
Troubleshooting Oracle CDC Source Connector for Confluent Platform
This page contains troubleshooting information for the Kafka Connect Oracle CDC Source connector.
Note
Some of the troubleshooting steps may differ for the self-managed Confluent Platform connector versus the fully-managed Confluent Cloud connector. If you find differences, use the feedback button and the Confluent Documentation team will correct any discrepancies.
Basic troubleshooting
The following sections describe a few potential issues and how to resolve them.
Important
Before troubleshooting start-up issues: If you don’t see a snapshot or if no records are populating the redo-log topic, make sure the Oracle database and the database user are properly configured. The Oracle CDC Source connector will not produce the expected results until you complete the required prerequisite configuration steps.
New records are not populating my table-specific topic
The existing schema may not be compatible with the redo log topic. Removing the schema or using a different redo log topic may fix this issue.
Numbers in my table-specific topics are not human readable
NUMBER or DECIMAL types in a table are converted to a decimal value that is represented in byte type in Kafka. For example purposes, suppose you have the following table:
CREATE TABLE MARIPOSA_ORDERDETAILS ( \
"ORDER_NUMBER" NUMBER (9) PRIMARY KEY, \
"PRODUCT_CODE" NUMBER (9), \
"DESCRIPTION" CLOB, \
"QUANTITY_ORDERED" NUMBER (25,13), \
"PRICE_EACH" VARCHAR2(10), \
"QUANTITY_INVENTORY" NUMBER (4,2) \
)\
SEGMENT CREATION IMMEDIATE PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 NOCOMPRESS LOGGING \
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) \
TABLESPACE "USERS"
The following examples show a record and a schema from this table, using the Avro converter. The first example shows the original results (not human readable) and the second example shows how the results can be made human readable using the "numeric.mapping":"best_fit_or_decimal" connector property.
Result is not human readable
The record from the table:
{
"ORDER_NUMBER": "\u0001\u001f",
"PRODUCT_CODE": {
"bytes": "\u0003ê"
},
"QUANTITY_ORDERED": {
"bytes": "QÚ \u0007 \u0000"
},
"PRICE_EACH": {
"string": "$7500"
},
"QUANTITY_INVENTORY": {
"bytes": "\u0003è"
},
"table": {
"string": "ORCL.ADMIN.MARIPOSA_ORDERDETAILS"
},
"scn": {
"string": "33003097"
},
"op_type": {
"string": "R"
},
"op_ts": null,
"current_ts": {
"string": "1610143106957"
},
"row_id": null,
"username": null
}
The schema from the table:
{
"fields": [
{
"name": "ORDER_NUMBER",
"type": {
"connect.name": "org.apache.kafka.connect.data.Decimal",
"connect.parameters": {
"scale": "0"
},
"connect.version": 1,
"logicalType": "decimal",
"precision": 64,
"scale": 0,
"type": "bytes"
}
},
{
"default": null,
"name": "PRODUCT_CODE",
"type": [
"null",
{
"connect.name": "org.apache.kafka.connect.data.Decimal",
"connect.parameters": {
"scale": "0"
},
"connect.version": 1,
"logicalType": "decimal",
"precision": 64,
"scale": 0,
"type": "bytes"
}
]
},
{
"default": null,
"name": "QUANTITY_ORDERED",
"type": [
"null",
{
"connect.name": "org.apache.kafka.connect.data.Decimal",
"connect.parameters": {
"scale": "13"
},
"connect.version": 1,
"logicalType": "decimal",
"precision": 64,
"scale": 13,
"type": "bytes"
}
]
},
{
"default": null,
"name": "PRICE_EACH",
"type": [
"null",
"string"
]
},
{
"default": null,
"name": "QUANTITY_INVENTORY",
"type": [
"null",
{
"connect.name": "org.apache.kafka.connect.data.Decimal",
"connect.parameters": {
"scale": "2"
},
"connect.version": 1,
"logicalType": "decimal",
"precision": 64,
"scale": 2,
"type": "bytes"
}
]
},
{
"default": null,
"name": "table",
"type": [
"null",
"string"
]
},
{
"default": null,
"name": "scn",
"type": [
"null",
"string"
]
},
{
"default": null,
"name": "op_type",
"type": [
"null",
"string"
]
},
{
"default": null,
"name": "op_ts",
"type": [
"null",
"string"
]
},
{
"default": null,
"name": "current_ts",
"type": [
"null",
"string"
]
},
{
"default": null,
"name": "row_id",
"type": [
"null",
"string"
]
},
{
"default": null,
"name": "username",
"type": [
"null",
"string"
]
}
],
"name": "ConnectDefault",
"namespace": "io.confluent.connect.avro",
"type": "record"
}
Human readable result
If you want to see NUMBER as INT or DOUBLE, you can use the "numeric.mapping":"best_fit_or_decimal" connector property. The following examples show a record and a schema from this table, using this property setting.
The record from the table:
{
"ORDER_NUMBER": 399,
"PRODUCT_CODE": {
"int": 1001
},
"QUANTITY_ORDERED": {
"double": 10
},
"PRICE_EACH": {
"string": "$2500"
},
"QUANTITY_INVENTORY": {
"double": 10
},
"table": {
"string": "ORCL.ADMIN.MARIPOSA_ORDERDETAILS"
},
"scn": {
"string": "33014353"
},
"op_type": {
"string": "R"
},
"op_ts": null,
"current_ts": {
"string": "1610143395344"
},
"row_id": null,
"username": null
}
The schema from the table:
{
"fields": [
{
"name": "ORDER_NUMBER",
"type": "int"
},
{
"default": null,
"name": "PRODUCT_CODE",
"type": [
"null",
"int"
]
},
{
"default": null,
"name": "QUANTITY_ORDERED",
"type": [
"null",
"double"
]
},
{
"default": null,
"name": "PRICE_EACH",
"type": [
"null",
"string"
]
},
{
"default": null,
"name": "QUANTITY_INVENTORY",
"type": [
"null",
"double"
]
},
{
"default": null,
"name": "table",
"type": [
"null",
"string"
]
},
{
"default": null,
"name": "scn",
"type": [
"null",
"string"
]
},
{
"default": null,
"name": "op_type",
"type": [
"null",
"string"
]
},
{
"default": null,
"name": "op_ts",
"type": [
"null",
"string"
]
},
{
"default": null,
"name": "current_ts",
"type": [
"null",
"string"
]
},
{
"default": null,
"name": "row_id",
"type": [
"null",
"string"
]
},
{
"default": null,
"name": "username",
"type": [
"null",
"string"
]
}
],
"name": "ConnectDefault",
"namespace": "io.confluent.connect.avro",
"type": "record"
}
NUMERIC data type with no precision or scale results in unreadable output
The following Oracle database table includes ORDER_NUMBER and CUSTOMER_NUMBER NUMERIC data types without precision or scale included.
CREATE TABLE MARIPOSA_ORDERS (
"ORDER_NUMBER" NUMBER PRIMARY KEY,
"ORDER_DATE" TIMESTAMP(6) NOT NULL,
"SHIPPED_DATE" TIMESTAMP(6) NOT NULL,
"STATUS" VARCHAR2(50),
"CUSTOMER_NUMBER" NUMBER)
The Oracle CDC Source connector generates the following schema in Schema Registry, when using the Avro converter and the connector property "numeric.mapping: "best_fit_or_decimal":
{ "fields": [
{ "name": "ORDER_NUMBER",
"type": {
"connect.name": "org.apache.kafka.connect.data.Decimal",
"connect.parameters": { "scale": "127" },
"connect.version": 1,
"logicalType": "decimal",
"precision": 64,
"scale": 127,
"type": "bytes"
}
},
{ "name": "ORDER_DATE",
"type": {
"connect.name": "org.apache.kafka.connect.data.Timestamp",
"connect.version": 1,
"logicalType": "timestamp-millis",
"type": "long"
}
},
{ "name": "SHIPPED_DATE",
"type": {
"connect.name": "org.apache.kafka.connect.data.Timestamp",
"connect.version": 1,
"logicalType": "timestamp-millis",
"type": "long"
}
},
{ "default": null,
"name": "STATUS",
"type": [ "null", "string" ]
},
{ "default": null,
"name": "CUSTOMER_NUMBER",
"type": [ "null",
{ "connect.name": "org.apache.kafka.connect.data.Decimal",
"connect.parameters": {"scale": "127"},
"connect.version": 1,
"logicalType": "decimal",
"precision": 64,
"scale": 127,
"type": "bytes"
} ]
},
... omitted
{ "default": null,
"name": "username",
"type": [ "null", "string" ]
} ],
"name": "ConnectDefault",
"namespace": "io.confluent.connect.avro",
"type": "record"
}
In this scenario, the resulting values for ORDER_NUMBER or CUSTOMER_NUMBER are unreadable, as shown below:
A\u0000\u000b\u001b8¸®æ«Îò,Rt]!\u0013_\u0018aVKæ,«1\u0010êo\u0017\u000bKðÀ\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
This is because the connector attempts to preserve accuracy (not lose any decimals) when precision and scale are not provided. As a workaround, you can set "numeric.mapping: "best_fit_or_double" or "numeric.mapping: best_fit_or_string", or use ksqlDB to create a new stream with explicit data types (based on a Schema Registry schema). For example:
CREATE STREAM ORDERS_RAW (
ORDER_NUMBER DECIMAL(9,2),
ORDER_DATE TIMESTAMP,
SHIPPED_DATE TIMESTAMP,
STATUS VARCHAR,
CUSTOMER_NUMBER DECIMAL(9,2) )
WITH (
KAFKA_TOPIC='ORCL.ADMIN.MARIPOSA_ORDERS',
VALUE_FORMAT='AVRO'
);
When you check the stream using SELECT * FROM ORDERS_RAW EMIT CHANGES, you will see readable values for ORDER_NUMBER and CUSTOMER_NUMBER as shown in the following example.
{
"ORDER_NUMBER": 5361,
"ORDER_DATE": "2020-08-06T03:41:58.000",
"SHIPPED_DATE": "2020-08-11T03:41:58.000",
"STATUS": "Not shipped yet",
"CUSTOMER_NUMBER": 9076
}
No BLOBs, CLOBs, or NCLOBs in my table-specific topics
Since BLOBs, CLOBs, and NCLOBs are very large objects (LOBs), the connector stores these objects in separate Kafka topics. If "lob.topic.name.template" is empty, the connector ignores BLOBs, CLOBs, and NCLOBs. You can use the following example property to specify where the connector stores these large objects:
"lob.topic.name.template":"${databaseName}.${schemaName}.${tableName}.${columnName}"
Why do my table-specific topics show no new records?
When you check the log, you may see the following error:
[2020-12-08 23:32:20,714] ERROR Exception in RecordQueue thread (io.confluent.connect.oracle.cdc.util.RecordQueue)
org.apache.kafka.connect.errors.ConnectException: Failed to subscribe to the redo log topic 'redo-log-topic' even after waiting PT1M. Verify that this redo log topic exists in the brokers at broker:9092, and that the redo log reading task is able to produce to that topic.
at io.confluent.connect.oracle.cdc.ChangeEventGenerator.subscribeToRedoLogTopic(ChangeEventGenerator.java:266)
at io.confluent.connect.oracle.cdc.ChangeEventGenerator.execute(ChangeEventGenerator.java:221)
at io.confluent.connect.oracle.cdc.util.RecordQueue.lambda$createLoggingSupplier$1(RecordQueue.java:468)
at java.base/java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1700)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.base/java.lang.Thread.run(Thread.java:834)
[2020-12-08 23:33:14,750] INFO WorkerSourceTask{id=cdc-oracle-source-pdb-0} Committing offsets (org.apache.kafka.connect.runtime.WorkerSourceTask)
[2020-12-08 23:33:14,751] INFO WorkerSourceTask{id=cdc-oracle-source-pdb-0} flushing 0 outstanding messages for offset commit (org.apache.kafka.connect.runtime.WorkerSourceTask)
The redo.log.startup.polling.limit.ms property defaults to 300000 milliseconds (5 minutes). Connect tasks will wait for five minutes until a redo-log-topic is created. To resolve this issue, you can increase redo.log.startup.polling.limit.ms.
If there is no redo log topic, you can create it. Before you run the connector, use the following command to create the topic. Make sure the topic name matches the value you use for the "redo.log.topic.name" configuration property.
bin/kafka-topics --create --topic <redo-log-topic-name> \
--bootstrap-server broker:9092 --replication-factor 1 \
--partitions 1 --config cleanup.policy=delete \
--config retention.ms=120960000
Why are my topics empty?
Topics may be empty for a number of reasons. You must ensure the following:
You can access the database from where you run the connector.
The database user has privilege to select from the tables.
The table has at least one row.
The
table.inclusion.regexconfiguration property matches the fully qualified table name (for example,dbo.Users) and that the regular expression in thetable.exclusion.regexconfiguration property does not match the fully qualified table name.If
start.fromis set to a particular SCN, ensure the rows in the database have changed since that SCN.If
start.from=snapshot(the default), ensure the rows in the database have changed since the snapshot for the table was created.The
redo.log.row.fetch.sizeproperty defaults to10. If you’ve changed fewer than the number of rows specified, it’s possible that the connector is waiting for more changes to appear before sending the latest batch of records.
Why don’t I see change events in my topics?
Note
If the redo log topic updates are not propagated to the table topic and security is enabled on the Kafka cluster, you must configure redo.log.consumer.* accordingly.
If the topic has at least one record produced by the connector that is currently running, make sure that the database rows have changed on the corresponding table since the initial snapshot for the table was taken.
Ensure the table.inclusion.regex configuration property matches the fully qualified table name (for example, dbo.Users) and the regular expression in the table.exclusion.regex configuration property does not match the fully qualified table name.
When Supplemental Log is turned on for a database or multiple tables, it might take time for a connector to catch up on reading a redo log and to find relevant records. Check the current SCN in the database with SELECT CURRENT_SCN FROM V$DATABASE and compare it with the last SCN the connector processed or saw in a connect-offsets topic (the topic name could be different depending on a setup) or in TRACE logs. If there is a huge gap, consider increasing redo.log.row.fetch.size to 100, 1000, or even a larger number.
curl -s -X PUT -H "Content-Type:application/json" \
http://localhost:8083/admin/loggers/io.confluent.connect.oracle \
-d '{"level": "TRACE"}' \
| jq '.'
Why is there no throughput when the connector is running with no exceptions?
One common reason is that automatic topic creation is off, and the redo log topic or change event topics were not manually created. Or, there are typos in the topic names.
Change events appear in the redo log topic but not in table-specific topics
When the redo.log.consumer.bootstrap.server is set improperly, the connector will at first appear to work with table-specific topics being populated with an initial snapshot. However, subsequent changes to the table (for example, the insertion of new rows) will not appear in table-specific topics, but in the redo log topic, and logs will not readily show that there is an issue with the configuration.
Resolution: Ensure the redo.log.consumer.bootstrap.servers configuration property is set properly.
Why do I see duplicate redo log topic consumers for the same table?
You may see duplicate redo log topic consumers for the same table if the assignment of database tables to tasks is changed. This reassignment may occur when:
New tables are added to the connector using the
table.inclusion.regexortable.exclusion.regexconfiguration parameter.The
tasks.maxconfiguration property is updated.An internal redistribution of the tasks occurs.
This can cause creation of duplicate consumers for the same table which will reprocess the redo log events and create duplicate records in the change event topics.
Errors and exceptions
The following sections provide troubleshooting for several errors and exceptions.
The connector fails with “Redo Log consumer failed to subscribe…”
This may occur if the connector can’t read from the redo log topic due to security being configured on the Kafka cluster.
When security is enabled on a Kafka cluster, you must configure redo.log.consumer.* accordingly. For example, in the case of an SSL-secured (non-Confluent Cloud) cluster, you can configure the following properties:
"redo.log.consumer.security.protocol": "SSL",
"redo.log.consumer.ssl.truststore.location": "<filepath>",
"redo.log.consumer.ssl.truststore.password": "<password>",
"redo.log.consumer.ssl.keystore.location": "<filepath>",
"redo.log.consumer.ssl.keystore.password": "<password>",
"redo.log.consumer.ssl.key.password": "<password>”,
"redo.log.consumer.ssl.truststore.type":"<type>",
"redo.log.consumer.ssl.keystore.type": "<type>",
If configuring the connector to send data to a Confluent Cloud cluster, the following properties can be configured:
"redo.log.consumer.bootstrap.servers: "XXXXXXXX",
"redo.log.consumer.security.protocol: "SASL_SSL",
"redo.log.consumer.ssl.endpoint.identification.algorithm: "https",
"redo.log.consumer.sasl.mechanism: "PLAIN",
"redo.log.consumer.sasl.jaas.config: "org.apache.kafka.common.security.plain.PlainLoginModule required username='XXXXXXXXX' password='XXXXXXXXXX';"
ORA-65024: Pluggable database <pdb-name> is not open
You may see this message if you use the connector against a pluggable database (PDB). If so, use the following command to check your PDB’s status:
SELECT inst_id, name, open_mode, restricted, open_time
FROM gv$pdbs
ORDER BY name;
Also, ensure your pluggable database is opened in READ WRITE mode.
“500 Request timed” returned by REST API when creating connector
During validation of the connector, in some environments, it takes more than 90 seconds (REST API timeout) to validate all tables accessible to the user and verifying supplemental logging settings.
REST API would return:
{
"error_code": 500,
"message": "Request timed out"
}
Setting the following connector configuration is generally helps to solve the issue:
"oracle.connection.defaultRowPrefetch": "5000"
For versions 2.3.0 and later of the Confluent Platform Oracle CDC connector, setting the following configuration should help to solve the issue:
"oracle.validation.result.fetch.size": "5000"
ORA-01031: insufficient privileges
First, make sure you have set up the prerequisite privileges. For details, see Configure database user privileges.
Second, check whether supplemental logging is turned on for the databases or tables you want. You can enable supplemental logging for all tables or specific tables.
Supplemental logging for all tables
Enter the following command to turn on supplemental logging for all tables and columns.
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
After enabling supplemental logging, enter the following:
select supplemental_log_data_min, supplemental_log_data_pk, supplemental_log_data_all from v$database
You should see that
SUPPLEMENTAL_LOG_DATA_ALLisYESas shown in the following example screen.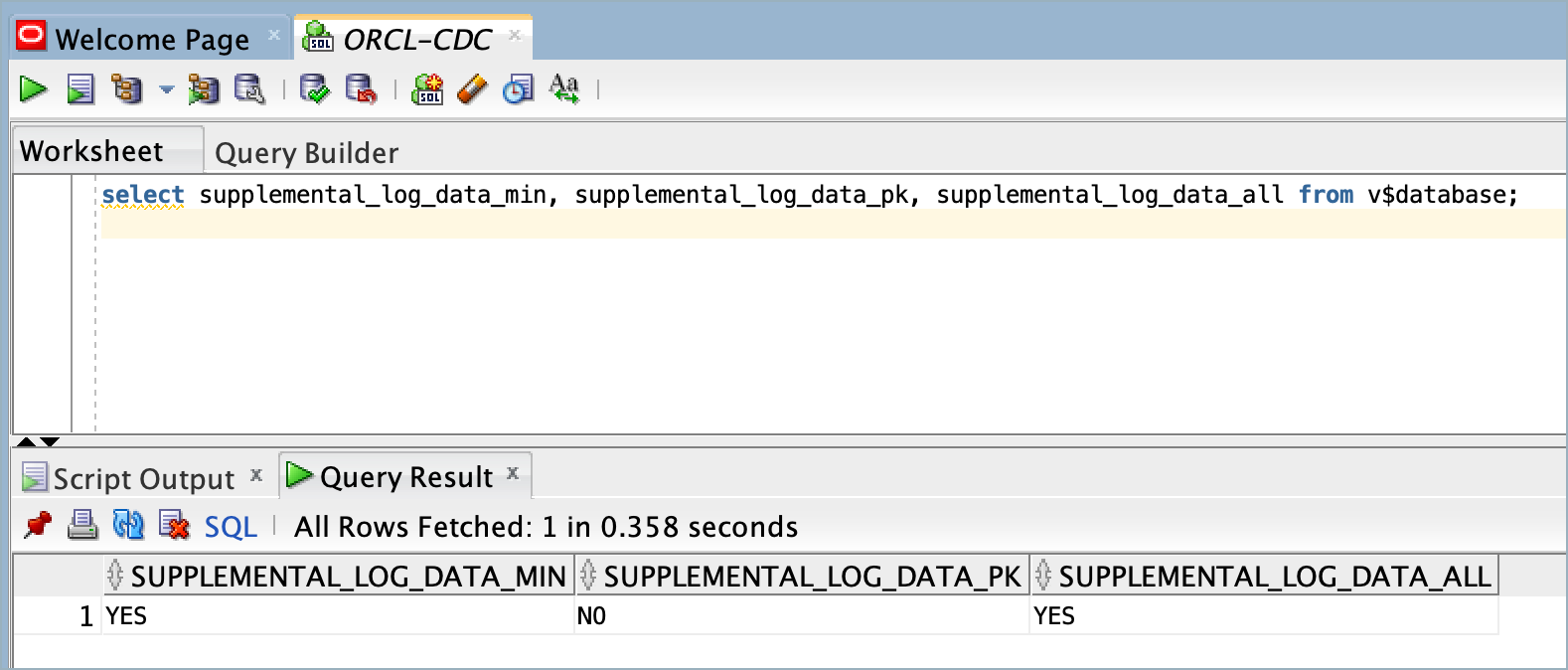
Supplemental logging for specific tables
Enter the following command to turn on supplemental logging for specific tables.
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS; ALTER TABLE <schema-name>.<table-name> ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
After enabling supplemental logging, enter the following:
select supplemental_log_data_min, supplemental_log_data_pk, supplemental_log_data_all from v$database
You should see that
SUPPLEMENTAL_LOG_DATA_ALLisNOas shown in the following example screen.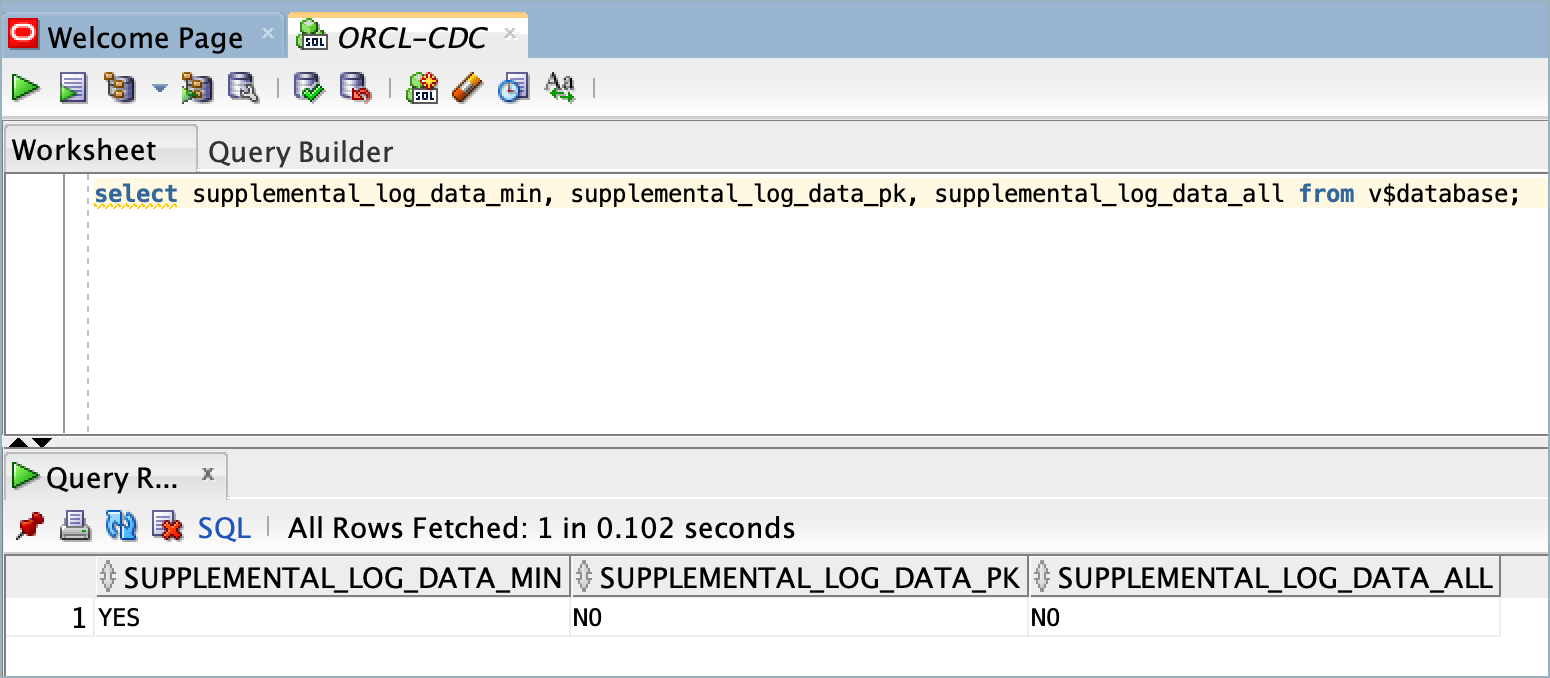
ORA-01291: missing log file
You may notice that the connector stops producing records after some time. This may occur with earlier versions of the connector due to low prefetch size relative to database activity. If the redo.log.row.fetch.size is set to a value much lower than the expected amount of data received in redo logs, the connector fails to catch up to the current SCN and as a result is delayed by hours or even days.
Resolution: Update to the latest version of the connector. This issue is largely resolved by performing filtering of the redo log in the database query. Additionally, you should set redo.log.row.fetch.size to a much lower value and account for only the data expected in tables monitored by the connector.
Note
Versions 2.3.0 and later of the Confluent Platform Oracle CDC connector, include a heartbeat feature which enables|cp| users to workaround this error.
For more details, see the Confluent Support Knowledge Based article
ORA-06550: identifier ‘DBMS_LOGMNR’ must be declared
You may see this error when running an Oracle CDC source connector against an Amazon RDS for Oracle. Run the following command:
exec rdsadmin.rdsadmin_util.grant_sys_object('DBMS_LOGMNR', 'MYUSER', 'EXECUTE');
This record has failed the validation on broker and hence will be rejected
If you have tables without primary keys, you might see the following error message for table-specific topics. This is because the connector tried to write records without primary keys to a compaction topic (i.e., property: "topic.creation.default.cleanup.policy":"compact").
[2022-01-25 15:23:44,497] ERROR
WorkerSourceTask{id=OracleCDC_Mariposa_No_PK4-1} failed to send record to
ORCL.ADMIN.ORDERS: (org.apache.kafka.connect.runtime.WorkerSourceTask:370)
org.apache.kafka.common.InvalidRecordException: This record has failed the
validation on broker and hence will be rejected.
You can set "topic.creation.default.cleanup.policy" to “delete” or you can define another topic creation rule. For example:
"topic.creation.groups":"redo",
"topic.creation.redo.include":"oracle-redo-log-topic",
"topic.creation.redo.replication.factor":3,
"topic.creation.redo.partitions":1,
"topic.creation.redo.cleanup.policy":"delete",
"topic.creation.redo.retention.ms":1209600000,
"topic.creation.default.replication.factor":3,
"topic.creation.default.partitions":5,
"topic.creation.default.cleanup.policy":"compact",
“topic.creation.groups”:”nokey”,
"topic.creation.nokey.include":"ORCL.ADMIN.ORDERS",
"topic.creation.nokey.replication.factor":3,
"topic.creation.nokey.cleanup.policy":"delete",
Inclusion pattern matches no tables…
When a connector can’t find tables that match the regular expression entries in the table.inclusion.regex property, the following message will display:
Inclusion pattern matches no tables...
This connector would not output any records…
If no table matches the inclusion and exclusion pattern specified in table.inclusion.regex and table.exclusion.regex respectively, the following message will display:
"This connector would not output any records, since no tables matched the
inclusion pattern '...' or were excluded by the pattern '...', or the redo
log topic name was not specified"?
Resolution: Check the inclusion pattern and the exclusion pattern specified in table.inclusion.regex and table.exclusion.regex configuration properties.
Note
You must use a fully-qualified table name to match tables. A fully-qualified table name consists of three parts:
database name (either SID or PDB name)
schema name
table name
For example, if you want to match tables in a pluggable database (PDB) named MY_PDB1 and the schema is SYS, the inclusion is MY_PDB1[.]SYS[.].*.
Invalid value xxxx.YYYY.ERR$_TMP_PRS…
If the table.topic.name.template configuration property is set to a value that contains unescaped $ characters, the connector will display the following message:
"Invalid value xxxx.YYYY.ERR$_TMP_PRS for configuration
table.topic.name.template: must match pattern … Invalid value Must contain
only valid variable substitutions or characters escaped with `\\`: Invalid
value xxxx.YYYY.ERR$_TMP_PRS"?
Resolution: Check the value set on the configuration shown in the error message. Be sure that it does not contain unescaped $ characters. The $ character can be escaped with a backslash \ to make the following valid configuration value: xxxx.YYYY.ERR\$_TMP_PRS.
oracle.simplefan.impl.FanManager configure SEVERE:…
When trying to connect to an Oracle Cloud Autonomous Database, if the JDBC driver is trying to connect to the ONE service on the database when Oracle RAC Fast Application Notification (FAN) events are not enabled on the database, the connector will display the following message:
oracle.simplefan.impl.FanManager configure SEVERE: attempt
to configure ONS in FanManager failed with oracle.ons.NoServersAvailable:
Subscription time out
Resolution: Ensure the following configuration property is set to false:
oracle.fan.events.enable=false
Error caused by records with a decimal number
When you have a record with a decimal number, you might see the following error message:
[2021-09-17 09:44:38,697] ERROR Exception in RecordQueue thread (io.confluent.connect.oracle.cdc.util.RecordQueue:467)
org.apache.kafka.connect.errors.ConnectException: Exception converting redo to change event. SQL: 'insert into "C##MYUSER"."CUSTOMERS"("ID","FIRST_NAME","LAST_NAME","EMAIL","GENDER","CLUB_STATUS","COMMENTS","AMOUNT","CREATE_TS","UPDATE_TS") values ('6','Rica','Blaisdell','rblaisdell0@rambler.ru','Female','bronze','Universal optimal hierarchy','12,45',TO_TIMESTAMP('2021-09-17 09:44:37.428'),NULL);' INFO: null
at io.confluent.connect.oracle.cdc.record.OracleChangeEventSourceRecordConverter.convert(OracleChangeEventSourceRecordConverter.java:320)
at io.confluent.connect.oracle.cdc.ChangeEventGenerator.doGenerateChangeEvent(ChangeEventGenerator.java:431)
at io.confluent.connect.oracle.cdc.ChangeEventGenerator.execute(ChangeEventGenerator.java:212)
at io.confluent.connect.oracle.cdc.util.RecordQueue.lambda$createLoggingSupplier$0(RecordQueue.java:465)
at java.base/java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1700)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.base/java.lang.Thread.run(Thread.java:834)
Caused by: org.apache.kafka.connect.errors.ConnectException: Could not convert field AMOUNT value 12,45 to type FLOAT64
The error occurs when you try to use a comma (,) as a decimal separator–the connector expects a period (.). To address the issue, you must specify a language and location in KAFKA_OPTS as shown in the following example:
export KAFKA_OPTS="-Duser.language=en -Duser.country=US"
After you set KAFKA_OPTS, start Confluent Platform. If it is already running, restart it. You should see a decimal number with a period (.) as a decimal separator.
Example from a redo log topic
{"SCN":{"long":381755},"START_SCN":{"long":381755},"COMMIT_SCN":{"long":381756},"TIMESTAMP":{"long":1631926545000},"START_TIMESTAMP":{"long":1631926545000},"COMMIT_TIMESTAMP":{"long":1631926545000},"XIDUSN":{"long":8},"XIDSLT":{"long":14},"XIDSQN":{"long":394},"XID":{"bytes":"\b\u0000\u000E\u0000\u0001\u0000\u0000"},"PXIDUSN":{"long":8},"PXIDSLT":{"long":14},"PXIDSQN":{"long":394},"PXID":{"bytes":"\b\u0000\u000E\u0000\u0001\u0000\u0000"},"TX_NAME":null,"OPERATION":{"string":"INSERT"},"OPERATION_CODE":{"int":1},"ROLLBACK":{"boolean":false},"SEG_OWNER":{"string":"C##MYUSER"},"SEG_NAME":{"string":"CUSTOMERS"},"TABLE_NAME":{"string":"CUSTOMERS"},"SEG_TYPE":{"int":2},"SEG_TYPE_NAME":{"string":"TABLE"},"TABLE_SPACE":{"string":"USERS"},"ROW_ID":{"string":"AAAE5KAAEAAAAFrAAF"},"USERNAME":{"string":"C##MYUSER"},"OS_USERNAME":{"string":"UNKNOWN"},"MACHINE_NAME":{"string":"UNKNOWN"},"AUDIT_SESSIONID":{"long":110020},"SESSION_NUM":{"long":139},"SERIAL_NUM":{"long":7},"SESSION_INFO":{"string":"UNKNOWN"},"THREAD_NUM":{"long":1},"SEQUENCE_NUM":{"long":2},"RBASQN":{"long":3},"RBABLK":{"long":5994},"RBABYTE":{"long":16},"UBAFIL":{"long":3},"UBABLK":{"long":12583166},"UBAREC":{"long":41},"UBASQN":{"long":101},"ABS_FILE_NUM":{"long":4},"REL_FILE_NUM":{"long":4},"DATA_BLK_NUM":{"long":363},"DATA_OBJ_NUM":{"long":20042},"DATA_OBJV_NUM":{"long":1},"DATA_OBJD_NUM":{"long":20042},"SQL_REDO":{"string":"insert into \"C##MYUSER\".\"CUSTOMERS\"(\"ID\",\"FIRST_NAME\",\"LAST_NAME\",\"EMAIL\",\"GENDER\",\"CLUB_STATUS\",\"COMMENTS\",\"AMOUNT\",\"CREATE_TS\",\"UPDATE_TS\") values ('6','Rica','Blaisdell','rblaisdell0@rambler.ru','Female','bronze','Universal optimal hierarchy','12.45',TO_TIMESTAMP('2021-09-17 10:55:44.638'),NULL);"},"SQL_UNDO":{"string":"delete from \"C##MYUSER\".\"CUSTOMERS\" where \"ID\" = '6' and \"FIRST_NAME\" = 'Rica' and \"LAST_NAME\" = 'Blaisdell' and \"EMAIL\" = 'rblaisdell0@rambler.ru' and \"GENDER\" = 'Female' and \"CLUB_STATUS\" = 'bronze' and \"COMMENTS\" = 'Universal optimal hierarchy' and \"AMOUNT\" = '12.45' and \"CREATE_TS\" = TO_TIMESTAMP('2021-09-17 10:55:44.638') and \"UPDATE_TS\" IS NULL and ROWID = 'AAAE5KAAEAAAAFrAAF';"},"RS_ID":{"string":" 0x000003.0000176a.0010 "},"SSN":{"long":5},"CSF":{"boolean":false},"INFO":null,"STATUS":{"int":0},"REDO_VALUE":{"long":48},"UNDO_VALUE":{"long":49},"SAFE_RESUME_SCN":{"long":0},"CSCN":{"long":381756},"OBJECT_ID":null,"EDITION_NAME":null,"CLIENT_ID":null,"SRC_CON_NAME":null,"SRC_CON_ID":null,"SRC_CON_UID":null,"SRC_CON_DBID":null,"SRC_CON_GUID":null,"CON_ID":null}
Example from a table-specific topic
{"ID":6,"FIRST_NAME":{"string":"Rica"},"LAST_NAME":{"string":"Blaisdell"},"EMAIL":{"string":"rblaisdell0@rambler.ru"},"GENDER":{"string":"Female"},"CLUB_STATUS":{"string":"bronze"},"COMMENTS":{"string":"Universal optimal hierarchy"},"AMOUNT":{"double":12.45},"CREATE_TS":{"long":1631901344638},"UPDATE_TS":null,"table":{"string":"xe.C##MYUSER.CUSTOMERS"},"scn":{"string":"381755"},"op_type":{"string":"I"},"op_ts":{"string":"1631926545000"},"current_ts":{"string":"1631901348993"},"row_id":{"string":"AAAE5KAAEAAAAFrAAF"},"username":{"string":"C##MYUSER"}}
Table schema not being registered when using ENABLE NOVALIDATE
If you create a table with ENABLE NOVALIDATE to validate existing data, schemas may differ between the initial load and online updates. In addition, primary keys may not be set immediately. For example, if you create a table using the following declarations:
CREATE TABLE CUSTOMERS (
"TATXA1" NCHAR(10),
"TAITM" NUMBER,
"TAEFDJ" NUMBER(6,0),
FIRST_NAME VARCHAR(50),
LAST_NAME VARCHAR(50),
EMAIL VARCHAR(50),
GENDER VARCHAR(50),
CLUB_STATUS VARCHAR(20),
COMMENTS VARCHAR(90),
CREATE_TS TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
UPDATE_TS TIMESTAMP
);
CREATE UNIQUE INDEX "CUSTOMERS_0" ON CUSTOMERS ("TATXA1", "TAITM", "TAEFDJ");
ALTER TABLE CUSTOMERS ADD CONSTRAINT "CUSTOMERS_PK" PRIMARY KEY ("TATXA1", "TAITM", "TAEFDJ") USING INDEX "CUSTOMERS_0" ENABLE NOVALIDATE;
After executing DESC CUSTOMERS;, you should see output similar to the following:
Name Null? Type
----------- ----- ------------
TATXA1 NCHAR(10)
TAITM NUMBER
TAEFDJ NUMBER(6)
FIRST_NAME VARCHAR2(50)
LAST_NAME VARCHAR2(50)
EMAIL VARCHAR2(50)
GENDER VARCHAR2(50)
CLUB_STATUS VARCHAR2(20)
COMMENTS VARCHAR2(90)
CREATE_TS TIMESTAMP(6)
UPDATE_TS TIMESTAMP(6)
In an ALTER TABLE statement, ENABLE NOVALIDATE resumes constraint checking on disabled constraints without first validating all data in the table. You can try one of the following workarounds:
Workaround 1: Set the schema compatibility to
NONEand restart the connector. Once the schema evolves with primary keys, change the schema compatibility back to BACKWARD.curl -X POST http://localhost:8083/connectors/cdc-oracle-source-rac/restart\?includeTasks\=true\&onlyFailed\=false -H "Content-Type: application/json" | jq .
Workaround 2: Create a primary key without
ENABLE NOVALIDATE, or drop the problematic constraint and add a new one withoutENABLE NOVALIDATERegex pattern issues. For example:ALTER TABLE CUSTOMERS drop constraint "CUSTOMERS_PK"; ALTER TABLE CUSTOMERS ADD CONSTRAINT "CUSTOMERS_PK" PRIMARY KEY ("TATXA1", "TAITM", "TAEFDJ") USING INDEX "CUSTOMERS_0";After executing
DESC CUSTOMERS;, you should see the following output:Name Null? Type ----------- -------- ------------ TATXA1 NOT NULL NCHAR(10) TAITM NOT NULL NUMBER TAEFDJ NOT NULL NUMBER(6) FIRST_NAME VARCHAR2(50) LAST_NAME VARCHAR2(50) EMAIL VARCHAR2(50) GENDER VARCHAR2(50) CLUB_STATUS VARCHAR2(20) COMMENTS VARCHAR2(90) CREATE_TS TIMESTAMP(6) UPDATE_TS TIMESTAMP(6)
Skipping result containing unsupported column type
The connector will display this error message if you select a table or column name that has more than 30 characters for mining. LogMiner doesn’t support table and column names that exceed 30 characters.
Redo log consumer failed to subscribe to redo log topic
The connector will display this error message if the redo log consumer created by the connector is unable to subscribe to the redo log topic. As a result, no data will be populated in the table change event topics. To resolve this error, you must verify your redo.log.consumer.* properties. The following may be potential causes of the error:
Incorrect value for
redo.log.consumer.bootstrap.server.Incorrect or missing
redo.log.consumer.*security configurations in case of a secured Kafka cluster.
Regex pattern issues
The following sections provide regex pattern guidance.
Amazon RDS instances for Oracle
Scenario: You have tables named CONFLUENT_CUSTOMERS, CONFLUENT_ORDERS, CONFLUENT_PRODUCTS, DEMO, and TESTING under the schema C##MYUSER, tables EMPLOYEES and DEPARTMENTS under the schema HR, tables CUSTOMERS and ORDERS under the schema SALES.
To capture changes to tables starting with CONFLUENT, use the following regex pattern:
"oracle.sid":"ORCL",
"oracle.username": "C##MYUSER",
"table.inclusion.regex":"ORCL[.]C##MYUSER[.]CONFLUENT.*",
To capture changes to starting with DEMO and TESTING, use the following regex pattern:
"oracle.sid":"ORCL",
"oracle.username": "C##MYUSER",
"table.inclusion.regex":"ORCL[.]C##MYUSER[.](DEMO|TESTING)",
To capture changes to tables starting with CONFLUENT, DEMO and TESTING, use the following regex pattern:
"oracle.sid":"ORCL",
"oracle.username": "C##MYUSER",
"table.inclusion.regex":"ORCL[.]C##MYUSER[.](CONFLUENT.*|DEMO|TESTING)",
To capture changes in the schema HR for tables EMPLOYEES and DEPARTMENTS and the schema SALES for tables CUSTOMERS and ORDERS, use the following regex pattern:
"oracle.sid":"ORCL",
"oracle.username": "C##MYUSER",
"table.inclusion.regex":"ORCL[.](HR[.](EMPLOYEES|DEPARTMENTS)|SALES[.](CUSTOMERS|ORDERS))",
Oracle Non-container and container Databases (CDBs)
Scenario: You have tables named CONFLUENT_CUSTOMERS, CONFLUENT_ORDERS, CONFLUENT_PRODUCTS, DEMO, and TESTING under the schema C##MYUSER, tables EMPLOYEES and DEPARTMENTS under the schema HR, tables CUSTOMERS and ORDERS under the schema SALES.
To capture changes to tables starting with CONFLUENT, use the following regex pattern:
"oracle.sid":"ORCLCDB",
"oracle.username": "C##MYUSER",
"table.inclusion.regex":"ORCLCDB[.]C##MYUSER[.]CONFLUENT.*",
To capture changes to tables starting with DEMO and TESTING, use the following regex pattern:
"oracle.sid":"ORCLCDB",
"oracle.username": "C##MYUSER",
"table.inclusion.regex":"ORCLCDB[.]C##MYUSER[.](DEMO|TESTING)",
To capture changes to tables starting with CONFLUENT, and DEMO and TESTING tables, use the following regex pattern:
"oracle.sid":"ORCLCDB",
"oracle.username": "C##MYUSER",
"table.inclusion.regex":"ORCLCDB[.]C##MYUSER[.](CONFLUENT.*|DEMO|TESTING)",
To capture changes in schema HR for tables EMPLOYEES and DEPARTMENTS and schema SALES for tables CUSTOMERS and ORDERS use the following regex pattern:
"oracle.sid":"ORCLCDB",
"oracle.username": "C##MYUSER",
"table.inclusion.regex":"ORCLCDB[.](HR[.](EMPLOYEES|DEPARTMENTS)|SALES[.](CUSTOMERS|ORDERS))",
Oracle Pluggable Databases (PDBs)
Scenario: You have tables named CONFLUENT_CUSTOMERS, CONFLUENT_ORDERS, CONFLUENT_PRODUCTS, DEMO, and TESTING under the schema C##MYUSER, tables EMPLOYEES and DEPARTMENTS under the schema HR, tables CUSTOMERS and ORDERS under the schema SALES.
To capture changes to tables starting with CONFLUENT, use the following regex pattern:
"oracle.sid":"ORCLCDB",
"oracle.pdb.name": "ORCLPDB1",
"oracle.username": "C##MYUSER",
"table.inclusion.regex":"ORCLPDB1[.]C##MYUSER[.]CONFLUENT.*",
To capture changes to tables starting with DEMO and TESTING, use the following regex pattern:
"oracle.sid":"ORCLCDB",
"oracle.pdb.name": "ORCLPDB1",
"oracle.username": "C##MYUSER",
"table.inclusion.regex":"ORCLPDB1[.]C##MYUSER[.](DEMO|TESTING)",
To capture changes to tables starting with CONFLUENT, and DEMO and TESTING, use the following regex pattern:
"oracle.sid":"ORCLCDB",
"oracle.pdb.name": "ORCLPDB1",
"oracle.username": "C##MYUSER",
"table.inclusion.regex":"ORCLPDB1[.]C##MYUSER[.](CONFLUENT.*|DEMO|TESTING)",
To capture changes in the schema HR for tables EMPLOYEES and DEPARTMENTS and the schema SALES for tables CUSTOMERS and ORDERS, use the following regex pattern:
"oracle.sid":"ORCLCDB",
"oracle.username": "C##MYUSER",
"table.inclusion.regex":"ORCLPDB1[.](HR[.](EMPLOYEES|DEPARTMENTS)|SALES[.](CUSTOMERS|ORDERS))",