Important
You are viewing documentation for an older version of Confluent Platform. For the latest, click here.
Avro Schema Serializer and Deserializer¶
This document describes how to use Avro schemas with the Apache Kafka® Java client and console tools.
Avro Serializer¶
You can plug KafkaAvroSerializer into KafkaProducer to send messages of Avro type to Kafka.
Currently supported primitive types are null, Boolean, Integer, Long, Float, Double, String,
byte[], and complex type of IndexedRecord. Sending data of other types to KafkaAvroSerializer will
cause a SerializationException. Typically, IndexedRecord is used for the value of the Kafka message.
If used, the key of the Kafka message is often one of the primitive types
mentioned above. When sending a message to a topic t, the Avro schema for the
key and the value will be automatically registered in Schema Registry under the subject
t-key and t-value, respectively, if the compatibility test passes. The only
exception is that the null type is never registered in Schema Registry.
In the following example, a message is sent with a key of type string and a value of type Avro record
to Kafka. A SerializationException may occur during the send call, if the data is not well formed.
Tip
The examples below use the default address and port for the Kafka bootstrap server (localhost:9092) and Schema Registry (localhost:8081).
import org.apache.avro.Schema;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericRecord;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
io.confluent.kafka.serializers.StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
io.confluent.kafka.serializers.KafkaAvroSerializer.class);
props.put("schema.registry.url", "http://localhost:8081");
KafkaProducer producer = new KafkaProducer(props);
String key = "key1";
String userSchema = "{\"type\":\"record\"," +
"\"name\":\"myrecord\"," +
"\"fields\":[{\"name\":\"f1\",\"type\":\"string\"}]}";
Schema.Parser parser = new Schema.Parser();
Schema schema = parser.parse(userSchema);
GenericRecord avroRecord = new GenericData.Record(schema);
avroRecord.put("f1", "value1");
ProducerRecord<Object, Object> record = new ProducerRecord<>("topic1", key, avroRecord);
try {
producer.send(record);
} catch(SerializationException e) {
// may need to do something with it
}
// When you're finished producing records, you can flush the producer to ensure it has all been written to Kafka and
// then close the producer to free its resources.
finally {
producer.flush();
producer.close();
}
Avro Deserializer¶
You can plug in KafkaAvroDeserializer to KafkaConsumer to receive messages of any Avro type from Kafka.
In the following example, messages are received with a key of type string and a value of type Avro record
from Kafka. When getting the message key or value, a SerializationException may occur if the data is
not well formed.
Tip
The examples below use the default address and port for the Kafka bootstrap server (localhost:9092) and Schema Registry (localhost:8081).
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.avro.generic.GenericRecord;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.Arrays;
import java.util.Properties;
import java.util.Random;
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "group1");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "io.confluent.kafka.serializers.KafkaAvroDeserializer");
props.put("schema.registry.url", "http://localhost:8081");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
String topic = "topic1";
final Consumer<String, GenericRecord> consumer = new KafkaConsumer<String, GenericRecord>(props);
consumer.subscribe(Arrays.asList(topic));
try {
while (true) {
ConsumerRecords<String, GenericRecord> records = consumer.poll(100);
for (ConsumerRecord<String, GenericRecord> record : records) {
System.out.printf("offset = %d, key = %s, value = %s \n", record.offset(), record.key(), record.value());
}
}
} finally {
consumer.close();
}
With Avro, it is not necessary to use a property to specify a specific type,
since the type can be derived directly from the Avro schema, using the namespace
and name of the Avro type. This allows the Avro deserializer to be used out of
the box with topics that have records of heterogeneous Avro types. This would
be the case when using the RecordNameStrategy (or TopicRecordNameStrategy) to
store multiple types in the same topic, as described in Martin Kleppmann’s blog post
Should You Put Several Event Types in the Same Kafka Topic?.
(An alternative is to use schema references, as described in Multiple Event Types in the Same Topic and
Putting Several Event Types in the Same Topic – Revisited)
This differs from the Protobuf and JSON Schema deserializers, where in order to return a specific rather than a generic type, you must use a specific property.
Here is a summary of specific and generic return types for each schema format.
| Avro | Protobuf | JSON Schema | |
|---|---|---|---|
| Specific type | Generated class that extends org.apache.avro.SpecificRecord | Generated class that extends com.google.protobuf.Message | Java class (that is compatible with Jackson serialization) |
| Generic type | org.apache.avro.GenericRecord | com.google.protobuf.DynamicMessage | com.fasterxml.jackson.databind.JsonNode |
Test Drive Avro Schema¶
To see how this works and test drive the Avro schema format, use the command
line kafka-avro-console-producer and kafka-avro-console-consumer to send
and receive Avro data in JSON format from the console. Under the hood, the
producer and consumer use AvroMessageFormatter and AvroMessageReader to
convert between Avro and JSON.
Avro defines both a binary serialization format and a JSON serialization format. This allows you to use JSON when human-readability is desired, and the more efficient binary format when storing data in topics.
Note
- Prerequisites to run these examples are generally the same as those described for the Schema Registry Tutorial with the exception of Maven, which is not needed here. Also, Confluent Platform version 5.5.0 or later is required here.
- The following examples use the the default Schema Registry URL value (
localhost:8081). The examples show how to configure this inline by supplying the URL as an argument to the--propertyflag in the command line arguments of the producer and consumer (--property schema.registry.url=<address of your schema registry>). Alternatively, you could set this property in$CONFLUENT_HOME/etc/kafka/server.properties, and not have to include it in the producer and consumer commands. For example:confluent.schema.registry.url=http://localhost:8081
These examples make use of the kafka-avro-console-producer and kafka-avro-console-consumer, which are located in $CONFLUENT_HOME/bin.
The command line producer and consumer are useful for understanding how the built-in Avro schema support works on Confluent Platform.
When you incorporate the serializer and deserializer into the code for your own producers and consumers, messages and associated schemas are processed the same way as they are on the console producers and consumers.
The suggested consumer commands include a flag to read --from-beginning to
be sure you capture the messages even if you don’t run the consumer immediately
after running the producer. If you leave off the --from-beginning flag, the
consumer will read only the last message produced during its current session.
Start Confluent Platform using the following command:
confluent local start
Tip
- Alternatively, you can simply run
confluent local schema-registrywhich also startskafkaandzookeeperas dependencies. This demo does not directly reference the other services, such as Connect and Control Center. That said, you may want to run the full stack anyway to further explore, for example, how the topics and messages display on Control Center. To learn more aboutconfluent local, see Quick Start for Apache Kafka using Confluent Platform (Local) and confluent local in the Confluent CLI command reference. - The
confluent localcommands run in the background so you can re-use this command window. Separate sessions are required for the producer and consumer.
- Alternatively, you can simply run
Verify registered schema types.
Starting with Confluent Platform 5.5.0, Schema Registry now supports arbitrary schema types. You should verify which schema types are currently registered with Schema Registry.
To do so, type the following command (assuming you use the default URL and port for Schema Registry,
localhost:8081):curl http://localhost:8081/schemas/types
The response will be one or more of the following. If additional schema format plugins are installed, these will also be available.
["JSON", "PROTOBUF", "AVRO"]
Alternatively, use the curl
--silentflag, and pipe the command through jq (curl --silent http://localhost:8081/schemas/types | jq) to get nicely formatted output:"JSON", "PROTOBUF", "AVRO"
Use the producer to send Avro records in JSON as the message value.
The new topic,
t1-a, will be created as a part of this producer command if it does not already exist.kafka-avro-console-producer --broker-list localhost:9092 --property schema.registry.url=http://localhost:8081 --topic t1-a \ --property value.schema='{"type":"record","name":"myrecord","fields":[{"name":"f1","type":"string"}]}'Tip
The current Avro specific producer does not show a
>prompt, just a blank line at which to type producer messages.Type the following command in the shell, and hit return.
{"f1": "value1-a"}Use the consumer to read from topic
t1-aand get the value of the message in JSON.kafka-avro-console-consumer --bootstrap-server localhost:9092 --from-beginning --topic t1-a --property schema.registry.url=http://localhost:8081
You should see following in the console.
{"f1": "value1-a"}Run a new producer command to send strings and Avro records in JSON to a new topic,
t2-a, as the key and the value of the message, respectively.If you are using the same shell for the producer, use Ctl-C to stop the previous producer, then run this new producer command.
kafka-avro-console-producer --broker-list localhost:9092 --topic t2-a \ --property parse.key=true \ --property "key.separator= "\ --property key.schema='{"type":"string"}' \ --property value.schema='{"type":"record","name":"myrecord","fields":[{"name":"f1","type":"string"}]}' \ --property schema.registry.url=http://localhost:8081In the shell, type in the following.
"key1" {"f1": "value2-a"}Keep this session of the producer running.
Use the consumer to read from topic
t2-aboth the key and the value of the messages in JSON.(Use Ctl-C to stop the consumer that was reading from topic
t1-a, and restart it with this new command to read the key and value from topict2-a.)kafka-avro-console-consumer --from-beginning --topic t2-a \ --bootstrap-server localhost:9092 \ --property print.key=true \ --property schema.registry.url=http://localhost:8081
You should see following in the console.
"key1" {"f1": "value2-a"}Restart the consumer to read again from topic
t2-a, this time to print the key and value of the message in JSON along with the schema IDs for the key and value.During registration, Schema Registry assigns an ID for new schemas that is greater than the IDs of the existing registered schemas. The IDs from different Schema Registry instances may be different.
kafka-avro-console-consumer --from-beginning --topic t2-a \ --bootstrap-server localhost:9092 \ --property print.key=true \ --property print.schema.ids=true \ --property schema.id.separator=: \ --property schema.registry.url=http://localhost:8081
You should see following in the console.
"key1":1 {"f1": "value2-a"}You can also use a consumer to read from the topic while specifying a custom key deserializer (different format from the value). If the topic contains a key in a format other than Avro, you can specify your own key deserializer as shown below.
kafka-avro-console-consumer --from-beginning --topic t2-a \ --bootstrap-server localhost:9092 \ --property print.key=true --key-deserializer=org.apache.kafka.common.serialization.StringDeserializer \ --property schema.registry.url=http://localhost:8081
Keep your current session of the consumer running (either of the consumers shown on this step will work).
Return to the producer session and type a new value at the prompt:
"key1" {"f1": "value3-a"}Return to the consumer session to verify that the last produced value is reflected on the consumer console:
"key1" {"f1":"value3-a"}Use Confluent Control Center to examine schemas and messages.
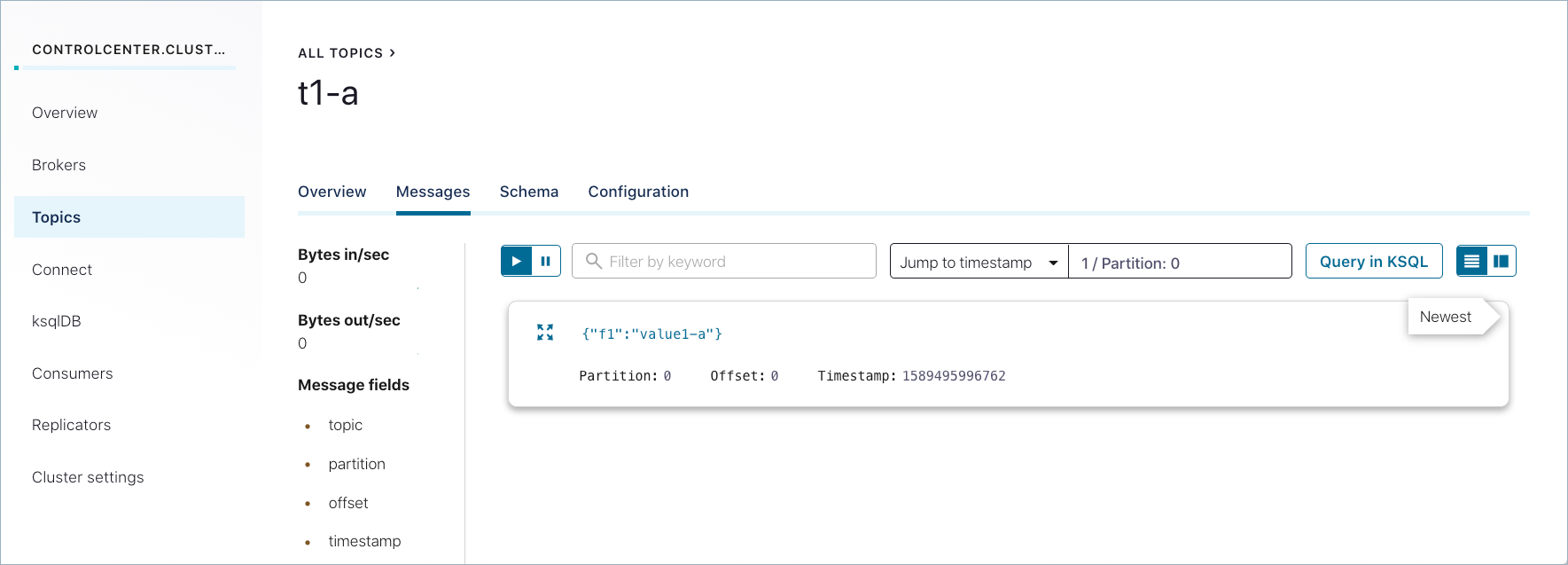
Messages that were successfully produced also show on Control Center (http://localhost:9021/) in Topics > <topicName> > Messages. You may have to select a partition or jump to a timestamp to see messages sent earlier. (For timestamp, type in a number, which will default to partition
1/Partition: 0, and press return. To get the message view shown here, select the cards icon on the upper right.)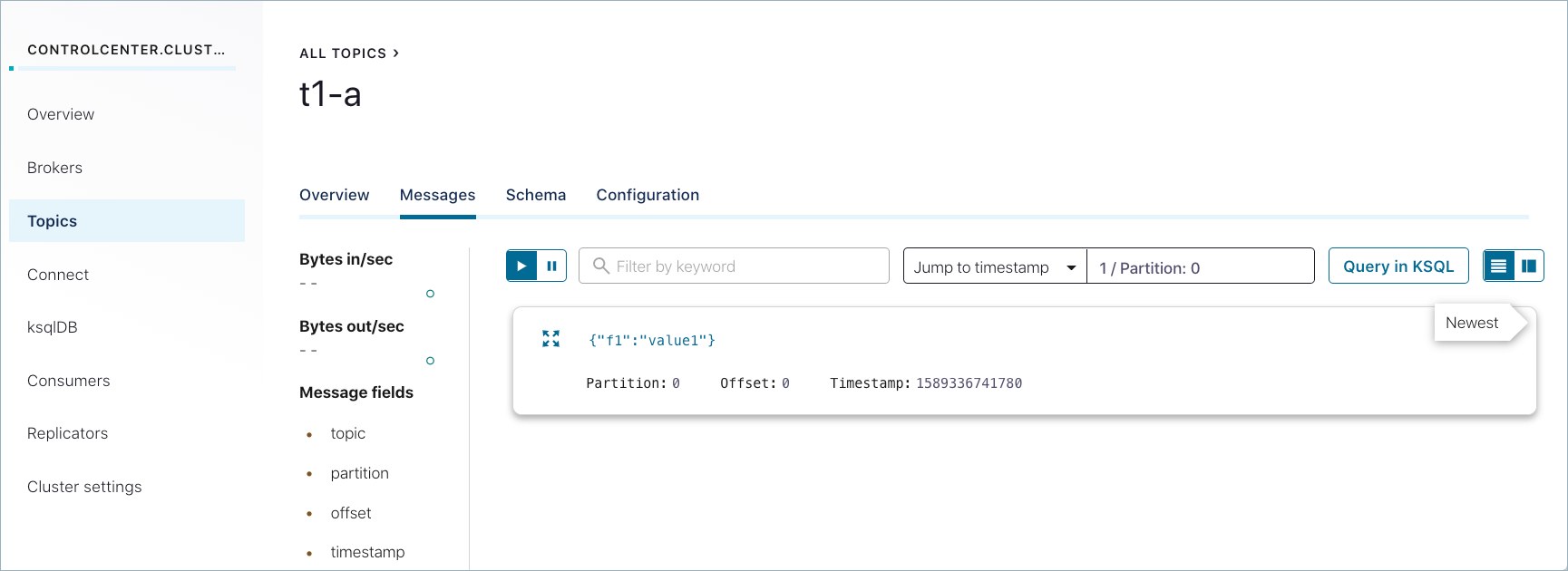
Schemas you create are available on the Schemas tab for the selected topic.
Run shutdown and cleanup tasks.
- You can stop the consumer and producer with Ctl-C in their respective command windows.
- To stop Confluent Platform, type
confluent local stop. - If you would like to clear out existing data (topics, schemas, and messages) before starting again with another test, type
confluent local destroy.
Schema References in Avro¶
Confluent Platform provides full support for the notion of schema references, the ability of a schema to refer to other schemas.
Tip
Schema references are also supported in Confluent Cloud on Avro, Protobuf, and JSON Schema formats. On the Confluent Cloud CLI, you can use the --refs <file> flag on ccloud schema-registry schema create to reference another schema.
To learn more, see the example given below in Multiple Event Types in the Same Topic, the associated blog post that goes into further detail on this, and the API example for how to register (create) a new schema in POST /subjects/(string: subject)/versions. That example includes a referenced schema.
Multiple Event Types in the Same Topic¶
In addition to providing a way for one schema to call other schemas, schema references can be used to efficiently combine multiple event types in the same topic and still maintain subject-topic constraints.
In Avro, this is accomplished as follows:
Use the default subject naming strategy,
TopicNameStrategy, which uses the topic name to determine the subject to be used for schema lookups, and helps to enforce subject-topic constraints.Use an Avro union to define the schema references as a list of schema names, for example:
[ "io.confluent.examples.avro.Customer", "io.confluent.examples.avro.Product", "io.confluent.examples.avro.Payment" ]
When the schema is registered, send an array of reference versions. For example:
[ { "name": "io.confluent.examples.avro.Customer", "subject": "customer", "version": 1 }, { "name": "io.confluent.examples.avro.Product", "subject": "product", "version": 1 }, { "name": "io.confluent.examples.avro.Order", "subject": "order", "version": 1 } ]Configure the Avro serializer to use your Avro union for serialization, and not the event type, by configuring the following properties in your producer application:
auto.register.schemas=false use.latest.version=true
For example:
props.put(AbstractKafkaAvroSerDeConfig.AUTO_REGISTER_SCHEMAS, false); props.put(AbstractKafkaAvroSerDeConfig.USE_LATEST_VERSION, true);
Tip
- Setting
auto.register.schemasto false disables auto-registration of the event type, so that it does not override the union as the latest schema in the subject. Settinguse.latest.versionto true causes the Avro serializer to look up the latest schema version in the subject (which will be the union) and use that for serialization. Otherwise, if set to false, the serializer will look for the event type in the subject and fail to find it. (See also, Auto Schema Registration in the Schema Registry Tutorial.) - See also, Schema Registry Configuration Options for Kafka Connect.
- Setting
Reflection Based Avro Serializer and Deserializer¶
Starting with version 5.4.0, Confluent Platform also provides a ReflectionAvroSerializer and ReflectionAvroDeserializer for reading and writing data in reflection Avro format.
The serializer writes data in wire format defined here, and the deserializer reads data per the same wire format.
The serde for the reflection-based Avro serializer and deserializer is ReflectionAvroSerde.
To learn more, see Kafka Streams Data Types and Serialization in the Streams Developer Guide.
Avro Schema Compatibility Rules¶
The compatibility rules for Avro are detailed in the specification under Schema Resolution.
See also, Schema Evolution and Compatibility and Compatibility Checks in the overview.
Suggested Reading¶
- Examples of Kafka client producers and consumers, with and without Avro, are documented at Code Examples.
- Schema Registry API Reference
- Apache Avro Project
- Apache Avro documentation