
Horizontal Scaling for Oracle CDC Source Connector for Confluent Platform
The following sections provide information about horizontal scaling.
Task Example
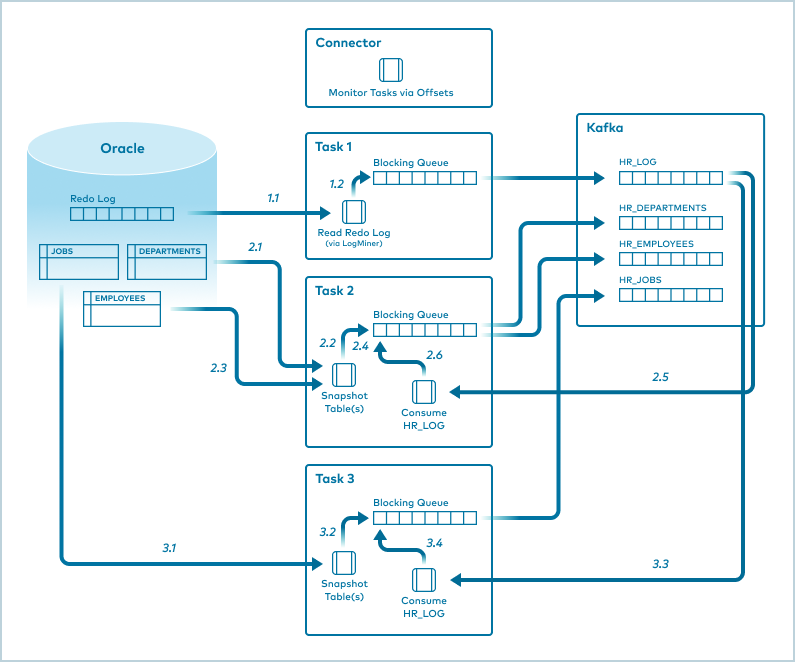
The Oracle CDC Source connector scales horizontally using the existing Kafka Connect framework. The connector is configured with three tasks in the following graphic.
Task 1: Reads records from the Oracle Database Redo Log, then writes these records to a redo log topic in Apache Kafka®.
Task 2: Creates a snapshot for the DEPARTMENTS and EMPLOYEES tables.
Task 3: Creates a snapshot for the JOBS table.
Once Task 2 and Task 3 are done with snapshotting, they read records from the Redo Log Topic in Kafka rather than from the Oracle database Redo Log Topic. The three tasks populate Kafka with table-specific topics from the snapshot forward.
Tip
If you need to create snapshots for many tables, you can add more tasks to get better snapshot performance.
Horizontal Scaling Example
Table Partition Snapshots
The connector performs snapshots, in parallel, of large tables that are partitioned in Oracle, and distributes these table-partition snapshots across all tasks. To do this, you use the connector properties start.from=snapshot and snapshot.by.table.partitions.
For example, when the connector is configured with start.from=snapshot, you can set the property snapshot.by.table.partitions=true allowing you to assign more than one task to one table (if the table is partitioned). This is scaling the number of tasks linearly, so more snapshots are performed in parallel across a larger number of tasks. For example, a connector can capture and snapshot a single large table (N=1) with many table partitions (for example, P=20) using up to P+1 tasks. This reduces the overall time required to perform the snapshot by scaling out the number of tasks.
When running a connector with snapshot.by.table.partitions=true, create table-specific topics ahead of time. If table-specific topics are not created ahead of time, some tasks assigned to partitioned tables will fail.