
Multi-Datacenter Architectures on Confluent Platform
Confluent Platform is often used across multiple data centers, for example for disaster recovery, migrations, or geographic locality. Confluent Platform contains several features and products that support multi-data center architectures.
The following sections describe common multi-data center architectures along with use cases and recommended high-level implementations.
Terms
Term | Description |
|---|---|
Recovery Point Objective (RPO) | In the event of failure, at which point in the data’s history does the failover need to resume from? In other words, how much data can be lost during a failure? In order to have zero RPO, synchronous replication is required. |
Recovery Time Objective (RTO) | In the event of failure, how much time can elapse while a failover takes place? In other words, how long can a failover take? In order to have near-zero RTO, seamless client failover is required. |
End user | The humans or computers that use an application built on Confluent Platform. |
Application | The software that provides an interface to the end user and interacts with Confluent Cloud or Confluent Platform on the backend. |
Disaster Recovery (DR) | Umbrella term that encompasses architecture, implementation, tooling, policies, and procedures that all allow an application to recover from a disaster, and in the context of this document, a full data center failure. |
High Availability (HA) | A highly available system can operate continuously even amidst failure. In the context of multi-data center architectures, a highly available application built on Confluent Platform can operate even during a full data center failure. An HA application has a disaster recovery policy. |
Event | A single message produced or consumed to/from Confluent Cloud or Confluent Platform. |
Millisecond (ms) | 1/1,000th of a second |
In addition to the above terminology, review the concepts in Configure Multi-Region Clusters in Confluent Platform.
Why multi-data center?
An application may benefit from a multi data center architecture for one or more of the following reasons:
Data center failure disaster recovery - When a data center experiences a region-wide failure, a multi-region architecture allows failover to a different region to decrease RTO and RPO.
Global operations with minimized latency - End users in one locality, for example in North America, connect to a North American region, whereas end users in another locality, for example in Europe, connect to a European region. This ensures each end user experiences the lowest possible latency.
Data sovereignty - End-user data within certain jurisdictions must never leave the jurisdiction or must be aggregated or anonymized when leaving the jurisdiction.
Data governance - Similar to data sovereignty, some applications require that certain data never leave a certain region or network but perhaps not because of a sovereignty’s laws.
Network isolation - Some applications use Confluent Platform within or through a network DMZ to increase network security.
Why not multi-data center?
Not all applications require a multi-region architecture. For example, many startups don’t have SLAs that require low RPO and/or low RTO during a full region failure.
Further, single-region architectures are simpler and easier to operate and maintain.
Multi-Cluster replication (excluding disaster recovery)
In a multi-cluster replication architecture, some or all events in a region are replicated (mirrored) to another region. These regions are called the source and destination, respectively. This architecture is suitable for many use cases. While Disaster Recovery also can involve replication between multiple clusters, it will be covered in its own sections, below.
Use cases
Self-Managed Confluent Platform to Confluent Cloud Migration
When migrating an application’s Confluent Platform usage from a self-managed Confluent Platform deployment to Confluent Cloud, use a replication architecture to migrate events and components of the application in a piecemeal fashion to Confluent Cloud. This piecemeal method allows for the migration to occur in smaller, more manageable chunks, and possibly decreases or removes any downtime that might have otherwise been caused by a migration.
Lift and shift migration
In a lift-and-shift migration, the original application uses an alternative messaging system instead of Confluent Platform.
In this use case, use a source Connector or Bridge instead of replication components. These connectors read from the alternative messaging system and produce to the Confluent Platform cluster.
Network isolation
Some applications require that certain events only be available within certain regions or networks, whereas other events can or must be available in separate regions or networks.
In such applications, often a separate Confluent Platform cluster is used in each region or network, one cluster replicating to the other.
Data Governance
The Data Governance use case is very similar to the Network Isolation use case above, except that events may be restricted in certain regions for reasons other than network security. See also the Aggregation architecture below.
Aggregation (Hub-and-Spoke)
An aggregation architecture has one or many regions, each running its own local Confluent Platform cluster and application. All or a subset of the local events are replicated to a single, probably larger, aggregate Confluent Platform cluster. Sometimes the aggregate cluster is referred to as the “hub,” and the other regions are referred to as “spokes.”
Aggregation architectures are generally used in one of the following categories:
To support global operations where each spoke region is serving customers in the local geography, yet where a global view of all events is required as well.
To support data governance, where each team uses an independent Confluent Platform cluster, replicating events to an aggregate cluster for applications that require cross-team events. Note that these clusters could run in the same region or separate regions.
This architecture is common in Retail and Entertainment, which typically have many geographically dispersed locations where their customers come to do business in person. It is also used in Transportation, such as cruise ships, and Manufacturing, such as the automotive industry.
Implementation recommendations
Use Cluster Linking for Confluent Platform to replicate topics and metadata between clusters.
2-Cluster Active-Passive
A 2-cluster active-passive architecture involves two clusters: one fully operational “active” cluster serving all produce and consume requests, and one “passive” cluster that is a copy of the “active” but without applications of the “active” but without applications running against it. When the “active” data center fails, applications failover to the “passive” data center. The key difference between this and the 2-cluster active-active architecture is that the active-passive architecture has applications only running in one cluster during normal operating conditions.
This architecture provides RPO > 0 and RTO > 0. RPO is greater than 0 because cross-cluster replication is asynchronous. RTO is greater than 0 because applications need to fail over to a different Confluent Platform cluster.
In this architecture, the entire application is run within the active cluster. Every event produced to the local active cluster is replicated asynchronously to the passive backup cluster.
Then, when failover is triggered, applications are started in the passive cluster, producing and consuming from the passive cluster.
When to use?
Consider using this architecture when the data centers are far apart, have high network latency, or have unpredictable network latency.
When not to use?
Do not use this architecture when a small amount of data loss in the event of a data center failure would lead to a catastrophic cost (such as a breach of regulation).
Implementation recommendations
2+-Cluster Active-Active
A 2+-cluster active-active architecture involves two or more fully-independent Confluent Platform clusters, each a copy of the other. When one of the data centers fails, applications fail over to the other cluster.
This architecture provides RPO > 0 and RTO either > 0 or near 0, depending on your overall architecture. RPO is greater than 0 because cross-cluster replication is asynchronous. If the failure is irrecoverable, a small amount of data can be lost. RTO can be low because you have at least one cluster running at all times. Your architecture must detect a failure and divert traffic upstream (such as through a load balancer or DNS) to the remaining active cluster. Applications must be duplicated and deployed in both fully-operational data centers in order to achieve an RTO close to 0. If your applications only run in one datacenter at a time, then the RTO depends on the amount of time it takes to restart them in the surviving data center.
When to use?
Consider using this architecture when two or more data centers are strategically located in areas of low-latency or low-cost, and thus there is a business advantage from running applications in multiple data centers at the same time. Additionally, consider this architecture when the data centers are far apart, have high network latency, or have unpredictable network latency.
When not to use?
Do not use this architecture when a small amount of data loss in the event of a data center failure would lead to a catastrophic cost (for example, breach of regulation).
Do not use this architecture if an active/passive one would work just as well.
Use Cases
Telecommunications
Telecommunications applications typically require low latency and tolerate low RPO and RTO.
Implementation recommendations
Stretched cluster 3-datacenter
A stretched 3-data center cluster architecture in kraft mode involves three data centers that are connected by a low latency (sub-100ms) and stable (very tight p99s) network, usually a “dark fiber” network that is owned or leased privately by the company. Confluent Server nodes are configured with appropriate process.roles (either broker,controller for combined roles or dedicated broker and controller roles) and are spread evenly across the three data centers to form a single, stretched KRaft cluster. The KRaft controller quorum now manages the cluster metadata and handles leader elections for all Kafka brokers in this single, stretched cluster.
Stretched clusters can provide RPO = 0 and RTO = 0. They can also provide RPO > 0 and RTO > 0, depending on configuration.
The most common setup is to stretch between data centers in neighboring states, such as New York, New Jersey, and Boston. This provides redundancy against a data center failure, power or cooling outage, or geographic disaster.
When to use?
Use a stretched cluster when extremely high availability is paramount (RPO = 0 and RTO ~ 0) and three data centers are connected by a stable, low-latency network.
Stretched cluster architectures are most commonly used for applications located within a single geographic region (such as the Northeast USA)
When not to use?
Do not use a stretched cluster when data centers are far apart (for example, in distant geographic regions) or when network performance is poor or unknown.
Do not use a stretched cluster when fewer than three fully operational data centers are available, or when you don’t have a strict RPO = 0 need (for example, if your business can tolerate a small amount of data loss in the event of a failure without catastrophic consequences).
Use Cases
Consumer banking and high frequency trading
Many consumer banks or trading firms have low or zero RPO and RTO requirements and customers only within a single country or continent.
Tip
To learn more about how to achieve near zero RPO and RTO, see the following blog post, which supplements the use cases detailed below: Automatic Observer Promotion Brings Fast and Safe Multi-Datacenter Failover with Confluent Platform 6.1
Physical infrastructure
If Kafka powers physical infrastructure, like trains, then downtime or data loss may put lives at risk.
Implementation recommendations
Deploy Confluent with Configure Multi-Region Clusters in Confluent Platform and three racks, one for each data center. Confluent Server nodes, whether configured as combined broker,controller roles or dedicated broker and controller roles, should be spread evenly across data centers to establish the kraft controller quorum and distribute brokers. Ensure the log.dirs for controllers are configured appropriately for resilience.
Note
You can contact Confluent for guidance when considering these architectures. Working with Confluent Professional Services is highly recommended to ensure the proper tuning and configuration is done to achieve these strict requirements
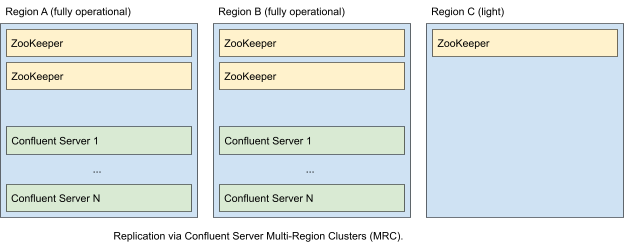
Stretched cluster 2.5 datacenter
A stretched 2.5-data center architecture involves two fully-operational data centers and one light (0.5) data center running a single, stretched cluster. The fully operational data centers run an equal number of Confluent Server nodes configured as brokers and controllers, whereas the light data center runs a subset of kraft controller nodes to maintain the controller quorum (the equivalent of running a single ZooKeeper server in legacy deployments). When any single datacenter fails, the KRaft controller quorum remains available. When a fully operational datacenter fails, applications fail over to the other datacenter.
This architecture provides RPO = 0 or > 0 depending on configuration, and RTO >= 0. RPO is greater than 0 when inter-data center replication is not guaranteed to be synchronous.
RTO is near zero when an application instance is running in each data center, and you have automatic-observer promotion with replicas in each data center, and a third data center with at least one KRaft controller node, as described in this blog post: Automatic Observer Promotion Brings Fast and Safe Multi-Datacenter Failover with Confluent Platform. Otherwise, RTO is greater than 0 due to needing to failover applications to another data center.
You can achieve different RPO depending on replica configurations. To achieve RPO = 0, you need at least two data centers with replicas, and the number of minimum in-sync replicas must be greater than the number of replicas in any given data center. For example, if you configure two replicas and one observer per location and min.ISR=3, there is synchronous replication across the two locations, and RPO = 0 for a data center failure. Note that producers must be configured to acks=all to support this. If producers are not adequately configured, the replica placement as described is necessary but not sufficient to achieve RPO = 0.
Note
A common deployment is to run two data centers that contain brokers and controllers, and a third location that hosts only KRaft controller nodes so a quorum can be established. In this setup, if there is a network partition between the brokers, but not between the controller nodes, then manual action is required to restore the cluster to health, even if Automatic Observer Promotion is in use. If you have this type of deployment, it is important to be aware of this potential failure scenario and set up appropriate monitoring, alerting, and procedures to address it.
When to use?
Use a 2.5 DC stretched cluster when extremely high availability is paramount (RPO = 0 and RTO ~ 0) and three data centers are connected by a stable, low-latency network.
When not to use?
Do not use a stretched cluster when data centers are far apart (for example, in distant geographic regions) or when network performance is > 100 ms, unstable, or unknown.
Use Cases
Consumer banking and high frequency trading
Many consumer banks or trading firms have low or zero RPO and RTO requirements and customers only within a single country or continent.
Tip
To learn more about how to achieve near zero RPO and RTO, see the following blog post, which supplements the use cases detailed below: Automatic Observer Promotion Brings Fast and Safe Multi-Datacenter Failover with Confluent Platform 6.1
Physical infrastructure
If Kafka powers physical infrastructure, like trains, then downtime or data loss may put lives at risk.
Implementation recommendations
In all three data centers, deploy Confluent Server nodes configured as kraft controllers. In a five-host controller cluster, deploy two in one fully-operational data center, deploy two in the other fully-operational data center, and deploy the fifth in the light data center. Deploy an equal number of brokers in each fully-operational data center.
Enable and configure the Configure Multi-Region Clusters in Confluent Platform, including self-promoting observers, as described in Automatic Observer Promotion Brings Fast and Safe Multi-Datacenter Failover with Confluent Platform 6.1.
Note that MRC is only available in Confluent Platform.
Note
You can contact Confluent for guidance when considering these architectures. Working with Confluent Professional Services is highly recommended to ensure the proper tuning and configuration is done to achieve these strict requirements
Architecture diagram
Comparison chart of multi-region options
Product | Confluent Cloud Support | RPO in a DC failure | RTO in a DC failure | Description |
|---|---|---|---|---|
Yes, self-managed connecting to Confluent Cloud | > 0 | > 0 | Cluster Linking perfectly mirrors topics and metadata from one data center to another, and is built into Confluent Server brokers | |
MirrorMaker | Yes, self-managed connecting to Confluent Cloud | > 0 | > 0 | |
No | = 0 or > 0, depending on the configuration | >= 0 | Multi-Region Clusters (MRC) is a feature set that supports seamless failover and simpler multi-data center architectures. |