Important
You are viewing documentation for an older version of Confluent Platform. For the latest, click here.
Schema Registry¶
Schema Registry provides a serving layer for your metadata. It provides a RESTful interface for storing and retrieving Avro schemas. It stores a versioned history of all schemas, provides multiple compatibility settings and allows evolution of schemas according to the configured compatibility settings and expanded Avro support. It provides serializers that plug into Apache Kafka® clients that handle schema storage and retrieval for Kafka messages that are sent in the Avro format.
Schema Registry is a distributed storage layer for Avro Schemas which uses Kafka as its underlying storage mechanism. Some key design decisions:
- Assigns globally unique ID to each registered schema. Allocated IDs are guaranteed to be monotonically increasing but not necessarily consecutive.
- Kafka provides the durable backend, and functions as a write-ahead changelog for the state of Schema Registry and the schemas it contains.
- Schema Registry is designed to be distributed, with single-master architecture, and ZooKeeper/Kafka coordinates master election (based on the configuration).
Tip
To see a working example of Schema Registry, check out Confluent Platform demo. The demo shows you how to deploy a Kafka streaming ETL, including Schema Registry, using KSQL for stream processing.
Avro Background¶
When sending data over the network or storing it in a file, we need a way to encode the data into bytes. The area of data serialization has a long history, but has evolved quite a bit over the last few years. People started with programming language specific serialization such as Java serialization, which makes consuming the data in other languages inconvenient. People then moved to language agnostic formats such as JSON.
However, formats like JSON lack a strictly defined format, which has two significant drawbacks:
- Data consumers may not understand data producers: The lack of structure makes consuming data in these formats more challenging because fields can be arbitrarily added or removed, and data can even be corrupted. This drawback becomes more severe the more applications or teams across an organization begin consuming a data feed: if an upstream team can make arbitrary changes to the data format at their discretion, then it becomes very difficult to ensure that all downstream consumers will (continue to) be able to interpret the data. What’s missing is a “contract” (cf. schema below) for data between the producers and the consumers, similar to the contract of an API.
- Overhead and verbosity: They are verbose because field names and type information have to be explicitly represented in the serialized format, despite the fact that are identical across all messages.
A few cross-language serialization libraries have emerged that require the data structure to be formally defined by some sort of schemas. These libraries include Avro, Thrift, and Protocol Buffers. The advantage of having a schema is that it clearly specifies the structure, the type and the meaning (through documentation) of the data. With a schema, data can also be encoded more efficiently. In particular, we recommend Avro which is supported in Confluent Platform.
An Avro schema defines the data structure in a JSON format.
The following is an example Avro schema that specifies a user record with two fields: name and favorite_number
of type string and int, respectively.
{"namespace": "example.avro",
"type": "record",
"name": "user",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": "int"}
]
}
You can then use this Avro schema, for example, to serialize a Java object (POJO) into bytes, and deserialize these bytes back into the Java object.
One of the interesting things about Avro is that it not only requires a schema during data serialization, but also during data deserialization. Because the schema is provided at decoding time, metadata such as the field names don’t have to be explicitly encoded in the data. This makes the binary encoding of Avro data very compact.
Schema ID Allocation¶
Schema ID allocation always happen in the master node and they ensure that the Schema IDs are monotonically increasing.
If you are using Kafka master election, the Schema ID is always based off the last ID that was
written to Kafka store. During a master re-election, batch allocation happens only after the new
master has caught up with all the records in the store <kafkastore.topic>.
If you are using ZooKeeper master election, /<schema.registry.zk.namespace>/schema_id_counter
path stores the upper bound on the current ID batch, and new batch allocation is triggered by both master election and exhaustion of the current batch. This batch allocation helps guard against potential zombie-master scenarios, (for example, if the previous master had a GC pause that lasted longer than the ZooKeeper timeout, triggering master reelection).
Kafka Backend¶
Kafka is used as Schema Registry storage backend.
The special Kafka topic <kafkastore.topic> (default _schemas), with a single partition, is used as a highly available write ahead log.
All schemas, subject/version and ID metadata, and compatibility settings are appended as messages to this log.
A Schema Registry instance therefore both produces and consumes messages under the _schemas topic.
It produces messages to the log when, for example, new schemas are registered under a subject, or when updates to compatibility settings are registered.
Schema Registry consumes from the _schemas log in a background thread, and updates its local caches on consumption of each new _schemas message to reflect the newly added schema or compatibility setting.
Updating local state from the Kafka log in this manner ensures durability, ordering, and easy recoverability.
Single Master Architecture¶
Schema Registry is designed to work as a distributed service using single master architecture. In this configuration, at most one Schema Registry instance is master at any given moment (ignoring pathological ‘zombie masters’). Only the master is capable of publishing writes to the underlying Kafka log, but all nodes are capable of directly serving read requests. Slave nodes serve registration requests indirectly by simply forwarding them to the current master, and returning the response supplied by the master. Prior to Schema Registry version 4.0, master election was always coordinated through ZooKeeper. Master election can now optionally happen via Kafka group protocol as well.
Note
Please make sure not to mix up the election modes amongst the nodes in same cluster. This will lead to multiple masters and issues with your operations.
Kafka Coordinator Master Election¶
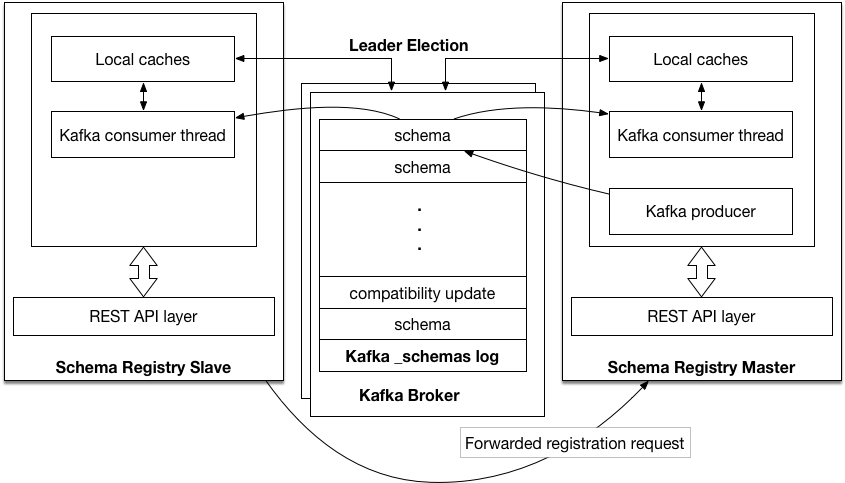
Kafka based Schema Registry
Kafka based master election is chosen when <kafkastore.connection.url> is not configured and
has the Kafka bootstrap brokers <kafkastore.bootstrap.servers> specified. The kafka group
protocol, chooses one amongst the master eligible nodes master.eligibility=true as the master. Kafka-based master
election can be used in cases where ZooKeeper is not available, for example for hosted or cloud
Kafka environments, or if access to ZooKeeper has been locked down.
ZooKeeper Master Election¶
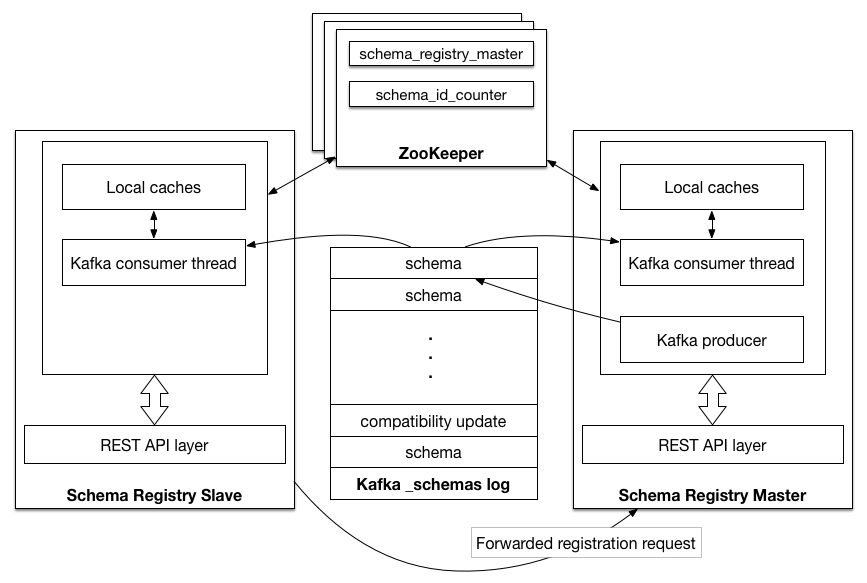
ZooKeeper based Schema Registry
ZooKeeper master election is chosen when ZooKeeper URL is specified in Schema Registry config
<kafkastore.connection.url>.
The current master is maintained as data in the ephemeral node on the /<schema.registry.zk.namespace>/schema_registry_master path in ZooKeeper. Schema Registry nodes listen to data change and deletion events on this path, and shutdown or failure of the master process triggers each node with master.eligibility=true to participate in a new round of election. Master election is a simple ‘first writer wins’ policy: the first node to successfully write its own data to /<schema.registry.zk.namespace>/schema_registry_master is the new master.
Schema Registry is also designed for multi-colo configuration. See Schema Registry Multi-DC Setup for more details.
High Availability for Single Master Setup¶
Many services in Confluent Platform are effectively stateless (they store state in Kafka and load it on demand at start-up) and can redirect requests automatically. You can treat these services as you would deploying any other stateless application and get high availability features effectively for free by deploying multiple instances. Each instance loads all of the Schema Registry state so any node can serve a READ, and all nodes know how to forward requests to the master for WRITEs.
A common pattern is to put the instances behind a single virtual IP or round
robin DNS such that you can use a single URL in the schema.registry.url
configuration but use the entire cluster of Schema Registry instances. This also makes it
easy to handle changes to the set of servers without having to reconfigure and
restart all of your applications. The same strategy applies to REST proxy or
Kafka Connect.
A simple setup with just a few nodes means Schema Registry can fail over easily with a simple multi-node deployment and single master election protocol.
Documentation¶
- Installing and Configuring Schema Registry
- Confluent Schema Registry Tutorial
- Schema Evolution and Compatibility
- Using Schema Registry
- Monitoring Schema Registry
- Schema Registry Multi-DC Setup
- Schema Registry Security Overview
- Schema Registry Security Plugin
- Schema Registry Developer Guide
- Schema Registry Serializer and Formatter
- Schema Deletion Guidelines
- Using Kafka Connect with Schema Registry
- Schema Registry Changelog