Value field. Possible options are Greater than, Less than, Equal to, Not equal to, Online, or Offline, depending on the selected Metric.
- Value
- The value to which the cluster Metric is compared.
Consumer Group Triggers¶
Use this consumer group trigger field reference for guidance when adding a consumer group trigger.
Note
Consumer group alerts in Confluent Control Center are based on the total cumulative lag for all partitions in all topics consumed in a Consumer group.
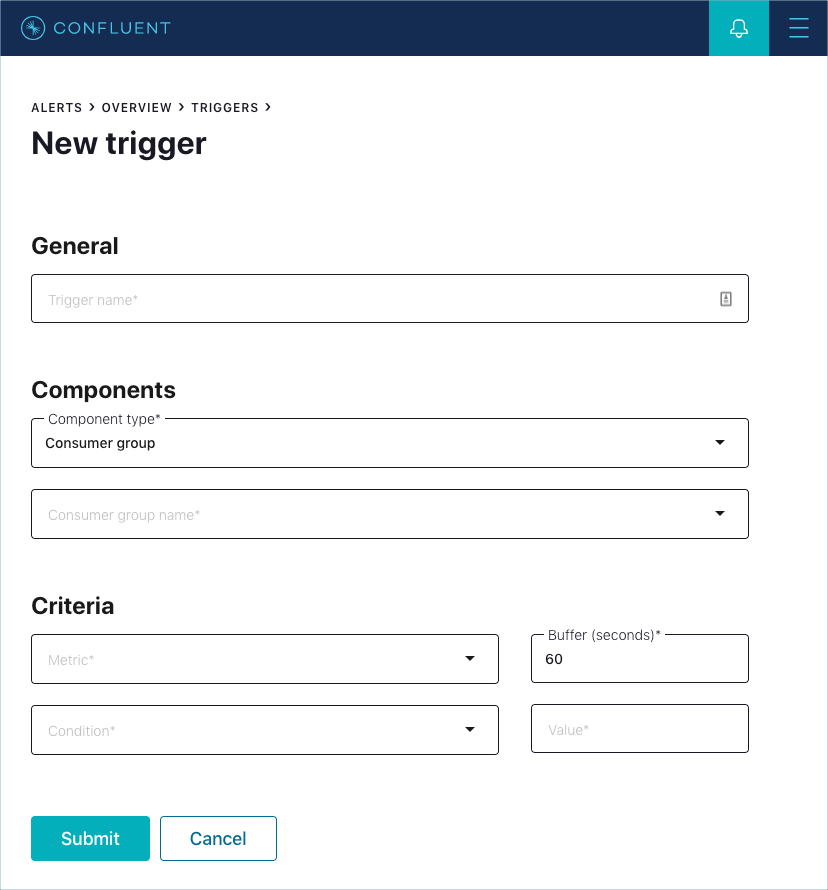
Consumer group trigger form
- Trigger name
A unique name used to identify the trigger (for example: consumer group name under consumption).
Note
Uniqueness is not enforced. As a recommended best practice, use unique and descriptive names to avoid confusion.
- Component type
- Should be pre-selected as Consumer group (default type) if the Set up an alert button was clicked from the Consumer lag page. Otherwise, select Consumer group.
- Consumer group name
- The name of the consumer group to monitor for anomalies.
- Metric
The metric to monitor:
- Average latency (ms)
- Average latency of the consumer group in milliseconds.
- Consumer lag
- How far behind consumer applications are while consuming from their producer applications. The consumer lag is the difference between the end offset and the current offset. Tracks the opposite of Consumer lead.
- Consumer lead
- How far ahead consumer applications are while consuming from producer applications. The consumer lead is the difference between the current offset and the beginning offset. For example, a consumer at offset 15 in a partition that starts at offset 0 would have a lead of 15. This alert metric indicates when consumption is close to the earliest available messages, which means there is potential for data loss. Tracks the opposite of Consumer lag.
- Consumption difference
- The difference between the expected consumption value and the actual consumption value within a given time bin. Typically, there is a gap between expected and actual consumption that is very close to real time. This gap should diminish over time.
- Maximum latency (ms)
- Maximum latency of the consumer group in milliseconds.
- Buffer (Deprecated)
- The delay behind real time to wait until a time window is considered for triggering. Refer to Buffer for consumer group triggers (deprecated) for more information.
- Condition
- The trigger will fire when the Condition is true of the comparison between the value of the metric being monitored and the value of the Value field. Available options are Greater than, Less than, Equal to, or Not equal to.
- Value
- The value to which the monitored consumer group Metric is compared.
Topic Triggers¶
Use this topic trigger field reference for guidance when adding a topic trigger.
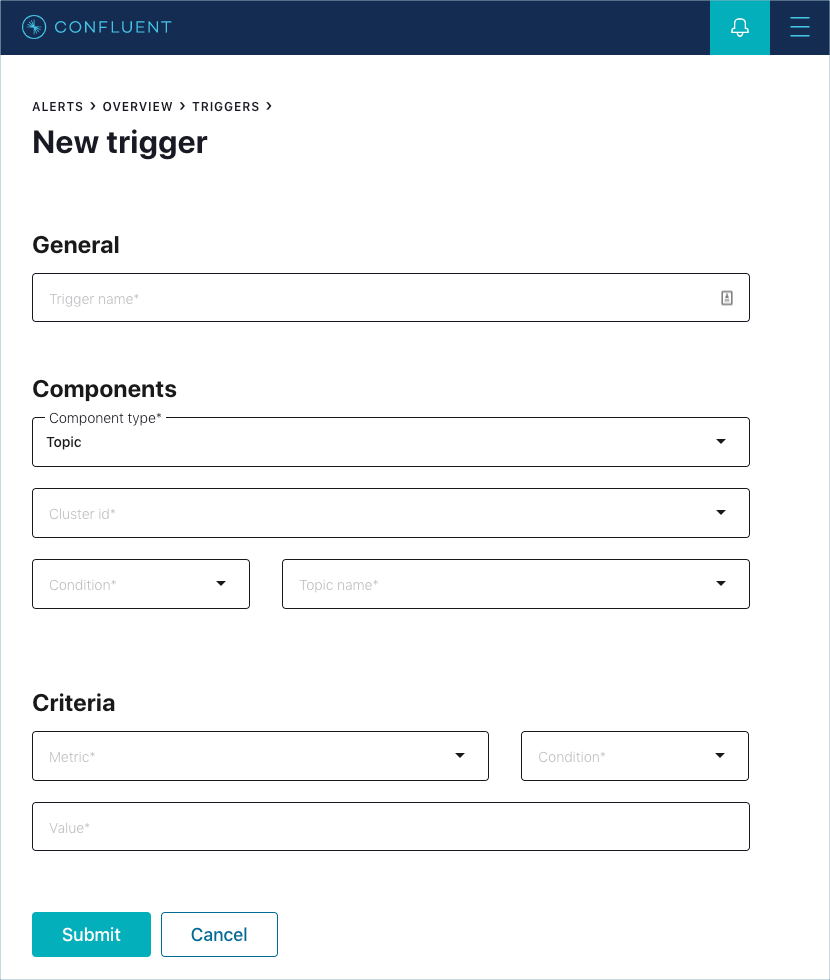
Topic trigger form
- Trigger name
A unique name used to identify the trigger (for example: topic name production requests).
Note
Uniqueness is not enforced. As a recommended best practice, use unique and descriptive names to avoid confusion.
- Component type
- Should be pre-selected as Topic if you clicked Set up an alert from the legacy System Health > Topics tab or within another page context menu. Otherwise, Topic should be selected.
- Cluster id
- The trigger for a topic is limited to a specific cluster ID. If you require a topic to be triggered by multiple clusters, create independent triggers for each cluster.
- Condition
A select list of options for matching against the value field (below). The name of the topic can Equals, Begins with, Ends with, or Contains a specified value.
Note
For example, selecting Contains and then entering ‘topic’ into the value field will match ‘my topic’, ‘topical’, and ‘topics with data’. If Begins with is selected, the trigger will only match ‘topical’ and ‘topics with data’, not ‘my topic’.
- Topic name
The name or part of a topic name to be triggered against. Works in conjunction with Condition to match against one or more topics.
Note
If multiple topics match against topic name, the trigger will be per topic, not an aggregate. In the case where there are two topics that Begin with ‘mytopic’; and the trigger is set to
Bytes infor Metric,Greater thanfor Condition, and100for Value, any ‘mytopic’ matches will fire the trigger if they get > 100 Bytes In.Warning
A message appears when there are greater than five topics that match the criteria. Narrow the criteria if you see this message.
- Metric
The value to check for the trigger alert. Possible values are:
- Bytes in
- Amount of bytes per second coming in to a topic.
- Bytes out
- Amount of bytes per second going out from a topic (does not account for internal replication traffic).
Note
Prior to Apache Kafka® 0.11.0.0, the
BytesOutPerSecaccounted for traffic from the consumer and internal replication. This has been changed to only account for consumer traffic for this topic. Adjust alerts accordingly.- Out of sync replica count
- Total number of topic partition replicas in a cluster that are in sync with the leader; i.e., sum of each (topic partition * topic replication factor).
- Production request count
- Amount of production requests per second to a topic in a cluster.
- Under-replicated topic partitions
- Amount of under-replicated topic partitions. A use case for this metric would be wanting to know if a Kafka broker crashed while holding a specific topic partition.
- Condition
- The trigger will fire when a Condition is true for the comparison between the value of the metric being monitored and the value of the Value field. Available options are Greater than, Less than, Equal to, or Not equal to.
- Value
- The value to which the topic Metric is compared.
Tip
See Example triggers for step-by-step trigger examples.
Edit an alert trigger¶
- Click the Alerts bell icon in the top banner. The Alerts page opens to the History tab by default.
- Click the Triggers tab.
- Click the name of the trigger.
- Click Edit trigger.
- Make the changes you want to the trigger fields.
- Click Submit.
Delete an alert trigger¶
- Click the Alerts bell icon in the top banner. The Alerts page opens to the History tab by default.
- Click the Triggers tab.
- Click the name of the trigger.
- Click Delete trigger.
- Confirm deleting the trigger.