Important
You are viewing documentation for an older version of Confluent Platform. For the latest, click here.
Configuring Control Center¶
Control Center is a component of Confluent Platform and the binaries are located at https://www.confluent.io/download/ as a part of the Confluent Platform bundle.
System Requirements¶
For the complete Control Center system requirements, see the Confluent Platform system requirements.
Important
To use Control Center, you must have access the host that runs the application. You can configure the network port that Confluent Control Center uses to serve data. Because Confluent Control Center is a web application, you can use a proxy to control and secure access to it.
Configuration¶
Control Center stores cluster metadata and user data (triggers/actions) in the _confluent-command topic.
This topic is not changed during an upgrade. To reset it, change the confluent.controlcenter.command.topic config
to something else (e.g. _confluent-command-2) and restart Control Center,
this will re-index the cluster metadata and remove all triggers/actions.
By default, Control Center keeps 3 days worth of data for the monitoring topic _confluent-monitoring and metrics topic _confluent-metrics,
and 24 hours of data of all of it’s internal topics.
This means that you can take Control Center down for maintenance for as long as 24 hours without data loss.
You can change these values by setting the following config parameters:
confluent.monitoring.interceptor.topic.retention.msconfluent.metrics.topic.retention.msconfluent.controlcenter.internal.topics.retention.ms
Control Center also has a number of internal topics that it uses for aggregations. Data on these topics is kept with different retention periods based on the data type.
- Streams Monitoring data is held at two retention levels, 96 hours for granular data, and 700 days for historical data. For example, if you have the same number of clients reading and writing granular data from the same number of topics, the amount of space that is required is about twice the amount needed for running at 96 hours.
- Metrics data has a retention period of 7 days. With a constant number of topic partitions in a cluster, the amount of data that is used for metrics data should grow linearly and max out after 7 days of accumulation.
By default, Control Center stores 3 copies on all topic partitions for availability and fault tolerance.
The full set of configuration options are documented in Control Center Parameter Reference.
Partitions and Replication¶
Define the number of partitions (<num-partitions>) and replication (<num-replication>) settings for Control Center by
adding these lines to your properties file (<path-to-file>/etc/confluent-control-center/control-center.properties).
confluent.controlcenter.internal.topics.partitions=<num-partitions>
confluent.controlcenter.internal.topics.replication=<num-replication>
confluent.controlcenter.command.topic.replication=<num-replication>
confluent.monitoring.interceptor.topic.partitions=<num-partitions>
confluent.monitoring.interceptor.topic.replication=<num-replication>
confluent.metrics.topic.partitions=<num-partitions>
confluent.metrics.topic.replication=<num-replication>
For more information, see the Control Center Parameter Reference.
Multi-Cluster Configuration¶
You can use Control Center to manage and monitor multiple Kafka clusters. All metric data from the interceptors and metrics reporters is tagged by Apache Kafka® cluster ID and aggregated in Control Center by cluster ID. The cluster ID is randomly generated by Kafka, but you can assign meaningful names using Control Center.
To manage and monitor multiple clusters with Control Center, you must have the following prerequisites:
- Control Center must be installed.
- Multiple Kafka clusters must be already running. You cannot deploy new clusters with Control Center. This will be added in a future release of Control Center.
- Each Kafka cluster must have Confluent Metrics Reporter configured to enable monitoring
- Each Kafka cluster must be specified in the Control Center configuration using its own
confluent.controlcenter.kafka.<name>.bootstrap.serversconfiguration. See Control Center Parameter Reference for more details.
There are two basic methods for configuring the interceptor and metrics reporter plugins in multi-cluster environments: direct and replicated.
With either method, you install a single Control Center server and connect to a Kafka cluster. This cluster acts as the storage and coordinator for Control Center.
- Direct: Using the direct method, the plugins will report the data directly to the Control Center cluster. If your network topology allows direct communication from interceptors and metrics reporters to the Control Center cluster, the direct method is the recommended solution.
- Replicated: Using the replicated method, the plugins will report data to a local Kafka cluster that they have access to. A replicator process will copy the data to the Control Center cluster. For more information, see the Replicator quick start. The replicated configuration is simpler to use when deploying interceptors, because they will report to the local cluster by default. Use this setup if you have a network topology that prevents Control Center plugins from communicating directly with the Control Center cluster, or if you are already using Replicator and you are familiar with its operations.
Direct
You can configure interceptors to send metrics data directly to the Control Center Kafka cluster. This cluster might be separate from the Kafka cluster that the Client being monitored is connected to.
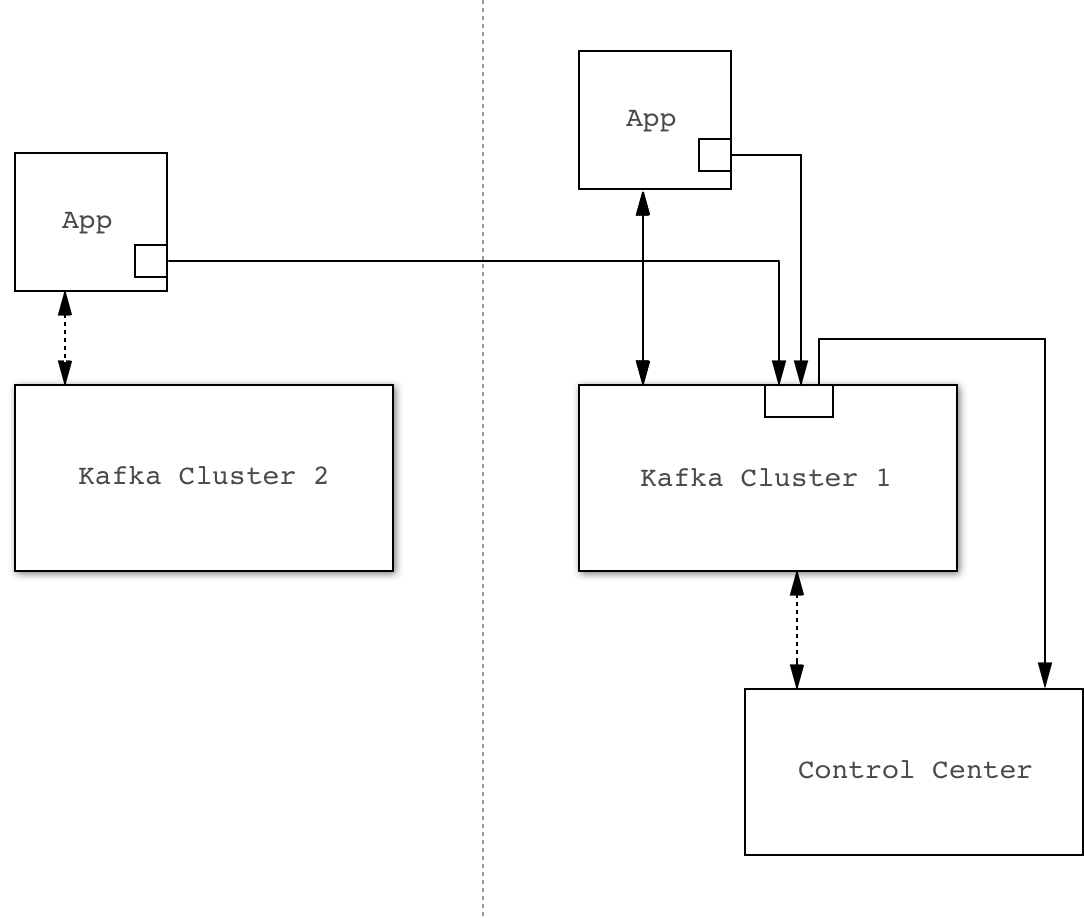
Example direct configuration. Solid lines indicate flow of interceptor data.
The primary advantage of this method is its robust protection against availability issues with the cluster being monitored.
The primary disadvantage is that every Kafka client must be configured with the Control Center Kafka cluster connection parameters. This could potentially be more time consuming, particularly if Confluent Control Center Security is enabled.
Here is an example configuration for a client:
bootstrap.servers=kafka-cluster-1:9092 # this is the cluster your clients are talking to
confluent.monitoring.interceptor.bootstrap.servers=kafka-cluster-2:9092 # this is the |c3-short| cluster
Replicated
By default, interceptors and metric reporters send metric data to the same Kafka cluster they are monitoring. You can
use Confluent Replicator to transfer and merge this data into the Kafka Cluster that
is used by Control Center. The _confluent-monitoring and _confluent-metrics topics must be replicated to the Control Center cluster.
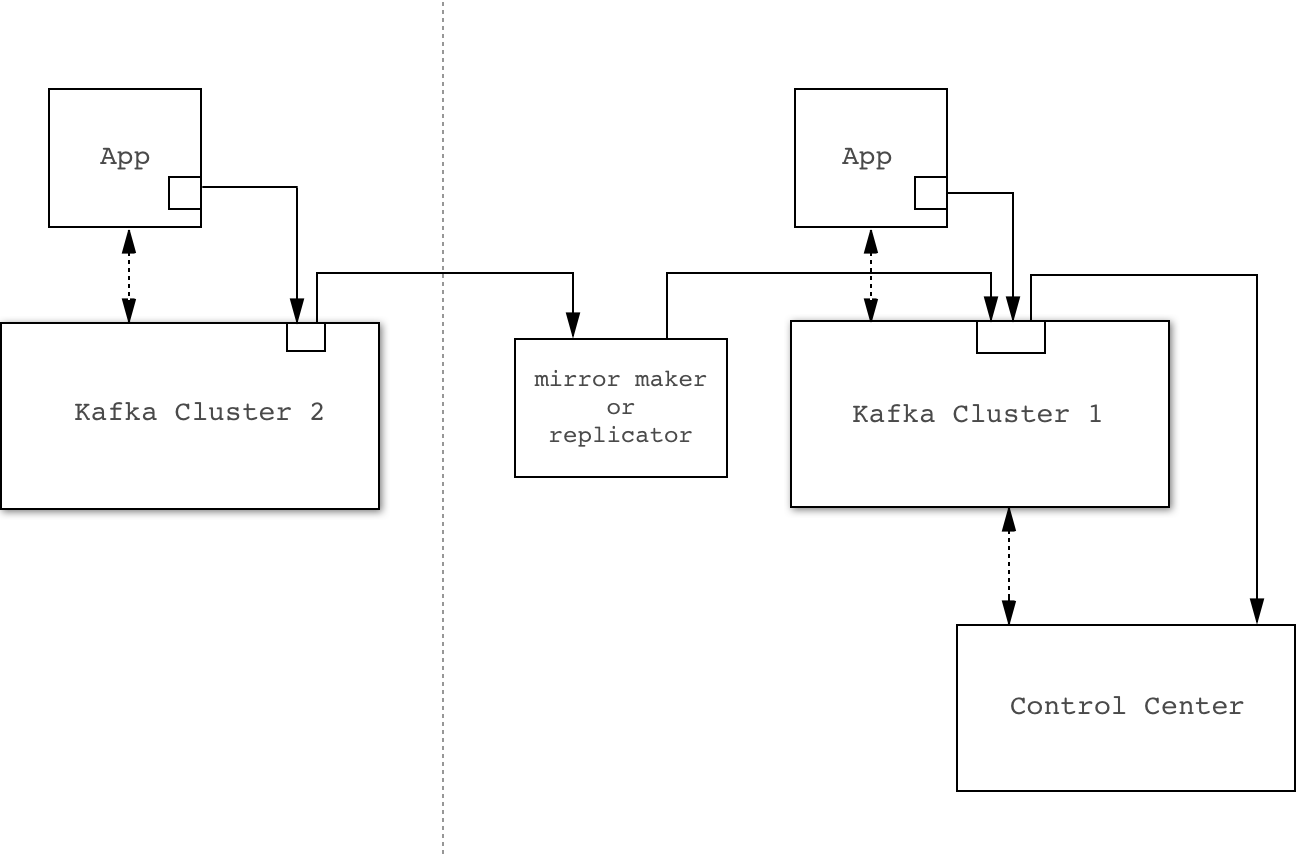
Example replicated configuration. Solid lines indicate flow of interceptor and cluster data.
Dedicated Metric Data Cluster¶
You can send your monitoring data to an existing Kafka cluster or configure a dedicated cluster for this purpose.
Here are the advantages to giving Control Center its own Kafka cluster:
- By hosting Control Center on its own Kafka Cluster, it is independent of the availability of the production cluster it is monitoring. For example, if there are severe production issues, you will continue to receive alerts and be able to view the Control Center monitoring information. A production disaster is when you need these metrics the most.
- Ease of upgrade. Future versions of Control Center are likely to take advantage of new features of Kafka. If you use a separate Kafka cluster for Control Center, it may be easier for you to take advantage of new features in future versions of Control Center if the upgrade path does not involve any production Kafka cluster.
- The cluster may have reduced security requirements that could make it easier to implement the direct strategy described.
- The Control Center requires a significant amount of disk space and throughput for metrics collection. By giving Control Center its own dedicated cluster, you guarantee that Control Center workload will never interfere with production traffic.
Here are the disadvantages of giving Control Center its own Kafka cluster:
- A dedicated cluster requires additional hardware (virtual or physical), setup, and maintenance.
- If Control Center uses a dedicated cluster, it probably cannot be used to manage Connectors. This will be fixed in a future release of Control Center.
Saturation Testing¶
Control Center was saturation-tested on simulated monitoring data. The goal is to find the maximum size cluster that Control Center can successfully monitor, along several important dimensions.
Test Setup¶
- All servers are running on EC2 m4.2xlarge
- Three Kafka brokers
- One Confluent Control Center instance
- Two nodes generating load, one for broker monitoring and one for stream monitoring
- Eight streams threads, which is
confluent.controlcenter.streams.num.stream.threadsdefault configuration. - JDK 8
Broker Monitoring¶
Kafka metrics were generated to simulate by a cluster with three brokers and no producers and consumers. The number of partitions were increased on the simulated cluster until we saw lag on Control Center.
Result: We were able to increase to 10,000 partitions. Control Center keeps up with the incoming metrics.
Caveat: Any change to sizing or network topology would likely give different results.
Streams Monitoring¶
Metrics were generated as if by a cluster with three brokers and 5000 partitions in 250 topics. The number of consumer groups was increased to report consumption completeness and lag data from 1 through 100,000, in 5,000 consumer group increments. Each simulated consumer group included a single consumer reading from a single partition.
Result: At 20,000 consumer groups, Control Center was no longer able to keep up with incoming data on this server size and the reports lagged behind.
Caveat: We tested up to 20,000 consumers, but no producers. This likely has impact on the monitoring capacity.
Example Deployments¶
Here are some example Control Center setup we tested internally.
Broker Monitoring¶
- Given:
- 1 Confluent Control Center (running on EC2 m4.2xlarge)
- 3 Kafka Brokers
- 1 ZooKeeper
- 200 Topics
- 10 Partitions per Topic
- 3x Replication Factor
- Default JVM settings
- Default Control Center config
- Default Kafka config
- Expect:
- Control Center state store size ~50MB/hr
- Kafka log size ~500MB/hr (per broker)
- Average CPU load ~7 %
- Allocated java on-heap memory ~580 MB and off-heap ~100 MB
- Total allocated memory including page cache ~3.6 GB
- Network read utilization ~150 KB/sec
- Network write utilization ~170 KB/sec
Streams Monitoring¶
- Given:
- 1 Confluent Control Center (running on EC2 m4.2xlarge)
- 3 Kafka Brokers
- 1 ZooKeeper
- 30 Topics
- 10 Partitions per Topic
- 150 Consumers
- 50 Consumer Groups
- 3x Replication Factor
- Default JVM settings
- Default Control Center config
- Default Kafka config
- Expect:
- Control Center state store size ~1 GB/hr
- Kafka log size ~1 GB/hr (per broker)
- Average CPU load ~8 %
- Allocated java on-heap memory ~600 MB and off-heap ~100 MB
- Total allocated memory including page cache ~4 GB
- Network read utilization ~160 KB/sec
- Network write utilization ~180 KB/sec
Next steps¶
- For troubleshooting information, see Troubleshooting Control Center.
- For a complete example that includes stream monitoring, see the Confluent Platform Quick Start.