Important
You are viewing documentation for an older version of Confluent Platform. For the latest, click here.
Confluent Schema Registry Tutorial¶
Overview¶
This tutorial provides a step-by-step example to use Confluent Schema Registry. It walks through the steps to enable client applications to read and write Avro data with compatibility checks as schemas evolve.
Benefits¶
Kafka producers write data to Kafka topics and Kafka consumers read data from Kafka topics. There is an implicit “contract” that producers write data with a schema that can be read by consumers, even as producers and consumers evolve their schemas. Confluent Schema Registry helps ensure that this contract is met with compatibility checks.
It is useful to think about schemas as APIs. Applications depend on APIs and expect any changes made to APIs are still compatible and applications can still run. Similarly, streaming applications depend on schemas and expect any changes made to schemas are still compatible and they can still run. Schema evolution requires compatibility checks to ensure that the producer-consumer contract is not broken. This is where Confluent Schema Registry helps: it provides centralized schema management and compatibility checks as schemas evolve.
Target Audience¶
The target audience is a developer writing Kafka streaming applications who wants to build a robust application leveraging Avro data and Confluent Schema Registry. The principles in this tutorial apply to any Kafka client that interacts with Schema Registry.
This tutorial is not meant to cover the operational aspects of running the Schema Registry service. For production deployments of Confluent Schema Registry, refer to Running Schema Registry in Production.
Before You Begin¶
Prerequisites¶
Before proceeding with this tutorial
Verify that you have installed the following on your local machine:
- Java 1.8 to run Confluent Platform
- Maven to compile the client Java code
jqtool to nicely format the results from querying the Schema Registry REST endpoint
Use the Confluent Platform Quick Start to bring up Confluent Platform. With a single-line command, you can have a basic Kafka cluster with Confluent Schema Registry and other services running on your local machine.
$ confluent start This CLI is intended for development only, not for production https://docs.confluent.io/current/cli/index.html Starting zookeeper zookeeper is [UP] Starting kafka kafka is [UP] Starting schema-registry schema-registry is [UP] Starting kafka-rest kafka-rest is [UP] Starting connect connect is [UP] Starting ksql-server ksql-server is [UP] Starting control-center control-center is [UP]
Note
If you only want to start ZooKeeper, Kafka, and Schema Registry, type confluent start schema-registry
Clone the Confluent Platform examples repo from GitHub and work in the clients/avro/ subdirectory, which provides the sample code you will compile and run in this tutorial.
$ git clone https://github.com/confluentinc/examples.git
$ cd examples/clients/avro
$ git checkout 5.1.4-post
Terminology¶
First let us levelset on terminology: what is a topic versus a schema versus a subject.
A Kafka topic contains messages, and each message is a key-value pair. Either the message key or the message value, or both, can be serialized as Avro. A schema defines the structure of the Avro data format. The Kafka topic name can be independent of the schema name. Schema Registry defines a scope in which schemas can evolve, and that scope is the subject. The name of the subject depends on the configured subject name strategy, which by default is set to derive subject name from topic name.
As a practical example, let’s say a retail business is streaming transactions in a Kafka topic called transactions. A producer is writing data with a schema Payment to that Kafka topic transactions. If the producer is serializing the message value as Avro, then Schema Registry has a subject called transactions-value. If the producer is also serializing the message key as Avro, Schema Registry would have a subject called transactions-key, but for simplicity, in this tutorial consider only the message value. That Schema Registry subject transactions-value has at least one schema called Payment. The subject transactions-value defines the scope in which schemas for that subject can evolve and Schema Registry does compatibility checking within this scope. In this scenario, if developers evolve the schema Payment and produce new messages to the topic transactions, Schema Registry checks that those newly evolved schemas are compatible with older schemas in the subject transactions-value and adds those new schemas to the subject.
Schema Definition¶
The first thing developers need to do is agree on a basic schema for data. Client applications form a contract: producers will write data in a schema and consumers will be able to read that data.
Consider the original Payment schema:
$ cat src/main/resources/avro/io/confluent/examples/clients/basicavro/Payment.avsc
{"namespace": "io.confluent.examples.clients.basicavro",
"type": "record",
"name": "Payment",
"fields": [
{"name": "id", "type": "string"},
{"name": "amount", "type": "double"}
]
}
Let’s break down what this schema defines
namespace: a fully qualified name that avoids schema naming conflictstype: Avro data type, one ofrecord,enum,union,array,map,fixedname: unique schema name in this namespacefields: one or more simple or complex data types for arecord. The first field in this record is called id, and it is of type string. The second field in this record is called amount, and it is of type double.
Client Applications Writing Avro¶
Maven¶
This tutorial uses Maven to configure the project and dependencies.
Java applications that have Kafka producers or consumers using Avro require pom.xml files to include, among other things:
- Confluent Maven repository
- Confluent Maven plugin repository
- Dependencies
org.apache.avro.avroandio.confluent.kafka-avro-serializerto serialize data as Avro - Plugin
avro-maven-pluginto generate Java class files from the source schema
The pom.xml file may also include:
- Plugin
kafka-schema-registry-maven-pluginto check compatibility of evolving schemas
For a full pom.xml example, refer to this pom.xml.
Configuring Avro¶
Apache Kafka applications using Avro data and Confluent Schema Registry need to specify at least two configuration parameters:
- Avro serializer or deserializer
- URL to the Confluent Schema Registry
There are two basic types of Avro records that your application can use: a specific code-generated class or a generic record. The examples in this tutorial demonstrate how to use the specific Payment class. Using a specific code-generated class requires you to define and compile a Java class for your schema, but it easier to work with in your code. However, in other scenarios where you need to work dynamically with data of any type and do not have Java classes for your record types, use GenericRecord.
Java Producers¶
Within the application, Java producers need to configure the Avro serializer for the Kafka value (or Kafka key) and URL to Confluent Schema Registry. Then the producer can write records where the Kafka value is of Payment class. When constructing the producer, configure the message value class to use the application’s code-generated Payment class. For example:
import io.confluent.kafka.serializers.KafkaAvroSerializer;
import io.confluent.kafka.serializers.AbstractKafkaAvroSerDeConfig;
...
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class);
props.put(AbstractKafkaAvroSerDeConfig.SCHEMA_REGISTRY_URL_CONFIG, schemaRegistryUrl);
...
...
KafkaProducer<String, Payment> producer = new KafkaProducer<String, Payment>(props));
final Payment payment = new Payment(orderId, 1000.00d);
final ProducerRecord<String, Payment> record = new ProducerRecord<String, Payment>(TOPIC, payment.getId().toString(), payment);
producer.send(record);
...
For a full Java producer example, refer to the producer example.
Because the pom.xml includes avro-maven-plugin, the Payment class is automatically generated during compile.
To run this producer, first compile the project and then run ProducerExample.
$ mvn clean compile package
$ mvn exec:java -Dexec.mainClass=io.confluent.examples.clients.basicavro.ProducerExample
You should see:
...
Successfully produced 10 messages to a topic called transactions
...
Java Consumers¶
Within the application, Java consumers need to configure the Avro deserializer for the Kafka value (or Kafka key) and URL to Confluent Schema Registry.
Then the consumer can read records where the Kafka value is of Payment class.
By default, each record is deserialized into an Avro GenericRecord, but in this tutorial the record should be deserialized using the application’s code-generated Payment class.
Therefore, configure the deserializer to use Avro SpecificRecord, i.e., SPECIFIC_AVRO_READER_CONFIG should be set to true.
For example:
import io.confluent.kafka.serializers.KafkaAvroDeserializer;
import io.confluent.kafka.serializers.AbstractKafkaAvroSerDeConfig;
...
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, KafkaAvroDeserializer.class);
props.put(KafkaAvroDeserializerConfig.SPECIFIC_AVRO_READER_CONFIG, true);
props.put(AbstractKafkaAvroSerDeConfig.SCHEMA_REGISTRY_URL_CONFIG, schemaRegistryUrl);
...
...
KafkaConsumer<String, Payment> consumer = new KafkaConsumer<>(props));
consumer.subscribe(Collections.singletonList(TOPIC));
while (true) {
ConsumerRecords<String, Payment> records = consumer.poll(100);
for (ConsumerRecord<String, Payment> record : records) {
String key = record.key();
Payment value = record.value();
}
}
...
For a full Java consumer example, refer to the consumer example.
Because the pom.xml includes avro-maven-plugin, the Payment class is automatically generated during compile.
To run this consumer, first compile the project and then run ConsumerExample (assuming you already ran the ProducerExample above).
$ mvn clean compile package
$ mvn exec:java -Dexec.mainClass=io.confluent.examples.clients.basicavro.ConsumerExample
You should see:
...
offset = 0, key = id0, value = {"id": "id0", "amount": 1000.0}
offset = 1, key = id1, value = {"id": "id1", "amount": 1000.0}
offset = 2, key = id2, value = {"id": "id2", "amount": 1000.0}
offset = 3, key = id3, value = {"id": "id3", "amount": 1000.0}
offset = 4, key = id4, value = {"id": "id4", "amount": 1000.0}
offset = 5, key = id5, value = {"id": "id5", "amount": 1000.0}
offset = 6, key = id6, value = {"id": "id6", "amount": 1000.0}
offset = 7, key = id7, value = {"id": "id7", "amount": 1000.0}
offset = 8, key = id8, value = {"id": "id8", "amount": 1000.0}
offset = 9, key = id9, value = {"id": "id9", "amount": 1000.0}
...
Hit Ctrl-C to stop.
Other Kafka Clients¶
The objective of this tutorial is to learn about Avro and Schema Registry centralized schema management and compatibility checks. To keep examples simple, this tutorial focuses on Java producers and consumers, but other Kafka clients work in similar ways. For examples of other Kafka clients interoperating with Avro and Schema Registry:
- KSQL
- Kafka Streams
- Kafka Connect
- Confluent REST Proxy
- Non-Java clients based on librdkafka , including Confluent Python, Confluent Go, Confluent DotNet
Centralized Schema Management¶
Schemas in Schema Registry¶
At this point, you have producers serializing Avro data and consumers deserializing Avro data. The producers are registering schemas and consumers are retrieving schemas. You can view subjects and associated schemas via the REST endpoint in Schema Registry.
View all the subjects registered in Schema Registry (assuming Schema Registry is running on the local machine listening on port 8081):
$ curl --silent -X GET http://localhost:8081/subjects/ | jq .
[
"transactions-value"
]
In this example, the Kafka topic transactions has messages whose value, i.e., payload, is Avro. View the associated subject transactions-value in Schema Registry:
$ curl --silent -X GET http://localhost:8081/subjects/transactions-value/versions/latest | jq .
{
"subject": "transactions-value",
"version": 1,
"id": 1,
"schema": "{\"type\":\"record\",\"name\":\"Payment\",\"namespace\":\"io.confluent.examples.clients.basicavro\",\"fields\":[{\"name\":\"id\",\"type\":\"string\"},{\"name\":\"amount\",\"type\":\"double\"}]}"
}
Let’s break down what this version of the schema defines
- subject: the scope in which schemas for the messages in the topic transactions can evolve
- version: the schema version for this subject, which starts at 1 for each subject
- id: the globally unique schema version id, unique across all schemas in all subjects
- schema: the structure that defines the schema format
The schema is identical to the schema file defined for Java client applications. Notice in the output above, the schema is escaped JSON, i.e., the double quotes are preceded with backslashes.
Based on the schema id, you can also retrieve the associated schema by querying Schema Registry REST endpoint:
$ curl --silent -X GET http://localhost:8081/schemas/ids/1 | jq .
{
"schema": "{\"type\":\"record\",\"name\":\"Payment\",\"namespace\":\"io.confluent.examples.clients.basicavro\",\"fields\":[{\"name\":\"id\",\"type\":\"string\"},{\"name\":\"amount\",\"type\":\"double\"}]}"
}
If you are using Confluent Control Center, you can view the topic schema easily from the UI, and inspect new data arriving into the topic:
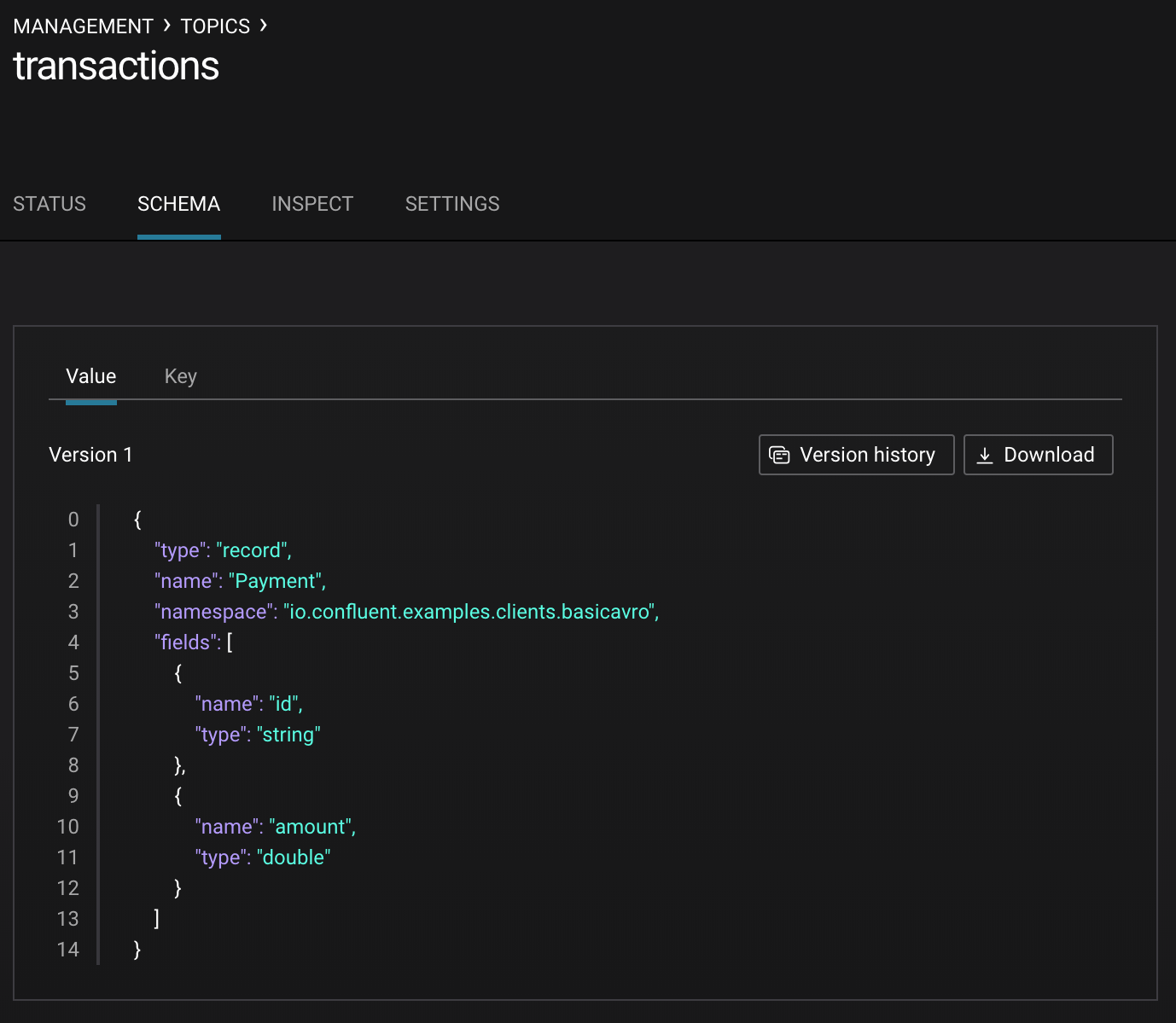
Schema IDs in Messages¶
Integration with Confluent Schema Registry means that Kafka messages do not need to be written with the entire Avro schema. Instead, Kafka messages are written with the schema id. The producers writing the messages and the consumers reading the messages must be using the same Schema Registry to get the same mapping between a schema and schema id.
In this example, a producer sends the new schema for Payments to Schema Registry. Schema Registry registers this schema Payments to the subject transactions-value, and returns the schema id of 1 to the producer. The producer caches this mapping between the schema and schema id for subsequent message writes, so it only contacts Schema Registry on the first schema write. When a consumer reads this data, it sees the Avro schema id of 1 and sends a schema request to Schema Registry. Schema Registry retrieves the schema associated to schema id 1, and returns the schema to the consumer. The consumer caches this mapping between the schema and schema id for subsequent message reads, so it only contacts Schema Registry the on first schema id read.
Auto Schema Registration¶
By default, client applications automatically register new schemas. If they produce new messages to a new topic, then they will automatically try to register new schemas. This is very convenient in development environments, but in production environments we recommend that client applications do not automatically register new schemas. Register schemas outside of the client application to control when schemas are registered with Confluent Schema Registry and how they evolve.
Within the application, disable automatic schema registration by setting the configuration parameter auto.register.schemas=false, as shown in the example below.
props.put(AbstractKafkaAvroSerDeConfig.AUTO_REGISTER_SCHEMAS, false);
To manually register the schema outside of the application, send the schema to Schema Registry and associate it with a subject, in this case transactions-value. It returns a schema id of 1.
$ curl -X POST -H "Content-Type: application/vnd.schemaregistry.v1+json" --data '{"schema": "{\"type\":\"record\",\"name\":\"Payment\",\"namespace\":\"io.confluent.examples.clients.basicavro\",\"fields\":[{\"name\":\"id\",\"type\":\"string\"},{\"name\":\"amount\",\"type\":\"double\"}]}"}' http://localhost:8081/subjects/transactions-value/versions
{"id":1}
Schema Evolution and Compatibility¶
Changing Schemas¶
So far in this tutorial, you have seen the benefit of Confluent Schema Registry as being centralized schema management that enables client applications to register and retrieve globally unique schema ids. The main value of Schema Registry, however, is in enabling schema evolution. Similar to how APIs evolve and need to be compatible for all applications that rely on old and new versions of the API, schemas also evolve and likewise need to be compatible for all applications that rely on old and new versions of a schema. This schema evolution is a natural behavior of how applications and data develop over time.
Confluent Schema Registry allows for schema evolution and provides compatibility checks to ensure that the contract between producers and consumers is not broken. This allows producers and consumers to update independently and evolve their schemas independently, with assurances that they can read new and legacy data. This is especially important in Kafka because producers and consumers are decoupled applications that are sometimes developed by different teams.
Transitive compatibility checking is important once you have more than two versions of a schema for a given subject. If compatibility is configured as transitive, then it checks compatibility of a new schema against all previously registered schemas; otherwise, it checks compatibility of a new schema only against the latest schema.
For example, if there are three schemas for a subject that change in order X-2, X-1, and X then:
- transitive: ensures compatibility between X-2 <==> X-1 and X-1 <==> X and X-2 <==> X
- non-transitive: ensures compatibility between X-2 <==> X-1 and X-1 <==> X, but not necessarily X-2 <==> X
Refer to an example of schema changes which are incrementally compatible, but not transitively so.
The Confluent Schema Registry default compatibility type BACKWARD is non-transitive, which means that it’s not BACKWARD_TRANSITIVE.
As a result, new schemas are checked for compatibility only against the latest schema.
These are the compatibility types:
BACKWARD: (default) consumers using the new schema can read data written by producers using the latest registered schemaBACKWARD_TRANSITIVE: consumers using the new schema can read data written by producers using all previously registered schemasFORWARD: consumers using the latest registered schema can read data written by producers using the new schemaFORWARD_TRANSITIVE: consumers using all previously registered schemas can read data written by producers using the new schemaFULL: the new schema is forward and backward compatible with the latest registered schemaFULL_TRANSITIVE: the new schema is forward and backward compatible with all previously registered schemasNONE: schema compatibility checks are disabled
You can change this globally or per subject, but for the remainder of this tutorial, leave the default compatibility type to backward. Refer to Schema Evolution and Compatibility for a more in-depth explanation on the compatibility types.
Failing Compatibility Checks¶
Schema Registry checks compatibility as schemas evolve to uphold the producer-consumer contract. Without Schema Registry checking compatibility, your applications could potentially break on schema changes.
In the Payment schema example, let’s say the business now tracks additional information for each payment, for example, a field region that represents the place of sale.
Consider the Payment2a schema which includes this extra field region:
$ cat src/main/resources/avro/io/confluent/examples/clients/basicavro/Payment2a.avsc
{"namespace": "io.confluent.examples.clients.basicavro",
"type": "record",
"name": "Payment",
"fields": [
{"name": "id", "type": "string"},
{"name": "amount", "type": "double"},
{"name": "region", "type": "string"}
]
}
Before proceeding, think about whether this schema is backward compatible. Specifically, ask yourself whether a consumer can use this new schema to read data written by producers using the older schema without the region field? The answer is no. Consumers will fail reading data with the older schema because the older data does not have the region field, therefore this schema is not backward compatible.
Confluent provides a Schema Registry Maven Plugin, which you can use to check compatibility in development or integrate into your CI/CD pipeline.
Our sample pom.xml includes this plugin to enable compatibility checks.
<plugin>
<groupId>io.confluent</groupId>
<artifactId>kafka-schema-registry-maven-plugin</artifactId>
<version>5.1.4</version>
<configuration>
<schemaRegistryUrls>
<param>http://localhost:8081</param>
</schemaRegistryUrls>
<subjects>
<transactions-value>src/main/resources/avro/io/confluent/examples/clients/basicavro/Payment2a.avsc</transactions-value>
</subjects>
</configuration>
<goals>
<goal>test-compatibility</goal>
</goals>
</plugin>
It is currently configured to check compatibility of the new Payment2a schema for the transactions-value subject in Schema Registry. Run the compatibility check and verify that it fails:
$ mvn io.confluent:kafka-schema-registry-maven-plugin:5.1.4:test-compatibility
...
[ERROR] Schema examples/clients/avro/src/main/resources/avro/io/confluent/examples/clients/basicavro/Payment2a.avsc is not compatible with subject(transactions-value)
...
You could have also just tried to register the new schema Payment2a manually to Schema Registry, which is a useful way for non-Java clients to check compatibility. As expected, Schema Registry rejects it with an error message that it is incompatible.
$ curl -X POST -H "Content-Type: application/vnd.schemaregistry.v1+json" --data '{"schema": "{\"type\":\"record\",\"name\":\"Payment\",\"namespace\":\"io.confluent.examples.clients.basicavro\",\"fields\":[{\"name\":\"id\",\"type\":\"string\"},{\"name\":\"amount\",\"type\":\"double\"},{\"name\":\"region\",\"type\":\"string\"}]}"}' http://localhost:8081/subjects/transactions-value/versions
{"error_code":409,"message":"Schema being registered is incompatible with an earlier schema"}
Passing Compatibility Checks¶
To maintain backward compatibility, a new schema must assume default values for the new field if it is not provided.
Consider an updated Payment2b schema that has a default value for region:
$ cat src/main/resources/avro/io/confluent/examples/clients/basicavro/Payment2b.avsc
{"namespace": "io.confluent.examples.clients.basicavro",
"type": "record",
"name": "Payment",
"fields": [
{"name": "id", "type": "string"},
{"name": "amount", "type": "double"},
{"name": "region", "type": "string", "default": ""}
]
}
Update the pom.xml to refer to Payment2b.avsc instead of Payment2a.avsc. Re-run the compatibility check and verify that it passes:
$ mvn io.confluent:kafka-schema-registry-maven-plugin:5.1.4:test-compatibility
...
[INFO] Schema examples/clients/avro/src/main/resources/avro/io/confluent/examples/clients/basicavro/Payment2b.avsc is compatible with subject(transactions-value)
...
You can try registering the new schema Payment2b directly, and it succeeds.
$ curl -X POST -H "Content-Type: application/vnd.schemaregistry.v1+json" --data '{"schema": "{\"type\":\"record\",\"name\":\"Payment\",\"namespace\":\"io.confluent.examples.clients.basicavro\",\"fields\":[{\"name\":\"id\",\"type\":\"string\"},{\"name\":\"amount\",\"type\":\"double\"},{\"name\":\"region\",\"type\":\"string\",\"default\":\"\"}]}"}' http://localhost:8081/subjects/transactions-value/versions
{"id":2}
View the latest subject for transactions-value in Schema Registry:
$ curl --silent -X GET http://localhost:8081/subjects/transactions-value/versions/latest | jq .
{
"subject": "transactions-value",
"version": 2,
"id": 2,
"schema": "{\"type\":\"record\",\"name\":\"Payment\",\"namespace\":\"io.confluent.examples.clients.basicavro\",\"fields\":[{\"name\":\"id\",\"type\":\"string\"},{\"name\":\"amount\",\"type\":\"double\"},{\"name\":\"region\",\"type\":\"string\",\"default\":\"\"}]}"
}
Notice the changes:
- version: changed from 1 to 2
- id: changed from 1 to 2
- schema: updated with the new field region that has a default value
Next Steps¶
- Adapt your applications to use Avro data
- Change compatibility modes to suit your application needs
- Test new schemas so that they pass compatibility checks
- For a more in-depth understanding of the benefits of Avro, read Why Avro For Kafka Data
- For a more in-depth understanding of the benefits of Confluent Schema Registry, read Yes, Virginia, You Really Do Need a Schema Registry