
Multi-Region Deployment of Confluent Platform
Confluent for Kubernetes (CFK) supports configuring, deploying, and operating Confluent Platform across multiple Kubernetes clusters running in different regions as a single multi-region cluster.
In this deployment scenario, Kafka, ZooKeeper, and Schema Registry can be deployed in multiple regions to form a logical cluster stretched across Kubernetes regions.
For information about Confluent Platform in multi-region clusters, see Multi-Region Clusters.
To form a multi-region cluster, Confluent must be deployed across three or more Kubernetes clusters.
CFK supports various multi-region cluster deployment scenarios for Confluent Platform. The following are example deployment scenarios.
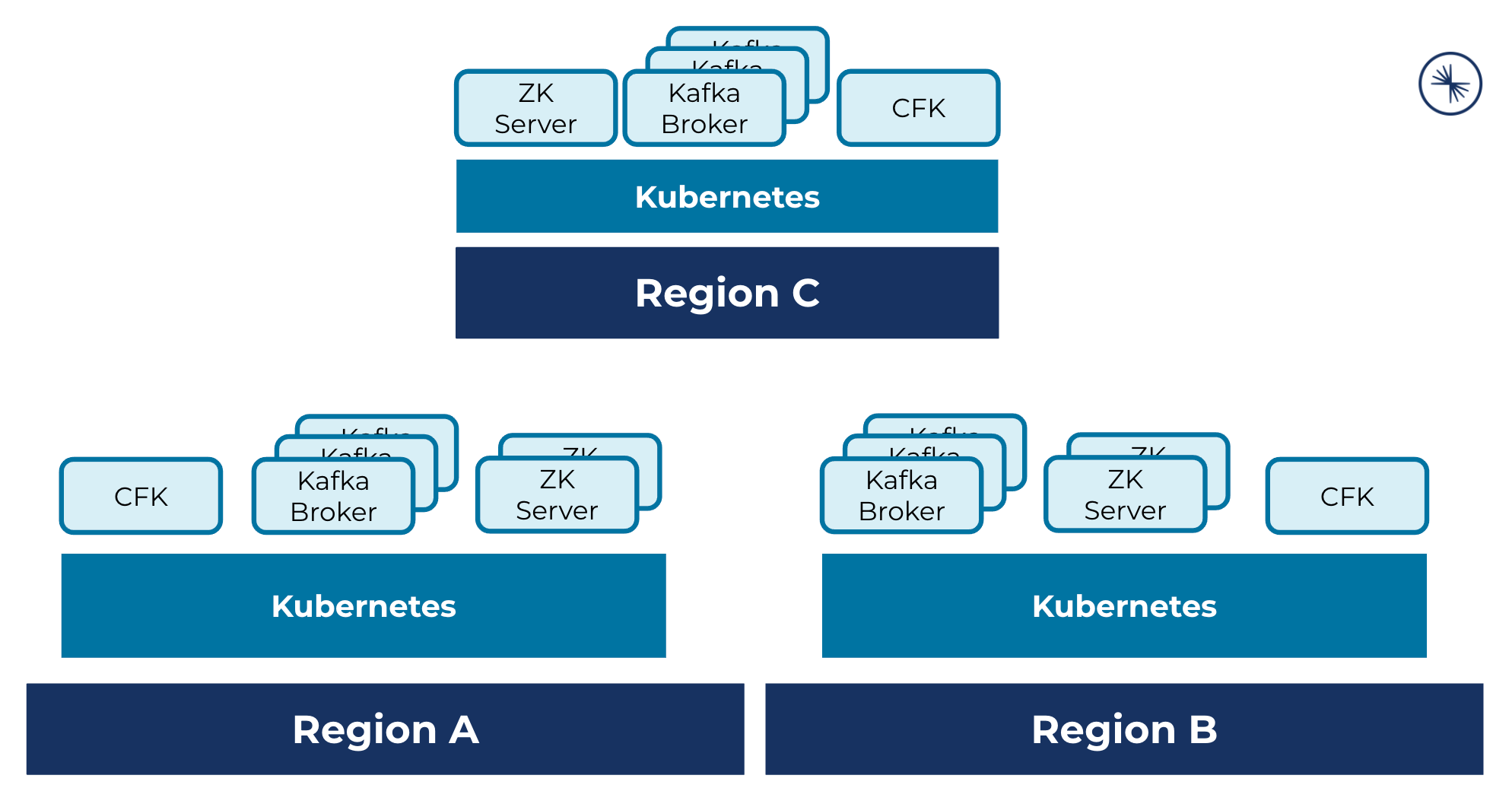
A multi-region cluster deployment across three Kubernetes regions, where each cluster hosts CFK, Kafka brokers, and ZooKeeper servers:
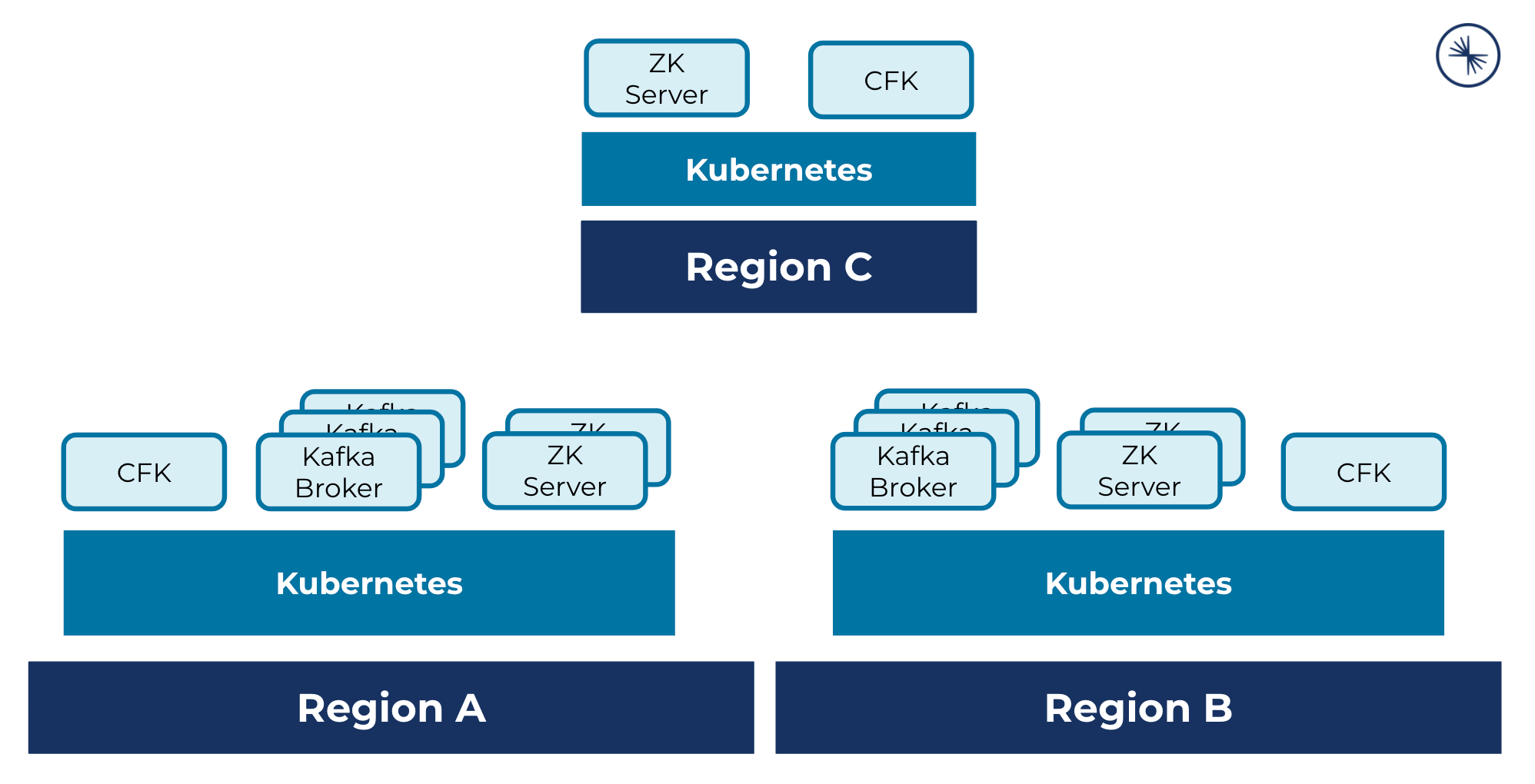
A multi-region cluster deployment across three Kubernetes regions, where each cluster hosts CFK, ZooKeeper servers, and two clusters host Kafka brokers:
For basic and comprehensive use case scenarios, see Confluent for Kubernetes examples GitHub repo.
The supported security features work in the multi-region cluster deployments. For specific configurations, see Configure Security with Confluent for Kubernetes.
Setup requirements for Kubernetes clusters
- Namespace naming
Have one uniquely named namespace in each Kubernetes region cluster.
- Flat pod networking among Kubernetes region clusters
Pod Classless Inter-Domain Routings (CIDRs) across the Kubernetes clusters must not overlap.
- DNS resolution and TCP communication among Kubernetes region clusters
Kubernetes clusters must be able to resolve other’s internal DNS and route to other’s internal pods.
You can use kube-dns or CoreDNS to expose region clusters’ DNS.
- Firewall rules
Allow TCP traffic on the standard ZooKeeper, Kafka, and Schema Registry ports among all region clusters’ pod subnetworks.
For specific configuration and validation steps on various platforms, specifically, GKE, EKS, and AKS, see Multi-region Cluster Networking in the CFK example repo.
- Kubernetes context
When working with multiple Kubernetes clusters, the
kubectlcommands run against a cluster in a specific context that specifies a Kubernetes cluster, a user, and a namespace.Append
--context <cluster-context>to thekubectlcommands to ensure they are run against the correct cluster.
Configure Confluent Platform in a multi-region cluster
Using distinct Kafka broker ids and other component server ids, namely ZooKeeper and Schema Registry, CFK creates and manages a logical multi-region cluster of each Confluent component.
Kubernetes nodes in each region have labels defined as topology.kubernetes.io/region=<region>. For example, when using three Kubernetes clusters, us-central-1, us-east-1, and us-west-1, the nodes in the regions will have labels topology.kubernetes.io/region=us-central-1, topology.kubernetes.io/region=us-east-1, and topology.kubernetes.io/region=us-west-1, respectively.
When CFK in each region schedules a broker pod, it will look up the region by reading the topology.kubernetes.io/region label of the Kubernetes node in the cluster, and deploy the broker to these nodes that have the matching broker.rack=<region>. You should not override the broker.rack property. For more information about the property, see broker.rack.
Deploy CFK to each region as described in Deploy Confluent for Kubernetes.
Configure ZooKeeper.
Set ZooKeeper server id offset to a different number in each Kubernetes region cluster using
annotationsin the ZooKeeper CR.For example:
metadata: annotations: platform.confluent.io/zookeeper-myid-offset: "100"
The default is
0.The offsets should be sufficiently spread out, like
100,200,300, etc., to accommodate future cluster growth in each region.This offset cannot be changed once set. So, you should carefully consider how wide you want these offsets to be before you deploy the cluster.
Specify the peer ZooKeeper servers in the
spec.configOverrides.peersproperty. For example, using the ZooKeeper servers configured in the previous step:spec: configOverrides: peers: - server.100=zookeeper-0.zookeeper.central.svc.cluster.local:2888:3888 - server.200=zookeeper-0.zookeeper.east.svc.cluster.local:2888:3888 - server.300=zookeeper-0.zookeeper.west.svc.cluster.local:2888:3888
Configure Kafka.
Set the broker id offset to a different number in the Kafka CR in each region.
For example:
metadata: annotations: platform.confluent.io/broker-id-offset: 100
The default is
0.The offsets should be sufficiently spread out, like
100,200,300, etc., to accommodate future cluster growth in each region.This offset cannot be changed once set. So, you should carefully consider how wide you want these offsets to be before you deploy the cluster.
In the Kafka CRs, specify a comma-separated list of ZooKeeper endpoints in
spec.dependencies.zookeeper.endpoint. This value should be the same in all Kafka CRs across Kubernetes clusters.For example:
spec: dependencies: zookeeper: endpoint: zookeeper.central.svc.cluster.local:2182/mrc,zookeeper.east.svc.cluster.local:2182/mrc,zookeeper.west.svc.cluster.local:2182/mrc
The ZooKeeper node id (
mrcin the above example) can be any string, but it needs to be the same for all the Kafka deployments in a multi-region cluster.If you are deploying multiple multi-region clusters utilizing the same ZooKeeper, use different node ids, for example,
mrc1,mrc2, etc., in each multi-region cluster.This value should not be changed once the cluster is created. Otherwise, it will result in data loss.
Configure external access to Kafka brokers through Load Balancers, Node Ports, or static host-based ingress controller routing. See Confluent Platform Networking Overview.
Configure Schema Registry to be deployed in each Kubernetes region cluster.
To form a logical cluster of Schema Registry across Kubernetes region clusters, specify the following properties in the Schema Registry CRs:
spec.dependencies.kafka.bootstrapEndpoint: A comma-separated list of Kafka endpoints across all Kubernetes region clustersspec.configOverrides.server.schema.registry.group.id: Use the same group id for all Schema Registry services across all Kubernetes region clustersspec.configOverrides.server.kafkastore.topic: Specify a string that starts with_for this log topic name. Use the same value for all Schema Registry services across all Kubernetes region clusters.
For example:
spec: dependencies: kafka: bootstrapEndpoint: kafka.central.svc.cluster.local:9071,kafka.east.svc.cluster.local:9071,kafka.west.svc.cluster.local:9071 configOverrides: server: - schema.registry.group.id=schema-registry-mrc - kafkastore.topic=_schemas_mrc
For details about deploying multi-region Schema Registry, see Multi Data Center Setup of Schema Registry.
Configure the remaining Confluent Platform components, including Control Center (Legacy), Connect, and ksqlDB, to be deployed in one Kubernetes region cluster and utilize the stretched Kafka.
In the component CRs, specify a comma-separated list of Kafka endpoints.
For example:
spec: dependencies: kafka: bootstrapEndpoint: kafka.central.svc.cluster.local:9071,kafka.east.svc.cluster.local:9071,kafka.west.svc.cluster.local:9071
Apply the CRs with the
kubectl apply -f <component CRs>in each region.
Manage Confluent Platform in multi-region cluster
The following are a few of the common tasks you would perform in a multi-region clusters. Some can be done in one region and get propagated to all regions, and some can be done in a specific region as noted.
- Create topics
You can create and manage topics in any region in a multi-region cluster, and those topics are accessible from all the regions in the cluster.
See Manage Kafka Topics for creating and managing topics.
- Scale Kafka
You need to scale Kafka at the regional level. Update the Kafka CR in a specific region to scale the Kafka cluster in that region.
See Scale Confluent Platform Clusters and Balance Data for scaling Kafka clusters.
- Manage rolebindings
You can create and manage rolebindings in any region in a multi-region cluster, and those rolebindings are accessible from all the regions in the cluster.
- Rotate certificates
To rotate TLS certificates used in a region, you follow the steps described in Manage TLS Certificates in the specific region.
- Restart Kafka
You need to restart Kafka in a specific region as described in Restart Confluent Platform.