Looking for Schema Management Confluent Cloud docs? You are currently viewing Confluent Platform documentation. If you are looking for Confluent Cloud docs, check out Schema Management on Confluent Cloud.
Avro スキーマのシリアライザーと逆シリアライザー¶
このドキュメントでは、Apache Kafka® の Java クライアントやコンソールツールで Avro スキーマを使用する方法について説明します。
Avro シリアライザー¶
KafkaAvroSerializer を KafkaProducer にプラグインすることで、Avro 型のメッセージを Kafka に送信できます。
現在サポートされているプリミティブ型は、null、Boolean、Integer、Long、Float、Double、String、byte[] のほか、IndexedRecord という複合型です。その他の型のデータを KafkaAvroSerializer に送信すると、SerializationException が発生します。通常、Kafka メッセージの値には IndexedRecord が使用されます。
Kafka メッセージのキーは(使用されている場合)、たいてい前述のいずれかのプリミティブ型に該当します。メッセージをトピック t に送信すると自動的に、キーと値の Avro スキーマが、それぞれ t-key および t-value というサブジェクトで Schema Registry に登録されます(互換性テストを通過した場合)。唯一の例外は null 型で、Schema Registry に登録されることはありません。
次の例では、string 型のキーと Avro record 型の値を含んだメッセージを Kafka に送信します。データの形式が正しくないと、send の呼び出し中に SerializationException が発生する可能性があります。
ちなみに
以下の例では、Kafka ブートストラップサーバーと Schema Registry にデフォルトのアドレスとポート(それぞれ localhost:9092 および localhost:8081)が使用されています。
import org.apache.avro.Schema;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericRecord;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import io.confluent.kafka.serializers.KafkaAvroSerializer;
import java.util.Properties;
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
org.apache.kafka.common.serialization.StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
io.confluent.kafka.serializers.KafkaAvroSerializer.class);
props.put("schema.registry.url", "http://localhost:8081");
KafkaProducer producer = new KafkaProducer(props);
String key = "key1";
String userSchema = "{\"type\":\"record\"," +
"\"name\":\"myrecord\"," +
"\"fields\":[{\"name\":\"f1\",\"type\":\"string\"}]}";
Schema.Parser parser = new Schema.Parser();
Schema schema = parser.parse(userSchema);
GenericRecord avroRecord = new GenericData.Record(schema);
avroRecord.put("f1", "value1");
ProducerRecord<Object, Object> record = new ProducerRecord<>("topic1", key, avroRecord);
try {
producer.send(record);
} catch(SerializationException e) {
// may need to do something with it
}
// When you're finished producing records, you can flush the producer to ensure it has all been written to Kafka and
// then close the producer to free its resources.
finally {
producer.flush();
producer.close();
}
ちなみに
avro-maven-plugin によって生成されたコードで Java 固有のプロパティ("avro.java.string":"String" など)が追加され、それによってスキーマの進化が妨げられる場合があります。これは、Avro シリアライザーの構成で avro.remove.java.properties=true を設定することでオーバーライドできます。
Avro 逆シリアライザー¶
KafkaAvroDeserializer を KafkaConsumer にプラグインすることで、Avro 型のメッセージを Kafka から受信できます。次の例では、string 型のキーと Avro record 型の値を含んだメッセージを Kafka から受信します。データの形式が正しくないと、メッセージのキーまたは値を受け取る際に SerializationException が発生する可能性があります。
ちなみに
以下の例では、Kafka ブートストラップサーバーと Schema Registry にデフォルトのアドレスとポート(それぞれ localhost:9092 および localhost:8081)が使用されています。
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.avro.generic.GenericRecord;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.Arrays;
import java.util.Properties;
import java.util.Random;
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "group1");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "io.confluent.kafka.serializers.KafkaAvroDeserializer");
props.put("schema.registry.url", "http://localhost:8081");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
String topic = "topic1";
final Consumer<String, GenericRecord> consumer = new KafkaConsumer<String, GenericRecord>(props);
consumer.subscribe(Arrays.asList(topic));
try {
while (true) {
ConsumerRecords<String, GenericRecord> records = consumer.poll(100);
for (ConsumerRecord<String, GenericRecord> record : records) {
System.out.printf("offset = %d, key = %s, value = %s \n", record.offset(), record.key(), record.value());
}
}
} finally {
consumer.close();
}
Avro では、プロパティを使用して具体的な型を指定する必要はありません。型は、Avro 型の名前空間と名前を使用して Avro スキーマから直接導出されます。そのため、異種混合の Avro 型から成るレコードを含んだトピックに対して Avro デシリアライザーをそのまま使用できます。Martin Kleppmann のブログ記事「Should You Put Several Event Types in the Same Kafka Topic?」で取り上げられているように、``RecordNameStrategy` (または TopicRecordNameStrategy)を使用して、同じトピックに複数の型を格納する場合がこれに該当します<https://www.confluent.io/blog/put-several-event-types-kafka-topic/>`__。(「同じトピック内の複数のイベントタイプ」と「Putting Several Event Types in the Same Topic – Revisited」で取り上げられているような、スキーマ参照を使用する方法もあります)。
この点は、 Protobuf や JSON Schema のデシリアライザーとは異なります。汎用的な型ではなく具体的な型をこれらのデシリアライザーで取得するためには、特定のプロパティを使用する必要があります。
以下の表は、返される具体的な型と汎用的な型をスキーマ形式ごとにまとめたものです。
| Avro | Protobuf | JSON Schema | |
|---|---|---|---|
| 具体的な型 | 生成されたクラス(org.apache.avro.SpecificRecord を実装) | 生成されたクラス(com.google.protobuf.Message を拡張) | Java クラス(Jackson シリアル化との互換性あり) |
| 汎用的な型 | org.apache.avro.GenericRecord | com.google.protobuf.DynamicMessage | com.fasterxml.jackson.databind.JsonNode |
Avro スキーマの使用例¶
Avro スキーマ形式の実際の動作と使用例を確認するために、コンソールからコマンドライン kafka-avro-console-producer と kafka-avro-console-consumer を使用して、Avro データを JSON フォーマットで送受信します。内部では、プロデューサーとコンシューマーが AvroMessageFormatter と AvroMessageReader を使用して、Avro と JSON との間で変換を実行します。
Avro には、バイナリシリアル化フォーマットと JSON シリアル化フォーマットの両方が定義されています。人間が読めるようにしたければ JSON を使用し、トピックへのデータの格納効率を優先したければバイナリフォーマットを使用することができます。
注釈
- 以下の例を実行するための前提条件は、 Schema Registry のチュートリアル に記載されている条件とほぼ同じです。ただし、ここでは Maven は必要ありません。また、ここでは Confluent Platform バージョン 5.5.0 以降が必要となります。
- 以降の例では、Schema Registry の URL にデフォルト値(
localhost:8081)が使用されています。これらの例を見ると、その URL をプロデューサーとコンシューマーのコマンドライン引数の--propertyフラグに引数として指定することにより、インラインでこの値を設定していることがわかります(--property schema.registry.url=<実際の Schema Registry のアドレス>)。別の方法として、このプロパティを$CONFLUENT_HOME/etc/kafka/server.propertiesで設定することもできます。そうすれば、プロデューサーとコンシューマーのコマンドで URL を指定する必要はありません。たとえば、「confluent.schema.registry.url=http://localhost:8081」のように指定します。
以下の例では、$CONFLUENT_HOME/bin にある kafka-avro-console-producer と kafka-avro-console-consumer を利用しています。
コマンドラインのプロデューサーとコンシューマーは、Confluent Platform における組み込みの Avro スキーマ機能の働きを理解するうえで役立ちます。
実際にプロデューサーとコンシューマーのコードにシリアライザーとデシリアライザーを組み込んだときにも、コンソールから実行したときと同じようにメッセージおよび関連するスキーマが処理されます。
プロデューサーを実行した直後にコンシューマーを実行できなかった場合でも確実にメッセージを取り込むために、コンシューマーコマンドには、先頭から読み取るためのフラグ(--from-beginning)を指定することをお勧めします。--from-beginning フラグを省略した場合、コンシューマーは、現在のセッション中に生成された最後のメッセージしか読み取りません。
次のコマンドを使用して Confluent Platform を起動します。
confluent local services startちなみに
- 単に
confluent local schema-registryを実行してもかまいません。その場合は、依存関係としてkafkaとzookeeperも起動されます。このデモでは、Connect や Control Center など、他のサービスを直接参照することはしていません。もっとも、さらに理解を深めるために(トピックやメッセージが Control Center にどのように表示されるかなど)、フルスタックを実行したい場合もあるでしょう。confluent localの詳細については、「Confluent Platform のクイックスタート(ローカルインストール)」および Confluent CLI コマンドリファレンスの「confluent local」を参照してください。 confluent localのコマンドはバックグラウンドで実行されるので、そのコマンドウィンドウを再利用することができます。プロデューサーとコンシューマーのセッションは独立している必要があります。
- 単に
登録されているスキーマタイプを確認します。
Confluent Platform 5.5.0 以降では、Schema Registry で任意のスキーマタイプがサポートされます。どのタイプのスキーマが現在 Schema Registry に登録されているかを確認する必要があります。
そこで、次のコマンドを入力します(Schema Registry の URL とポートには、デフォルトの
localhost:8081が使用されているものとします)。curl http://localhost:8081/schemas/types
次のいずれかまたは複数の項目が応答として返されます。さらに、スキーマ形式プラグインがインストールされている場合は、それらも候補となります。
["JSON", "PROTOBUF", "AVRO"]
または、
curl --silentフラグを使用し、コマンドをパイプで jq に連結すれば(curl --silent http://localhost:8081/schemas/types | jq)、整った書式の出力結果を得ることができます。"JSON", "PROTOBUF", "AVRO"
プロデューサーを使用して、JSON 形式の Avro レコードをメッセージの値として送信します。
トピック
t1-aがまだ存在しない場合、このプロデューサーコマンドの実行過程で新たに作成されます。kafka-avro-console-producer --broker-list localhost:9092 --property schema.registry.url=http://localhost:8081 --topic t1-a \ --property value.schema='{"type":"record","name":"myrecord","fields":[{"name":"f1","type":"string"}]}'ちなみに
現在の Avro 用プロデューサーには、
>プロンプトが表示 "されません"。単に空白の行が表示され、そこにプロデューサーのメッセージを入力します。シェルに次のコマンドを入力し、Return キーを押します。
{"f1": "value1-a"}コンシューマーを使用して、トピック
t1-aからメッセージを読み取り、その値を JSON で取得します。kafka-avro-console-consumer --bootstrap-server localhost:9092 --from-beginning --topic t1-a --property schema.registry.url=http://localhost:8081
コンソールには次のように表示されます。
{"f1": "value1-a"}新しいプロデューサーコマンドを実行して、JSON 形式の文字列と Avro レコードを、それぞれメッセージのキーと値として新しいトピック(
t2-a)に送信します。プロデューサーに同じシェルを使用する場合は、Ctrl キーを押しながら C キーを押して先ほどのプロデューサーを停止し、次の新しいプロデューサーコマンドを実行します。
kafka-avro-console-producer --broker-list localhost:9092 --topic t2-a \ --property parse.key=true \ --property "key.separator= "\ --property key.schema='{"type":"string"}' \ --property value.schema='{"type":"record","name":"myrecord","fields":[{"name":"f1","type":"string"}]}' \ --property schema.registry.url=http://localhost:8081シェルで、次のように入力します。
"key1" {"f1": "value2-a"}このプロデューサーセッションは実行したままにしてください。
コンシューマーを使用してトピック
t2-aから、メッセージのキーと値の両方を JSON 形式で読み取ります。(Ctrl キーを押しながら C キーを押して、トピック
t1-aから読み取りを行っていたコンシューマーを停止します。続けて、次の新しいコマンドを使用してコンシューマーを再起動し、トピックt2-aからキーと値を読み取ります。)kafka-avro-console-consumer --from-beginning --topic t2-a \ --bootstrap-server localhost:9092 \ --property print.key=true \ --property schema.registry.url=http://localhost:8081
コンソールには次のように表示されます。
"key1" {"f1": "value2-a"}コンシューマーを再起動して、再度トピック
t2-aから読み取ります。今回は、メッセージのキーと値を、そのスキーマ ID とともに JSON 形式で出力します。登録中、Schema Registry は、既に登録されているスキーマの ID より大きい ID を新しいスキーマに割り当てます。Schema Registry インスタンスが異なれば、ID も異なる場合があります。
kafka-avro-console-consumer --from-beginning --topic t2-a \ --bootstrap-server localhost:9092 \ --property print.key=true \ --property print.schema.ids=true \ --property schema.id.separator=: \ --property schema.registry.url=http://localhost:8081
コンソールには次のように表示されます。
"key1":2 {"f1":"value2-a"}:1コンシューマーを使用してトピックから読み取りを行う際に、カスタムのキーデシリアライザー(値とは異なるフォーマット)を指定することもできます。Avro 以外のフォーマットのキーがトピックに含まれている場合は、次のようにして、独自のキーデシリアライザーを指定できます。
kafka-avro-console-consumer --from-beginning --topic t2-a \ --bootstrap-server localhost:9092 \ --property print.key=true \ --key-deserializer=org.apache.kafka.common.serialization.StringDeserializer \ --property schema.registry.url=http://localhost:8081
現在のコンシューマーセッションは実行したままにしてください(この手順に示したどちらか一方のコンシューマーでかまいません)。
プロデューサーセッションに戻り、プロンプトで新しい値を入力します。
"key1" {"f1": "value3-a"}コンシューマーセッションに戻り、最後に生成した値がコンシューマーのコンソールに反映されていることを確認します。
"key1" {"f1":"value3-a"}Confluent Control Center を使用して、スキーマとメッセージを調査します。
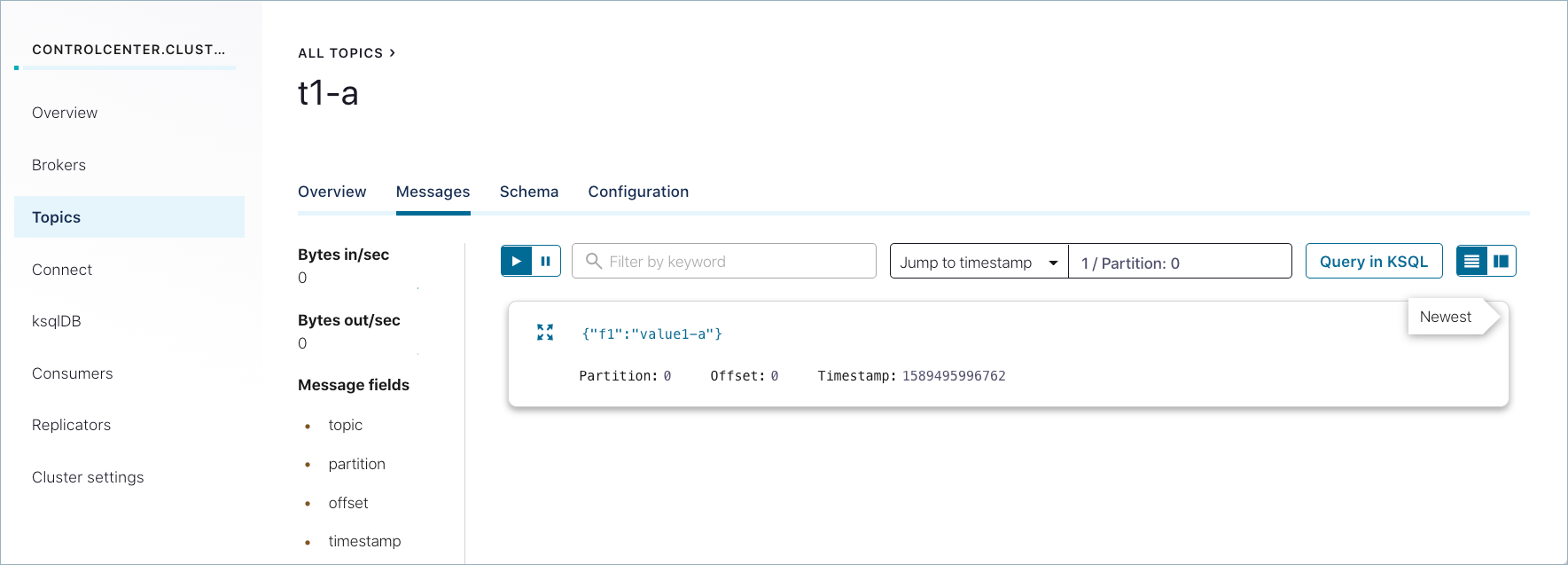
正常に生成されたメッセージは、Control Center (http://localhost:9021/)の Topics > <トピック名> > Messages にも表示されます。以前に送信されたメッセージを表示するには、パーティションを選択するか、タイムスタンプに移動しなければならない場合があります。(タイムスタンプに移動するには、数値を入力して Return キーを押します。デフォルトのパーティションは
1/Partition: 0です。ここに示されているようなメッセージビューを取得するには、右上の カード アイコンを選択します。)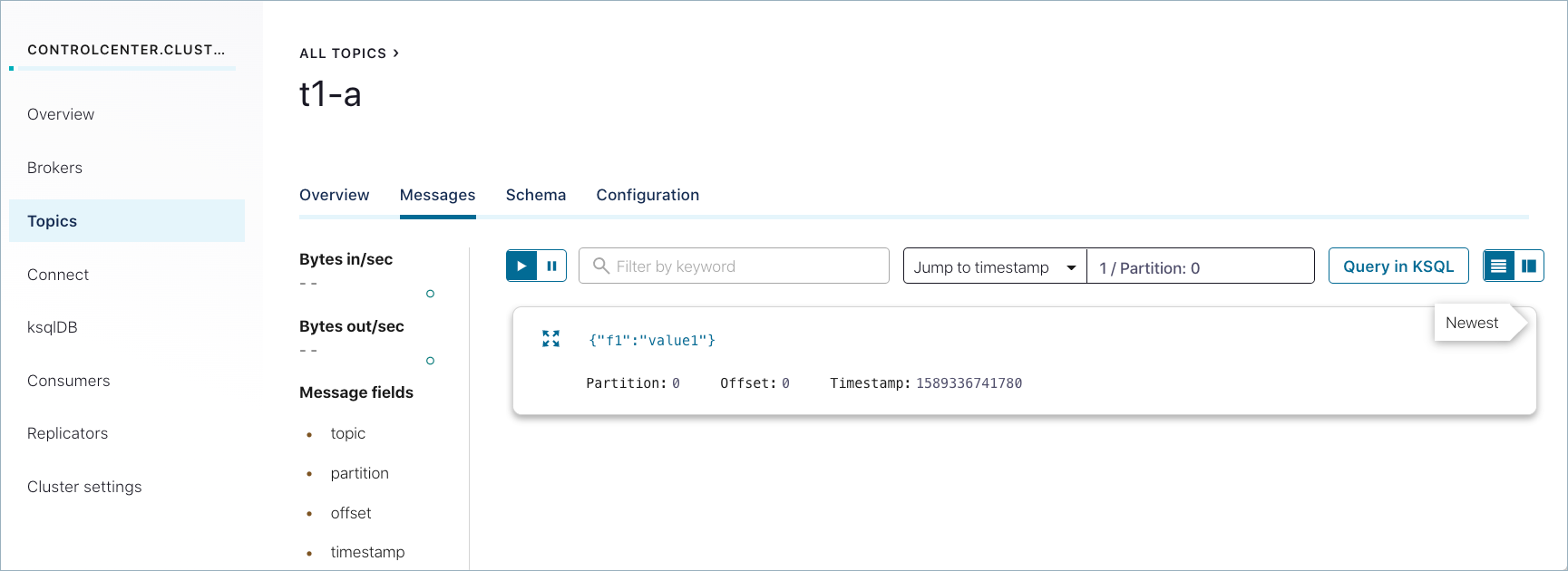
作成するスキーマには、選択したトピックの Schemas タブからアクセスできます。
シャットダウンとクリーンアップのタスクを実行します。
- コンシューマーとプロデューサーを停止するには、それぞれのコマンドウィンドウで Ctrl キーを押しながら C キーを押します。
- Confluent Platform を停止するには、「
confluent local stop」と入力します。 - 別のテストを最初から実行する前に既存のデータ(トピック、スキーマ、メッセージ)を削除する場合は、「
confluent local destroy」と入力します。
Avro のスキーマ参照¶
Confluent Platform は、 スキーマ参照 (スキーマから別のスキーマを参照する機能)という概念をフルサポートします。
ちなみに
Confluent Cloud でも、Avro、Protobuf、JSON Schema の各形式でスキーマ参照がサポートされます。Confluent Cloud CLI から、ccloud schema-registry schema create の --refs <file> フラグを使用することで他のスキーマを参照できます。
詳細については、以下の「同じトピック内の複数のイベントタイプ」で取り上げられている例や、この点について詳しく解説している ブログ記事、さらに POST /subjects/(string: subject)/versions で新しいスキーマを登録(作成)する API の例を参照してください。この例に、参照先スキーマが記載されています。
同じトピック内の複数のイベントタイプ¶
スキーマ参照 が提供するのは、あるスキーマから他のスキーマを呼び出すしくみだけではありません。スキーマ参照を使用することで、複数のイベントタイプを同じトピックの中で効率よく組み合わせ ながらも、サブジェクト-トピック制約を維持することができます。
Avro でこれを実現するには、次のようにします。
デフォルトの サブジェクト命名方法 である
TopicNameStrategyを使用します。この命名方法では、スキーマのルックアップに使用されるサブジェクトがトピック名を使用して決定されます。また、この命名方法によって、サブジェクト-トピック制約の適用が促されます。Avro の union を使用し、スキーマ名のリストとしてスキーマ参照を定義する。その例を次に示します。
[ "io.confluent.examples.avro.Customer", "io.confluent.examples.avro.Product", "io.confluent.examples.avro.Payment" ]
スキーマが登録されるときに、参照バージョンの配列を送信します。以下に例を示します。
[ { "name": "io.confluent.examples.avro.Customer", "subject": "customer", "version": 1 }, { "name": "io.confluent.examples.avro.Product", "subject": "product", "version": 1 }, { "name": "io.confluent.examples.avro.Order", "subject": "order", "version": 1 } ]プロデューサーアプリケーションで次のプロパティを構成し、イベントタイプではなく Avro の union を使用してシリアル化を行うように Avro シリアライザーを構成する。
auto.register.schemas=false use.latest.version=true
以下に例を示します。
props.put(AbstractKafkaAvroSerDeConfig.AUTO_REGISTER_SCHEMAS, false); props.put(AbstractKafkaAvroSerDeConfig.USE_LATEST_VERSION, true);
ちなみに
auto.register.schemasを false に設定すると、イベントタイプの自動登録が無効になるので、union がサブジェクト内の最新のスキーマとしてオーバーライドされることはありません。use.latest.versionが true に設定されている場合、Avro シリアライザーは、(union となる)サブジェクトから最新のスキーマバージョンを検索し、それをシリアル化に使用します。それ以外の(false に設定されている)場合、シリアライザーは、サブジェクトからイベントタイプを探しますが、その検出に失敗します(Schema Registry のチュートリアルの「スキーマの自動登録」も参照してください)。- Kafka Connect の Schema Registry の「構成オプション」も参照してください。
リフレクションベースの Avro シリアライザーと逆シリアライザー¶
バージョン 5.4.0 以降の Confluent Platform は、ReflectionAvroSerializer と ReflectionAvroDeserializer を使用したリフレクション Avro フォーマットでのデータの読み取りと書き込みにも対応しています。
シリアライザーは、 こちらに定義されている wire フォーマット でデータを書き込み、デシリアライザーは、同じ wire フォーマットを使用してデータを読み取ります。
リフレクションベースの Avro シリアライザーおよびデシリアライザーの serde は ReflectionAvroSerde です。
詳細については、「Streams 開発者ガイド」の「Kafka Streams のデータ型とシリアル化」を参照してください。
Allow for Null Fields¶
Starting with version 6.2.0 of Confluent Platform, a new configuration option, avro.reflection.allow.null, was added to support null fields when using the リフレクションベースの Avro シリアライザーと逆シリアライザー.
If avro.reflection.allow.null is set to true, null values are allowed in fields. (The default is false.)
Avro スキーマの互換性ルール¶
Avro の互換性ルールについては、仕様の「Schema Resolution」に詳しく説明されています。
概要の「スキーマ進化と互換性」および「互換性チェック」も参照してください。
おすすめの関連情報¶
- Kafka クライアントのプロデューサーとコンシューマーの例が「Apache Kafka® のサンプルコード」に掲載されています(Avro を使用している例と使用していない例があります)。
- Schema Registry API リファレンス
- Schema Registry API の使用例
- Apache Avro プロジェクト
- Apache Avro ドキュメント