
Multi-Region Deployment of Confluent Platform in Confluent for Kubernetes
Confluent for Kubernetes (CFK) supports configuring, deploying, and operating Confluent Platform in multi-region clusters (MRCs). In the MRC deployment scenario, Kafka, ZooKeeper, and Schema Registry are deployed in multiple regions to form a logical cluster stretched across Kubernetes regions.
For information about Confluent Platform in multi-region clusters, see Multi-Region Clusters.
To form a multi-region cluster, Confluent must be deployed across three or more Kubernetes clusters.
CFK supports various multi-region cluster deployment scenarios for Confluent Platform. The following are example deployment scenarios.
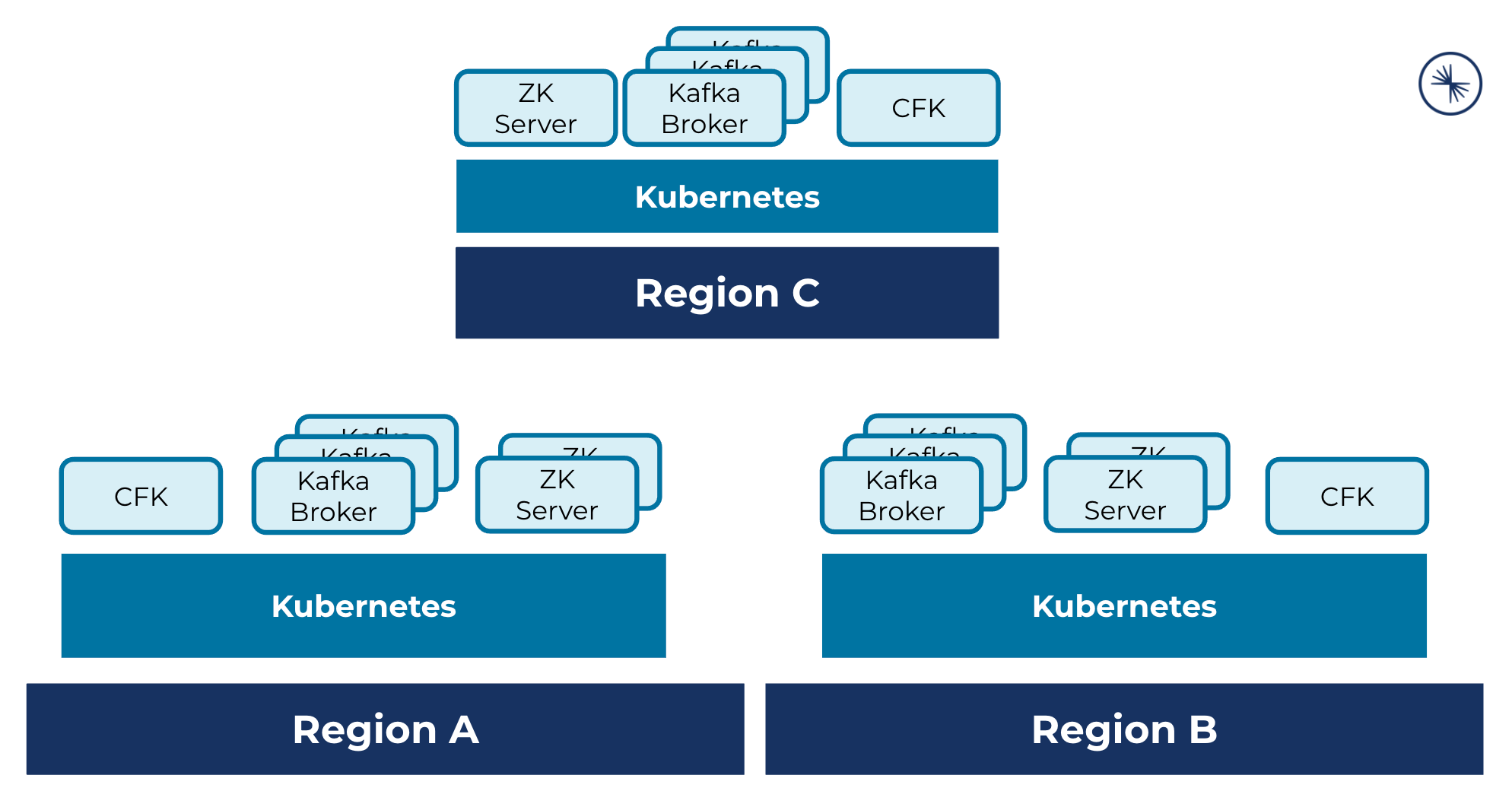
A multi-region cluster deployment across three Kubernetes regions, where each cluster hosts CFK, Kafka brokers, and ZooKeeper servers:
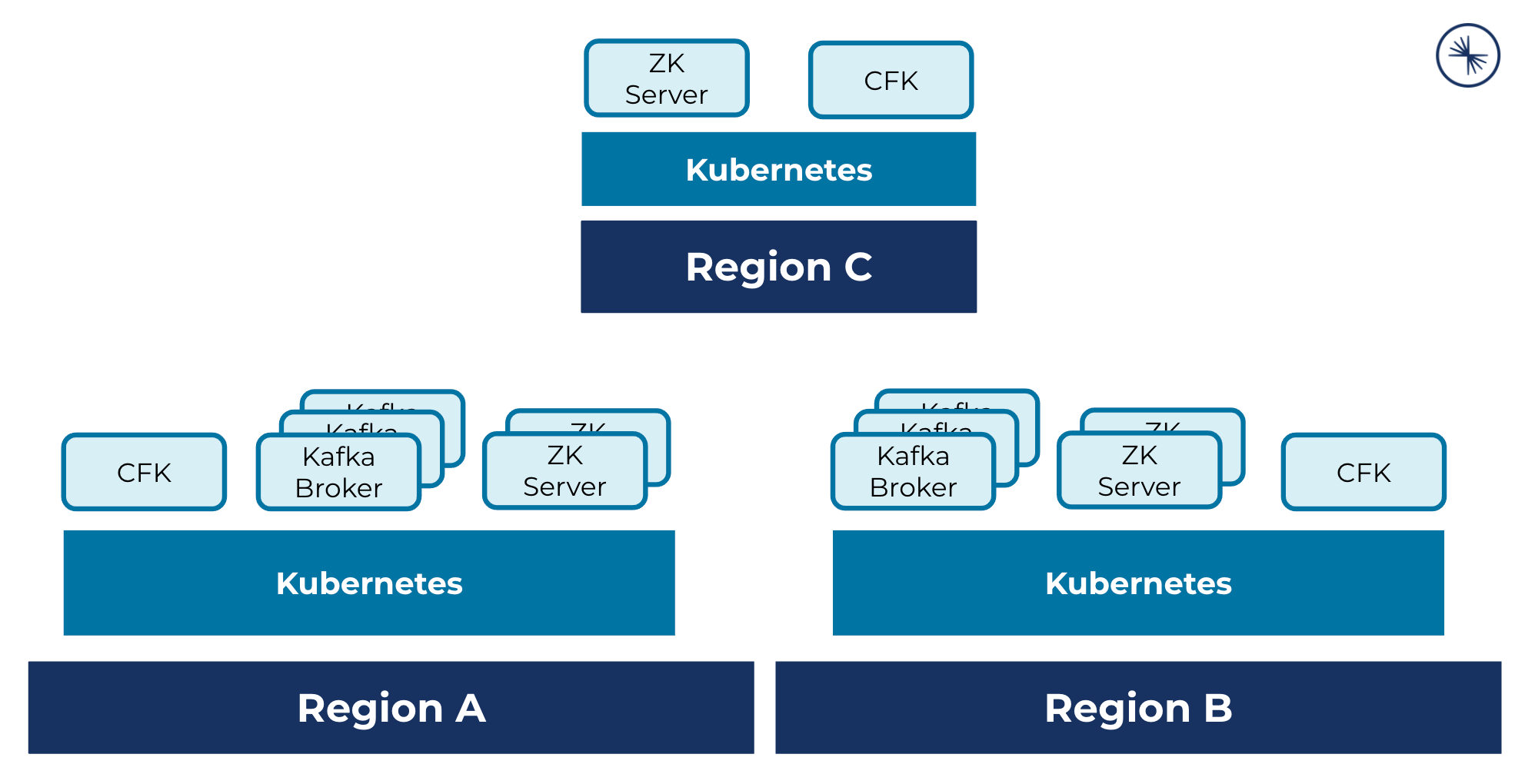
A multi-region cluster deployment across three Kubernetes regions, where each cluster hosts CFK, ZooKeeper servers, and two clusters host Kafka brokers:
You can set up an MRC with the following communication methods among ZooKeeper, Kafka, and Schema Registry deployed across regions:
Use internal listeners among ZooKeeper, Kafka, and Schema Registry across regions.
You set up a DNS resolution that allows each region in the MRC configuration to be able to resolve internal pods in other regions. Internal listeners are used among the MRC components (ZooKeeper, Kafka, and Schema Registry).
Use external access among ZooKeeper, Kafka, and Schema Registry across regions.
Without the required networking configuration, CFK redirects internal communication among the MRC components (ZooKeeper, Kafka, and Schema Registry) to use endpoints that can be accessed externally by each region.
For MRC, if there are other components that depend on Kafka, you need to configure an external listener for Kafka. If you want to reduce the number of load balancers, you can use an alternative way for external access, such as Ingress.
The supported security features work in multi-region cluster deployments. For specific configurations, see Configure Security for Confluent Platform with Confluent for Kubernetes.
Setup requirements for Kubernetes clusters
- Namespace naming
Have one uniquely named namespace in each Kubernetes region cluster.
- Flat pod networking among Kubernetes region clusters (when using internal listeners)
Pod Classless Inter-Domain Routings (CIDRs) across the Kubernetes clusters must not overlap.
- DNS resolution among Kubernetes region clusters (when using internal listeners)
Kubernetes clusters must be able to resolve other’s internal DNS and route to other’s internal pods.
You can use kube-dns or CoreDNS to expose region clusters’ DNS.
- Firewall rules (when using internal listeners)
Allow TCP traffic on the standard ZooKeeper, Kafka, and Schema Registry ports among all regions
clusters’ pod subnetworks.
For specific configuration and validation steps on various platforms, specifically, GKE, EKS, and AKS, see Multi-region Cluster Networking in the CFK example repo.
- Kubernetes region node label
Kubernetes nodes in each region have labels defined as
topology.kubernetes.io/region=<region>.For example, when using three Kubernetes clusters,
us-central-1,us-east-1, andus-west-1, the nodes in the regions will have labelstopology.kubernetes.io/region=us-central-1,topology.kubernetes.io/region=us-east-1, andtopology.kubernetes.io/region=us-west-1, respectively.When CFK in each region schedules a broker pod, it will look up the region by reading the
topology.kubernetes.io/regionlabel of the Kubernetes node in the cluster, and deploy the broker to these nodes that have the matchingbroker.rack=<region>. You should not override thebroker.rackproperty. For more information about the property, see broker.rack property.- Kubernetes context
When working with multiple Kubernetes clusters, the
kubectlcommands run against a cluster in a specific context that specifies a Kubernetes cluster, a user, and a namespace.Append
--context <cluster-context>to thekubectlcommands to ensure they are run against the correct cluster.
For sample use case scenarios, see Confluent for Kubernetes examples GitHub repo.
Configure Confluent Platform in a multi-region cluster
Using distinct Kafka broker IDs, ZooKeeper IDs, and Schema Registry IDs, CFK creates and manages a logical multi-region cluster of each component.
Deploy CFK to each region.
For Kafka to communicate with ZooKeeper using an external endpoint within the MRC region, enable the Zookeeper MRC external listener. ZooKeeper MRC external listeners support load balancers and node ports.
For Kafka brokers to communicate with other Kafka brokers using an external endpoint within the MRC region, enable the Kafka MRC external listener. Kafka MRC external listeners support load balancers, node ports, routes, port-based and hosted-based static accesses.
Note that the MDS listener does not currently support routes for external access.
Configure MRC Schema Registry, or configure active-passive MRC Schema Registery.
For Kafka to communicate with the active-passive Schema Registry clusters using an external endpoint within the MRC region, enable the Schema Registry MRC external listener. Schema Registry MRC external listeners support load balancers.
Configure the remaining Confluent Platform components, including Control Center (Legacy), Connect, and ksqlDB, to be deployed in one Kubernetes region cluster and to utilize the stretched Kafka.
In the component CRs, specify a comma-separated list of Kafka endpoints.
For example, for Confluent Platform components to use internal listeners to access Kafka:
kind: <Confluent component> spec: dependencies: kafka: bootstrapEndpoint: kafka.central.svc.cluster.local:9071,kafka.east.svc.cluster.local:9071,kafka.west.svc.cluster.local:9071
For example, for Confluent Platform components to use external URLs to access Kafka:
kind: <Confluent component> spec: dependencies: kafka: bootstrapEndpoint: kafka.central.svc.cluster.local:9071,kafka-east.platformops.dev.gcp.devel.cpdev.cloud:9092,kafka-west.platformops.dev.gcp.devel.cpdev.cloud:9092
Apply the CRs with the
kubectl apply -f <component CRs>in each region.
Configure ZooKeeper in MRC
To form a logical cluster of ZooKeeper across Kubernetes region clusters:
Set the ZooKeeper server id offset to a different number in each Kubernetes region cluster using
annotationsin the ZooKeeper CR.For example:
kind: Zookeeper metadata: annotations: platform.confluent.io/zookeeper-myid-offset: "100"
The default is
"0".The offsets should be sufficiently spread out among regions, like
100,200,300, etc., to accommodate future cluster growth in each region.Because this offset cannot be changed once set, carefully consider how wide you want these offsets to be before you deploy the clusters.
Specify the peer ZooKeeper servers in the
spec.peersproperty of the ZooKeeper CR.For example:
kind: Zookeeper spec: peers: - server.100=zookeeper-0.zookeeper.central.svc.cluster.local:2888:3888 - server.200=zookeeper-0.zookeeper.east.svc.cluster.local:2888:3888 - server.300=zookeeper-0.zookeeper.west.svc.cluster.local:2888:3888
Configure ZooKeeper in MRC with external access URLs
You can use a load balancer or node ports for ZooKeeper external access.
To configure ZooKeeper to use the external access URL to communicate with the other ZooKeeper and Kafka in MRC:
In each ZooKeeper CR, specify the peer ZooKeeper URLs (
spec.peers), using external access URLs to other regions but a local URL to its own region. ZooKeeper instances communicate with one another through ports 2888 (peer) and 3888 (leader election).For example:
kind: Zookeeper spec: peers: - server.0=zookeeper-0.zookeeper.central.svc.cluster.local:2888:3888 - server.10=zk-east0.platformops.dev.gcp.devel.cpdev.cloud:2888:3888 - server.11=zk-east1.platformops.dev.gcp.devel.cpdev.cloud:2888:3888
Configure the external MRC listener:
kind: Zookeeper spec: externalAccess: type: --- [1] loadBalancer: --- [2] prefix: --- [3] domain: --- [4] nodePort: --- [5] host: --- [6] nodePortOffset: --- [7]
[1] Required. The valid values are
loadBalancerandnodePort.[2] Configure the external access through load balancers.
[3] ZooKeeper prefix.
[4] Required. Set it to the domain where your Kubernetes cluster is running.
[5] Configure the external access through node ports.
[6] The host name.
[7] The starting port number.
Configure ZooKeeper with multiple hostname resolutions
In an MRC deployment, where the ZooKeeper hostnames don’t resolve to a single IP address, such as where the name and IP address a ZooKeeper host uses inside the Kubernetes cluster are different from the external IP of a Kubernetes load balancer service, ZooKeeper could experience problems forming a quorum, joining a quorum, or various communication issues with the quorum.
To configure hyperlinked ZooKeeper with multiple hostname resolution:
On hosts where multiple ZooKeeper nodes are required, create multiple ZooKeeper CRs.
Set
spec.replicasto1in each ZooKeeper CR.The setting specifies that each ZooKeeper pod has a unique peer list.
Set the ZooKeeper pod’s own hostname as
0.0.0.0.The setting prevents each peer from communicating its IP address to other peers, forcing each peer to communicate with other peers using the hostnames they have been configured with.
Configure appropriate Kubernetes Services and DNS records to allow clients and servers outside the Kubernetes cluster to communicate with the ZooKeeper pods within the cluster.
In the following example, the West region has two ZooKeeper CRs for two ZooKeeper pods:
apiVersion: platform.confluent.io/v1beta1
kind: Zookeeper
metadata:
annotations:
platform.confluent.io/zookeeper-myid-offset: "20"
name: zookeeper20
namespace: west
spec:
peers:
- server.30=zk-central0.platformops.dev.gcp.devel.cpdev.cloud:2888:3888
- server.10=zk-east0.platformops.dev.gcp.devel.cpdev.cloud:2888:3888
- server.11=zk-east1.platformops.dev.gcp.devel.cpdev.cloud:2888:3888
- server.20=0.0.0.0:2888:3888
- server.21=zookeeper21-0.zookeeper21.west.svc.cluster.local:2888:3888
replicas: 1
---
apiVersion: platform.confluent.io/v1beta1
kind: Zookeeper
metadata:
annotations:
platform.confluent.io/zookeeper-myid-offset: "21"
name: zookeeper21
namespace: west
spec:
peers:
- server.30=zk-central0.platformops.dev.gcp.devel.cpdev.cloud:2888:3888
- server.10=zk-east0.platformops.dev.gcp.devel.cpdev.cloud:2888:3888
- server.11=zk-east1.platformops.dev.gcp.devel.cpdev.cloud:2888:3888
- server.20=zookeeper20-0.zookeeper20.west.svc.cluster.local:2888:3888
- server.21=0.0.0.0:2888:3888
replicas: 1
Configure Kafka in MRC
To form a logical cluster of Kafka across Kubernetes region clusters:
Set the broker id offset to a different number in the Kafka CR in each region.
For example:
kind: Kafka metadata: annotations: platform.confluent.io/broker-id-offset: "100"
The default is
"0".The offsets should be sufficiently spread out among regions, like
100,200,300, etc., to accommodate future cluster growth in each region.This offset cannot be changed once set. So, you should carefully consider how wide you want these offsets to be before you deploy the clusters.
In the Kafka CRs, specify a comma-separated list of ZooKeeper endpoints in
spec.dependencies.zookeeper.endpointin the ZooKeeper CR. This value should be the same in all Kafka CRs across Kubernetes clusters.Kafka communicates with ZooKeeper through the client port (2181/2182).
For example:
kind: Kafka spec: dependencies: zookeeper: endpoint: zookeeper.central.svc.cluster.local:2182/mrc,zookeeper.east.svc.cluster.local:2182/mrc,zookeeper.west.svc.cluster.local:2182/mrc
The ZooKeeper node id (
mrcin the above example) can be any string, but it needs to be the same for all the Kafka deployments in a multi-region cluster.If you are deploying multiple multi-region clusters utilizing the same ZooKeeper, use different node ids, for example,
mrc1,mrc2, etc., in each multi-region cluster.This value should not be changed once the cluster is created. Otherwise, it results in data loss.
Configure Kafka in MRC with external access URLs
When defined with external access, inter-broker communications go across external access on the replication listener.
The replication listener supports all the external access methods that Kafka supports, namely a load balancer, node ports, routes, port-based and hosted-based static accesses.
In the Kafka CR in each region, configure inter-broker external access to Kafka brokers through the replication listener:
kind: Kafka
spec:
listeners:
replication:
externalAccess:
type: --- [1]
loadBalancer: --- [2]
bootstrapPrefix: --- [3]
brokerPrefix: --- [4]
domain: --- [5]
nodePort: --- [6]
host: --- [7]
nodePortOffset: --- [8]
route: --- [9]
bootstrapPrefix: --- [10]
brokerPrefix: --- [11]
domain: --- [12]
staticForHostBasedRouting: --- [13]
domain: --- [14]
port: --- [15]
brokerPrefix: --- [16]
staticForPortBasedRouting: --- [17]
host: --- [18]
portOffset: --- [19]
internal:
tls:
enabled: true --- [20]
[1] Required. Specify the Kubernetes service for external access. The valid options are
loadBalancer,nodePort,route,staticForPortBasedRouting, andstaticForHostBasedRouting.[2] Configure the external access through load balancers.
[6] Configure the external access through node ports.
[9] Configure the external access through OpenShift routes.
To use routes, TLS must be enabled ([20]) on the internal listener.
[13] Configure the external access through host-based static routing.
[17] Configure the external access through port-based static routing.
[3] [10] Kafka bootstrap prefix.
[4] [11] [16] Kafka broker prefix.
[5] [12] [14] Required. Set it to the domain where your Kubernetes cluster is running.
[7] [18] The host name to be used in the advertised listener for a broker.
[15] The port to be used in the advertised listener for a broker.
[8] [19] The starting port number.
[20] Required when the external access type is set to
route([1]).
RBAC in MRC with external access
When RBAC is enabled, CFK creates external access on the same service for both the replication and token listeners. The kafka.spec.listeners.replication.externalAccess settings are used to create a token listener with the following exceptions:
Route
Separate routes will be created for the replication listeners and the token listeners. The token listener uses the
[brokerPrefix]-token[replica].[domain]domain, and the replication listener uses the[brokerPrefix][replica].[domain]domain.For example, if the domain is
example.comand the brokerPrefix is defaultb, the replication listener domains will beb0.example.com,b1.example.com,b2.example.com, and so on. The token listener domains will beb-token0.example.com,b-token1.example.com,b-token2.example.com.StaticForHostBasedRouting
The token listener uses the
[brokerPrefix]-token[replica].[domain]domain, and the replication listener uses the[brokerPrefix][replica].[domain]domain.
For examples, see External Access in MRC.
Configure Schema Registry in MRC
Currently, the Schema Registry clusters in the stretch (non active-passive) mode only work
with internal listeners.
To form a logical cluster of Schema Registry across Kubernetes region clusters, specify the following properties in each Schema Registry CR:
kind: SchemaRegistry
spec:
configOverrides
server:
- schema.registry.group.id --- [1]
- kafkastore.topic --- [2]
dependencies:
kafka:
bootstrapEndpoint: --- [3]
[1] Specify the same group id for all Schema Registry services across all Kubernetes region clusters.
[2] Specify a string that starts with
_for this log topic name. Use the same value for all Schema Registry services across all Kubernetes region clusters.[3] Specify a comma-separated list of Kafka endpoints across all Kubernetes region clusters.
The following is an example snippet of a Schema Registry CR:
kind: SchemaRegistry
spec:
dependencies:
kafka:
bootstrapEndpoint: kafka-central.platformops.dev.gcp.devel.cpdev.cloud:9092,kafka-west.platformops.dev.gcp.devel.cpdev.cloud:9092,kafka-east.platformops.dev.gcp.devel.cpdev.cloud:9092
configOverrides:
server:
- schema.registry.group.id=schema-registry-mrc
- kafkastore.topic=_schemas_mrc
For details about deploying a multi-region Schema Registry, see Multi Data Center Setup of Schema Registry.
Configure active-passive Schema Registry in MRC
Communication among Schema Registry clusters in different regions is necessary in the active-passive mode. In the active-passive mode, data is copied from the follower Schema Registry to the leader Schema Registry. The follower Schema Registry needs to be able to resolve the leader’s endpoint.
To form a logical cluster of active-passive Schema Registry across Kubernetes region clusters, specify the following properties in each Schema Registry CR:
kind: SchemaRegistry
spec:
configOverride:
server:
- schema.registry.group.id --- [1]
- leader.eligibility --- [2]
[1] Specify the same group id for all Schema Registry services across all Kubernetes region clusters.
[2] Set to
falseon the passive clusters, andtrueon the active clusters.
Configure active-passive Schema Registry in MRC with external access
Currently, in CFK, active-passive schema registry is only supported through load balancers.
To set up Schema Registry clusters in the active-passive mode with external MRC access, conigure each Schema Registry CR as below:
kind: SchemaRegistry
spec:
configOverride:
server:
- inter.instance.listener.name=EXTERNAL --- [1]
- schema.registry.group.id --- [2]
- leader.eligibility --- [3]
listeners:
external:
externalAccess:
type: loadbalancer --- [4]
loadBalancer: --- [5]
prefix: --- [6]
domain: --- [7]
[1] Required.
[2] Specify the same group id for all Schema Registry services across all Kubernetes region clusters.
[3] Set to
falseon the passive clusters, andtrueon the active clusters.[4] Required. Set to
loadBalancer.[5] Configure the external access through load balancers.
[6] Schema Registry prefix.
[7] Required. Set it to the domain where your Kubernetes cluster is running.
Manage Confluent Platform in the multi-region cluster
The following are a few of the common tasks you would perform in a multi-region cluster. Some can be done in one region and get propagated to all regions, and some can be done in a specific region as noted.
- Create topics
You can create and manage topics in any region in a multi-region cluster, and those topics are accessible from all the regions in the cluster.
See Manage Kafka Topics for Confluent Platform Using Confluent for Kubernetes for creating and managing topics.
- Scale Kafka
You need to scale Kafka at the regional level. Update the Kafka CR in a specific region to scale the Kafka cluster in that region.
See Scale Confluent Platform Clusters and Balance Data using Confluent for Kubernetes for scaling Kafka clusters.
- Manage rolebindings
You can create and manage rolebindings in any region in a multi-region cluster, and those rolebindings are accessible from all the regions in the cluster.
See Manage RBAC for Confluent Platform Using Confluent for Kubernetes.
- Rotate certificates
To rotate TLS certificates used in a region, you follow the steps described in Manage TLS Certificates for Confluent Platform Using Confluent for Kubernetes in the specific region.
- Restart Kafka
You need to restart Kafka in a specific region as described in Restart Confluent Platform Using Confluent for Kubernetes.