Important
You are viewing documentation for an older version of Confluent Platform. For the latest, click here.
Schema Registry Single and Multi-Datacenter Deployments¶
Single Datacenter Setup¶
Within a single datacenter or location, a multi-node, multi-broker cluster provides Kafka data replication across the nodes.
Producers write and consumers read data to/from topic partition leaders. Leaders replicate data to followers so that messages are copied to more than one broker.
You can configure parameters on producers and consumers to optimize your single cluster deployment for various goals, including message durability and high availability.
Kafka producers can set the acks configuration
parameter to control when a write is considered successful.
For example, setting producers to acks=all requires other brokers in the
cluster acknowledge receiving the data before the leader broker responds to the
producer.
If a leader broker fails, the Kafka cluster recovers when a follower broker is elected leader and client applications can continue to write and read messages through the new leader.
Kafka Election¶
Recommended Deployment¶
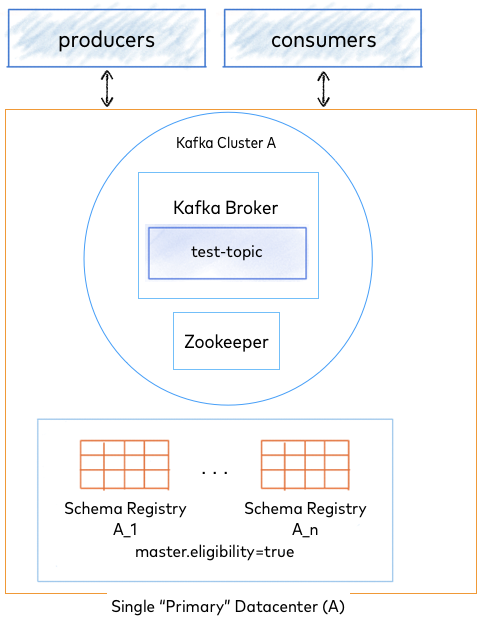
Single datacenter with Kafka intra-cluster replication
The image above shows a single data center - DC A. For this example, Kafka is used for primary election, which is recommended.
Note
You can also set up a single cluster with ZooKeeper, but this configuration is deprecated in favor of Kafka leader election.
Important Settings¶
kafkastore.bootstrap.servers
This should point to the primary Kafka cluster (DC A in this example).
schema.registry.group.id
schema.registry.group.id is used as the consumer group.id. For single datacenter setup, make this setting the same for all nodes in the cluster. When set, schema.registry.group.id overrides group.id for the Kafka group when Kafka is used for primary election. (Without this configuration, group.id will be “schema-registry”.)
master.eligibility
In a single datacenter setup, all Schema Registry instances will be local to the Kafka cluster and should have master.eligibility set to true.
Run Book¶
Let’s say you have Schema Registry running in a single datacenter , and the master node goes down; what do you do? First, note that the remaining Schema Registry instances can continue to serve requests.
- If one Schema Registry node goes down, another node is elected primary and the cluster auto-recovers.
- Restart the node, and it will come back as a follower (since a new primary was elected in the meantime).
Multi-Datacenter Setup¶
Spanning multiple datacenters (DCs) with your Confluent Schema Registry synchronizes data across sites, further protects against data loss, and reduces latency. The recommended multi-datacenter deployment designates one datacenter as “primary” and all others as “secondary”. If the “primary” datacenter fails and is unrecoverable, you must manually designate what was previously a “secondary” datacenter as the new “primary” per the steps in the Run Books below.
Kafka Election¶
Recommended Deployment¶
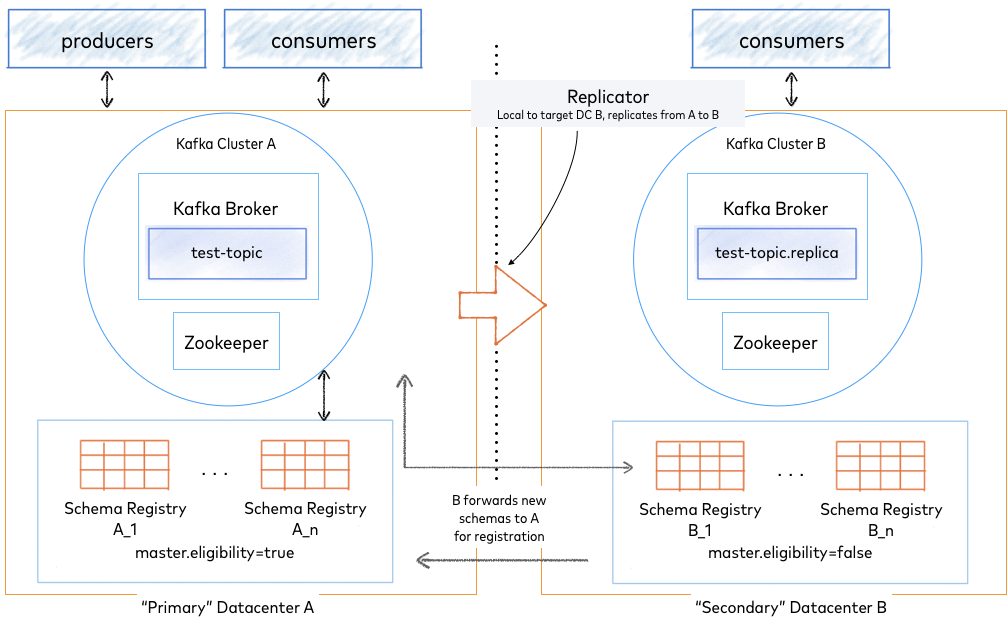
Multi datacenter with Kafka based primary election
The image above shows two datacenters - DC A, and DC B. Either could be on-premises, in Confluent Cloud, or part of a bridge to cloud solution. Each of the two datacenters has its own Apache Kafka® cluster, ZooKeeper cluster, and Schema Registry.
The Schema Registry nodes in both datacenters link to the primary Kafka cluster in DC A, and the secondary datacenter (DC B) forwards Schema Registry writes to the primary (DC A). Note that Schema Registry nodes and hostnames must be addressable and routable across the two sites to support this configuration.
Schema Registry instances in DC B have master.eligibility set to false, meaning that
none can be elected primary during steady state operation with both datacenters
online.
To protect against complete loss of DC A, Kafka cluster A (the source) is replicated to Kafka cluster B (the target). This is achieved by running the Replicator local to the target cluster (DC B).
In this active-passive setup, Replicator runs in one direction, copying Kafka data
and configurations from the active DC A to the passive DC B. Since the Schema Registry
instances in both data centers point to the internal _schemas topic in DC A,
there is no need to replicate the internal schemas topic itself.
Producers write data to just the active cluster. Depending on the overall design, consumers can read data from the active cluster only, leaving the passive cluster for disaster recovery, or from both clusters to optimize reads on a geo-local cache.
In the event of a partial or complete disaster in one datacenter, applications can failover to the secondary datacenter.
Important Settings¶
kafkastore.bootstrap.servers
This should point to the primary Kafka cluster (DC A in this example).
schema.registry.group.id
Use this setting to override the group.id for the Kafka group used when Kafka is used for primary election. Without this configuration, group.id will be “schema-registry”. If you want to run more than one Schema Registry cluster against a single Kafka cluster you, should make this setting unique for each cluster.
master.eligibility
A Schema Registry server with master.eligibility set to false is guaranteed to remain a secondary during any primary election. Schema Registry instances in a “secondary” datacenter should have this set to false, and Schema Registry instances local to the shared Kafka (primary) cluster should have this set to true.
Hostnames must be reachable and resolve across datacenters to support forwarding of new schemas from DC B to DC A.
Setup¶
Assuming you have Schema Registry running, here are the recommended steps to add Schema Registry instances in a new “secondary” datacenter (call it DC B):
- In DC B, make sure Kafka has
unclean.leader.election.enableset to false. - In DC B, run Replicator with Kafka in the “primary” datacenter (DC A) as the source and Kafka in DC B as the target.
- In Schema Registry config files in DC B, set the
kafkastore.bootstrap.serversto point to Kafka cluster in DC A and setmaster.eligibilityto false. - Start your new Schema Registry instances with these configs.
Run Book¶
Let’s say you have Schema Registry running in multiple datacenters, and you lose your “primary” datacenter; what do you do? First, note that the remaining Schema Registry instances running on the “secondary” can continue to serve any request that does not result in a write to Kafka. This includes GET requests on existing IDs and POST requests on schemas already in the registry. They will be unable to register new schemas.
- If possible, revive the “primary” datacenter by starting Kafka and Schema Registry as before.
- If you must designate a new datacenter (call it DC B) as “primary”, reconfigure the
kafkastore.bootstrap.serversin DC B to point to its local Kafka cluster and update Schema Registry config files to setmaster.eligibilityto true. - Restart your Schema Registry instances with these new configs in a rolling fashion.
ZooKeeper Election¶
Alternative Deployment¶
Important
ZooKeeper leader election is deprecated. Kafka leader election is recommended for multi-cluster deployments.
As an alternative to Kafka leader election, you can use ZooKeeper leader election. This would entail having two datacenters - DC A, and DC B. Each of the two data centers has its own ZooKeeper cluster, Kafka cluster, and Schema Registry cluster. Both Schema Registry clusters link to Kafka and ZooKeeper in DC A, and the secondary datacenter (DC B) forwards Schema Registry writes to the primary (DC A). The Schema Registry nodes and hostnames must be addressable and routable across the two sites to support this configuration.
The Schema Registry instances in DC B have master.eligibility set to false, meaning that none can ever be elected primary.
In this active-passive setup, Replicator runs in one direction, copying Kafka data and configurations from the active DC A to the passive DC B.
To protect against complete loss of DC A, Kafka cluster A (the source) is replicated to Kafka cluster B (the target). This is achieved by running the Replicator local to the target cluster.
In the event of a partial or complete disaster in one datacenter, applications can failover to the secondary datacenter.
Important Settings¶
kafkastore.connection.url
kafkastore.connection.url should be identical across all Schema Registry nodes. By sharing this setting, all Schema Registry instances will point to the same ZooKeeper cluster.
schema.registry.zk.namespace
Namespace under which Schema Registry related metadata is stored in ZooKeeper. This setting should be identical across all nodes in the same Schema Registry.
master.eligibility
A Schema Registry server with master.eligibility set to false is guaranteed to remain a secondary during any primary election. Schema Registry instances in a “secondary” datacenter should have this set to false, and Schema Registry instances local to the shared Kafka cluster should have this set to true.
Hostnames must be reachable and resolve across datacenters to support forwarding of new schemas from DC B to DC A.
Setup¶
Assuming you have Schema Registry running, here are the recommended steps to add Schema Registry instances in a new “secondary” datacenter (call it DC B):
- In DC B, make sure Kafka has
unclean.leader.election.enableset to false. - In DC B, run Replicator with Kafka in the “primary” datacenter (DC A) as the source and Kafka in DC B as the target.
- In Schema Registry config files in DC B, set
kafkastore.connection.urlandschema.registry.zk.namespaceto match the instances already running, and setmaster.eligibilityto false. - Start your new Schema Registry instances with these configs.
Run Book¶
Let’s say you have Schema Registry running in multiple datacenters, and you have lost your “primary” datacenter; what do you do? First, note that the remaining Schema Registry instances will continue to be able to serve any request which does not result in a write to Kafka. This includes GET requests on existing IDs and POST requests on schemas already in the registry.
- If possible, revive the “primary” datacenter by starting Kafka and Schema Registry as before.
- If you must designate a new datacenter (call it DC B) as “primary”, update Schema Registry config files so that
kafkastore.connection.urlpoints to the local ZooKeeper, and changemaster.eligibilityto true. Then restart your Schema Registry instances with these new configs in a rolling fashion.
Suggested Reading¶
- For information about multi-cluster and multi-datacenter deployments in general, see Multi-DC Deployment Architectures.
- For a broader explanation of disaster recovery design configurations and use cases, see the whitepaper on Disaster Recovery for Multi-Datacenter Apache Kafka Deployments.
- For an overview of schema management in Confluent Platform, including details of single primary architecture, see Schema Management and High Availability for Single Primary Setup.
- Schema Registry is also available in Confluent Cloud; for details on how to lift and shift or extend existing clusters to cloud, see Migrate Schemas.