
Configure Replicator for Cross-Cluster Failover in Confluent Platform
Multi-datacenter designs load balance the processing of data in multiple clusters, and safeguard against outages by replicating data across the clusters. If one datacenter goes down, the remaining datacenters have replicas of the data and can take over where the failed datacenter left off. Once the original datacenter recovers, it resumes message processing. Replicator knows where to re-start data synchronization across clusters based on these supporting features for failover and disaster recovery:
This document describes parameters for the above features as a part of initial setup, and failover and recovery designs.
You can configure Replicator to manage failures in active-standby or active-active setups.
In an active-standby deployment, Replicator runs in one direction, copying Kafka messages and metadata from the active or primary cluster (Datacenter A in the example below) to the standby or secondary passive cluster (Datacenter B, below).
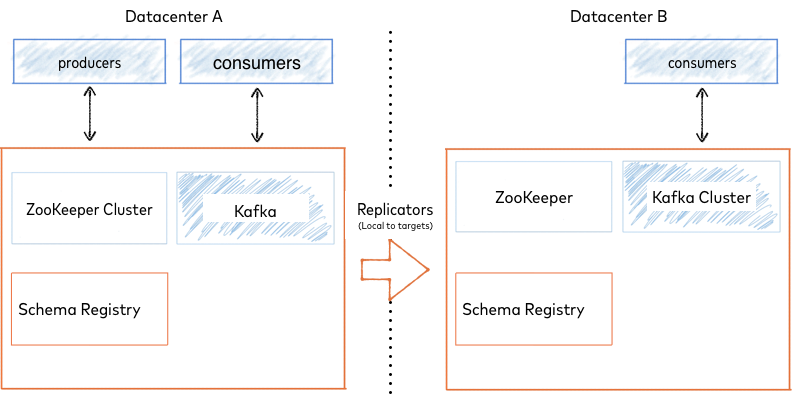
Active-Passive Deployment
In an active-active deployment, one Replicator copies Kafka messages and metadata from the origin Datacenter A to the destination Datacenter B, and another Replicator copies Kafka data and messages from origin Datacenter B to destination Datacenter A.
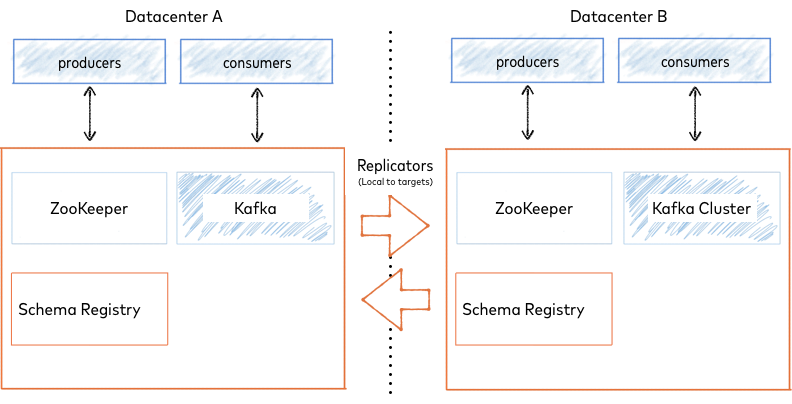
Active-Active Deployment
Producers write data to both clusters, and depending on client application design, consumers can read data produced in their own cluster along with data produced in the other cluster and replicated to their local cluster.
Configuring Replicator to handle failover scenarios
Replicator can translate committed offsets from the active primary cluster to the standby secondary cluster. In case of failover from the primary cluster to the secondary cluster, the consumers will start consuming data from the last committed offset.
Configuring the consumer for failover (timestamp preservation)
You must configure an additional interceptor for consumers from initial deployment in the source cluster. During failover, the interceptor will allow consumers to resume when reading topics that are replicated to the secondary cluster.
interceptor.classes=io.confluent.connect.replicator.offsets.ConsumerTimestampsInterceptor
Important
The
timestamp-interceptoris supported for consumers on Java based Kafka clients only.You can only set the
timestamp-interceptorfor consumers.Do not set the interceptor for Replicator.
Use discretion when setting the interceptor on Connect workers; for the interceptor to be useful, the worker must be running sink connectors and these must use Kafka for their offset management.
This interceptor is located under kafka-connect-replicator in (timestamp-interceptor-7.8.9.jar). This JAR must be available on the CLASSPATH of the consumer.
Tip
The location of the JAR file is dependent on your platform and type of Confluent install. For example, on Mac OS install with zip.tar, by default,
timestamp-interceptor-<version>.jaris in the Confluent directory in/share/java/kafka-connect-replicator.
The timestamp-interceptor is located in the Confluent Maven repository:
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
For Maven projects, include the following dependency:
<dependency>
<groupId>io.confluent</groupId>
<artifactId>timestamp-interceptor</artifactId>
<version>7.8.9</version>
</dependency>
The ConsumerTimestampsInterceptor will write to a new topic __consumer_timestamps to preserve the required timestamp information for the offset translation. The Replicator reads from this new topic and will use the timestamps to determine the correct offsets in the secondary cluster.
Important
The ConsumerTimestampsInterceptor is a producer to the __consumer_timestamps topic on the source cluster and as such requires appropriate security configurations. These should be provided with the timestamps.producer. prefix. for example, timestamps.producer.security.protocol=SSL. For more information on security configurations see:
The interceptor also requires ACLs for the __consumer_timestamps topic. The consumer principal requires WRITE and DESCRIBE operations on the __consumer_timestamps topic.
To learn more, see:
Discussion on consumer offsets and timestamp preservation in the whitepaper on Disaster Recovery for Multi-Datacenter Apache Kafka Deployments.
Replicator configuration for failover
You must set the following property to instruct Replicator to translate offsets and set them in the secondary cluster.
dest.kafka.bootstrap.servers=localhost:9092
Bringing the primary cluster back up after a failover
After the original primary cluster is restarted, it can be brought up to date by running Replicator in the primary cluster. This will copy data that has been produced in the secondary cluster since the failover. However, before running Replicator in the primary cluster, you must address these prerequisites:
There might be data in the primary cluster that was never replicated to the secondary before the failure occurred. Determine if the extra data needs to be copied to the secondary cluster, and whether its order matters. If order doesn’t matter, then you can briefly resume Replicator running in the secondary cluster to copy the data from the primary to the secondary. If order matters, then there is no standard answer on how to handle the extra data, since it will depend on your business needs.
The Replicator must only replicate new data. It should not replicate data that has already been replicated during the original active-standby configuration. Replicator uses the same offset translation mechanism that it uses for other consumers, to keep track of where it must resume in the secondary cluster. This allows it to switch from reading the primary to the secondary cluster. The ID of the consumer group must be the same when switching from one cluster to the other. For the consumer group ID, the Replicator will either use the value of
src.consumer.group.idif specified, or thenameof the Replicator.
Understanding consumer offset translation
Replicator automatically translates offsets using timestamps so that consumers can failover to a different datacenter and start consuming data in the destination cluster where they left off in the origin cluster.
If one cluster goes down, consumers must restart to connect to a new cluster. Before the outage, they consumed messages from topics in one cluster, and afterwards, they consume messages from topics in the other cluster or datacenter.
You can configure Replicator parameters on Consumer Offset Translation to specify where in a topic consumers should start reading, after failover to a new cluster.
By default, when a consumer is created in a failover cluster, you can set the configuration parameter auto.offset.reset to either latest or earliest.
For some applications and scenarios, these defaults are sufficient; for example, latest message for clickstream analytics or log analytics, and earliest message for idempotent systems or any other system that can handle duplicates. But for other applications, neither of these defaults may be appropriate. The desired behavior might be that the consumer starts reading at a specific message and consumes only the unread messages.
To target a specific offset (rather than rely on latest or earliest defaults), the consumer must reset its consumer offsets to meaningful values in the new cluster. Consumers can’t reset by relying only on offsets to determine where to start because the offsets may differ between clusters. One approach is to use timestamps. Timestamp preservation in messages adds context to offsets, so a consumer can start consuming messages at an offset that is derived from a timestamp.
You can configure offset translation by using the parameters described in Advanced configuration for failover scenarios (Tuning offset translation), Enabling or disabling offset translation, and Consumer Offset Translation in Replicator Configuration Reference for Confluent Platform.
To use this capability, configure Java consumer applications with an interceptor called Consumer Timestamps Interceptor, which preserves metadata of consumed messages including:
Consumer group ID
Topic name
Partition
Committed offset
Timestamp
Consumer timestamp information is preserved in a Kafka topic called __consumer_timestamps located in the origin cluster. Replicator does not replicate this topic because it has only local cluster significance.
Tip
You can view the data stored on the __consumer_timestamps topic using a console consumer. For this to work, the Replicator library must be added to the consumer classpath and special deserializers must be used.
export CLASSPATH=/usr/share/java/kafka-connect-replicator/*
kafka-console-consumer --topic __consumer_timestamps --bootstrap-server kafka1:9092 --property print.key=true --property key.deserializer=io.confluent.connect.replicator.offsets.GroupTopicPartitionDeserializer --property value.deserializer=io.confluent.connect.replicator.offsets.TimestampAndDeltaDeserializer
As Replicator copies data from one datacenter to another, it concurrently does the following:
Reads the consumer offset and timestamp information from the
__consumer_timestampstopic in the origin cluster to understand a consumer group’s progress.Translates the committed offsets in the origin datacenter to the corresponding offsets in the destination datacenter.
Writes the translated offsets to the
__consumer_offsetstopic in the destination cluster, as long as no consumers in that group are connected to the destination cluster.
When Replicator writes the translated offsets to the __consumer_offsets topic in the destination cluster, it applies the offsets to any topic renames configured with topic.rename.format. If there are already consumers in that consumer group connected to the destination cluster, Replicator does not write offsets to the __consumer_offsets topic since those consumers will be committing their own offsets. Either way, when a consumer application fails over to the backup cluster, it looks for and will find previously committed offsets using the normal mechanism.
Using provenance headers to prevent duplicates or cyclic message repetition
If provenance.header.enable=true, Replicator adds a provenance header to all records (messages) that it replicates to a given cluster. The provenance header contains:
ID of the origin cluster where this message was first produced
Name of the topic to which this message was first produced
Timestamp when Replicator first copied the record
Replicator can use this provenance header information to avoid duplicates when switching from one cluster to another (since records may have been replicated after the last committed offset). It checks to determine if the destination cluster is equal to the origin cluster from the provenance headers.
By default, Replicator will not replicate a message to a destination cluster if the cluster ID of the destination cluster matches the origin cluster ID in the provenance header, and if the destination topic name matches the origin topic name in the provenance header. Since these are checked at the topic level, you can replicate back to the origin cluster as long as it is to a different topic. For A -> B -> C, the record in C will have 2 provenance headers, one for B and one for A.
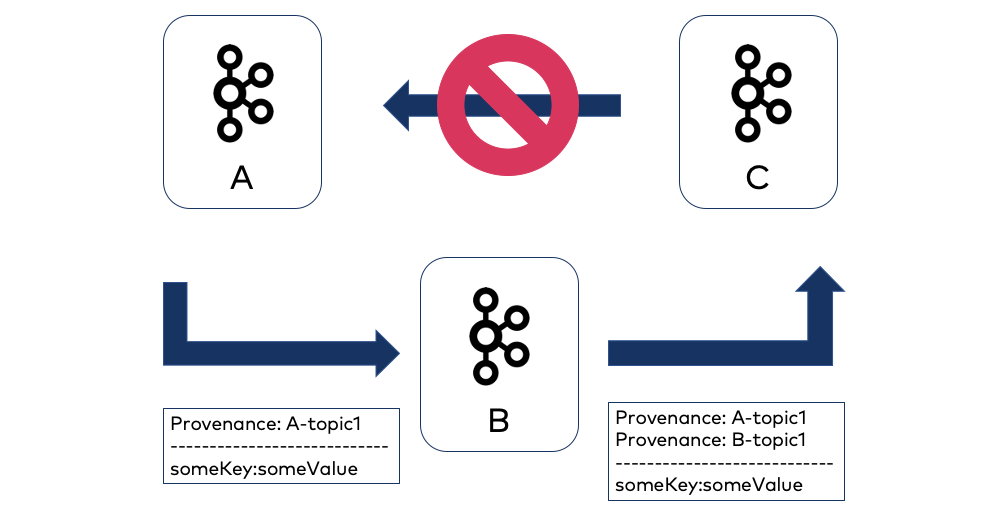
The provenance header is also useful for avoiding “infinite” replication loops in active-active setups involving bi-directional replication, where Replicator is running in each active cluster.
The effect of this is that even applications in different datacenters can access topics with exactly the same name while Replicator automatically avoids cyclic repetition of messages.
Tip
When using provenance headers, you must explicitly set header.converter=io.confluent.connect.replicator.util.ByteArrayConverter to get human readable header output, as described in Destination Data Conversion configuration options on Replicator. This enables the replicator to read the contents of the header.
To learn more, see provenance.header.enable under Consumer Offset Translation in the Replicator configuration reference.
However, if your brokers do not support the message format for 0.11.0 (message format version v2) or you have topics that do not support the message format for 0.11.0, then you will need to configure Replicator with provenance.header.enable=false (which is the default) or else errors will result. To learn more, see the discussion on Topic Renaming.
Provenance headers are a Replicator configuration option for Consumer Offset Translation.
Note
If Kafka messages have custom headers and are being replicated with provenance headers (provenance.header.enable=true), the consumer applications that are processing headers should skip the header with key __replicator_id. Depending on how the consumer is processing records, this may not require a code change. If the consumer is asking for a specific header, no change is required. If, however, the consumer is using toArray from the Kafka class Interface Headers to return all headers, the consumer must explicitly skip __replicator_id, otherwise, the replication will produce errors such as “could not decode JSON types ..” and “unrecognized tokens”.
Here is an example of Java code for the consumer that uses ConsumerRecord to read the header keys and skips __replicator_id:
ConsumerRecord<byte[], byte[]> record = ...
Headers headers = record.headers();
if (headers != null) {
for (Header header : headers) {
if (!"__replicator_id".equals(header.key())) {
... process application header...
}
}
}
Advanced configuration for failover scenarios (Tuning offset translation)
The following configuration properties are for advanced tuning of offset translation.
Important
Offset translation is for Java consumers only; it does not work for other types of applications.
Replicator configuration
offset.translator.tasks.maxThe maximum number of Replicator tasks that will perform offset translation. If -1 (the default), all tasks will perform offset translation.
Type: int
Default: -1
Importance: medium
offset.translator.tasks.separateWhether to translate offsets in separate tasks from those performing topic replication.
Type: boolean
Default: false
Importance: medium
offset.timestamps.commitWhether to commit internal offset timestamps for Replicator, so that it can resume properly when switching to the secondary cluster.
Type: boolean
Default: true
Importance: medium
provenance.header.enableWhether to enable the use of provenance headers during replication.
Type: boolean
Default: false
Importance: medium
fetch.offset.expiry.msThe amount of time in milliseconds after which a fetch offset request for offset translation expires and is discarded.
Type: long
Default: 600000
Importance: low
fetch.offset.retry.backoff.msThe amount of time in milliseconds to wait before attempting to retry a failed fetch offset request during offset translation.
Type: long
Default: 100
Importance: low
Consumer configuration
timestamps.topic.num.partitionsThe number of partitions for the consumer timestamps topic.
Type: int
Default: 50
Importance: high
timestamps.topic.replication.factorThe replication factor for the consumer timestamps topic.
Type: short
Default: 3
Importance: high
timestamps.topic.max.per.partitionThe maximum number of timestamp records that will be held in memory for processing per partition. This is initially unbounded but can be configured lower to reduce memory consumption. If the number of timestamp records exceeds this value, then timestamps could be lost, which would result in losing the corresponding translated offsets.
Type: int
Default: Integer.MAX_VALUE
Importance: low
Enabling or disabling offset translation
Consumer Offset Translation is enabled (on) by default (offset.translator.tasks.max is set to -1).
There are some cases that may require disabling offset translation. For example:
To troubleshoot a Replicator issue
When upgrading from earlier releases of Replicator that did not have bootstrap servers configured (with offset translation enabled, you would get an error message
ConfigException: No resolvable bootstrap urls given in bootstrap.servers)
To disable offset translation, specify the following parameters:
offset.timestamps.commit=false- Turn off committing internal consumer offset timestamps to source.offset.translator.tasks.max=0- Turn off offset translation for consumer interceptors.
To re-enable offset translation, set offset.timestamps.commit to true and offset.translator.tasks.max to -1.