Important
You are viewing documentation for an older version of Confluent Platform. For the latest, click here.
Schema Registry Multi-DC Setup¶
Spanning multiple datacenters with your Schema Registry provides additional protection against data loss and improved latency. The recommended multi-datacenter deployment designates one datacenter as “master” and all others as “slaves”. If the “master” datacenter fails and is unrecoverable, a “slave” datacenter will need to be manually designated the new “master” through the steps in the Run Book below.
Kafka Election¶
Recommended Deployment¶
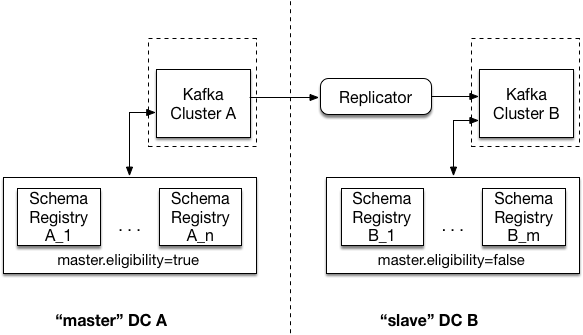
Multi DC with Kafka based master election
In the image above, there are two data centers - DC A, and DC B. Each of the two data centers has its own ZooKeeper cluster, Kafka cluster, and Schema Registry cluster. Schema Registry clusters link to Kafka clusters in the respective DC.
Note that Schema Registry instances in DC B have master.eligibility set to false, meaning
that none can ever be elected master.
To protect against complete loss of DC A, Kafka cluster A (the source) is replicated to Kafka cluster B (the target). This is achieved by running the Replicator Tutorial on Docker <connect_replicator>` local to the target cluster.
Important Settings¶
kafkastore.bootstrap.servers
kafkastore.bootstrap.servers should point to the local Kafka cluster
schema.registry.group.id
Use this setting to override the group.id for the Kafka group used when Kafka is used for master election. Without this configuration, group.id will be “schema-registry”. If you want to run more than one Schema Registry cluster against a single Kafka cluster you should make this setting unique for each cluster.
master.eligibility
A Schema Registry server with master.eligibility set to false is guaranteed to remain a slave during any master election. Schema Registry instances in a “slave” data center should have this set to false, and Schema Registry instances local to the shared Kafka cluster should have this set to true.
Setup¶
Assuming you have Schema Registry running, here are the recommended steps to add Schema Registry instances in a new “slave” datacenter (call it DC B):
- In DC B, make sure Kafka has
unclean.leader.election.enableset to false. - In DC B, run Replicator with Kafka in the “master” datacenter (DC A) as the source and Kafka in DC B as the target.
- In Schema Registry config files in DC B, set the
kafkastore.bootstrap.serversto point to Kafka Cluster in DC B and setmaster.eligibilityto false. - Start your new Schema Registry instances with these configs.
Run Book¶
Let’s say you have Schema Registry running in multiple datacenters, and you have lost your “master” datacenter; what do you do? First, note that the remaining Schema Registry instances will continue to be able to serve any request which does not result in a write to Kafka. This includes GET requests on existing IDs and POST requests on schemas already in the registry.
- If possible, revive the “master” datacenter by starting Kafka and Schema Registry as before.
- If you must designate a new datacenter (call it DC B) as “master”, update Schema Registry config files so that
master.eligibilityis set to true. Then restart your Schema Registry instances with these new configs in a rolling fashion.
ZooKeeper Election¶
Recommended Deployment¶
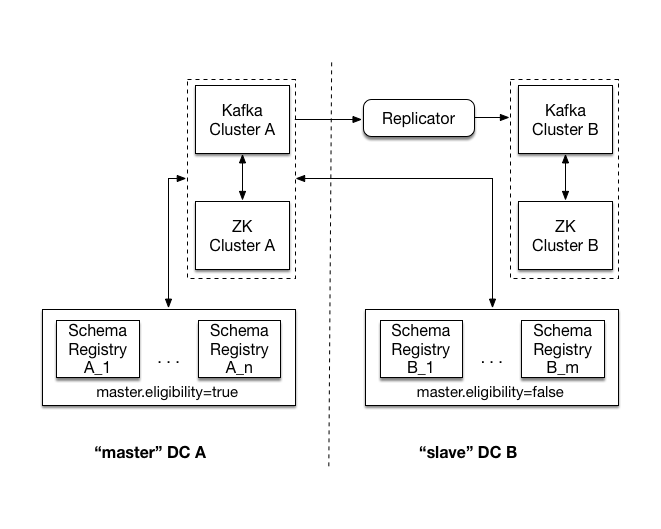
Multi DC with Zookeeper based master election
In the image above, there are two data centers - DC A, and DC B. Each of the two data centers has its own ZooKeeper cluster, Kafka cluster, and Schema Registry cluster. Both Schema Registry clusters link to Kafka and ZooKeeper in DC A.
Note that Schema Registry instances in DC B have master.eligibility set to false, meaning that none can ever be elected master.
To protect against complete loss of DC A, Kafka cluster A (the source) is replicated to Kafka cluster B (the target). This is achieved by running the Replicator Tutorial on Docker <connect_replicator>` local to the target cluster.
Important Settings¶
kafkastore.connection.url
kafkastore.connection.url should be identical across all Schema Registry nodes. By sharing this setting, all Schema Registry instances will point to the same ZooKeeper cluster.
schema.registry.zk.namespace
Namespace under which Schema Registry related metadata is stored in ZooKeeper. This setting should be identical across all nodes in the same Schema Registry.
master.eligibility
A Schema Registry server with master.eligibility set to false is guaranteed to remain a slave during any master election. Schema Registry instances in a “slave” data center should have this set to false, and Schema Registry instances local to the shared Kafka cluster should have this set to true.
Setup¶
Assuming you have Schema Registry running, here are the recommended steps to add Schema Registry instances in a new “slave” datacenter (call it DC B):
- In DC B, make sure Kafka has
unclean.leader.election.enableset to false. - In DC B, run Replicator with Kafka in the “master” datacenter (DC A) as the source and Kafka in DC B as the target.
- In Schema Registry config files in DC B, set
kafkastore.connection.urlandschema.registry.zk.namespaceto match the instances already running, and setmaster.eligibilityto false. - Start your new Schema Registry instances with these configs.
Run Book¶
Let’s say you have Schema Registry running in multiple datacenters, and you have lost your “master” datacenter; what do you do? First, note that the remaining Schema Registry instances will continue to be able to serve any request which does not result in a write to Kafka. This includes GET requests on existing IDs and POST requests on schemas already in the registry.
- If possible, revive the “master” datacenter by starting Kafka and Schema Registry as before.
- If you must designate a new datacenter (call it DC B) as “master”, update Schema Registry config files so that
kafkastore.connection.urlpoints to the local ZooKeeper, and changemaster.eligibilityto true. The restart your Schema Registry instances with these new configs in a rolling fashion.