チュートリアル: マルチリージョンクラスター¶
概要¶
このチュートリアルでは、Confluent Server 内に直接組み込まれる Multi-Region Clusters 機能を説明します。
Multi-Region Clusters では、利用者は複数のデータセンター間で 1 つの Apache Kafka® クラスターを実行できます。Multi-Region Clusters は、ストレッチクラスターと呼ばれることも多く、リージョンの複数のアベイラビリティゾーンにわたるデータセンター間でデータをレプリケートします。データをレプリケートする方法としては、Kafka トピックごとに同期または非同期を選択できます。優れた永続性が保証されており、ディザスターリカバリ(DR)がはるかに容易になります。
利点:
- データセンター間における、同期および非同期レプリケーションのマルチサイトデプロイをサポートします
- コンシューマーは、データのローカル性を活用して Kafka データを読み取ることができます。つまり、パフォーマンスが向上し、コストが低下します
- Kafka メッセージの順序がデータセンター間で維持されます
- コンシューマーオフセットが維持されます
- データセンターで災害が発生した場合は、他のデータセンターで、同期レプリケーション向けに構成されたトピックのために新しいリーダーが自動的に選ばれ、アプリケーションは中断されずに進行するため、これらのトピックについて非常に低い RTO および RPO=0 が実現されます。
概念¶
レプリカ は、トピックのパーティションに割り当てられたブローカーであり、"リーダー"、"フォロワー"、"オブザーバー" のいずれかになります。"リーダー" とは、プロデューサーのメッセージを受け入れるブローカー/レプリカです。"フォロワー" とは、ISR リストを結合し、最高水準点(メッセージの受信確認をプロデューサーに返信するときにリーダーが使用する)の計算に参加することができるブローカー/レプリカです。
ISR リスト(同期レプリカ)には、特定のトピックパーティションを持つブローカーが含まれます。リーダーから、ISR のすべてのメンバーにデータがコピーされた後に、プロデューサーが受信確認を受け取ります。ISR のフォロワーは、現在のリーダーに障害が発生した場合はリーダーになることができます。
オブザーバー もブローカー/レプリカであり、特定のトピックパーティションのデータのコピーを保持します。オブザーバー はリーダーではありませんが、コンシューマーはオブザーバーから読み取ることができます。この動作は、"フォロワーフェッチ" と呼ばれます。ただし、データはリーダーから非同期でコピーされるので、プロデューサーはオブザーバーからの受信確認の返信を待機しません。
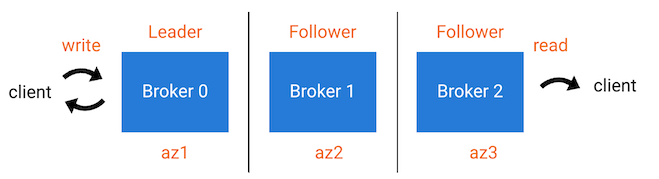
"機能低下のない" 定常状態の場合、オブザーバーは ISR リストに加わらず、リーダーになることはありません。ISR のブローカーに障害が発生した場合、手作業によるリーダーの割り当ての変更、または自動的な オブザーバーの自動昇格 の 2 つのうちいずれかの方法で、オブザーバーが昇格され ISR リストに加わることができます。オブザーバーの自動昇格 は、特定の "機能低下" のある状況で、オブザーバーが ISR に昇格されるプロセスです。オブザーバーが自動的に ISR に昇格されるかどうかの条件は、トピックのレプリカ配置ポリシーの observerPromotionPolicy フィールドで制御されます。
under-min-isr: ISR のレプリカの数がトピックのmin.insync.replicasの構成を下回るかどうか。under-replicated: ISR のレプリカの数がトピックのレプリカ配置ポリシーで構成されているレプリカ数を下回るかどうか。leader-is-observer: 現在のパーティションリーダーがオブザーバーかどうか。
ちなみに
これらの概念と構成の詳細については、「マルチリージョンクラスター」を参照してください。
構成¶
このチュートリアルのシナリオは、次のとおりです。
- 3 つのリージョン :
west、central、およびeast - ブローカーの命名規則 :
broker-[region]-[broker_id]
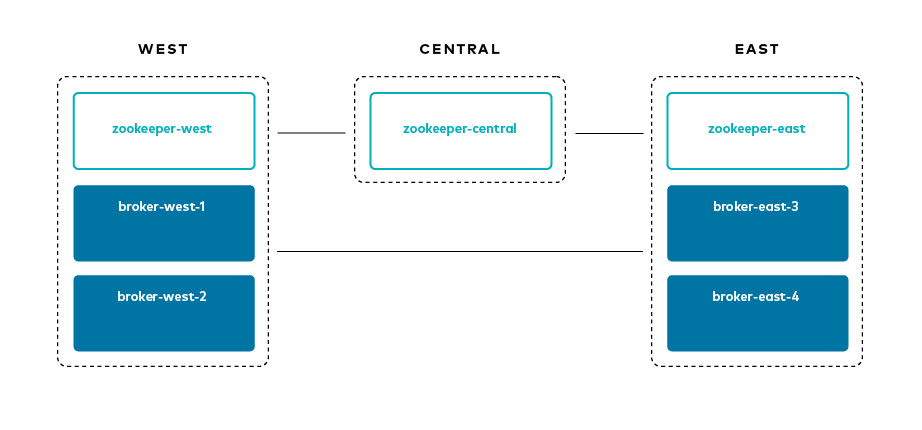
このチュートリアルでは、専用の Kafka クラスターを使用して Confluent Control Center をサポートし、マルチリージョンクラスターをモニタリングします。
関連する、さまざまなコンポーネントレベルの構成パラメーターをいくつか紹介します。
ブローカー¶
すべてのブローカー構成は docker-compose.yml ファイル で調べることができます。最も重要な構成パラメーターは、以下のとおりです。
broker.rack: ブローカーの場所を示します。たとえば、eastまたはwestというリージョンを表します。replica.selector.class=org.apache.kafka.common.replica.RackAwareReplicaSelector: クライアントがフォロワーから読み取ることができるようにします(対照的に、クライアントは、通常はリーダーからのみ読み取ることができます)。confluent.log.placement.constraints: 新規作成されたトピックに、デフォルトのレプリカ配置制約構成を設定します。confluent.metrics.reporter.bootstrap.serversおよびconfluent.monitoring.interceptor.bootstrap.servers: 専用のメトリクスクラスターにメトリクスを送信します。
クライアント¶
client.rack: クライアントの場所を示します。たとえば、eastまたはwestというリージョンを表します。replication.factor: トピックレベルでは、レプリケーション係数とレプリカ配置制約は同時に使用できないため、Kafka Streams アプリケーション用に、replication.factor=-1を設定してレプリカ配置制約が優先されるようにします。min.insync.replicas: 永続性の保証が、レプリカ配置とmin.insync.replicasによって実現されます。各リージョンの フォロワー数は、min.insync.replicasの条件を満たすのに十分である必要があります。たとえば、min.insync.replicas=3の場合は、westに 3 つのレプリカ、eastに 3 つのレプリカが必要です。
トピック¶
--replica-placement <path-to-replica-placement-policy-json>: トピックの作成時に、この引数によって特定のトピックのレプリカ配置ポリシーが定義されます。
チュートリアルのダウンロードと実行¶
confluentinc/examples GitHub リポジトリのクローンを作成し、
7.1.1-postブランチをチェックアウトします。git clone https://github.com/confluentinc/examples
cd examplesgit checkout 7.1.1-post次のコマンドを実行して、Multi-Region Clusters のディレクトリに移動します。
cd multiregion
Multi-Region Clusters に慣れる必要がある新規ユーザーには、このチュートリアルの手順を自分で操作して完了することをお勧めします。その場合は、次のセクションまでスキップ してください。
または、チュートリアルの手順をすべて自動化する次のスクリプトで、チュートリアル全体をエンドツーエンドで実行することもできます。
./scripts/start.sh
自動化されたデモを実行してプロンプトに戻るまでには数分かかります。進捗状況は、出力を手動のステップのワークフローおよびコード例と比較することで把握できます。デモを途中で停止するには、Ctrl キーを押しながら C キーを押します。
このスクリプトを実行した後は、必ず「チュートリアルの停止と終了後の手順」の説明に従ってすべてのサービスを停止し、Docker 環境をクリーンアップしてください。
起動¶
この Multi-Region Clusters のサンプルでは、トラフィックコントロール(
tc)を使用して、リージョン間のレイテンシとパケット損失を挿入することで WAN リンクのシミュレーションを行います。Confluent の UBI ベースの Docker イメージにはtcがインストールされていないため、tcを含むカスタム Docker イメージを構築します。./scripts/build_docker_images.sh
すべての Docker コンテナーを起動します。
docker-compose up -d
docker-compose psで、次の Docker コンテナーを表示します。Name Command State Ports ---------------------------------------------------------------------------------------------------------------- broker-ccc /etc/confluent/docker/run Up 0.0.0.0:8098->8098/tcp, 9092/tcp, 0.0.0.0:9098->9098/tcp broker-east-3 /etc/confluent/docker/run Up 0.0.0.0:8093->8093/tcp, 9092/tcp, 0.0.0.0:9093->9093/tcp broker-east-4 /etc/confluent/docker/run Up 0.0.0.0:8094->8094/tcp, 9092/tcp, 0.0.0.0:9094->9094/tcp broker-west-1 /etc/confluent/docker/run Up 0.0.0.0:8091->8091/tcp, 0.0.0.0:9091->9091/tcp, 9092/tcp broker-west-2 /etc/confluent/docker/run Up 0.0.0.0:8092->8092/tcp, 0.0.0.0:9092->9092/tcp control-center /etc/confluent/docker/run Up 0.0.0.0:9021->9021/tcp zookeeper-ccc /etc/confluent/docker/run Up 2181/tcp, 0.0.0.0:2188->2188/tcp, 2888/tcp, 3888/tcp zookeeper-central /etc/confluent/docker/run Up 2181/tcp, 0.0.0.0:2182->2182/tcp, 2888/tcp, 3888/tcp zookeeper-east /etc/confluent/docker/run Up 2181/tcp, 0.0.0.0:2183->2183/tcp, 2888/tcp, 3888/tcp zookeeper-west /etc/confluent/docker/run Up 0.0.0.0:2181->2181/tcp, 2888/tcp, 3888/tcp
レイテンシとパケット損失の挿入¶
以下の図は、リージョンと WAN リンクの間のレイテンシのシミュレーションを示したものです。
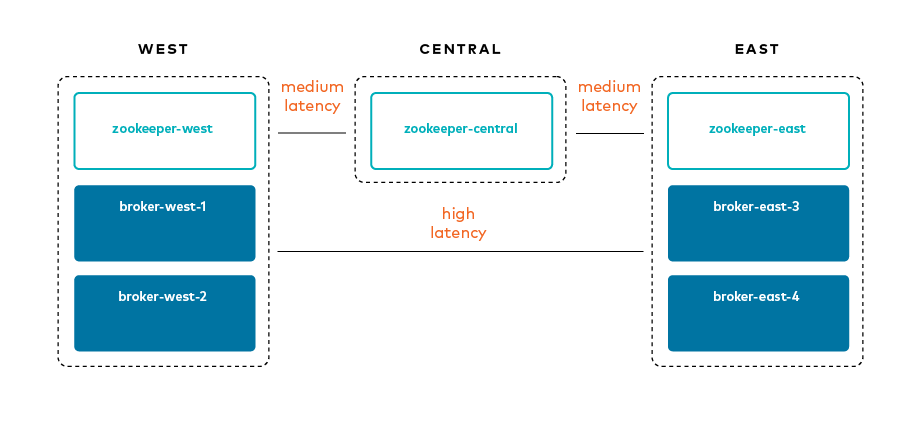
Docker がサンプルに使用する IP アドレスを表示します。
docker inspect -f '{{.Name}} - {{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' $(docker ps -aq)スクリプト latency_docker.sh を実行して、Docker コンテナーで
tcを構成します。./scripts/latency_docker.sh
レプリカ配置¶
このチュートリアルでは、さまざまなトピックを使用して Multi-Region Clusters の原則を解説します。
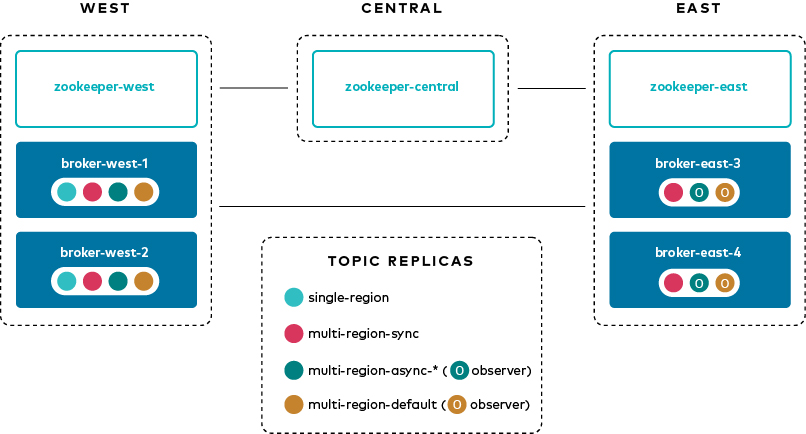
各トピックには、一致する制約のセット(たとえば、replicas と observers に対応する count と rack )を指定するレプリカ配置ポリシーがあります。レプリカ配置ポリシーのファイルは、前述の引数 --replica-placement <path-to-replica-placement-policy-json> で定義されます(このファイルは config ディレクトリにあります)。各配置には、最小 count が関連付けられており、これにより、クラスター全体でレプリカの一定の規模が保証されます。
このチュートリアルでは、次のトピックを作成します。スクリプト create-topics.sh を実行して、すべてのトピックを作成することができますが、必要な引数を示すために、各トピックの作成手順をわかりやすく説明します。
| トピック名 | リーダー | フォロワー(同期レプリカ) | オブザーバー(非同期レプリカ) | ISR リスト | デフォルトのレプリカ配置制約の使用 | オブザーバーの昇格ポリシー |
|---|---|---|---|---|---|---|
| single-region | 1x west | 1x west | (なし) | {1,2} | × | なし |
| multi-region-sync | 1x west | 1x west、2x east | (なし) | {1,2,3,4} | × | なし |
| multi-region-async | 1x west | 1x west | 2x east | {1,2} | × | なし |
| multi-region-async-op-under-min-isr | 1x west | 1x west | 2x east | {1,2} | × | under-min-isr |
| multi-region-async-op-under-replicated | 1x west | 1x west | 2x east | {1,2} | × | under-replicated |
| multi-region-async-op-leader-is-observer | 1x west | 1x west | 2x east | {1,2} | × | leader-is-observer |
| multi-region-default | 1x west | 1x west | 2x east | {1,2} | ○ | なし |
Kafka トピック
single-regionを作成します。docker-compose exec broker-west-1 kafka-topics --create \ --bootstrap-server broker-west-1:19091 \ --topic single-region \ --partitions 1 \ --replica-placement /etc/kafka/demo/placement-single-region.json \ --config min.insync.replicas=1
このトピックのレプリカ配置ポリシー placement-single-region.json は、以下のとおりです。
{ "version": 1, "replicas": [ { "count": 2, "constraints": { "rack": "west" } } ] }Kafka トピック
multi-region-syncを作成します。docker-compose exec broker-west-1 kafka-topics --create \ --bootstrap-server broker-west-1:19091 \ --topic multi-region-sync \ --partitions 1 \ --replica-placement /etc/kafka/demo/placement-multi-region-sync.json \ --config min.insync.replicas=1
このトピックのレプリカ配置ポリシー placement-multi-region-sync.json は、以下のとおりです。
{ "version": 1, "replicas": [ { "count": 2, "constraints": { "rack": "west" } }, { "count": 2, "constraints": { "rack": "east" } } ] }Kafka トピック
multi-region-asyncを作成します。docker-compose exec broker-west-1 kafka-topics --create \ --bootstrap-server broker-west-1:19091 \ --topic multi-region-async \ --partitions 1 \ --replica-placement /etc/kafka/demo/placement-multi-region-async.json \ --config min.insync.replicas=1
このトピックのレプリカ配置ポリシー placement-multi-region-async.json は、以下のとおりです。
{ "version": 1, "replicas": [ { "count": 2, "constraints": { "rack": "west" } } ], "observers": [ { "count": 2, "constraints": { "rack": "east" } } ] }Kafka トピック
multi-region-async-op-under-min-isrを作成します。docker-compose exec broker-west-1 kafka-topics \ --create \ --bootstrap-server broker-west-1:19091 \ --topic multi-region-async-op-under-min-isr \ --partitions 1 \ --replica-placement /etc/kafka/demo/placement-multi-region-async-op-under-min-isr.json \ --config min.insync.replicas=2
このトピックのレプリカ配置ポリシー placement-multi-region-async-op-under-min-isr.json は、以下のとおりです。
{ "version": 2, "replicas": [ { "count": 2, "constraints": { "rack": "west" } } ], "observers": [ { "count": 2, "constraints": { "rack": "east" } } ], "observerPromotionPolicy":"under-min-isr" }Kafka トピック
multi-region-async-op-under-replicatedを作成します。docker-compose exec broker-west-1 kafka-topics \ --create \ --bootstrap-server broker-west-1:19091 \ --topic multi-region-async-op-under-replicated \ --partitions 1 \ --replica-placement /etc/kafka/demo/placement-multi-region-async-op-under-replicated.json \ --config min.insync.replicas=1
このトピックのレプリカ配置ポリシー placement-multi-region-async-op-under-replicated.json は、以下のとおりです。
{ "version": 2, "replicas": [ { "count": 2, "constraints": { "rack": "west" } } ], "observers": [ { "count": 2, "constraints": { "rack": "east" } } ], "observerPromotionPolicy":"under-replicated" }Kafka トピック
multi-region-async-op-leader-is-observerを作成します。docker-compose exec broker-west-1 kafka-topics \ --create \ --bootstrap-server broker-west-1:19091 \ --topic multi-region-async-op-leader-is-observer \ --partitions 1 \ --replica-placement /etc/kafka/demo/placement-multi-region-async-op-leader-is-observer.json \ --config min.insync.replicas=1
このトピックのレプリカ配置ポリシー placement-multi-region-async-op-leader-is-observer.json は、以下のとおりです。
{ "version": 2, "replicas": [ { "count": 2, "constraints": { "rack": "west" } } ], "observers": [ { "count": 2, "constraints": { "rack": "east" } } ], "observerPromotionPolicy":"leader-is-observer" }Kafka トピック
multi-region-defaultを作成します。--replica-placement引数が、デフォルトの配置制約を示すために使用されていないことに注意してください。docker-compose exec broker-west-1 kafka-topics \ --create \ --bootstrap-server broker-west-1:19091 \ --topic multi-region-default \ --config min.insync.replicas=1
スクリプト describe-topics.sh を実行して、トピックのレプリカ配置を表示します。
./scripts/describe-topics.sh
出力は以下のようになります。
==> Describe topic: single-region Topic: single-region PartitionCount: 1 ReplicationFactor: 2 Configs: min.insync.replicas=1,confluent.placement.constraints={"version":1,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[]} Topic: single-region Partition: 0 Leader: 2 Replicas: 2,1 Isr: 2,1 Offline: ==> Describe topic: multi-region-sync Topic: multi-region-sync PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"version":1,"replicas":[{"count":2,"constraints":{"rack":"west"}},{"count":2,"constraints":{"rack":"east"}}],"observers":[]} Topic: multi-region-sync Partition: 0 Leader: 1 Replicas: 1,2,3,4 Isr: 1,2,3,4 Offline: ==> Describe topic: multi-region-async Topic: multi-region-async PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"version":1,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-async Partition: 0 Leader: 2 Replicas: 2,1,3,4 Isr: 2,1 Offline: Observers: 3,4 ==> Describe topic: multi-region-async-op-under-min-isr Topic: multi-region-async-op-under-min-isr PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=2,confluent.placement.constraints={"observerPromotionPolicy":"under-min-isr","version":2,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-async-op-under-min-isr Partition: 0 Leader: 2 Replicas: 2,1,3,4 Isr: 2,1 Offline: Observers: 3,4 ==> Describe topic: multi-region-async-op-under-replicated Topic: multi-region-async-op-under-replicated PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"observerPromotionPolicy":"under-replicated","version":2,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-async-op-under-replicated Partition: 0 Leader: 2 Replicas: 2,1,3,4 Isr: 2,1 Offline: Observers: 3,4 ==> Describe topic: multi-region-async-op-leader-is-observer Topic: multi-region-async-op-leader-is-observer PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"observerPromotionPolicy":"leader-is-observer","version":2,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-async-op-leader-is-observer Partition: 0 Leader: 2 Replicas: 2,1,3,4 Isr: 2,1 Offline: Observers: 3,4 ==> Describe topic: multi-region-default Topic: multi-region-default PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"version":1,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-default Partition: 0 Leader: 2 Replicas: 2,1,3,4 Isr: 2,1 Offline: Observers: 3,4Confluent Control Center でトピックのレプリカ配置を表示します。
Confluent Control Center UI(http://localhost:9021)に移動します。

2 つのクラスターを確認します。1 つは "mrc" で、マルチリージョンクラスターです。もう 1 つは "metrics" で、Confluent Control Center を実行する、専用のメトリクスクラスターです。Confluent Control Center を専用の Kafka クラスターで支援するため、モニタリング対象の本稼働環境のクラスターの可用性に依存しません。このチュートリアルのこれ以降では、"mrc" クラスター内のトピックを操作します。"mrc" クラスターをクリックして、"Topics" セクションを開きます。

各トピックをクリックして、レプリカとオブザーバーの配置の詳細を確認します。Confluent Control Center は、上記の CLI の出力に対応します。以下に
multi-region-asyncトピックの例を示します。
次のことを確認してください。
multi-region-async、multi-region-async-op-under-min-isr、multi-region-async-op-under-replicated、multi-region-async-op-leader-is-observer、およびmulti-region-defaultトピックのレプリカが、westおよびeastリージョンの両方にありますが、1 と 2 のみが ISR に含まれ、3 と 4 はオブザーバーです。これは、CLI の出力または Confluent Control Center で確認できます。
クライアントのパフォーマンス¶
プロデューサー¶
プロデューサーパフォーマンステストスクリプト run-producer.sh を実行します。
./scripts/run-producer.sh
パフォーマンスの結果が次のように表示されることを検証します。
==> Produce: Single-region Replication (topic: single-region) 5000 records sent, 240.453977 records/sec (1.15 MB/sec), 10766.48 ms avg latency, 17045.00 ms max latency, 11668 ms 50th, 16596 ms 95th, 16941 ms 99th, 17036 ms 99.9th. ==> Produce: Multi-region Sync Replication (topic: multi-region-sync) 100 records sent, 2.145923 records/sec (0.01 MB/sec), 34018.18 ms avg latency, 45705.00 ms max latency, 34772 ms 50th, 44815 ms 95th, 45705 ms 99th, 45705 ms 99.9th. ==> Produce: Multi-region Async Replication to Observers (topic: multi-region-async) 5000 records sent, 228.258388 records/sec (1.09 MB/sec), 11296.69 ms avg latency, 18325.00 ms max latency, 11866 ms 50th, 17937 ms 95th, 18238 ms 99th, 18316 ms 99.9th.
次のことを確認してください。
- 1 番目と 3 番目のケースで、
single-regionおよびmulti-region-asyncトピックのスループットパフォーマンスはほぼ同じです(前の例ではそれぞれ1.15 MB/secと1.09 MB/sec)。これは、westリージョンのレプリカのみが受信確認を送信する必要があるためです。 - 2 番目の
multi-region-syncトピックのケースでは、eastおよびwestリージョン間のネットワーク帯域幅が狭く、この両リージョンのブローカーによって ISR が構成されているため、スループットが大幅に低下しています(前の例では0.01 MB/sec)。これは、プロデューサーが、westとeastのメンバーが含まれる ISR のすべてのメンバーからackを受信するまで待機してから処理を続行するためです。 - 3 番目のトピック
multi-region-asyncのケースのオブザーバーは、プロデューサーの全体的なスループットには影響しません。これは、westリージョンがackをプロデューサーに返信するのは、プロデューサーがwestリージョンで 2 回レプリケートされた後であり、プロデューサーは、eastリージョンへの非同期コピーを待機しないためです。 - この例では、
multi-region-defaultに対する生成は行われません。これは、同じ構成を持つmulti-region-asyncと動作が同じであるためです。
- 1 番目と 3 番目のケースで、
コンシューマー¶
コンシューマーパフォーマンステストスクリプト run-consumer.sh を実行します。このとき、コンシューマーは
eastです。./scripts/run-consumer.sh
パフォーマンスの結果が次のように表示されることを検証します。
==> Consume from east: Multi-region Async Replication reading from Leader in west (topic: multi-region-async) start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec 2019-09-25 17:10:27:266, 2019-09-25 17:10:53:683, 23.8419, 0.9025, 5000, 189.2721, 1569431435702, -1569431409285, -0.0000, -0.0000 ==> Consume from east: Multi-region Async Replication reading from Observer in east (topic: multi-region-async) start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec 2019-09-25 17:10:56:844, 2019-09-25 17:11:02:902, 23.8419, 3.9356, 5000, 825.3549, 1569431461383, -1569431455325, -0.0000, -0.0000
次のことを確認してください。
- 1 番目のシナリオでは、
eastで動作しているコンシューマーは、westのリーダーから読み取り、eastとwest` の間の狭い帯域幅の影響を受けます。このケースでは、コンシューマーのスループットが低くなります(前の例では毎秒 ``0.9025MB)。 - 2 番目のシナリオでは、
eastで実行されているコンシューマーは、やはりeastのフォロワーから読み取ります。このケースでは、コンシューマーのスループットが高くなります(前の例では3.9356MB/秒)。 - この例では、
multi-region-defaultからの消費は行われません。これは、同じ構成を持つmulti-region-asyncと動作が同じであるためです。
- 1 番目のシナリオでは、
モニタリング¶
Confluent Server には、トピックのパーティションの正常性とステートを調べるためにモニタリングする必要がある JMX メトリクスがいくつかあります。このチュートリアルでは、次の JMX メトリクスを説明します。関連する他の JMX メトリクスについては、「メトリクス」を参照してください。
ReplicasCount- JMX での完全なオブジェクト名はkafka.cluster:type=Partition,name=ReplicasCount,topic=<topic-name>,partition=<partition-id>です。トピックのパーティションに割り当てられているレプリカ(同期レプリカとオブザーバー)の数をレポートします。InSyncReplicasCount- JMX での完全なオブジェクト名はkafka.cluster:type=Partition,name=InSyncReplicasCount,topic=<topic-name>,partition=<partition-id>です。ISR に含まれているレプリカの数をレポートします。CaughtUpReplicasCount- JMX での完全なオブジェクト名はkafka.cluster:type=Partition,name=CaughtUpReplicasCount,topic=<topic-name>,partition=<partition-id>です。トピックのパーティションリーダーに追い付いていると見なされるレプリカの数をレポートします。オブザーバーは追い付いている場合でも ISR には参加していないため、この値は ISR のサイズより大きくなる場合があります。ObserversInIsrCount- JMX での完全なオブジェクト名はkafka.cluster:type=Partition,name=ObserversInIsrCount,topic=<topic-name>,partition=<partition-id>です。現在 ISR に昇格されているオブザーバーの数をレポートします。
コマンドラインから実行して JMX メトリクスを収集することができるスクリプトもありますが、一般的なコマンド形式は、次のとおりです。
docker-compose exec broker-west-1 kafka-run-class kafka.tools.JmxTool --jmx-url service:jmx:rmi:///jndi/rmi://localhost:8091/jmxrmi --object-name kafka.cluster:type=Partition,name=<METRIC>,topic=<TOPIC>,partition=0 --one-time true
スクリプト jmx_metrics.sh を実行して、
ReplicasCount、InSyncReplicasCount、CaughtUpReplicasCount、ObserversInIsrCountの JMX メトリクスを各ブローカーから取得します。./scripts/jmx_metrics.sh
以下のような出力が表示されることを検証します。
==> JMX metric: ReplicasCount single-region: 2 multi-region-sync: 4 multi-region-async: 4 multi-region-async-op-under-min-isr: 4 multi-region-async-op-under-replicated: 4 multi-region-async-op-leader-is-observer: 4 multi-region-default: 4 ==> JMX metric: InSyncReplicasCount single-region: 2 multi-region-sync: 4 multi-region-async: 2 multi-region-async-op-under-min-isr: 2 multi-region-async-op-under-replicated: 2 multi-region-async-op-leader-is-observer: 2 multi-region-default: 2 ==> JMX metric: CaughtUpReplicasCount single-region: 2 multi-region-sync: 4 multi-region-async: 4 multi-region-async-op-under-min-isr: 4 multi-region-async-op-under-replicated: 4 multi-region-async-op-leader-is-observer: 4 multi-region-default: 4 ==> JMX metric: ObserversInIsrCount single-region: 0 multi-region-sync: 0 multi-region-async: 0 multi-region-async-op-under-min-isr: 0 multi-region-async-op-under-replicated: 0 multi-region-async-op-leader-is-observer: 0 multi-region-default: 0
機能低下リージョン¶
このセクションでは、west リージョンでの単一ブローカーの障害のシミュレーションを行います。
次のコマンドを実行して、
westリージョン内のブローカー Docker コンテナーを 1 つ停止します。docker-compose stop broker-west-1
スクリプト describe-topics.sh を実行して、新しいトピックのレプリカ配置を検証します。
./scripts/describe-topics.sh
出力は以下のようになります。
==> Describe topic: single-region Topic: single-region PartitionCount: 1 ReplicationFactor: 2 Configs: min.insync.replicas=1,confluent.placement.constraints={"version":1,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[]} Topic: single-region Partition: 0 Leader: 2 Replicas: 1,2 Isr: 2 Offline: 1 ==> Describe topic: multi-region-sync Topic: multi-region-sync PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"version":1,"replicas":[{"count":2,"constraints":{"rack":"west"}},{"count":2,"constraints":{"rack":"east"}}],"observers":[]} Topic: multi-region-sync Partition: 0 Leader: 2 Replicas: 1,2,3,4 Isr: 2,3,4 Offline: 1 ==> Describe topic: multi-region-async Topic: multi-region-async PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"version":1,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-async Partition: 0 Leader: 2 Replicas: 1,2,4,3 Isr: 2 Offline: 1 Observers: 4,3 ==> Describe topic: multi-region-async-op-under-min-isr Topic: multi-region-async-op-under-min-isr PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=2,confluent.placement.constraints={"observerPromotionPolicy":"under-min-isr","version":2,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-async-op-under-min-isr Partition: 0 Leader: 2 Replicas: 2,1,3,4 Isr: 2,4 Offline: 1 Observers: 3,4 ==> Describe topic: multi-region-async-op-under-replicated Topic: multi-region-async-op-under-replicated PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"observerPromotionPolicy":"under-replicated","version":2,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-async-op-under-replicated Partition: 0 Leader: 2 Replicas: 2,1,3,4 Isr: 2,4 Offline: 1 Observers: 3,4 ==> Describe topic: multi-region-async-op-leader-is-observer Topic: multi-region-async-op-leader-is-observer PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"observerPromotionPolicy":"leader-is-observer","version":2,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-async-op-leader-is-observer Partition: 0 Leader: 2 Replicas: 2,1,3,4 Isr: 2 Offline: 1 Observers: 3,4 ==> Describe topic: multi-region-default Topic: multi-region-default PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"version":1,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-default Partition: 0 Leader: 2 Replicas: 1,2,3,4 Isr: 2 Offline: 1 Observers: 3,4Confluent Control Center で同様のレプリカ配置を検証します。新しいトピックの統計情報が正しくレポートされるまでに、最大 5 分かかる場合があることに注意してください。

次のことを確認してください。
multi-region-async-op-under-min-isr、multi-region-sync、multi-region-async-op-under-replicatedを除くすべてのトピックで、ISR のレプリカは 1 つだけです。これは、すべてのレプリカの指示を出したレプリカ配置はwestリージョンにあり、このリージョンに残っているライブブローカーは 1 つだけであるためです。- 2 番目のシナリオでは、
multi-region-syncトピックで維持されている ISR に 3 つのブローカーがありました。これは、配置ポリシーで、east リージョンのブローカーが ISR に参加することが、必ず許可されるためです。 multi-region-async-op-under-min-isrおよびmulti-region-async-op-under-replicatedトピックの配置ポリシーでは、オブザーバーが自動的に ISR に昇格されることが許可されています。multi-region-async-op-under-min-isrの場合、オブザーバーではないレプリカの数(1)は、min.insync.replicasの値(2)より小さくなっています。min.insync.replicasの要件を満たすため、複数のオブザーバーが ISR に昇格されます。multi-region-async-op-under-replicatedの場合、オンラインレプリカの数(1)は、レプリカ配置で意図されたオブザーバーではないレプリカの数(2)より小さくなっています。この要件を満たすため、1 つのオブザーバーが昇格されます。
スクリプト jmx_metrics.sh を実行して、
ReplicasCount、InSyncReplicasCount、CaughtUpReplicasCount、ObserversInIsrCountの JMX メトリクスを各ブローカーから取得します。./scripts/jmx_metrics.sh
以下のような出力が表示されることを検証します。
==> JMX metric: ReplicasCount single-region: 2 multi-region-sync: 4 multi-region-async: 4 multi-region-async-op-under-min-isr: 4 multi-region-async-op-under-replicated: 4 multi-region-async-op-leader-is-observer: 4 multi-region-default: 4 ==> JMX metric: InSyncReplicasCount single-region: 1 multi-region-sync: 3 multi-region-async: 1 multi-region-async-op-under-min-isr: 2 multi-region-async-op-under-replicated: 2 multi-region-async-op-leader-is-observer: 1 multi-region-default: 1 ==> JMX metric: CaughtUpReplicasCount single-region: 1 multi-region-sync: 4 multi-region-async: 3 multi-region-async-op-under-min-isr: 3 multi-region-async-op-under-replicated: 4 multi-region-async-op-leader-is-observer: 4 multi-region-default: 3 ==> JMX metric: ObserversInIsrCount single-region: 0 multi-region-sync: 0 multi-region-async: 0 multi-region-async-op-under-min-isr: 1 multi-region-async-op-under-replicated: 1 multi-region-async-op-leader-is-observer: 0 multi-region-default: 0
フェイルオーバー¶
リージョンの障害¶
このセクションでは、west リージョンをダウンさせて、リージョンの障害のシミュレーションを行います。
次のコマンドを実行して、
westリージョンに対応する Docker コンテナーを停止します。docker-compose stop broker-west-1 broker-west-2 zookeeper-west
スクリプト describe-topics.sh を実行して、新しいトピックのレプリカ配置を検証します。
./scripts/describe-topics.sh
出力は以下のようになります。
==> Describe topic: single-region Topic: single-region PartitionCount: 1 ReplicationFactor: 2 Configs: min.insync.replicas=1,confluent.placement.constraints={"version":1,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[]} Topic: single-region Partition: 0 Leader: none Replicas: 2,1 Isr: 1 Offline: 2,1 ==> Describe topic: multi-region-sync Topic: multi-region-sync PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"version":1,"replicas":[{"count":2,"constraints":{"rack":"west"}},{"count":2,"constraints":{"rack":"east"}}],"observers":[]} Topic: multi-region-sync Partition: 0 Leader: 3 Replicas: 1,2,3,4 Isr: 3,4 Offline: 1,2 ==> Describe topic: multi-region-async Topic: multi-region-async PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"version":1,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-async Partition: 0 Leader: none Replicas: 2,1,3,4 Isr: 1 Offline: 2,1 Observers: 3,4 ==> Describe topic: multi-region-async-op-under-min-isr Topic: multi-region-async-op-under-min-isr PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=2,confluent.placement.constraints={"observerPromotionPolicy":"under-min-isr","version":2,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-async-op-under-min-isr Partition: 0 Leader: 4 Replicas: 2,1,4,3 Isr: 4,3 Offline: 2,1 Observers: 4,3 ==> Describe topic: multi-region-async-op-under-replicated Topic: multi-region-async-op-under-replicated PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"observerPromotionPolicy":"under-replicated","version":2,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-async-op-under-replicated Partition: 0 Leader: 4 Replicas: 1,2,3,4 Isr: 4,3 Offline: 1,2 Observers: 3,4 ==> Describe topic: multi-region-async-op-leader-is-observer Topic: multi-region-async-op-leader-is-observer PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"observerPromotionPolicy":"leader-is-observer","version":2,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-async-op-leader-is-observer Partition: 0 Leader: none Replicas: 1,2,4,3 Isr: 2 Offline: 1,2 Observers: 4,3 ==> Describe topic: multi-region-default Topic: multi-region-default PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"version":1,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-default Partition: 0 Leader: none Replicas: 2,1,3,4 Isr: 1 Offline: 2,1 Observers: 3,45 分程度で Confluent Control Center クラスターのメトリクスが安定すると、以下のような出力が表示されます。

次のことを確認してください。
- 1 番目のシナリオでは、
single-regionトピックにはリーダーがありません。このトピックのレプリカは ISR に 2 つのみで、両方ともwestリージョンにありましたが、現在は停止しているためです。 - 2 番目のシナリオでは、
multi-region-syncトピックによってeastの新しいリーダーが自動的に選出されています(前の出力ではレプリカの 3)。クライアントはeastリージョンで、これらのレプリカにフェイルオーバーできます。 multi-region-async、multi-region-default、およびmulti-region-async-op-leader-is-observerトピックにリーダーが存在しません。これは、これらのトピックのレプリカは ISR に 2 つのみであり、両方ともwestリージョンにありましたが、現在は停止しているためです。eastリージョンのオブザーバーは、ISR 内になかったため、自動的にリーダーになる資格はありません。multi-region-async-op-under-min-isrおよびmulti-region-async-op-under-replicatedトピックでは、複数のオブザーバーが ISR に昇格されており、1 つのオブザーバーがリーダーになっています。これは、これを許可するように、レプリカ配置ポリシーでobserverPromotionPolicyが設定されているためです。
- 1 番目のシナリオでは、
スクリプト jmx_metrics.sh を実行して、
ReplicasCount、InSyncReplicasCount、CaughtUpReplicasCount、ObserversInIsrCountの JMX メトリクスを各ブローカーから取得します。./scripts/jmx_metrics.sh
以下のような出力が表示されることを検証します。
==> JMX metric: ReplicasCount single-region: 0 multi-region-sync: 4 multi-region-async: 0 multi-region-async-op-under-min-isr: 4 multi-region-async-op-under-replicated: 4 multi-region-async-op-leader-is-observer: 0 multi-region-default: 0 ==> JMX metric: InSyncReplicasCount single-region: 0 multi-region-sync: 2 multi-region-async: 0 multi-region-async-op-under-min-isr: 2 multi-region-async-op-under-replicated: 2 multi-region-async-op-leader-is-observer: 0 multi-region-default: 0 ==> JMX metric: CaughtUpReplicasCount single-region: 0 multi-region-sync: 2 multi-region-async: 0 multi-region-async-op-under-min-isr: 2 multi-region-async-op-under-replicated: 2 multi-region-async-op-leader-is-observer: 0 multi-region-default: 0 ==> JMX metric: ObserversInIsrCount single-region: 0 multi-region-sync: 0 multi-region-async: 0 multi-region-async-op-under-min-isr: 2 multi-region-async-op-under-replicated: 2 multi-region-async-op-leader-is-observer: 0 multi-region-default: 0
オブザーバーのフェイルオーバー¶
multi-region-async および multi-region-default トピックのオブザーバーを明示的に east リージョンにフェイルオーバーするには、次の手順を実行します。
クリーンではないリーダー選出をトリガーします(注 :
クリーンではないリーダー選出により、データ損失が発生する場合があります)。docker-compose exec broker-east-4 kafka-leader-election --bootstrap-server broker-east-4:19094 --election-type UNCLEAN --topic multi-region-async --partition 0 docker-compose exec broker-east-4 kafka-leader-election --bootstrap-server broker-east-4:19094 --election-type UNCLEAN --topic multi-region-default --partition 0
スクリプト describe-topics.sh を実行して、各トピックの詳細を再度表示します。
./scripts/describe-topics.sh
出力は以下のようになります。
... ==> Describe topic: multi-region-async Topic: multi-region-async PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"version":1,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-async Partition: 0 Leader: 3 Replicas: 2,1,3,4 Isr: 3,4 Offline: 2,1 Observers: 3,4 ... ==> Describe topic: multi-region-default Topic: multi-region-default PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"version":1,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-default Partition: 0 Leader: 3 Replicas: 2,1,3,4 Isr: 3,4 Offline: 2,1 Observers: 3,4Confluent Control Center の "Topics" セクションで、クリーンではないリーダーの選出の変化を確認します。

次のことを確認してください。
- トピック
multi-region-asyncおよびmulti-region-defaultに再びリーダーが存在します(CLI の出力ではレプリカの 3)。 - トピック
multi-region-asyncおよびmulti-region-defaultにはオブザーバーが存在しており、現在は ISR リスト内にあります(CLI の出力ではレプリカの 3 および 4)。
- トピック
スクリプト jmx_metrics.sh を実行して、
ReplicasCount、InSyncReplicasCount、CaughtUpReplicasCount、ObserversInIsrCountの JMX メトリクスを各ブローカーから取得します。./scripts/jmx_metrics.sh
以下のような出力が表示されることを検証します。
==> JMX metric: ReplicasCount single-region: 0 multi-region-sync: 4 multi-region-async: 4 multi-region-async-op-under-min-isr: 4 multi-region-async-op-under-replicated: 4 multi-region-async-op-leader-is-observer: 0 multi-region-default: 4 ==> JMX metric: InSyncReplicasCount single-region: 0 multi-region-sync: 2 multi-region-async: 2 multi-region-async-op-under-min-isr: 2 multi-region-async-op-under-replicated: 2 multi-region-async-op-leader-is-observer: 0 multi-region-default: 2 ==> JMX metric: CaughtUpReplicasCount single-region: 0 multi-region-sync: 2 multi-region-async: 2 multi-region-async-op-under-min-isr: 2 multi-region-async-op-under-replicated: 2 multi-region-async-op-leader-is-observer: 0 multi-region-default: 2 ==> JMX metric: ObserversInIsrCount single-region: 0 multi-region-sync: 0 multi-region-async: 2 multi-region-async-op-under-min-isr: 2 multi-region-async-op-under-replicated: 2 multi-region-async-op-leader-is-observer: 0 multi-region-default: 2
永続的フェイルオーバー¶
サンプルのこの時点では、west リージョンのブローカーが再びオンラインになった場合は、multi-region-async および multi-region-default トピックの各リーダーが west で再びレプリカとして選出されます(つまり、レプリカ 1 または 2)。状況によっては、これが好都合な場合もありますが、リーダーが自動的には west リージョンにフェイルバックされないようにする場合は、次の手順を実行して、トピック配置制約の構成とレプリカの割り当てを変更します。
トピック
multi-region-defaultについて、変更したレプリカ配置ポリシー placement-multi-region-default-reverse.json を表示します。{ "version": 1, "replicas": [ { "count": 2, "constraints": { "rack": "east" } } ], "observers": [ { "count": 2, "constraints": { "rack": "west" } } ] }スクリプト permanent-failover.sh を実行して、
multi-region-defaultに対するレプリカ配置制約の構成とレプリカの割り当てを変更します。./scripts/permanent-failover.sh
スクリプトは、
kafka-configsを使用してレプリカ配置ポリシーを変更し、次にconfluent-rebalancerを実行してレプリカを移動します。echo -e "\n==> Switching replica placement constraints for multi-region-default\n" docker-compose exec broker-east-3 kafka-configs \ --bootstrap-server broker-east-3:19093 \ --alter \ --topic multi-region-default \ --replica-placement /etc/kafka/demo/placement-multi-region-default-reverse.json echo -e "\n==> Running Confluent Rebalancer on multi-region-default\n" docker-compose exec broker-east-3 confluent-rebalancer execute \ --metrics-bootstrap-server broker-ccc:19098 \ --bootstrap-server broker-east-3:19093 \ --replica-placement-only \ --topics multi-region-default \ --force \ --throttle 10000000 docker-compose exec broker-east-3 confluent-rebalancer finish \ --bootstrap-server broker-east-3:19093
スクリプト describe-topics.sh を実行して、各トピックの詳細を再度表示します。
./scripts/describe-topics.sh
出力は以下のようになります。
... ==> Describe topic: multi-region-default Topic: multi-region-default PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"version":1,"replicas":[{"count":2,"constraints":{"rack":"east"}}],"observers":[{"count":2,"constraints":{"rack":"west"}}]} Topic: multi-region-async Partition: 0 Leader: 3 Replicas: 3,4,2,1 Isr: 3,4 Offline: 2,1 Observers: 2,1 ...multi-region-defaultトピックをクリックし、PartitionsおよびReplica Placementセクションを参照して、同様のリーダーの配置を確認します。
次のことを確認してください。
- トピック
multi-region-defaultでは、以前は同期レプリカであったレプリカの 2 および 1 はオブザーバーとなり、オフラインのままです。 - トピック
multi-region-defaultでは、以前はオブザーバーであったレプリカの 3 および 4 は同期レプリカとなっています。
- トピック
スクリプト jmx_metrics.sh を実行して、
ReplicasCount、InSyncReplicasCount、CaughtUpReplicasCount、ObserversInIsrCountの JMX メトリクスを各ブローカーから取得します。./scripts/jmx_metrics.sh
以下のような出力が表示されることを検証します。
==> JMX metric: ReplicasCount single-region: 0 multi-region-sync: 4 multi-region-async: 4 multi-region-async-op-under-min-isr: 4 multi-region-async-op-under-replicated: 4 multi-region-async-op-leader-is-observer: 0 multi-region-default: 4 ==> JMX metric: InSyncReplicasCount single-region: 0 multi-region-sync: 2 multi-region-async: 2 multi-region-async-op-under-min-isr: 2 multi-region-async-op-under-replicated: 2 multi-region-async-op-leader-is-observer: 0 multi-region-default: 2 ==> JMX metric: CaughtUpReplicasCount single-region: 0 multi-region-sync: 2 multi-region-async: 2 multi-region-async-op-under-min-isr: 2 multi-region-async-op-under-replicated: 2 multi-region-async-op-leader-is-observer: 0 multi-region-default: 2 ==> JMX metric: ObserversInIsrCount single-region: 0 multi-region-sync: 0 multi-region-async: 2 multi-region-async-op-under-min-isr: 2 multi-region-async-op-under-replicated: 2 multi-region-async-op-leader-is-observer: 0 multi-region-default: 0
フェイルバック¶
ここで、リージョン west をオンラインに戻し、構成を復元して定常状態と同様に戻します。
次のコマンドを実行して
westリージョンを再びオンラインにします。docker-compose start broker-west-1 broker-west-2 zookeeper-west
リーダーの選出によって、優先するレプリカが復元されるまで、5 分間(
leader.imbalance.check.interval.secondsのデフォルト期間)待機します。docker-compose exec broker-east-4 kafka-leader-election --bootstrap-server broker-east-4:19094 --election-type PREFERRED --all-topic-partitionsでこの復元をトリガーすることもできます。スクリプト describe-topics.sh を使用して、新しいトピックのレプリカ配置が復元されたことを検証します。
./scripts/describe-topics.sh
出力は以下のようになります。
Topic: single-region PartitionCount: 1 ReplicationFactor: 2 Configs: min.insync.replicas=1,confluent.placement.constraints={"version":1,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[]} Topic: single-region Partition: 0 Leader: 2 Replicas: 2,1 Isr: 1,2 Offline: ==> Describe topic: multi-region-sync Topic: multi-region-sync PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"version":1,"replicas":[{"count":2,"constraints":{"rack":"west"}},{"count":2,"constraints":{"rack":"east"}}],"observers":[]} Topic: multi-region-sync Partition: 0 Leader: 1 Replicas: 1,2,3,4 Isr: 3,4,2,1 Offline: ==> Describe topic: multi-region-async Topic: multi-region-async PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"version":1,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-async Partition: 0 Leader: 2 Replicas: 2,1,3,4 Isr: 2,1 Offline: Observers: 3,4 ==> Describe topic: multi-region-async-op-under-min-isr Topic: multi-region-async-op-under-min-isr PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=2,confluent.placement.constraints={"observerPromotionPolicy":"under-min-isr","version":2,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-async-op-under-min-isr Partition: 0 Leader: 2 Replicas: 2,1,3,4 Isr: 1,2 Offline: Observers: 3,4 ==> Describe topic: multi-region-async-op-under-replicated Topic: multi-region-async-op-under-replicated PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"observerPromotionPolicy":"under-replicated","version":2,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-async-op-under-replicated Partition: 0 Leader: 2 Replicas: 2,1,3,4 Isr: 1,2 Offline: Observers: 3,4 ==> Describe topic: multi-region-async-op-leader-is-observer Topic: multi-region-async-op-leader-is-observer PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"observerPromotionPolicy":"leader-is-observer","version":2,"replicas":[{"count":2,"constraints":{"rack":"west"}}],"observers":[{"count":2,"constraints":{"rack":"east"}}]} Topic: multi-region-async-op-leader-is-observer Partition: 0 Leader: 2 Replicas: 2,1,3,4 Isr: 2,1 Offline: Observers: 3,4 ==> Describe topic: multi-region-default Topic: multi-region-default PartitionCount: 1 ReplicationFactor: 4 Configs: min.insync.replicas=1,confluent.placement.constraints={"version":1,"replicas":[{"count":2,"constraints":{"rack":"east"}}],"observers":[{"count":2,"constraints":{"rack":"west"}}]} Topic: multi-region-async Partition: 0 Leader: 3 Replicas: 3,4,2,1 Isr: 3,4 Offline: Observers: 2,1次のことを確認してください。
- 特に、
westリージョンに障害が発生したときにリーダーを失ったsingle-regionを含め、すべてのトピックに再びリーダーが存在しています。 multi-region-syncとmulti-region-asyncのリーダーがwestリージョンに復元されています。復元されていない場合は、5 分間(leader.imbalance.check.interval.secondsの持続期間)待ちます。- 永続的フェイルオーバーを実行したため、
multi-region-defaultのリーダーはeastリージョンのままです。 multi-region-async-op-under-min-isrおよびmulti-region-async-op-under-replicatedで自動的に昇格されたオブザーバーはすべて、westリージョンが復元されると、自動的に降格されます。この降格のプロセスではリーダー選出の必要はなく、障害の発生したリージョンが復元されるとすぐに実行されます。- Confluent Control Center トピックページは、このチュートリアルの開始時と同様になります。
- 特に、
注釈
オブザーバーに対するフェイルオーバーからのフェイルバックでは、ログが切り捨てられてから ISR に追い付き、結合されるため、オブザーバーにレプリケートされていなかったデータはすべて失われます。
スクリプト jmx_metrics.sh を実行して、
ReplicasCount、InSyncReplicasCount、CaughtUpReplicasCount、ObserversInIsrCountの JMX メトリクスを各ブローカーから取得します。./scripts/jmx_metrics.sh
次のような出力が表示されることを確認します。定常状態だったチュートリアル開始時の出力と完全に一致します。
==> JMX metric: ReplicasCount single-region: 2 multi-region-sync: 4 multi-region-async: 4 multi-region-async-op-under-min-isr: 4 multi-region-async-op-under-replicated: 4 multi-region-async-op-leader-is-observer: 4 multi-region-default: 4 ==> JMX metric: InSyncReplicasCount single-region: 2 multi-region-sync: 4 multi-region-async: 2 multi-region-async-op-under-min-isr: 2 multi-region-async-op-under-replicated: 2 multi-region-async-op-leader-is-observer: 2 multi-region-default: 2 ==> JMX metric: CaughtUpReplicasCount single-region: 2 multi-region-sync: 4 multi-region-async: 4 multi-region-async-op-under-min-isr: 4 multi-region-async-op-under-replicated: 4 multi-region-async-op-leader-is-observer: 4 multi-region-default: 4 ==> JMX metric: ObserversInIsrCount single-region: 0 multi-region-sync: 0 multi-region-async: 0 multi-region-async-op-under-min-isr: 0 multi-region-async-op-under-replicated: 0 multi-region-async-op-leader-is-observer: 0 multi-region-default: 0
チュートリアルの停止と終了後の手順¶
サンプル環境とすべての Docker コンテナーを停止するには、次のコマンドを実行します。
./scripts/stop.sh
アプリケーションを手動で停止するには、以下のコマンドを実行します。
docker-compose down
自動または手動デモの実行を完了した場合で、アプリケーションの停止後に Docker 環境のクリーンアップのみを実行する場合は、以下のようなコマンドを使用できます。
- コンテナーの停止:
docker stop $(docker ps -a -q) - コンテナーの削除:
docker rm $(docker ps -a -q) - イメージの削除:
docker rmi $(docker images -q)(省略可)
トラブルシューティング¶
デモのスタートアップでエラーが発生する¶
デモアプリケーションは、OS パッケージや Docker イメージなど、さまざまなサイトからリソースをプルします。ネットワーク接続の信頼性が低い場合、またはこれらのサイトを利用できない場合は、必要なリソースをプルする際にデモでエラーが発生することがあります。
エラーが発生した場合は、以下のコマンドを実行した後、ダウンロードを再試行して、スクリプトを開始します。
docker-compose down
コンテナーが相互に ping を実行しない¶
コンテナーが相互に ping を実行しない場合は(スクリプト validate_connectivity.sh の実行が失敗した場合など)、次の手順を実行します。
サンプルを停止します。
./scripts/stop.sh
Docker 環境をクリーンアップします。
docker-compose down -v --remove-orphans # More aggressive cleanup docker volume pruneサンプルを再起動します。
./scripts/start.sh
それでもコンテナーが相互に ping を実行しない場合は、Docker を再起動し、再び実行します。
検出可能なレイテンシとジッターがない¶
multi-region-sync とそれ以外のトピックで同期レプリケーションのパフォーマンスに差がない場合は、Docker ネットワークが機能していないか、各実行の間に適切にクリーンアップされていない可能性があります。
Docker を再起動します。UI を使用して再起動するか、以下を実行することができます。
macOS を実行している場合:
osascript -e 'quit app "Docker"' && open -a Docker
Docker Toolbox を実行している場合:
docker-machine restart