Kafka Connect の概念¶
Kafka Connect は、Apache Kafka® との間でデータのストリーミングを行うためのフレームワークです。Confluent Platform にはいくつかの 組み込みのコネクター が付属しており、リレーショナルデータベースや HDFS などの一般的に使用されているシステムとの間でデータのストリーミングを行うために使用することができます。Kafka Connect の内部的な仕組みについて説明するうえで役立つため、ここでは、いくつかの主要な概念について説明します。
- コネクター -- タスクを管理して、データストリーミングを調整する機能の高度な抽象化
- タスク -- Kafka からデータをコピーする方法または Kafka にデータをコピーする方法の実装
- ワーカー -- コネクターおよびタスクを実行するために実行されるプロセス
- コンバーター -- Connect とデータを送受信するシステムとの間でやり取りされるデータを変換するために使用されるコード
- 変換 -- コネクターで生成されたメッセージやコネクターに送信されたメッセージに変更を加えるシンプルなロジック
- デッドレターキュー -- Connect でコネクターのエラーを処理する方法
コネクター¶
Connectors in Kafka Connect define where data should be copied to and from. A connector instance is a logical job that is responsible for managing the copying of data between Kafka and another system. All of the classes that implement or are used by a connector are defined in a connector plugin. Both connector instances and connector plugins may be referred to as "connectors", but it should always be clear from the context which is being referred to (for example, "install a connector" refers to the plugin, and "check the status of a connector" refers to a connector instance).
既存のコネクター を使用することが推奨されています。ただし、新しいコネクタープラグインをゼロから作成することもできます。開発者が新しいコネクタープラグインを作成する場合の大まかなワークフローは次のとおりです。詳細については、「開発者ガイド」を参照してください。

タスク¶
タスクは、Connect のデータモデルにおける主役です。実際にデータをコピーする一連の タスク の調整を各コネクターインスタンスが行います。コネクターで 1 つのジョブを複数のタスクに分割できるため、Kafka Connect では、並列処理とスケーラブルなデータのコピーが組み込みでサポートされており、必要な構成作業もほとんどありません。これらのタスクでは、タスク自体に状態(ステート)は保存されません。タスクのステートは Kafka の特別なトピックである config.storage.topic および status.storage.topic に保存され、関連するコネクターによって管理されます。そのため、タスクはいつでも開始、終了、再開することができ、回復性と拡張性を備えたデータパイプラインを実現できます。
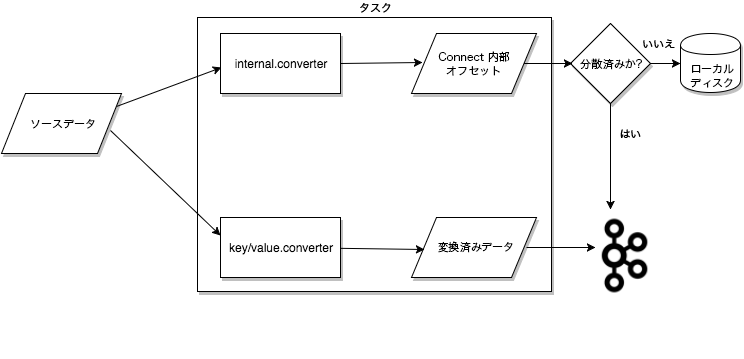
Connect ソースタスクから Kafka に渡されるデータの大まかな流れ。内部オフセットはタスク自体ではなく、Kafka またはディスク上に保存されることに注意してください。¶
タスクのバランス調整¶
When a connector is first submitted to the cluster, the workers rebalance the full set of connectors in the cluster and their tasks so that each worker has approximately the same amount of work. This same rebalancing procedure is also used when connectors increase or decrease the number of tasks they require, or when a connector's configuration is changed. When a worker fails, tasks are rebalanced across the active workers. When a task fails, no rebalance is triggered as a task failure is considered an exceptional case. As such, failed tasks are not automatically restarted by the framework and should be restarted via the REST API.
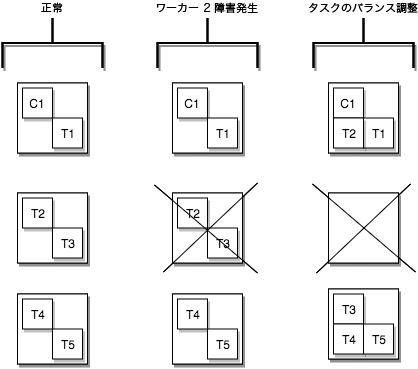
ワーカーの障害発生時にタスクのバランス調整がどのように行われるかを示す、タスクのフェイルオーバーの例¶
ワーカー¶
コネクターとタスクは論理作業単位であり、プロセスで実行されるようにスケジュールが設定される必要があります。Kafka Connect ではこれらのプロセスを ワーカー と呼び、ワーカーにはスタンドアロンと分散の 2 種類があります。
スタンドアロンワーカー¶
スタンドアロンモードは最もシンプルなモードで、すべてのコネクターおよびタスクの実行を 1 つのプロセスで行います。
プロセスが単一であるため、必要な構成が最小限で済みます。スタンドアロンモードは、初期段階や開発中、また、ホストからのログの収集など、1 つのプロセスで十分な場合に役立ちます。ただし、プロセスが 1 つだけであるため、機能も制限されます。拡張性が 1 つのプロセスに限定され、1 つのプロセスに対してモニタリングを行う以上のフォールトトレランスがありません。
分散ワーカー¶
分散モードは、Kafka Connect に拡張性と自動フォールトトレランスをもたらします。分散モードでは、同じ group.id を使用して複数のワーカープロセスを開始します。ワーカープロセスは自動的に調整を行い、使用可能なすべてのワーカーでコネクターおよびタスクの実行のスケジューリングを行います。ワーカーを追加した場合、ワーカーをシャットダウンした場合、またはワーカーで予期せず障害が発生した場合、残りのワーカーによってその状態が検出され、自動的に調整が行われ、その時点で使用可能なワーカー間でコネクターおよびタスクが再分配されます。コンシューマーグループのバランス調整と似ていることに注意してください。内部的には、Connect ワーカーではコンシューマーグループを使用して調整やバランス調整が行われます。
重要
同じ group.id を持つワーカーはすべて同じ Connect クラスターに属します。たとえば、worker-a で group.id=connect-cluster-a と設定されていて、worker-b の group.id も同じである場合、worker-a と worker-b は、connect-cluster-a というクラスターを構成します。

3 ノードの Kafka Connect 分散モードクラスター。コネクター(タスクの再構成が必要な変更の有無に関する、ソースシステムやシンクシステムのモニタリング)とタスク(コネクターのデータのサブセットのコピー)については、アクティブなワーカー間で自動的にバランス調整が行われます。パーティションごとに各タスクが割り当てられており、複数のタスクの負荷が分散されている様子を示しています。¶
コンバーター¶
Kafka Connect のデプロイで、Kafka への書き込みや Kafka からの読み取りの際に特定のデータフォーマットをサポートするために、コンバーターが必要になります。タスクではコンバーターを使用して、データのフォーマットをバイト型から Connect の内部データフォーマットに、またはその逆に変換します。
デフォルトでは、Confluent Platform には以下のコンバーターが用意されています。
- AvroConverter
io.confluent.connect.avro.AvroConverter: use with Schema Registry - ProtobufConverter
io.confluent.connect.protobuf.ProtobufConverter: use with Schema Registry - JsonSchemaConverter
io.confluent.connect.json.JsonSchemaConverter: use with Schema Registry - JsonConverter
org.apache.kafka.connect.json.JsonConverter(Schema Registry なし): 構造化データに使用 - StringConverter
org.apache.kafka.connect.storage.StringConverter: シンプルな文字列フォーマット - ByteArrayConverter
org.apache.kafka.connect.converters.ByteArrayConverter: 変換を行わない "パススルー" のオプションを提供
コンバーターはコネクター自体とは切り離されているため、さまざまなコネクターでコンバーターを無理なく再利用できます。たとえば、同じ Avro コンバーターを使用して、JDBC Source Connector による Kafka への Avro データの書き込みと、HDFS Sink Connector による Kafka からの Avro データの読み取りを実現できます。つまり、たとえば JDBC ソースから返された ResultSet が Parquet ファイルとして HDFS に書き込まれる場合などにも、同じコンバーターを使用することができます。
次の図は、JDBC Source Connector を使用したデータベースからの読み取り、Kafka への書き込み、さらに HDFS Sink Connector を使用した HDFS への書き込みで、コンバーターがどのように使用されるかを示したものです。
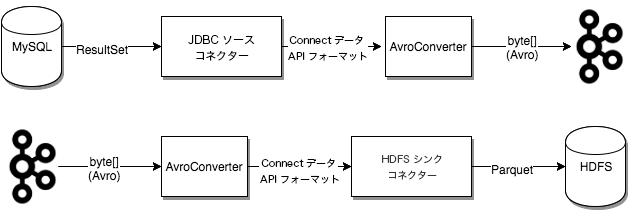
For detailed information about converters, see Configuring Key and Value Converters. For more information about how converters and Schema Registry work, see Kafka Connect と Schema Registry の使用.
ちなみに
コンバーターの詳細については、「コンバーターとシリアル化について」を参照してください。
変換¶
変換を使用するようコネクターを構成して、個々のメッセージに簡単で軽微な変更を加えることができます。これは、小規模なデータの調整やイベントのルーティングなどに役立つ場合があります。コネクターの構成で、複数の変換を連続して使用することもできます。ただし、複数のメッセージに複雑な変換や操作を適用する場合は、 ksqlDB 概要 や Kafka Streams の概要 で実装するのが適しています。
A transform is a simple function that accepts one record as an input and outputs a modified record. All transforms provided by Kafka Connect perform simple but commonly useful modifications. Note that you can implement the Transformation interface with your own custom logic, package them as a Kafka Connect plugin, and use them with any connectors.
ソースコネクターで変換が使用される場合、Kafka Connect がコネクターで生成された各ソースレコードを最初の変換に渡すと、変更が加えられ、新しいソースレコードが出力されます。この更新済みのソースレコードがチェーン内の次の変換に渡され、新しく変更が加えられたソースレコードが生成されます。このようにして残りの変換も実行されます。最終的に更新されたソースレコードが バイナリ形式に変換 され、Kafka に書き込まれます。
変換は、シンクコネクターで使用することもできます。Kafka Connect は Kafka からメッセージを読み取り、 バイナリ表現をシンクレコードに変換 します。変換がある場合、Kafka Connect がレコードを最初の変換に渡すと、変更が加えられ、新しい更新済みのシンクレコードが出力されます。この更新済みのシンクレコードがチェーン内の次の変換に渡され、新しいシンクレコードが生成されます。このようにして残りの変換も実行され、最終的に更新されたシンクレコードがシンクコネクターに渡されて、処理されます。
詳細については、「Single Message Transforms for Confluent Platform」を参照してください。
| 変換 | 説明 |
|---|---|
| Cast | フィールドや、キーまたは値の全体を特定の型に変換(キャスト)します(整数のフィールドを狭範囲の整数のフィールドに変換するなど)。 |
| Drop | レコードの 1 つのキーまたは値をドロップ(破棄)して null を設定します。 |
| DropHeaders | Not currently available for managed connectors. Drop one or more headers from each record. |
| ExtractField | スキーマが存在する場合は Struct から、スキーマのないデータの場合は Map から、指定されたフィールドを抽出します。null 値はすべてそのまま渡されます。 |
| ExtractTopic | レコードトピックを、キーまたは値から派生された新しいトピックに置き換えます。 |
| Filter(Apache Kafka) | すべてのレコードをドロップします。述語 と組み合わせて使用します。 |
| Filter(Confluent) | 構成可能な filter.condition と一致するレコードを含めるか、ドロップします。 |
| Flatten | ネストしたデータ構造をフラット化します。これにより、階層ごとにフィールド名が区切り文字で連結されて、それぞれのフィールド名が生成されます(区切り文字は変更することができます)。 |
| GzipDecompress | Not currently available for managed connectors. Gzip-decompress the entire byteArray key or value input. |
| HeaderFrom | Not currently available for managed connectors. Moves or copies fields in a record key or value into the record's header. |
| HoistField | スキーマが存在する場合は Struct の、スキーマのないデータの場合は Map の、指定されたフィールド名を使用してデータをラップします。 |
| InsertField | レコードメタデータの属性または構成された静的な値を使用してフィールドを挿入します。 |
| InsertHeader | Not currently available for managed connectors. Insert a literal value as a record header. |
| MaskField | 指定されたフィールドを、そのフィールドの型に対して有効な null 値でマスクします。 |
| MessageTimeStampRouter | 元のトピックの値とレコードのタイムスタンプフィールドに応じて、レコードのトピックフィールドを更新します。 |
| RegexRouter | Not currently available for managed connectors. Update the record topic using the configured regular expression and replacement string. |
| ReplaceField | フィールドにフィルターをかけるか、フィールドの名前を変更します。 |
| SetSchemaMetadata | レコードのキーまたは値のスキーマに対して、スキーマ名とバージョンのいずれか、または両方を設定します。 |
| TimestampConverter | Unix エポック、文字列、Connect の Date 型および Timestamp 型など、タイムスタンプのフォーマットを別のフォーマットに変換します。 |
| TimestampRouter | 元のトピックの値とレコードのタイムスタンプに応じて、レコードのトピックフィールドを更新します。 |
| TombstoneHandler | tombstone レコードを管理します。tombstone レコードとは、ValueSchema の有無に関係なく、値フィールド全体が null になっているレコードと定義されています。 |
| TopicRegexRouter | Only available for managed Source connectors. Update the record topic using the configured regular expression and replacement string. |
| ValueToKey | レコードキーを、レコード値のフィールドのサブセットから形成された新しいキーに置き換えます。 |
デッドレターキュー¶
さまざまな理由から、無効なレコードが生じることがあります。1 例として、シンクコネクターの構成で Avro フォーマットが想定されているにもかかわらず、そのシンクコネクターに JSON フォーマットでシリアル化されたレコードが届いた場合が挙げられます。無効なレコードをシンクコネクターで処理できない場合、コネクターの構成プロパティ errors.tolerance に基づいてエラーが処理されます。
デッドレターキューは、シンクコネクターにのみ適用されます。
注釈
デッドレターキューのトピックは、Confluent Cloud シンクコネクター用に自動生成されます。詳細については、「Confluent Cloud デッドレターキュー」を参照してください。
この構成プロパティの有効な値としては、none (デフォルト)と all の 2 つがあります。
errors.tolerance が none に設定されている場合、エラーが発生するか無効なレコードが見つかると、その時点でコネクタータスクは失敗となり、コネクターのステータスが Failed になります。この問題を解決するには、Kafka Connect ワーカーのログを確認して障害が発生した原因を特定し、問題を修正して、コネクターを再起動する必要があります。
errors.tolerance が all に設定されている場合、エラーや無効なレコードはすべて無視され、処理が続行されます。Connect ワーカーのログには、エラーは書き込まれません。失敗したレコードがあるかどうかを判断するには、 内部メトリクス を使用するか、ソースのレコード数を計算して、処理されたレコード数と比較する必要があります。
エラー処理機能を使用することができ、その場合、無効なレコードはすべて特別なトピックにルーティングされ、エラーがレポートされます。このトピックには、シンクコネクターで処理できなかったレコードの デッドレターキュー が含まれます。
デッドレターキューのトピックの作成¶
デッドレターキューを作成するには、以下の構成プロパティをシンクコネクターの構成に追加します。
errors.tolerance = all
errors.deadletterqueue.topic.name = <dead-letter-topic-name>
デッドレターキューが有効になっている、GCS のシンクコネクターの構成の例を以下に示します。
{
"name": "gcs-sink-01",
"config": {
"connector.class": "io.confluent.connect.gcs.GcsSinkConnector",
"tasks.max": "1",
"topics": "gcs_topic",
"gcs.bucket.name": "<my-gcs-bucket>",
"gcs.part.size": "5242880",
"flush.size": "3",
"storage.class": "io.confluent.connect.gcs.storage.GcsStorage",
"format.class": "io.confluent.connect.gcs.format.avro.AvroFormat",
"partitioner.class": "io.confluent.connect.storage.partitioner.DefaultPartitioner",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://localhost:8081",
"schema.compatibility": "NONE",
"confluent.topic.bootstrap.servers": "localhost:9092",
"confluent.topic.replication.factor": "1",
"errors.tolerance": "all",
"errors.deadletterqueue.topic.name": "dlq-gcs-sink-01"
}
}
デッドレタートピックには失敗したレコードが含まれていますが、それでは、理由はわかりません。さらに次の構成プロパティを追加すると、失敗したレコードのヘッダー情報を含めることができます。
errors.deadletterqueue.context.headers.enable = true
Record headers are added to the dead letter queue when this parameter is set to true
(the default is false). You can then use the kcat (旧 kafkacat)ユーティリティ to view the record header
and determine why the record failed. Errors are also sent to Connect Reporter.
注釈
元のレコードヘッダーとの競合を回避するため、デッドレターキューのコンテキストヘッダーキーは先頭が _connect.errors になります。
先ほどの例で、ヘッダーを有効にした構成がこちらです。
{
"name": "gcs-sink-01",
"config": {
"connector.class": "io.confluent.connect.gcs.GcsSinkConnector",
"tasks.max": "1",
"topics": "gcs_topic",
"gcs.bucket.name": "<my-gcs-bucket>",
"gcs.part.size": "5242880",
"flush.size": "3",
"storage.class": "io.confluent.connect.gcs.storage.GcsStorage",
"format.class": "io.confluent.connect.gcs.format.avro.AvroFormat",
"partitioner.class": "io.confluent.connect.storage.partitioner.DefaultPartitioner",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://localhost:8081",
"schema.compatibility": "NONE",
"confluent.topic.bootstrap.servers": "localhost:9092",
"confluent.topic.replication.factor": "1",
"errors.tolerance": "all",
"errors.deadletterqueue.topic.name": "dlq-gcs-sink-01",
"errors.deadletterqueue.context.headers.enable":true
}
}
参考
このトピックの詳細については、「Kafka Connect の詳説 – エラー処理とデッドレターキュー」を参照してください。
セキュリティを有効にしたデッドレターキューの使用¶
セキュリティを有効にして Confluent Platform を使用すると、Confluent Platform 管理クライアント によってデッドレターキューのトピックが作成されます。無効なレコードは、まず、それらのレコードを送信するように構成されている内部のプロデューサーに渡されます。その後、管理クライアントによってデッドレターキューのトピックが作成されます。
セキュアな Confluent Platform 環境でデッドレターキューを使用するには、追加の管理クライアントの構成プロパティ(.admin というプレフィックス付き)を Connect ワーカーの構成に追加する必要があります。追加の Connect ワーカーの構成プロパティを指定する SASL/PLAIN の例を以下に示します。
admin.ssl.endpoint.identification.algorithm=https
admin.sasl.mechanism=PLAIN
admin.security.protocol=SASL_SSL
admin.request.timeout.ms=20000
admin.retry.backoff.ms=500
admin.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="<user>" \
password="<secret>";
参考
ロールベースアクセス制御(RBAC)環境における Connect ワーカー、シンクコネクター、デッドレターキュートピックの構成の詳細については、「Kafka Connect と RBAC」を参照してください。