Important
You are viewing documentation for an older version of Confluent Platform. For the latest, click here.
Cloud ETL Demo¶
As enterprises move more and more of their applications to the cloud, they are also moving their on-prem ETL (extract, transform, load) pipelines to the cloud, as well as building new ones. This demo showcases a cloud ETL solution leveraging all fully-managed services on Confluent Cloud.
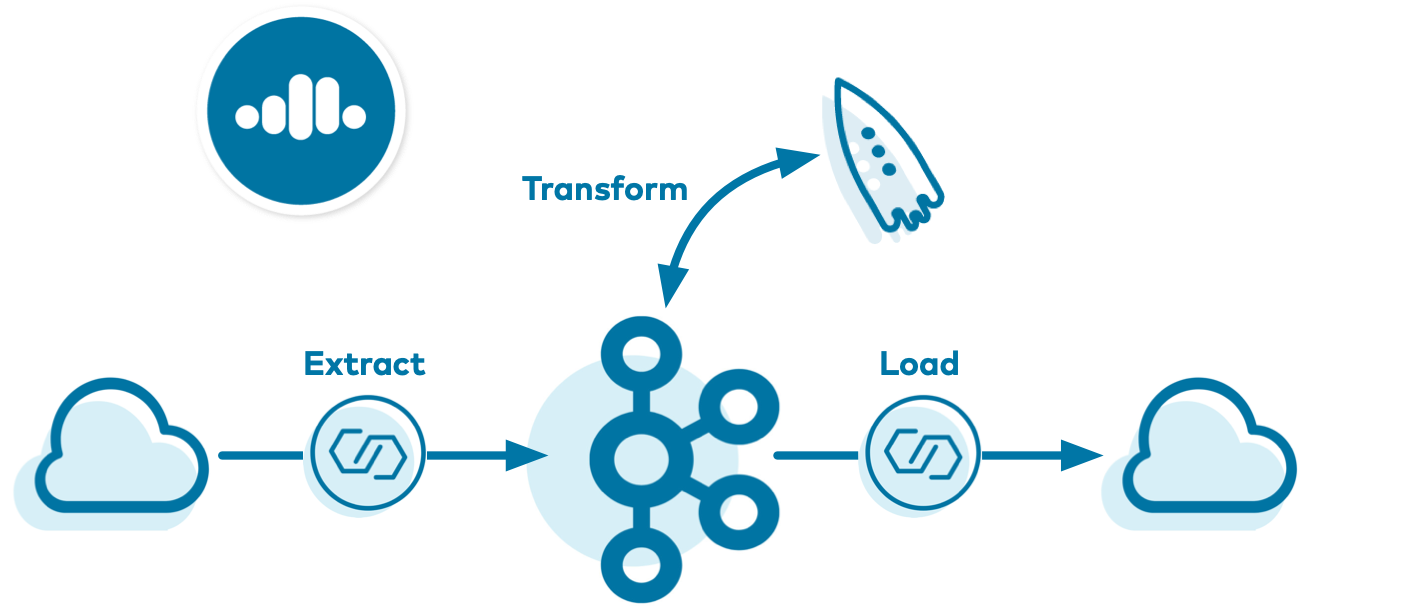
There are many powerful use cases for these real-time cloud ETL pipelines, and this demo showcases one such use case—a log ingestion pipeline that spans multiple cloud providers. Using Confluent Cloud CLI, the demo creates a source connector that reads data from either an AWS Kinesis stream or AWS RDS PostgreSQL database into Confluent Cloud. Then it creates a Confluent Cloud ksqlDB application that processes that data. Finally, a sink connector writes the output data into cloud storage in the provider of your choice (one of GCP GCS, AWS S3, or Azure Blob).
The end result is an event streaming ETL, running 100% in the cloud, spanning multiple cloud providers. This enables you to:
- Build business applications on a full event streaming platform
- Span multiple cloud providers (AWS, GCP, Azure) and on-prem datacenters
- Use Kafka to aggregate data into a single source of truth
- Harness the power of ksqlDB for stream processing
Tip
For more information about building a cloud ETL pipeline on Confluent Cloud, see this blog post.
Confluent Cloud Promo Code¶
The first 20 users to sign up for Confluent Cloud and use promo code C50INTEG will receive an additional $50 free usage (details).
End-to-end Streaming ETL¶
This demo showcases an entire end-to-end cloud ETL deployment, built for 100% cloud services:
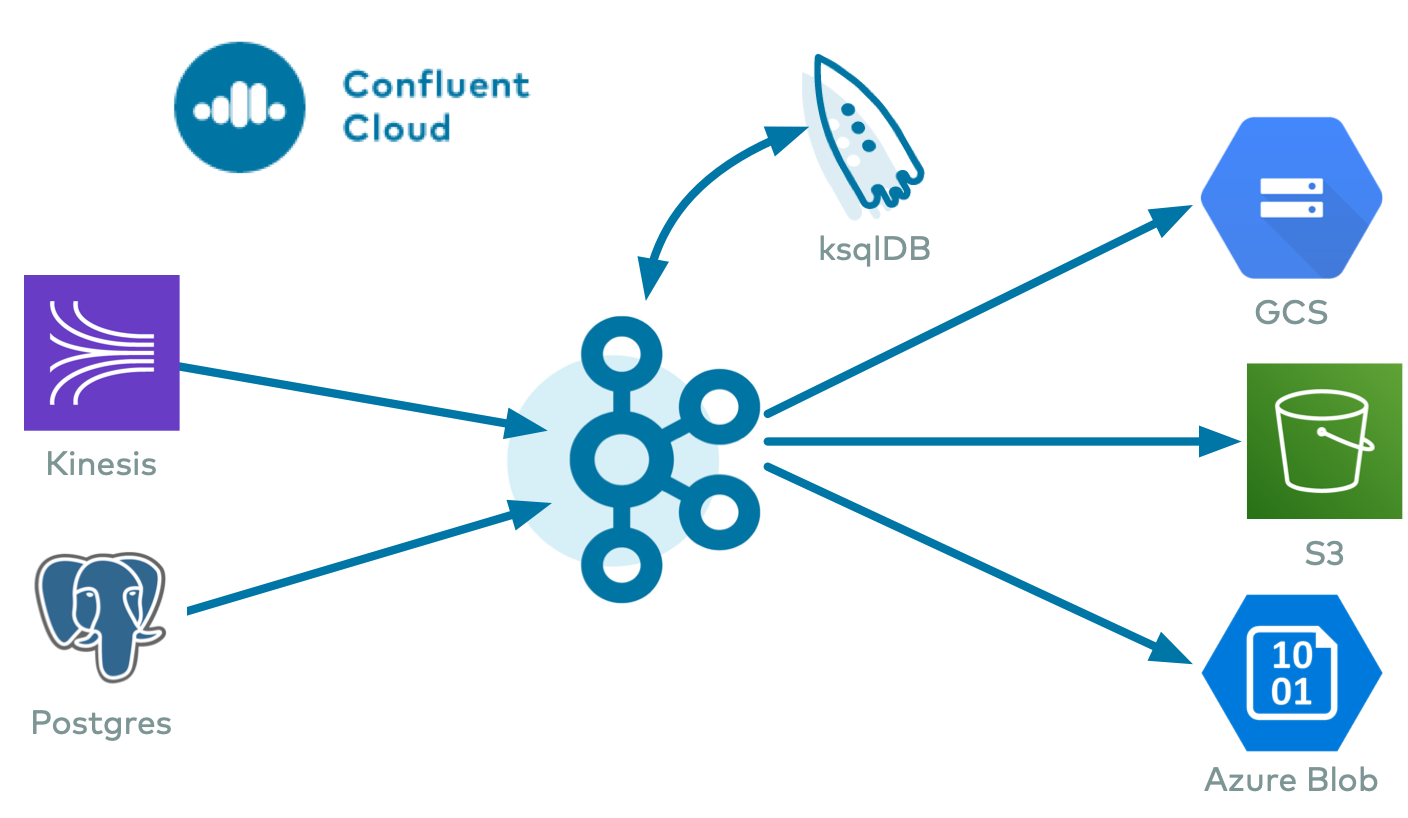
- Cloud source connectors: writes data to Kafka topics in Confluent Cloud from a cloud service, one of:
- Cloud sink connectors: writes data from Kafka topics in Confluent Cloud to cloud storage, one of:
- Confluent Cloud ksqlDB : streaming SQL engine that enables real-time data processing against Kafka
- Confluent Cloud Schema Registry: centralized management of schemas and compatibility checks as schemas evolve
Data Flow¶
The data set is a stream of log messages, which in this demo is mock data captured in eventlogs.json. It resembles this:
{"eventSourceIP":"192.168.1.1","eventAction":"Upload","result":"Pass","eventDuration":3}
{"eventSourceIP":"192.168.1.1","eventAction":"Create","result":"Pass","eventDuration":2}
{"eventSourceIP":"192.168.1.1","eventAction":"Delete","result":"Fail","eventDuration":5}
{"eventSourceIP":"192.168.1.2","eventAction":"Upload","result":"Pass","eventDuration":1}
{"eventSourceIP":"192.168.1.2","eventAction":"Create","result":"Pass","eventDuration":3}
| Component | Consumes From | Produces To |
|---|---|---|
| Kinesis/PostgreSQL source connector | Kinesis stream or RDS PostgreSQL table | Kafka topic
eventlogs |
| ksqlDB | eventlogs |
ksqlDB streams and tables |
| GCS/S3/Blob sink connector | ksqlDB tables
COUNT_PER_SOURCE,
SUM_PER_SOURCE |
GCS/S3/Blob |
Caution¶
This cloud-etl demo uses real cloud resources, including that of Confluent Cloud, AWS Kinesis or RDS PostgreSQL, and one of the cloud storage providers.
To avoid unexpected charges, carefully evaluate the cost of resources before launching the demo and ensure all resources are destroyed after you are done running it.
Prerequisites¶
Cloud services¶
- Confluent Cloud cluster
- Access to AWS and (optional) GCP or Azure
Local Tools¶
- Confluent Cloud CLI v1.7.0 or later, logged in with the
--saveargument which saves your Confluent Cloud user login credentials or refresh token (in the case of SSO) to the localnetrcfile. gsutilCLI, properly initialized with your credentials: (optional) if destination is GCP GCSawsCLI, properly initialized with your credentials: used for AWS Kinesis or RDS PostgreSQL, and (optional) if destination is AWS S3azCLI, properly initialized with your credentials: (optional) if destination is Azure Blob storagejqcurltimeout: used by the bash scripts to terminate a consumer process after a certain period of time.timeoutis available on most Linux distributions but not on macOS. macOS users should view the installation instructions for macOS.python- Download Confluent Platform 5.5.15: for more advanced Confluent CLI functionality (optional)
Run the Demo¶
Setup¶
Because this demo interacts with real resources in Kinesis or RDS PostgreSQL, a destination storage service, and Confluent Cloud, you must set up some initial parameters to communicate with these services.
This demo creates a new Confluent Cloud environment with required resources to run this demo. As a reminder, this demo uses real Confluent Cloud resources and you may incur charges so carefully evaluate the cost of resources before launching the demo.
Clone the examples GitHub repository and check out the
5.5.15-postbranch.git clone https://github.com/confluentinc/examples cd examples git checkout 5.5.15-post
Change directory to the
cloud-etldemo.cd cloud-etl
Modify the demo configuration file at config/demo.cfg. Set the proper credentials and parameters for the source:
- AWS Kinesis
DATA_SOURCE='kinesis'KINESIS_STREAM_NAMEKINESIS_REGIONAWS_PROFILE
- AWS RDS (PostgreSQL)
DATA_SOURCE='rds'DB_INSTANCE_IDENTIFIERRDS_REGIONAWS_PROFILE
- AWS Kinesis
In the same demo configuration file, set the required parameters for the destination cloud storage provider:
- GCP GCS
DESTINATION_STORAGE='gcs'GCS_CREDENTIALS_FILEGCS_BUCKET
- AWS S3
DESTINATION_STORAGE='s3'S3_PROFILES3_BUCKET
- Azure Blob
DESTINATION_STORAGE='az'AZBLOB_STORAGE_ACCOUNTAZBLOB_CONTAINER
- GCP GCS
Run¶
Log in to Confluent Cloud with the command
ccloud login --save, and use your Confluent Cloud username and password. The--saveargument saves your Confluent Cloud user login credentials or refresh token (in the case of SSO) to the localnetrcfile.ccloud login --save
Run the demo. You must explicitly set the cloud provider and region for your Confluent Cloud cluster when you start the demo, and they must match the destination cloud storage provider and region. This will take several minutes to complete as it creates new resources in Confluent Cloud and other cloud providers.
# Example for running to AWS S3 in us-west-2 CLUSTER_CLOUD=aws CLUSTER_REGION=us-west-2 ./start.sh # Example for running to GCP GCS in us-west2 CLUSTER_CLOUD=gcp CLUSTER_REGION=us-west2 ./start.sh # Example for running to Azure Blob in westus2 CLUSTER_CLOUD=azure CLUSTER_REGION=westus2 ./start.sh
As part of this script run, it creates a new Confluent Cloud stack of fully managed resources and generates a local configuration file with all connection information, cluster IDs, and credentials, which is useful for other demos/automation. View this local configuration file, where
SERVICE ACCOUNT IDis auto-generated by the script.cat stack-configs/java-service-account-<SERVICE ACCOUNT ID>.config
Your output should resemble:
# -------------------------------------- # Confluent Cloud connection information # -------------------------------------- # ENVIRONMENT ID: <ENVIRONMENT ID> # SERVICE ACCOUNT ID: <SERVICE ACCOUNT ID> # KAFKA CLUSTER ID: <KAFKA CLUSTER ID> # SCHEMA REGISTRY CLUSTER ID: <SCHEMA REGISTRY CLUSTER ID> # KSQLDB APP ID: <KSQLDB APP ID> # -------------------------------------- ssl.endpoint.identification.algorithm=https security.protocol=SASL_SSL sasl.mechanism=PLAIN bootstrap.servers=<BROKER ENDPOINT> sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username\="<API KEY>" password\="<API SECRET>"; basic.auth.credentials.source=USER_INFO schema.registry.basic.auth.user.info=<SR API KEY>:<SR API SECRET> schema.registry.url=https://<SR ENDPOINT> ksql.endpoint=<KSQLDB ENDPOINT> ksql.basic.auth.user.info=<KSQLDB API KEY>:<KSQLDB API SECRET>
Log into the Confluent Cloud UI at http://confluent.cloud .
Connectors¶
The demo automatically created Kafka Connect connectors using the Confluent Cloud CLI command
ccloud connector createthat included passing in connector configuration files from the connector configuration directory:- AWS Kinesis source connector configuration file
- PostgreSQL source connector configuration file
- GCS sink connector configuration file
- GCS sink connector with Avro configuration file
- S3 sink connector configuration file
- S3 sink connector with Avro configuration file
- Azure Blob sink connector configuration file
- Azure Blob sink connector with Avro configuration file
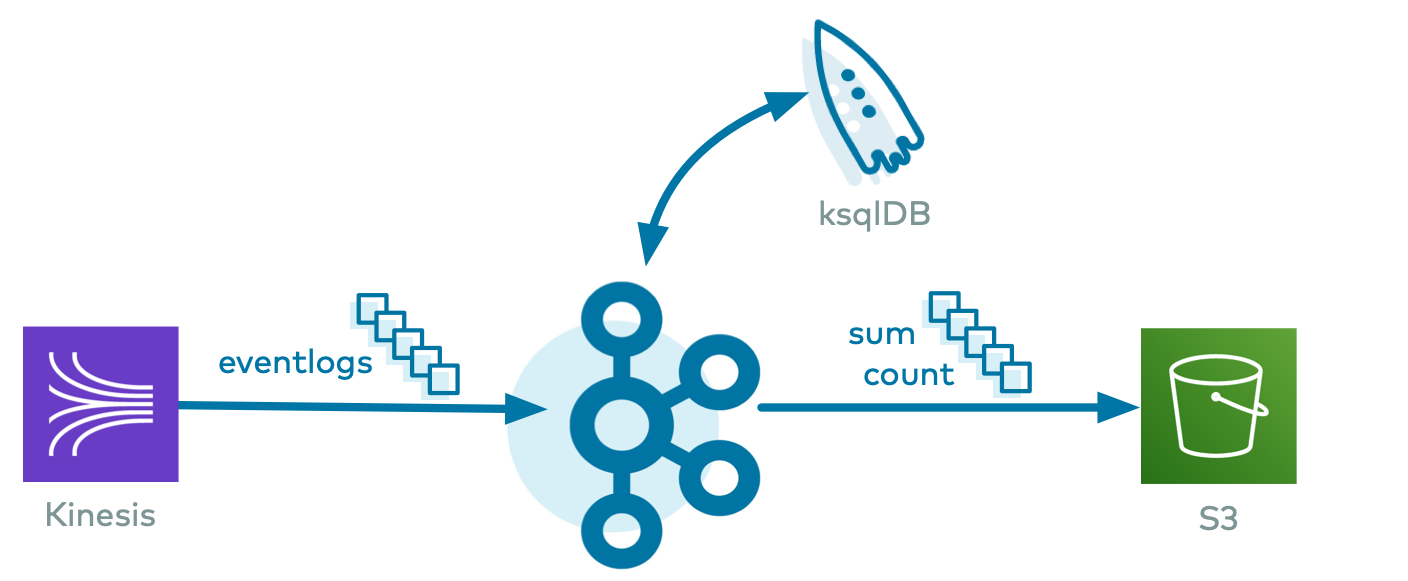
For example, if you configured the demo to source data from Kinesis, it ran this AWS Kinesis connector configuration file.
{ "name": "demo-KinesisSource", "connector.class": "KinesisSource", "tasks.max": "1", "kafka.api.key": "$CLOUD_KEY", "kafka.api.secret": "$CLOUD_SECRET", "aws.access.key.id": "$AWS_ACCESS_KEY_ID", "aws.secret.key.id": "$AWS_SECRET_ACCESS_KEY", "kafka.topic": "$KAFKA_TOPIC_NAME_IN", "kinesis.region": "$KINESIS_REGION", "kinesis.stream": "$KINESIS_STREAM_NAME", "kinesis.position": "TRIM_HORIZON" }Let’s say you ran the demo with Kinesis as the source and S3 as the sink, the pipeline would resemble:
Using the Confluent Cloud CLI, list all the fully-managed connectors created in this cluster.
ccloud connector list
Your output should resemble:
ID | Name | Status | Type | Trace +-----------+---------------------+---------+--------+-------+ lcc-2jrx1 | demo-S3Sink-no-avro | RUNNING | sink | lcc-vnrqp | demo-KinesisSource | RUNNING | source | lcc-5qwrn | demo-S3Sink-avro | RUNNING | sink |
Describe any running connector in more detail, in this case
lcc-vnrqpwhich corresponds to the the AWS Kinesis connector.ccloud connector describe lcc-vnrqp
Your output should resemble:
Connector Details +--------+--------------------+ | ID | lcc-vnrqp | | Name | demo-KinesisSource | | Status | RUNNING | | Type | source | | Trace | | +--------+--------------------+ Task Level Details TaskId | State +--------+---------+ 0 | RUNNING Configuration Details Config | Value +---------------------+---------------------------------------------------------+ name | demo-KinesisSource kafka.api.key | **************** kafka.api.secret | **************** schema.registry.url | https://psrc-4yovk.us-east-2.aws.confluent.cloud cloud.environment | prod kafka.endpoint | SASL_SSL://pkc-4kgmg.us-west-2.aws.confluent.cloud:9092 kafka.region | us-west-2 kafka.user.id | 73800 kinesis.position | TRIM_HORIZON kinesis.region | us-west-2 kinesis.stream | demo-logs aws.secret.key.id | **************** connector.class | KinesisSource tasks.max | 1 aws.access.key.id | ****************View these same connectors from the Confluent Cloud UI at https://confluent.cloud/
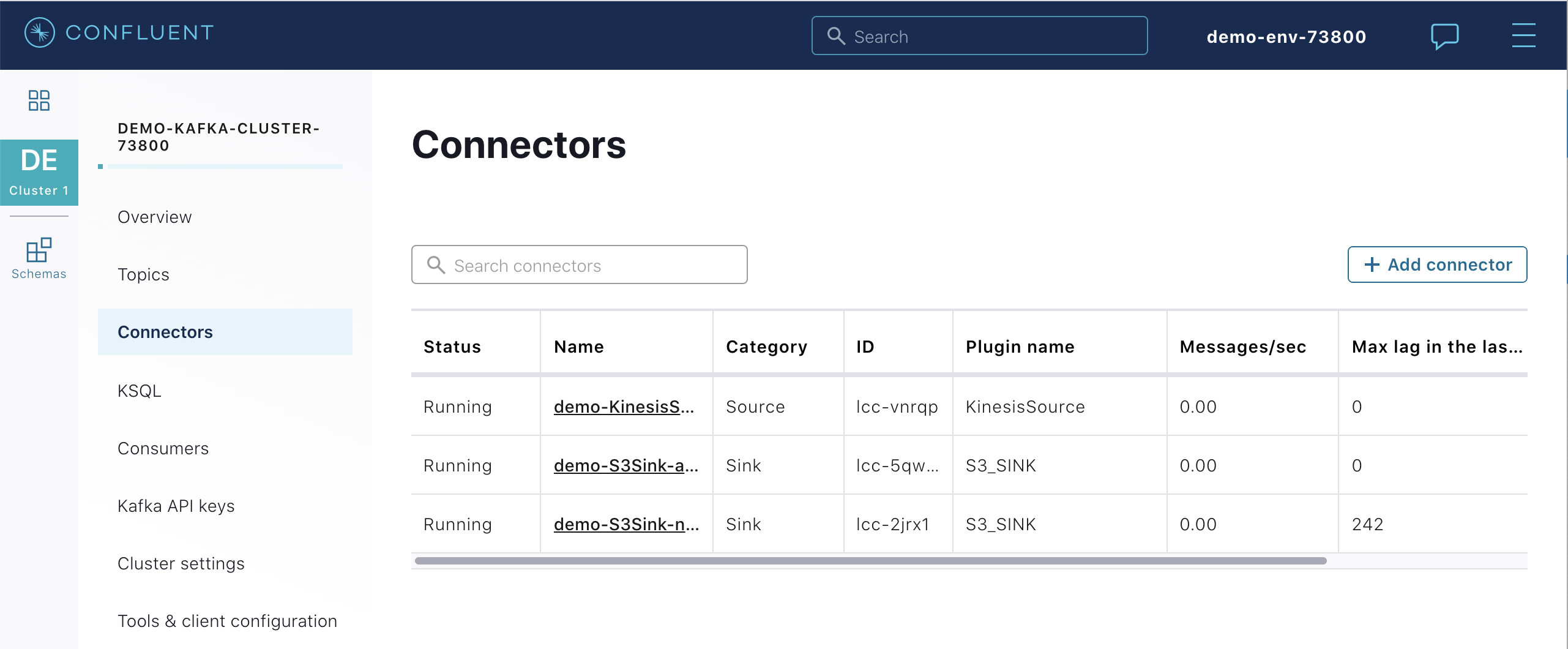
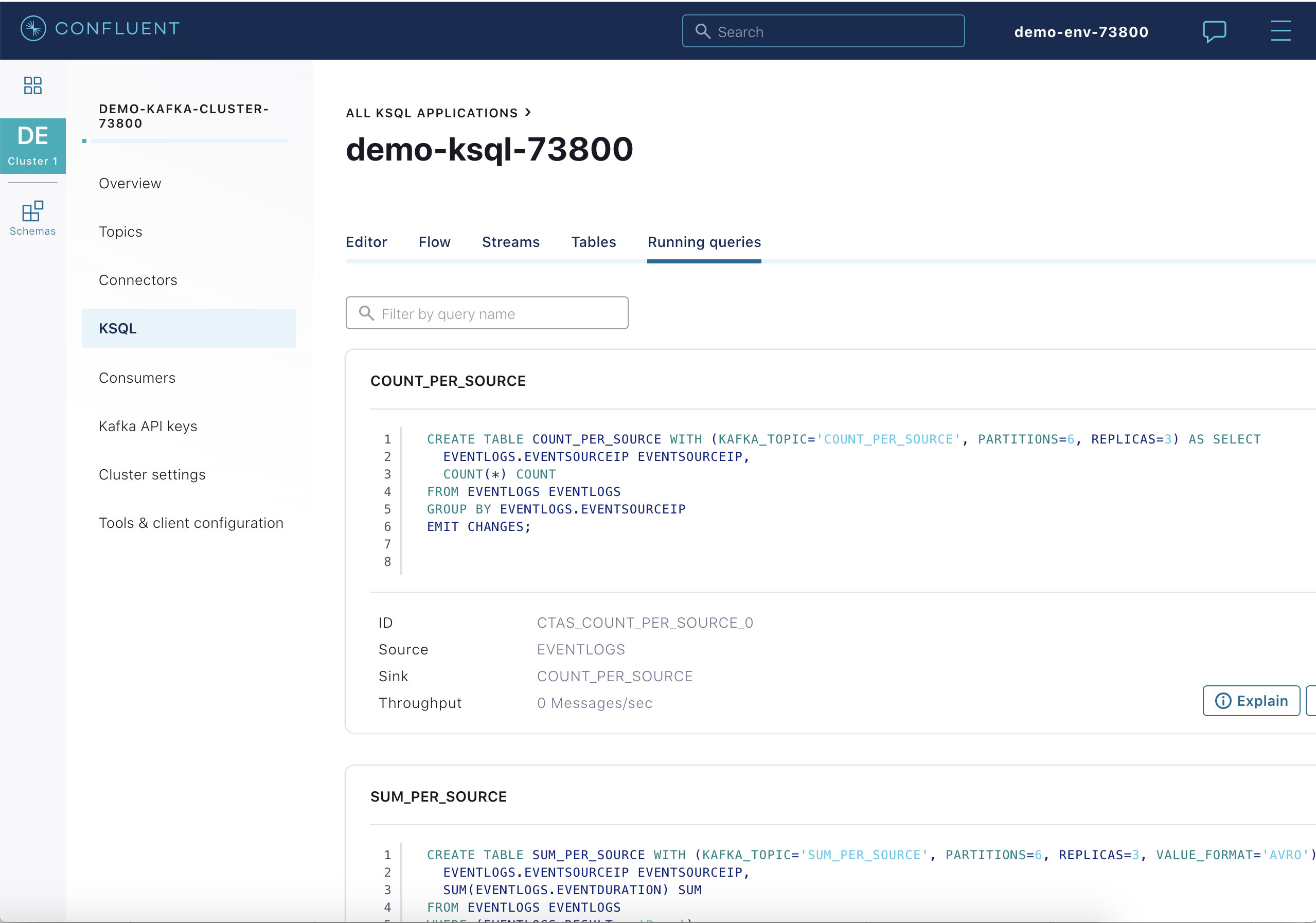
ksqlDB¶
From the Confluent Cloud UI, select your Kafka cluster and click the ksqlDB tab to view the flow through your ksqlDB application:

This flow is the result of this set of ksqlDB statements. It generated a ksqlDB TABLE
COUNT_PER_SOURCE, formatted as JSON, and its underlying Kafka topic isCOUNT_PER_SOURCE. It also generated a ksqlDB TABLESUM_PER_SOURCE, formatted as Avro, and its underlying Kafka topic isSUM_PER_SOURCE.CREATE STREAM eventlogs (eventSourceIP VARCHAR, eventAction VARCHAR, result VARCHAR, eventDuration BIGINT) WITH (KAFKA_TOPIC='eventlogs', VALUE_FORMAT='JSON'); CREATE TABLE count_per_source WITH (KAFKA_TOPIC='COUNT_PER_SOURCE', PARTITIONS=6) AS SELECT eventSourceIP, COUNT(*) as count FROM eventlogs GROUP BY eventSourceIP EMIT CHANGES; CREATE TABLE sum_per_source WITH (KAFKA_TOPIC='SUM_PER_SOURCE', PARTITIONS=6, VALUE_FORMAT='AVRO') AS SELECT eventSourceIP as ROWKEY, as_value(eventSourceIP) as eventSourceIP, SUM(EVENTDURATION) as sum FROM eventlogs WHERE (RESULT = 'Pass') GROUP BY eventSourceIP EMIT CHANGES;
Use the Confluent Cloud ksqlDB UI or its REST API to interact with the ksqlDB application:
curl -X POST $KSQLDB_ENDPOINT/ksql \ -H "Content-Type: application/vnd.ksql.v1+json; charset=utf-8" \ -u $KSQLDB_BASIC_AUTH_USER_INFO \ -d @<(cat <<EOF { "ksql": "SHOW QUERIES;", "streamsProperties": {} } EOF )Your output should resemble:
[ { "@type": "queries", "statementText": "SHOW QUERIES;", "queries": [ { "queryString": "CREATE TABLE COUNT_PER_SOURCE WITH (KAFKA_TOPIC='COUNT_PER_SOURCE', PARTITIONS=6, REPLICAS=3) AS SELECT\n EVENTLOGS.EVENTSOURCEIP EVENTSOURCEIP,\n COUNT(*) COUNT\nFROM EVENTLOGS EVENTLOGS\nGROUP BY EVENTLOGS.EVENTSOURCEIP\nEMIT CHANGES;", "sinks": [ "COUNT_PER_SOURCE" ], "sinkKafkaTopics": [ "COUNT_PER_SOURCE" ], "id": "CTAS_COUNT_PER_SOURCE_0", "statusCount": { "RUNNING": 1 }, "queryType": "PERSISTENT", "state": "RUNNING" }, { "queryString": "CREATE TABLE SUM_PER_SOURCE WITH (KAFKA_TOPIC='SUM_PER_SOURCE', PARTITIONS=6, REPLICAS=3, VALUE_FORMAT='AVRO') AS SELECT\n EVENTLOGS.EVENTSOURCEIP ROWKEY,\n AS_VALUE(EVENTLOGS.EVENTSOURCEIP) EVENTSOURCEIP,\n SUM(EVENTLOGS.EVENTDURATION) SUM\nFROM EVENTLOGS EVENTLOGS\nWHERE (EVENTLOGS.RESULT = 'Pass')\nGROUP BY EVENTLOGS.EVENTSOURCEIP\nEMIT CHANGES;", "sinks": [ "SUM_PER_SOURCE" ], "sinkKafkaTopics": [ "SUM_PER_SOURCE" ], "id": "CTAS_SUM_PER_SOURCE_5", "statusCount": { "RUNNING": 1 }, "queryType": "PERSISTENT", "state": "RUNNING" } ], "warnings": [] } ]View the Avro schema for the topic
SUM_PER_SOURCEin Confluent Cloud Schema Registry.curl --silent -u <SR API KEY>:<SR API SECRET> https://<SR ENDPOINT>/subjects/SUM_PER_SOURCE-value/versions/latest | jq -r '.schema' | jq .
Your output should resemble:
{ "type": "record", "name": "KsqlDataSourceSchema", "namespace": "io.confluent.ksql.avro_schemas", "fields": [ { "name": "EVENTSOURCEIP", "type": [ "null", "string" ], "default": null }, { "name": "SUM", "type": [ "null", "long" ], "default": null } ] }View these same queries from the Confluent Cloud UI at https://confluent.cloud/
Validate¶
View the data from Kinesis, Kafka, and cloud storage after running the demo, running the read-data.sh script.
./read-data.sh stack-configs/java-service-account-<SERVICE ACCOUNT ID>.config
Your output should resemble:
Data from Kinesis stream demo-logs --limit 10: {"eventSourceIP":"192.168.1.1","eventAction":"Upload","result":"Pass","eventDuration":3} {"eventSourceIP":"192.168.1.1","eventAction":"Create","result":"Pass","eventDuration":2} {"eventSourceIP":"192.168.1.1","eventAction":"Delete","result":"Fail","eventDuration":5} {"eventSourceIP":"192.168.1.2","eventAction":"Upload","result":"Pass","eventDuration":1} {"eventSourceIP":"192.168.1.2","eventAction":"Create","result":"Pass","eventDuration":3} {"eventSourceIP":"192.168.1.1","eventAction":"Upload","result":"Pass","eventDuration":3} {"eventSourceIP":"192.168.1.1","eventAction":"Create","result":"Pass","eventDuration":2} {"eventSourceIP":"192.168.1.1","eventAction":"Delete","result":"Fail","eventDuration":5} {"eventSourceIP":"192.168.1.2","eventAction":"Upload","result":"Pass","eventDuration":1} {"eventSourceIP":"192.168.1.2","eventAction":"Create","result":"Pass","eventDuration":3} Data from Kafka topic eventlogs: confluent local consume eventlogs -- --cloud --config stack-configs/java-service-account-<SERVICE ACCOUNT ID>.config --from-beginning --property print.key=true --max-messages 10 5 {"eventSourceIP":"192.168.1.5","eventAction":"Upload","result":"Pass","eventDuration":4} 5 {"eventSourceIP":"192.168.1.5","eventAction":"Create","result":"Pass","eventDuration":1} 5 {"eventSourceIP":"192.168.1.5","eventAction":"Delete","result":"Fail","eventDuration":1} 5 {"eventSourceIP":"192.168.1.5","eventAction":"Upload","result":"Pass","eventDuration":4} 5 {"eventSourceIP":"192.168.1.5","eventAction":"Create","result":"Pass","eventDuration":1} 5 {"eventSourceIP":"192.168.1.5","eventAction":"Delete","result":"Fail","eventDuration":1} 5 {"eventSourceIP":"192.168.1.5","eventAction":"Upload","result":"Pass","eventDuration":4} 5 {"eventSourceIP":"192.168.1.5","eventAction":"Create","result":"Pass","eventDuration":1} 5 {"eventSourceIP":"192.168.1.5","eventAction":"Delete","result":"Fail","eventDuration":1} 5 {"eventSourceIP":"192.168.1.5","eventAction":"Upload","result":"Pass","eventDuration":4} Data from Kafka topic COUNT_PER_SOURCE: confluent local consume COUNT_PER_SOURCE -- --cloud --config stack-configs/java-service-account-<SERVICE ACCOUNT ID>.config --from-beginning --property print.key=true --max-messages 10 192.168.1.5 {"EVENTSOURCEIP":"192.168.1.5","COUNT":1} 192.168.1.5 {"EVENTSOURCEIP":"192.168.1.5","COUNT":2} 192.168.1.5 {"EVENTSOURCEIP":"192.168.1.5","COUNT":3} 192.168.1.5 {"EVENTSOURCEIP":"192.168.1.5","COUNT":4} 192.168.1.5 {"EVENTSOURCEIP":"192.168.1.5","COUNT":5} 192.168.1.5 {"EVENTSOURCEIP":"192.168.1.5","COUNT":6} 192.168.1.5 {"EVENTSOURCEIP":"192.168.1.5","COUNT":7} 192.168.1.5 {"EVENTSOURCEIP":"192.168.1.5","COUNT":8} 192.168.1.5 {"EVENTSOURCEIP":"192.168.1.5","COUNT":9} 192.168.1.5 {"EVENTSOURCEIP":"192.168.1.5","COUNT":10} Data from Kafka topic SUM_PER_SOURCE: confluent local consume SUM_PER_SOURCE -- --cloud --config stack-configs/java-service-account-<SERVICE ACCOUNT ID>.config --from-beginning --property print.key=true --value-format avro --property basic.auth.credentials.source=USER_INFO --property schema.registry.basic.auth.user.info=$SCHEMA_REGISTRY_BASIC_AUTH_USER_INFO --property schema.registry.url=$SCHEMA_REGISTRY_URL --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --max-messages 10 192.168.1.2 {"EVENTSOURCEIP":{"string":"192.168.1.2"},"SUM":{"long":1}} 192.168.1.2 {"EVENTSOURCEIP":{"string":"192.168.1.2"},"SUM":{"long":4}} 192.168.1.2 {"EVENTSOURCEIP":{"string":"192.168.1.2"},"SUM":{"long":5}} 192.168.1.2 {"EVENTSOURCEIP":{"string":"192.168.1.2"},"SUM":{"long":8}} 192.168.1.2 {"EVENTSOURCEIP":{"string":"192.168.1.2"},"SUM":{"long":11}} 192.168.1.2 {"EVENTSOURCEIP":{"string":"192.168.1.2"},"SUM":{"long":12}} 192.168.1.2 {"EVENTSOURCEIP":{"string":"192.168.1.2"},"SUM":{"long":15}} 192.168.1.2 {"EVENTSOURCEIP":{"string":"192.168.1.2"},"SUM":{"long":16}} 192.168.1.2 {"EVENTSOURCEIP":{"string":"192.168.1.2"},"SUM":{"long":19}} 192.168.1.2 {"EVENTSOURCEIP":{"string":"192.168.1.2"},"SUM":{"long":22}} Objects in Cloud storage gcs: gs://confluent-cloud-etl-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=26/hour=03/COUNT_PER_SOURCE+1+0000000000.bin gs://confluent-cloud-etl-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=26/hour=03/COUNT_PER_SOURCE+1+0000001000.bin gs://confluent-cloud-etl-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=26/hour=03/COUNT_PER_SOURCE+1+0000002000.bin gs://confluent-cloud-etl-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=26/hour=03/COUNT_PER_SOURCE+1+0000003000.bin gs://confluent-cloud-etl-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=26/hour=03/COUNT_PER_SOURCE+1+0000004000.bin gs://confluent-cloud-etl-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=26/hour=03/COUNT_PER_SOURCE+3+0000000000.bin gs://confluent-cloud-etl-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=26/hour=03/COUNT_PER_SOURCE+3+0000001000.bin gs://confluent-cloud-etl-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=26/hour=03/COUNT_PER_SOURCE+3+0000002000.bin gs://confluent-cloud-etl-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=26/hour=03/COUNT_PER_SOURCE+3+0000003000.bin gs://confluent-cloud-etl-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=26/hour=03/COUNT_PER_SOURCE+3+0000004000.bin gs://confluent-cloud-etl-demo/topics/SUM_PER_SOURCE/year=2020/month=02/day=26/hour=03/SUM_PER_SOURCE+1+0000000000.avro gs://confluent-cloud-etl-demo/topics/SUM_PER_SOURCE/year=2020/month=02/day=26/hour=03/SUM_PER_SOURCE+1+0000001000.avro gs://confluent-cloud-etl-demo/topics/SUM_PER_SOURCE/year=2020/month=02/day=26/hour=03/SUM_PER_SOURCE+1+0000002000.avro gs://confluent-cloud-etl-demo/topics/SUM_PER_SOURCE/year=2020/month=02/day=26/hour=03/SUM_PER_SOURCE+1+0000003000.avro gs://confluent-cloud-etl-demo/topics/SUM_PER_SOURCE/year=2020/month=02/day=26/hour=03/SUM_PER_SOURCE+3+0000000000.avro gs://confluent-cloud-etl-demo/topics/SUM_PER_SOURCE/year=2020/month=02/day=26/hour=03/SUM_PER_SOURCE+3+0000001000.avro gs://confluent-cloud-etl-demo/topics/SUM_PER_SOURCE/year=2020/month=02/day=26/hour=03/SUM_PER_SOURCE+3+0000002000.avro gs://confluent-cloud-etl-demo/topics/SUM_PER_SOURCE/year=2020/month=02/day=26/hour=03/SUM_PER_SOURCE+3+0000003000.avroAdd more entries in the source and see them propagate through the pipeline by viewing messages in the Confluent Cloud UI or CLI.
If you are running Kinesis:
./add_entries_kinesis.sh
If you are running RDS PostgreSQL:
./add_entries_rds.sh
View the new messages from the Confluent Cloud UI.
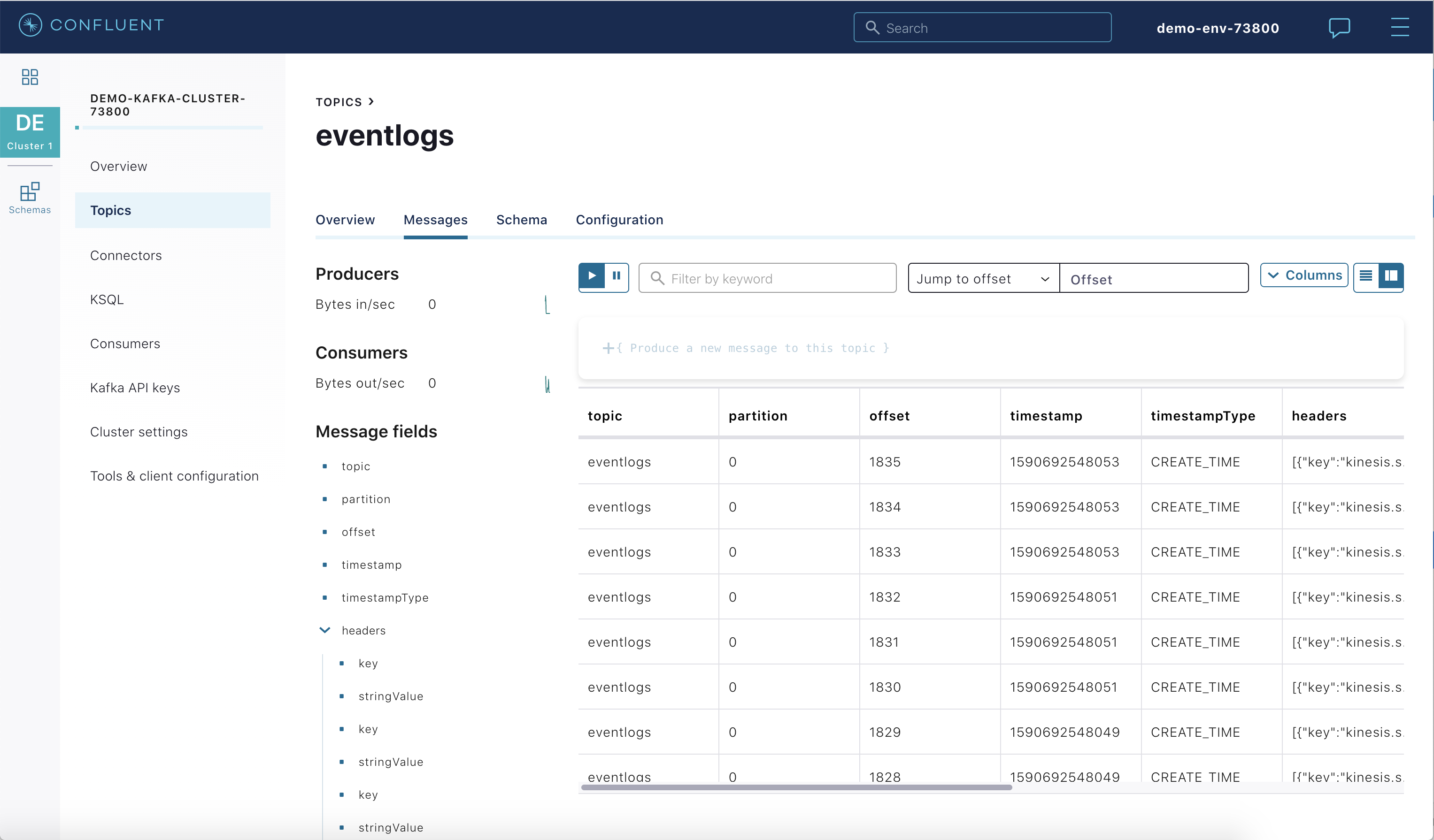
Stop¶
Stop the demo and clean up all the resources, delete Kafka topics, delete the fully-managed connectors, delete the data in the cloud storage:
./stop.sh stack-configs/java-service-account-<SERVICE ACCOUNT ID>.config
Always verify that resources in Confluent Cloud have been destroyed.
Additional Resources¶
- To find additional Confluent Cloud demos, see Confluent Cloud Demos Overview.