Docker での Replicator デモ¶
このデモでは、データセンター間でデータの双方向コピーを行う Confluent Replicator の 2 つのインスタンスを含む、アクティブ/アクティブのマルチデータセンター設計をデプロイします。
この Docker 環境は、本稼働環境ではなくデモのみを目的としたものです。
デモのセットアップ¶
- 前提条件:
- Docker
- Docker バージョン 1.11 またはそれ以降が インストールされ動作している。
- Docker Compose が インストール済みである 。Docker Compose は、Docker for Mac ではデフォルトでインストールされます。
- Docker メモリーに最小でも 6 GB が割り当てられている。Docker Desktop for Mac を使用しているとき、Docker メモリーの割り当てはデフォルトで 2 GB です。Docker のデフォルトの割り当てを 6 GB に変更できます。Preferences、Resources、Advanced の順に移動します。
- インターネット接続
- Confluent Platform で現在サポートされる オペレーティングシステム
- Docker でのネットワークと Kafka
- 内部コンポーネントと外部コンポーネントが Docker ネットワークに通信できるように、ホストとポートを構成します。詳細については、こちらの記事 を参照してください。
- Docker
設計¶
これは、データセンター dc1 と dc2 間でデータの双方向コピーを行う Confluent Replicator の 2 つのインスタンスを含む、アクティブ/アクティブのマルチデータセンター設計です。
Confluent Control Center は、クラスターを管理およびモニタリングするために実行されています。
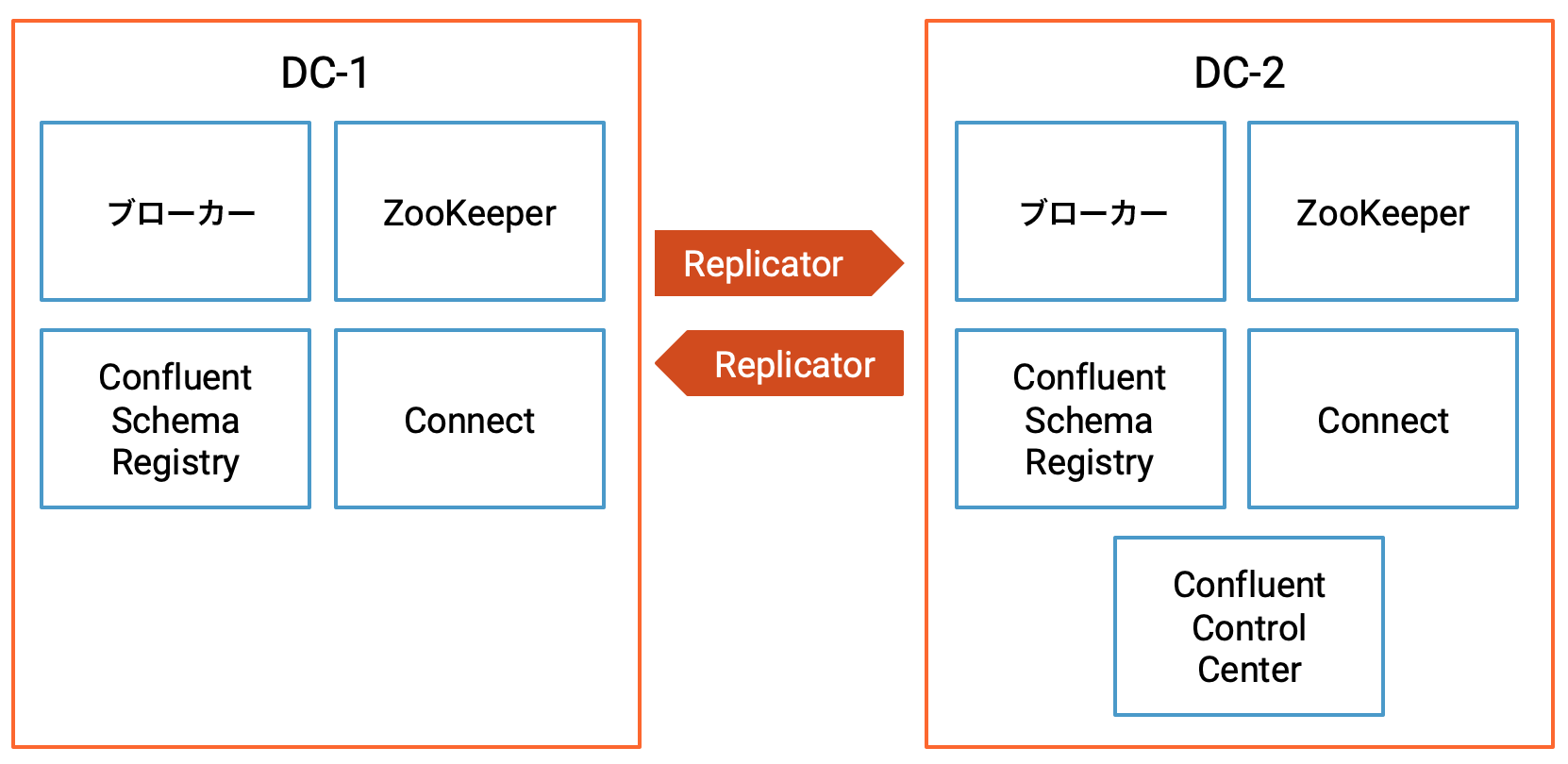
Confluent Platform コンポーネントのポート¶
| dc1 | dc2 | |
|---|---|---|
| ブローカー | 9091 | 9092 |
| ZooKeeper | 2181 | 2182 |
| Schema Registry | 8081(プライマリ) | 8082(セカンダリ) |
| Connect | 8381(dc2→dc1 にコピー) | 8382(dc1→dc2 にコピー) |
| Control Center | 9021 |
データ生成とトピック名¶
| データ生成 Docker コンテナー | 送信元 DC | 送信元トピック | Replicator インスタンス | 送信先 DC | 送信先トピック |
|---|---|---|---|---|---|
| datagen-dc1- topic1 | dc1 | topic1、_schemas | replicator-dc1 -to-dc2-topic1 | dc2 | topic1、_schemas |
| datagen-dc1- topic2 | dc1 | topic2 | replicator-dc1 -to-dc2-topic2 | dc2 | topic2.replica |
| datagen-dc2- topic1 | dc2 | topic1 | replicator-dc2 -to-dc1-topic1 | dc1 | topic1 |
Confluent Replicator (バージョン 5.0.1 以降)は、メッセージヘッダー内の来歴情報を使用して dc1 topic1 と dc2 topic1 の間のデータ循環反復を回避します。
デモの実行¶
環境¶
このデモは、以下のソフトウェアで動作が検証されています。
- Docker バージョン 17.06.1-ce
- Docker Compose ファイル形式 2.1 の Docker Compose バージョン 1.14.0
サービスの起動¶
confluentinc/examples GitHub リポジトリのクローンを作成し、
7.1.1-postブランチをチェックアウトします。git clone https://github.com/confluentinc/examples cd examples git checkout 7.1.1-post
multi-datacenterサンプルディレクトリに移動します。cd multi-datacenter/各データセンターのすべてのサービスとトピックのサンプルメッセージを開始します。
./start.sh
docker-compose.yml ファイル内の Kafka ブローカー、Schema Registry、および Connect ワーカーの完全な構成を表示します。
cat docker-compose.yml
マルチデータセンターセットアップの検証¶
Replicator¶
このマルチデータセンター環境には、2 つの Apache Kafka® クラスター、dc1 と dc2 があります。これらのクラスターは Confluent Control Center によって管理されています。Confluent Replicator は、dc1 と dc2 間の双方向でデータをコピーしますが、その仕組みをわかりやすく説明するために、以下のセクションでは dc1 から dc2 へのレプリケーションのみについて検討します。
デモを起動(前のセクション を参照)したら、Chrome ブラウザーで Control Center UI(http://localhost:9021)に移動して、2 つの Kafka クラスター、
dc1とdc2が存在することを確認します。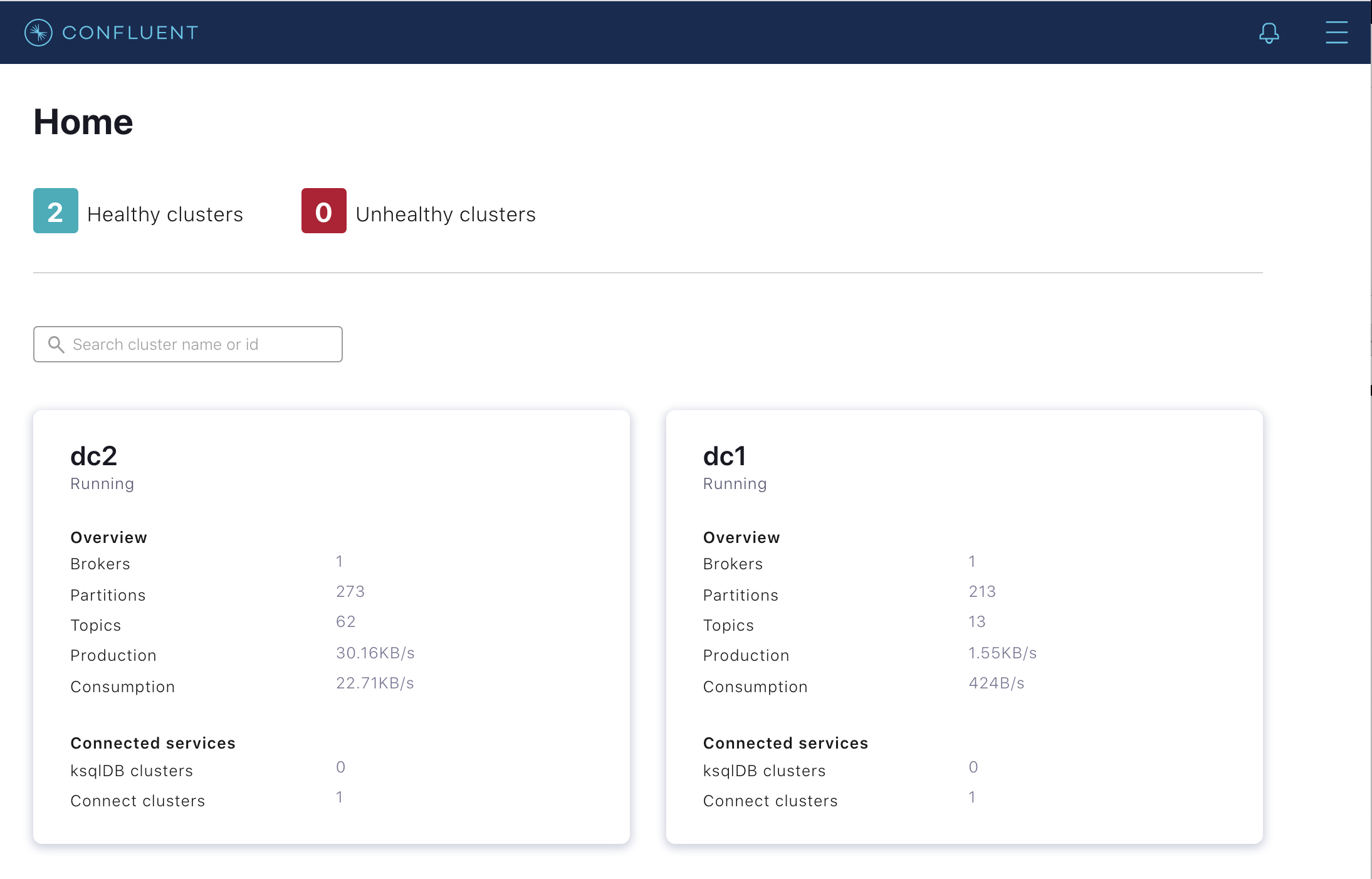
このデモでは、2 つの Kafka Connect クラスター、
connect-dc1とconnect-dc2を使用します。Replicator は、通常、送信先 Connect クラスターで実行されるソースコネクターです。そのため、connect-dc1はdc2からdc1にコピーする Replicator を実行し、connect-dc2はdc1からdc2にコピーする Replicator を実行します。バージョン 5.2 以降、Control Center は複数の Kafka Connect クラスターを管理できますが、このデモでは、connect-dc2で実行され、dc1からdc2にコピーする Replicator インスタンスのみを取り上げます。dc1からdc2にコピーする Replicator の場合: Connect メニューに移動して、Kafka Connect(connect-dc2に構成されています)が Replicator の 2 つのインスタンス、replicator-dc1-to-dc2-topic1 と replicator-dc1-to-dc2-topic2 を実行していることを確認します。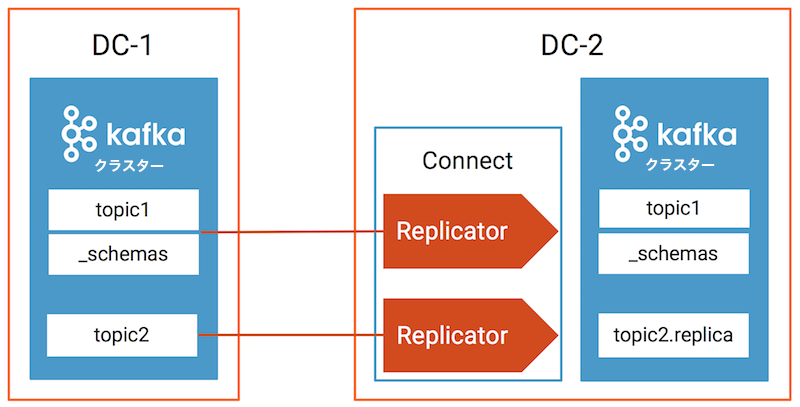
トピックの検査¶
各データセンターについて、さまざまなトピックのデータ、来歴情報、タイムスタンプ情報、およびクラスター ID を検査します。
./read-topics.sh
以下のように出力されることを確認します。
-----dc1----- list topics: __consumer_offsets __consumer_timestamps _confluent-command _confluent-license _confluent-telemetry-metrics _confluent_balancer_api_state _confluent_balancer_broker_samples _confluent_balancer_partition_samples _schemas connect-configs-dc1 connect-offsets-dc1 connect-status-dc1 topic1 topic2 topic1: {"userid":{"string":"User_7"},"dc":{"string":"dc1"}} {"userid":{"string":"User_7"},"dc":{"string":"dc2"}} {"userid":{"string":"User_9"},"dc":{"string":"dc2"}} {"userid":{"string":"User_2"},"dc":{"string":"dc1"}} {"userid":{"string":"User_5"},"dc":{"string":"dc2"}} {"userid":{"string":"User_1"},"dc":{"string":"dc1"}} {"userid":{"string":"User_3"},"dc":{"string":"dc2"}} {"userid":{"string":"User_7"},"dc":{"string":"dc1"}} {"userid":{"string":"User_1"},"dc":{"string":"dc2"}} {"userid":{"string":"User_8"},"dc":{"string":"dc1"}} Processed a total of 10 messages topic2: {"registertime":{"long":1513471082347},"userid":{"string":"User_2"},"regionid":{"string":"Region_7"},"gender":{"string":"OTHER"}} {"registertime":{"long":1496006007512},"userid":{"string":"User_5"},"regionid":{"string":"Region_6"},"gender":{"string":"OTHER"}} {"registertime":{"long":1494319368203},"userid":{"string":"User_7"},"regionid":{"string":"Region_2"},"gender":{"string":"FEMALE"}} {"registertime":{"long":1493150028737},"userid":{"string":"User_1"},"regionid":{"string":"Region_5"},"gender":{"string":"FEMALE"}} {"registertime":{"long":1517151907191},"userid":{"string":"User_5"},"regionid":{"string":"Region_3"},"gender":{"string":"OTHER"}} {"registertime":{"long":1489672305692},"userid":{"string":"User_2"},"regionid":{"string":"Region_6"},"gender":{"string":"OTHER"}} {"registertime":{"long":1511471447951},"userid":{"string":"User_2"},"regionid":{"string":"Region_5"},"gender":{"string":"MALE"}} {"registertime":{"long":1488018372941},"userid":{"string":"User_7"},"regionid":{"string":"Region_2"},"gender":{"string":"OTHER"}} {"registertime":{"long":1500952152251},"userid":{"string":"User_2"},"regionid":{"string":"Region_1"},"gender":{"string":"MALE"}} {"registertime":{"long":1493556444692},"userid":{"string":"User_1"},"regionid":{"string":"Region_8"},"gender":{"string":"FEMALE"}} Processed a total of 10 messages _schemas: null null null {"subject":"topic1-value","version":1,"id":1,"schema":"{\"type\":\"record\",\"name\":\"KsqlDataSourceSchema\",\"namespace\":\"io.confluent.ksql.avro_schemas\",\"fields\":[{\"name\":\"userid\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"dc\",\"type\":[\"null\",\"string\"],\"default\":null}]}","deleted":false} {"subject":"topic2-value","version":1,"id":2,"schema":"{\"type\":\"record\",\"name\":\"KsqlDataSourceSchema\",\"namespace\":\"io.confluent.ksql.avro_schemas\",\"fields\":[{\"name\":\"registertime\",\"type\":[\"null\",\"long\"],\"default\":null},{\"name\":\"userid\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"regionid\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"gender\",\"type\":[\"null\",\"string\"],\"default\":null}]}","deleted":false} {"subject":"topic2.replica-value","version":1,"id":2,"schema":"{\"type\":\"record\",\"name\":\"KsqlDataSourceSchema\",\"namespace\":\"io.confluent.ksql.avro_schemas\",\"fields\":[{\"name\":\"registertime\",\"type\":[\"null\",\"long\"],\"default\":null},{\"name\":\"userid\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"regionid\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"gender\",\"type\":[\"null\",\"string\"],\"default\":null}]}","deleted":false} [2021-01-04 19:16:09,579] ERROR Error processing message, terminating consumer process: (kafka.tools.ConsoleConsumer$) org.apache.kafka.common.errors.TimeoutException Processed a total of 6 messages provenance info (cluster, topic, timestamp): 2qHo2TsdTIaTjvkCyf3qdw,topic1,1609787778125 2qHo2TsdTIaTjvkCyf3qdw,topic1,1609787779123 2qHo2TsdTIaTjvkCyf3qdw,topic1,1609787780125 2qHo2TsdTIaTjvkCyf3qdw,topic1,1609787781246 2qHo2TsdTIaTjvkCyf3qdw,topic1,1609787782125 Processed a total of 10 messages timestamp info (group: topic-partition): replicator-dc1-to-dc2-topic2: topic2-0 1609787797164 replicator-dc1-to-dc2-topic1: topic1-0 1609787797117 Processed a total of 2 messages cluster id: ZagAAEfORQG-lxwq6OsV5Q -----dc2----- list topics: __consumer_offsets __consumer_timestamps _confluent-command _confluent-controlcenter-6-1-0-1-AlertHistoryStore-changelog _confluent-controlcenter-6-1-0-1-AlertHistoryStore-repartition _confluent-controlcenter-6-1-0-1-Group-ONE_MINUTE-changelog _confluent-controlcenter-6-1-0-1-Group-ONE_MINUTE-repartition _confluent-controlcenter-6-1-0-1-Group-THREE_HOURS-changelog _confluent-controlcenter-6-1-0-1-Group-THREE_HOURS-repartition _confluent-controlcenter-6-1-0-1-KSTREAM-OUTEROTHER-0000000106-store-changelog _confluent-controlcenter-6-1-0-1-KSTREAM-OUTEROTHER-0000000106-store-repartition _confluent-controlcenter-6-1-0-1-KSTREAM-OUTERTHIS-0000000105-store-changelog _confluent-controlcenter-6-1-0-1-KSTREAM-OUTERTHIS-0000000105-store-repartition _confluent-controlcenter-6-1-0-1-MetricsAggregateStore-changelog _confluent-controlcenter-6-1-0-1-MetricsAggregateStore-repartition _confluent-controlcenter-6-1-0-1-MonitoringMessageAggregatorWindows-ONE_MINUTE-changelog _confluent-controlcenter-6-1-0-1-MonitoringMessageAggregatorWindows-ONE_MINUTE-repartition _confluent-controlcenter-6-1-0-1-MonitoringMessageAggregatorWindows-THREE_HOURS-changelog _confluent-controlcenter-6-1-0-1-MonitoringMessageAggregatorWindows-THREE_HOURS-repartition _confluent-controlcenter-6-1-0-1-MonitoringStream-ONE_MINUTE-changelog _confluent-controlcenter-6-1-0-1-MonitoringStream-ONE_MINUTE-repartition _confluent-controlcenter-6-1-0-1-MonitoringStream-THREE_HOURS-changelog _confluent-controlcenter-6-1-0-1-MonitoringStream-THREE_HOURS-repartition _confluent-controlcenter-6-1-0-1-MonitoringTriggerStore-changelog _confluent-controlcenter-6-1-0-1-MonitoringTriggerStore-repartition _confluent-controlcenter-6-1-0-1-MonitoringVerifierStore-changelog _confluent-controlcenter-6-1-0-1-MonitoringVerifierStore-repartition _confluent-controlcenter-6-1-0-1-TriggerActionsStore-changelog _confluent-controlcenter-6-1-0-1-TriggerActionsStore-repartition _confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelog _confluent-controlcenter-6-1-0-1-TriggerEventsStore-repartition _confluent-controlcenter-6-1-0-1-actual-group-consumption-rekey _confluent-controlcenter-6-1-0-1-aggregate-topic-partition-store-changelog _confluent-controlcenter-6-1-0-1-aggregate-topic-partition-store-repartition _confluent-controlcenter-6-1-0-1-aggregatedTopicPartitionTableWindows-ONE_MINUTE-changelog _confluent-controlcenter-6-1-0-1-aggregatedTopicPartitionTableWindows-ONE_MINUTE-repartition _confluent-controlcenter-6-1-0-1-aggregatedTopicPartitionTableWindows-THREE_HOURS-changelog _confluent-controlcenter-6-1-0-1-aggregatedTopicPartitionTableWindows-THREE_HOURS-repartition _confluent-controlcenter-6-1-0-1-cluster-rekey _confluent-controlcenter-6-1-0-1-expected-group-consumption-rekey _confluent-controlcenter-6-1-0-1-group-aggregate-store-ONE_MINUTE-changelog _confluent-controlcenter-6-1-0-1-group-aggregate-store-ONE_MINUTE-repartition _confluent-controlcenter-6-1-0-1-group-aggregate-store-THREE_HOURS-changelog _confluent-controlcenter-6-1-0-1-group-aggregate-store-THREE_HOURS-repartition _confluent-controlcenter-6-1-0-1-group-stream-extension-rekey _confluent-controlcenter-6-1-0-1-metrics-trigger-measurement-rekey _confluent-controlcenter-6-1-0-1-monitoring-aggregate-rekey-store-changelog _confluent-controlcenter-6-1-0-1-monitoring-aggregate-rekey-store-repartition _confluent-controlcenter-6-1-0-1-monitoring-message-rekey-store _confluent-controlcenter-6-1-0-1-monitoring-trigger-event-rekey _confluent-license _confluent-metrics _confluent-monitoring _confluent-telemetry-metrics _confluent_balancer_api_state _confluent_balancer_broker_samples _confluent_balancer_partition_samples _schemas connect-configs-dc2 connect-offsets-dc2 connect-status-dc2 topic1 topic2.replica topic1: {"userid":{"string":"User_2"},"dc":{"string":"dc2"}} {"userid":{"string":"User_1"},"dc":{"string":"dc1"}} {"userid":{"string":"User_6"},"dc":{"string":"dc2"}} {"userid":{"string":"User_9"},"dc":{"string":"dc1"}} {"userid":{"string":"User_9"},"dc":{"string":"dc2"}} {"userid":{"string":"User_9"},"dc":{"string":"dc1"}} {"userid":{"string":"User_9"},"dc":{"string":"dc2"}} {"userid":{"string":"User_9"},"dc":{"string":"dc1"}} {"userid":{"string":"User_9"},"dc":{"string":"dc2"}} {"userid":{"string":"User_9"},"dc":{"string":"dc1"}} Processed a total of 10 messages topic2.replica: {"registertime":{"long":1488571887136},"userid":{"string":"User_2"},"regionid":{"string":"Region_4"},"gender":{"string":"FEMALE"}} {"registertime":{"long":1496554479008},"userid":{"string":"User_3"},"regionid":{"string":"Region_9"},"gender":{"string":"OTHER"}} {"registertime":{"long":1515819037639},"userid":{"string":"User_1"},"regionid":{"string":"Region_7"},"gender":{"string":"FEMALE"}} {"registertime":{"long":1498630829454},"userid":{"string":"User_9"},"regionid":{"string":"Region_5"},"gender":{"string":"FEMALE"}} {"registertime":{"long":1491954362758},"userid":{"string":"User_6"},"regionid":{"string":"Region_6"},"gender":{"string":"FEMALE"}} {"registertime":{"long":1498308706008},"userid":{"string":"User_2"},"regionid":{"string":"Region_2"},"gender":{"string":"OTHER"}} {"registertime":{"long":1509409463384},"userid":{"string":"User_5"},"regionid":{"string":"Region_8"},"gender":{"string":"OTHER"}} {"registertime":{"long":1494736574275},"userid":{"string":"User_4"},"regionid":{"string":"Region_4"},"gender":{"string":"OTHER"}} {"registertime":{"long":1513254638109},"userid":{"string":"User_3"},"regionid":{"string":"Region_5"},"gender":{"string":"FEMALE"}} {"registertime":{"long":1499607488391},"userid":{"string":"User_4"},"regionid":{"string":"Region_2"},"gender":{"string":"OTHER"}} Processed a total of 10 messages _schemas: null null null {"subject":"topic1-value","version":1,"id":1,"schema":"{\"type\":\"record\",\"name\":\"KsqlDataSourceSchema\",\"namespace\":\"io.confluent.ksql.avro_schemas\",\"fields\":[{\"name\":\"userid\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"dc\",\"type\":[\"null\",\"string\"],\"default\":null}]}","deleted":false} {"subject":"topic2-value","version":1,"id":2,"schema":"{\"type\":\"record\",\"name\":\"KsqlDataSourceSchema\",\"namespace\":\"io.confluent.ksql.avro_schemas\",\"fields\":[{\"name\":\"registertime\",\"type\":[\"null\",\"long\"],\"default\":null},{\"name\":\"userid\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"regionid\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"gender\",\"type\":[\"null\",\"string\"],\"default\":null}]}","deleted":false} {"subject":"topic2.replica-value","version":1,"id":2,"schema":"{\"type\":\"record\",\"name\":\"KsqlDataSourceSchema\",\"namespace\":\"io.confluent.ksql.avro_schemas\",\"fields\":[{\"name\":\"registertime\",\"type\":[\"null\",\"long\"],\"default\":null},{\"name\":\"userid\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"regionid\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"gender\",\"type\":[\"null\",\"string\"],\"default\":null}]}","deleted":false} [2021-01-04 19:17:26,336] ERROR Error processing message, terminating consumer process: (kafka.tools.ConsoleConsumer$) org.apache.kafka.common.errors.TimeoutException Processed a total of 6 messages provenance info (cluster, topic, timestamp): ZagAAEfORQG-lxwq6OsV5Q,topic1,1609787854055 ZagAAEfORQG-lxwq6OsV5Q,topic1,1609787854057 ZagAAEfORQG-lxwq6OsV5Q,topic1,1609787856052 ZagAAEfORQG-lxwq6OsV5Q,topic1,1609787857052 ZagAAEfORQG-lxwq6OsV5Q,topic1,1609787857054 Processed a total of 10 messages timestamp info (group: topic-partition): replicator-dc2-to-dc1-topic1: topic1-0 1609787867007 replicator-dc2-to-dc1-topic1: topic1-0 1609787877008 Processed a total of 2 messages cluster id: 2qHo2TsdTIaTjvkCyf3qdw
注釈
Confluent Platform 6.2.1 以降では、_confluent-command 内部トピックが提供され、_confluent-license トピックの代わりに使用することが推奨されており、新しいクラスターでもこれがデフォルトになります。今後は両方がサポートされます。詳細については「コンポーネントライセンスの構成」を参照してください。
Replicator のパフォーマンスのモニタリング¶
Replicator のモニタリングは、以下のために重要です。
- 複数のデータセンター間のデータ同期状態の測定
- ネットワークと Confluent Platform のパフォーマンス最適化
Replicator モニタリング¶
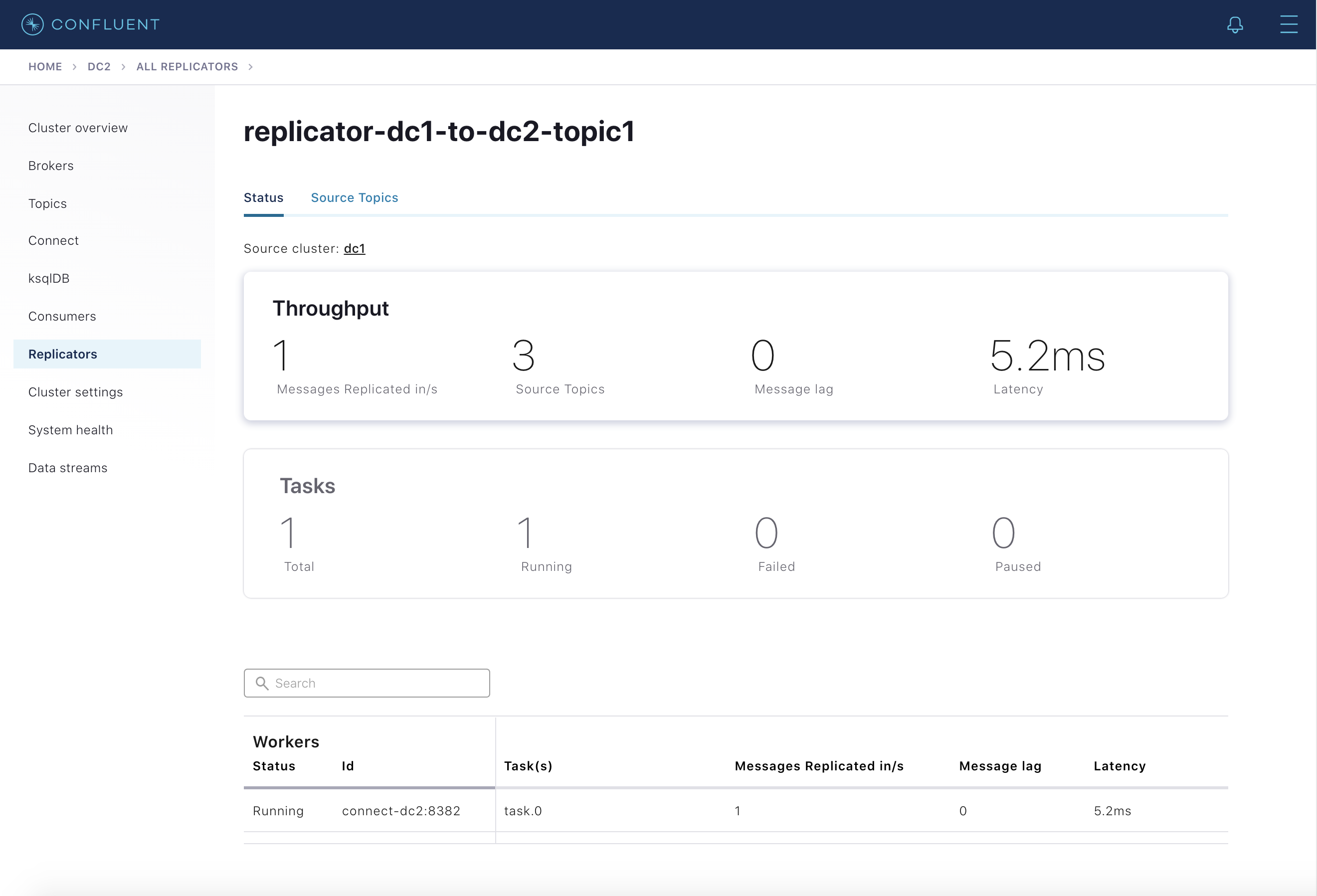
Control Center では、Replicators メニューから Replicator の詳細なモニタリングを確認できます。これを選択すると、現在クラスターで実行されている Replicator インスタンスの概要が表示されます。Replicator ごとに、以下の重要なメトリクスが表示されます。
- Source Cluster - Replicator のレプリケート元になるクラスター
- Source Topics - レプリケートされているトピックの数
- Messages Replicated in/s - 1 秒あたりにレプリケートされたメッセージの数
- Message Lag - 送信元クラスターに存在し、送信先にまだレプリケートされていないメッセージの数
- Latency - メッセージが送信先に存在する時刻と送信元に存在する時刻の差異
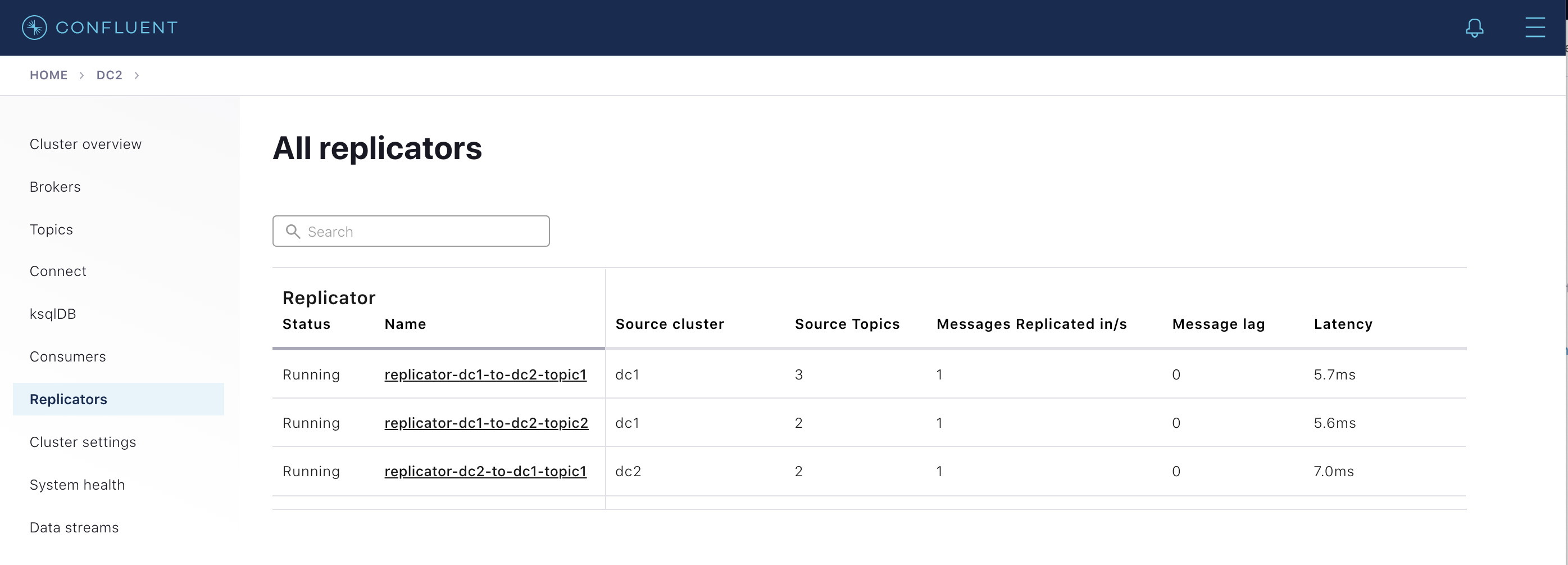
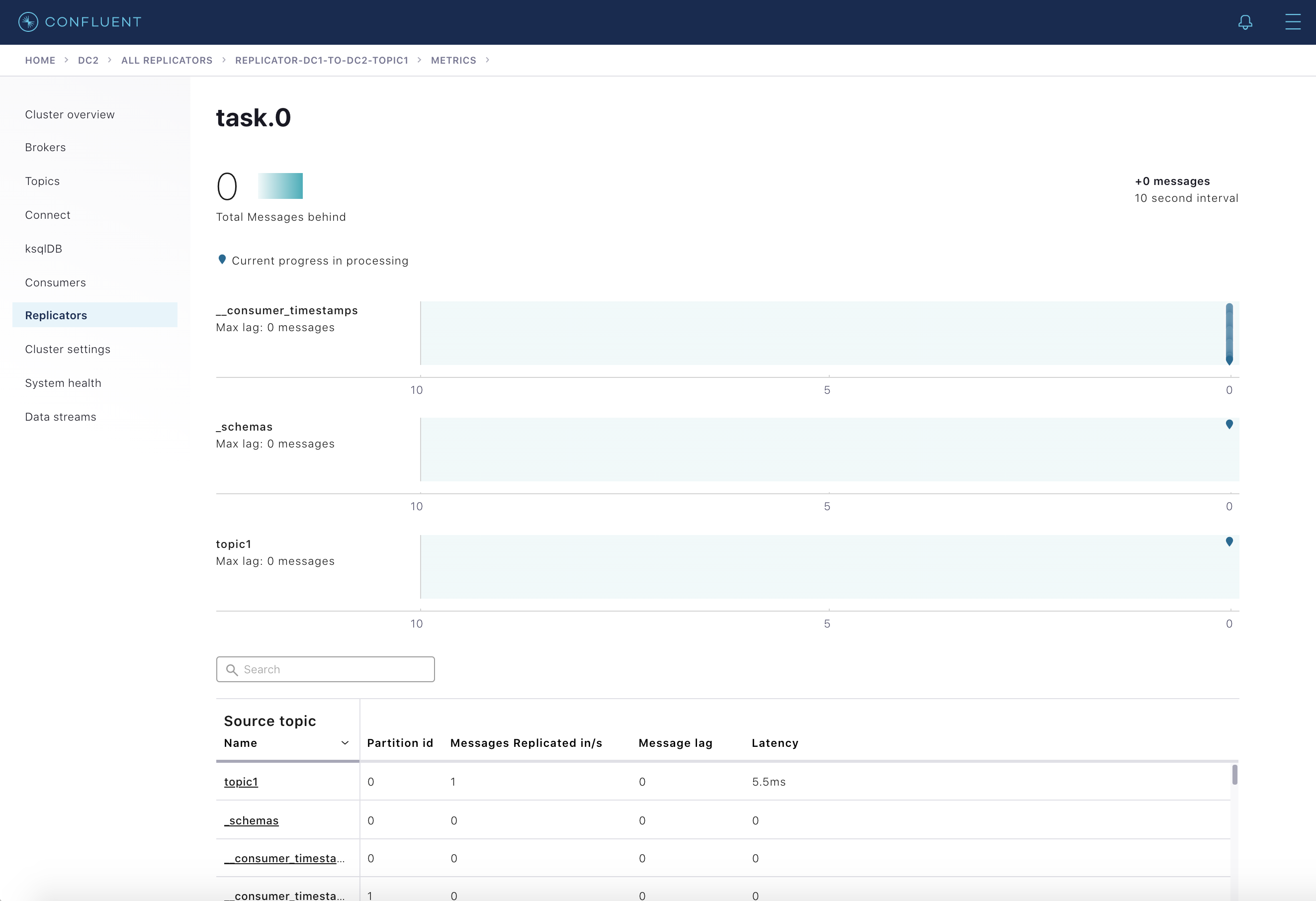
ここに表示される Replicator インスタンスを選択すると、特定のインスタンスに関する詳細が表示されます。Status タブでは前述のメトリクスが Connect タスクごとに表示され、Source Topics タブではそれらがトピックごとに表示されます。
さらに Throughput カードを選択すると、詳しいメッセージラグが Connect タスクごとに表示されます。表示されているいずれかのタスクを選択すると、そのタスクがレプリケートしているパーティションのメトリクスが表示されます。
ストリームモニタリング¶
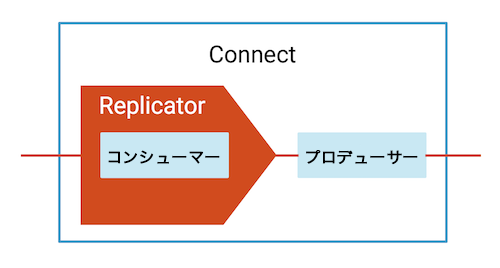
Control Center のモニタリング機能には、ストリームパフォーマンスのモニタリングが含まれています。これにより、すべてのデータが消費されていること、さらにスループットとレイテンシを検証できます。モニタリングは、コンシューマーグループまたはトピック単位で表示されます。Confluent Replicator は、送信元クラスターからデータを読み取る組み込みのコンシューマーを備えているため、Control Center でそのパフォーマンスをモニタリングできます。Replicator のストリームモニタリングを有効にするには、モニタリングコンシューマーインターセプター でこれを構成します。例 を参照してください。
左側のメニューから
dc1Kafka クラスターを選択し、次に Data Streams を選択します。2 つのコンシューマーグループが存在し、それぞれdc1からdc2へと実行されている Replicator インスタンス、replicator-dc1-to-dc2-topic1とreplicator-dc1-to-dc2-topic2のものであることを確認します。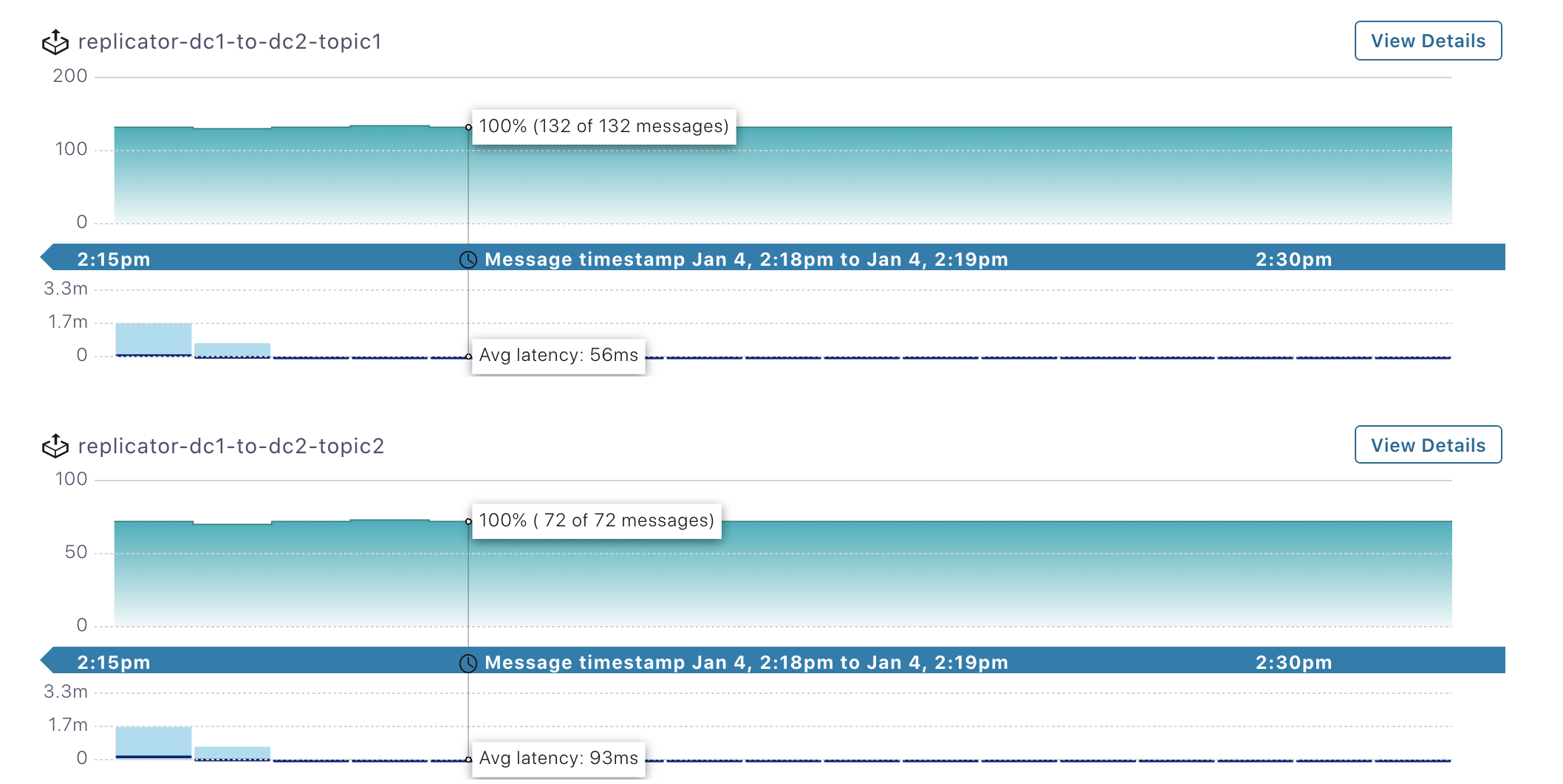
左側のメニューから
dc2Kafka クラスターを選択し、次に Data Streams を選択します。dc2からdc1へと実行されている 1 つのコンシューマーグループ、replicator-dc2-to-dc1-topic1が存在することを確認します。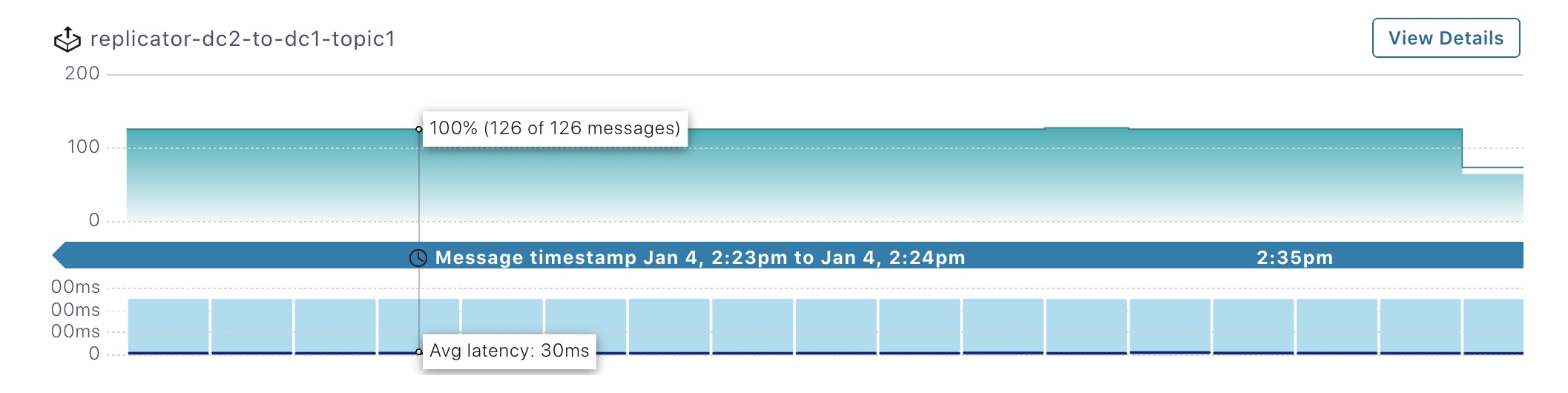
コンシューマーラグ¶
Replicator には送信元クラスターからデータを読み取る組み込みのコンシューマーがあり、Connect ワーカーのプロデューサーが送信先クラスターにデータをコミットした後にのみ、そのオフセットをコミットします(コミットの頻度は offset.flush.interval.ms パラメーターで構成します)。送信元クラスターで Replicator の組み込みコンシューマーのコンシューマーラグをモニタリングできます(dc1 から dc2 にデータをコピーする Replicator インスタンスの場合、送信元クラスターは dc1 です)。Replicator のコンシューマーラグをモニタリングする機能は、offset.topic.commit=true が設定されている場合に有効になります(デフォルトは true)。これにより、Replicator は、送信先クラスターにメッセージが書き込まれた後に自身のコンシューマーオフセットを送信元クラスター dc1 にコミットします。
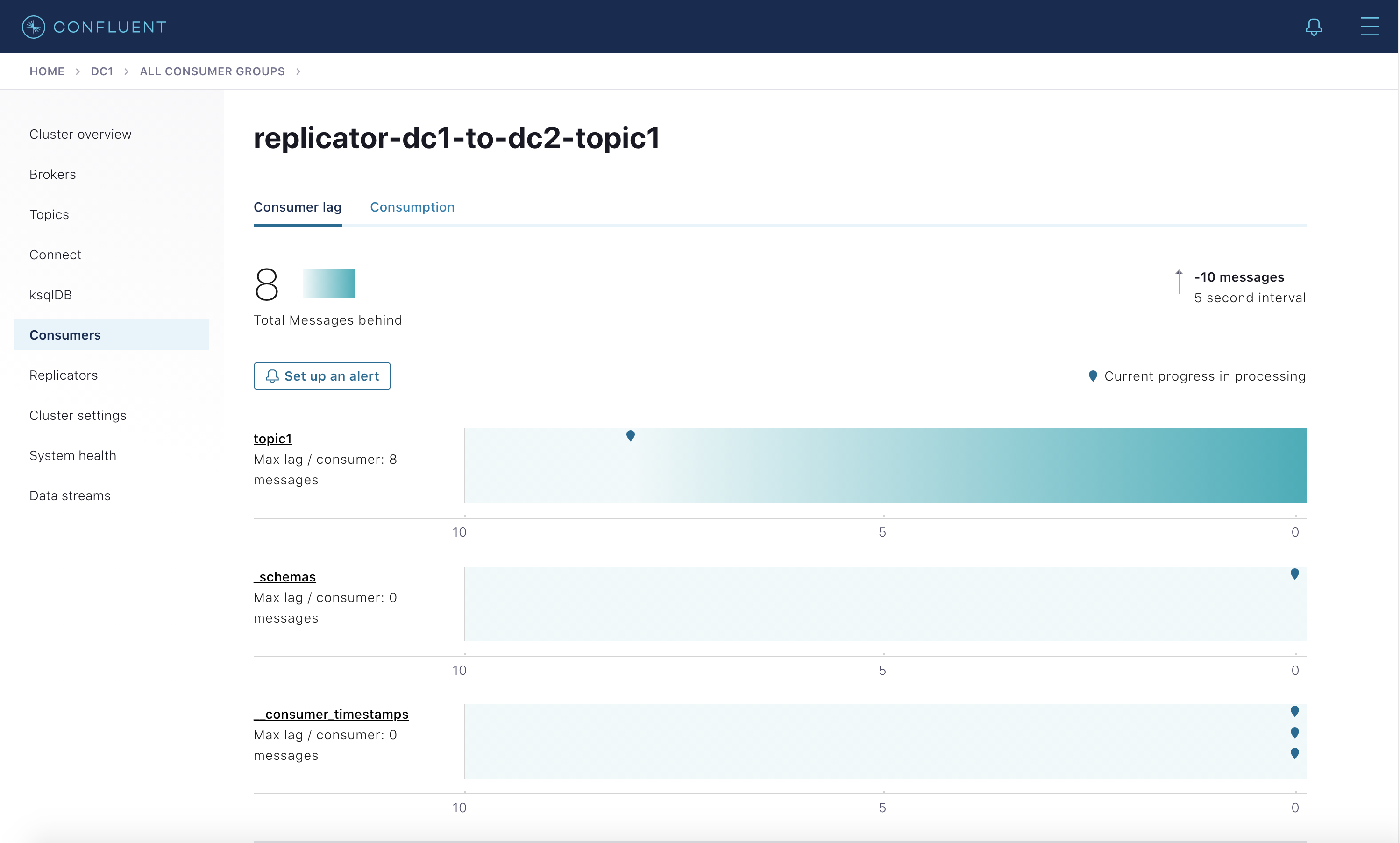
dc1からdc2にコピーする Replicator の場合 : 左側のメニューからdc1(送信元クラスター)を選択し、次に Consumers を選択します。2 つのコンシューマーグループが存在し、それぞれdc1からdc2へと実行されている Replicator インスタンス、replicator-dc1-to-dc2-topic1とreplicator-dc1-to-dc2-topic2のものであることを確認します。Replicator のコンシューマーラグ情報は Control Center およびkafka-consumer-groupsで確認できますが、JMX を通じて取得することはできません。replicator-dc1-to-dc2-topic1をクリックして、topic1および_schemasの読み取り時の Replicator のコンシューマーラグを表示します。この表示は、以下と同等です。docker-compose exec broker-dc1 kafka-consumer-groups --bootstrap-server broker-dc1:29091 --describe --group replicator-dc1-to-dc2-topic1
replicator-dc1-to-dc2-topic2をクリックして、topic2の読み取り時の Replicator のコンシューマーラグを表示します(これはdocker-compose exec broker-dc1 kafka-consumer-groups --bootstrap-server broker-dc1:29091 --describe --group replicator-dc1-to-dc2-topic2に相当します)。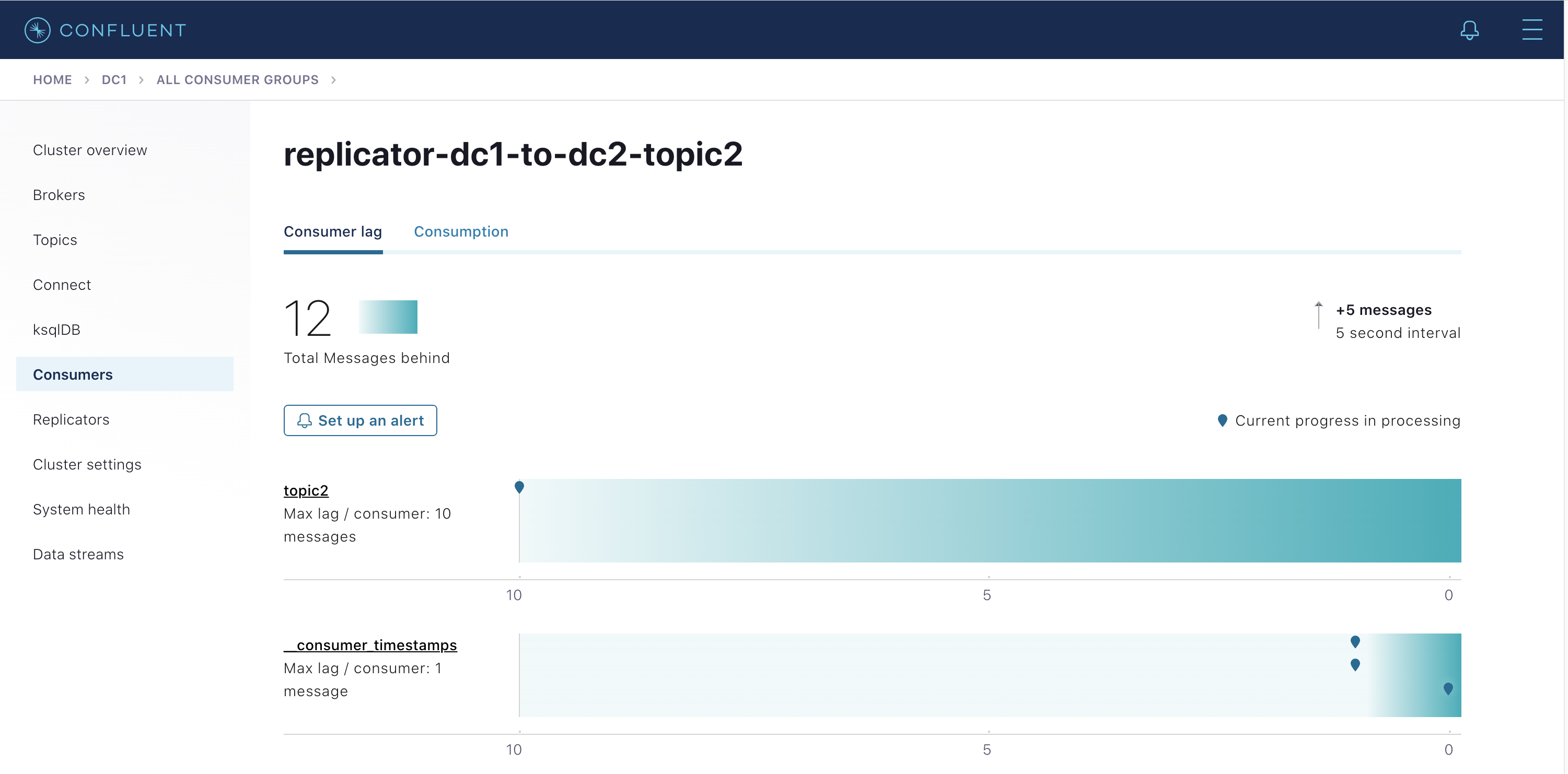
dc1からdc2にコピーする Replicator の場合 : 送信先クラスターdc2で Replicator コンシューマーラグのモニタリングを試行しないでください。Control Center ではdc2内のトピック(つまりtopic1、_schemas、topic2.replica)のコンシューマーラグも表示されますが、これは Replicator がそれらから消費していることを意味しません。dc2でこのコンシューマーラグが表示されるのは、デフォルトで Replicator にoffset.timestamps.commit=trueが構成されているためです。これにより、Replicator は送信先クラスターdc2の__consumer_offsetsトピックにそのコンシューマーグループの自身のオフセットタイムスタンプをコミットします。ディザスターリカバリが発生した場合、これにより Replicator はセカンダリクラスターに切り替えたときでも中止したポイントから再開できるようになります。コンシューマーラグと、Replicator の組み込みコンシューマーに関連付けられている MBean 属性
records-lagを混同しないでください。この属性は、Replicator の組み込みコンシューマーが元のデータ生成レートを維持できているかどうかを反映しますが、送信先クラスターにメッセージを生成するときのレプリケーションラグは考慮していません。records-lagはリアルタイムであり、通常は値が0.0です。docker-compose exec connect-dc2 \ kafka-run-class kafka.tools.JmxTool \ --object-name "kafka.consumer:type=consumer-fetch-manager-metrics,partition=0,topic=topic1,client-id=replicator-dc1-to-dc2-topic1-0" \ --attributes "records-lag" \ --jmx-url service:jmx:rmi:///jndi/rmi://connect-dc2:9892/jmxrmi
フェイルオーバー後のアプリケーションの再開¶
障害が発生したら、Java コンシューマーアプリケーションを別のデータセンターに切り替えます。送信先クラスターでは、アプリケーションは送信元クラスターで中止したポイントからデータの消費を自動的に再開できます。
この機能を使用するには、コンシューマータイムスタンプインターセプター で Java コンシューマーアプリケーションを構成します。このサンプルコードは こちら で公開されています。
デモの開始(前のセクション を参照)後に、コンシューマーを実行して
dc1Kafka クラスターに接続します。コンシューマーグループ ID が自動的にjava-consumer-topic1として構成され、コンシューマータイムスタンプインターセプターとモニタリングインターセプターが使用されます。mvn clean package mvn exec:java -Dexec.mainClass=io.confluent.examples.clients.ConsumerMultiDatacenterExample -Dexec.args="topic1 localhost:9091 http://localhost:8081 localhost:9092"
コンシューマー出力で、dc1 と dc2 の両方からデータを読み取っていることを確認します。
... key = User_1, value = {"userid": "User_1", "dc": "dc1"} key = User_9, value = {"userid": "User_9", "dc": "dc2"} key = User_6, value = {"userid": "User_6", "dc": "dc2"} ...
コンシューマーが dc1 から消費している場合でも、コンシューマーグループ
java-consumer-topic1に対してコミットされた dc2 コンシューマーオフセットが存在します。以下のコマンドを実行して、dc2 の__consumer_offsetsトピックから読み取ります。docker-compose exec broker-dc2 \ kafka-console-consumer \ --topic __consumer_offsets \ --bootstrap-server localhost:9092 \ --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" | grep java-consumer
コミットされたオフセットが存在することを確認します。
... [java-consumer-topic1,topic1,0]::OffsetAndMetadata(offset=1142, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1547146285084, expireTimestamp=None) [java-consumer-topic1,topic1,0]::OffsetAndMetadata(offset=1146, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1547146286082, expireTimestamp=None) [java-consumer-topic1,topic1,0]::OffsetAndMetadata(offset=1150, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1547146287084, expireTimestamp=None) ...
Kafka クライアントで Confluent Monitoring Interceptor が構成されている場合、これらはメタデータを
_confluent-monitoringというトピックに書き込みます。Kafka クライアントには、Apache Kafka クライアント API を使用して Kafka ブローカーに接続するアプリケーション(カスタムクライアントコードなど)、または組み込みのプロデューサーまたはコンシューマーを備えたサービス(Kafka Connect、ksqlDB、Kafka Streams アプリケーションなど)が含まれています。Control Center はそのトピックを使用して、すべてのメッセージが配信されていることを確認し、スループットとレイテンシのパフォーマンスに関する統計を提供します。その同じトピックから、どのプロデューサーがどのトピックに書き込んでいるか、どのコンシューマーがどのトピックから読み取っているかも確認できます。また、リポジトリにはサンプルの スクリプト が含まれています。./map_topics_clients.py
注釈
このスクリプトはデモ専用です。本稼働環境には適していません。
Java コンシューマーが実行されている安定した状態では、以下のように表示されます。
Reading topic _confluent-monitoring for 60 seconds...please wait __consumer_timestamps producers consumer-1 producer-10 producer-11 producer-6 producer-8 consumers replicator-dc1-to-dc2-topic1 replicator-dc1-to-dc2-topic2 replicator-dc2-to-dc1-topic1 _schemas producers connect-worker-producer-dc2 consumers replicator-dc1-to-dc2-topic1 topic1 producers connect-worker-producer-dc1 connect-worker-producer-dc2 datagen-dc1-topic1 datagen-dc2-topic1 consumers java-consumer-topic1 replicator-dc1-to-dc2-topic1 replicator-dc2-to-dc1-topic1 topic2 producers datagen-dc1-topic2 consumers replicator-dc1-to-dc2-topic2 topic2.replica producers connect-worker-producer-dc2
dc1をシャットダウンします。docker-compose stop connect-dc1 schema-registry-dc1 broker-dc1 zookeeper-dc1
コンシューマーを停止してから再起動して、
dc2Kafka クラスターに接続します。同じコンシューマーグループ ID、java-consumer-topic1を引き続き使用するため、中止したポイントから再開できます。mvn exec:java -Dexec.mainClass=io.confluent.examples.clients.ConsumerMultiDatacenterExample -Dexec.args="topic1 localhost:9092 http://localhost:8082 localhost:9092"
dc2からのデータのみが表示されることを確認します。... key = User_8, value = {"userid": "User_8", "dc": "dc2"} key = User_9, value = {"userid": "User_9", "dc": "dc2"} key = User_5, value = {"userid": "User_5", "dc": "dc2"} ...
デモの停止¶
デモを終了する場合は、デモを停止して Docker コンテナーとイメージを削除します。
以下のスクリプトを実行してすべてのサービスを停止し、Docker コンテナーとイメージを削除します。
./stop.sh
以下のコマンドを実行して、実行されているコンテナーが存在しないことを確認します。
docker container ls
次のステップ¶
- 障害シナリオの発生時の回復性を高めるように複数の Apache Kafka クラスターを設計および構成するための実用的なガイドについては、ディザスターリカバリに関するホワイトペーパー を参照してください。このホワイトペーパーでは、フェイルオーバーとフェイルバックを行い、最終的にリカバリを成功させるための計画について説明しています。
- データレプリケーションに Confluent Platform を使用する方法の概要については、「Overview」を参照してください。
- Replicator を構成して独自のマルチクラスターデプロイをセットアップする方法のクイックスタートについては、「チュートリアル: クラスターの境界を越えたデータのレプリケーション」を参照してください。
- Replicator の概要については、「Replicator の概要」を参照してください。
- Confluent Platform を使用してフォロワー、オブザーバー、レプリカ配置を含むストレッチクラスターを作成する方法については、「Multi-Region Clusters」を参照してください。