Deploy and Manage Confluent Platform Using Confluent for Kubernetes¶
Confluent for Kubernetes (CFK) is a cloud-native management control plane for deploying and managing Confluent in your private cloud environment. It provides a standard and simple interface to customize, deploy, and manage Confluent Platform through declarative API.
CFK runs on Kubernetes, the runtime for private cloud architectures.
CFK is a Kubernetes Deployment whose lifecycle is managed by Helm, but all the various Confluent components have their custom resource definitions (CRDs) that can be managed just like any other Kubernetes resource.
CFK actively monitors the custom resources to ensure their state matches the desired state.
Note
CFK is the next generation of Confluent Operator. For Confluent Operator 1.x documentation, see Confluent Operator 1, or use the version picker to browse to a specific version of the documentation.
For an overview of CFK, see Introducing Confluent for Kubernetes.
The following video provides an introduction to CFK.
The following shows the high-level architecture of CFK and Confluent Platform in Kubernetes. Note that CFK also supports Confluent REST Proxy that is not shown in the diagram.
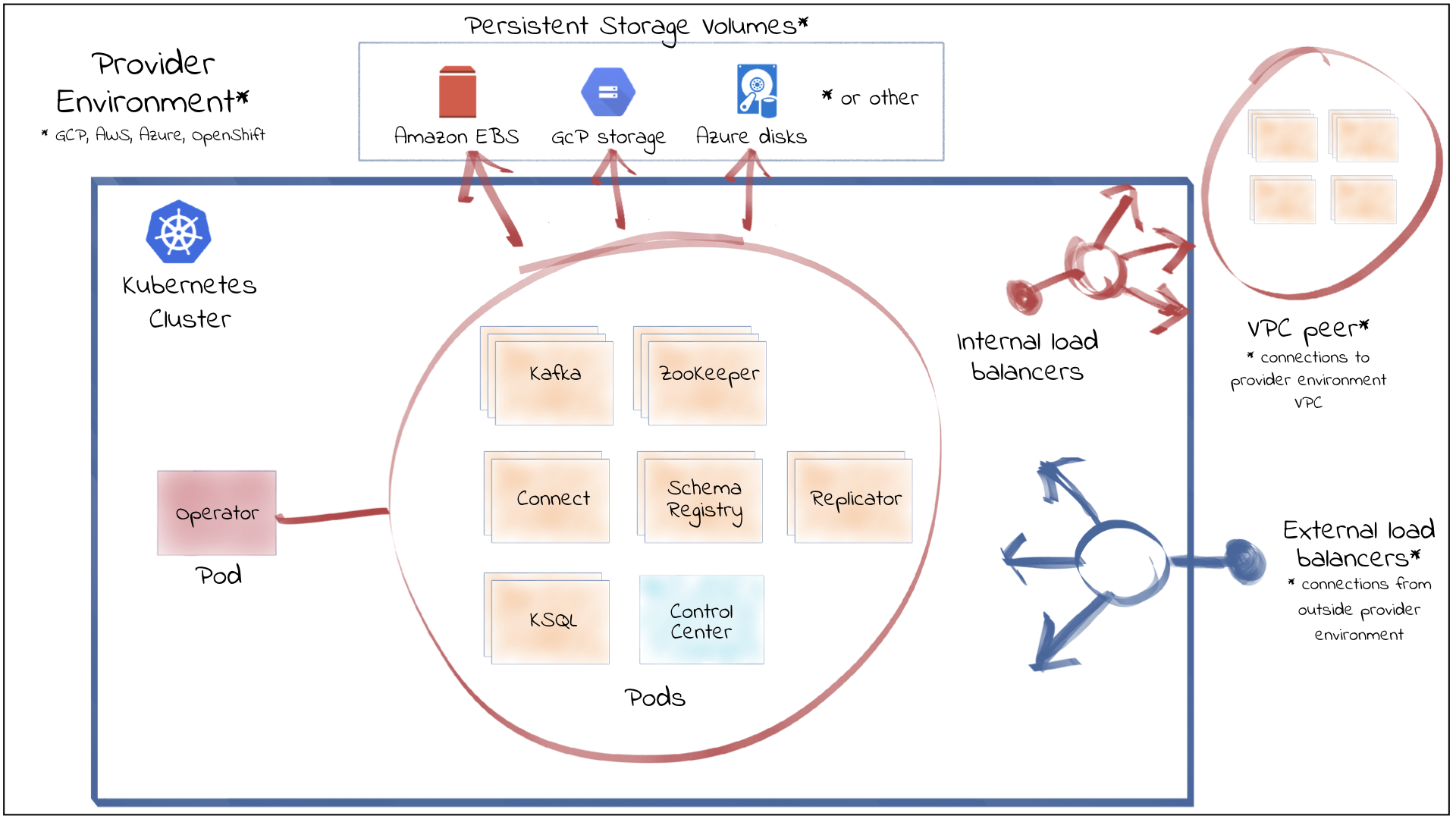
Features¶
The following are summaries of the main, notable features of CFK.
- Cloud Native Declarative API
- Declarative Kubernetes-native API approach to configure, deploy, and manage Confluent Platform components (namely Apache Kafka®, Connect workers, ksqlDB, Schema Registry, Confluent Control Center, Confluent REST Proxy) and application resources (such as topics, rolebindings) through Infrastructure as Code (IaC).
- Provides built-in automation for cloud-native security best practices:
- Complete granular RBAC, authentication and TLS network encryption
- Auto-generated certificates
- Support for credential management systems, such as Hashicorp Vault, to inject sensitive configurations in memory to Confluent deployments
- Provides server properties, JVM, and Log4j configuration overrides for customization of all Confluent Platform components.
- Upgrades
- Provides automated rolling updates for configuration changes.
- Provides automated rolling upgrades with no impact to Kafka availability.
- Scaling
- Provides single command, automated scaling and reliability checks of Confluent Platform.
- Resiliency
- Restores a Kafka pod with the same Kafka broker ID, configuration, and persistent storage volumes if a failure occurs.
- Provides automated rack awareness to spread replicas of a partition across different racks (or zones), improving availability of Kafka brokers and limiting the risk of data loss.
- Scheduling
- Supports Kubernetes labels and annotations to provide useful context to DevOps teams and ecosystem tooling.
- Supports Kubernetes tolerations and pod/node affinity for efficient resource utilization and pod placement.
- Monitoring
- Supports metrics aggregation using JMX/Jolokia.
- Supports aggregated metrics export to Prometheus.