Confluent Platform とは¶
ちなみに
はじめに、Confluent Cloud にサインアップするか、Confluent Platform をダウンロードしてください。
Confluent Platform は、継続的でリアルタイムのストリームとしてデータに簡単にアクセスし、それを保存および管理できるフルスケールのストリーミングプラットフォームです。Apache Kafka® の元々の開発者によって構築された Confluent では、エンタープライズ級の機能で Kafka の利点が拡張されていると同時に、Kafka の管理およびモニタリングの負荷が排除されています。現在、Fortune 100 の 80% 以上の企業がデータストリーミングテクノロジーで強化を図っており、その大半で Confluent が使用されています。
Confluent を採用するメリット¶
履歴データとリアルタイムデータを統合して、中央の Single Source of Truth(信頼できる唯一の情報源)とすることで、Confluent では、まったく新しいカテゴリの最新のイベント駆動型アプリケーションを簡単に構築できます。また、共通のデータパイプラインを獲得でき、優れた拡張性、パフォーマンス、信頼性を備えた、パワフルで新しいユースケースが可能になります。
Confluent の用途¶
Confluent Platform を利用することで、基盤となるメカニズム(各種システム間でのデータの転送方法や統合方法など)を気にすることなく、データからどのようにしてビジネス価値を引き出すかに集中することができます。具体的には、Confluent Platform により、Kafka へのデータソースの接続、ストリーミングアプリケーションの構築、および Kafka インフラストラクチャの保護、モニタリング、管理が簡素化されます。現在、Confluent Platform は、金融サービス、オムニチャネル小売、自律走行車から不正検出、マイクロサービス、IoT までの数多くの業界にわたり、広範なユースケースで使用されています。
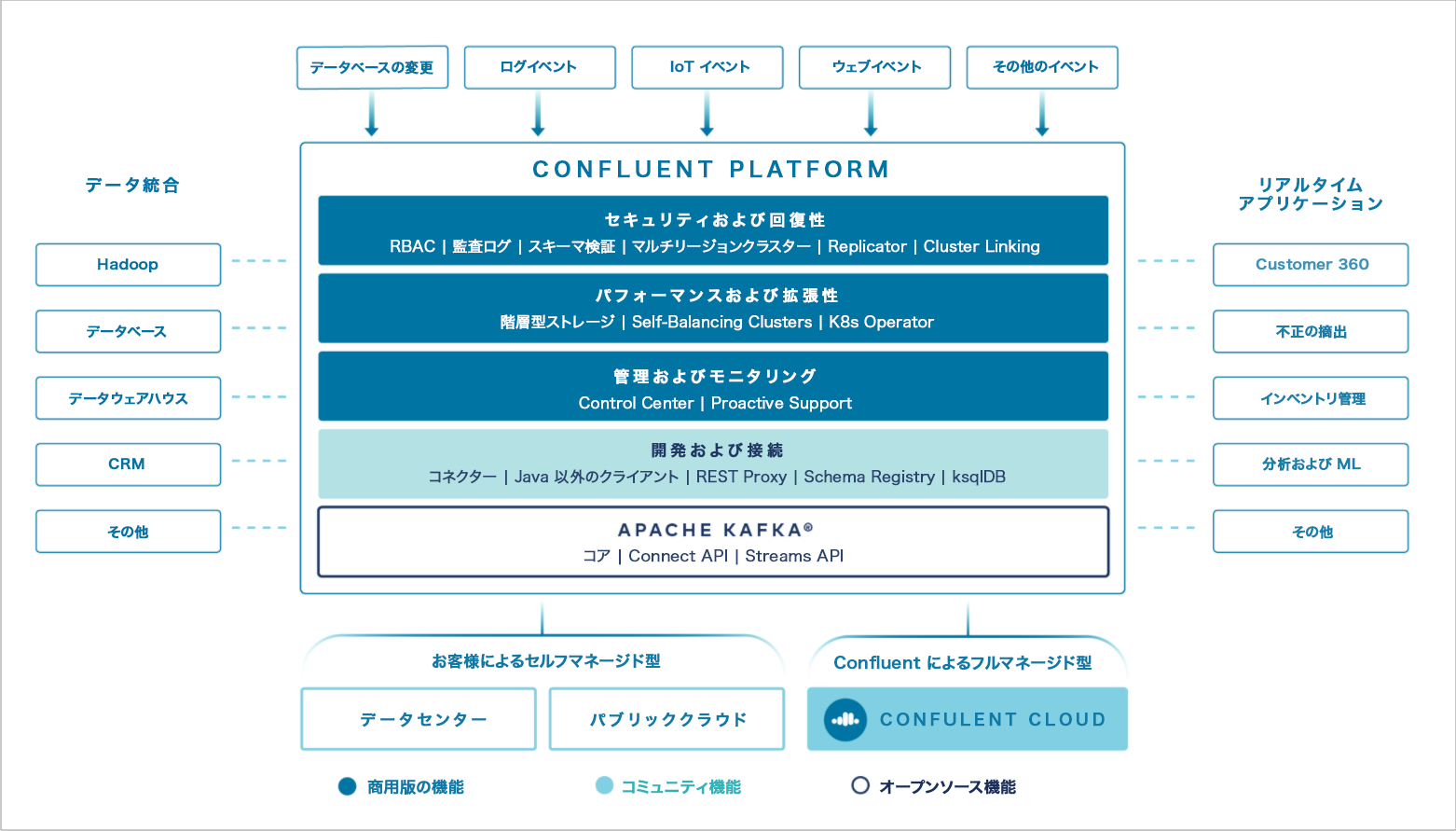
Confluent Platform コンポーネント¶
Confluent のイベントストリーミングテクノロジの概要¶
Confluent Platform の中核を成すのは、最も広く利用されているオープンソース分散ストリーミングプラットフォームである Apache Kafka です。Kafka の主な機能は、次のとおりです。
- レコードストリームのパブリッシュおよびサブスクライブ
- フォールトトレラントな方法によるレコードストリームの格納
- レコードストリームの処理
Confluent Platform には、Schema Registry、REST Proxy、全部で 100 を超える構築済み Kafka コネクター、および ksqlDB も標準で含まれています。
Kafka を採用するメリット¶
Fortune 500 の 60% の企業 が、ユーザーのアクティビティデータ、システムログ、アプリケーションのメトリクス、株価ティッカーデータ、デバイスの計装信号の収集など、さまざまなユースケースで Kafka を使用しています。
Kafka オープンソースプロジェクトの主要なコンポーネントは、Kafka ブローカーと Kafka Java クライアント API です。
- Kafka ブローカー
- Kafka のメッセージング、データ永続性、およびストレージ階層を形成する Kafka ブローカー。
- Kafka Java クライアント API
- プロデューサー API は、アプリケーションが 1 つ以上の Kafka トピックにストリームレコードをパブリッシュできるようにする Java クライアントです。
- コンシューマー API アプリケーションは、1 つまたは複数のトピックをサブスクライブし、そこに生成されたレコードのストリームを処理できるようにする Java クライアントです。
- ストリーム API により、アプリケーションはストリームプロセッサーとして機能できます。1 つまたは複数のトピックからの入力ストリームを消費して 1 つまたは複数の出力トピックにストリームを出力し、入力ストリームを出力ストリームに効率的に変えることができます。非常に取り入れやすく、運用が容易で、ストリーム処理アプリケーションを記述するための高レベルの DSL を備えています。したがって、Kafka で管理されるデータを処理して分析するための最も便利でスケーラブルなオプションです。
- 管理用 API は、トピック、ブローカー、ACL、およびその他の Kafka オブジェクトの作成、検査、削除、管理の機能を提供します。
- Kafka Connect API
- Connect API は、Kafka と他のデータシステム間でスケーラブルかつ信頼性の高い方法でデータをストリーミングするために使用できるコンポーネントです。これにより、Kafka との間でデータを出し入れするようにコネクターを簡単に構成することができます。Kafka Connect は、データベース全体を取り込んだり、すべてのアプリケーションサーバーから Kafka トピックにメトリクスを収集したりして、データをストリーム処理に利用できるようにします。コネクターは、Kafka トピックから Elasticsearch などのセカンダリインデックスにデータを配信したり、オフライン分析のために Hadoop などのバッチシステムにデータを配信したりすることもできます。
Confluent Platform と Kafka - 主な相違点¶
Confluent Platform の各リリースには、Event Streaming Platform の構築と管理を簡単にする 最新リリースの Kafka と追加のツールやサービスが含まれています。Confluent Platform ではコミュニティ版ライセンスの機能と商用ライセンス版の機能の両方が提供され、Kafka デプロイを補完および強化できます。
参考
この構成の動作例については、Confluent Platform デモ を参照してください。構成リファレンスについては、デモの docker-compose.yml ファイル を参照してください。
Confluent Platform のエンタープライズ機能の概要¶
Confluent Control Center¶
Confluent Control Center は、Kafka を管理およびモニタリングするための GUI ベースのシステムです。Kafka Connect を簡単に管理し、他のシステムとの接続を作成、編集、および管理することができます。また、プロデューサーからコンシューマーへのデータストリームをモニタリングすることで、すべてのメッセージが確実に配信されるようにし、メッセージの配信にかかる時間を測定することができます。Control Center を使用することで、コードを一行も書くことなく、Kafka をベースにした本稼働環境用のデータパイプラインを構築することができます。Control Center は、データストリームのレイテンシと完全性の統計に関するアラートを定義する機能も備えており、メールで配信したり、一元的なアラートシステムからクエリを実行したりすることができます。
Confluent for Kubernetes¶
Confluent for Kubernetes は、Kubernetes Operator です。Kubernetes Operator は、特定のプラットフォームアプリケーションに固有の機能や要件を提供することで、Kubernetes のオーケストレーション機能を拡張します。Confluent Platform では、Kubernetes 上での Kafka のデプロイプロセスを大幅に簡素化し、一般的なインフラストラクチャのライフサイクルタスクを自動化することもできます。
詳細については、「Kubernetes 用の Confluent」を参照してください。
Kafka への Confluent コネクター¶
コネクターにより Kafka Connect API が活用され、Kafka が、データベース、キー値ストア、検索インデックス、ファイルシステムなどの他のシステムに接続されます。
Confluent Hub には、最も一般的なデータソースとシンクのためのダウンロード可能なコネクターが用意されています。これらのコネクターには、Confluent Platform を使用して十分にテストされ、サポートされているバージョンが含まれています。詳細については、以下のドキュメントを参照してください。
Confluent は、商用コネクターとコミュニティライセンス取得済みコネクターの両方を提供します。詳細、およびコネクターのダウンロードについては、「Confluent Hub」を参照してください。
Self-Balancing Clusters¶
Self-Balancing Clusters で、自動ロードバランス機能、障害検出、および自己調整が可能になります。また、必要に応じて、ブローカーの追加または廃止がサポートされ、手動調整の必要はありません。Self-Balancing が、クラスターの不均衡を自動でモニタリングし、構成に基づいてバランス調整を自動でトリガーするという点で、Self-Balancing は、Auto Data Balancer の次の繰り返し処理と言えます(自動バランスオプション Only when brokers are added または Anytime を選択できます)。
パーティション再割り当ての計画と実行をユーザーが行う必要はありません。
Confluent Cluster Linking¶
Cluster Linking により、クラスター同士が直接接続され、一方のクラスターから他方のクラスターにトピックがリンクブリッジでミラーリングされます。Cluster Linking により、マルチデータセンター、マルチクラスター、およびハイブリッドクラウドのデプロイのセットアップが簡素化されます。
Confluent Auto Data Balancer¶
クラスターが大きくなるにつれ、トピックやパーティションはそれぞれ異なる速度で大きくなり、ブローカーが追加されたり削除され、時間の経過とともにデータセンターのリソース間でワークロードが不均衡になります。ブローカーの中には、まったく動作していないものもあれば、大きなパーティションまたは多くのパーティションによってメモリーが消費され、メッセージの配信が遅くなっているものもあります。Confluent Auto Data Balancer を実行することで、クラスター内のブローカー数、パーティションサイズ、パーティション数、およびリーダー数を監視できます。データを移動してクラスター全体で均等なワークロードを作成し、バランス調整のトラフィックをスロットル化して本稼働環境ワークロードへの影響を最小限に抑えながら、バランス調整を行うことができます。
詳細については、データの自動バランス調整のドキュメント を参照してください。
Confluent Replicator¶
Replicator では、複数のデータセンターにある複数の Kafka クラスターを、これまで以上に簡単に維持できます。データとトピックの構成のデータセンター間レプリケーションを管理することで、次のようなユースケースが可能になります。
- アクティブ/アクティブの地理的位置指定デプロイ: ユーザーは近くのデータセンターにアクセスして、低いレイテンシと高いパフォーマンスを実現するためにアーキテクチャを最適化することができます
- 一元的分析 : 複数の Kafka クラスターからのデータを 1 つの場所に集約して、組織全体の分析を行います
- クラウド移行 : Kafka を使用して、オンプレミスのアプリケーションとクラウドのデプロイ間でデータを同期します
Replicator を使用して、これらすべてのシナリオで、Confluent Control Center またはコマンドラインツールからレプリケーションを構成し、管理することができます。作業を開始するには、Replicator のクイックスタートチュートリアル など、Replicator に関するドキュメント を参照してください。
Tiered Storage¶
階層型ストレージ で、好みのクラウドプロバイダーを使用して Kafka データの大規模ボリュームを格納するためのオプションが提供されます。これにより、運用の負荷とコストが削減されます。階層型ストレージを使用することで、データをコスト効率の高いオブジェクトストレージに保持できるため、ブローカーをスケーリングするのが、コンピュートリソースがさらに必要な場合のみとなります。
Confluent JMS Client¶
Confluent Platform には、Kafka 用の JMS 対応のクライアントが含まれています。この Kafka クライアントは、Kafka ブローカーをバックエンドとして使用して、JMS 1.1 標準 API を実装しています。これは、JMS を使用しているレガシーアプリケーションがあり、既存の JMS メッセージブローカーを Kafka で置き換える場合に便利です。レガシー JMS メッセージブローカーを Kafka に置き換えることで、既存のアプリケーションを大幅に書き換えることなく、最新のストリーミングプラットフォームと統合することができます。
詳細については、「JMS Client」を参照してください。
Confluent MQTT Proxy¶
Provides a way to to publish data directly Kafka from MQTT devices and gateways without the need for a MQTT Broker in the middle.
詳細については、「MQTT Proxy」を参照してください。
Confluent セキュリティプラグイン¶
Confluent セキュリティプラグインは、さまざまな Confluent Platform ツールや製品にセキュリティ機能を追加するために使用されます。
現在、Confluent REST Proxy 用のプラグインが用意されており、これを使用することで受信リクエストを認証し、認証されたプリンシパルを Kafka へのリクエストに伝播させることができます。これにより、Confluent REST Proxy クライアントは、Kafka ブローカーのマルチテナントセキュリティ機能を利用できるようになります。詳細については、「REST Proxy のセキュリティ」、「REST Proxy セキュリティプラグイン」、および「Schema Registry セキュリティプラグイン」を参照してください。
コミュニティ機能¶
ksqlDB¶
ksqlDB は、Kafka 用のストリーミング SQL エンジンです。Kafka 上でストリーム処理を行うための、使いやすくて強力な対話型 SQL インターフェイスを提供します。Java や Python などのプログラミング言語でコードを書く必要はありません。ksqlDB は、スケーラブルで、弾力性があり、フォールトトレラントおよびリアルタイム性が備えられています。データのフィルタリング、変換、集約、結合、ウィンドウ化、セッション化など、幅広いストリーミング操作をサポートしています。
ksqlDB は、以下のユースケースをサポートしています。
- ストリーミング ETL
- Kafka は、データパイプラインを強化するための一般的な選択肢です。ksqlDB を使用すると、パイプライン内のデータを簡単に変換して、メッセージを別のシステムにクリーンに移行するための準備を行うことができます。
- マテリアライズドキャッシュ/ビュー
- マテリアライズドビューは、読み取りアクセスを高速化するために、事前(ユーザーまたはアプリが実際にクエリを実行する前)に計算され、格納されているクエリ結果です。ksqlDB は、分散された具現化のためのイベントストリームとして、Kafka でのマテリアライズドビューの構築をサポートしています。Kafka を使用して格納し、ksqlDB を使用して計算することで、複雑さが緩和されています。
- イベント駆動型マイクロサービス
- Kafka で、ステートレスでイベント駆動型のマイクロサービスのモデル化のサポートを提供します。ステートフルなストリーム処理がサーバーのクラスターで管理される一方で、ステートレスなマイクロサービスの内部で副作用が実行され、Kafka トピックからイベントを読み取り、必要に応じてアクションを実行します。
詳細については、ksqlDB のドキュメント、ksqlDB 開発者サイト、および`ウェブサイト上の ksqlDB のスタートガイド <https://docs.ksqldb.io/en/latest/>`__ を参照してください。
Kafka への Confluent コネクター¶
コネクターにより Kafka Connect API が活用され、Kafka が、データベース、キー値ストア、検索インデックス、ファイルシステムなどの他のシステムに接続されます。Confluent Hub には、最も一般的なデータソースとシンクのためのダウンロード可能なコネクターが用意されています。
Confluent は、商用コネクターとコミュニティライセンス取得済みコネクターの両方を提供します。詳細、およびコネクターのダウンロードについては、「Confluent Hub」を参照してください。
Confluent クライアント¶
C/C++ クライアントライブラリ¶
ライブラリ librdkafka は、Kafka プロトコルの C/C++ 実装で、プロデューサーとコンシューマーの両方のサポートが含まれます。メッセージ配信、信頼性、および高性能を念頭に設計されています。メッセージの配信数に関して、現在のベンチマークでは、プロデューサーの場合は 1 秒間に 80 万、コンシューマーの場合は 1 秒間に 300 万を超えています。このライブラリには、メッセージセキュリティなど、Kafka 0.10 の多くの新機能に対するサポートが含まれています。また、Avro データシリアル化用の C/C++ ライブラリである libserdes(Schema Registry をサポート)と簡単に統合できます。
詳細については、Kafka クライアント のドキュメントを参照してください。
Go クライアントライブラリ¶
Confluent Platform には、フル機能で高性能な Go 用クライアントが含まれています。
詳細については、Kafka クライアント のドキュメントを参照してください。
.NET クライアントライブラリ¶
Confluent Platform には、フル機能で高性能の .NET 用クライアントが含まれています。
詳細については、Kafka クライアント のドキュメントを参照してください。
Confluent Schema Registry¶
緩く結合されたシステムで最も困難な課題の 1 つは、システムの成長や進化に合わせてデータとコードの互換性を確保することです。Kafka のようなメッセージングサービスでは、対話するサービスは、メッセージの "スキーマ" と呼ばれる共通のフォーマットに一致しなければなりません。多くのシステムにおいて、これらのフォーマットはアドホックで、コードによって暗黙的に定義されているだけであり、そのメッセージタイプを使用する各システムで重複していることがよくあります。
要件の変化に伴い、これらのフォーマットを進化させる必要が出てきます。アドホックな定義だけでは、開発者が自分の変更がどのような影響を与えるかを判断することは非常に困難です。
Confluent Cloud Schema Registry は、スキーマ管理の一元化により、安全でダウンタイムなしの スキーマ の進化を実現します。Avro®、JSON Schema、Protobuf の各スキーマの格納と取得のための RESTful インターフェイスを提供しています。Schema Registry は、Kafka のすべてのトピックで使用されているスキーマのすべてのバージョンを追跡し、ユーザー定義の 互換性設定 によってのみスキーマを進化させます。これにより開発者は、スキーマを修正することで把握できていない別のサービスを破損するという心配をすることなく、必要に応じてスキーマを安全に修正できるという安心感が得られます。スキーマのサポートは、データガバナンスソリューションの基本的なコンポーネントです。
Schema Registry には、Avro フォーマットで送信された Kafka メッセージについて、そのスキーマの格納と取得に対応する Kafka のクライアントも用意されています。この統合はシームレスです。既に Avro データで Kafka を使用している場合に Schema Registry を使用するには、アプリケーションにシリアライザーを含めて設定を変更するだけで済みます。
詳細については、Schema Registry のドキュメント を参照してください。スキーマの操作の実践的な紹介については、「Schema Registry のチュートリアル」を参照してください。サポートされているシリアル化と逆シリアル化のフォーマットの詳細については、「フォーマット、シリアライザー、逆シリアライザー」を参照してください。
Confluent REST Proxy¶
Kafka と Confluent は Java、C、C++、および Python 用のネイティブクライアントを提供しており、Kafka を通じて迅速かつ容易にメッセージを生成し、消費することができます。これらのクライアントは、通常、Kafka と直接通信するための最も簡単で、最も速く、最も安全な方法です。
しかし、ネイティブクライアントを使用するアプリケーションを作成して保守することが現実的でない場合もあります。例えば、PHP で作成したレガシーアプリケーションを Kafka に接続するような場合です。あるいは、ある企業がキャッシュレジスター上で動作するポイントオブセールソフトウェア( C# で作成され、Windows NT 4.0 上で動作し、業者が管理を行っているもの)を実行しており、パブリックインターネット上にデータを掲載する必要があるとします。これらのケースを支援するために、Confluent Platform には REST Proxy が含まれています。REST Proxy は、これらの問題を解決します。
Confluent REST Proxy は、Kafka クラスターと対話するための RESTful HTTP サービスを提供することで、どの言語からでも簡単に Kafka を操作することができます。REST Proxy は、Kafka へのメッセージの送信、個別およびコンシューマグループの一部としてのメッセージの読み込み、トピックのリストおよびその設定などのクラスターメタデータの検査など、すべてのコア機能をサポートしています。どの言語からでも、公式にメンテナンスされた高品質の Java クライアントの恩恵を十分に受けることができます。
REST Proxy は、Schema Registry にも統合されています。Avro のデータを読み取ったり書き込んで、Schema Registry にスキーマを登録して検索することができます。これは Avro との間で JSON データを自動的に変換するため、HTTP と JSON だけの使用で、どの言語からでも一元的スキーマ管理を十分に活用することができます。
詳細については、Confluent REST Proxy のドキュメント を参照してください。
Confluent Platform の Docker イメージ¶
Confluent Platform の Docker イメージは Docker Hub で入手でき、「Docker Image Reference」ページの Confluent のドキュメントで詳しく説明されています。これらのイメージの一部には、Confluent の商用ライセンスが必要なプロプライエタリコンポーネントが含まれています。これは、cp-enterprise-${component_name} として識別されます。
Confluent CLI およびその他のコマンドラインツール¶
Confluent Platform には、Confluent CLI などの多くのコマンドラインインターフェイス(CLI)ツールが付属しています。Confluent 提供のツールと Kafka ユーティリティの両方を含む、これらのすべてのリストは、Confluent のドキュメントの「Confluent Platform の CLI ツール」にあります。